 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Geolocation of Cultural Heritage using Multi-View Knowledge Graph Embedding
Sep 08, 2022
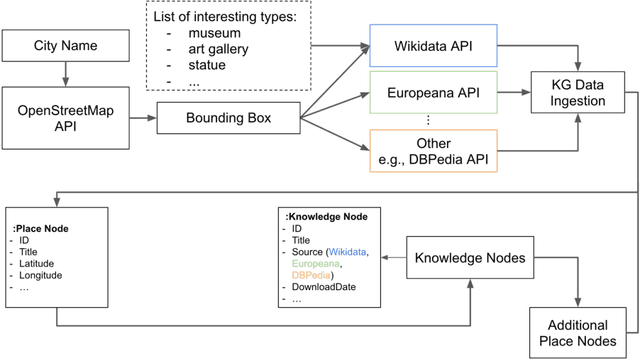

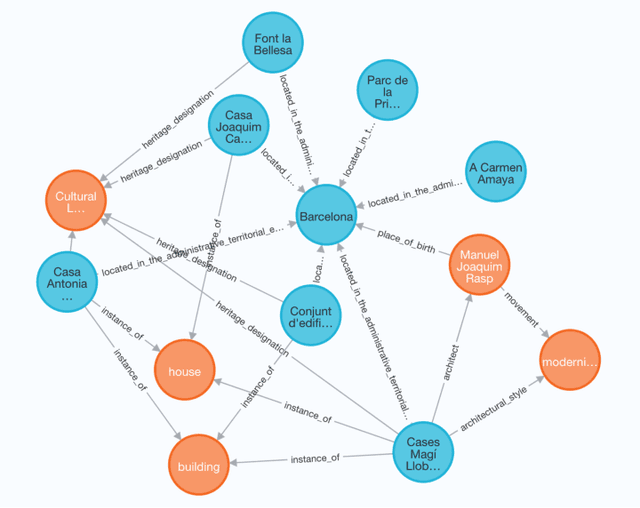
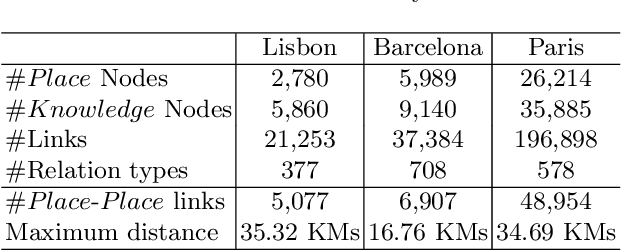
Knowledge Graphs (KGs) have proven to be a reliable way of structuring data. They can provide a rich source of contextual information about cultural heritage collections. However, cultural heritage KGs are far from being complete. They are often missing important attributes such as geographical location, especially for sculptures and mobile or indoor entities such as paintings. In this paper, we first present a framework for ingesting knowledge about tangible cultural heritage entities from various data sources and their connected multi-hop knowledge into a geolocalized KG. Secondly, we propose a multi-view learning model for estimating the relative distance between a given pair of cultural heritage entities, based on the geographical as well as the knowledge connections of the entities.
Quantum Noise-Induced Reservoir Computing
Jul 16, 2022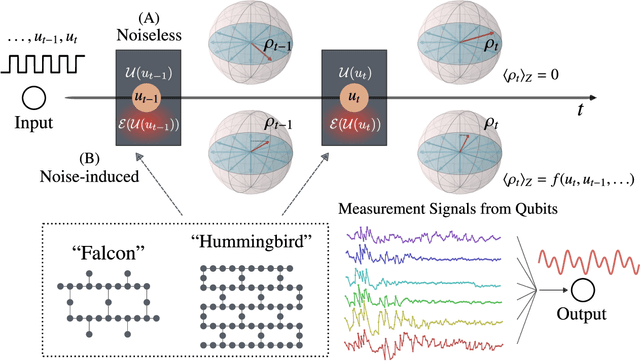
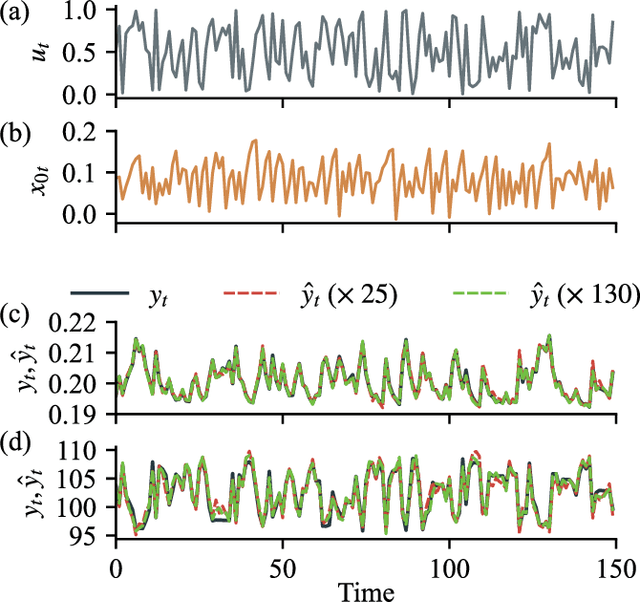
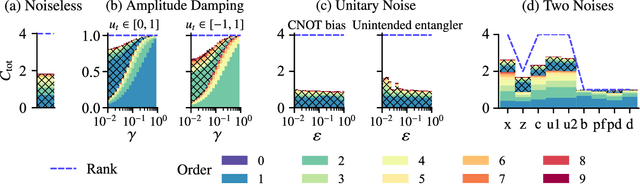
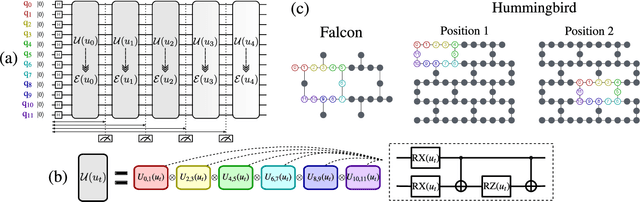
Quantum computing has been moving from a theoretical phase to practical one, presenting daunting challenges in implementing physical qubits, which are subjected to noises from the surrounding environment. These quantum noises are ubiquitous in quantum devices and generate adverse effects in the quantum computational model, leading to extensive research on their correction and mitigation techniques. But do these quantum noises always provide disadvantages? We tackle this issue by proposing a framework called quantum noise-induced reservoir computing and show that some abstract quantum noise models can induce useful information processing capabilities for temporal input data. We demonstrate this ability in several typical benchmarks and investigate the information processing capacity to clarify the framework's processing mechanism and memory profile. We verified our perspective by implementing the framework in a number of IBM quantum processors and obtained similar characteristic memory profiles with model analyses. As a surprising result, information processing capacity increased with quantum devices' higher noise levels and error rates. Our study opens up a novel path for diverting useful information from quantum computer noises into a more sophisticated information processor.
CometKiwi: IST-Unbabel 2022 Submission for the Quality Estimation Shared Task
Sep 13, 2022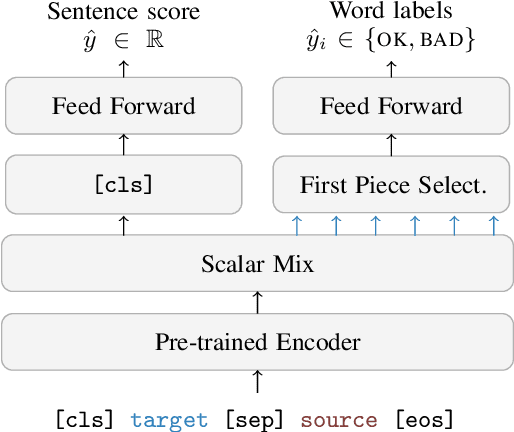
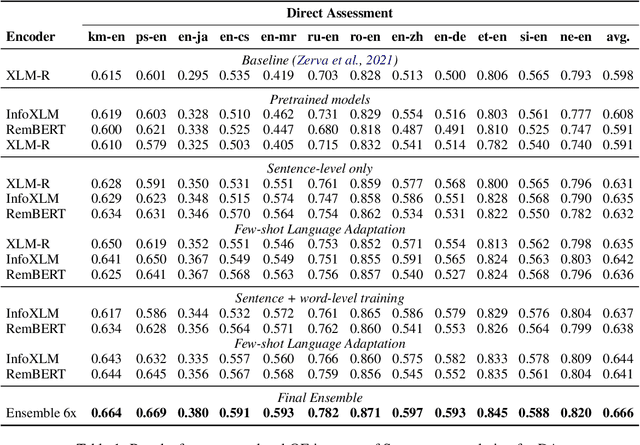
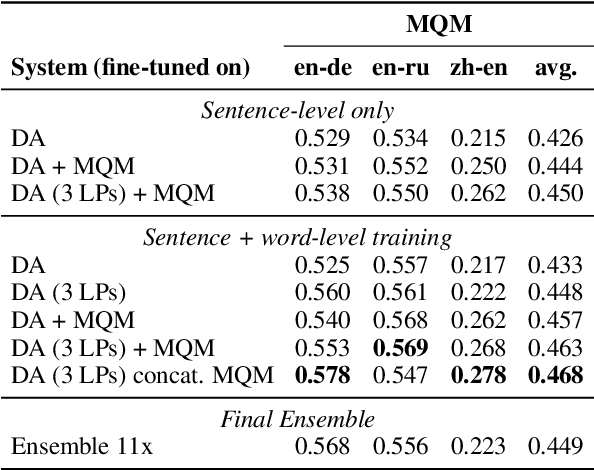
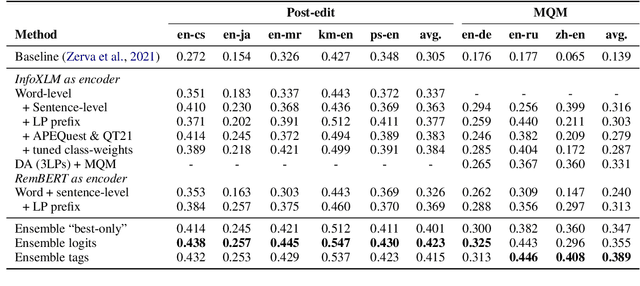
We present the joint contribution of IST and Unbabel to the WMT 2022 Shared Task on Quality Estimation (QE). Our team participated on all three subtasks: (i) Sentence and Word-level Quality Prediction; (ii) Explainable QE; and (iii) Critical Error Detection. For all tasks we build on top of the COMET framework, connecting it with the predictor-estimator architecture of OpenKiwi, and equipping it with a word-level sequence tagger and an explanation extractor. Our results suggest that incorporating references during pretraining improves performance across several language pairs on downstream tasks, and that jointly training with sentence and word-level objectives yields a further boost. Furthermore, combining attention and gradient information proved to be the top strategy for extracting good explanations of sentence-level QE models. Overall, our submissions achieved the best results for all three tasks for almost all language pairs by a considerable margin.
VS-CAM: Vertex Semantic Class Activation Mapping to Interpret Vision Graph Neural Network
Sep 15, 2022

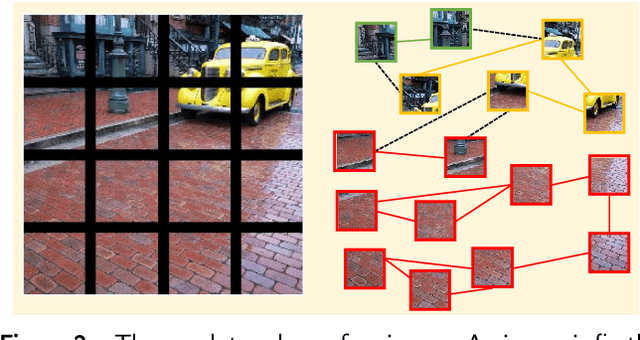

Graph convolutional neural network (GCN) has drawn increasing attention and attained good performance in various computer vision tasks, however, there lacks a clear interpretation of GCN's inner mechanism. For standard convolutional neural networks (CNNs), class activation mapping (CAM) methods are commonly used to visualize the connection between CNN's decision and image region by generating a heatmap. Nonetheless, such heatmap usually exhibits semantic-chaos when these CAMs are applied to GCN directly. In this paper, we proposed a novel visualization method particularly applicable to GCN, Vertex Semantic Class Activation Mapping (VS-CAM). VS-CAM includes two independent pipelines to produce a set of semantic-probe maps and a semantic-base map, respectively. Semantic-probe maps are used to detect the semantic information from semantic-base map to aggregate a semantic-aware heatmap. Qualitative results show that VS-CAM can obtain heatmaps where the highlighted regions match the objects much more precisely than CNN-based CAM. The quantitative evaluation further demonstrates the superiority of VS-CAM.
Physics-Informed Graph Neural Network for Spatial-temporal Production Forecasting
Sep 23, 2022

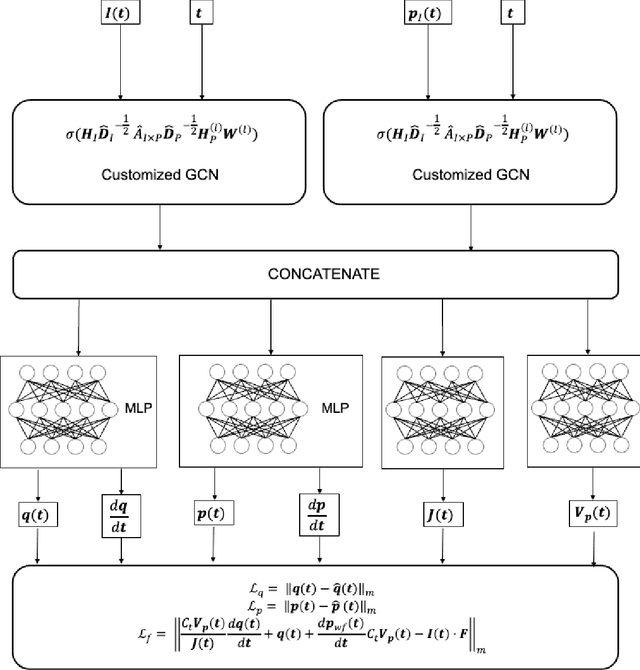
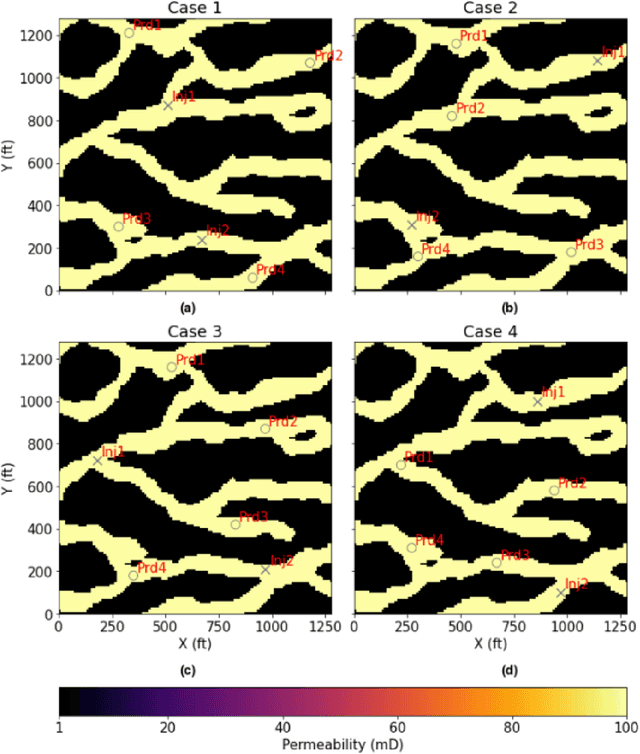
Production forecast based on historical data provides essential value for developing hydrocarbon resources. Classic history matching workflow is often computationally intense and geometry-dependent. Analytical data-driven models like decline curve analysis (DCA) and capacitance resistance models (CRM) provide a grid-free solution with a relatively simple model capable of integrating some degree of physics constraints. However, the analytical solution may ignore subsurface geometries and is appropriate only for specific flow regimes and otherwise may violate physics conditions resulting in degraded model prediction accuracy. Machine learning-based predictive model for time series provides non-parametric, assumption-free solutions for production forecasting, but are prone to model overfit due to training data sparsity; therefore may be accurate over short prediction time intervals. We propose a grid-free, physics-informed graph neural network (PI-GNN) for production forecasting. A customized graph convolution layer aggregates neighborhood information from historical data and has the flexibility to integrate domain expertise into the data-driven model. The proposed method relaxes the dependence on close-form solutions like CRM and honors the given physics-based constraints. Our proposed method is robust, with improved performance and model interpretability relative to the conventional CRM and GNN baseline without physics constraints.
Enhancing Identification of Structure Function of Academic Articles Using Contextual Information
Dec 02, 2021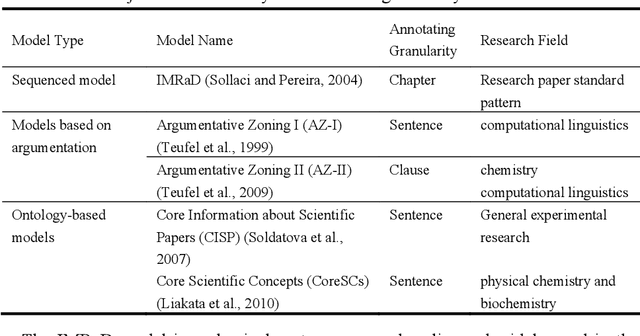
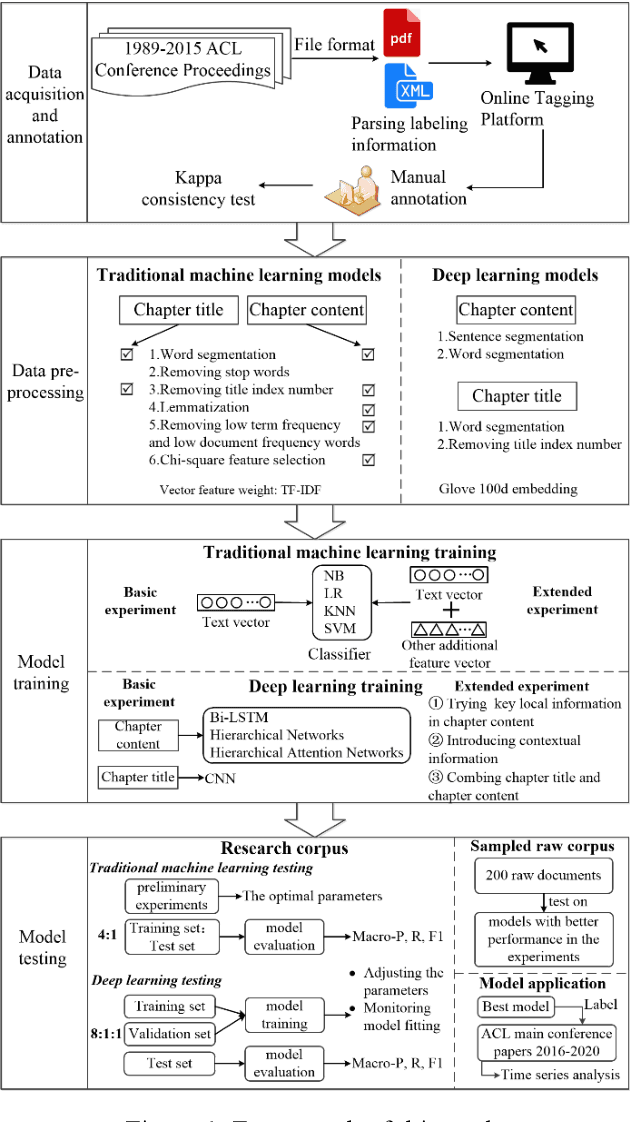
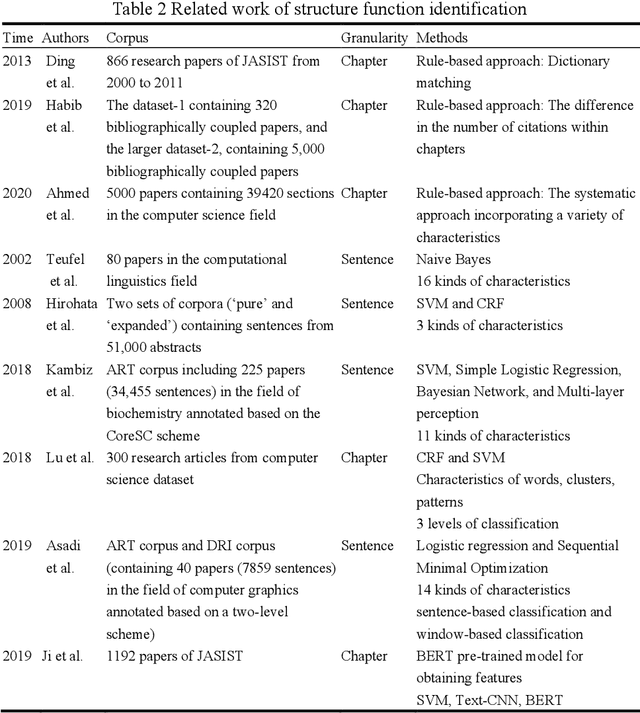
With the enrichment of literature resources, researchers are facing the growing problem of information explosion and knowledge overload. To help scholars retrieve literature and acquire knowledge successfully, clarifying the semantic structure of the content in academic literature has become the essential research question. In the research on identifying the structure function of chapters in academic articles, only a few studies used the deep learning model and explored the optimization for feature input. This limits the application, optimization potential of deep learning models for the research task. This paper took articles of the ACL conference as the corpus. We employ the traditional machine learning models and deep learning models to construct the classifiers based on various feature input. Experimental results show that (1) Compared with the chapter content, the chapter title is more conducive to identifying the structure function of academic articles. (2) Relative position is a valuable feature for building traditional models. (3) Inspired by (2), this paper further introduces contextual information into the deep learning models and achieved significant results. Meanwhile, our models show good migration ability in the open test containing 200 sampled non-training samples. We also annotated the ACL main conference papers in recent five years based on the best practice performing models and performed a time series analysis of the overall corpus. This work explores and summarizes the practical features and models for this task through multiple comparative experiments and provides a reference for related text classification tasks. Finally, we indicate the limitations and shortcomings of the current model and the direction of further optimization.
Neural Distributed Image Compression with Cross-Attention Feature Alignment
Jul 18, 2022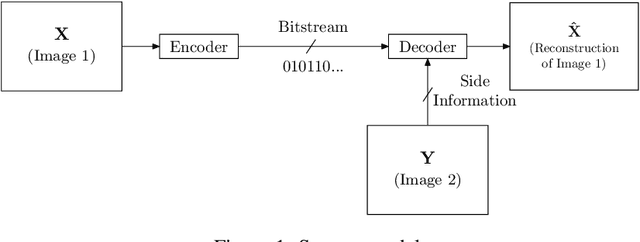
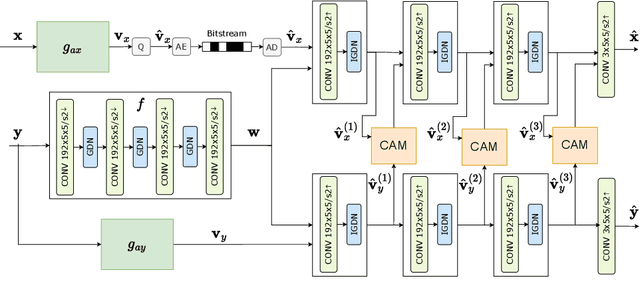
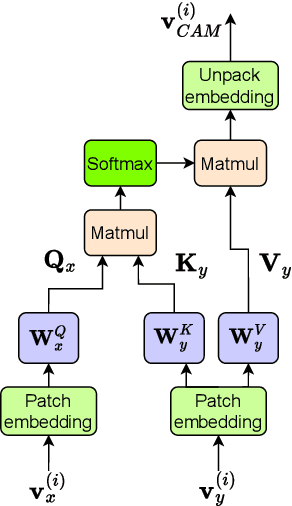
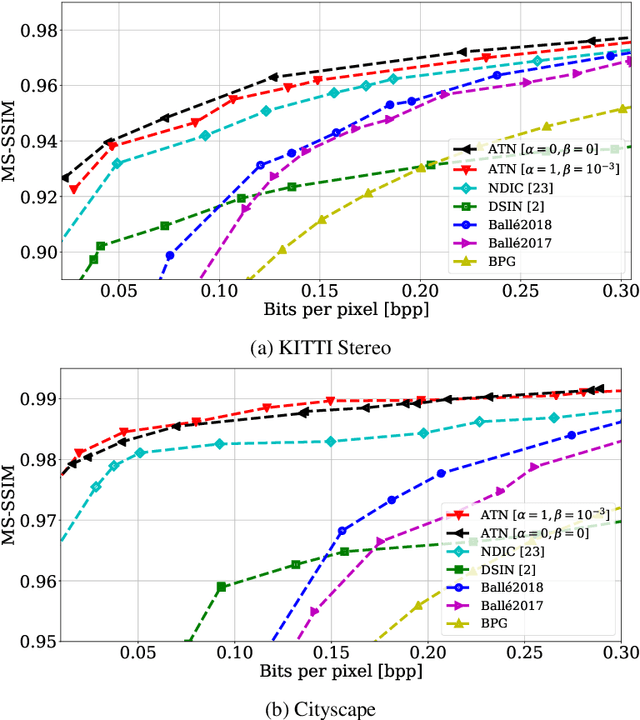
We propose a novel deep neural network (DNN) architecture for compressing an image when a correlated image is available as side information only at the decoder side, a special case of the well-known and heavily studied distributed source coding (DSC) problem. In particular, we consider a pair of stereo images, which have overlapping fields of view, captured by a synchronized and calibrated pair of cameras; and therefore, are highly correlated. We assume that one image of the pair is to be compressed and transmitted, while the other image is available only at the decoder. In the proposed architecture, the encoder maps the input image to a latent space using a DNN, quantizes the latent representation, and compresses it losslessly using entropy coding. The proposed decoder extracts useful information common between the images solely from the available side information, as well as a latent representation of the side information. Then, the latent representations of the two images, one received from the encoder, the other extracted locally, along with the locally generated common information, are fed to the respective decoders of the two images. We employ a cross-attention module (CAM) to align the feature maps obtained in the intermediate layers of the respective decoders of the two images, thus allowing better utilization of the side information. We train and demonstrate the effectiveness of the proposed algorithm on various realistic setups, such as KITTI and Cityscape datasets of stereo image pairs. Our results show that the proposed architecture is capable of exploiting the decoder-only side information in a more efficient manner as it outperforms previous works. We also show that the proposed method is able to provide significant gains even in the case of uncalibrated and unsynchronized camera array use cases.
CSSAM: U-net Network for Application and Segmentation of Welding Engineering Drawings
Sep 28, 2022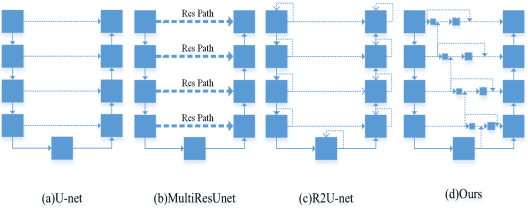
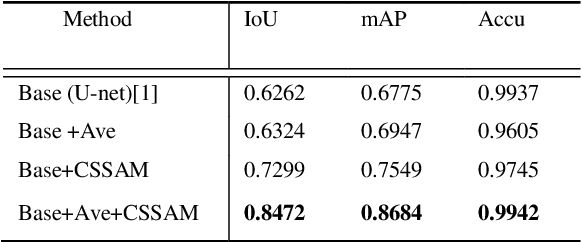
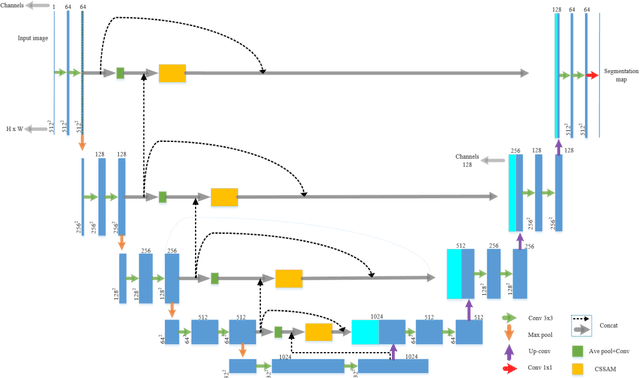

Heavy equipment manufacturing splits specific contours in drawings and cuts sheet metal to scale for welding. Currently, most of the segmentation and extraction of weld map contours is achieved manually. Its efficiency is greatly reduced. Therefore, we propose a U-net-based contour segmentation and extraction method for welding engineering drawings. The contours of the parts required for engineering drawings can be automatically divided and blanked, which significantly improves manufacturing efficiency. U-net includes an encoder-decoder, which implements end-to-end mapping through semantic differences and spatial location feature information between the encoder and decoder. While U-net excels at segmenting medical images, our extensive experiments on the Welding Structural Diagram dataset show that the classic U-Net architecture falls short in segmenting welding engineering drawings. Therefore, we design a novel Channel Spatial Sequence Attention Module (CSSAM) and improve on the classic U-net. At the same time, vertical max pooling and average horizontal pooling are proposed. Pass the pooling operation through two equal convolutions into the CSSAM module. The output and the features before pooling are fused by semantic clustering, which replaces the traditional jump structure and effectively narrows the semantic gap between the encoder and the decoder, thereby improving the segmentation performance of welding engineering drawings. We use vgg16 as the backbone network. Compared with the classic U-net, our network has good performance in engineering drawing dataset segmentation.
Zero-Shot Information Extraction as a Unified Text-to-Triple Translation
Sep 23, 2021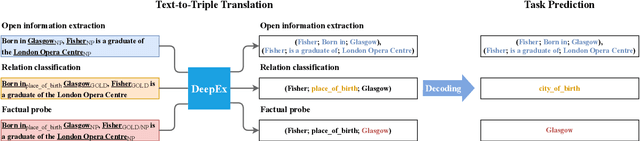
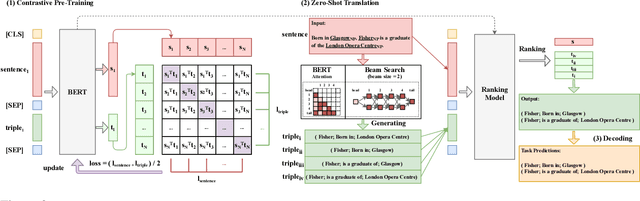

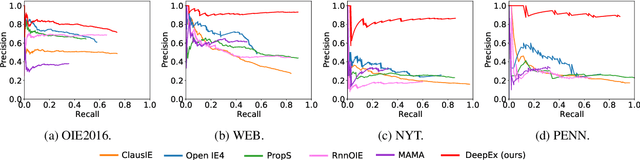
We cast a suite of information extraction tasks into a text-to-triple translation framework. Instead of solving each task relying on task-specific datasets and models, we formalize the task as a translation between task-specific input text and output triples. By taking the task-specific input, we enable a task-agnostic translation by leveraging the latent knowledge that a pre-trained language model has about the task. We further demonstrate that a simple pre-training task of predicting which relational information corresponds to which input text is an effective way to produce task-specific outputs. This enables the zero-shot transfer of our framework to downstream tasks. We study the zero-shot performance of this framework on open information extraction (OIE2016, NYT, WEB, PENN), relation classification (FewRel and TACRED), and factual probe (Google-RE and T-REx). The model transfers non-trivially to most tasks and is often competitive with a fully supervised method without the need for any task-specific training. For instance, we significantly outperform the F1 score of the supervised open information extraction without needing to use its training set.
A Gaze into the Internal Logic of Graph Neural Networks, with Logic
Aug 05, 2022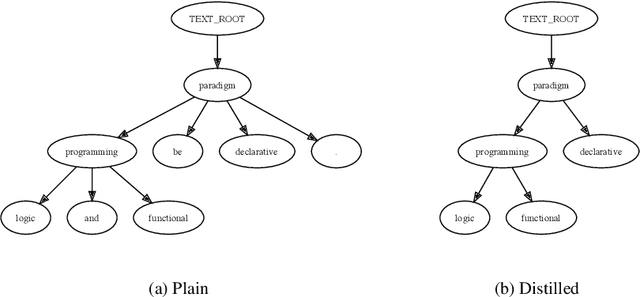

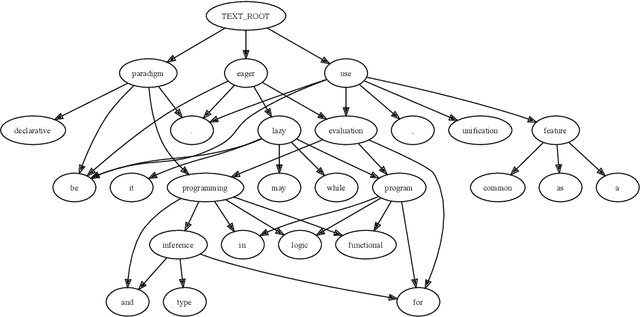
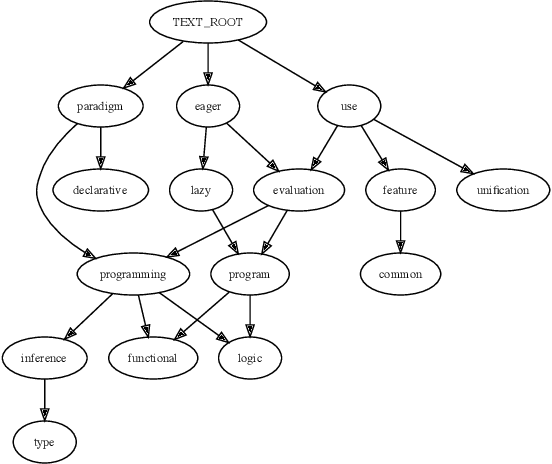
Graph Neural Networks share with Logic Programming several key relational inference mechanisms. The datasets on which they are trained and evaluated can be seen as database facts containing ground terms. This makes possible modeling their inference mechanisms with equivalent logic programs, to better understand not just how they propagate information between the entities involved in the machine learning process but also to infer limits on what can be learned from a given dataset and how well that might generalize to unseen test data. This leads us to the key idea of this paper: modeling with the help of a logic program the information flows involved in learning to infer from the link structure of a graph and the information content of its nodes properties of new nodes, given their known connections to nodes with possibly similar properties. The problem is known as graph node property prediction and our approach will consist in emulating with help of a Prolog program the key information propagation steps of a Graph Neural Network's training and inference stages. We test our a approach on the ogbn-arxiv node property inference benchmark. To infer class labels for nodes representing papers in a citation network, we distill the dependency trees of the text associated to each node into directed acyclic graphs that we encode as ground Prolog terms. Together with the set of their references to other papers, they become facts in a database on which we reason with help of a Prolog program that mimics the information propagation in graph neural networks predicting node properties. In the process, we invent ground term similarity relations that help infer labels in the test set by propagating node properties from similar nodes in the training set and we evaluate their effectiveness in comparison with that of the graph's link structure. Finally, we implement explanation generators that unveil performance upper bounds inherent to the dataset. As a practical outcome, we obtain a logic program, that, when seen as machine learning algorithm, performs close to the state of the art on the node property prediction benchmark.
* In Proceedings ICLP 2022, arXiv:2208.02685