 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Unsupervised Hashing with Semantic Concept Mining
Sep 23, 2022
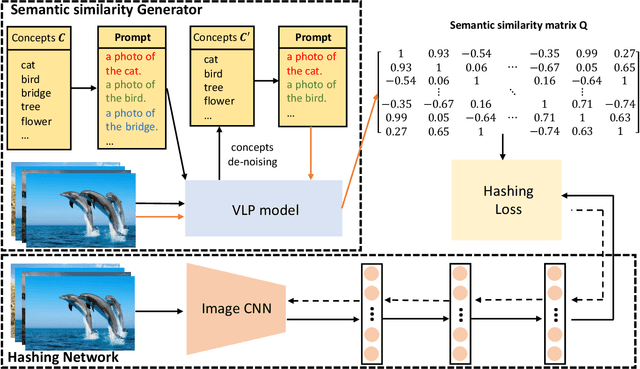
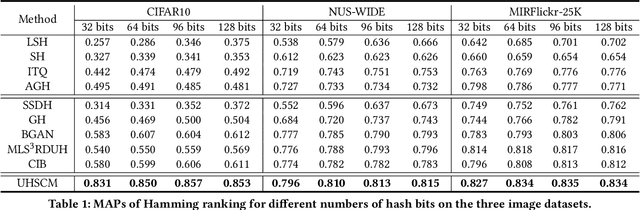
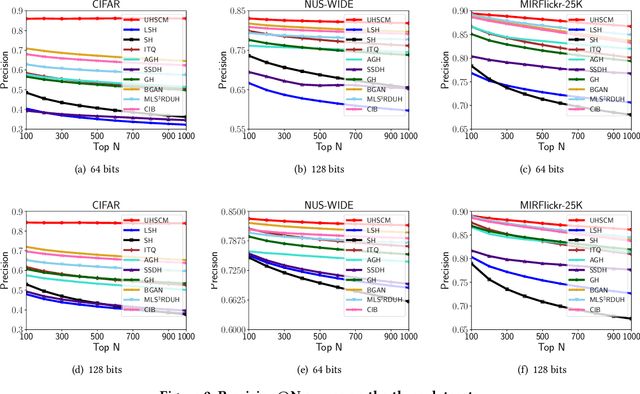
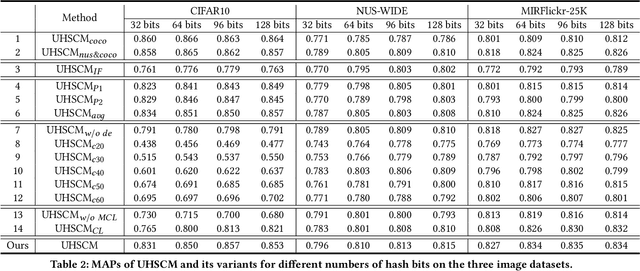
Recently, to improve the unsupervised image retrieval performance, plenty of unsupervised hashing methods have been proposed by designing a semantic similarity matrix, which is based on the similarities between image features extracted by a pre-trained CNN model. However, most of these methods tend to ignore high-level abstract semantic concepts contained in images. Intuitively, concepts play an important role in calculating the similarity among images. In real-world scenarios, each image is associated with some concepts, and the similarity between two images will be larger if they share more identical concepts. Inspired by the above intuition, in this work, we propose a novel Unsupervised Hashing with Semantic Concept Mining, called UHSCM, which leverages a VLP model to construct a high-quality similarity matrix. Specifically, a set of randomly chosen concepts is first collected. Then, by employing a vision-language pretraining (VLP) model with the prompt engineering which has shown strong power in visual representation learning, the set of concepts is denoised according to the training images. Next, the proposed method UHSCM applies the VLP model with prompting again to mine the concept distribution of each image and construct a high-quality semantic similarity matrix based on the mined concept distributions. Finally, with the semantic similarity matrix as guiding information, a novel hashing loss with a modified contrastive loss based regularization item is proposed to optimize the hashing network. Extensive experiments on three benchmark datasets show that the proposed method outperforms the state-of-the-art baselines in the image retrieval task.
Z-Index at CheckThat! Lab 2022: Check-Worthiness Identification on Tweet Text
Jul 15, 2022
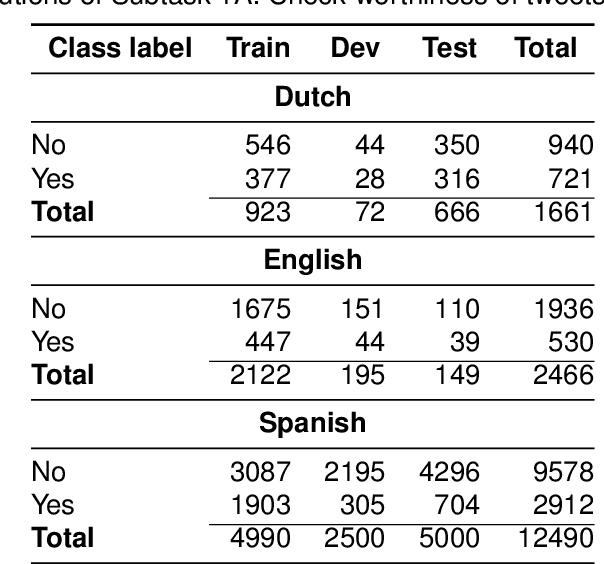
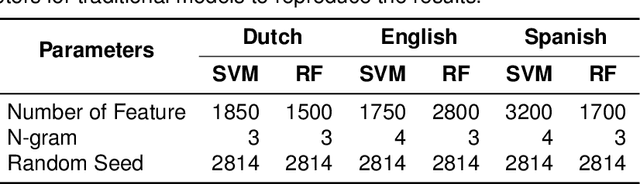

The wide use of social media and digital technologies facilitates sharing various news and information about events and activities. Despite sharing positive information misleading and false information is also spreading on social media. There have been efforts in identifying such misleading information both manually by human experts and automatic tools. Manual effort does not scale well due to the high volume of information, containing factual claims, are appearing online. Therefore, automatically identifying check-worthy claims can be very useful for human experts. In this study, we describe our participation in Subtask-1A: Check-worthiness of tweets (English, Dutch and Spanish) of CheckThat! lab at CLEF 2022. We performed standard preprocessing steps and applied different models to identify whether a given text is worthy of fact checking or not. We use the oversampling technique to balance the dataset and applied SVM and Random Forest (RF) with TF-IDF representations. We also used BERT multilingual (BERT-m) and XLM-RoBERTa-base pre-trained models for the experiments. We used BERT-m for the official submissions and our systems ranked as 3rd, 5th, and 12th in Spanish, Dutch, and English, respectively. In further experiments, our evaluation shows that transformer models (BERT-m and XLM-RoBERTa-base) outperform the SVM and RF in Dutch and English languages where a different scenario is observed for Spanish.
Representative Image Feature Extraction via Contrastive Learning Pretraining for Chest X-ray Report Generation
Sep 04, 2022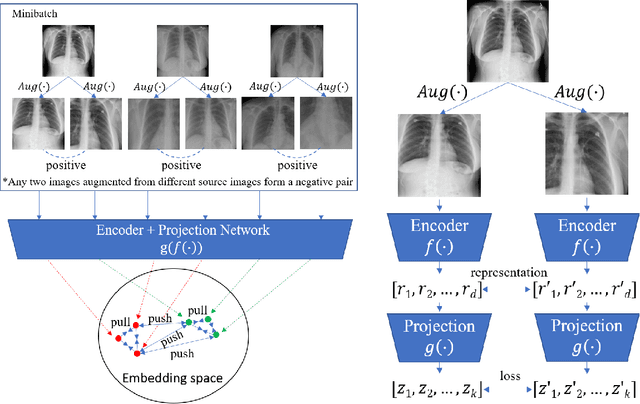
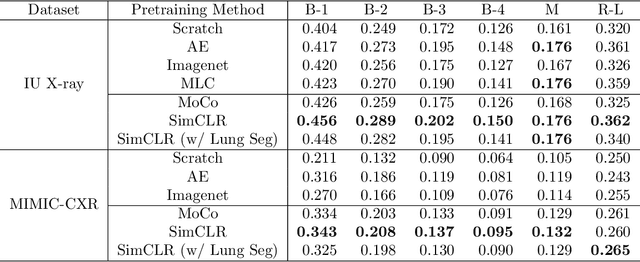

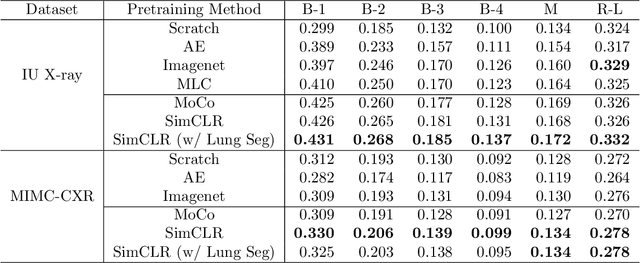
Medical report generation is a challenging task since it is time-consuming and requires expertise from experienced radiologists. The goal of medical report generation is to accurately capture and describe the image findings. Previous works pretrain their visual encoding neural networks with large datasets in different domains, which cannot learn general visual representation in the specific medical domain. In this work, we propose a medical report generation framework that uses a contrastive learning approach to pretrain the visual encoder and requires no additional meta information. In addition, we adopt lung segmentation as an augmentation method in the contrastive learning framework. This segmentation guides the network to focus on encoding the visual feature within the lung region. Experimental results show that the proposed framework improves the performance and the quality of the generated medical reports both quantitatively and qualitatively.
Performance Analysis for Reconfigurable Intelligent Surface Assisted MIMO Systems
Aug 25, 2022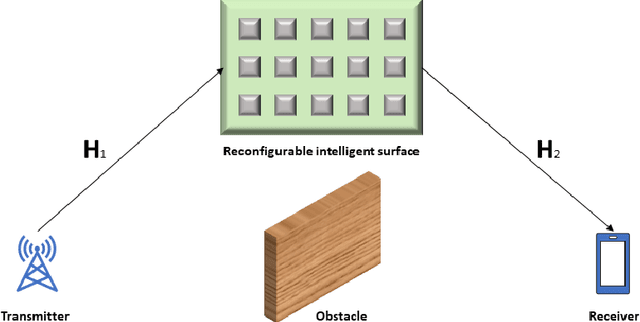
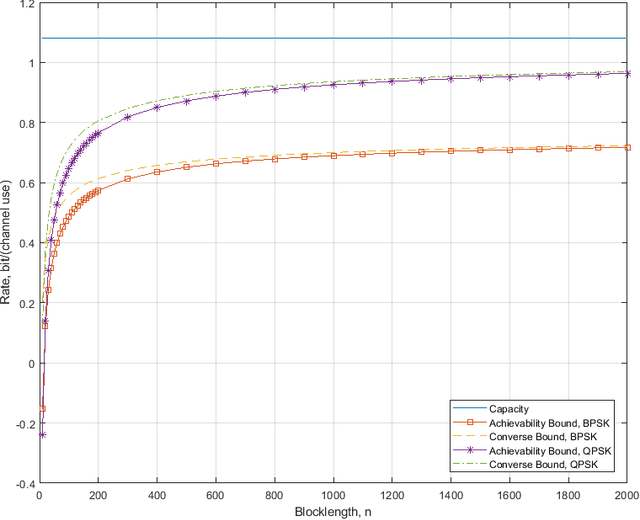
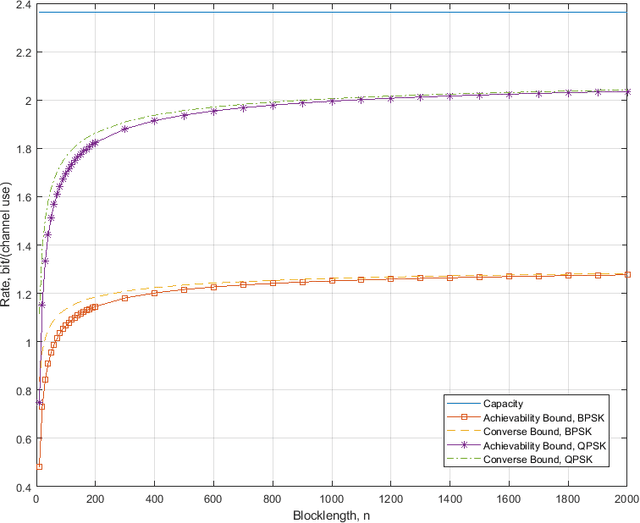
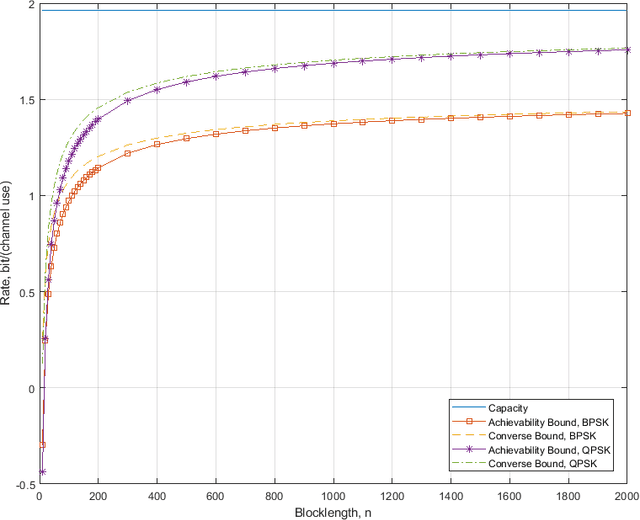
This paper investigates the maximal achievable rate for a given average error probability and blocklength for the reconfigurable intelligent surface (RIS) assisted multiple-input and multiple-output (MIMO) system. The result consists of a finite blocklength channel coding achievability bound and a converse bound based on the Berry-Esseen theorem, the Mellin transform and the mutual information. Numerical evaluation shows fast speed of convergence to the maximal achievable rate as the blocklength increases and also proves that the channel variance is a sound measurement of the backoff from the maximal achievable rate due to finite blocklength.
Second-order Approximation of Minimum Discrimination Information in Independent Component Analysis
Nov 30, 2021
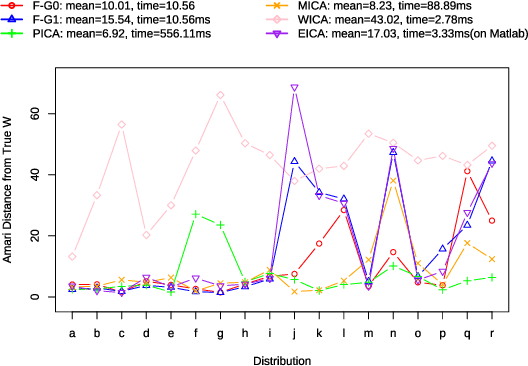

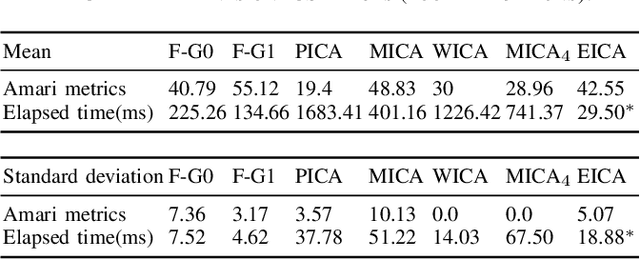
Independent Component Analysis (ICA) is intended to recover the mutually independent sources from their linear mixtures, and F astICA is one of the most successful ICA algorithms. Although it seems reasonable to improve the performance of F astICA by introducing more nonlinear functions to the negentropy estimation, the original fixed-point method (approximate Newton method) in F astICA degenerates under this circumstance. To alleviate this problem, we propose a novel method based on the second-order approximation of minimum discrimination information (MDI). The joint maximization in our method is consisted of minimizing single weighted least squares and seeking unmixing matrix by the fixed-point method. Experimental results validate its efficiency compared with other popular ICA algorithms.
Extracting Medication Changes in Clinical Narratives using Pre-trained Language Models
Aug 17, 2022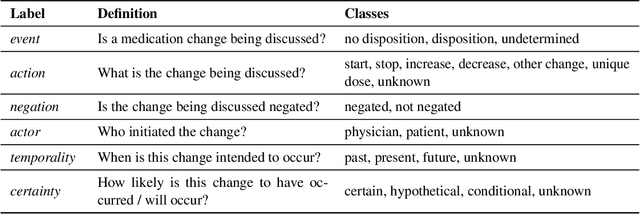
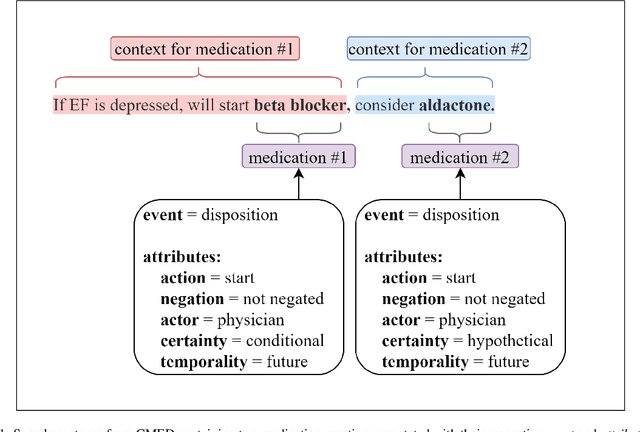
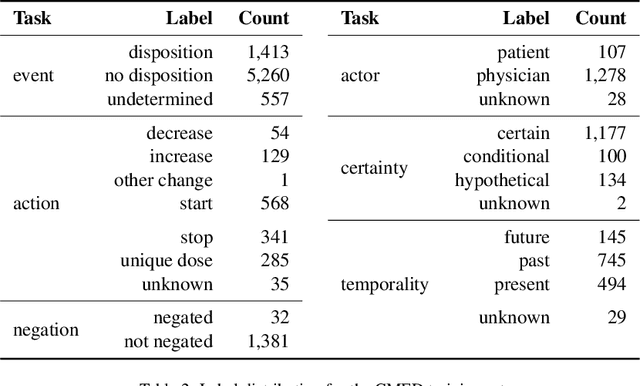
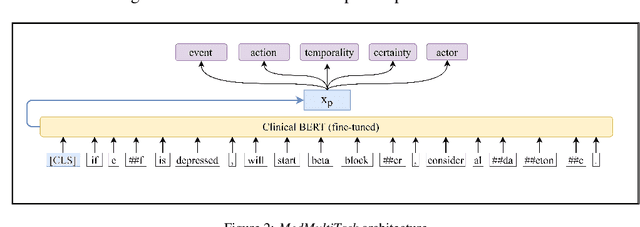
An accurate and detailed account of patient medications, including medication changes within the patient timeline, is essential for healthcare providers to provide appropriate patient care. Healthcare providers or the patients themselves may initiate changes to patient medication. Medication changes take many forms, including prescribed medication and associated dosage modification. These changes provide information about the overall health of the patient and the rationale that led to the current care. Future care can then build on the resulting state of the patient. This work explores the automatic extraction of medication change information from free-text clinical notes. The Contextual Medication Event Dataset (CMED) is a corpus of clinical notes with annotations that characterize medication changes through multiple change-related attributes, including the type of change (start, stop, increase, etc.), initiator of the change, temporality, change likelihood, and negation. Using CMED, we identify medication mentions in clinical text and propose three novel high-performing BERT-based systems that resolve the annotated medication change characteristics. We demonstrate that our proposed architectures improve medication change classification performance over the initial work exploring CMED. We identify medication mentions with high performance at 0.959 F1, and our proposed systems classify medication changes and their attributes at an overall average of 0.827 F1.
Summarizing Patients Problems from Hospital Progress Notes Using Pre-trained Sequence-to-Sequence Models
Aug 17, 2022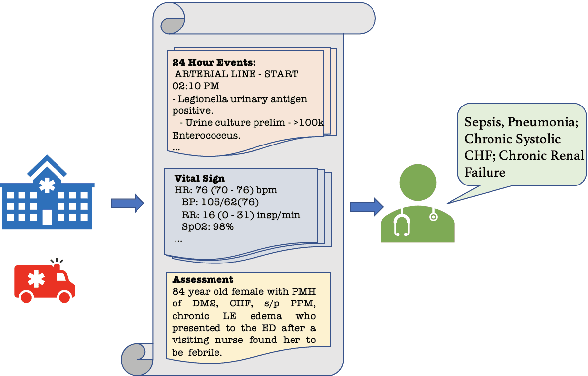

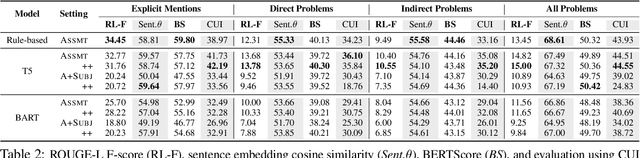

Automatically summarizing patients' main problems from daily progress notes using natural language processing methods helps to battle against information and cognitive overload in hospital settings and potentially assists providers with computerized diagnostic decision support. Problem list summarization requires a model to understand, abstract, and generate clinical documentation. In this work, we propose a new NLP task that aims to generate a list of problems in a patient's daily care plan using input from the provider's progress notes during hospitalization. We investigate the performance of T5 and BART, two state-of-the-art seq2seq transformer architectures, in solving this problem. We provide a corpus built on top of progress notes from publicly available electronic health record progress notes in the Medical Information Mart for Intensive Care (MIMIC)-III. T5 and BART are trained on general domain text, and we experiment with a data augmentation method and a domain adaptation pre-training method to increase exposure to medical vocabulary and knowledge. Evaluation methods include ROUGE, BERTScore, cosine similarity on sentence embedding, and F-score on medical concepts. Results show that T5 with domain adaptive pre-training achieves significant performance gains compared to a rule-based system and general domain pre-trained language models, indicating a promising direction for tackling the problem summarization task.
Normalizing Flows for Interventional Density Estimation
Sep 13, 2022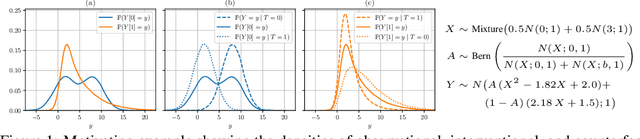
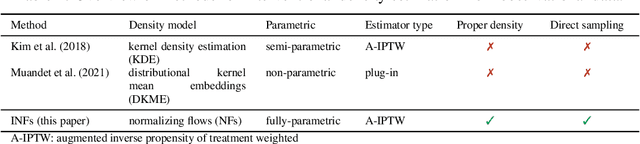
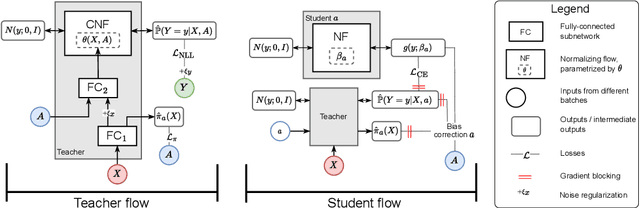

Existing machine learning methods for causal inference usually estimate quantities expressed via the mean of potential outcomes (e.g., average treatment effect). However, such quantities do not capture the full information about the distribution of potential outcomes. In this work, we estimate the density of potential outcomes after interventions from observational data. Specifically, we propose a novel, fully-parametric deep learning method for this purpose, called Interventional Normalizing Flows. Our Interventional Normalizing Flows offer a properly normalized density estimator. For this, we introduce an iterative training of two normalizing flows, namely (i) a teacher flow for estimation of nuisance parameters and (ii) a student flow for parametric estimation of the density of potential outcomes. For efficient and doubly-robust estimation of the student flow parameters, we develop a custom tractable optimization objective based on a one-step bias correction. Across various experiments, we demonstrate that our Interventional Normalizing Flows are expressive and highly effective, and scale well with both sample size and high-dimensional confounding. To the best of our knowledge, our Interventional Normalizing Flows are the first fully-parametric, deep learning method for density estimation of potential outcomes.
Quantifying the Online Long-Term Interest in Research
Sep 13, 2022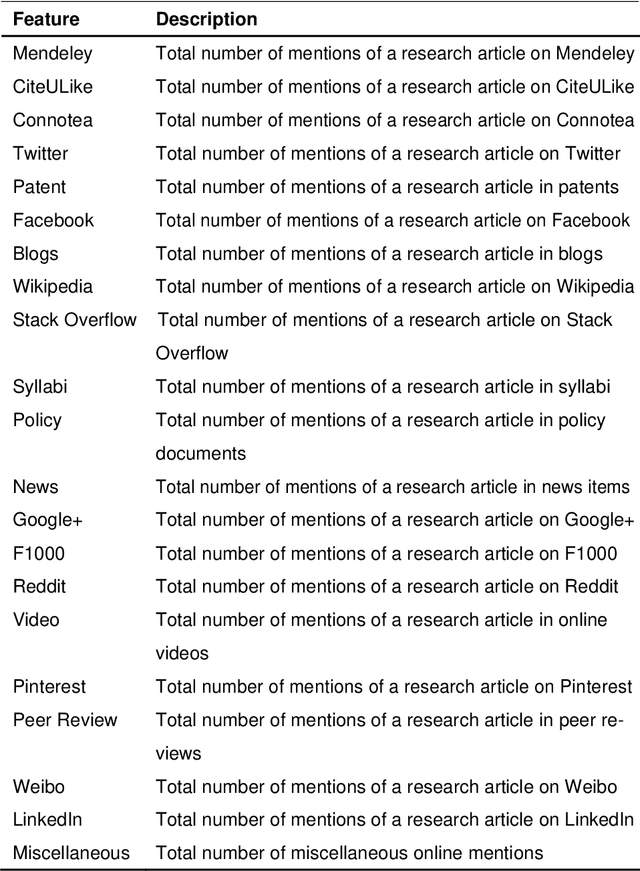
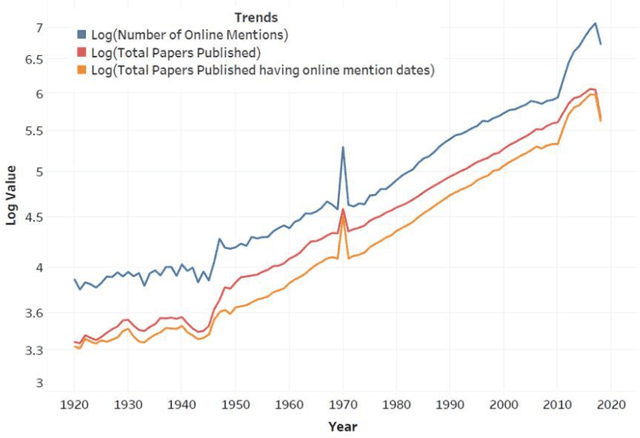
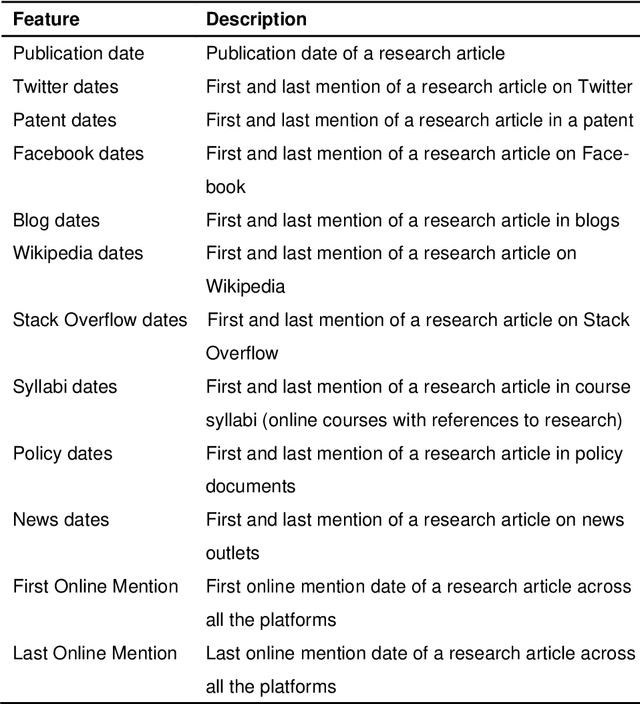
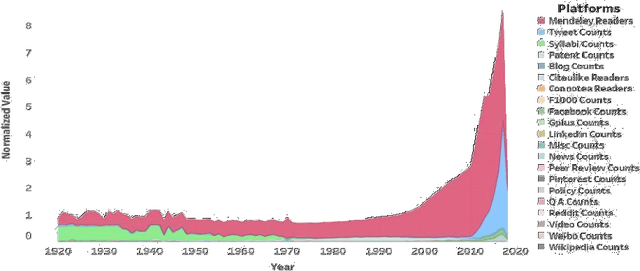
Research articles are being shared in increasing numbers on multiple online platforms. Although the scholarly impact of these articles has been widely studied, the online interest determined by how long the research articles are shared online remains unclear. Being cognizant of how long a research article is mentioned online could be valuable information to the researchers. In this paper, we analyzed multiple social media platforms on which users share and/or discuss scholarly articles. We built three clusters for papers, based on the number of yearly online mentions having publication dates ranging from the year 1920 to 2016. Using the online social media metrics for each of these three clusters, we built machine learning models to predict the long-term online interest in research articles. We addressed the prediction task with two different approaches: regression and classification. For the regression approach, the Multi-Layer Perceptron model performed best, and for the classification approach, the tree-based models performed better than other models. We found that old articles are most evident in the contexts of economics and industry (i.e., patents). In contrast, recently published articles are most evident in research platforms (i.e., Mendeley) followed by social media platforms (i.e., Twitter).
* Journal of Informetrics
Is Stochastic Gradient Descent Near Optimal?
Sep 18, 2022
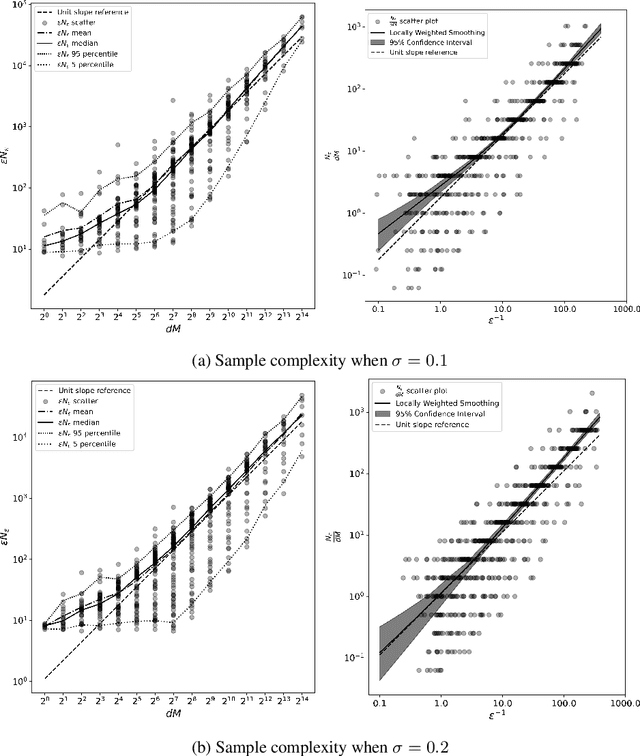

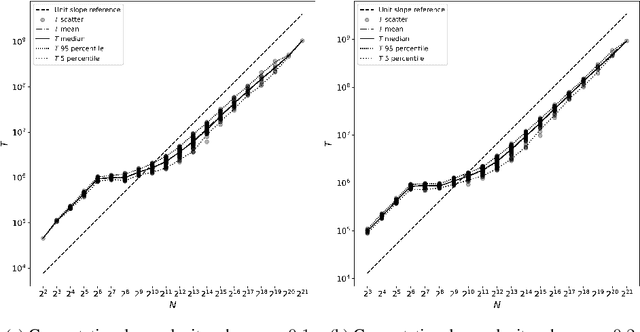
The success of neural networks over the past decade has established them as effective models for many relevant data generating processes. Statistical theory on neural networks indicates graceful scaling of sample complexity. For example, Joen & Van Roy (arXiv:2203.00246) demonstrate that, when data is generated by a ReLU teacher network with $W$ parameters, an optimal learner needs only $\tilde{O}(W/\epsilon)$ samples to attain expected error $\epsilon$. However, existing computational theory suggests that, even for single-hidden-layer teacher networks, to attain small error for all such teacher networks, the computation required to achieve this sample complexity is intractable. In this work, we fit single-hidden-layer neural networks to data generated by single-hidden-layer ReLU teacher networks with parameters drawn from a natural distribution. We demonstrate that stochastic gradient descent (SGD) with automated width selection attains small expected error with a number of samples and total number of queries both nearly linear in the input dimension and width. This suggests that SGD nearly achieves the information-theoretic sample complexity bounds of Joen & Van Roy (arXiv:2203.00246) in a computationally efficient manner. An important difference between our positive empirical results and the negative theoretical results is that the latter address worst-case error of deterministic algorithms, while our analysis centers on expected error of a stochastic algorithm.