 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Dynamic Network Sampling for Community Detection
Aug 29, 2022

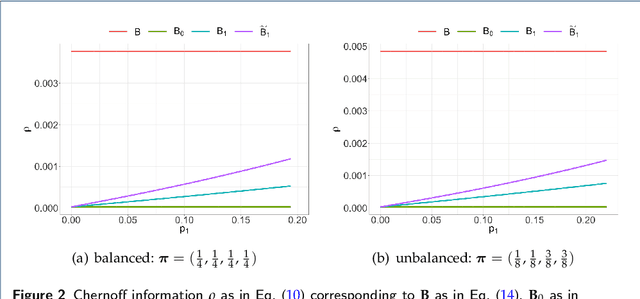
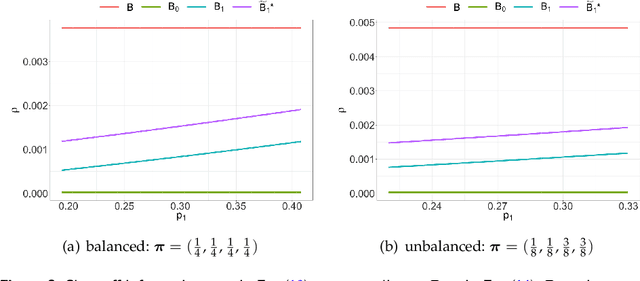
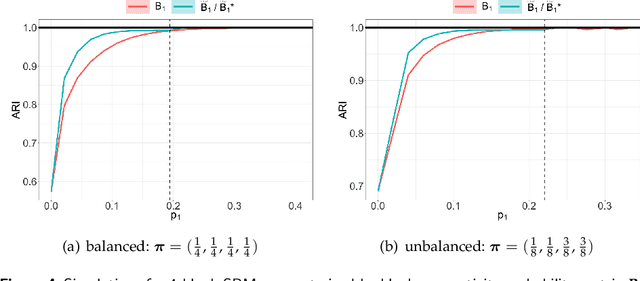
We propose a dynamic network sampling scheme to optimize block recovery for stochastic blockmodel (SBM) in the case where it is prohibitively expensive to observe the entire graph. Theoretically, we provide justification of our proposed Chernoff-optimal dynamic sampling scheme via the Chernoff information. Practically, we evaluate the performance, in terms of block recovery, of our method on several real datasets from different domains. Both theoretically and practically results suggest that our method can identify vertices that have the most impact on block structure so that one can only check whether there are edges between them to save significant resources but still recover the block structure.
SkIn: Skimming-Intensive Long-Text Classification Based on BERT and Application to Medical Corpus
Sep 13, 2022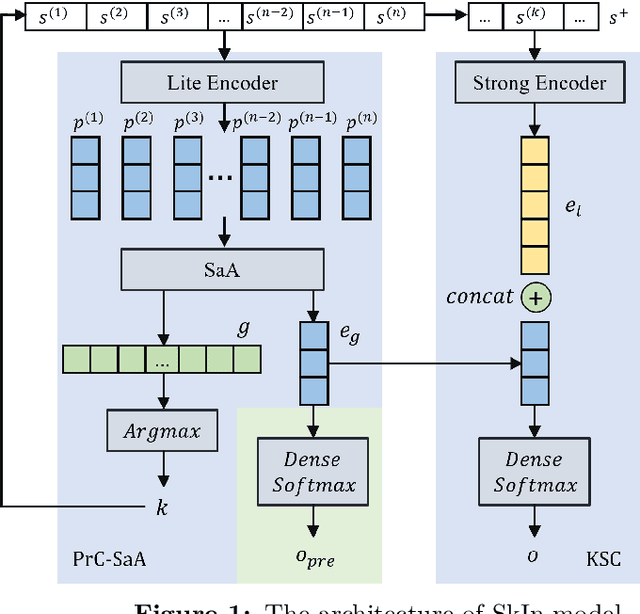
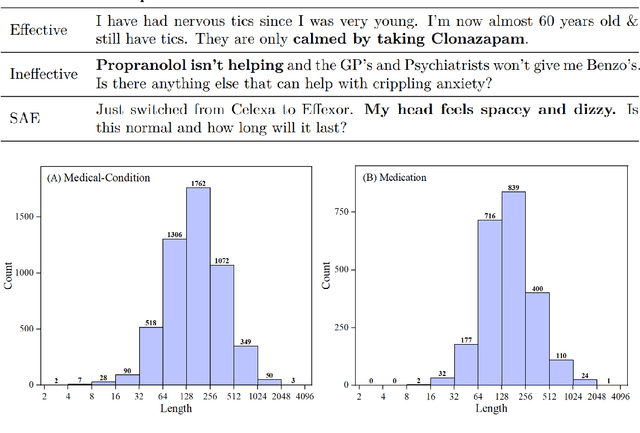
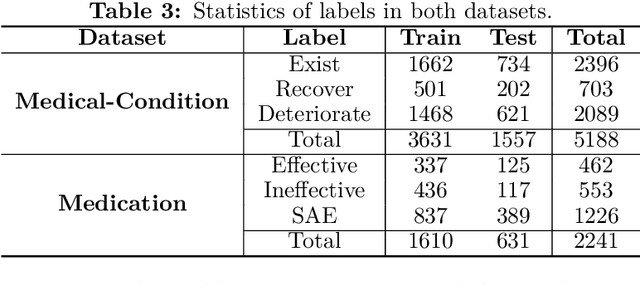
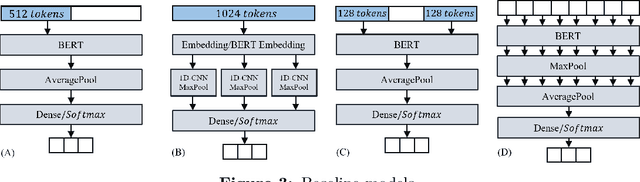
BERT is a widely used pre-trained model in natural language processing. However, because its time and space requirements increase with a quadratic level of the text length, the BERT model is difficult to use directly on the long-text corpus. The collected text data is usually quite long in some fields, such as health care. Therefore, to apply the pre-trained language knowledge of BERT to long text, in this paper, imitating the skimming-intensive reading method used by humans when reading a long paragraph, the Skimming-Intensive Model (SkIn) is proposed. It can dynamically select the critical information in the text so that the length of the input into the BERT-Base model is significantly reduced, which can effectively save the cost of the classification algorithm. Experiments show that the SkIn method has achieved better results than the baselines on long-text classification datasets in the medical field, while its time and space requirements increase linearly with the text length, alleviating the time and space overflow problem of BERT on long-text data.
Pure Exploration in Multi-armed Bandits with Graph Side Information
Aug 02, 2021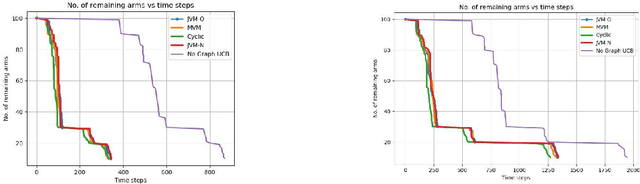
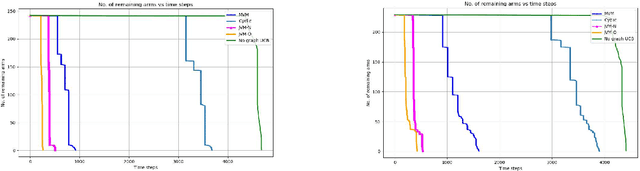
We study pure exploration in multi-armed bandits with graph side-information. In particular, we consider the best arm (and near-best arm) identification problem in the fixed confidence setting under the assumption that the arm rewards are smooth with respect to a given arbitrary graph. This captures a range of real world pure-exploration scenarios where one often has information about the similarity of the options or actions under consideration. We propose a novel algorithm GRUB (GRaph based UcB) for this problem and provide a theoretical characterization of its performance that elicits the benefit of the graph-side information. We complement our theory with experimental results that show that capitalizing on available graph side information yields significant improvements over pure exploration methods that are unable to use this information.
ITSA: An Information-Theoretic Approach to Automatic Shortcut Avoidance and Domain Generalization in Stereo Matching Networks
Jan 06, 2022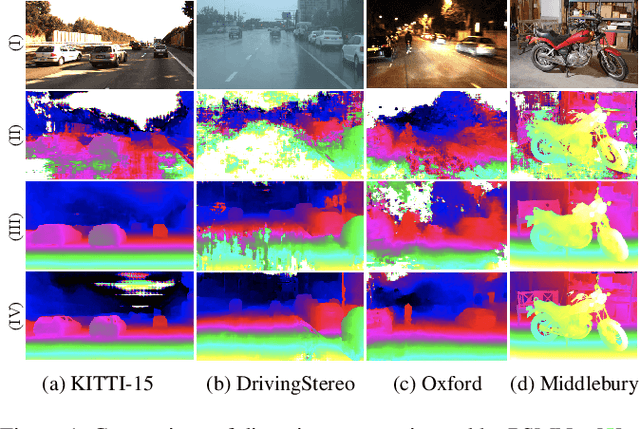

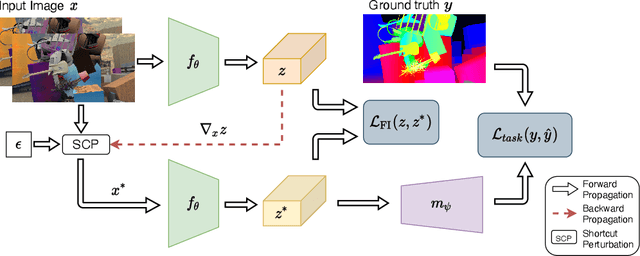
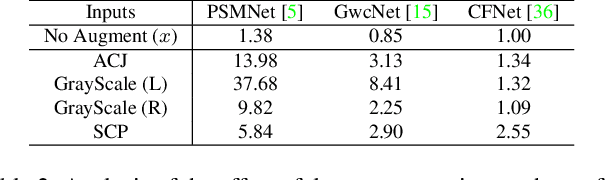
State-of-the-art stereo matching networks trained only on synthetic data often fail to generalize to more challenging real data domains. In this paper, we attempt to unfold an important factor that hinders the networks from generalizing across domains: through the lens of shortcut learning. We demonstrate that the learning of feature representations in stereo matching networks is heavily influenced by synthetic data artefacts (shortcut attributes). To mitigate this issue, we propose an Information-Theoretic Shortcut Avoidance~(ITSA) approach to automatically restrict shortcut-related information from being encoded into the feature representations. As a result, our proposed method learns robust and shortcut-invariant features by minimizing the sensitivity of latent features to input variations. To avoid the prohibitive computational cost of direct input sensitivity optimization, we propose an effective yet feasible algorithm to achieve robustness. We show that using this method, state-of-the-art stereo matching networks that are trained purely on synthetic data can effectively generalize to challenging and previously unseen real data scenarios. Importantly, the proposed method enhances the robustness of the synthetic trained networks to the point that they outperform their fine-tuned counterparts (on real data) for challenging out-of-domain stereo datasets.
A Guide to Employ Hyperspectral Imaging for Assessing Wheat Quality at Different Stages of Supply Chain in Australia: A Review
Sep 13, 2022


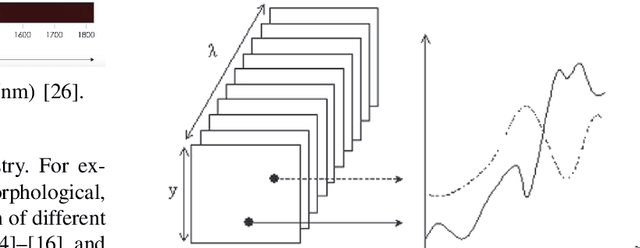
Wheat is one of the major staple crops across the globe. Therefore, it is mandatory to measure, maintain and improve the wheat quality for human consumption. Traditional wheat quality measurement methods are mostly invasive, destructive and limited to small samples of wheat. In a typical supply chain of wheat, there are many receival points where bulk wheat arrives, gets stored and forwarded as per the requirements. In this receival points, the application of traditional quality measurement methods is difficult and often very expensive. Therefore, there is a need for non-invasive, non-destructive real-time methods for wheat quality assessments. One such method that fulfils the above-mentioned criteria is hyperspectral imaging (HSI) for food quality measurement and it can also be applied to bulk samples. In this paper, we have investigated how HSI has been used in the literature for assessing stored wheat quality. So that the required information to implement real-time digital quality assessment methods at the different stages of Australian supply chain can be made available in a single and compact document.
State Definition for Conflict Analysis with Four-valued Logic
Jul 24, 2022
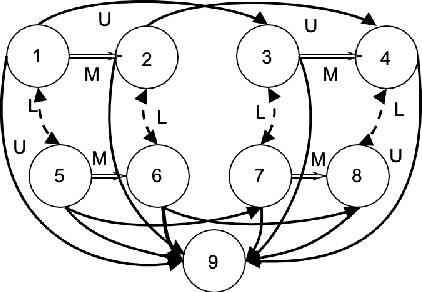
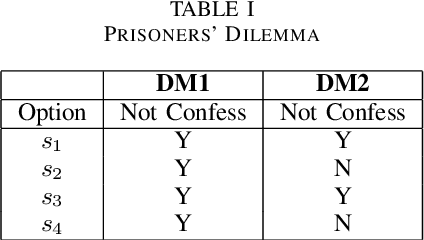
We examined a four-valued logic method for state settings in conflict resolution models. Decision-making models of conflict resolution, such as game theory and graph model for conflict resolution (GMCR), assume the description of a state to be the outcome of a combination of strategies or the consequence of option selection by the decision-makers. However, for a framework to function as a decision-making system, unless a clear definition of the task of placing information out of an infinite world exists, logical consistency cannot be ensured, and thus, the function may be incomputable. The introduction of paraconsistent four-valued logic can prevent incorrect state setting and analysis with insufficient information and provide logical validity to analytical methods that vary the analysis resolution depending on the degree of coarseness of the available information. This study proposes a GMCR stability analysis with state configuration based on Belnap's four-valued logic.
Replay based for Recovering Autonomous Robotic Vehicles from Sensor Deception Attacks
Sep 09, 2022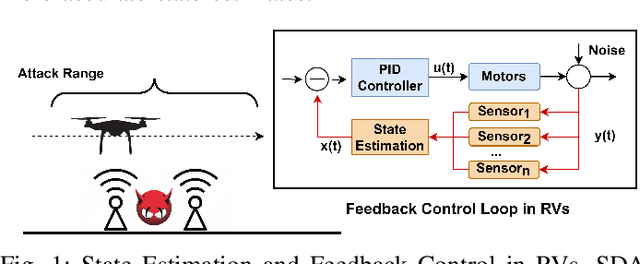
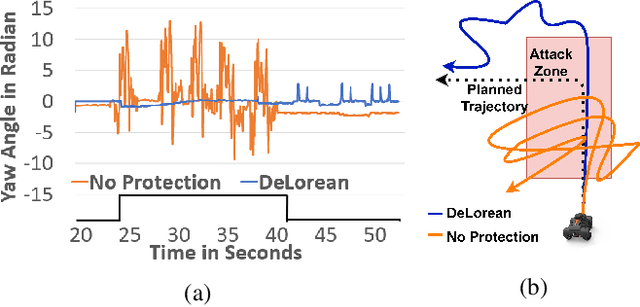
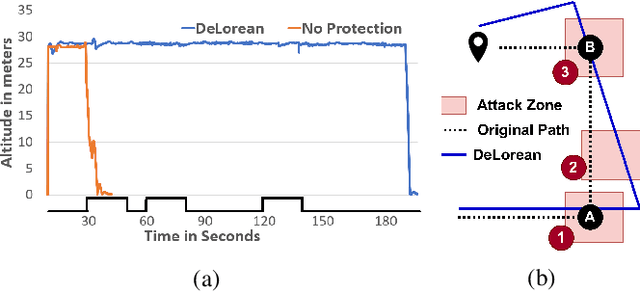
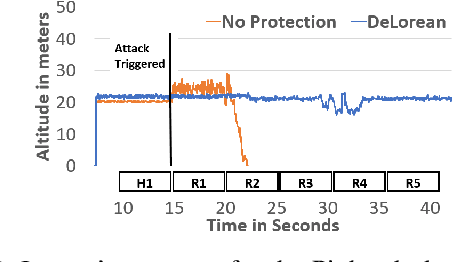
Sensors are crucial for autonomous operation in robotic vehicles (RV). Physical attacks on sensors such as sensor tampering or spoofing can feed erroneous values to RVs through physical channels, which results in mission failures. In this paper, we present DeLorean, a comprehensive diagnosis and recovery framework for securing autonomous RVs from physical attacks. We consider a strong form of physical attack called sensor deception attacks (SDAs), in which the adversary targets multiple sensors of different types simultaneously (even including all sensors). Under SDAs, DeLorean inspects the attack induced errors, identifies the targeted sensors, and prevents the erroneous sensor inputs from being used in RV's feedback control loop. DeLorean replays historic state information in the feedback control loop and recovers the RV from attacks. Our evaluation on four real and two simulated RVs shows that DeLorean can recover RVs from different attacks, and ensure mission success in 94% of the cases (on average), without any crashes. DeLorean incurs low performance, memory and battery overheads.
ActiveNeRF: Learning where to See with Uncertainty Estimation
Sep 18, 2022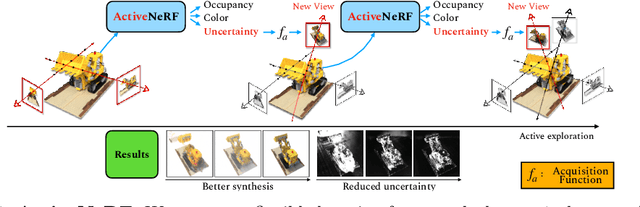
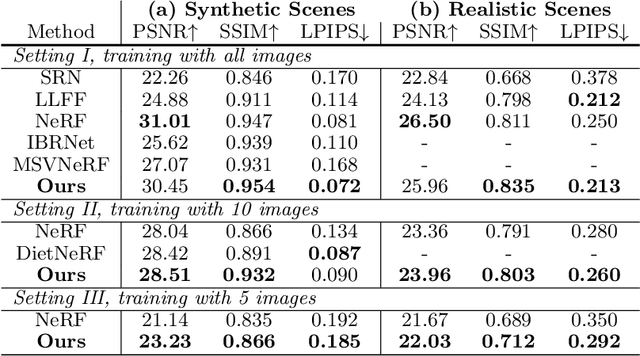

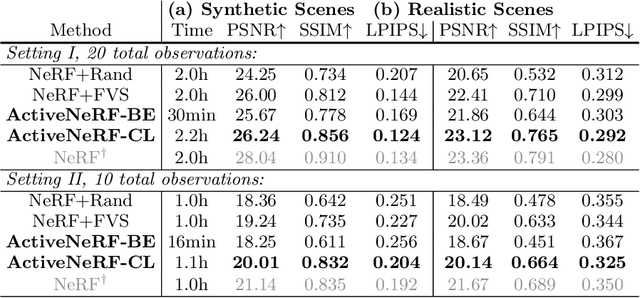
Recently, Neural Radiance Fields (NeRF) has shown promising performances on reconstructing 3D scenes and synthesizing novel views from a sparse set of 2D images. Albeit effective, the performance of NeRF is highly influenced by the quality of training samples. With limited posed images from the scene, NeRF fails to generalize well to novel views and may collapse to trivial solutions in unobserved regions. This makes NeRF impractical under resource-constrained scenarios. In this paper, we present a novel learning framework, ActiveNeRF, aiming to model a 3D scene with a constrained input budget. Specifically, we first incorporate uncertainty estimation into a NeRF model, which ensures robustness under few observations and provides an interpretation of how NeRF understands the scene. On this basis, we propose to supplement the existing training set with newly captured samples based on an active learning scheme. By evaluating the reduction of uncertainty given new inputs, we select the samples that bring the most information gain. In this way, the quality of novel view synthesis can be improved with minimal additional resources. Extensive experiments validate the performance of our model on both realistic and synthetic scenes, especially with scarcer training data. Code will be released at \url{https://github.com/LeapLabTHU/ActiveNeRF}.
ComplETR: Reducing the cost of annotations for object detection in dense scenes with vision transformers
Sep 13, 2022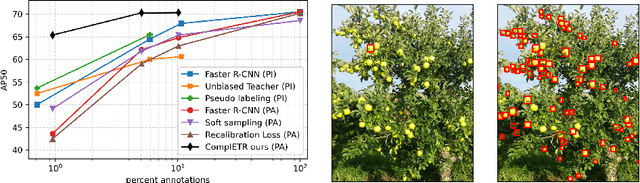
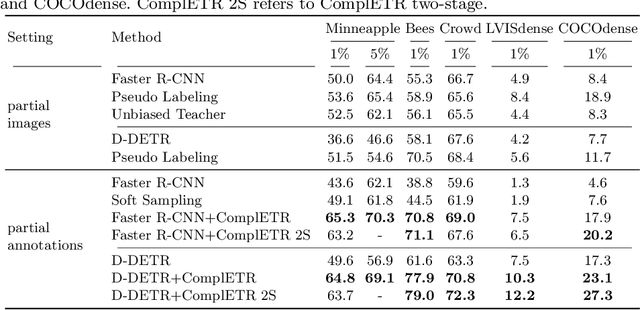
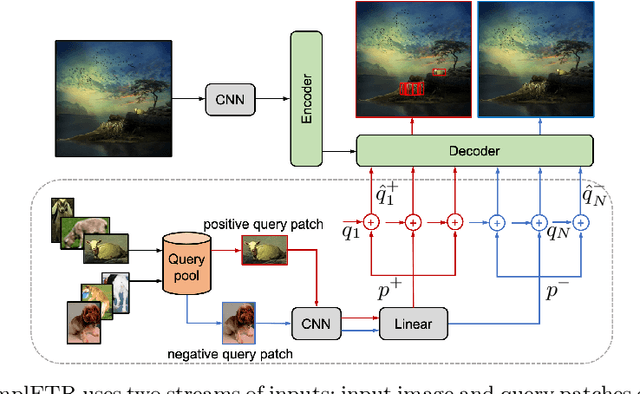
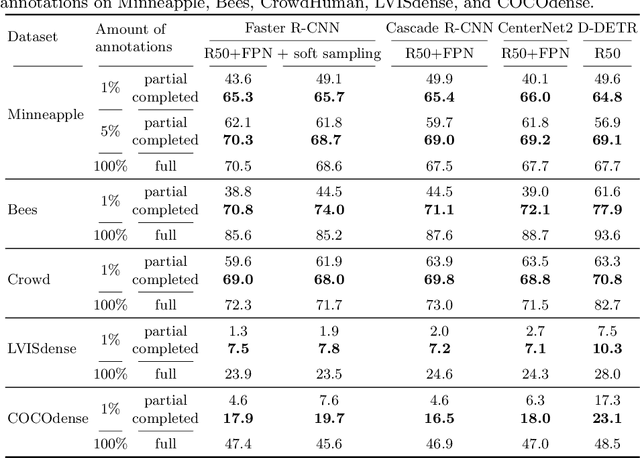
Annotating bounding boxes for object detection is expensive, time-consuming, and error-prone. In this work, we propose a DETR based framework called ComplETR that is designed to explicitly complete missing annotations in partially annotated dense scene datasets. This reduces the need to annotate every object instance in the scene thereby reducing annotation cost. ComplETR augments object queries in DETR decoder with patch information of objects in the image. Combined with a matching loss, it can effectively find objects that are similar to the input patch and complete the missing annotations. We show that our framework outperforms the state-of-the-art methods such as Soft Sampling and Unbiased Teacher by itself, while at the same time can be used in conjunction with these methods to further improve their performance. Our framework is also agnostic to the choice of the downstream object detectors; we show performance improvement for several popular detectors such as Faster R-CNN, Cascade R-CNN, CenterNet2, and Deformable DETR on multiple dense scene datasets.
Weakly Supervised Video Salient Object Detection via Point Supervision
Jul 15, 2022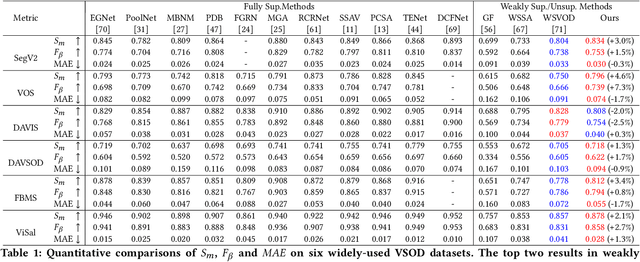
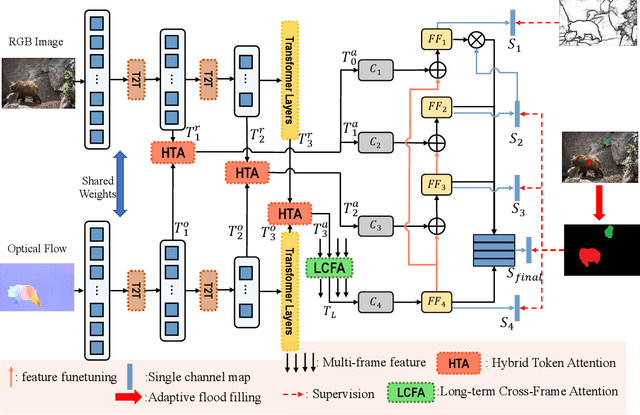
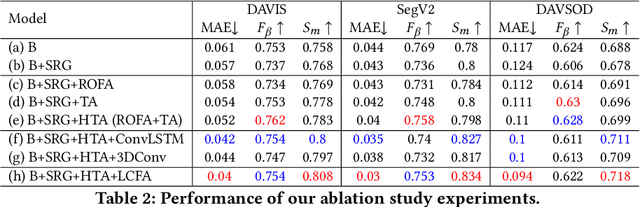
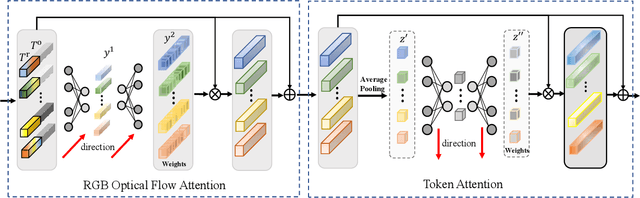
Video salient object detection models trained on pixel-wise dense annotation have achieved excellent performance, yet obtaining pixel-by-pixel annotated datasets is laborious. Several works attempt to use scribble annotations to mitigate this problem, but point supervision as a more labor-saving annotation method (even the most labor-saving method among manual annotation methods for dense prediction), has not been explored. In this paper, we propose a strong baseline model based on point supervision. To infer saliency maps with temporal information, we mine inter-frame complementary information from short-term and long-term perspectives, respectively. Specifically, we propose a hybrid token attention module, which mixes optical flow and image information from orthogonal directions, adaptively highlighting critical optical flow information (channel dimension) and critical token information (spatial dimension). To exploit long-term cues, we develop the Long-term Cross-Frame Attention module (LCFA), which assists the current frame in inferring salient objects based on multi-frame tokens. Furthermore, we label two point-supervised datasets, P-DAVIS and P-DAVSOD, by relabeling the DAVIS and the DAVSOD dataset. Experiments on the six benchmark datasets illustrate our method outperforms the previous state-of-the-art weakly supervised methods and even is comparable with some fully supervised approaches. Source code and datasets are available.