 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Unifying Generation and Compression: Ultra-low bitrate Image Coding Via Multi-stage Transformer
Mar 06, 2024

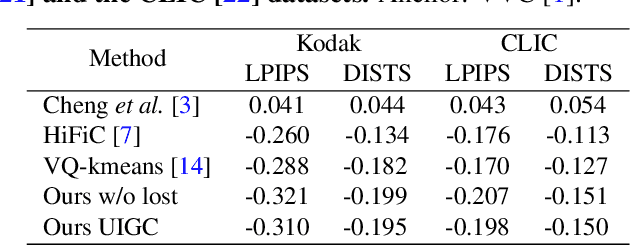
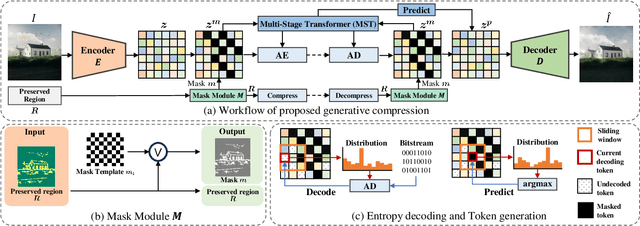
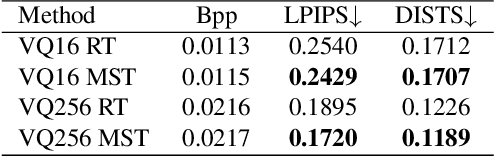
Recent progress in generative compression technology has significantly improved the perceptual quality of compressed data. However, these advancements primarily focus on producing high-frequency details, often overlooking the ability of generative models to capture the prior distribution of image content, thus impeding further bitrate reduction in extreme compression scenarios (<0.05 bpp). Motivated by the capabilities of predictive language models for lossless compression, this paper introduces a novel Unified Image Generation-Compression (UIGC) paradigm, merging the processes of generation and compression. A key feature of the UIGC framework is the adoption of vector-quantized (VQ) image models for tokenization, alongside a multi-stage transformer designed to exploit spatial contextual information for modeling the prior distribution. As such, the dual-purpose framework effectively utilizes the learned prior for entropy estimation and assists in the regeneration of lost tokens. Extensive experiments demonstrate the superiority of the proposed UIGC framework over existing codecs in perceptual quality and human perception, particularly in ultra-low bitrate scenarios (<=0.03 bpp), pioneering a new direction in generative compression.
KG-TREAT: Pre-training for Treatment Effect Estimation by Synergizing Patient Data with Knowledge Graphs
Mar 06, 2024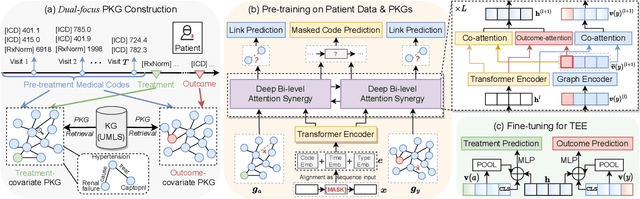
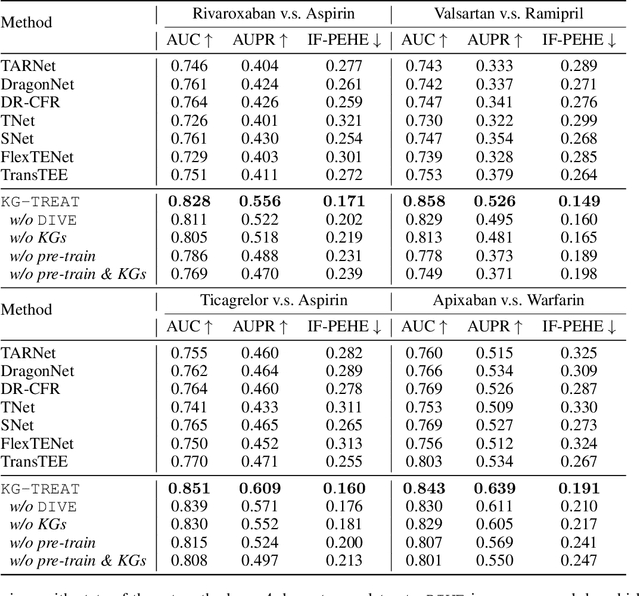

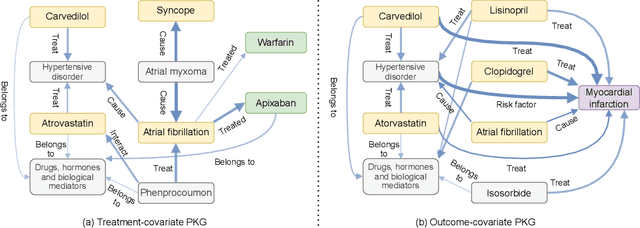
Treatment effect estimation (TEE) is the task of determining the impact of various treatments on patient outcomes. Current TEE methods fall short due to reliance on limited labeled data and challenges posed by sparse and high-dimensional observational patient data. To address the challenges, we introduce a novel pre-training and fine-tuning framework, KG-TREAT, which synergizes large-scale observational patient data with biomedical knowledge graphs (KGs) to enhance TEE. Unlike previous approaches, KG-TREAT constructs dual-focus KGs and integrates a deep bi-level attention synergy method for in-depth information fusion, enabling distinct encoding of treatment-covariate and outcome-covariate relationships. KG-TREAT also incorporates two pre-training tasks to ensure a thorough grounding and contextualization of patient data and KGs. Evaluation on four downstream TEE tasks shows KG-TREAT's superiority over existing methods, with an average improvement of 7% in Area under the ROC Curve (AUC) and 9% in Influence Function-based Precision of Estimating Heterogeneous Effects (IF-PEHE). The effectiveness of our estimated treatment effects is further affirmed by alignment with established randomized clinical trial findings.
One-Step Multi-View Clustering Based on Transition Probability
Mar 03, 2024

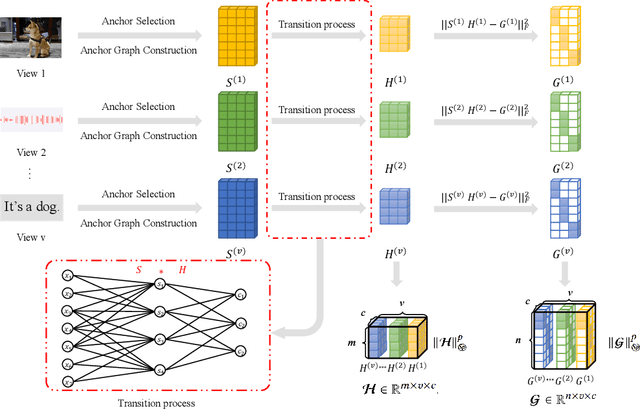
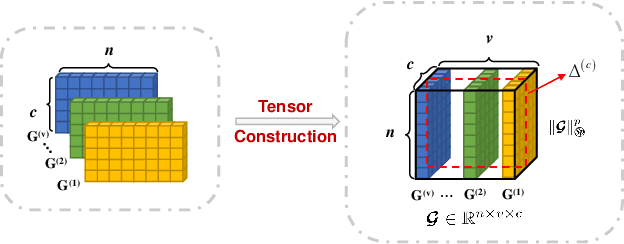
The large-scale multi-view clustering algorithms, based on the anchor graph, have shown promising performance and efficiency and have been extensively explored in recent years. Despite their successes, current methods lack interpretability in the clustering process and do not sufficiently consider the complementary information across different views. To address these shortcomings, we introduce the One-Step Multi-View Clustering Based on Transition Probability (OSMVC-TP). This method adopts a probabilistic approach, which leverages the anchor graph, representing the transition probabilities from samples to anchor points. Our method directly learns the transition probabilities from anchor points to categories, and calculates the transition probabilities from samples to categories, thus obtaining soft label matrices for samples and anchor points, enhancing the interpretability of clustering. Furthermore, to maintain consistency in labels across different views, we apply a Schatten p-norm constraint on the tensor composed of the soft labels. This approach effectively harnesses the complementary information among the views. Extensive experiments have confirmed the effectiveness and robustness of OSMVC-TP.
Perceptive self-supervised learning network for noisy image watermark removal
Mar 04, 2024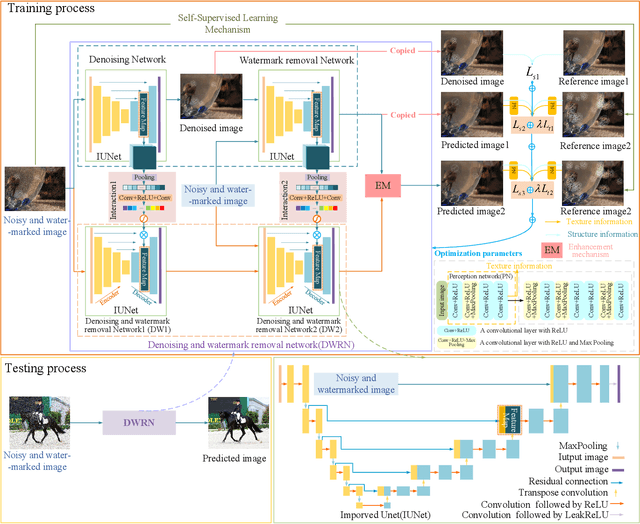



Popular methods usually use a degradation model in a supervised way to learn a watermark removal model. However, it is true that reference images are difficult to obtain in the real world, as well as collected images by cameras suffer from noise. To overcome these drawbacks, we propose a perceptive self-supervised learning network for noisy image watermark removal (PSLNet) in this paper. PSLNet depends on a parallel network to remove noise and watermarks. The upper network uses task decomposition ideas to remove noise and watermarks in sequence. The lower network utilizes the degradation model idea to simultaneously remove noise and watermarks. Specifically, mentioned paired watermark images are obtained in a self supervised way, and paired noisy images (i.e., noisy and reference images) are obtained in a supervised way. To enhance the clarity of obtained images, interacting two sub-networks and fusing obtained clean images are used to improve the effects of image watermark removal in terms of structural information and pixel enhancement. Taking into texture information account, a mixed loss uses obtained images and features to achieve a robust model of noisy image watermark removal. Comprehensive experiments show that our proposed method is very effective in comparison with popular convolutional neural networks (CNNs) for noisy image watermark removal. Codes can be obtained at https://github.com/hellloxiaotian/PSLNet.
ChatGPT and biometrics: an assessment of face recognition, gender detection, and age estimation capabilities
Mar 05, 2024

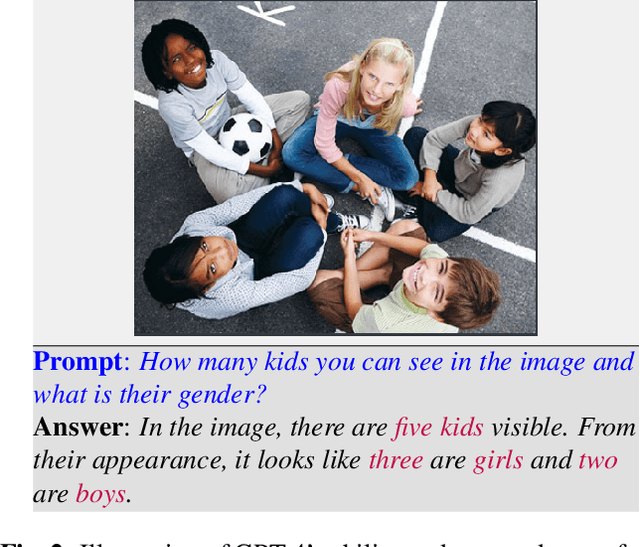

This paper explores the application of large language models (LLMs), like ChatGPT, for biometric tasks. We specifically examine the capabilities of ChatGPT in performing biometric-related tasks, with an emphasis on face recognition, gender detection, and age estimation. Since biometrics are considered as sensitive information, ChatGPT avoids answering direct prompts, and thus we crafted a prompting strategy to bypass its safeguard and evaluate the capabilities for biometrics tasks. Our study reveals that ChatGPT recognizes facial identities and differentiates between two facial images with considerable accuracy. Additionally, experimental results demonstrate remarkable performance in gender detection and reasonable accuracy for the age estimation tasks. Our findings shed light on the promising potentials in the application of LLMs and foundation models for biometrics.
Opportunistic Scheduling Using Statistical Information of Wireless Channels
Feb 13, 2024This paper considers opportunistic scheduler (OS) design using statistical channel state information~(CSI). We apply max-weight schedulers (MWSs) to maximize a utility function of users' average data rates. MWSs schedule the user with the highest weighted instantaneous data rate every time slot. Existing methods require hundreds of time slots to adjust the MWS's weights according to the instantaneous CSI before finding the optimal weights that maximize the utility function. In contrast, our MWS design requires few slots for estimating the statistical CSI. Specifically, we formulate a weight optimization problem using the mean and variance of users' signal-to-noise ratios (SNRs) to construct constraints bounding users' feasible average rates. Here, the utility function is the formulated objective, and the MWS's weights are optimization variables. We develop an iterative solver for the problem and prove that it finds the optimal weights. We also design an online architecture where the solver adaptively generates optimal weights for networks with varying mean and variance of the SNRs. Simulations show that our methods effectively require $4\sim10$ times fewer slots to find the optimal weights and achieve $5\sim15\%$ better average rates than the existing methods.
Graph Learning under Distribution Shifts: A Comprehensive Survey on Domain Adaptation, Out-of-distribution, and Continual Learning
Mar 07, 2024Graph learning plays a pivotal role and has gained significant attention in various application scenarios, from social network analysis to recommendation systems, for its effectiveness in modeling complex data relations represented by graph structural data. In reality, the real-world graph data typically show dynamics over time, with changing node attributes and edge structure, leading to the severe graph data distribution shift issue. This issue is compounded by the diverse and complex nature of distribution shifts, which can significantly impact the performance of graph learning methods in degraded generalization and adaptation capabilities, posing a substantial challenge to their effectiveness. In this survey, we provide a comprehensive review and summary of the latest approaches, strategies, and insights that address distribution shifts within the context of graph learning. Concretely, according to the observability of distributions in the inference stage and the availability of sufficient supervision information in the training stage, we categorize existing graph learning methods into several essential scenarios, including graph domain adaptation learning, graph out-of-distribution learning, and graph continual learning. For each scenario, a detailed taxonomy is proposed, with specific descriptions and discussions of existing progress made in distribution-shifted graph learning. Additionally, we discuss the potential applications and future directions for graph learning under distribution shifts with a systematic analysis of the current state in this field. The survey is positioned to provide general guidance for the development of effective graph learning algorithms in handling graph distribution shifts, and to stimulate future research and advancements in this area.
Exploring LLM-based Agents for Root Cause Analysis
Mar 07, 2024

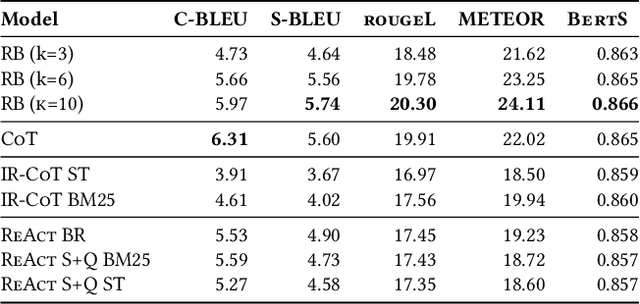
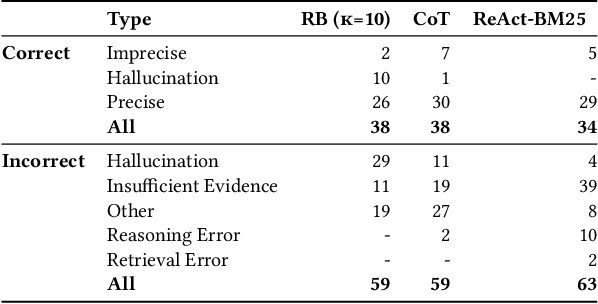
The growing complexity of cloud based software systems has resulted in incident management becoming an integral part of the software development lifecycle. Root cause analysis (RCA), a critical part of the incident management process, is a demanding task for on-call engineers, requiring deep domain knowledge and extensive experience with a team's specific services. Automation of RCA can result in significant savings of time, and ease the burden of incident management on on-call engineers. Recently, researchers have utilized Large Language Models (LLMs) to perform RCA, and have demonstrated promising results. However, these approaches are not able to dynamically collect additional diagnostic information such as incident related logs, metrics or databases, severely restricting their ability to diagnose root causes. In this work, we explore the use of LLM based agents for RCA to address this limitation. We present a thorough empirical evaluation of a ReAct agent equipped with retrieval tools, on an out-of-distribution dataset of production incidents collected at Microsoft. Results show that ReAct performs competitively with strong retrieval and reasoning baselines, but with highly increased factual accuracy. We then extend this evaluation by incorporating discussions associated with incident reports as additional inputs for the models, which surprisingly does not yield significant performance improvements. Lastly, we conduct a case study with a team at Microsoft to equip the ReAct agent with tools that give it access to external diagnostic services that are used by the team for manual RCA. Our results show how agents can overcome the limitations of prior work, and practical considerations for implementing such a system in practice.
Few-Shot Relation Extraction with Hybrid Visual Evidence
Mar 01, 2024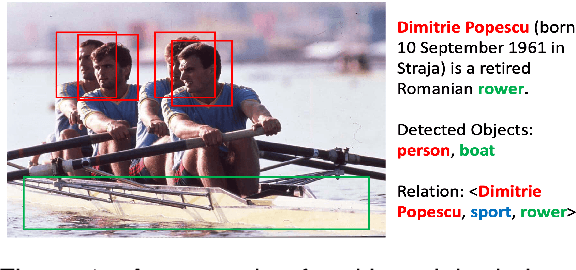

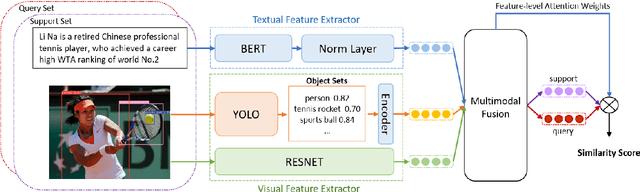

The goal of few-shot relation extraction is to predict relations between name entities in a sentence when only a few labeled instances are available for training. Existing few-shot relation extraction methods focus on uni-modal information such as text only. This reduces performance when there are no clear contexts between the name entities described in text. We propose a multi-modal few-shot relation extraction model (MFS-HVE) that leverages both textual and visual semantic information to learn a multi-modal representation jointly. The MFS-HVE includes semantic feature extractors and multi-modal fusion components. The MFS-HVE semantic feature extractors are developed to extract both textual and visual features. The visual features include global image features and local object features within the image. The MFS-HVE multi-modal fusion unit integrates information from various modalities using image-guided attention, object-guided attention, and hybrid feature attention to fully capture the semantic interaction between visual regions of images and relevant texts. Extensive experiments conducted on two public datasets demonstrate that semantic visual information significantly improves the performance of few-shot relation prediction.
* 16 pages, 5 figures
Adaptive Integrate-and-Fire Time Encoding Machine
Mar 05, 2024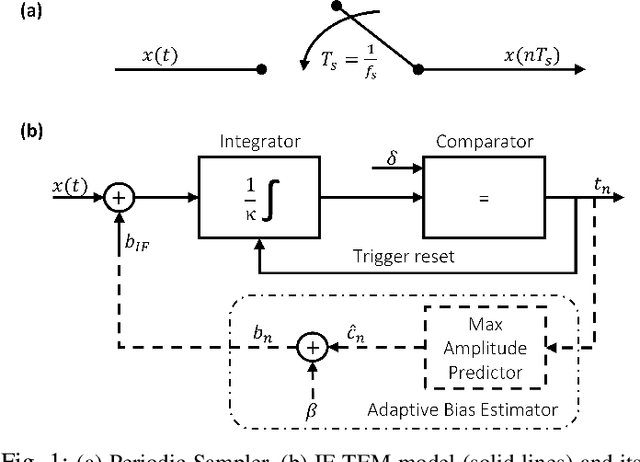
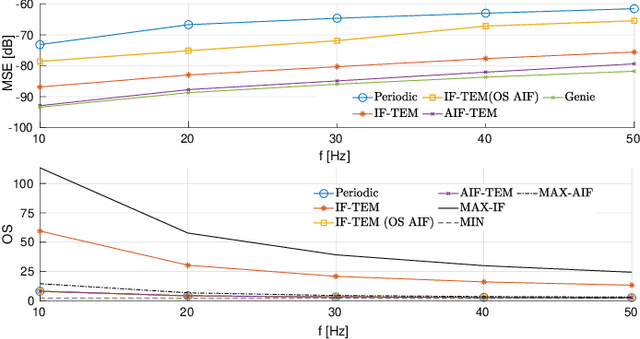
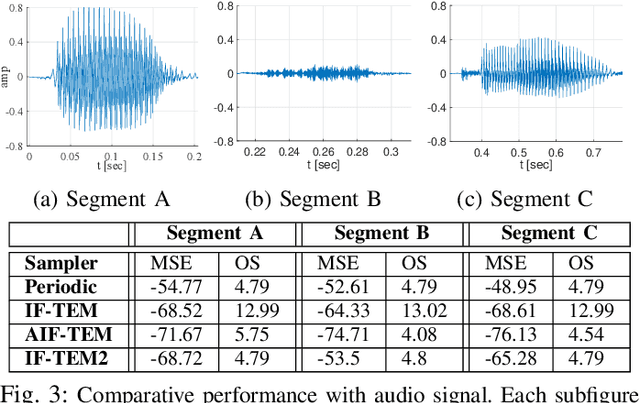
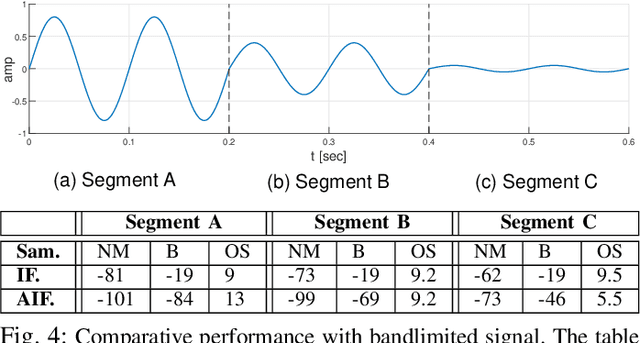
An integrate-and-fire time-encoding machine (IF-TEM) is an effective asynchronous sampler that translates amplitude information into non-uniform time sequences. In this work, we propose a novel Adaptive IF-TEM (AIF-TEM) approach. This design dynamically adjusts the TEM's sensitivity to changes in the input signal's amplitude and frequency in real-time. We provide a comprehensive analysis of AIF-TEM's oversampling and distortion properties. By the adaptive adjustments, AIF-TEM as we show can achieve significant performance improvements in practical finite regime, in terms of sampling rate-distortion. We demonstrate empirically that in the scenarios tested AIF-TEM outperforms classical IF-TEM and traditional Nyquist (i.e., periodic) sampling methods for band-limited signals. In terms of Mean Square Error (MSE), the reduction reaches at least 12dB (fixing the oversampling rate).