 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
MentorGNN: Deriving Curriculum for Pre-Training GNNs
Aug 21, 2022

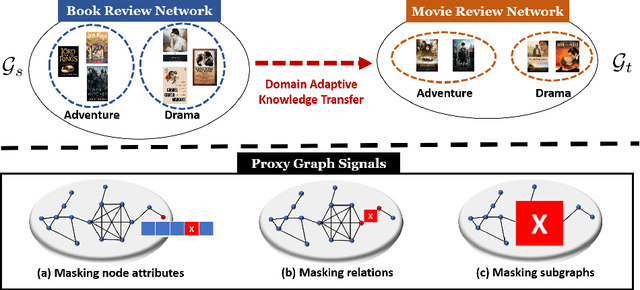
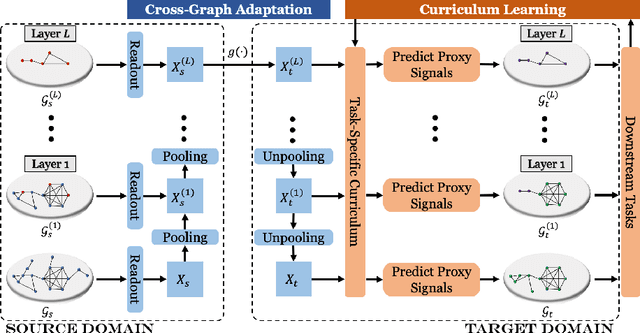
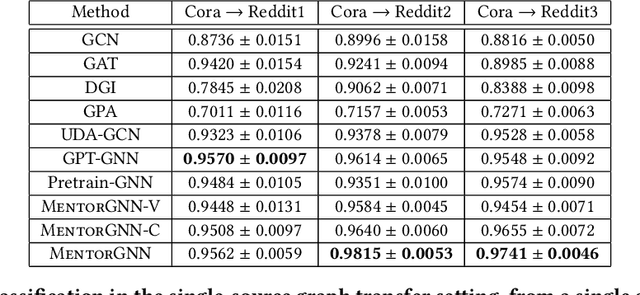
Graph pre-training strategies have been attracting a surge of attention in the graph mining community, due to their flexibility in parameterizing graph neural networks (GNNs) without any label information. The key idea lies in encoding valuable information into the backbone GNNs, by predicting the masked graph signals extracted from the input graphs. In order to balance the importance of diverse graph signals (e.g., nodes, edges, subgraphs), the existing approaches are mostly hand-engineered by introducing hyperparameters to re-weight the importance of graph signals. However, human interventions with sub-optimal hyperparameters often inject additional bias and deteriorate the generalization performance in the downstream applications. This paper addresses these limitations from a new perspective, i.e., deriving curriculum for pre-training GNNs. We propose an end-to-end model named MentorGNN that aims to supervise the pre-training process of GNNs across graphs with diverse structures and disparate feature spaces. To comprehend heterogeneous graph signals at different granularities, we propose a curriculum learning paradigm that automatically re-weighs graph signals in order to ensure a good generalization in the target domain. Moreover, we shed new light on the problem of domain adaption on relational data (i.e., graphs) by deriving a natural and interpretable upper bound on the generalization error of the pre-trained GNNs. Extensive experiments on a wealth of real graphs validate and verify the performance of MentorGNN.
The Power of Selecting Key Blocks with Local Pre-ranking for Long Document Information Retrieval
Nov 18, 2021
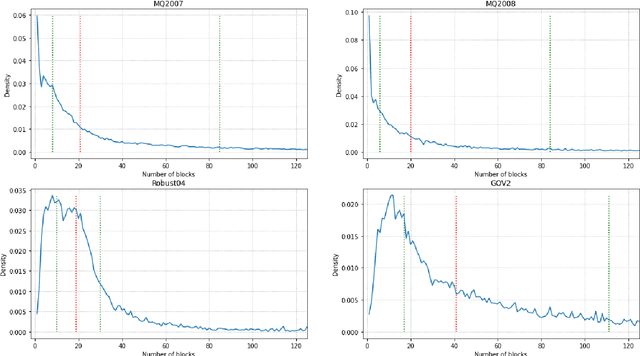
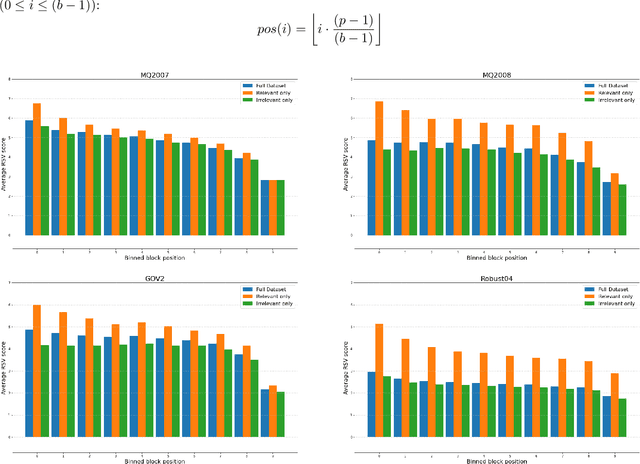
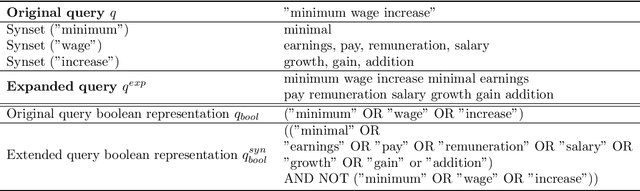
On a wide range of natural language processing and information retrieval tasks, transformer-based models, particularly pre-trained language models like BERT, have demonstrated tremendous effectiveness. Due to the quadratic complexity of the self-attention mechanism, however, such models have difficulties processing long documents. Recent works dealing with this issue include truncating long documents, segmenting them into passages that can be treated by a standard BERT model, or modifying the self-attention mechanism to make it sparser as in sparse-attention models. However, these approaches either lose information or have high computational complexity (and are both time, memory and energy consuming in this later case). We follow here a slightly different approach in which one first selects key blocks of a long document by local query-block pre-ranking, and then few blocks are aggregated to form a short document that can be processed by a model such as BERT. Experiments conducted on standard Information Retrieval datasets demonstrate the effectiveness of the proposed approach.
SGM-Net: Semantic Guided Matting Net
Aug 16, 2022
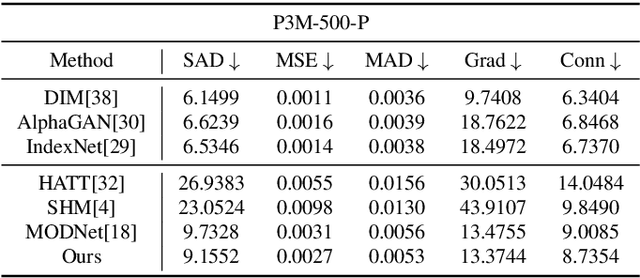
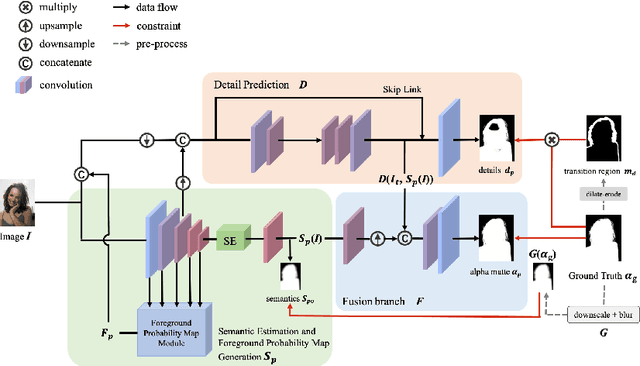
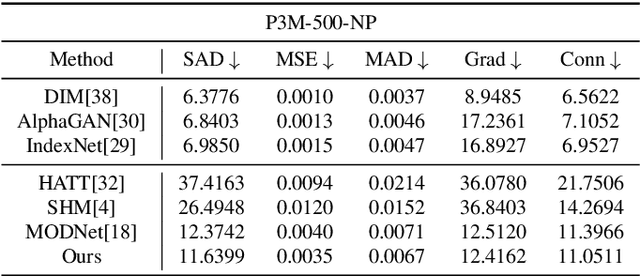
Human matting refers to extracting human parts from natural images with high quality, including human detail information such as hair, glasses, hat, etc. This technology plays an essential role in image synthesis and visual effects in the film industry. When the green screen is not available, the existing human matting methods need the help of additional inputs (such as trimap, background image, etc.), or the model with high computational cost and complex network structure, which brings great difficulties to the application of human matting in practice. To alleviate such problems, most existing methods (such as MODNet) use multi-branches to pave the way for matting through segmentation, but these methods do not make full use of the image features and only utilize the prediction results of the network as guidance information. Therefore, we propose a module to generate foreground probability map and add it to MODNet to obtain Semantic Guided Matting Net (SGM-Net). Under the condition of only one image, we can realize the human matting task. We verify our method on the P3M-10k dataset. Compared with the benchmark, our method has significantly improved in various evaluation indicators.
RGB-Event Fusion for Moving Object Detection in Autonomous Driving
Sep 17, 2022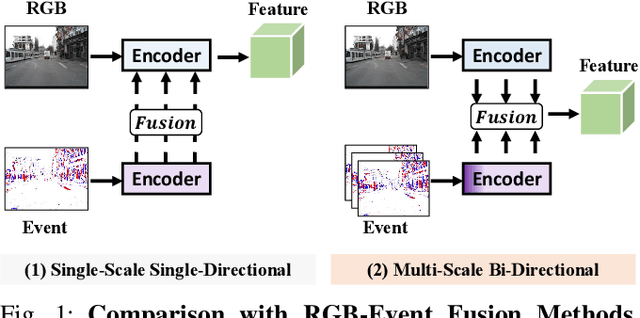
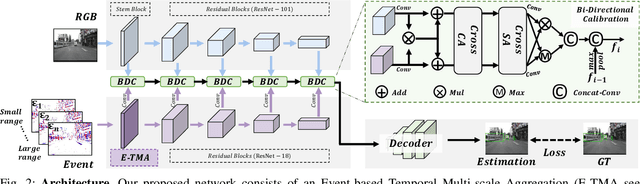
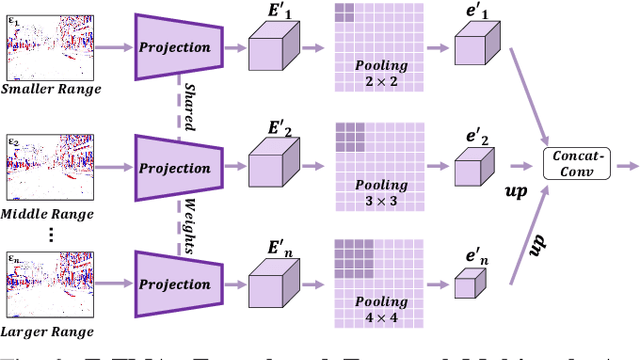
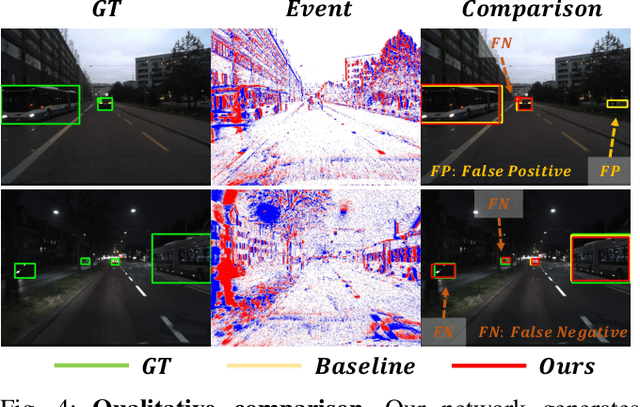
Moving Object Detection (MOD) is a critical vision task for successfully achieving safe autonomous driving. Despite plausible results of deep learning methods, most existing approaches are only frame-based and may fail to reach reasonable performance when dealing with dynamic traffic participants. Recent advances in sensor technologies, especially the Event camera, can naturally complement the conventional camera approach to better model moving objects. However, event-based works often adopt a pre-defined time window for event representation, and simply integrate it to estimate image intensities from events, neglecting much of the rich temporal information from the available asynchronous events. Therefore, from a new perspective, we propose RENet, a novel RGB-Event fusion Network, that jointly exploits the two complementary modalities to achieve more robust MOD under challenging scenarios for autonomous driving. Specifically, we first design a temporal multi-scale aggregation module to fully leverage event frames from both the RGB exposure time and larger intervals. Then we introduce a bi-directional fusion module to attentively calibrate and fuse multi-modal features. To evaluate the performance of our network, we carefully select and annotate a sub-MOD dataset from the commonly used DSEC dataset. Extensive experiments demonstrate that our proposed method performs significantly better than the state-of-the-art RGB-Event fusion alternatives.
Legal Case Document Similarity: You Need Both Network and Text
Sep 26, 2022
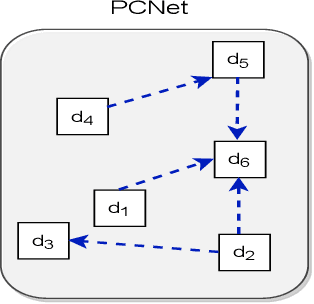

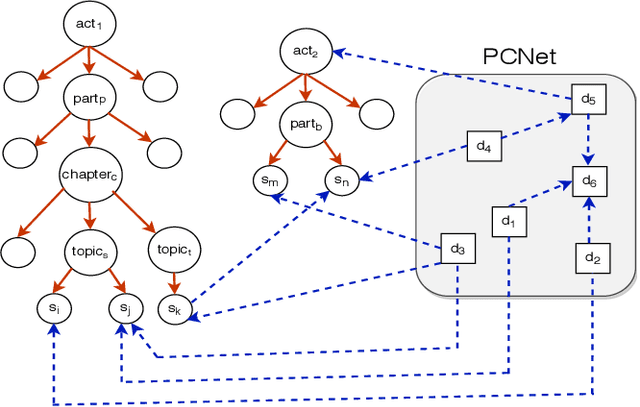
Estimating the similarity between two legal case documents is an important and challenging problem, having various downstream applications such as prior-case retrieval and citation recommendation. There are two broad approaches for the task -- citation network-based and text-based. Prior citation network-based approaches consider citations only to prior-cases (also called precedents) (PCNet). This approach misses important signals inherent in Statutes (written laws of a jurisdiction). In this work, we propose Hier-SPCNet that augments PCNet with a heterogeneous network of Statutes. We incorporate domain knowledge for legal document similarity into Hier-SPCNet, thereby obtaining state-of-the-art results for network-based legal document similarity. Both textual and network similarity provide important signals for legal case similarity; but till now, only trivial attempts have been made to unify the two signals. In this work, we apply several methods for combining textual and network information for estimating legal case similarity. We perform extensive experiments over legal case documents from the Indian judiciary, where the gold standard similarity between document-pairs is judged by law experts from two reputed Law institutes in India. Our experiments establish that our proposed network-based methods significantly improve the correlation with domain experts' opinion when compared to the existing methods for network-based legal document similarity. Our best-performing combination method (that combines network-based and text-based similarity) improves the correlation with domain experts' opinion by 11.8% over the best text-based method and 20.6\% over the best network-based method. We also establish that our best-performing method can be used to recommend / retrieve citable and similar cases for a source (query) case, which are well appreciated by legal experts.
EBOCA: Evidences for BiOmedical Concepts Association Ontology
Aug 01, 2022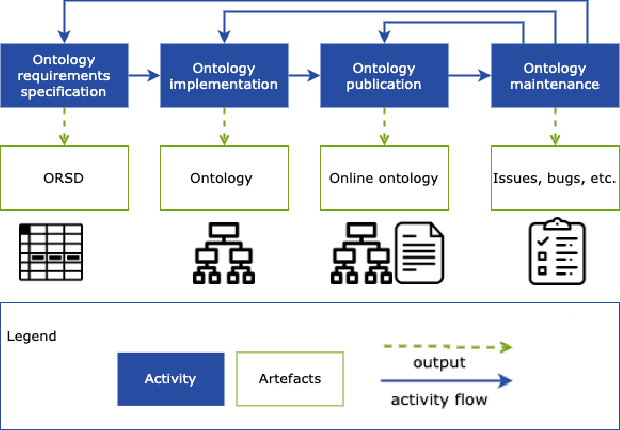
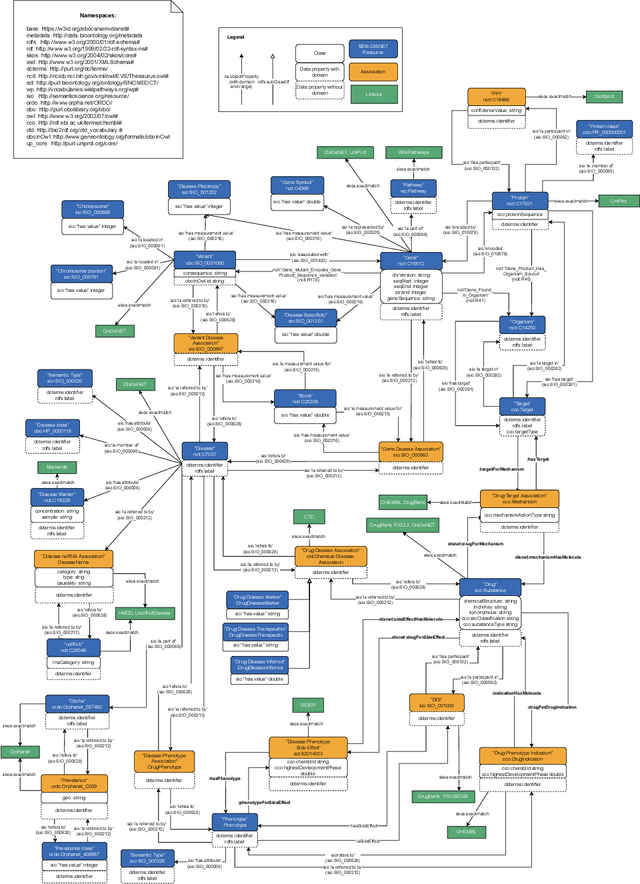
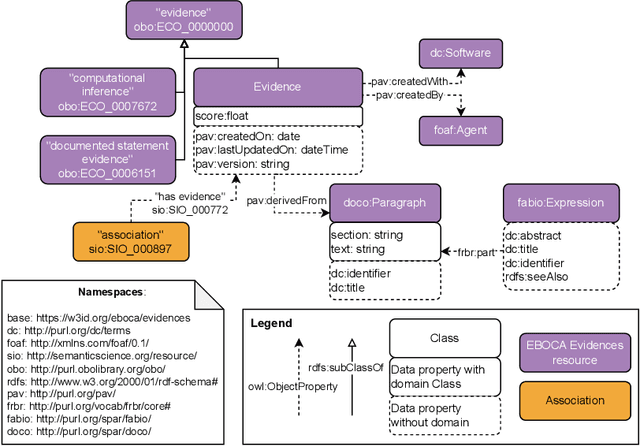
There is a large number of online documents data sources available nowadays. The lack of structure and the differences between formats are the main difficulties to automatically extract information from them, which also has a negative impact on its use and reuse. In the biomedical domain, the DISNET platform emerged to provide researchers with a resource to obtain information in the scope of human disease networks by means of large-scale heterogeneous sources. Specifically in this domain, it is critical to offer not only the information extracted from different sources, but also the evidence that supports it. This paper proposes EBOCA, an ontology that describes (i) biomedical domain concepts and associations between them, and (ii) evidences supporting these associations; with the objective of providing an schema to improve the publication and description of evidences and biomedical associations in this domain. The ontology has been successfully evaluated to ensure there are no errors, modelling pitfalls and that it meets the previously defined functional requirements. Test data coming from a subset of DISNET and automatic association extractions from texts has been transformed according to the proposed ontology to create a Knowledge Graph that can be used in real scenarios, and which has also been used for the evaluation of the presented ontology.
A Graph-based Algorithm for Robust Sequential Localization Exploiting Multipath for Obstructed-LOS-Bias Mitigation
Jul 24, 2022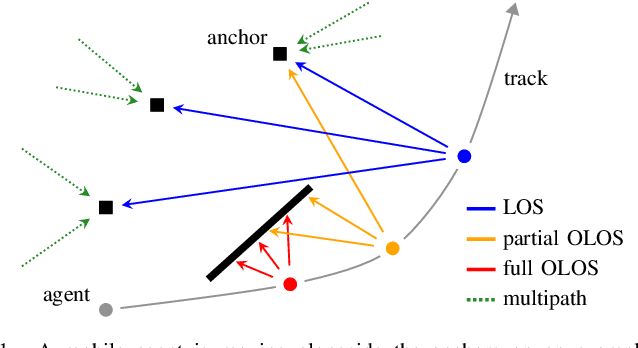
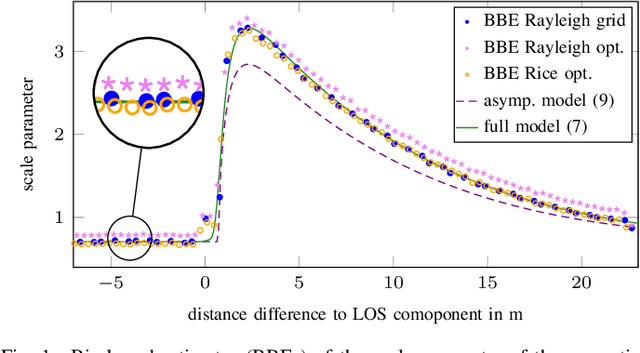
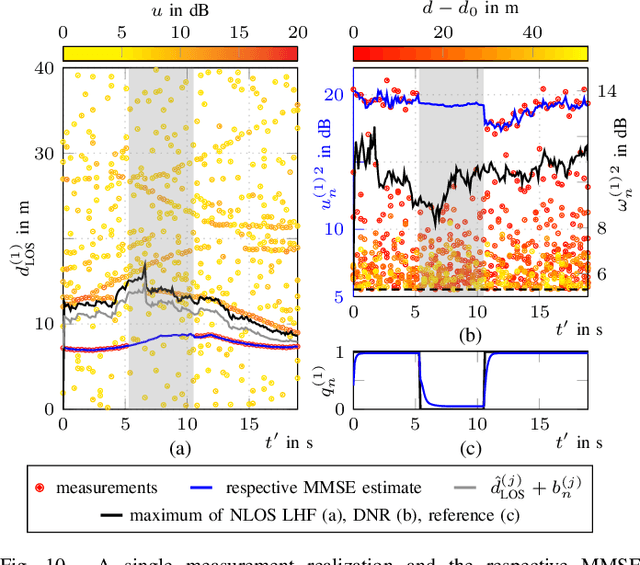
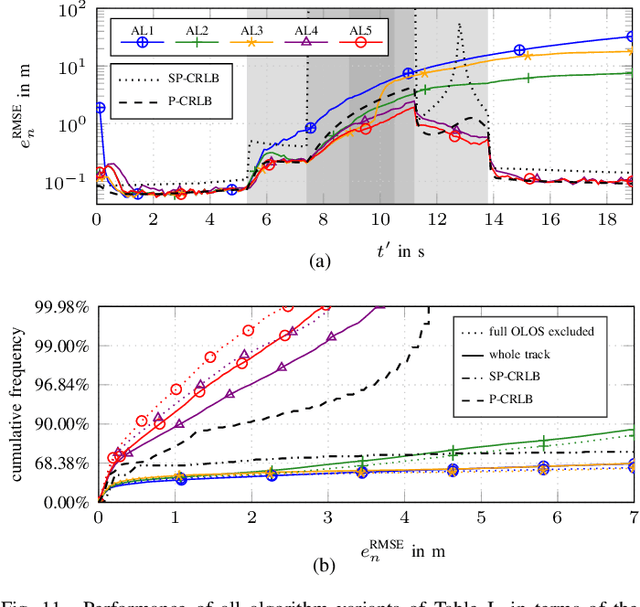
This paper presents a factor graph formulation and particle-based sum-product algorithm (SPA) for robust sequential localization in multipath-prone environments. The proposed algorithm jointly performs data association, sequential estimation of a mobile agent position, and adapts all relevant model parameters. We derive a novel non-uniform false alarm (FA) model that captures the delay and amplitude statistics of the multipath radio channel. This model enables the algorithm to indirectly exploit position-related information contained in the MPCs for the estimation of the agent position. Using simulated and real measurements, we demonstrate that the algorithm can provide high-accuracy position estimates even in fully obstructed line-of-sight (OLOS) situations, significantly outperforming the conventional amplitude-information probabilistic data association (AIPDA) filter. We show that the performance of our algorithm constantly attains the posterior Cramer-Rao lower bound (PCRLB), or even succeeds it, due to the additional information contained in the presented FA model.
Boosting 3D Object Detection via Object-Focused Image Fusion
Jul 21, 2022
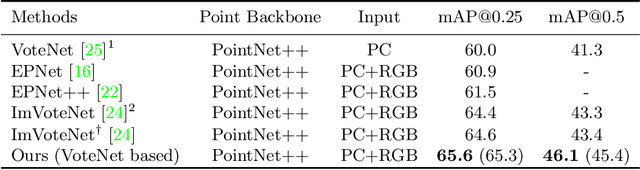

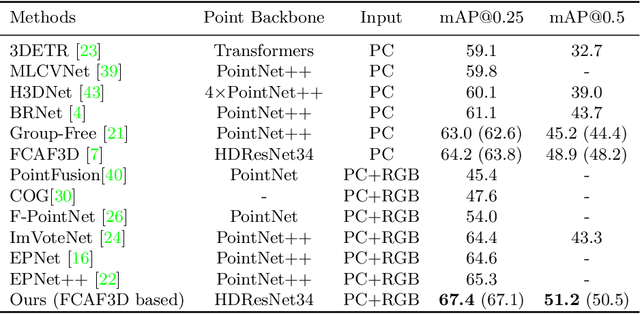
3D object detection has achieved remarkable progress by taking point clouds as the only input. However, point clouds often suffer from incomplete geometric structures and the lack of semantic information, which makes detectors hard to accurately classify detected objects. In this work, we focus on how to effectively utilize object-level information from images to boost the performance of point-based 3D detector. We present DeMF, a simple yet effective method to fuse image information into point features. Given a set of point features and image feature maps, DeMF adaptively aggregates image features by taking the projected 2D location of the 3D point as reference. We evaluate our method on the challenging SUN RGB-D dataset, improving state-of-the-art results by a large margin (+2.1 mAP@0.25 and +2.3mAP@0.5). Code is available at https://github.com/haoy945/DeMF.
TF-GridNet: Making Time-Frequency Domain Models Great Again for Monaural Speaker Separation
Sep 08, 2022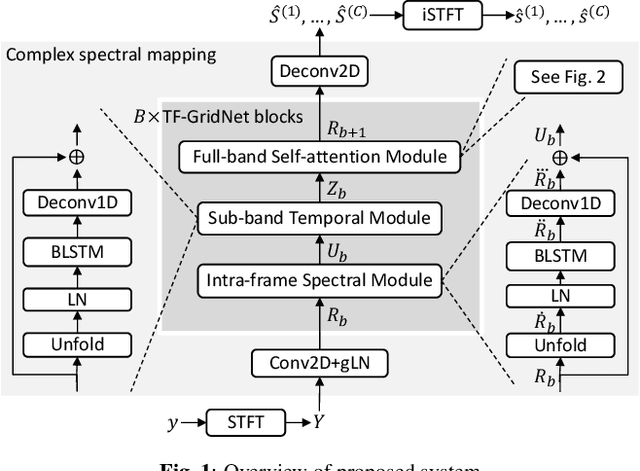
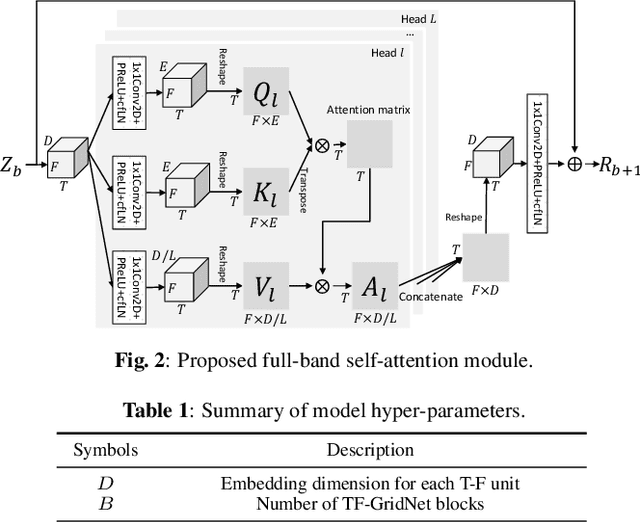


We propose TF-GridNet, a novel multi-path deep neural network (DNN) operating in the time-frequency (T-F) domain, for monaural talker-independent speaker separation in anechoic conditions. The model stacks several multi-path blocks, each consisting of an intra-frame spectral module, a sub-band temporal module, and a full-band self-attention module, to leverage local and global spectro-temporal information for separation. The model is trained to perform complex spectral mapping, where the real and imaginary (RI) components of the input mixture are stacked as input features to predict the target RI components. Besides using the scale-invariant signal-to-distortion ratio (SI-SDR) loss for model training, we include a novel loss term to encourage the separated sources to add up to the input mixture. Without using dynamic mixing, we obtain 23.4 dB SI-SDR improvement (SI-SDRi) on the WSJ0-2mix dataset, outperforming the previous best by a large margin.
Convolutional Neural Networks with A Topographic Representation Module for EEG-Based Brain-Computer Interfaces
Aug 30, 2022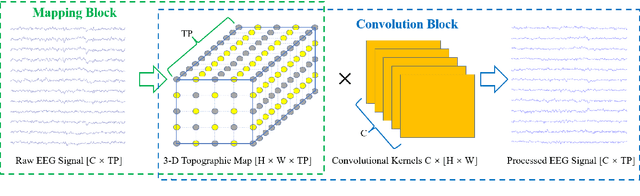
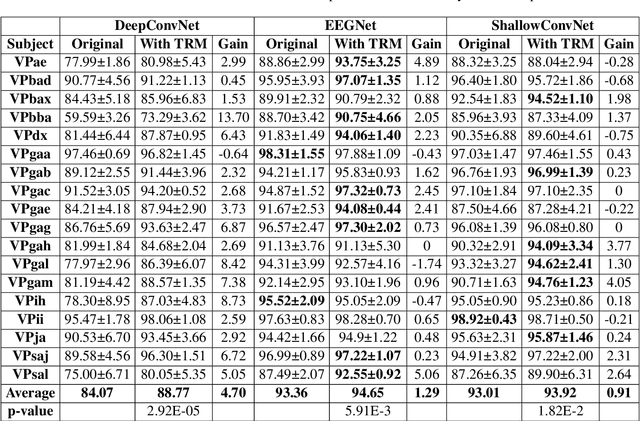
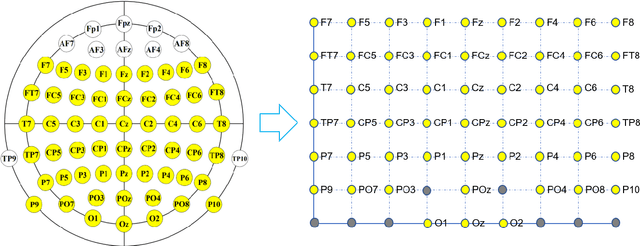
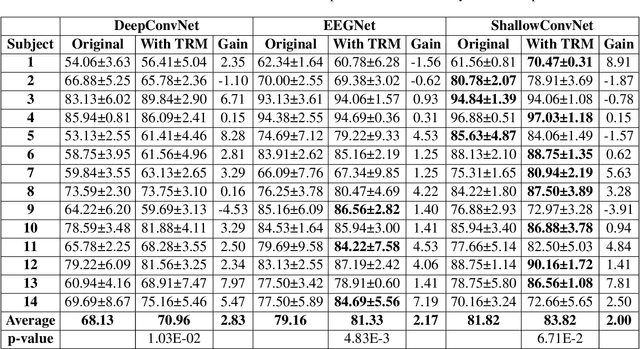
Objective: Convolutional Neural Networks (CNNs) have shown great potential in the field of Brain-Computer Interfaces (BCIs). The raw Electroencephalogram (EEG) signal is usually represented as 2-Dimensional (2-D) matrix composed of channels and time points, which ignores the spatial topological information. Our goal is to make the CNN with the raw EEG signal as input have the ability to learn EEG spatial topological features, and improve its performance while essentially maintaining its original structure. Methods:We propose an EEG Topographic Representation Module (TRM). This module consists of (1) a mapping block from the raw EEG signal to a 3-D topographic map and (2) a convolution block from the topographic map to an output of the same size as input. According to the size of the kernel used in the convolution block, we design 2 types of TRMs, namely TRM-(5,5) and TRM-(3,3). We embed the TRM into 3 widely used CNNs, and tested them on 2 publicly available datasets (Emergency Braking During Simulated Driving Dataset (EBDSDD), and High Gamma Dataset (HGD)). Results: The results show that the classification accuracies of all 3 CNNs are improved on both datasets after using the TRM. With TRM-(5,5), the average accuracies of DeepConvNet, EEGNet and ShallowConvNet are improved by 6.54%, 1.72% and 2.07% on EBDSDD, and by 6.05%, 3.02% and 5.14% on HGD, respectively; with TRM-(3,3), they are improved by 7.76%, 1.71% and 2.17% on EBDSDD, and by 7.61%, 5.06% and 6.28% on HGD, respectively. Significance: We improve the classification performance of 3 CNNs on 2 datasets by the use of TRM, indicating that it has the capability to mine the EEG spatial topological information. In addition, since the output of TRM has the same size as the input, CNNs with the raw EEG signal as input can use this module without changing their original structures.