 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Personalized Decision Making -- A Conceptual Introduction
Aug 19, 2022
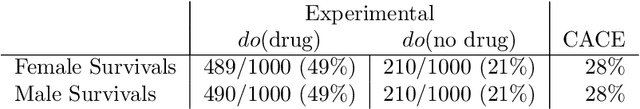
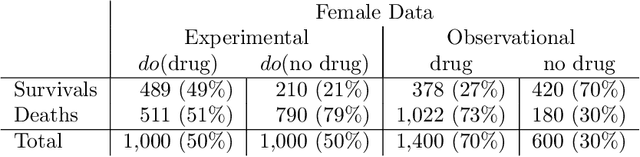
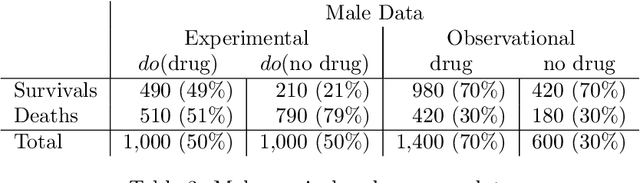
Personalized decision making targets the behavior of a specific individual, while population-based decision making concerns a sub-population resembling that individual. This paper clarifies the distinction between the two and explains why the former leads to more informed decisions. We further show that by combining experimental and observational studies we can obtain valuable information about individual behavior and, consequently, improve decisions over those obtained from experimental studies alone.
Hyperspectral Remote Sensing Benchmark Database for Oil Spill Detection with an Isolation Forest-Guided Unsupervised Detector
Sep 28, 2022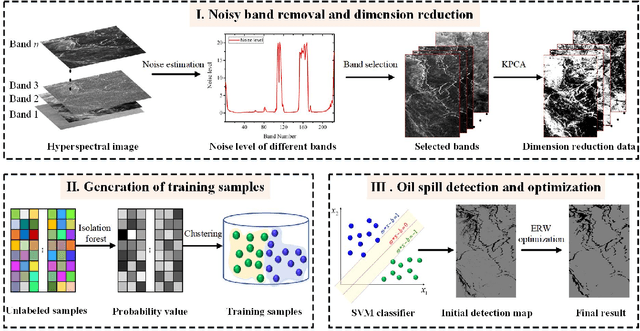
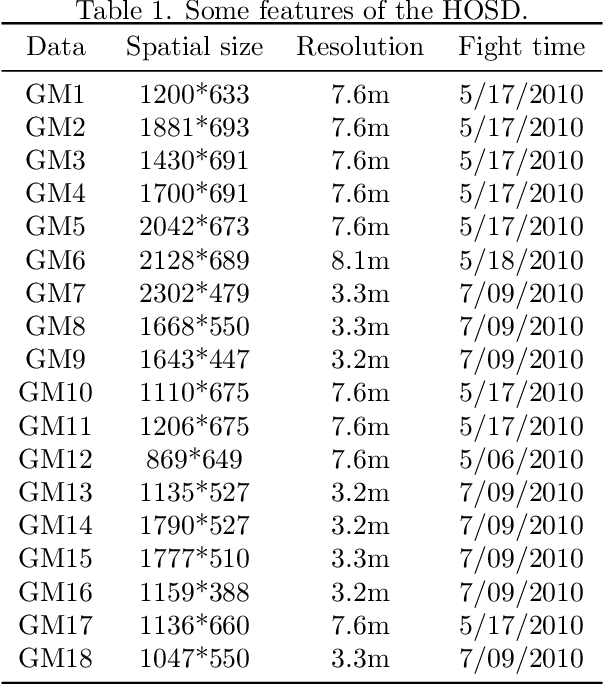
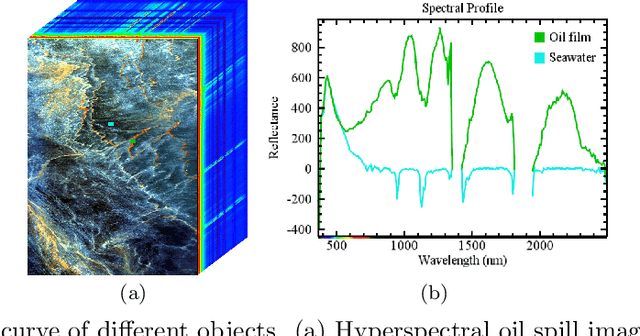
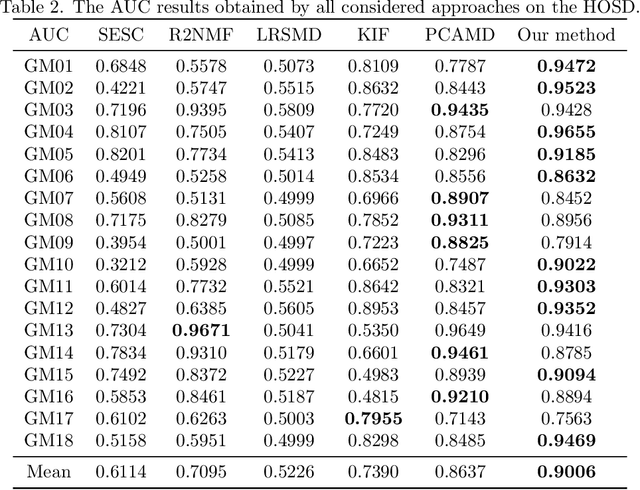
Oil spill detection has attracted increasing attention in recent years since marine oil spill accidents severely affect environments, natural resources, and the lives of coastal inhabitants. Hyperspectral remote sensing images provide rich spectral information which is beneficial for the monitoring of oil spills in complex ocean scenarios. However, most of the existing approaches are based on supervised and semi-supervised frameworks to detect oil spills from hyperspectral images (HSIs), which require a huge amount of effort to annotate a certain number of high-quality training sets. In this study, we make the first attempt to develop an unsupervised oil spill detection method based on isolation forest for HSIs. First, considering that the noise level varies among different bands, a noise variance estimation method is exploited to evaluate the noise level of different bands, and the bands corrupted by severe noise are removed. Second, kernel principal component analysis (KPCA) is employed to reduce the high dimensionality of the HSIs. Then, the probability of each pixel belonging to one of the classes of seawater and oil spills is estimated with the isolation forest, and a set of pseudo-labeled training samples is automatically produced using the clustering algorithm on the detected probability. Finally, an initial detection map can be obtained by performing the support vector machine (SVM) on the dimension-reduced data, and then, the initial detection result is further optimized with the extended random walker (ERW) model so as to improve the detection accuracy of oil spills. Experiments on airborne hyperspectral oil spill data (HOSD) created by ourselves demonstrate that the proposed method obtains superior detection performance with respect to other state-of-the-art detection approaches.
Multi-Scale Attention-based Multiple Instance Learning for Classification of Multi-Gigapixel Histology Images
Sep 07, 2022
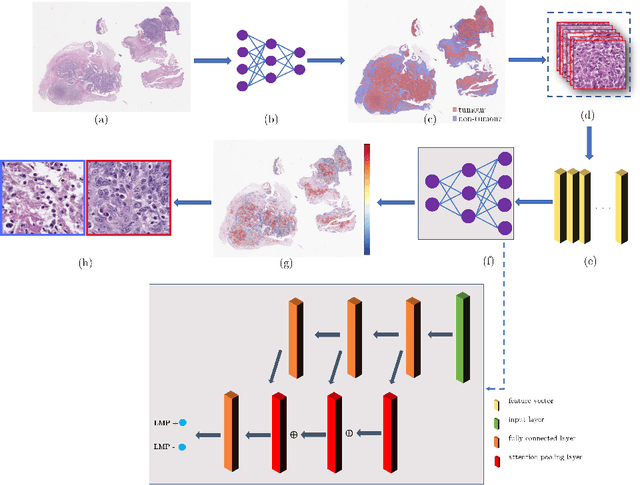
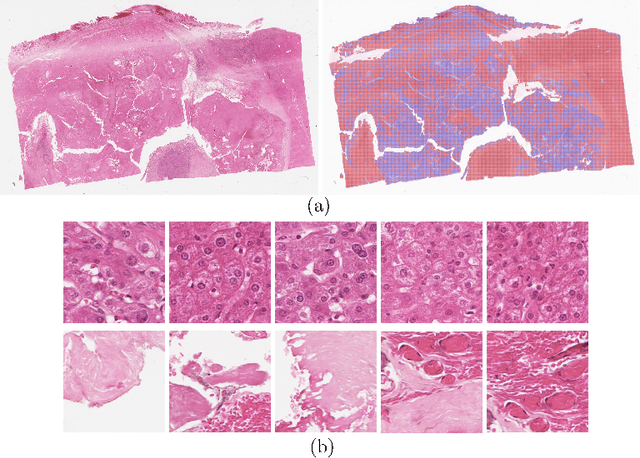

Histology images with multi-gigapixel of resolution yield rich information for cancer diagnosis and prognosis. Most of the time, only slide-level label is available because pixel-wise annotation is labour intensive task. In this paper, we propose a deep learning pipeline for classification in histology images. Using multiple instance learning, we attempt to predict the latent membrane protein 1 (LMP1) status of nasopharyngeal carcinoma (NPC) based on haematoxylin and eosin-stain (H&E) histology images. We utilised attention mechanism with residual connection for our aggregation layers. In our 3-fold cross-validation experiment, we achieved average accuracy, AUC and F1-score 0.936, 0.995 and 0.862, respectively. This method also allows us to examine the model interpretability by visualising attention scores. To the best of our knowledge, this is the first attempt to predict LMP1 status on NPC using deep learning.
Consensus-based Fast and Energy-Efficient Multi-Robot Task Allocation
Sep 21, 2022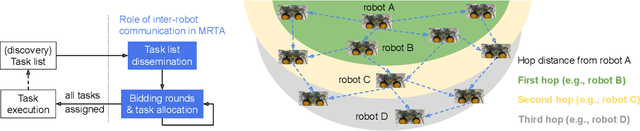
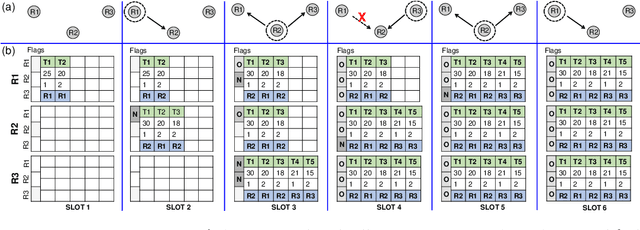
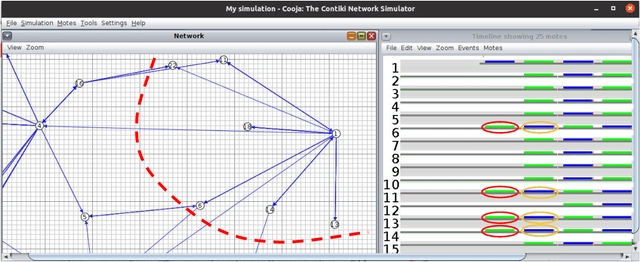
In a multi-robot system, the appropriate allocation of the tasks to the individual robots is a very significant component. The availability of a centralized infrastructure can guarantee an optimal allocation of the tasks. However, in many important scenarios such as search and rescue, exploration, disaster-management, war-field, etc., on-the-fly allocation of the dynamic tasks to the robots in a decentralized fashion is the only possible option. Efficient communication among the robots plays a crucial role in any such decentralized setting. Existing works on distributed Multi-Robot Task Allocation (MRTA) either assume that the network is available or a naive communication paradigm is used. On the contrary, in most of these scenarios, the network infrastructure is either unstable or unavailable and ad-hoc networking is the only resort. Recent developments in synchronous-transmission (ST) based wireless communication protocols are shown to be more efficient than the traditional asynchronous transmission-based protocols in ad hoc networks such as Wireless Sensor Network (WSN)/Internet of Things (IoT) applications. The current work is the first effort that utilizes ST for MRTA. Specifically, we propose an algorithm that efficiently adapts ST-based many-to-many interaction and minimizes the information exchange to reach a consensus for task allocation. We showcase the efficacy of the proposed algorithm through an extensive simulation-based study of its latency and energy-efficiency under different settings.
Doc2Dict: Information Extraction as Text Generation
May 16, 2021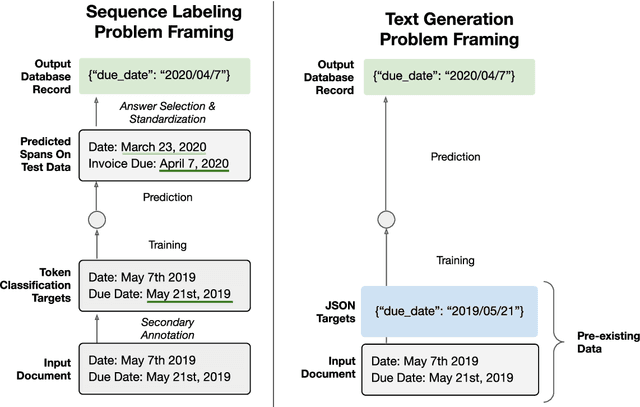
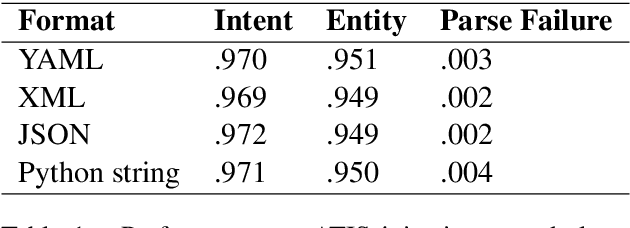
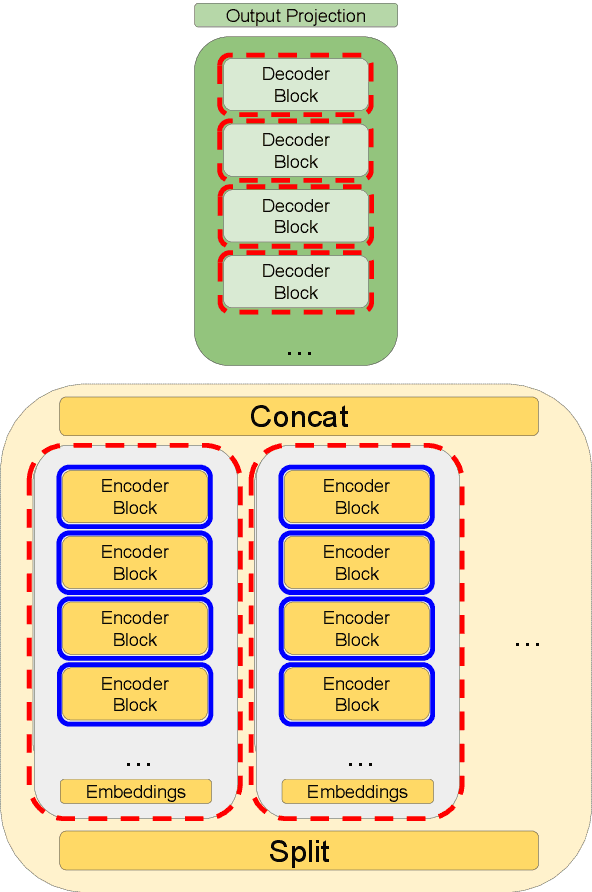
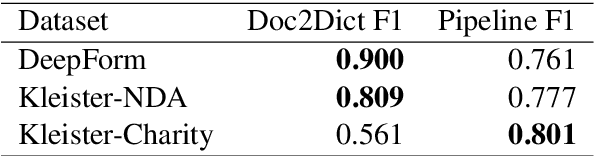
Typically, information extraction (IE) requires a pipeline approach: first, a sequence labeling model is trained on manually annotated documents to extract relevant spans; then, when a new document arrives, a model predicts spans which are then post-processed and standardized to convert the information into a database entry. We replace this labor-intensive workflow with a transformer language model trained on existing database records to directly generate structured JSON. Our solution removes the workload associated with producing token-level annotations and takes advantage of a data source which is generally quite plentiful (e.g. database records). As long documents are common in information extraction tasks, we use gradient checkpointing and chunked encoding to apply our method to sequences of up to 32,000 tokens on a single GPU. Our Doc2Dict approach is competitive with more complex, hand-engineered pipelines and offers a simple but effective baseline for document-level information extraction. We release our Doc2Dict model and code to reproduce our experiments and facilitate future work.
Toward a Generic Mapping Language for Transformations between RDF and Data Interchange Formats
Jul 21, 2022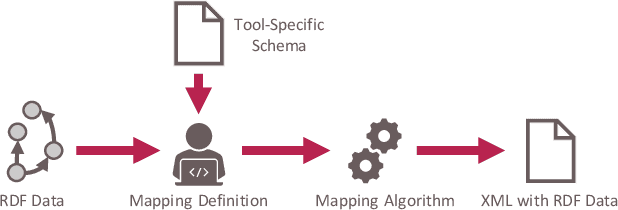

While there exist approaches to integrate heterogeneous data using semantic models, such semantic models can typically not be used by existing software tools. Many software tools - especially in engineering - only have options to import and export data in more established data interchange formats such as XML or JSON. Thus, if an information which is included in a semantic model needs to be used in a such a software tool, automatic approaches for mapping semantic information into an interchange format are needed. We aim to develop a generic mapping approach that allows users to create transformations of semantic information into a data interchange format with an arbitrary structure which can be defined by a user. This mapping approach is currently being elaborated. In this contribution, we report our initial steps targeted to transformations from RDF into XML. At first, a mapping language is introduced which allows to define automated mappings from ontologies to XML. Furthermore, a mapping algorithm capable of executing mappings defined in this language is presented. An evaluation is done with a use case in which engineering information needs to be used in a 3D modeling tool.
I2DFormer: Learning Image to Document Attention for Zero-Shot Image Classification
Sep 21, 2022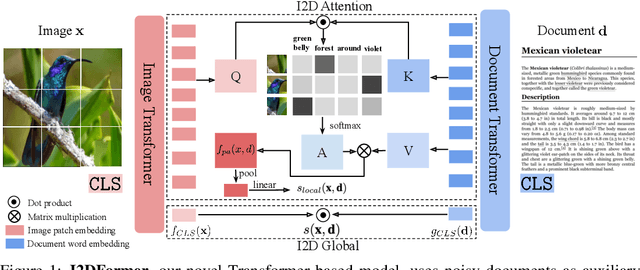
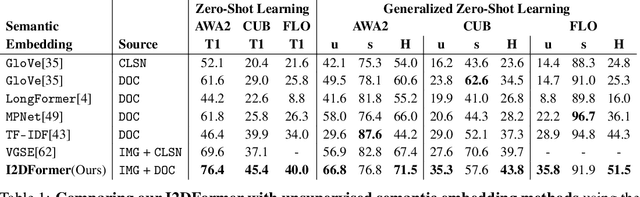
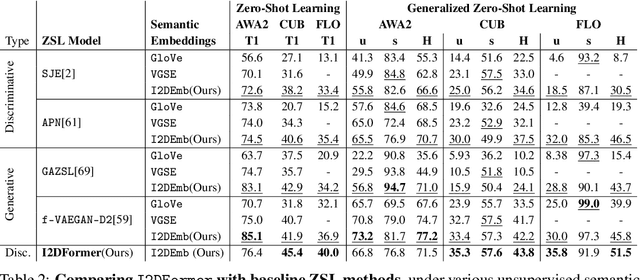

Despite the tremendous progress in zero-shot learning(ZSL), the majority of existing methods still rely on human-annotated attributes, which are difficult to annotate and scale. An unsupervised alternative is to represent each class using the word embedding associated with its semantic class name. However, word embeddings extracted from pre-trained language models do not necessarily capture visual similarities, resulting in poor zero-shot performance. In this work, we argue that online textual documents, e.g., Wikipedia, contain rich visual descriptions about object classes, therefore can be used as powerful unsupervised side information for ZSL. To this end, we propose I2DFormer, a novel transformer-based ZSL framework that jointly learns to encode images and documents by aligning both modalities in a shared embedding space. In order to distill discriminative visual words from noisy documents, we introduce a new cross-modal attention module that learns fine-grained interactions between image patches and document words. Consequently, our I2DFormer not only learns highly discriminative document embeddings that capture visual similarities but also gains the ability to localize visually relevant words in image regions. Quantitatively, we demonstrate that our I2DFormer significantly outperforms previous unsupervised semantic embeddings under both zero-shot and generalized zero-shot learning settings on three public datasets. Qualitatively, we show that our method leads to highly interpretable results where document words can be grounded in the image regions.
Promptagator: Few-shot Dense Retrieval From 8 Examples
Sep 23, 2022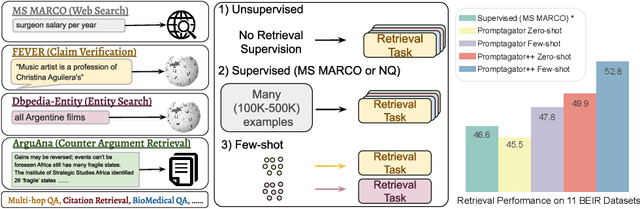
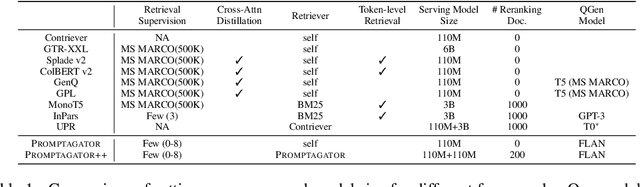
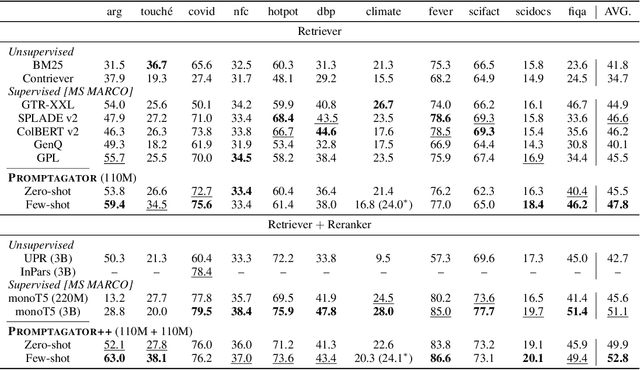
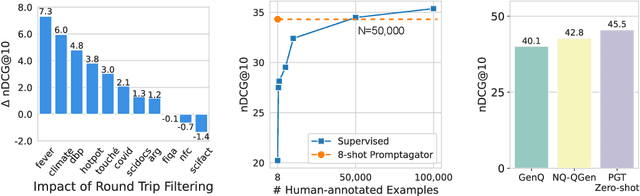
Much recent research on information retrieval has focused on how to transfer from one task (typically with abundant supervised data) to various other tasks where supervision is limited, with the implicit assumption that it is possible to generalize from one task to all the rest. However, this overlooks the fact that there are many diverse and unique retrieval tasks, each targeting different search intents, queries, and search domains. In this paper, we suggest to work on Few-shot Dense Retrieval, a setting where each task comes with a short description and a few examples. To amplify the power of a few examples, we propose Prompt-base Query Generation for Retriever (Promptagator), which leverages large language models (LLM) as a few-shot query generator, and creates task-specific retrievers based on the generated data. Powered by LLM's generalization ability, Promptagator makes it possible to create task-specific end-to-end retrievers solely based on a few examples {without} using Natural Questions or MS MARCO to train %question generators or dual encoders. Surprisingly, LLM prompting with no more than 8 examples allows dual encoders to outperform heavily engineered models trained on MS MARCO like ColBERT v2 by more than 1.2 nDCG on average on 11 retrieval sets. Further training standard-size re-rankers using the same generated data yields another 5.0 point nDCG improvement. Our studies determine that query generation can be far more effective than previously observed, especially when a small amount of task-specific knowledge is given.
Model2Detector: Widening the Information Bottleneck for Out-of-Distribution Detection using a Handful of Gradient Steps
Feb 22, 2022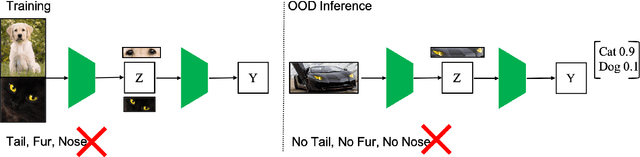
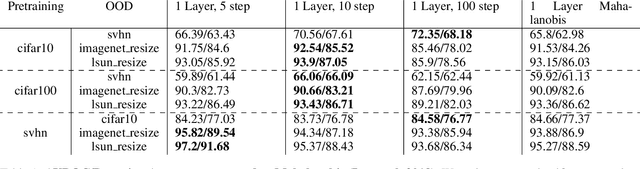
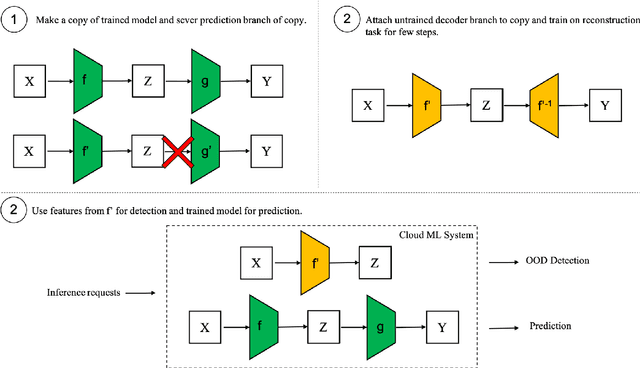
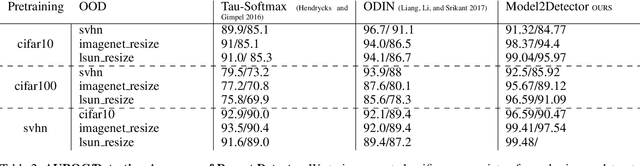
Out-of-distribution detection is an important capability that has long eluded vanilla neural networks. Deep Neural networks (DNNs) tend to generate over-confident predictions when presented with inputs that are significantly out-of-distribution (OOD). This can be dangerous when employing machine learning systems in the wild as detecting attacks can thus be difficult. Recent advances inference-time out-of-distribution detection help mitigate some of these problems. However, existing methods can be restrictive as they are often computationally expensive. Additionally, these methods require training of a downstream detector model which learns to detect OOD inputs from in-distribution ones. This, therefore, adds latency during inference. Here, we offer an information theoretic perspective on why neural networks are inherently incapable of OOD detection. We attempt to mitigate these flaws by converting a trained model into a an OOD detector using a handful of steps of gradient descent. Our work can be employed as a post-processing method whereby an inference-time ML system can convert a trained model into an OOD detector. Experimentally, we show how our method consistently outperforms the state-of-the-art in detection accuracy on popular image datasets while also reducing computational complexity.
Hybrid AI-based Anomaly Detection Model using Phasor Measurement Unit Data
Sep 21, 2022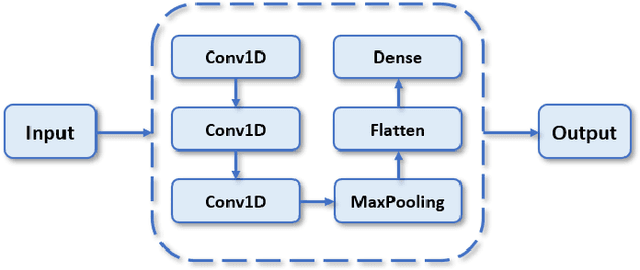
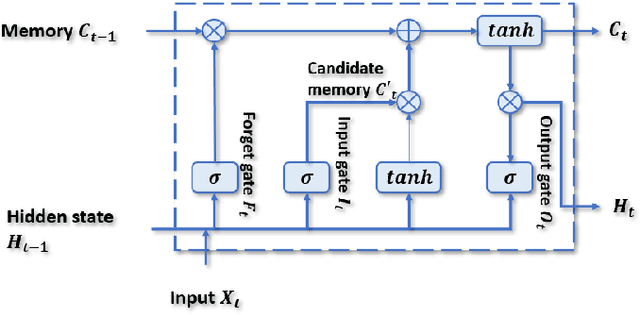
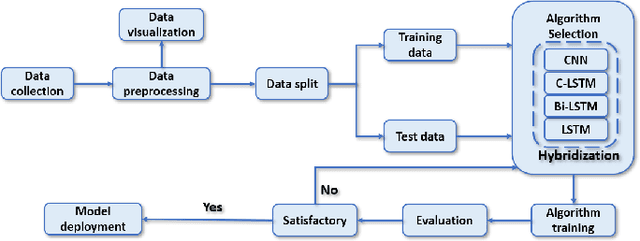
Over the last few decades, extensive use of information and communication technologies has been the main driver of the digitalization of power systems. Proper and secure monitoring of the critical grid infrastructure became an integral part of the modern power system. Using phasor measurement units (PMUs) to surveil the power system is one of the technologies that have a promising future. Increased frequency of measurements and smarter methods for data handling can improve the ability to reliably operate power grids. The increased cyber-physical interaction offers both benefits and drawbacks, where one of the drawbacks comes in the form of anomalies in the measurement data. The anomalies can be caused by both physical faults on the power grid, as well as disturbances, errors, and cyber attacks in the cyber layer. This paper aims to develop a hybrid AI-based model that is based on various methods such as Long Short Term Memory (LSTM), Convolutional Neural Network (CNN) and other relevant hybrid algorithms for anomaly detection in phasor measurement unit data. The dataset used within this research was acquired by the University of Texas, which consists of real data from grid measurements. In addition to the real data, false data that has been injected to produce anomalies has been analyzed. The impacts and mitigating methods to prevent such kind of anomalies are discussed.