 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Encoding protein dynamic information in graph representation for functional residue identification
Dec 15, 2021
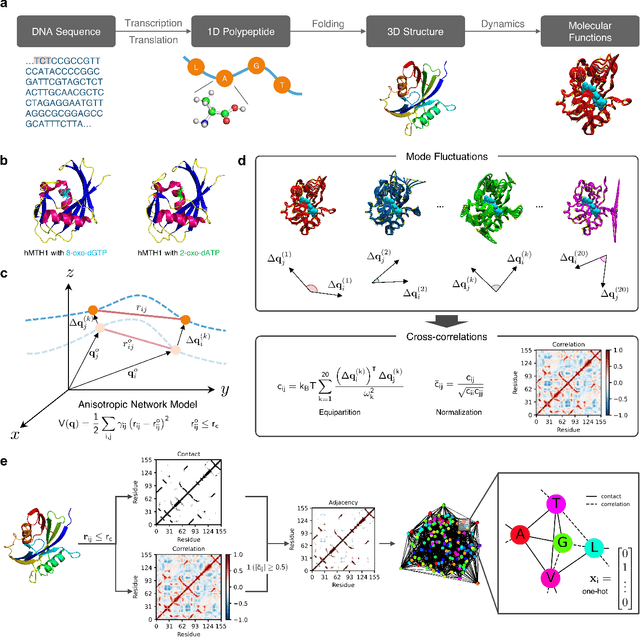

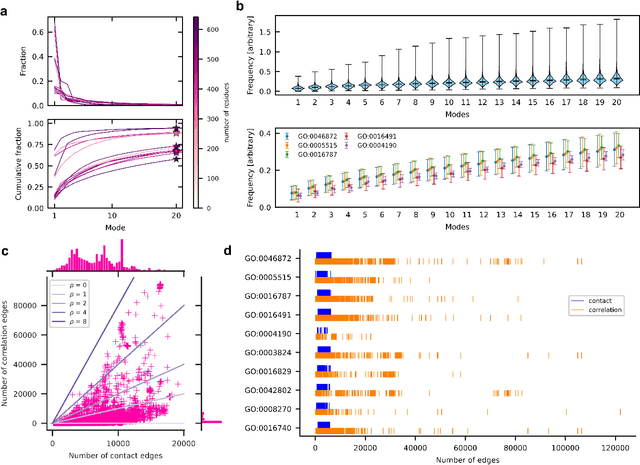
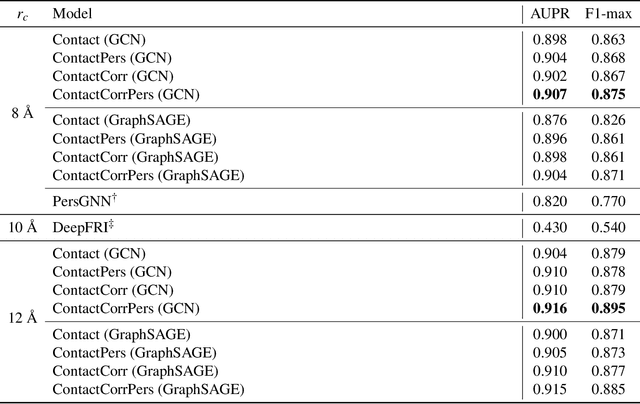
Recent advances in protein function prediction exploit graph-based deep learning approaches to correlate the structural and topological features of proteins with their molecular functions. However, proteins in vivo are not static but dynamic molecules that alter conformation for functional purposes. Here we apply normal mode analysis to native protein conformations and augment protein graphs by connecting edges between dynamically correlated residue pairs. In the multilabel function classification task, our method demonstrates a remarkable performance gain based on this dynamics-informed representation. The proposed graph neural network, ProDAR, increases the interpretability and generalizability of residue-level annotations and robustly reflects structural nuance in proteins. We elucidate the importance of dynamic information in graph representation by comparing class activation maps for the hMTH1, nitrophorin, and SARS-CoV-2 receptor binding domain. Our model successfully learns the dynamic fingerprints of proteins and provides molecular insights into protein functions, with vast untapped potential for broad biotechnology and pharmaceutical applications.
Learning Bias-Invariant Representation by Cross-Sample Mutual Information Minimization
Aug 13, 2021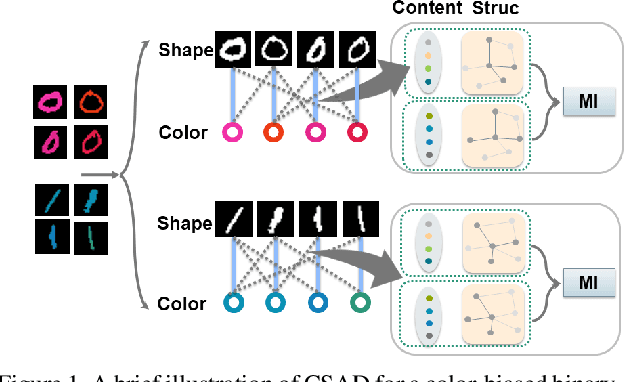
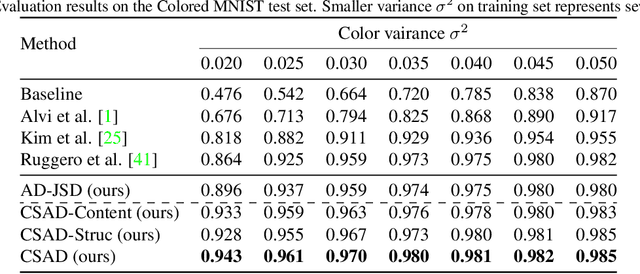
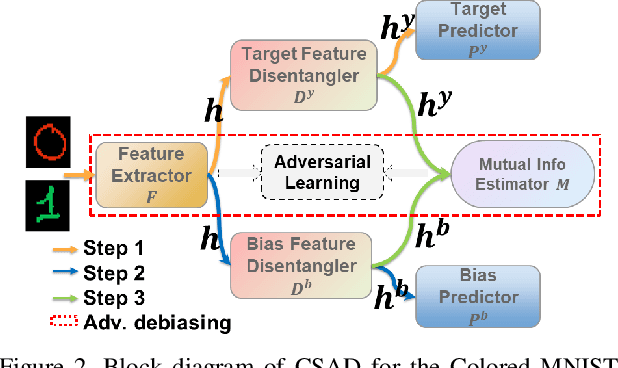
Deep learning algorithms mine knowledge from the training data and thus would likely inherit the dataset's bias information. As a result, the obtained model would generalize poorly and even mislead the decision process in real-life applications. We propose to remove the bias information misused by the target task with a cross-sample adversarial debiasing (CSAD) method. CSAD explicitly extracts target and bias features disentangled from the latent representation generated by a feature extractor and then learns to discover and remove the correlation between the target and bias features. The correlation measurement plays a critical role in adversarial debiasing and is conducted by a cross-sample neural mutual information estimator. Moreover, we propose joint content and local structural representation learning to boost mutual information estimation for better performance. We conduct thorough experiments on publicly available datasets to validate the advantages of the proposed method over state-of-the-art approaches.
Multi-dimension Geospatial feature learning for urban region function recognition
Jul 18, 2022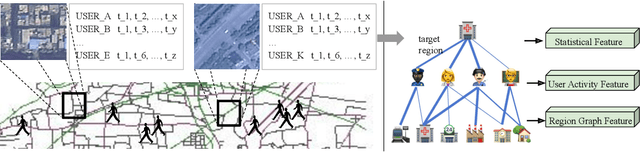
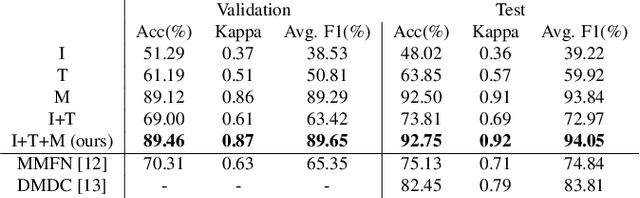
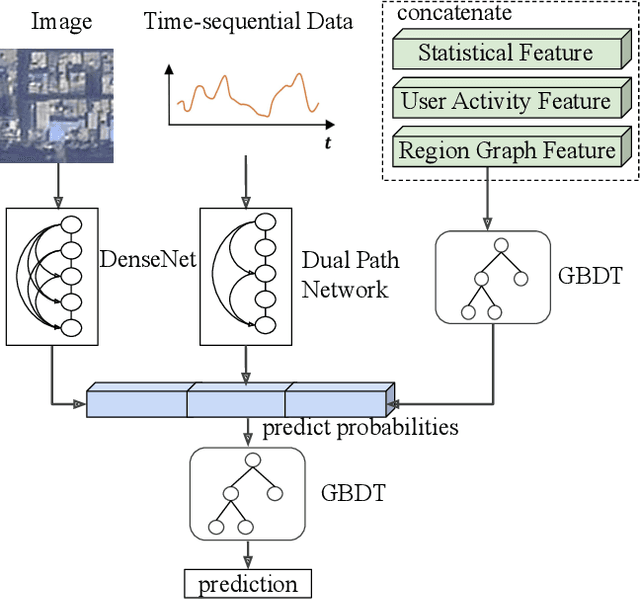

Urban region function recognition plays a vital character in monitoring and managing the limited urban areas. Since urban functions are complex and full of social-economic properties, simply using remote sensing~(RS) images equipped with physical and optical information cannot completely solve the classification task. On the other hand, with the development of mobile communication and the internet, the acquisition of geospatial big data~(GBD) becomes possible. In this paper, we propose a Multi-dimension Feature Learning Model~(MDFL) using high-dimensional GBD data in conjunction with RS images for urban region function recognition. When extracting multi-dimension features, our model considers the user-related information modeled by their activity, as well as the region-based information abstracted from the region graph. Furthermore, we propose a decision fusion network that integrates the decisions from several neural networks and machine learning classifiers, and the final decision is made considering both the visual cue from the RS images and the social information from the GBD data. Through quantitative evaluation, we demonstrate that our model achieves overall accuracy at 92.75, outperforming the state-of-the-art by 10 percent.
How Speech is Recognized to Be Emotional - A Study Based on Information Decomposition
Nov 24, 2021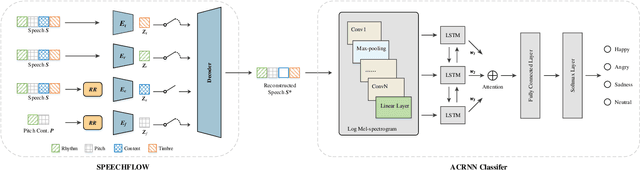
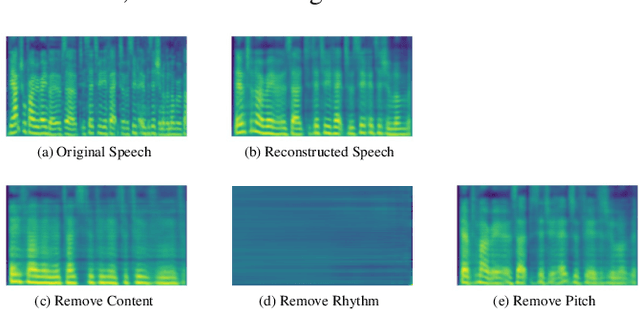
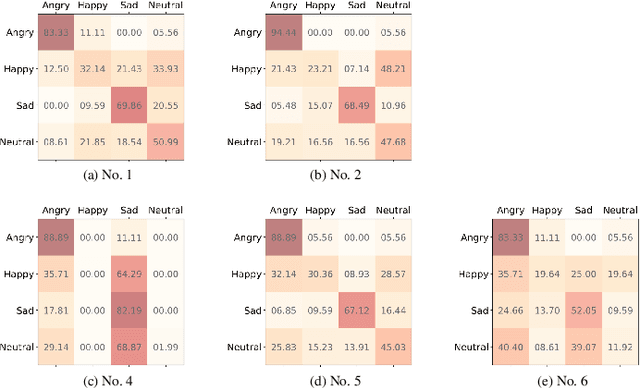
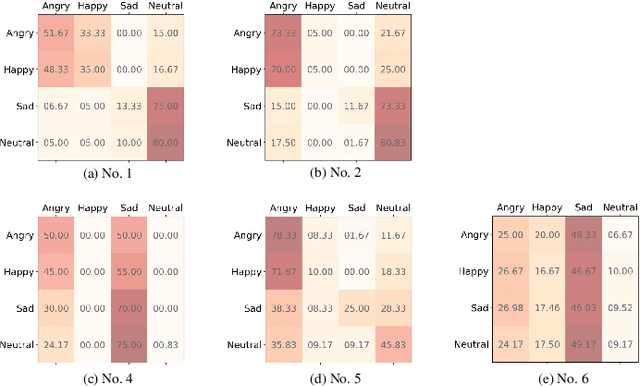
The way that humans encode their emotion into speech signals is complex. For instance, an angry man may increase his pitch and speaking rate, and use impolite words. In this paper, we present a preliminary study on various emotional factors and investigate how each of them impacts modern emotion recognition systems. The key tool of our study is the SpeechFlow model presented recently, by which we are able to decompose speech signals into separate information factors (content, pitch, rhythm). Based on this decomposition, we carefully studied the performance of each information component and their combinations. We conducted the study on three different speech emotion corpora and chose an attention-based convolutional RNN as the emotion classifier. Our results show that rhythm is the most important component for emotional expression. Moreover, the cross-corpus results are very bad (even worse than guess), demonstrating that the present speech emotion recognition model is rather weak. Interestingly, by removing one or several unimportant components, the cross-corpus results can be improved. This demonstrates the potential of the decomposition approach towards a generalizable emotion recognition.
Normalizing Flows for Interventional Density Estimation
Sep 13, 2022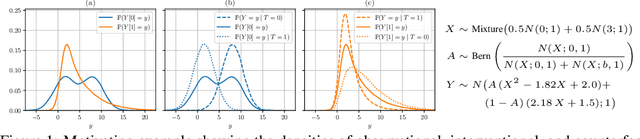
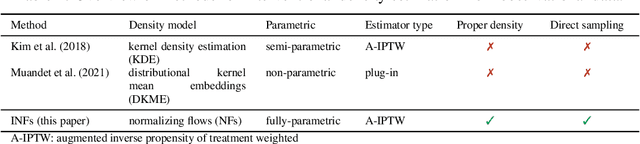
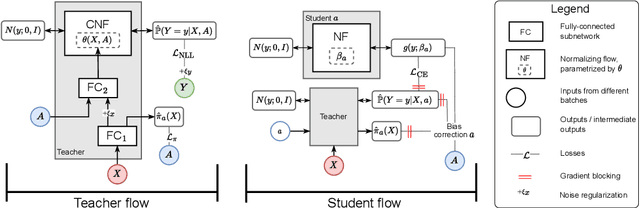

Existing machine learning methods for causal inference usually estimate quantities expressed via the mean of potential outcomes (e.g., average treatment effect). However, such quantities do not capture the full information about the distribution of potential outcomes. In this work, we estimate the density of potential outcomes after interventions from observational data. Specifically, we propose a novel, fully-parametric deep learning method for this purpose, called Interventional Normalizing Flows. Our Interventional Normalizing Flows offer a properly normalized density estimator. For this, we introduce an iterative training of two normalizing flows, namely (i) a teacher flow for estimation of nuisance parameters and (ii) a student flow for parametric estimation of the density of potential outcomes. For efficient and doubly-robust estimation of the student flow parameters, we develop a custom tractable optimization objective based on a one-step bias correction. Across various experiments, we demonstrate that our Interventional Normalizing Flows are expressive and highly effective, and scale well with both sample size and high-dimensional confounding. To the best of our knowledge, our Interventional Normalizing Flows are the first fully-parametric, deep learning method for density estimation of potential outcomes.
Microwave QR Code: An IRS-Based Solution
Aug 05, 2022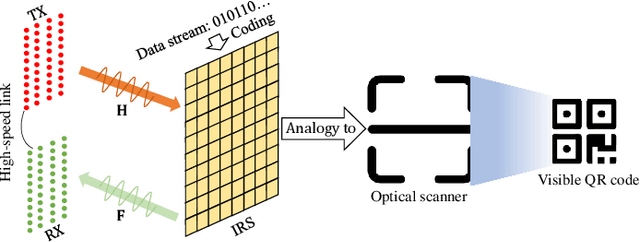
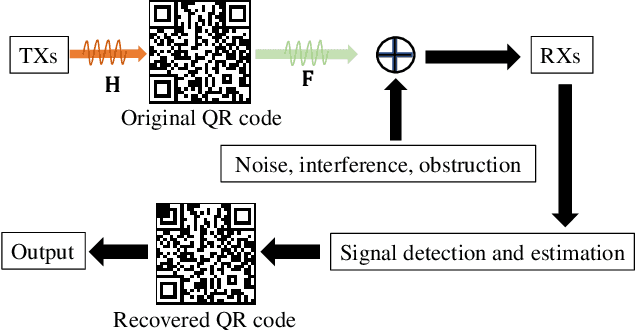
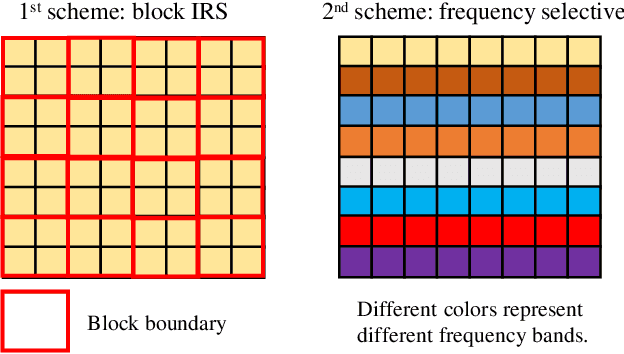
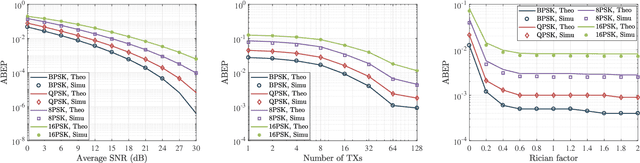
This letter proposes to employ intelligent reflecting surface (IRS) as an information media to display a microwave quick response (QR) code for Internet-of-Things applications. To be specific, an IRS is used to form a dynamic bitmap image thanks to its tunable elements. With a QR code shown on the IRS, the transmitting and receiving antenna arrays are jointly designed to scan it by radiating electromagnetic wave as well as receiving and detecting the reflected signal. Based on such an idea, an IRS enabled information and communication system is modelled. Accordingly, some fundamental systematic operating mechanisms are investigated, involving derivation of average bit error probability for signal modulation, QR code implementation on an IRS, transmission design, detection, etc. The simulations are performed to show the achievable communication performance of system and confirm the feasibility of IRS-based microwave QR code.
Quantifying the Online Long-Term Interest in Research
Sep 13, 2022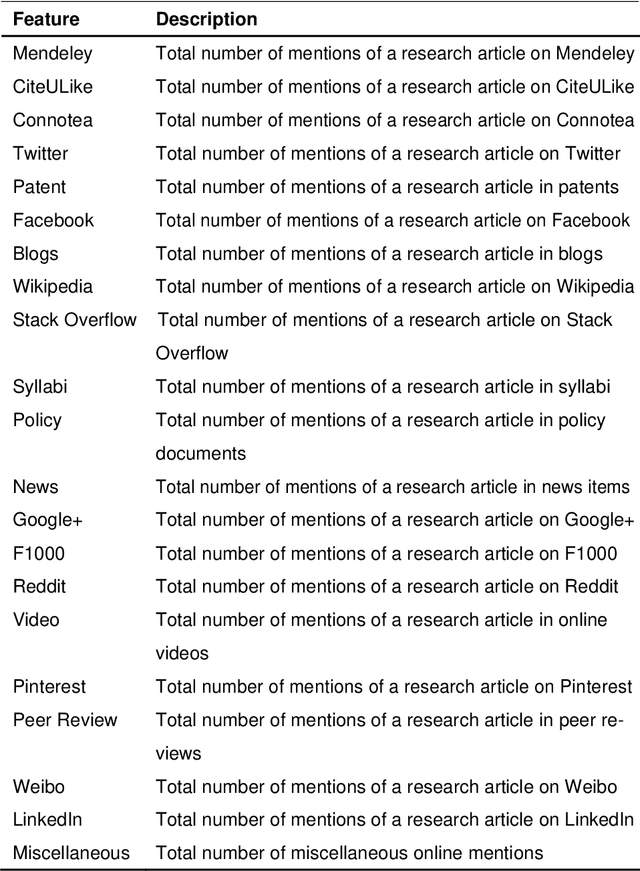
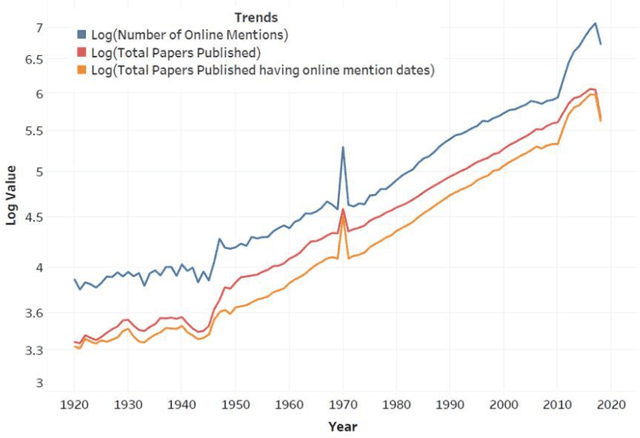
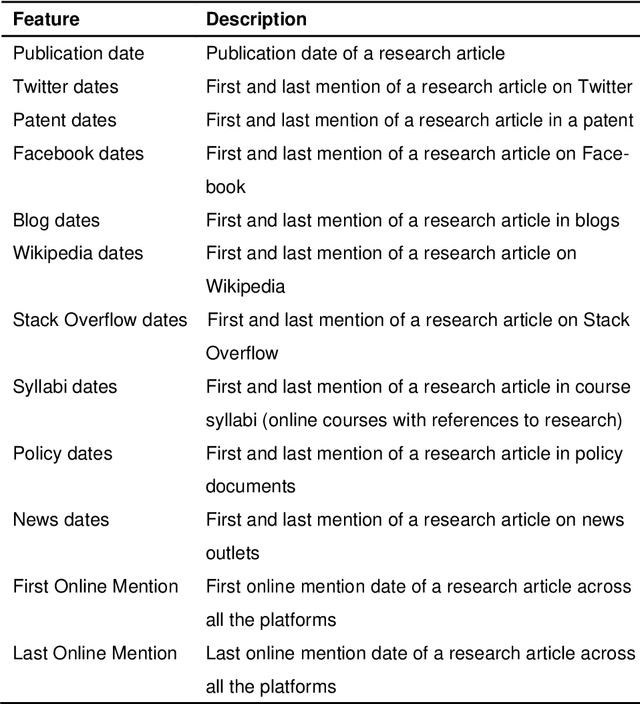
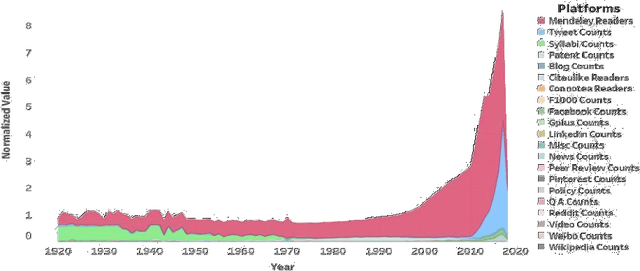
Research articles are being shared in increasing numbers on multiple online platforms. Although the scholarly impact of these articles has been widely studied, the online interest determined by how long the research articles are shared online remains unclear. Being cognizant of how long a research article is mentioned online could be valuable information to the researchers. In this paper, we analyzed multiple social media platforms on which users share and/or discuss scholarly articles. We built three clusters for papers, based on the number of yearly online mentions having publication dates ranging from the year 1920 to 2016. Using the online social media metrics for each of these three clusters, we built machine learning models to predict the long-term online interest in research articles. We addressed the prediction task with two different approaches: regression and classification. For the regression approach, the Multi-Layer Perceptron model performed best, and for the classification approach, the tree-based models performed better than other models. We found that old articles are most evident in the contexts of economics and industry (i.e., patents). In contrast, recently published articles are most evident in research platforms (i.e., Mendeley) followed by social media platforms (i.e., Twitter).
* Journal of Informetrics
Is Stochastic Gradient Descent Near Optimal?
Sep 18, 2022
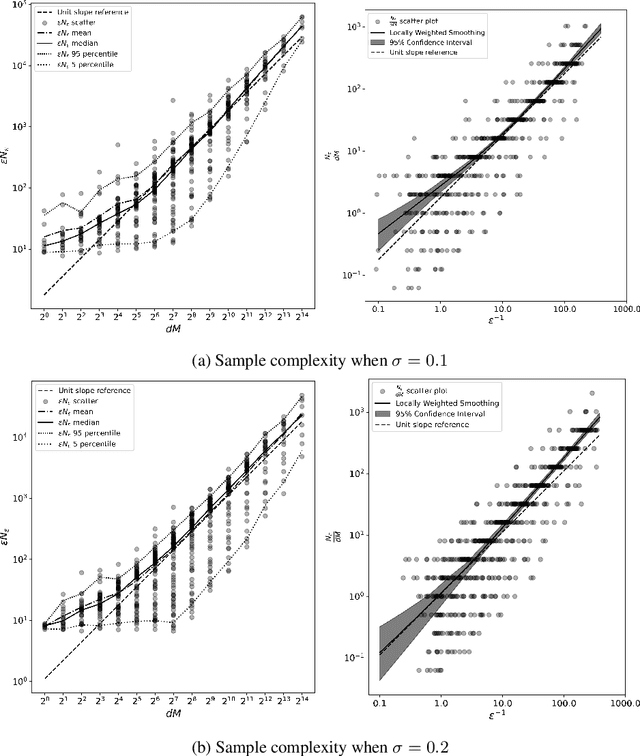

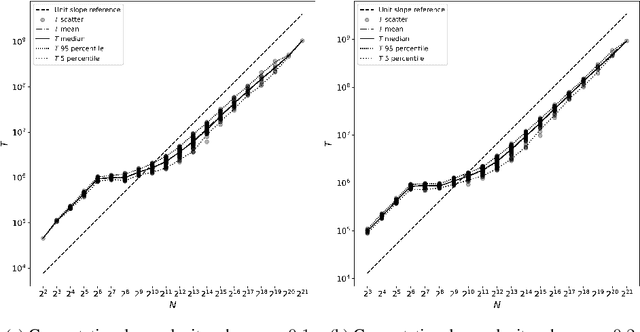
The success of neural networks over the past decade has established them as effective models for many relevant data generating processes. Statistical theory on neural networks indicates graceful scaling of sample complexity. For example, Joen & Van Roy (arXiv:2203.00246) demonstrate that, when data is generated by a ReLU teacher network with $W$ parameters, an optimal learner needs only $\tilde{O}(W/\epsilon)$ samples to attain expected error $\epsilon$. However, existing computational theory suggests that, even for single-hidden-layer teacher networks, to attain small error for all such teacher networks, the computation required to achieve this sample complexity is intractable. In this work, we fit single-hidden-layer neural networks to data generated by single-hidden-layer ReLU teacher networks with parameters drawn from a natural distribution. We demonstrate that stochastic gradient descent (SGD) with automated width selection attains small expected error with a number of samples and total number of queries both nearly linear in the input dimension and width. This suggests that SGD nearly achieves the information-theoretic sample complexity bounds of Joen & Van Roy (arXiv:2203.00246) in a computationally efficient manner. An important difference between our positive empirical results and the negative theoretical results is that the latter address worst-case error of deterministic algorithms, while our analysis centers on expected error of a stochastic algorithm.
What You See is What You Grasp: User-Friendly Grasping Guided by Near-eye-tracking
Sep 13, 2022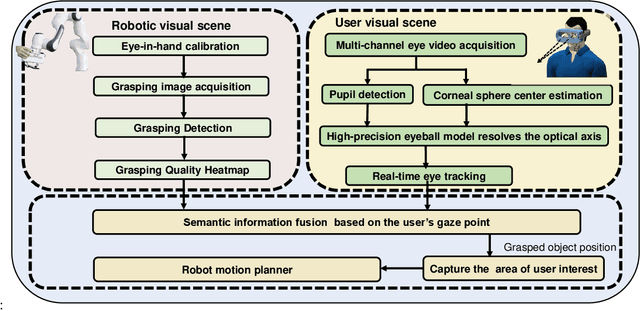

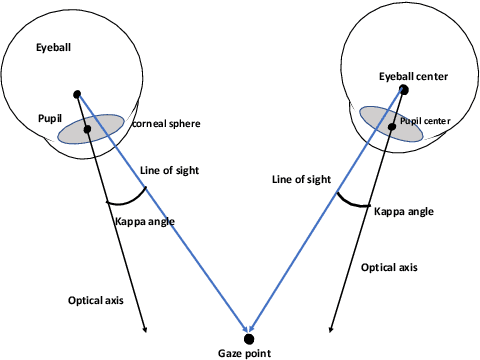
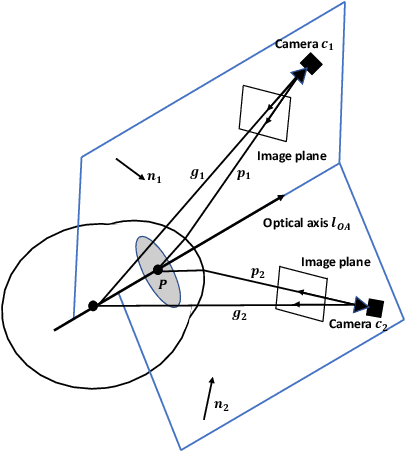
This work presents a next-generation human-robot interface that can infer and realize the user's manipulation intention via sight only. Specifically, we develop a system that integrates near-eye-tracking and robotic manipulation to enable user-specified actions (e.g., grasp, pick-and-place, etc), where visual information is merged with human attention to create a mapping for desired robot actions. To enable sight guided manipulation, a head-mounted near-eye-tracking device is developed to track the eyeball movements in real-time, so that the user's visual attention can be identified. To improve the grasping performance, a transformer based grasp model is then developed. Stacked transformer blocks are used to extract hierarchical features where the volumes of channels are expanded at each stage while squeezing the resolution of feature maps. Experimental validation demonstrates that the eye-tracking system yields low gaze estimation error and the grasping system yields promising results on multiple grasping datasets. This work is a proof of concept for gaze interaction-based assistive robot, which holds great promise to help the elder or upper limb disabilities in their daily lives. A demo video is available at \url{https://www.youtube.com/watch?v=yuZ1hukYUrM}.
A simplified convergence theory for Byzantine resilient stochastic gradient descent
Aug 25, 2022In distributed learning, a central server trains a model according to updates provided by nodes holding local data samples. In the presence of one or more malicious servers sending incorrect information (a Byzantine adversary), standard algorithms for model training such as stochastic gradient descent (SGD) fail to converge. In this paper, we present a simplified convergence theory for the generic Byzantine Resilient SGD method originally proposed by Blanchard et al. [NeurIPS 2017]. Compared to the existing analysis, we shown convergence to a stationary point in expectation under standard assumptions on the (possibly nonconvex) objective function and flexible assumptions on the stochastic gradients.