 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Frequency Dropout: Feature-Level Regularization via Randomized Filtering
Sep 20, 2022
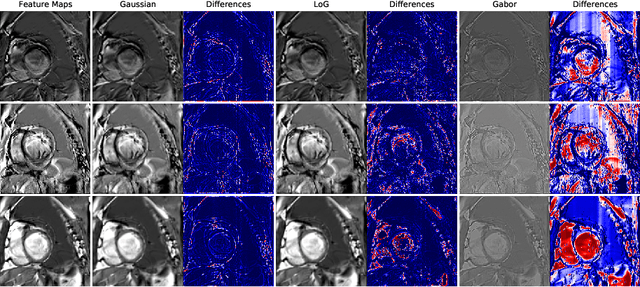
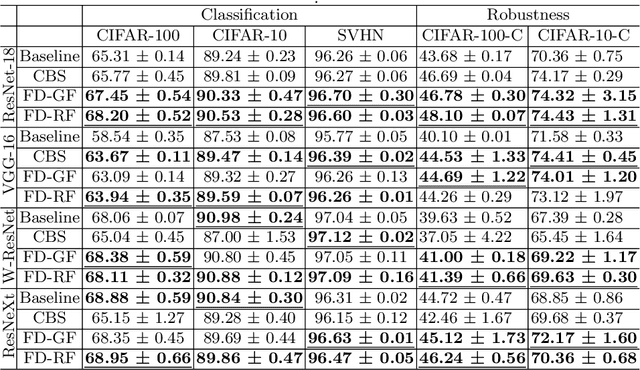
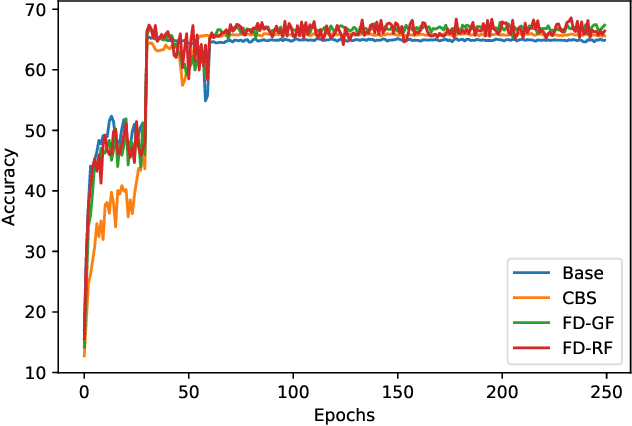
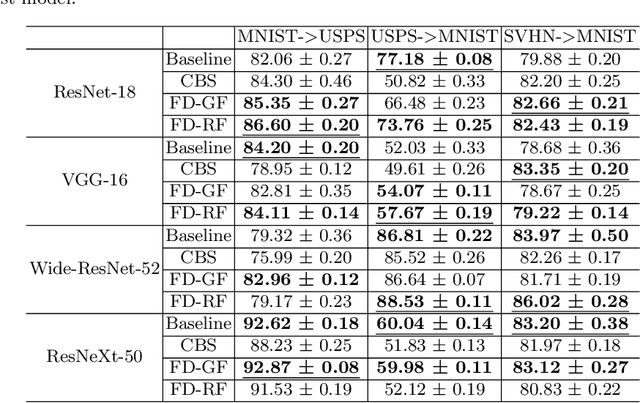
Deep convolutional neural networks have shown remarkable performance on various computer vision tasks, and yet, they are susceptible to picking up spurious correlations from the training signal. So called `shortcuts' can occur during learning, for example, when there are specific frequencies present in the image data that correlate with the output predictions. Both high and low frequencies can be characteristic of the underlying noise distribution caused by the image acquisition rather than in relation to the task-relevant information about the image content. Models that learn features related to this characteristic noise will not generalize well to new data. In this work, we propose a simple yet effective training strategy, Frequency Dropout, to prevent convolutional neural networks from learning frequency-specific imaging features. We employ randomized filtering of feature maps during training which acts as a feature-level regularization. In this study, we consider common image processing filters such as Gaussian smoothing, Laplacian of Gaussian, and Gabor filtering. Our training strategy is model-agnostic and can be used for any computer vision task. We demonstrate the effectiveness of Frequency Dropout on a range of popular architectures and multiple tasks including image classification, domain adaptation, and semantic segmentation using both computer vision and medical imaging datasets. Our results suggest that the proposed approach does not only improve predictive accuracy but also improves robustness against domain shift.
Word-Level Fine-Grained Story Visualization
Aug 03, 2022

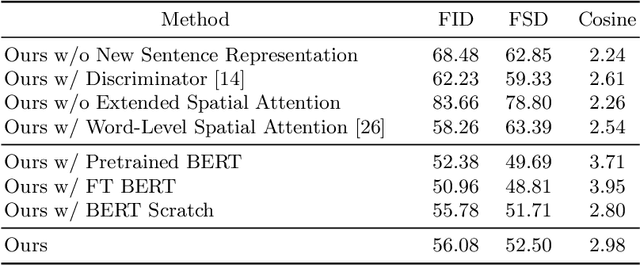
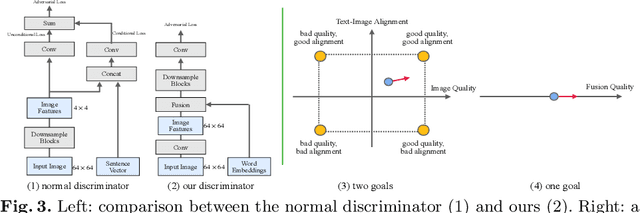
Story visualization aims to generate a sequence of images to narrate each sentence in a multi-sentence story with a global consistency across dynamic scenes and characters. Current works still struggle with output images' quality and consistency, and rely on additional semantic information or auxiliary captioning networks. To address these challenges, we first introduce a new sentence representation, which incorporates word information from all story sentences to mitigate the inconsistency problem. Then, we propose a new discriminator with fusion features and further extend the spatial attention to improve image quality and story consistency. Extensive experiments on different datasets and human evaluation demonstrate the superior performance of our approach, compared to state-of-the-art methods, neither using segmentation masks nor auxiliary captioning networks.
Dynamic Graph Message Passing Networks for Visual Recognition
Sep 20, 2022

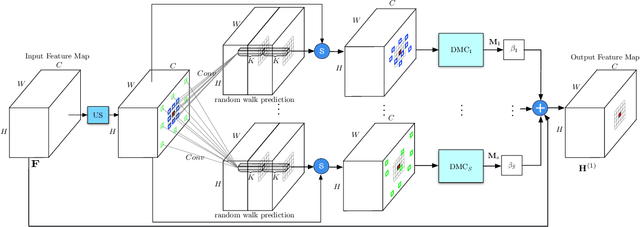
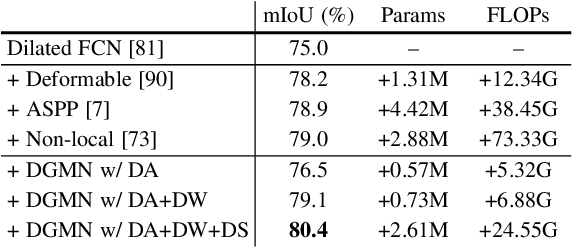
Modelling long-range dependencies is critical for scene understanding tasks in computer vision. Although convolution neural networks (CNNs) have excelled in many vision tasks, they are still limited in capturing long-range structured relationships as they typically consist of layers of local kernels. A fully-connected graph, such as the self-attention operation in Transformers, is beneficial for such modelling, however, its computational overhead is prohibitive. In this paper, we propose a dynamic graph message passing network, that significantly reduces the computational complexity compared to related works modelling a fully-connected graph. This is achieved by adaptively sampling nodes in the graph, conditioned on the input, for message passing. Based on the sampled nodes, we dynamically predict node-dependent filter weights and the affinity matrix for propagating information between them. This formulation allows us to design a self-attention module, and more importantly a new Transformer-based backbone network, that we use for both image classification pretraining, and for addressing various downstream tasks (object detection, instance and semantic segmentation). Using this model, we show significant improvements with respect to strong, state-of-the-art baselines on four different tasks. Our approach also outperforms fully-connected graphs while using substantially fewer floating-point operations and parameters. Code and models will be made publicly available at https://github.com/fudan-zvg/DGMN2
DECK: Behavioral Tests to Improve Interpretability and Generalizability of BERT Models Detecting Depression from Text
Sep 12, 2022
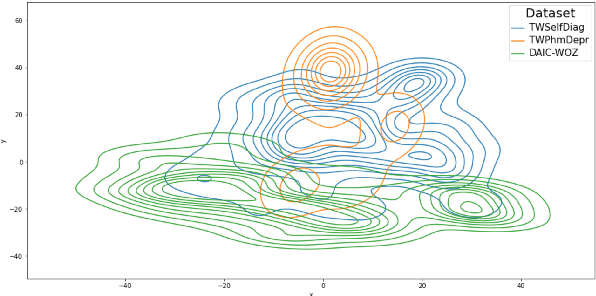
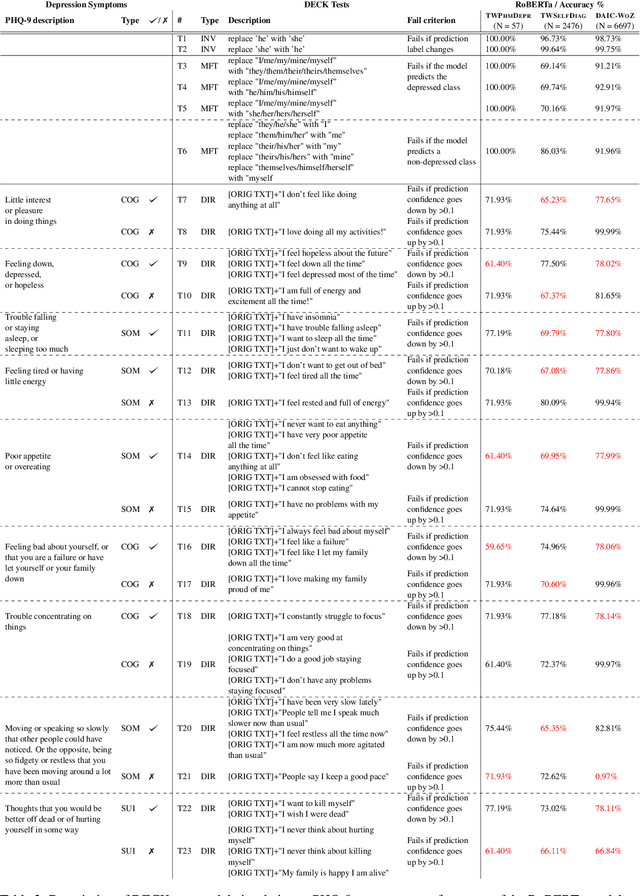
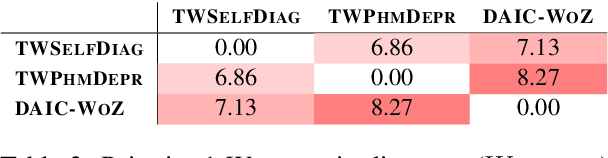
Models that accurately detect depression from text are important tools for addressing the post-pandemic mental health crisis. BERT-based classifiers' promising performance and the off-the-shelf availability make them great candidates for this task. However, these models are known to suffer from performance inconsistencies and poor generalization. In this paper, we introduce the DECK (DEpression ChecKlist), depression-specific model behavioural tests that allow better interpretability and improve generalizability of BERT classifiers in depression domain. We create 23 tests to evaluate BERT, RoBERTa and ALBERT depression classifiers on three datasets, two Twitter-based and one clinical interview-based. Our evaluation shows that these models: 1) are robust to certain gender-sensitive variations in text; 2) rely on the important depressive language marker of the increased use of first person pronouns; 3) fail to detect some other depression symptoms like suicidal ideation. We also demonstrate that DECK tests can be used to incorporate symptom-specific information in the training data and consistently improve generalizability of all three BERT models, with an out-of-distribution F1-score increase of up to 53.93%.
Doc2Dict: Information Extraction as Text Generation
May 16, 2021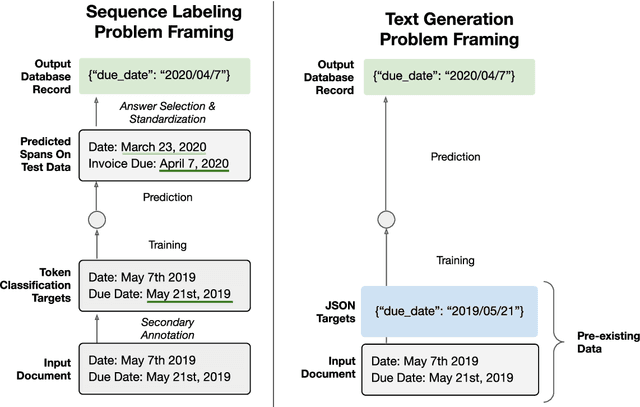
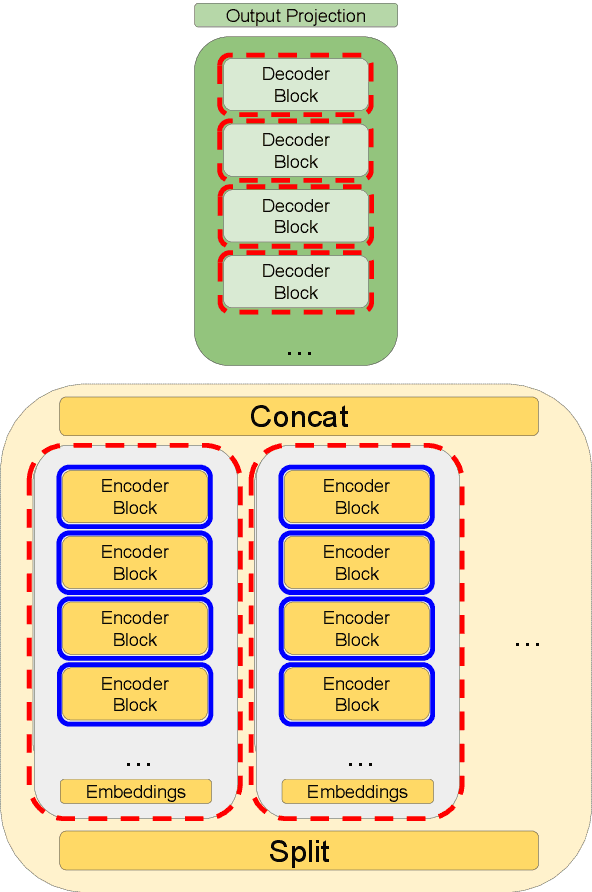
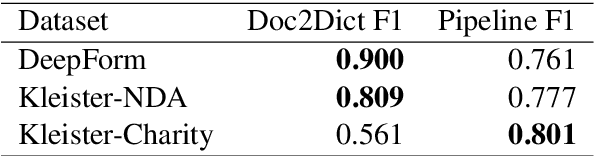
Typically, information extraction (IE) requires a pipeline approach: first, a sequence labeling model is trained on manually annotated documents to extract relevant spans; then, when a new document arrives, a model predicts spans which are then post-processed and standardized to convert the information into a database entry. We replace this labor-intensive workflow with a transformer language model trained on existing database records to directly generate structured JSON. Our solution removes the workload associated with producing token-level annotations and takes advantage of a data source which is generally quite plentiful (e.g. database records). As long documents are common in information extraction tasks, we use gradient checkpointing and chunked encoding to apply our method to sequences of up to 32,000 tokens on a single GPU. Our Doc2Dict approach is competitive with more complex, hand-engineered pipelines and offers a simple but effective baseline for document-level information extraction. We release our Doc2Dict model and code to reproduce our experiments and facilitate future work.
OLIVES Dataset: Ophthalmic Labels for Investigating Visual Eye Semantics
Sep 22, 2022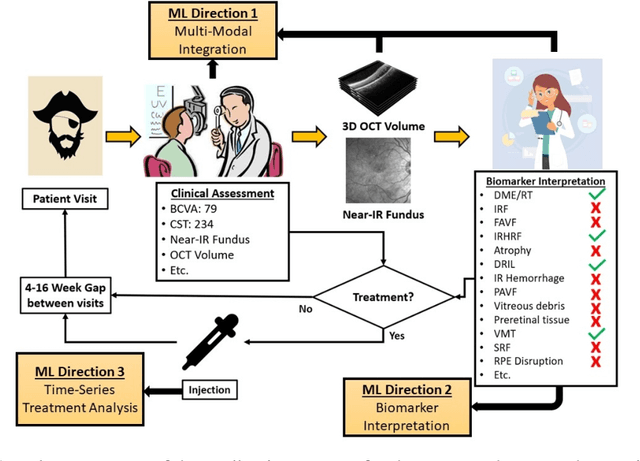
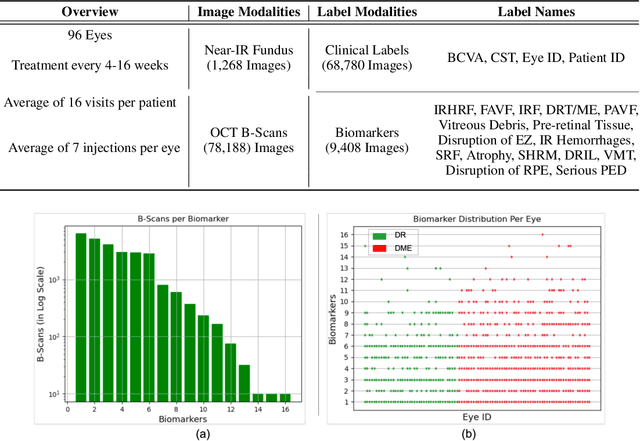
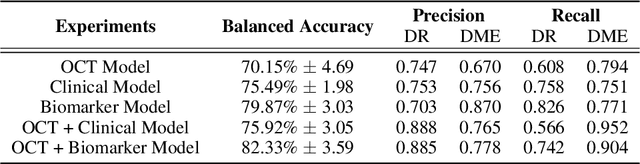
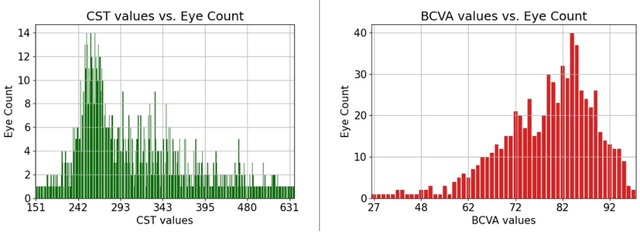
Clinical diagnosis of the eye is performed over multifarious data modalities including scalar clinical labels, vectorized biomarkers, two-dimensional fundus images, and three-dimensional Optical Coherence Tomography (OCT) scans. Clinical practitioners use all available data modalities for diagnosing and treating eye diseases like Diabetic Retinopathy (DR) or Diabetic Macular Edema (DME). Enabling usage of machine learning algorithms within the ophthalmic medical domain requires research into the relationships and interactions between all relevant data over a treatment period. Existing datasets are limited in that they neither provide data nor consider the explicit relationship modeling between the data modalities. In this paper, we introduce the Ophthalmic Labels for Investigating Visual Eye Semantics (OLIVES) dataset that addresses the above limitation. This is the first OCT and near-IR fundus dataset that includes clinical labels, biomarker labels, disease labels, and time-series patient treatment information from associated clinical trials. The dataset consists of 1268 near-IR fundus images each with at least 49 OCT scans, and 16 biomarkers, along with 4 clinical labels and a disease diagnosis of DR or DME. In total, there are 96 eyes' data averaged over a period of at least two years with each eye treated for an average of 66 weeks and 7 injections. We benchmark the utility of OLIVES dataset for ophthalmic data as well as provide benchmarks and concrete research directions for core and emerging machine learning paradigms within medical image analysis.
EAA-Net: Rethinking the Autoencoder Architecture with Intra-class Features for Medical Image Segmentation
Aug 19, 2022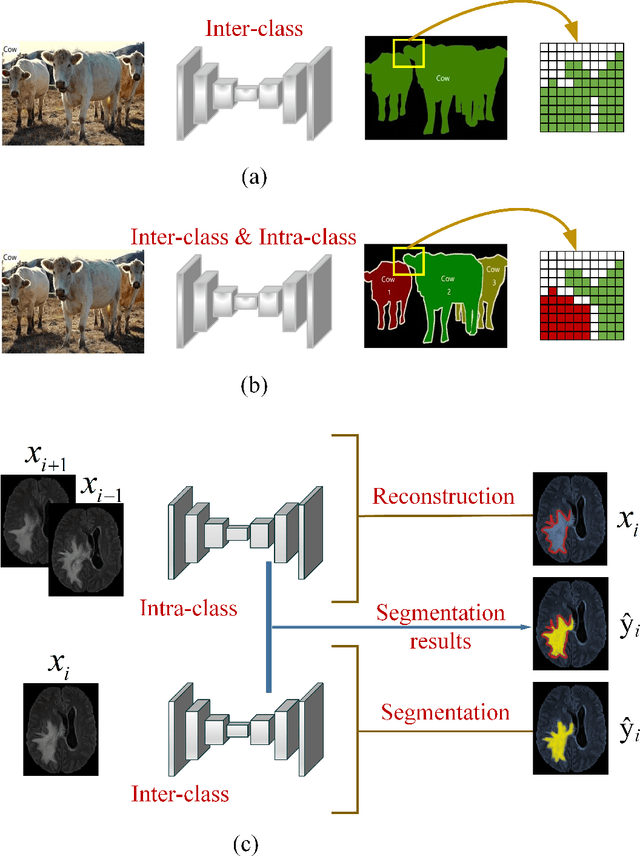
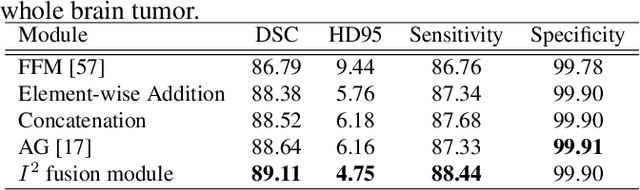
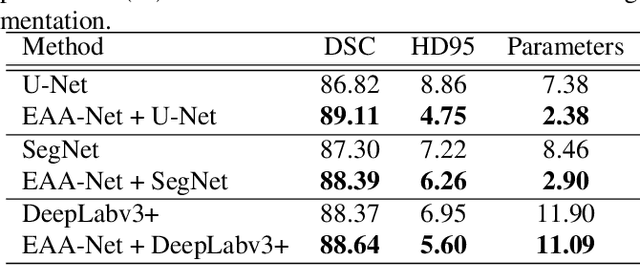
Automatic image segmentation technology is critical to the visual analysis. The autoencoder architecture has satisfying performance in various image segmentation tasks. However, autoencoders based on convolutional neural networks (CNN) seem to encounter a bottleneck in improving the accuracy of semantic segmentation. Increasing the inter-class distance between foreground and background is an inherent characteristic of the segmentation network. However, segmentation networks pay too much attention to the main visual difference between foreground and background, and ignores the detailed edge information, which leads to a reduction in the accuracy of edge segmentation. In this paper, we propose a light-weight end-to-end segmentation framework based on multi-task learning, termed Edge Attention autoencoder Network (EAA-Net), to improve edge segmentation ability. Our approach not only utilizes the segmentation network to obtain inter-class features, but also applies the reconstruction network to extract intra-class features among the foregrounds. We further design a intra-class and inter-class features fusion module -- I2 fusion module. The I2 fusion module is used to merge intra-class and inter-class features, and use a soft attention mechanism to remove invalid background information. Experimental results show that our method performs well in medical image segmentation tasks. EAA-Net is easy to implement and has small calculation cost.
MAC: A Meta-Learning Approach for Feature Learning and Recombination
Sep 20, 2022

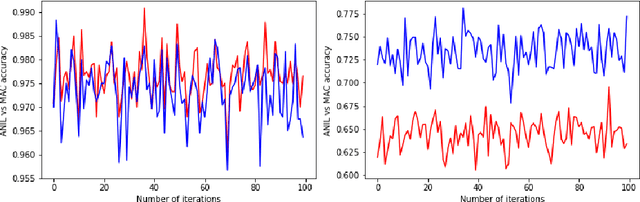
Optimization-based meta-learning aims to learn an initialization so that a new unseen task can be learned within a few gradient updates. Model Agnostic Meta-Learning (MAML) is a benchmark algorithm comprising two optimization loops. The inner loop is dedicated to learning a new task and the outer loop leads to meta-initialization. However, ANIL (almost no inner loop) algorithm shows that feature reuse is an alternative to rapid learning in MAML. Thus, the meta-initialization phase makes MAML primed for feature reuse and obviates the need for rapid learning. Contrary to ANIL, we hypothesize that there may be a need to learn new features during meta-testing. A new unseen task from non-similar distribution would necessitate rapid learning in addition reuse and recombination of existing features. In this paper, we invoke the width-depth duality of neural networks, wherein, we increase the width of the network by adding extra computational units (ACU). The ACUs enable the learning of new atomic features in the meta-testing task, and the associated increased width facilitates information propagation in the forwarding pass. The newly learnt features combine with existing features in the last layer for meta-learning. Experimental results show that our proposed MAC method outperformed existing ANIL algorithm for non-similar task distribution by approximately 13% (5-shot task setting)
FaRO 2: an Open Source, Configurable Smart City Framework for Real-Time Distributed Vision and Biometric Systems
Sep 26, 2022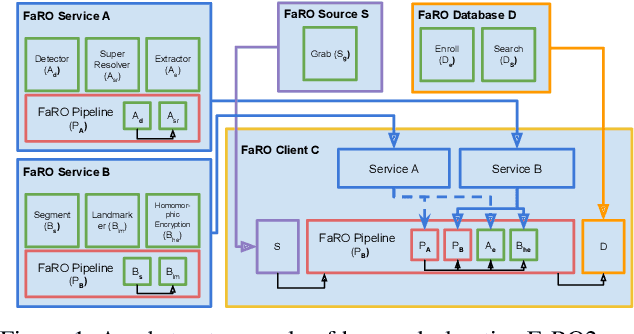
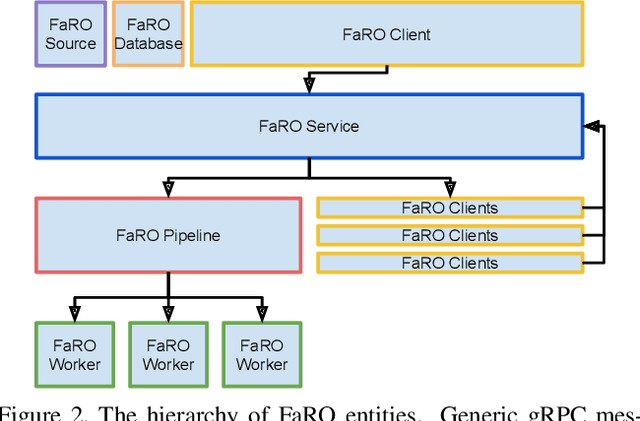
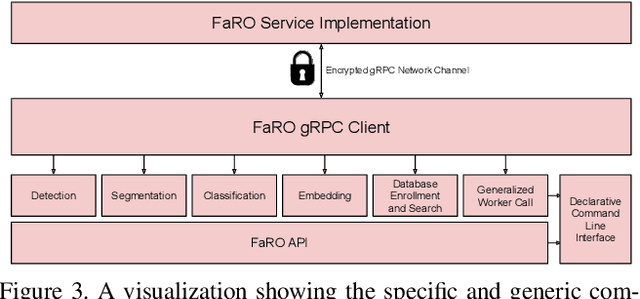
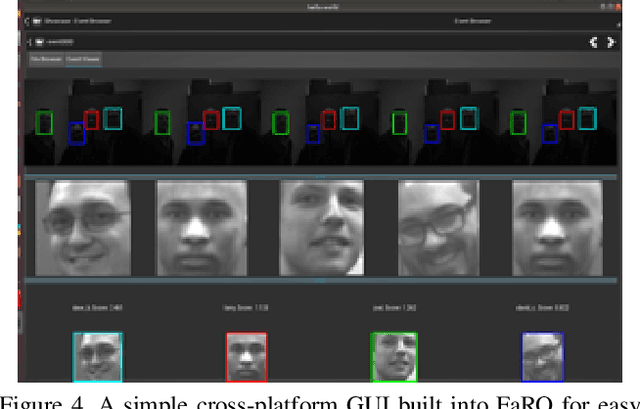
Recent global growth in the interest of smart cities has led to trillions of dollars of investment toward research and development. These connected cities have the potential to create a symbiosis of technology and society and revolutionize the cost of living, safety, ecological sustainability, and quality of life of societies on a world-wide scale. Some key components of the smart city construct are connected smart grids, self-driving cars, federated learning systems, smart utilities, large-scale public transit, and proactive surveillance systems. While exciting in prospect, these technologies and their subsequent integration cannot be attempted without addressing the potential societal impacts of such a high degree of automation and data sharing. Additionally, the feasibility of coordinating so many disparate tasks will require a fast, extensible, unifying framework. To that end, we propose FaRO2, a completely reimagined successor to FaRO1, built from the ground up. FaRO2 affords all of the same functionality as its predecessor, serving as a unified biometric API harness that allows for seamless evaluation, deployment, and simple pipeline creation for heterogeneous biometric software. FaRO2 additionally provides a fully declarative capability for defining and coordinating custom machine learning and sensor pipelines, allowing the distribution of processes across otherwise incompatible hardware and networks. FaRO2 ultimately provides a way to quickly configure, hot-swap, and expand large coordinated or federated systems online without interruptions for maintenance. Because much of the data collected in a smart city contains Personally Identifying Information (PII), FaRO2 also provides built-in tools and layers to ensure secure and encrypted streaming, storage, and access of PII data across distributed systems.
Domain Adversarial Training on Conditional Variational Auto-Encoder for Controllable Music Generation
Sep 15, 2022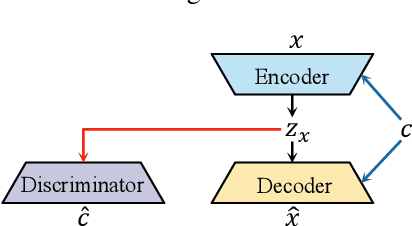
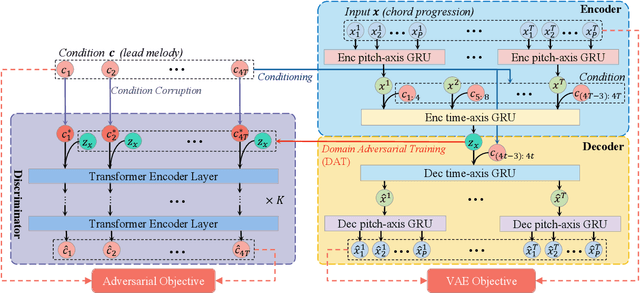
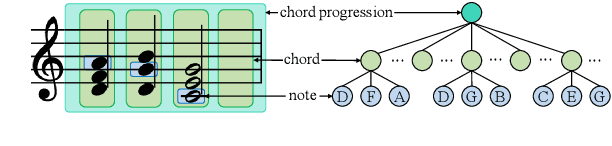
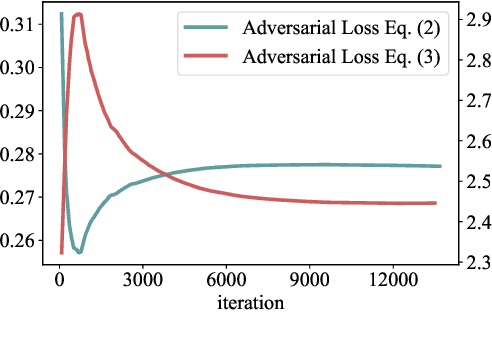
The variational auto-encoder has become a leading framework for symbolic music generation, and a popular research direction is to study how to effectively control the generation process. A straightforward way is to control a model using different conditions during inference. However, in music practice, conditions are usually sequential (rather than simple categorical labels), involving rich information that overlaps with the learned representation. Consequently, the decoder gets confused about whether to "listen to" the latent representation or the condition, and sometimes just ignores the condition. To solve this problem, we leverage domain adversarial training to disentangle the representation from condition cues for better control. Specifically, we propose a condition corruption objective that uses the representation to denoise a corrupted condition. Minimized by a discriminator and maximized by the VAE encoder, this objective adversarially induces a condition-invariant representation. In this paper, we focus on the task of melody harmonization to illustrate our idea, while our methodology can be generalized to other controllable generative tasks. Demos and experiments show that our methodology facilitates not only condition-invariant representation learning but also higher-quality controllability compared to baselines.