 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Adaptive Information Seeking for Open-Domain Question Answering
Sep 14, 2021

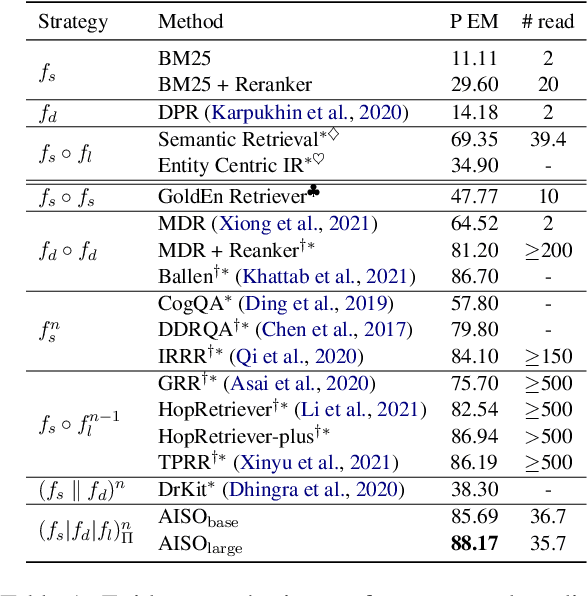
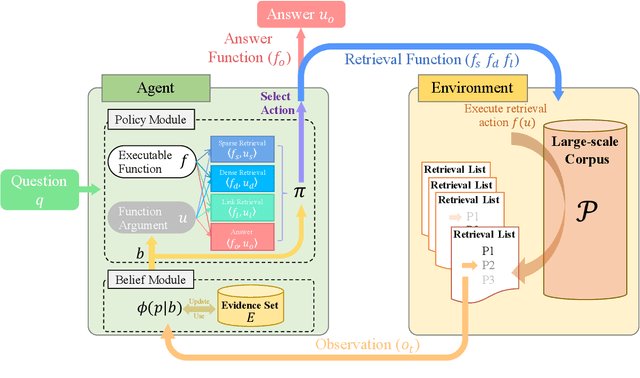
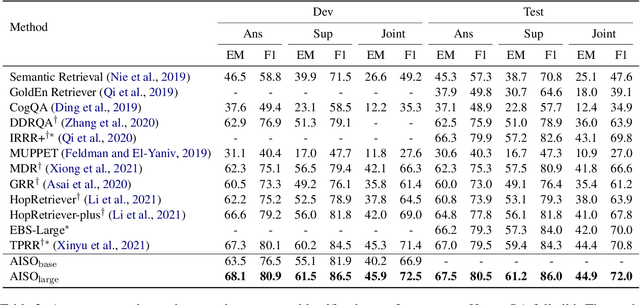
Information seeking is an essential step for open-domain question answering to efficiently gather evidence from a large corpus. Recently, iterative approaches have been proven to be effective for complex questions, by recursively retrieving new evidence at each step. However, almost all existing iterative approaches use predefined strategies, either applying the same retrieval function multiple times or fixing the order of different retrieval functions, which cannot fulfill the diverse requirements of various questions. In this paper, we propose a novel adaptive information-seeking strategy for open-domain question answering, namely AISO. Specifically, the whole retrieval and answer process is modeled as a partially observed Markov decision process, where three types of retrieval operations (e.g., BM25, DPR, and hyperlink) and one answer operation are defined as actions. According to the learned policy, AISO could adaptively select a proper retrieval action to seek the missing evidence at each step, based on the collected evidence and the reformulated query, or directly output the answer when the evidence set is sufficient for the question. Experiments on SQuAD Open and HotpotQA fullwiki, which serve as single-hop and multi-hop open-domain QA benchmarks, show that AISO outperforms all baseline methods with predefined strategies in terms of both retrieval and answer evaluations.
Convolutional Neural Networks with A Topographic Representation Module for EEG-Based Brain-Computer Interfaces
Aug 30, 2022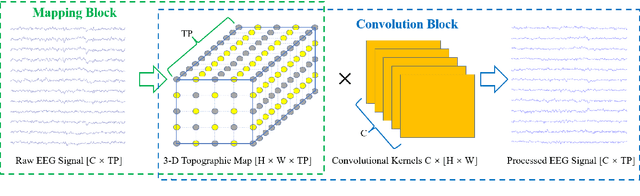
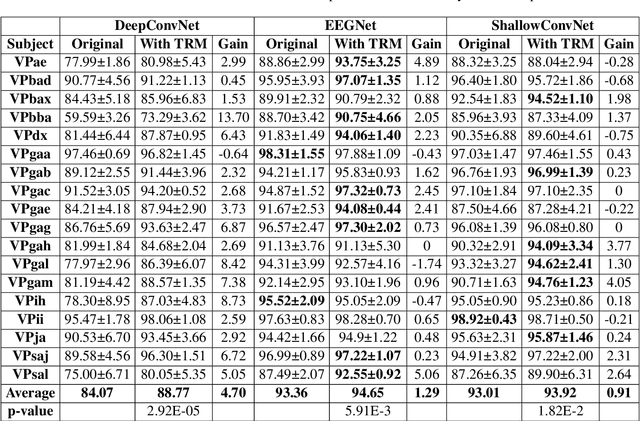
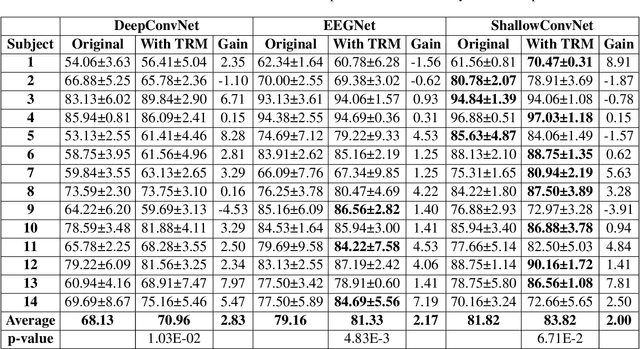
Objective: Convolutional Neural Networks (CNNs) have shown great potential in the field of Brain-Computer Interfaces (BCIs). The raw Electroencephalogram (EEG) signal is usually represented as 2-Dimensional (2-D) matrix composed of channels and time points, which ignores the spatial topological information. Our goal is to make the CNN with the raw EEG signal as input have the ability to learn EEG spatial topological features, and improve its performance while essentially maintaining its original structure. Methods:We propose an EEG Topographic Representation Module (TRM). This module consists of (1) a mapping block from the raw EEG signal to a 3-D topographic map and (2) a convolution block from the topographic map to an output of the same size as input. According to the size of the kernel used in the convolution block, we design 2 types of TRMs, namely TRM-(5,5) and TRM-(3,3). We embed the TRM into 3 widely used CNNs, and tested them on 2 publicly available datasets (Emergency Braking During Simulated Driving Dataset (EBDSDD), and High Gamma Dataset (HGD)). Results: The results show that the classification accuracies of all 3 CNNs are improved on both datasets after using the TRM. With TRM-(5,5), the average accuracies of DeepConvNet, EEGNet and ShallowConvNet are improved by 6.54%, 1.72% and 2.07% on EBDSDD, and by 6.05%, 3.02% and 5.14% on HGD, respectively; with TRM-(3,3), they are improved by 7.76%, 1.71% and 2.17% on EBDSDD, and by 7.61%, 5.06% and 6.28% on HGD, respectively. Significance: We improve the classification performance of 3 CNNs on 2 datasets by the use of TRM, indicating that it has the capability to mine the EEG spatial topological information. In addition, since the output of TRM has the same size as the input, CNNs with the raw EEG signal as input can use this module without changing their original structures.
RGB-Event Fusion for Moving Object Detection in Autonomous Driving
Sep 17, 2022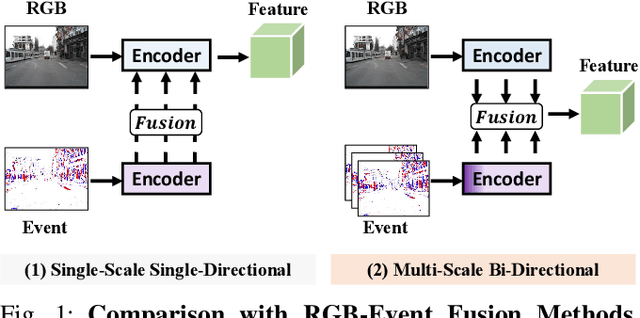
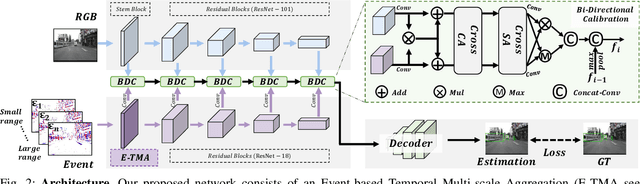
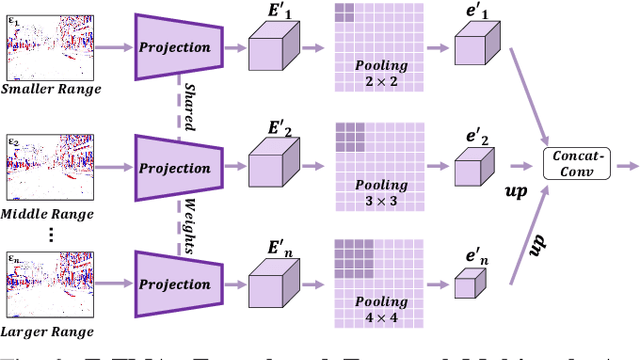
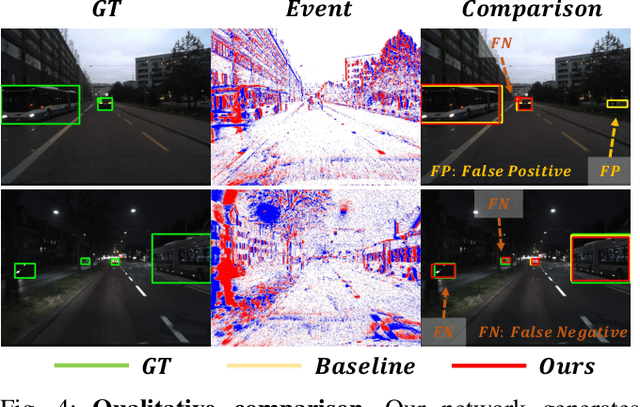
Moving Object Detection (MOD) is a critical vision task for successfully achieving safe autonomous driving. Despite plausible results of deep learning methods, most existing approaches are only frame-based and may fail to reach reasonable performance when dealing with dynamic traffic participants. Recent advances in sensor technologies, especially the Event camera, can naturally complement the conventional camera approach to better model moving objects. However, event-based works often adopt a pre-defined time window for event representation, and simply integrate it to estimate image intensities from events, neglecting much of the rich temporal information from the available asynchronous events. Therefore, from a new perspective, we propose RENet, a novel RGB-Event fusion Network, that jointly exploits the two complementary modalities to achieve more robust MOD under challenging scenarios for autonomous driving. Specifically, we first design a temporal multi-scale aggregation module to fully leverage event frames from both the RGB exposure time and larger intervals. Then we introduce a bi-directional fusion module to attentively calibrate and fuse multi-modal features. To evaluate the performance of our network, we carefully select and annotate a sub-MOD dataset from the commonly used DSEC dataset. Extensive experiments demonstrate that our proposed method performs significantly better than the state-of-the-art RGB-Event fusion alternatives.
A Comprehensive Survey on Video Saliency Detection with Auditory Information: the Audio-visual Consistency Perceptual is the Key!
Jun 20, 2022
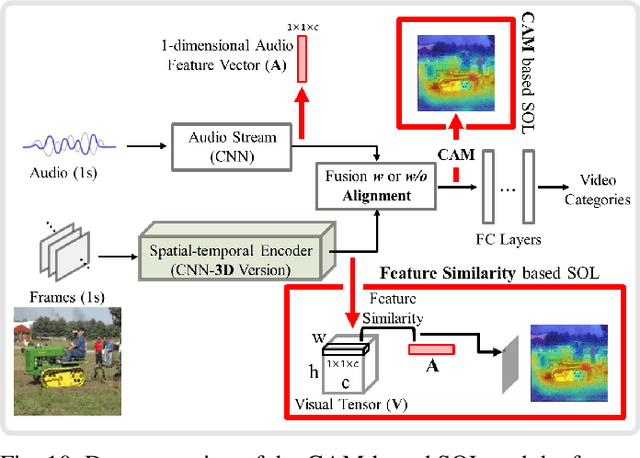
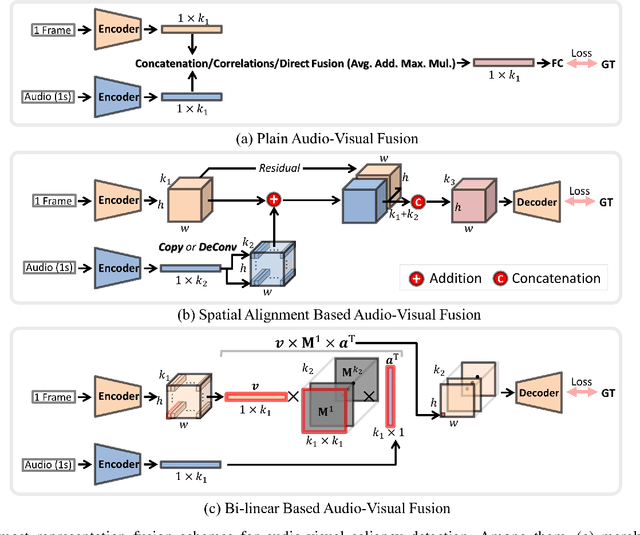
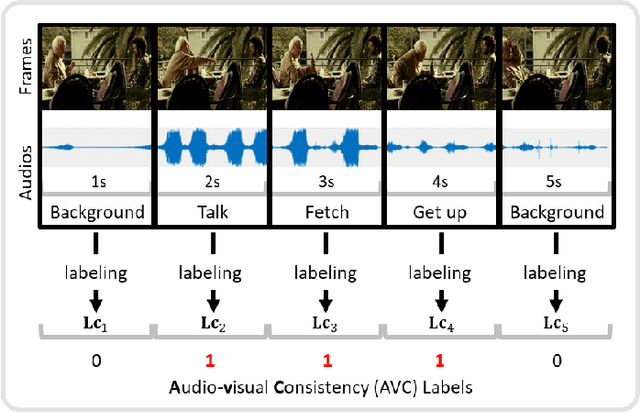
Video saliency detection (VSD) aims at fast locating the most attractive objects/things/patterns in a given video clip. Existing VSD-related works have mainly relied on the visual system but paid less attention to the audio aspect, while, actually, our audio system is the most vital complementary part to our visual system. Also, audio-visual saliency detection (AVSD), one of the most representative research topics for mimicking human perceptual mechanisms, is currently in its infancy, and none of the existing survey papers have touched on it, especially from the perspective of saliency detection. Thus, the ultimate goal of this paper is to provide an extensive review to bridge the gap between audio-visual fusion and saliency detection. In addition, as another highlight of this review, we have provided a deep insight into key factors which could directly determine the performances of AVSD deep models, and we claim that the audio-visual consistency degree (AVC) -- a long-overlooked issue, can directly influence the effectiveness of using audio to benefit its visual counterpart when performing saliency detection. Moreover, in order to make the AVC issue more practical and valuable for future followers, we have newly equipped almost all existing publicly available AVSD datasets with additional frame-wise AVC labels. Based on these upgraded datasets, we have conducted extensive quantitative evaluations to ground our claim on the importance of AVC in the AVSD task. In a word, both our ideas and new sets serve as a convenient platform with preliminaries and guidelines, all of which are very potential to facilitate future works in promoting state-of-the-art (SOTA) performance further.
Z-Index at CheckThat! Lab 2022: Check-Worthiness Identification on Tweet Text
Jul 15, 2022
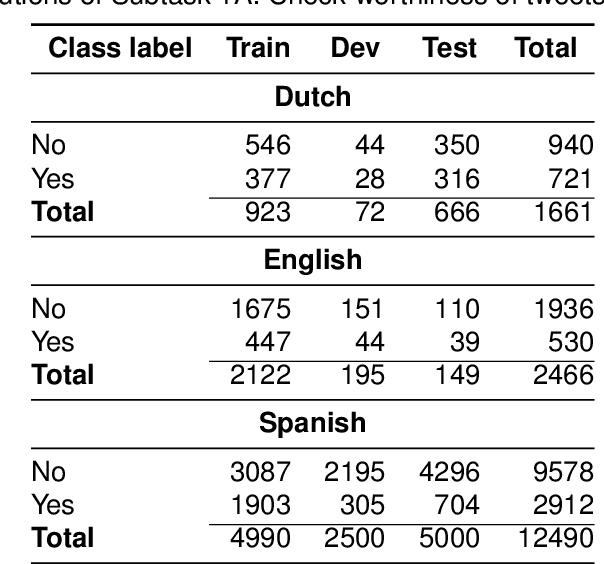
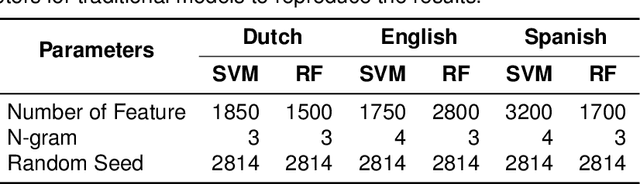

The wide use of social media and digital technologies facilitates sharing various news and information about events and activities. Despite sharing positive information misleading and false information is also spreading on social media. There have been efforts in identifying such misleading information both manually by human experts and automatic tools. Manual effort does not scale well due to the high volume of information, containing factual claims, are appearing online. Therefore, automatically identifying check-worthy claims can be very useful for human experts. In this study, we describe our participation in Subtask-1A: Check-worthiness of tweets (English, Dutch and Spanish) of CheckThat! lab at CLEF 2022. We performed standard preprocessing steps and applied different models to identify whether a given text is worthy of fact checking or not. We use the oversampling technique to balance the dataset and applied SVM and Random Forest (RF) with TF-IDF representations. We also used BERT multilingual (BERT-m) and XLM-RoBERTa-base pre-trained models for the experiments. We used BERT-m for the official submissions and our systems ranked as 3rd, 5th, and 12th in Spanish, Dutch, and English, respectively. In further experiments, our evaluation shows that transformer models (BERT-m and XLM-RoBERTa-base) outperform the SVM and RF in Dutch and English languages where a different scenario is observed for Spanish.
TF-GridNet: Making Time-Frequency Domain Models Great Again for Monaural Speaker Separation
Sep 08, 2022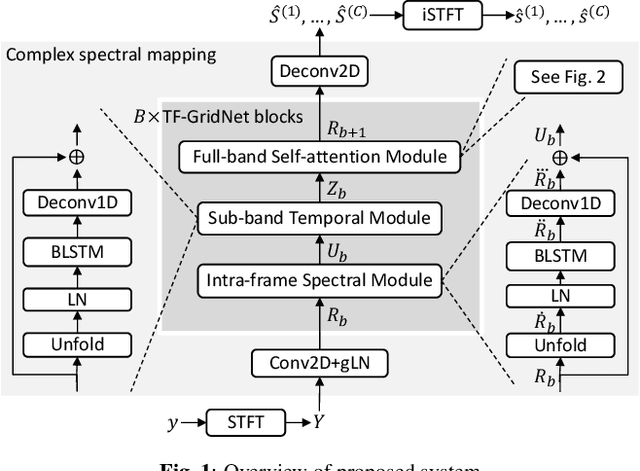
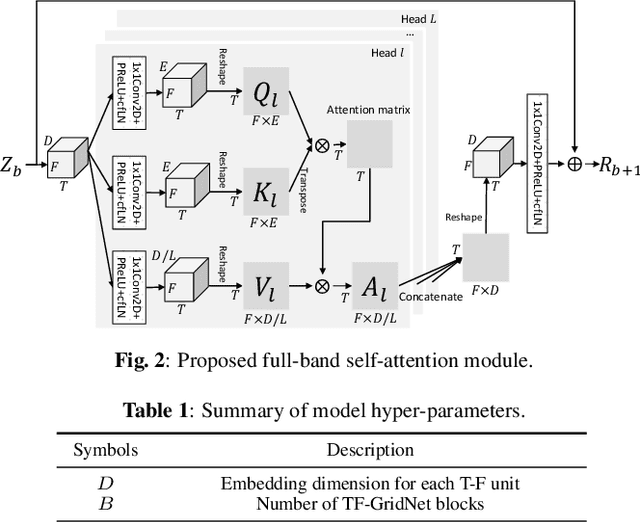


We propose TF-GridNet, a novel multi-path deep neural network (DNN) operating in the time-frequency (T-F) domain, for monaural talker-independent speaker separation in anechoic conditions. The model stacks several multi-path blocks, each consisting of an intra-frame spectral module, a sub-band temporal module, and a full-band self-attention module, to leverage local and global spectro-temporal information for separation. The model is trained to perform complex spectral mapping, where the real and imaginary (RI) components of the input mixture are stacked as input features to predict the target RI components. Besides using the scale-invariant signal-to-distortion ratio (SI-SDR) loss for model training, we include a novel loss term to encourage the separated sources to add up to the input mixture. Without using dynamic mixing, we obtain 23.4 dB SI-SDR improvement (SI-SDRi) on the WSJ0-2mix dataset, outperforming the previous best by a large margin.
Legal Case Document Similarity: You Need Both Network and Text
Sep 26, 2022
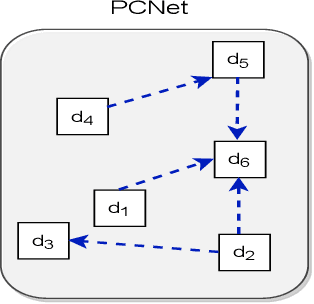

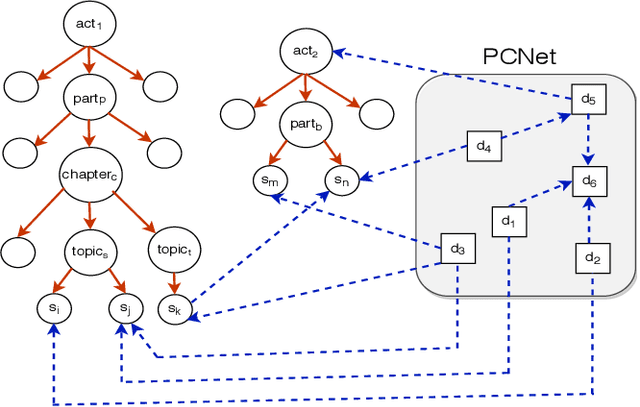
Estimating the similarity between two legal case documents is an important and challenging problem, having various downstream applications such as prior-case retrieval and citation recommendation. There are two broad approaches for the task -- citation network-based and text-based. Prior citation network-based approaches consider citations only to prior-cases (also called precedents) (PCNet). This approach misses important signals inherent in Statutes (written laws of a jurisdiction). In this work, we propose Hier-SPCNet that augments PCNet with a heterogeneous network of Statutes. We incorporate domain knowledge for legal document similarity into Hier-SPCNet, thereby obtaining state-of-the-art results for network-based legal document similarity. Both textual and network similarity provide important signals for legal case similarity; but till now, only trivial attempts have been made to unify the two signals. In this work, we apply several methods for combining textual and network information for estimating legal case similarity. We perform extensive experiments over legal case documents from the Indian judiciary, where the gold standard similarity between document-pairs is judged by law experts from two reputed Law institutes in India. Our experiments establish that our proposed network-based methods significantly improve the correlation with domain experts' opinion when compared to the existing methods for network-based legal document similarity. Our best-performing combination method (that combines network-based and text-based similarity) improves the correlation with domain experts' opinion by 11.8% over the best text-based method and 20.6\% over the best network-based method. We also establish that our best-performing method can be used to recommend / retrieve citable and similar cases for a source (query) case, which are well appreciated by legal experts.
How Speech is Recognized to Be Emotional - A Study Based on Information Decomposition
Nov 24, 2021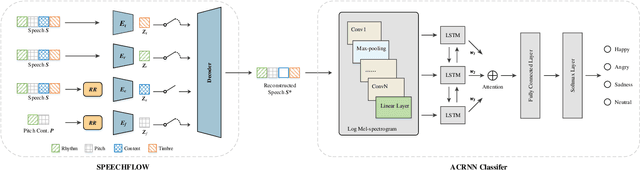
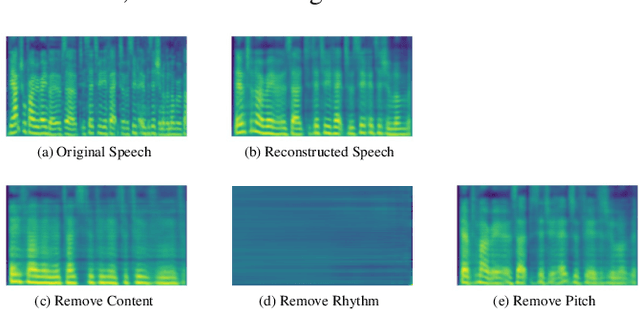
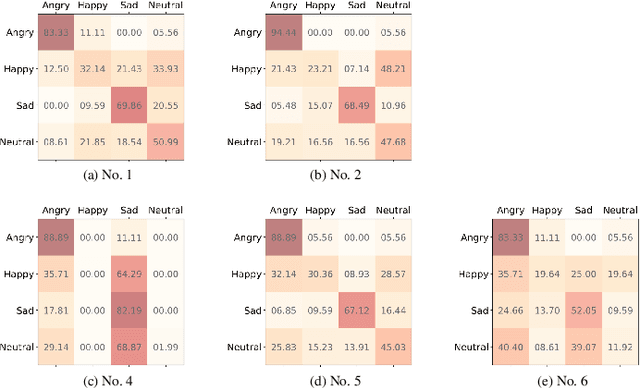
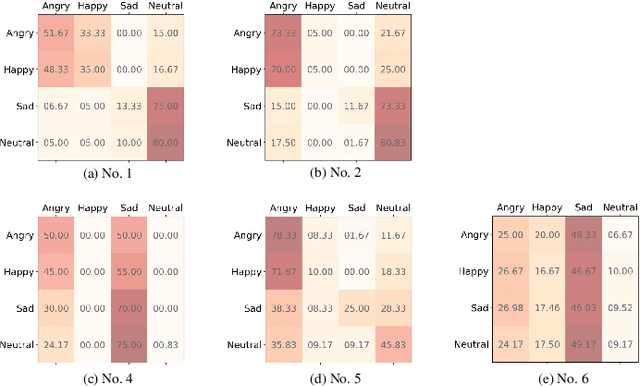
The way that humans encode their emotion into speech signals is complex. For instance, an angry man may increase his pitch and speaking rate, and use impolite words. In this paper, we present a preliminary study on various emotional factors and investigate how each of them impacts modern emotion recognition systems. The key tool of our study is the SpeechFlow model presented recently, by which we are able to decompose speech signals into separate information factors (content, pitch, rhythm). Based on this decomposition, we carefully studied the performance of each information component and their combinations. We conducted the study on three different speech emotion corpora and chose an attention-based convolutional RNN as the emotion classifier. Our results show that rhythm is the most important component for emotional expression. Moreover, the cross-corpus results are very bad (even worse than guess), demonstrating that the present speech emotion recognition model is rather weak. Interestingly, by removing one or several unimportant components, the cross-corpus results can be improved. This demonstrates the potential of the decomposition approach towards a generalizable emotion recognition.
A system for information extraction from scientific texts in Russian
Sep 14, 2021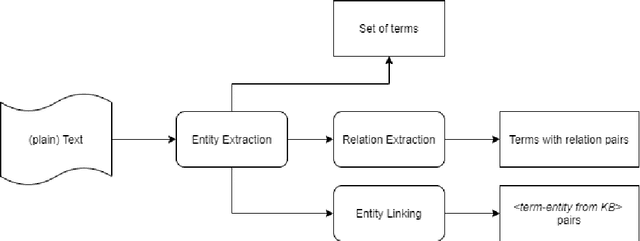
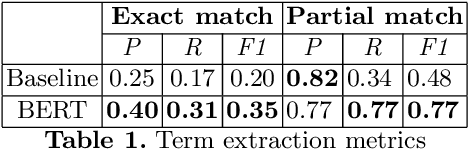
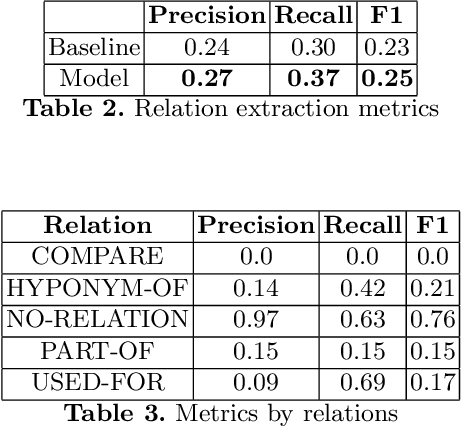
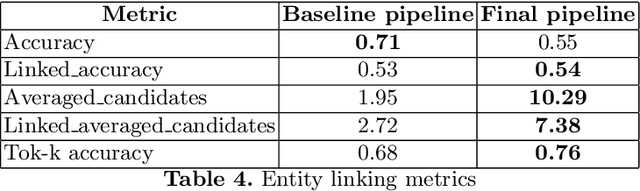
In this paper, we present a system for information extraction from scientific texts in the Russian language. The system performs several tasks in an end-to-end manner: term recognition, extraction of relations between terms, and term linking with entities from the knowledge base. These tasks are extremely important for information retrieval, recommendation systems, and classification. The advantage of the implemented methods is that the system does not require a large amount of labeled data, which saves time and effort for data labeling and therefore can be applied in low- and mid-resource settings. The source code is publicly available and can be used for different research purposes.
Time-lapse image classification using a diffractive neural network
Aug 23, 2022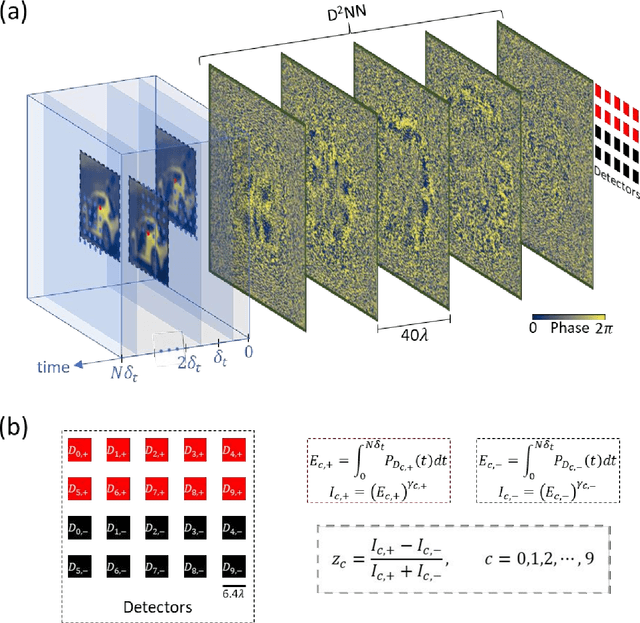
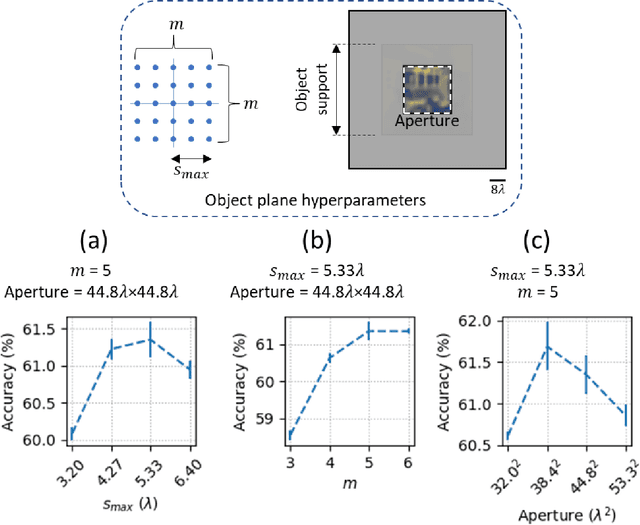
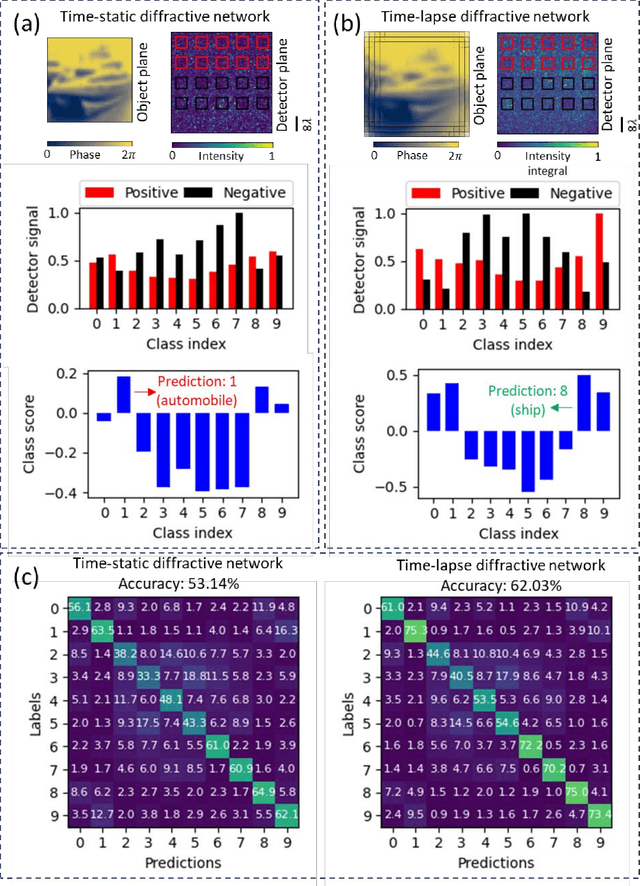
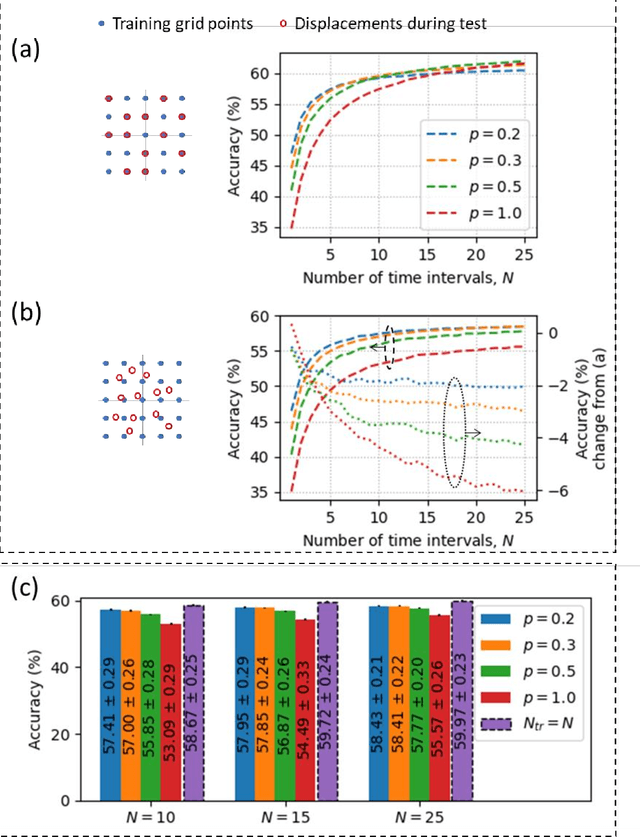
Diffractive deep neural networks (D2NNs) define an all-optical computing framework comprised of spatially engineered passive surfaces that collectively process optical input information by modulating the amplitude and/or the phase of the propagating light. Diffractive optical networks complete their computational tasks at the speed of light propagation through a thin diffractive volume, without any external computing power while exploiting the massive parallelism of optics. Diffractive networks were demonstrated to achieve all-optical classification of objects and perform universal linear transformations. Here we demonstrate, for the first time, a "time-lapse" image classification scheme using a diffractive network, significantly advancing its classification accuracy and generalization performance on complex input objects by using the lateral movements of the input objects and/or the diffractive network, relative to each other. In a different context, such relative movements of the objects and/or the camera are routinely being used for image super-resolution applications; inspired by their success, we designed a time-lapse diffractive network to benefit from the complementary information content created by controlled or random lateral shifts. We numerically explored the design space and performance limits of time-lapse diffractive networks, revealing a blind testing accuracy of 62.03% on the optical classification of objects from the CIFAR-10 dataset. This constitutes the highest inference accuracy achieved so far using a single diffractive network on the CIFAR-10 dataset. Time-lapse diffractive networks will be broadly useful for the spatio-temporal analysis of input signals using all-optical processors.