 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
In Differential Privacy, There is Truth: On Vote Leakage in Ensemble Private Learning
Sep 22, 2022
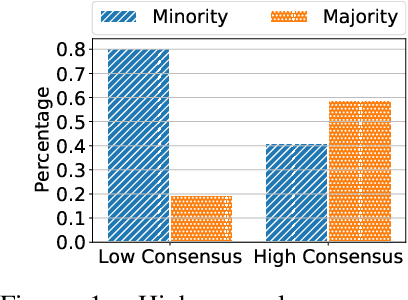

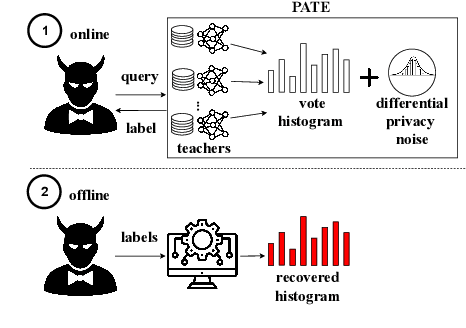
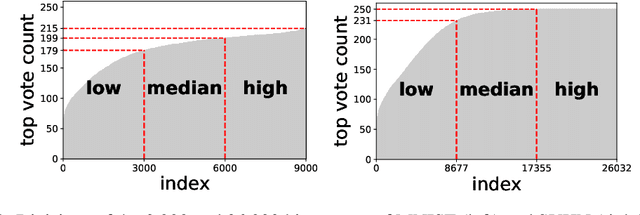
When learning from sensitive data, care must be taken to ensure that training algorithms address privacy concerns. The canonical Private Aggregation of Teacher Ensembles, or PATE, computes output labels by aggregating the predictions of a (possibly distributed) collection of teacher models via a voting mechanism. The mechanism adds noise to attain a differential privacy guarantee with respect to the teachers' training data. In this work, we observe that this use of noise, which makes PATE predictions stochastic, enables new forms of leakage of sensitive information. For a given input, our adversary exploits this stochasticity to extract high-fidelity histograms of the votes submitted by the underlying teachers. From these histograms, the adversary can learn sensitive attributes of the input such as race, gender, or age. Although this attack does not directly violate the differential privacy guarantee, it clearly violates privacy norms and expectations, and would not be possible at all without the noise inserted to obtain differential privacy. In fact, counter-intuitively, the attack becomes easier as we add more noise to provide stronger differential privacy. We hope this encourages future work to consider privacy holistically rather than treat differential privacy as a panacea.
Bias amplification in experimental social networks is reduced by resampling
Aug 15, 2022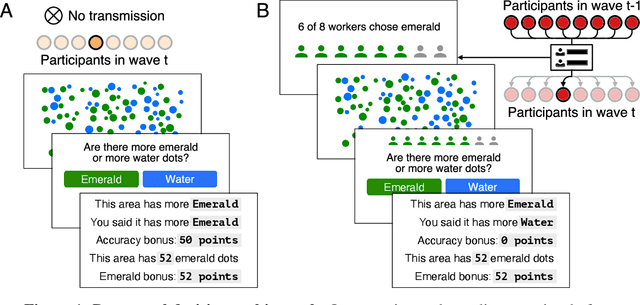
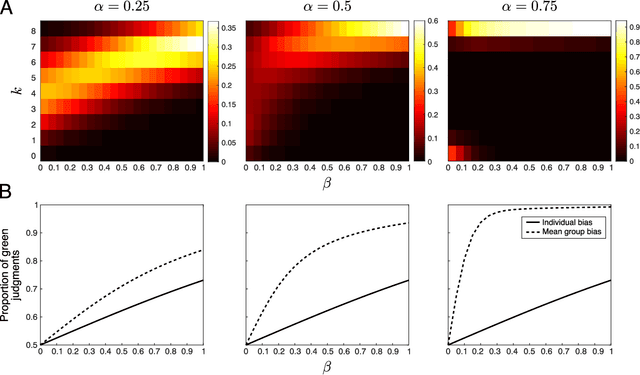
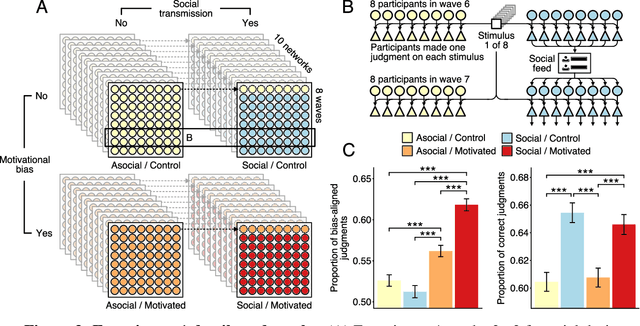
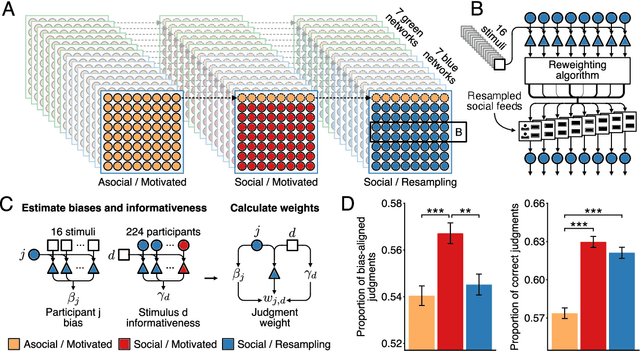
Large-scale social networks are thought to contribute to polarization by amplifying people's biases. However, the complexity of these technologies makes it difficult to identify the mechanisms responsible and to evaluate mitigation strategies. Here we show under controlled laboratory conditions that information transmission through social networks amplifies motivational biases on a simple perceptual decision-making task. Participants in a large behavioral experiment showed increased rates of biased decision-making when part of a social network relative to asocial participants, across 40 independently evolving populations. Drawing on techniques from machine learning and Bayesian statistics, we identify a simple adjustment to content-selection algorithms that is predicted to mitigate bias amplification. This algorithm generates a sample of perspectives from within an individual's network that is more representative of the population as a whole. In a second large experiment, this strategy reduced bias amplification while maintaining the benefits of information sharing.
Speechformer: Reducing Information Loss in Direct Speech Translation
Sep 09, 2021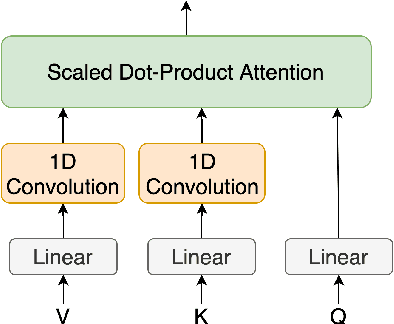
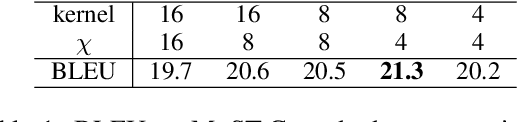
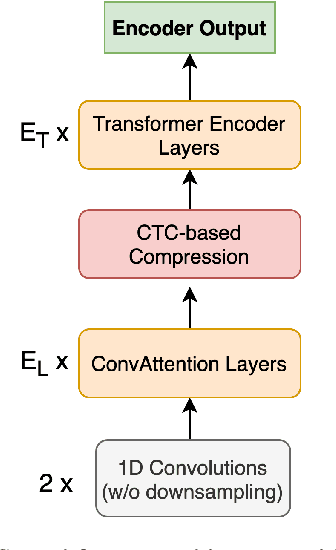
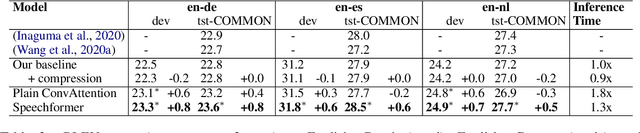
Transformer-based models have gained increasing popularity achieving state-of-the-art performance in many research fields including speech translation. However, Transformer's quadratic complexity with respect to the input sequence length prevents its adoption as is with audio signals, which are typically represented by long sequences. Current solutions resort to an initial sub-optimal compression based on a fixed sampling of raw audio features. Therefore, potentially useful linguistic information is not accessible to higher-level layers in the architecture. To solve this issue, we propose Speechformer, an architecture that, thanks to reduced memory usage in the attention layers, avoids the initial lossy compression and aggregates information only at a higher level according to more informed linguistic criteria. Experiments on three language pairs (en->de/es/nl) show the efficacy of our solution, with gains of up to 0.8 BLEU on the standard MuST-C corpus and of up to 4.0 BLEU in a low resource scenario.
Design of experiments for the calibration of history-dependent models via deep reinforcement learning and an enhanced Kalman filter
Sep 27, 2022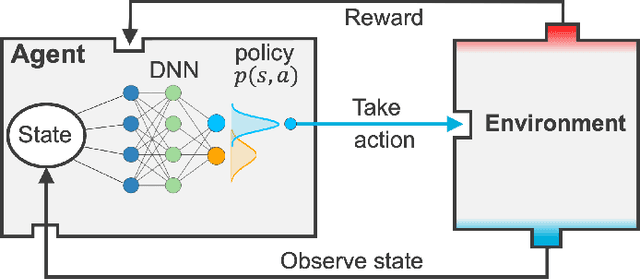

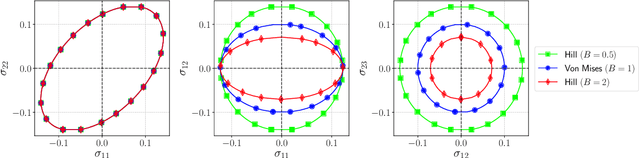
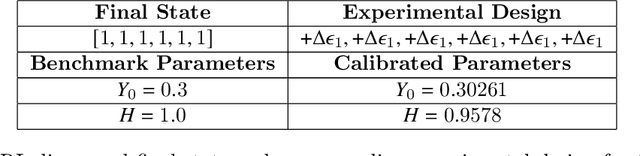
Experimental data is costly to obtain, which makes it difficult to calibrate complex models. For many models an experimental design that produces the best calibration given a limited experimental budget is not obvious. This paper introduces a deep reinforcement learning (RL) algorithm for design of experiments that maximizes the information gain measured by Kullback-Leibler (KL) divergence obtained via the Kalman filter (KF). This combination enables experimental design for rapid online experiments where traditional methods are too costly. We formulate possible configurations of experiments as a decision tree and a Markov decision process (MDP), where a finite choice of actions is available at each incremental step. Once an action is taken, a variety of measurements are used to update the state of the experiment. This new data leads to a Bayesian update of the parameters by the KF, which is used to enhance the state representation. In contrast to the Nash-Sutcliffe efficiency (NSE) index, which requires additional sampling to test hypotheses for forward predictions, the KF can lower the cost of experiments by directly estimating the values of new data acquired through additional actions. In this work our applications focus on mechanical testing of materials. Numerical experiments with complex, history-dependent models are used to verify the implementation and benchmark the performance of the RL-designed experiments.
CBAG: An Efficient Genetic Algorithm for the Graph Burning Problem
Aug 06, 2022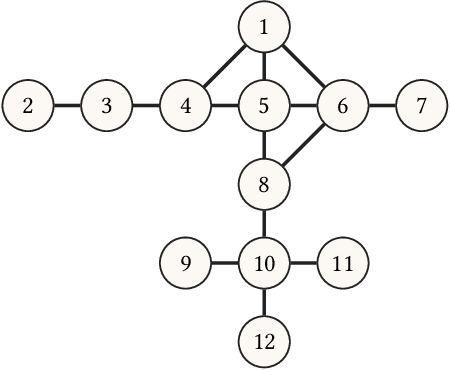
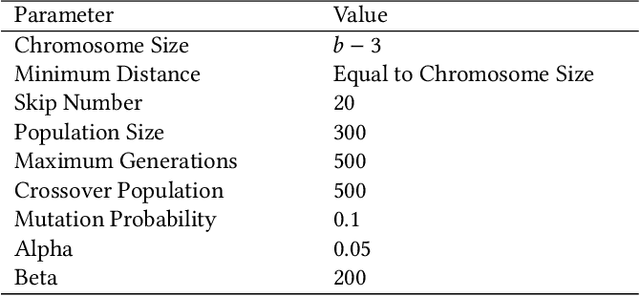
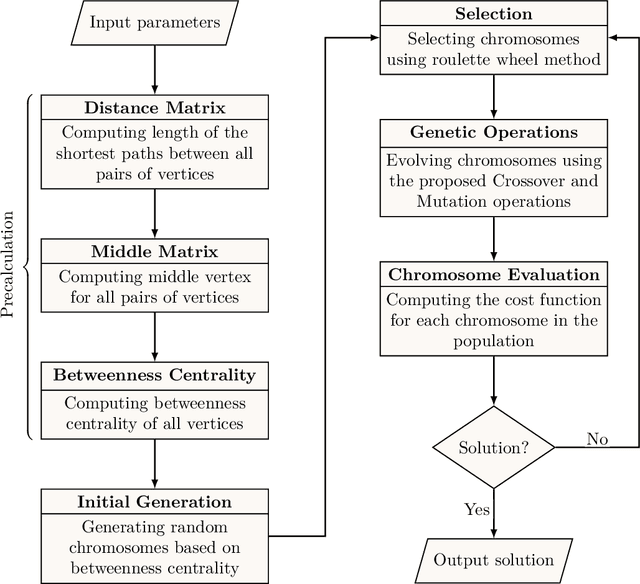

Information spread is an intriguing topic to study in network science, which investigates how information, influence, or contagion propagate through networks. Graph burning is a simplified deterministic model for how information spreads within networks. The complicated NP-complete nature of the problem makes it computationally difficult to solve using exact algorithms. Accordingly, a number of heuristics and approximation algorithms have been proposed in the literature for the graph burning problem. In this paper, we propose an efficient genetic algorithm called Centrality BAsed Genetic-algorithm (CBAG) for solving the graph burning problem. Considering the unique characteristics of the graph burning problem, we introduce novel genetic operators, chromosome representation, and evaluation method. In the proposed algorithm, the well-known betweenness centrality is used as the backbone of our chromosome initialization procedure. The proposed algorithm is implemented and compared with previous heuristics and approximation algorithms on 15 benchmark graphs of different sizes. Based on the results, it can be seen that the proposed algorithm achieves better performance in comparison to the previous state-of-the-art heuristics. The complete source code is available online and can be used to find optimal or near-optimal solutions for the graph burning problem.
InterTrack: Interaction Transformer for 3D Multi-Object Tracking
Aug 17, 2022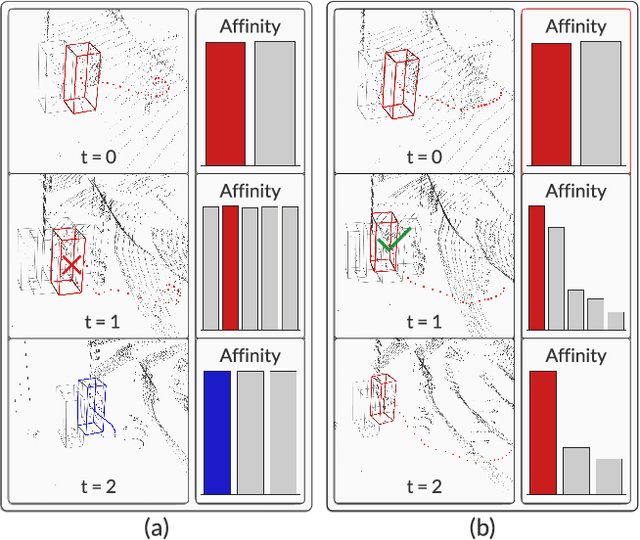
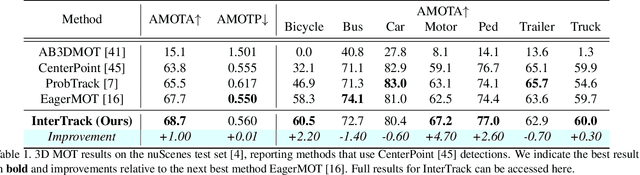
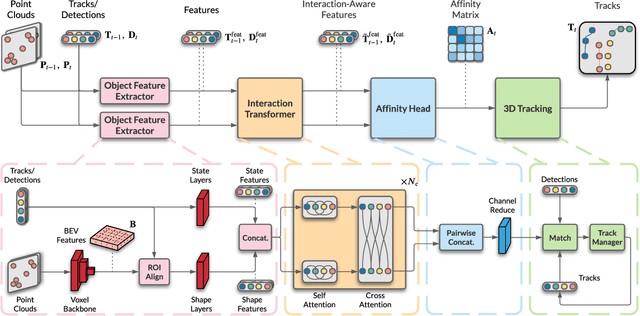
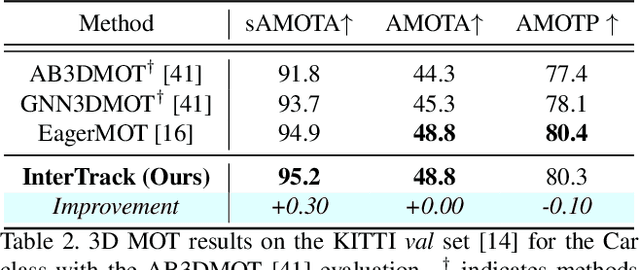
3D multi-object tracking (MOT) is a key problem for autonomous vehicles, required to perform well-informed motion planning in dynamic environments. Particularly for densely occupied scenes, associating existing tracks to new detections remains challenging as existing systems tend to omit critical contextual information. Our proposed solution, InterTrack, introduces the Interaction Transformer for 3D MOT to generate discriminative object representations for data association. We extract state and shape features for each track and detection, and efficiently aggregate global information via attention. We then perform a learned regression on each track/detection feature pair to estimate affinities, and use a robust two-stage data association and track management approach to produce the final tracks. We validate our approach on the nuScenes 3D MOT benchmark, where we observe significant improvements, particularly on classes with small physical sizes and clustered objects. As of submission, InterTrack ranks 1st in overall AMOTA among methods using CenterPoint detections.
Rapid, remote and low-cost finger vasculature mapping for heart rate monitoring
Aug 15, 2022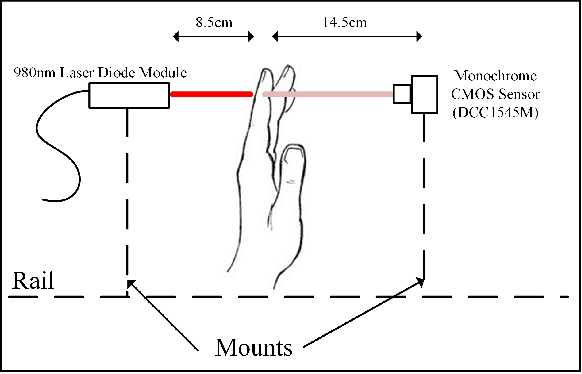

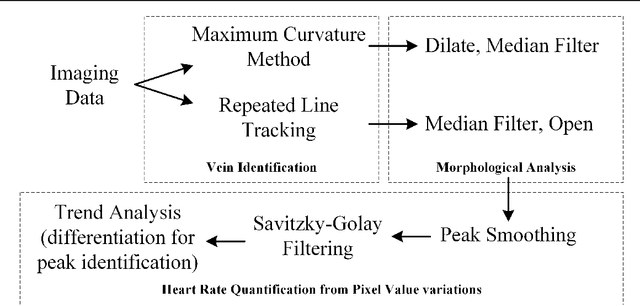

Today's diagnostics include devices such as pulse oximeters, blood pressure monitors, and temperature measurements. These devices provide vital information to medical personnel when making treatment decisions. Drawing inspiration from the fundamental utility of pulse oximeters, we present a methodology for a robust low-cost approach to imaging subsurface vasculature and monitoring heart rate. The approach uses off-the-shelf equipment, set up in free space without physical contact and exploits the nature of the interaction between light at near-infrared wavelengths with tissue. Image processing algorithms extract heart rate information from the snapshot and video sequence captured at a stand-off distance. The method can be applied in a room with ambient light and remains robust to scenarios comparable to medical situations. This research sets the platform for future diagnostic devices based on imaging systems and algorithms for non-contact point-of-care investigations.
A Validation Approach to Over-parameterized Matrix and Image Recovery
Sep 21, 2022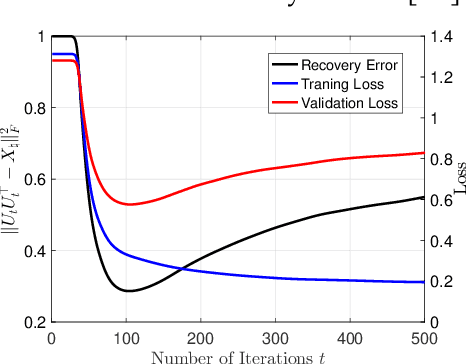
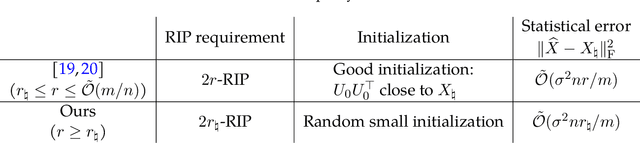
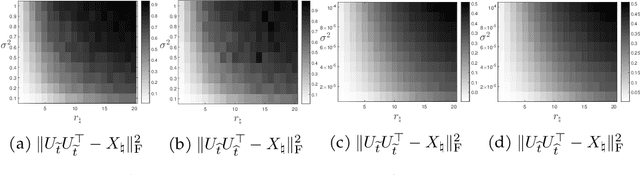
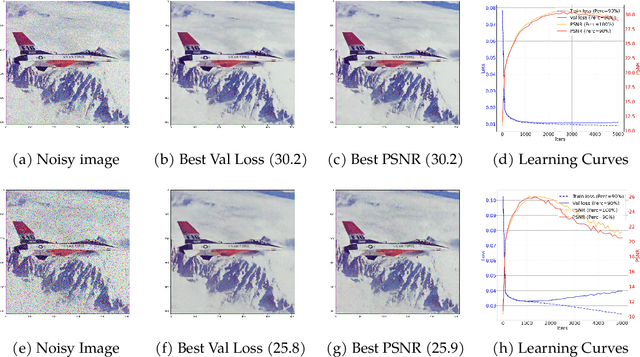
In this paper, we study the problem of recovering a low-rank matrix from a number of noisy random linear measurements. We consider the setting where the rank of the ground-truth matrix is unknown a prior and use an overspecified factored representation of the matrix variable, where the global optimal solutions overfit and do not correspond to the underlying ground-truth. We then solve the associated nonconvex problem using gradient descent with small random initialization. We show that as long as the measurement operators satisfy the restricted isometry property (RIP) with its rank parameter scaling with the rank of ground-truth matrix rather than scaling with the overspecified matrix variable, gradient descent iterations are on a particular trajectory towards the ground-truth matrix and achieve nearly information-theoretically optimal recovery when stop appropriately. We then propose an efficient early stopping strategy based on the common hold-out method and show that it detects nearly optimal estimator provably. Moreover, experiments show that the proposed validation approach can also be efficiently used for image restoration with deep image prior which over-parameterizes an image with a deep network.
Entropy Induced Pruning Framework for Convolutional Neural Networks
Aug 13, 2022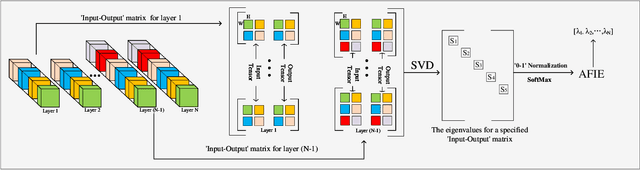
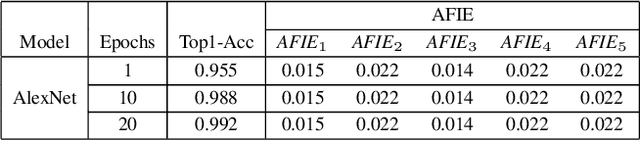
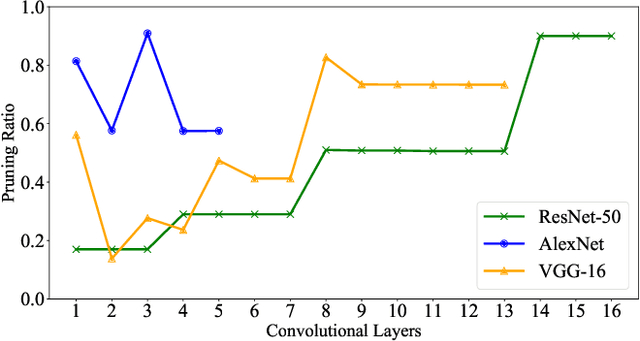

Structured pruning techniques have achieved great compression performance on convolutional neural networks for image classification task. However, the majority of existing methods are weight-oriented, and their pruning results may be unsatisfactory when the original model is trained poorly. That is, a fully-trained model is required to provide useful weight information. This may be time-consuming, and the pruning results are sensitive to the updating process of model parameters. In this paper, we propose a metric named Average Filter Information Entropy (AFIE) to measure the importance of each filter. It is calculated by three major steps, i.e., low-rank decomposition of the "input-output" matrix of each convolutional layer, normalization of the obtained eigenvalues, and calculation of filter importance based on information entropy. By leveraging the proposed AFIE, the proposed framework is able to yield a stable importance evaluation of each filter no matter whether the original model is trained fully. We implement our AFIE based on AlexNet, VGG-16, and ResNet-50, and test them on MNIST, CIFAR-10, and ImageNet, respectively. The experimental results are encouraging. We surprisingly observe that for our methods, even when the original model is only trained with one epoch, the importance evaluation of each filter keeps identical to the results when the model is fully-trained. This indicates that the proposed pruning strategy can perform effectively at the beginning stage of the training process for the original model.
Uncertainty Aware Multitask Pyramid Vision Transformer For UAV-Based Object Re-Identification
Sep 19, 2022
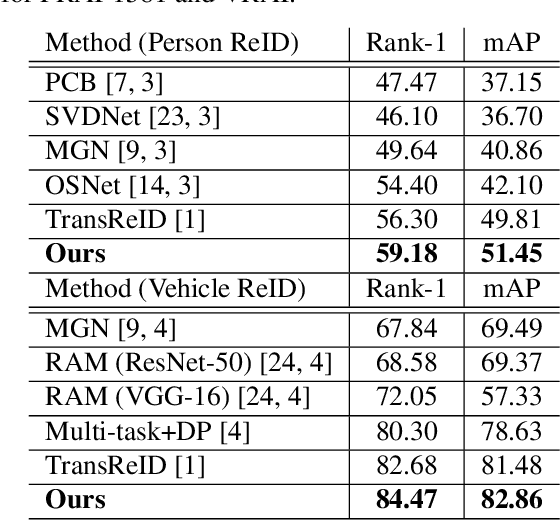
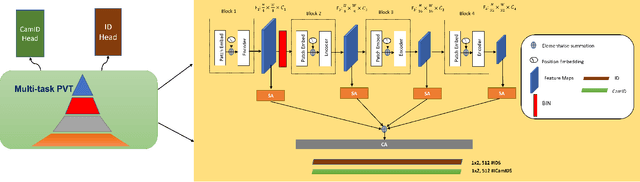
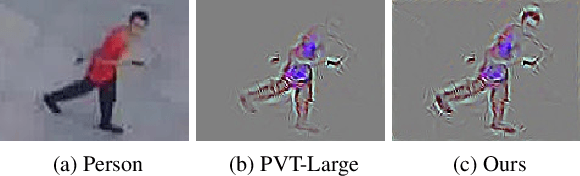
Object Re-IDentification (ReID), one of the most significant problems in biometrics and surveillance systems, has been extensively studied by image processing and computer vision communities in the past decades. Learning a robust and discriminative feature representation is a crucial challenge for object ReID. The problem is even more challenging in ReID based on Unmanned Aerial Vehicle (UAV) as the images are characterized by continuously varying camera parameters (e.g., view angle, altitude, etc.) of a flying drone. To address this challenge, multiscale feature representation has been considered to characterize images captured from UAV flying at different altitudes. In this work, we propose a multitask learning approach, which employs a new multiscale architecture without convolution, Pyramid Vision Transformer (PVT), as the backbone for UAV-based object ReID. By uncertainty modeling of intraclass variations, our proposed model can be jointly optimized using both uncertainty-aware object ID and camera ID information. Experimental results are reported on PRAI and VRAI, two ReID data sets from aerial surveillance, to verify the effectiveness of our proposed approach