 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A model-agnostic approach for generating Saliency Maps to explain inferred decisions of Deep Learning Models
Sep 27, 2022
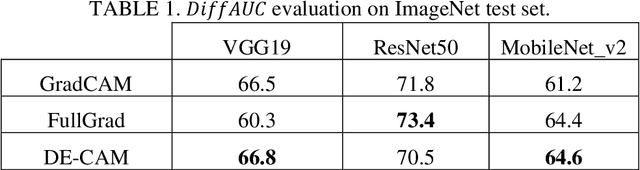

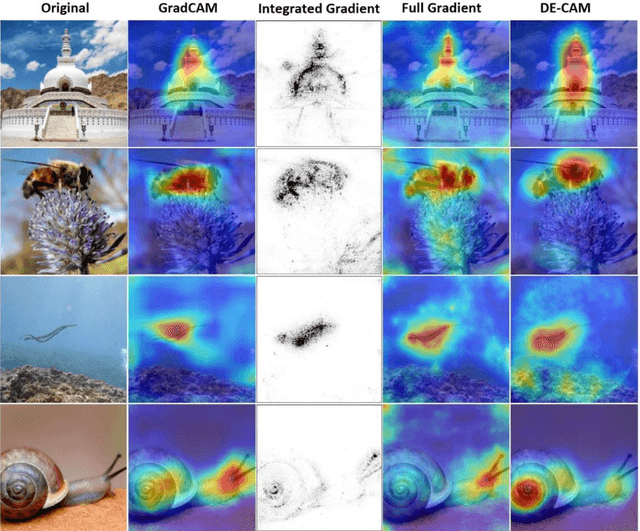
The widespread use of black-box AI models has raised the need for algorithms and methods that explain the decisions made by these models. In recent years, the AI research community is increasingly interested in models' explainability since black-box models take over more and more complicated and challenging tasks. Explainability becomes critical considering the dominance of deep learning techniques for a wide range of applications, including but not limited to computer vision. In the direction of understanding the inference process of deep learning models, many methods that provide human comprehensible evidence for the decisions of AI models have been developed, with the vast majority relying their operation on having access to the internal architecture and parameters of these models (e.g., the weights of neural networks). We propose a model-agnostic method for generating saliency maps that has access only to the output of the model and does not require additional information such as gradients. We use Differential Evolution (DE) to identify which image pixels are the most influential in a model's decision-making process and produce class activation maps (CAMs) whose quality is comparable to the quality of CAMs created with model-specific algorithms. DE-CAM achieves good performance without requiring access to the internal details of the model's architecture at the cost of more computational complexity.
Fusion of Inverse Synthetic Aperture Radar and Camera Images for Automotive Target Tracking
Sep 27, 2022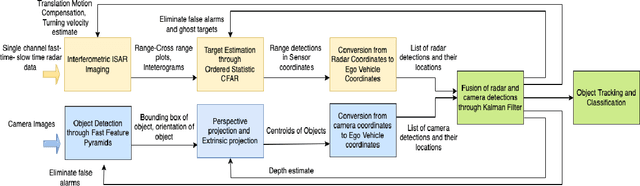
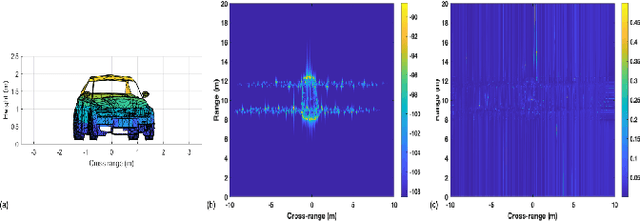

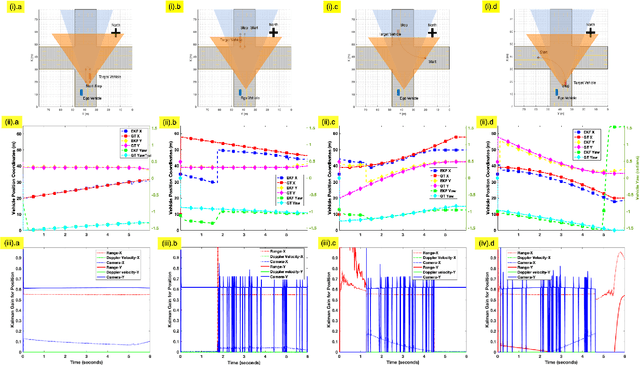
Automotive targets undergoing turns in road junctions offer large synthetic apertures over short dwell times to automotive radars that can be exploited for obtaining fine cross-range resolution. Likewise, the wide bandwidths of the automotive radar signal yield high-range resolution profiles. Together, they are exploited for generating inverse synthetic aperture radar (ISAR) images that offer rich information regarding the target vehicle's size, shape, and trajectory which is useful for object recognition and classification. However, a key requirement for ISAR is translation motion compensation and estimation of the turning velocity of the target. State-of-the-art algorithms for motion compensation trade-off between computational complexity and accuracy. An alternative low complexity method is to use an additional sensor for tracking the target motion. In this work, we propose to exploit computer vision algorithms to identify the radar target object in the sensor field-of-view (FoV) with high accuracy. Further, we propose to track the target vehicle's motion through fusion of vision and radar data. Vision data facilitates the accurate estimation of the lateral position of the target which complements the radar capability of accurate estimation of range and radial velocity. Through simulations and experimental evaluations with a monocular camera and Texas Instrument millimeter wave radar we demonstrate the effectiveness of sensor fusion for accurate target tracking for translational motion compensation and the generation of high-quality ISAR images.
Persistent Homology Guided Monte-Carlo Tree Search for Effective Non-Prehensile Manipulation
Oct 04, 2022
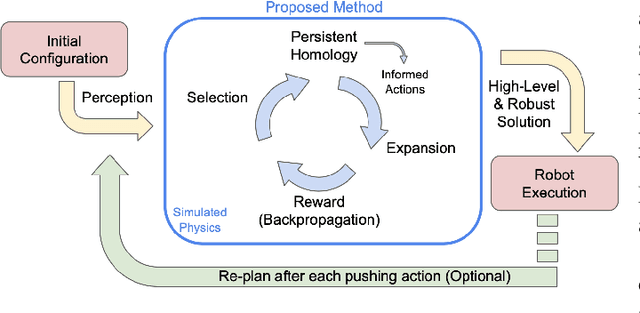
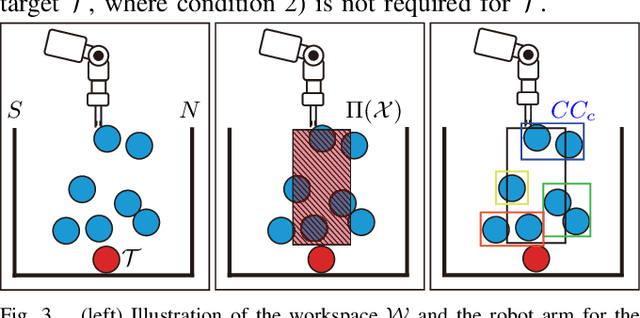

Performing object retrieval tasks in messy real-world workspaces involves the challenges of \emph{uncertainty} and \emph{clutter}. One option is to solve retrieval problems via a sequence of prehensile pick-n-place operations, which can be computationally expensive to compute in highly-cluttered scenarios and also inefficient to execute. The proposed framework selects the option of performing non-prehensile actions, such as pushing, to clean a cluttered workspace to allow a robotic arm to retrieve a target object. Non-prehensile actions, allow to interact simultaneously with multiple objects, which can speed up execution. At the same time, they can significantly increase uncertainty as it is not easy to accurately estimate the outcome of a pushing operation in clutter. The proposed framework integrates topological tools and Monte-Carlo tree search to achieve effective and robust pushing for object retrieval problems. In particular, it proposes using persistent homology to automatically identify manageable clustering of blocking objects in the workspace without the need for manually adjusting hyper-parameters. Furthermore, MCTS uses this information to explore feasible actions to push groups of objects together, aiming to minimize the number of pushing actions needed to clear the path to the target object. Real-world experiments using a Baxter robot, which involves some noise in actuation, show that the proposed framework achieves a higher success rate in solving retrieval tasks in dense clutter compared to state-of-the-art alternatives. Moreover, it produces high-quality solutions with a small number of pushing actions improving the overall execution time. More critically, it is robust enough that it allows to plan the sequence of actions offline and then execute them reliably online with Baxter.
A Generative Shape Compositional Framework: Towards Representative Populations of Virtual Heart Chimaeras
Oct 04, 2022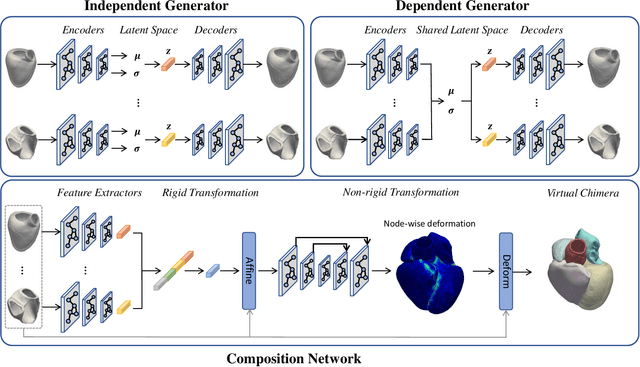
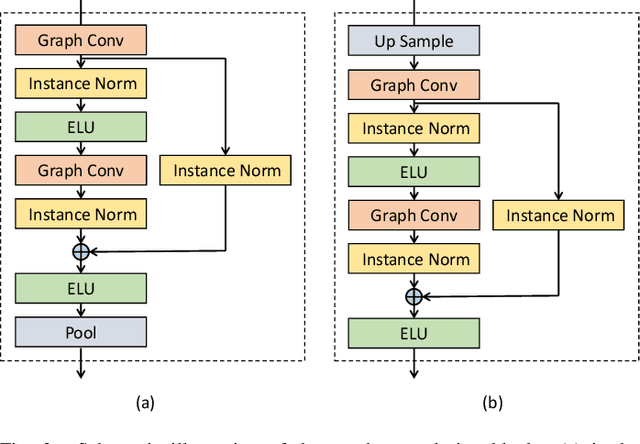
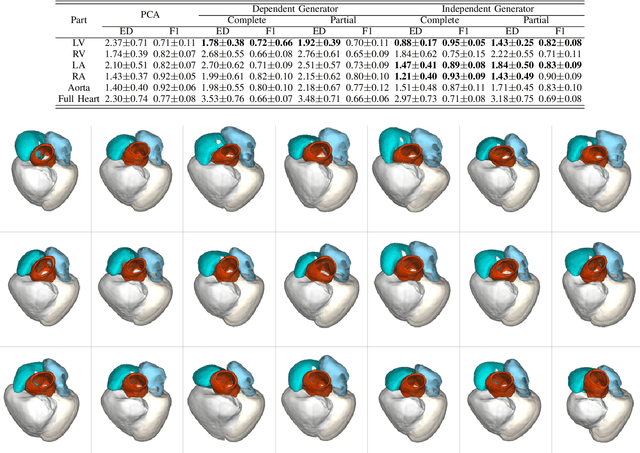
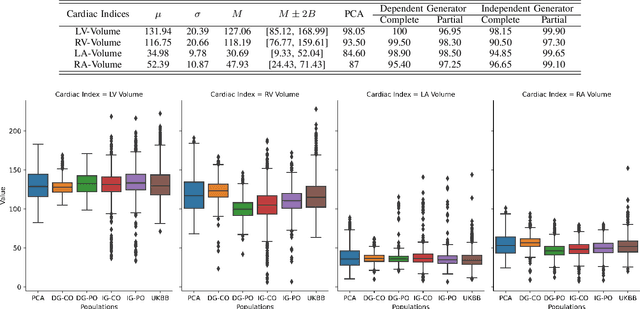
Generating virtual populations of anatomy that capture sufficient variability while remaining plausible is essential for conducting in-silico trials of medical devices. However, not all anatomical shapes of interest are always available for each individual in a population. Hence, missing/partially-overlapping anatomical information is often available across individuals in a population. We introduce a generative shape model for complex anatomical structures, learnable from datasets of unpaired datasets. The proposed generative model can synthesise complete whole complex shape assemblies coined virtual chimaeras, as opposed to natural human chimaeras. We applied this framework to build virtual chimaeras from databases of whole-heart shape assemblies that each contribute samples for heart substructures. Specifically, we propose a generative shape compositional framework which comprises two components - a part-aware generative shape model which captures the variability in shape observed for each structure of interest in the training population; and a spatial composition network which assembles/composes the structures synthesised by the former into multi-part shape assemblies (viz. virtual chimaeras). We also propose a novel self supervised learning scheme that enables the spatial composition network to be trained with partially overlapping data and weak labels. We trained and validated our approach using shapes of cardiac structures derived from cardiac magnetic resonance images available in the UK Biobank. Our approach significantly outperforms a PCA-based shape model (trained with complete data) in terms of generalisability and specificity. This demonstrates the superiority of the proposed approach as the synthesised cardiac virtual populations are more plausible and capture a greater degree of variability in shape than those generated by the PCA-based shape model.
Causes of Catastrophic Forgetting in Class-Incremental Semantic Segmentation
Sep 16, 2022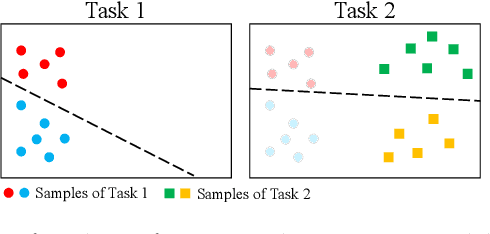
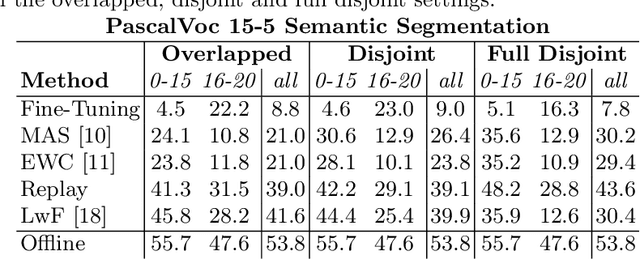
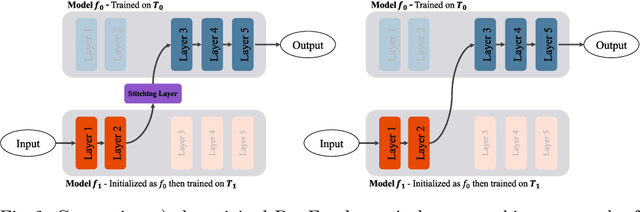
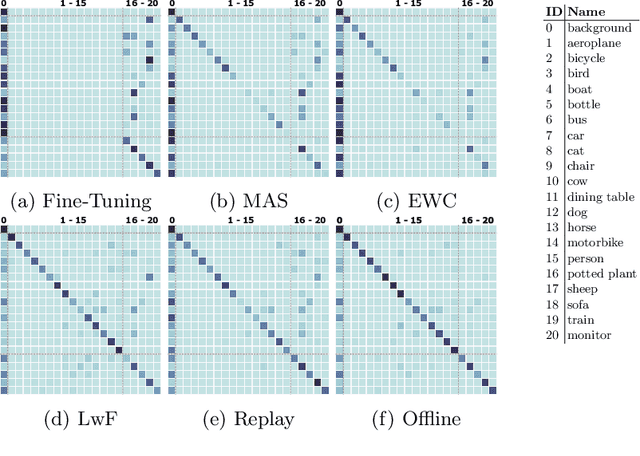
Class-incremental learning for semantic segmentation (CiSS) is presently a highly researched field which aims at updating a semantic segmentation model by sequentially learning new semantic classes. A major challenge in CiSS is overcoming the effects of catastrophic forgetting, which describes the sudden drop of accuracy on previously learned classes after the model is trained on a new set of classes. Despite latest advances in mitigating catastrophic forgetting, the underlying causes of forgetting specifically in CiSS are not well understood. Therefore, in a set of experiments and representational analyses, we demonstrate that the semantic shift of the background class and a bias towards new classes are the major causes of forgetting in CiSS. Furthermore, we show that both causes mostly manifest themselves in deeper classification layers of the network, while the early layers of the model are not affected. Finally, we demonstrate how both causes are effectively mitigated utilizing the information contained in the background, with the help of knowledge distillation and an unbiased cross-entropy loss.
3D-PL: Domain Adaptive Depth Estimation with 3D-aware Pseudo-Labeling
Sep 19, 2022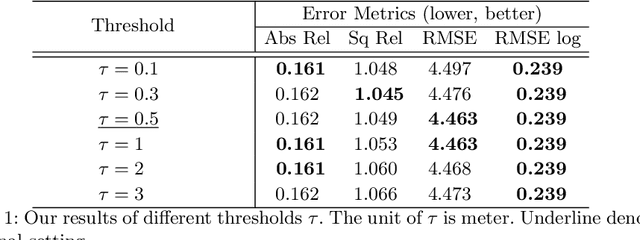

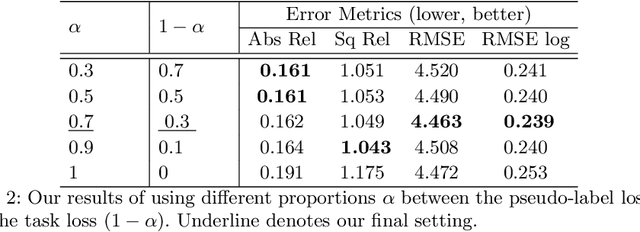

For monocular depth estimation, acquiring ground truths for real data is not easy, and thus domain adaptation methods are commonly adopted using the supervised synthetic data. However, this may still incur a large domain gap due to the lack of supervision from the real data. In this paper, we develop a domain adaptation framework via generating reliable pseudo ground truths of depth from real data to provide direct supervisions. Specifically, we propose two mechanisms for pseudo-labeling: 1) 2D-based pseudo-labels via measuring the consistency of depth predictions when images are with the same content but different styles; 2) 3D-aware pseudo-labels via a point cloud completion network that learns to complete the depth values in the 3D space, thus providing more structural information in a scene to refine and generate more reliable pseudo-labels. In experiments, we show that our pseudo-labeling methods improve depth estimation in various settings, including the usage of stereo pairs during training. Furthermore, the proposed method performs favorably against several state-of-the-art unsupervised domain adaptation approaches in real-world datasets.
Active Inference for Autonomous Decision-Making with Contextual Multi-Armed Bandits
Sep 19, 2022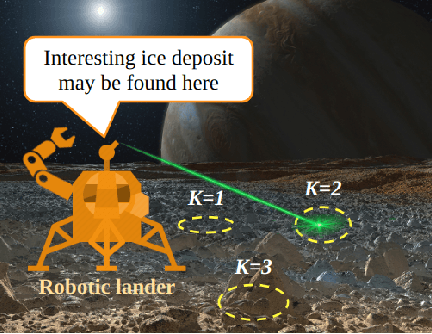
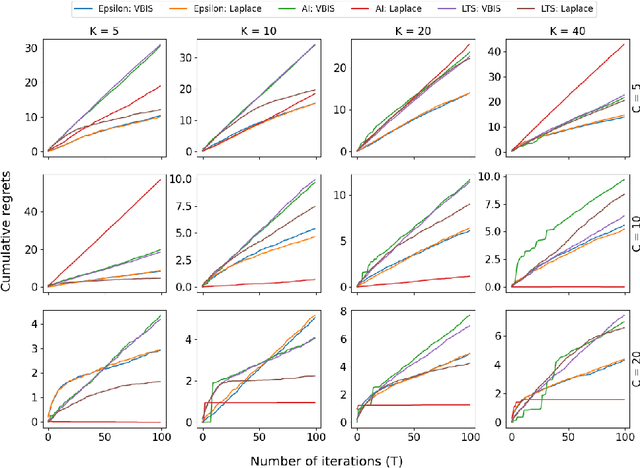
In autonomous robotic decision-making under uncertainty, the tradeoff between exploitation and exploration of available options must be considered. If secondary information associated with options can be utilized, such decision-making problems can often be formulated as a contextual multi-armed bandits (CMABs). In this study, we apply active inference, which has been actively studied in the field of neuroscience in recent years, as an alternative action selection strategy for CMABs. Unlike conventional action selection strategies, it is possible to rigorously evaluate the uncertainty of each option when calculating the expected free energy (EFE) associated with the decision agent's probabilistic model, as derived from the free-energy principle. We specifically address the case where a categorical observation likelihood function is used, such that EFE values are analytically intractable. We introduce new approximation methods for computing the EFE based on variational and Laplace approximations. Extensive simulation study results demonstrate that, compared to other strategies, active inference generally requires far fewer iterations to identify optimal options and generally achieves superior cumulative regret, for relatively low extra computational cost.
Efficient LiDAR Point Cloud Geometry Compression Through Neighborhood Point Attention
Aug 26, 2022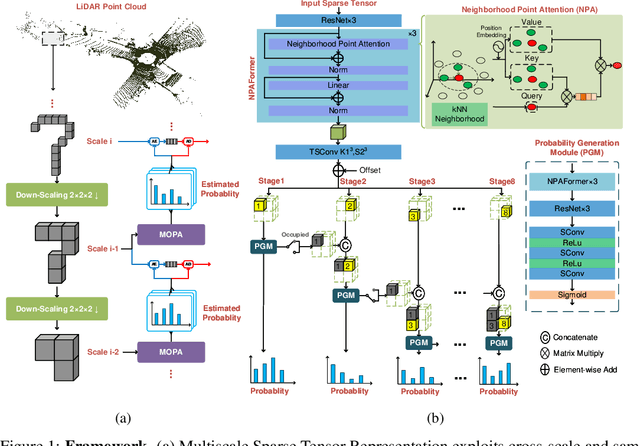
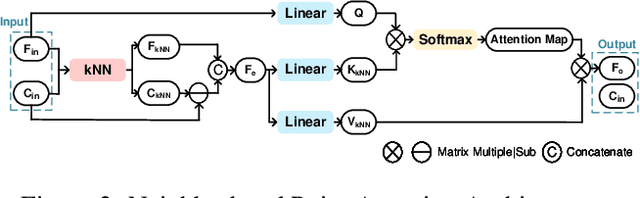
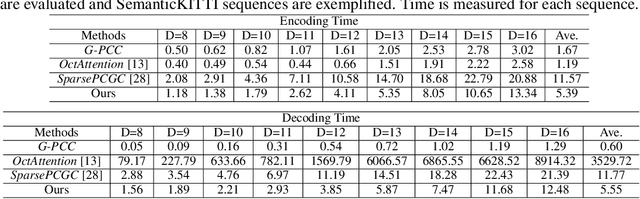
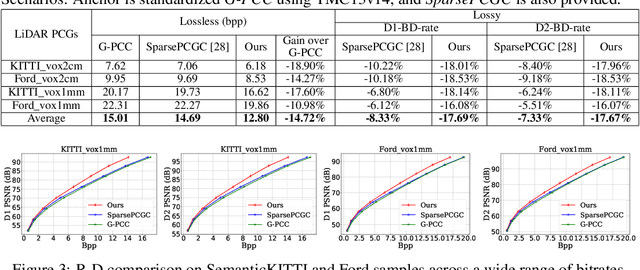
Although convolutional representation of multiscale sparse tensor demonstrated its superior efficiency to accurately model the occupancy probability for the compression of geometry component of dense object point clouds, its capacity for representing sparse LiDAR point cloud geometry (PCG) was largely limited. This is because 1) fixed receptive field of the convolution cannot characterize extremely and unevenly distributed sparse LiDAR points very well; and 2) pretrained convolutions with fixed weights are insufficient to dynamically capture information conditioned on the input. This work therefore suggests the neighborhood point attention (NPA) to tackle them, where we first use k nearest neighbors (kNN) to construct adaptive local neighborhood; and then leverage the self-attention mechanism to dynamically aggregate information within this neighborhood. Such NPA is devised as a NPAFormer to best exploit cross-scale and same-scale correlations for geometric occupancy probability estimation. Compared with the anchor using standardized G-PCC, our method provides >17% BD-rate gains for lossy compression, and >14% bitrate reduction for lossless scenario using popular LiDAR point clouds in SemanticKITTI and Ford datasets. Compared with the state-of-the-art (SOTA) solution using attention optimized octree coding method, our approach requires much less decoding runtime with about 640 times speedup on average, while still presenting better compression efficiency.
Whole-Body Lesion Segmentation in 18F-FDG PET/CT
Sep 16, 2022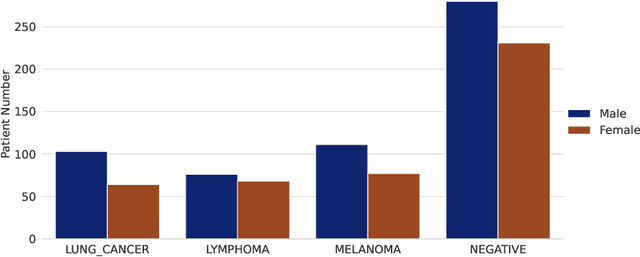
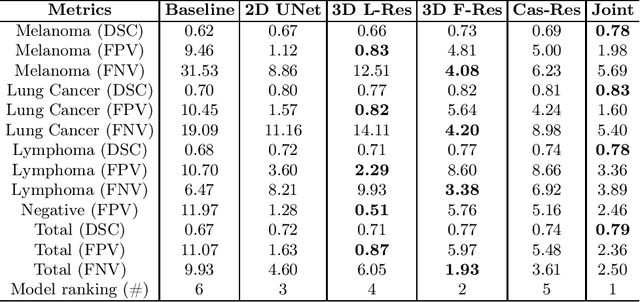
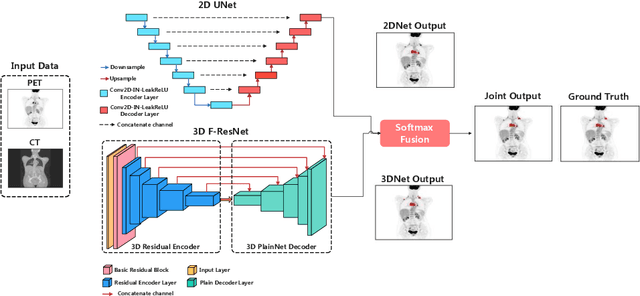
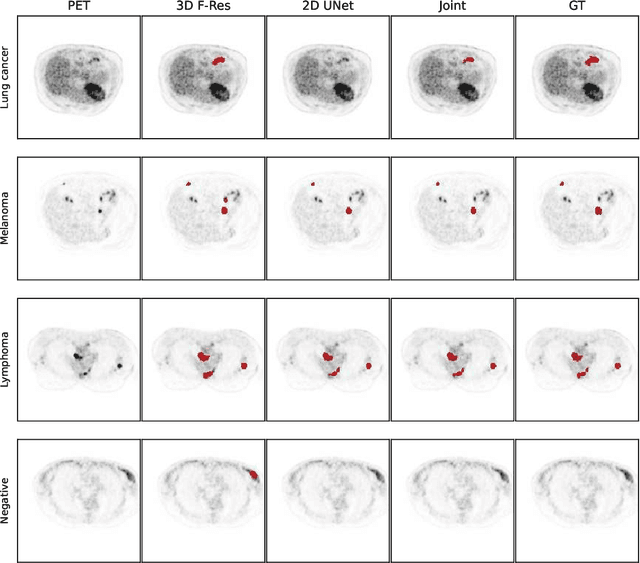
There has been growing research interest in using deep learning based method to achieve fully automated segmentation of lesion in Positron emission tomography computed tomography(PET CT) scans for the prognosis of various cancers. Recent advances in the medical image segmentation shows the nnUNET is feasible for diverse tasks. However, lesion segmentation in the PET images is not straightforward, because lesion and physiological uptake has similar distribution patterns. The Distinction of them requires extra structural information in the CT images. The present paper introduces a nnUNet based method for the lesion segmentation task. The proposed model is designed on the basis of the joint 2D and 3D nnUNET architecture to predict lesions across the whole body. It allows for automated segmentation of potential lesions. We evaluate the proposed method in the context of AutoPet Challenge, which measures the lesion segmentation performance in the metrics of dice score, false-positive volume and false-negative volume.
Community Detection in the Hypergraph SBM: Optimal Recovery Given the Similarity Matrix
Aug 23, 2022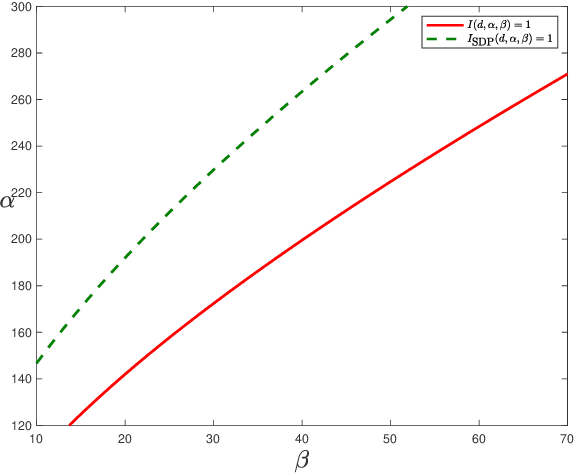
Community detection is a fundamental problem in network science. In this paper, we consider community detection in hypergraphs drawn from the $hypergraph$ $stochastic$ $block$ $model$ (HSBM), with a focus on exact community recovery. We study the performance of polynomial-time algorithms for community detection in a case where the full hypergraph is unknown. Instead, we are provided a $similarity$ $matrix$ $W$, where $W_{ij}$ reports the number of hyperedges containing both $i$ and $j$. Under this information model, Kim, Bandeira, and Goemans [KBG18] determined the information-theoretic threshold for exact recovery, and proposed a semidefinite programming relaxation which they conjectured to be optimal. In this paper, we confirm this conjecture. We also show that a simple, highly efficient spectral algorithm is optimal, establishing the spectral algorithm as the method of choice. Our analysis of the spectral algorithm crucially relies on strong $entrywise$ bounds on the eigenvectors of $W$. Our bounds are inspired by the work of Abbe, Fan, Wang, and Zhong [AFWZ20], who developed entrywise bounds for eigenvectors of symmetric matrices with independent entries. Despite the complex dependency structure in similarity matrices, we prove similar entrywise guarantees.