 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
HandMime: Sign Language Fingerspelling Acquisition via Imitation Learning
Sep 12, 2022

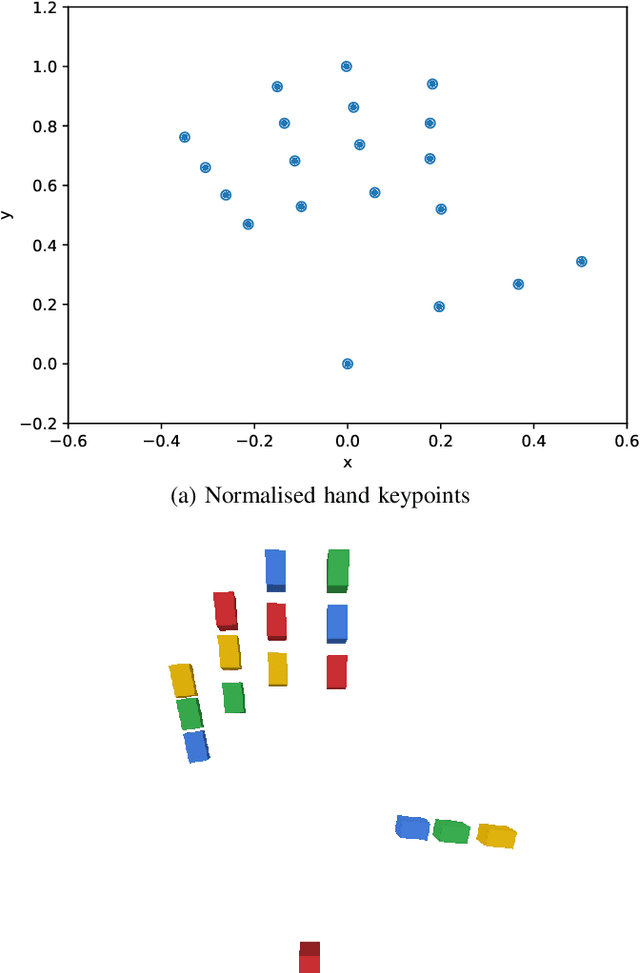
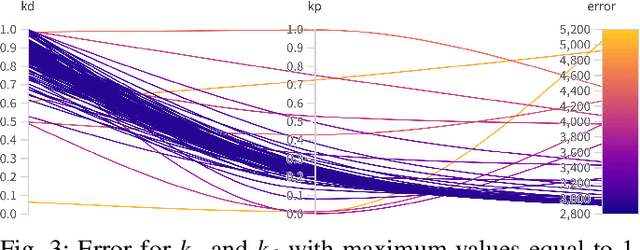
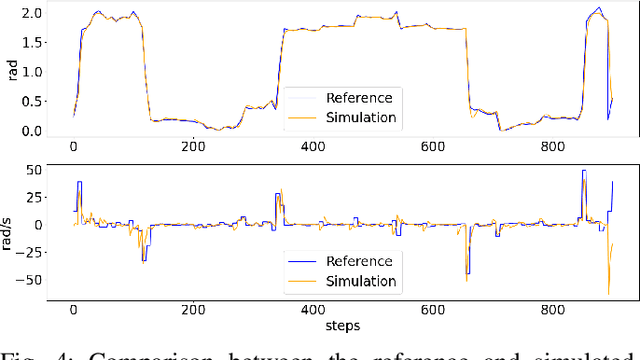
Learning fine-grained movements is among the most challenging topics in robotics. This holds true especially for robotic hands. Robotic sign language acquisition or, more specifically, fingerspelling sign language acquisition in robots can be considered a specific instance of such challenge. In this paper, we propose an approach for learning dexterous motor imitation from videos examples, without the use of any additional information. We build an URDF model of a robotic hand with a single actuator for each joint. By leveraging pre-trained deep vision models, we extract the 3D pose of the hand from RGB videos. Then, using state-of-the-art reinforcement learning algorithms for motion imitation (namely, proximal policy optimisation), we train a policy to reproduce the movement extracted from the demonstrations. We identify the best set of hyperparameters to perform imitation based on a reference motion. Additionally, we demonstrate the ability of our approach to generalise over 6 different fingerspelled letters.
Information Complexity and Generalization Bounds
May 04, 2021We present a unifying picture of PAC-Bayesian and mutual information-based upper bounds on the generalization error of randomized learning algorithms. As we show, Tong Zhang's information exponential inequality (IEI) gives a general recipe for constructing bounds of both flavors. We show that several important results in the literature can be obtained as simple corollaries of the IEI under different assumptions on the loss function. Moreover, we obtain new bounds for data-dependent priors and unbounded loss functions. Optimizing the bounds gives rise to variants of the Gibbs algorithm, for which we discuss two practical examples for learning with neural networks, namely, Entropy- and PAC-Bayes- SGD. Further, we use an Occam's factor argument to show a PAC-Bayesian bound that incorporates second-order curvature information of the training loss.
Multi-Figurative Language Generation
Sep 05, 2022
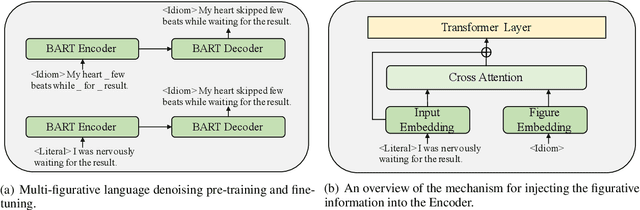

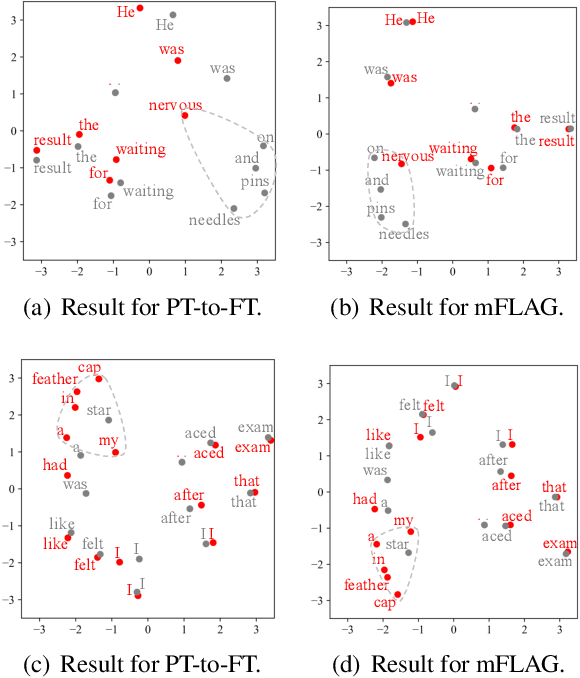
Figurative language generation is the task of reformulating a given text in the desired figure of speech while still being faithful to the original context. We take the first step towards multi-figurative language modelling by providing a benchmark for the automatic generation of five common figurative forms in English. We train mFLAG employing a scheme for multi-figurative language pre-training on top of BART, and a mechanism for injecting the target figurative information into the encoder; this enables the generation of text with the target figurative form from another figurative form without parallel figurative-figurative sentence pairs. Our approach outperforms all strong baselines. We also offer some qualitative analysis and reflections on the relationship between the different figures of speech.
Towards Computing an Optimal Abstraction for Structural Causal Models
Aug 01, 2022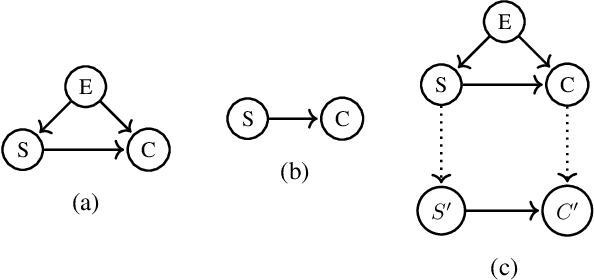
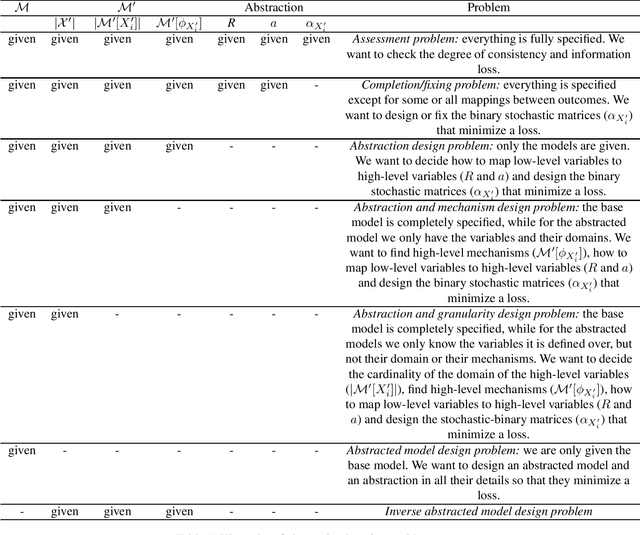
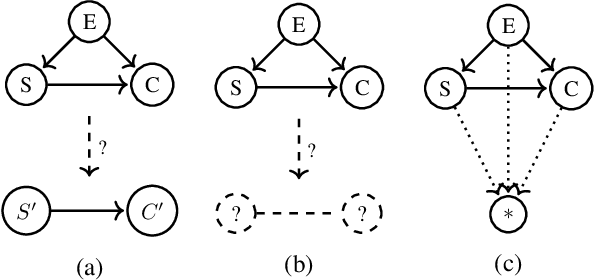
Working with causal models at different levels of abstraction is an important feature of science. Existing work has already considered the problem of expressing formally the relation of abstraction between causal models. In this paper, we focus on the problem of learning abstractions. We start by defining the learning problem formally in terms of the optimization of a standard measure of consistency. We then point out the limitation of this approach, and we suggest extending the objective function with a term accounting for information loss. We suggest a concrete measure of information loss, and we illustrate its contribution to learning new abstractions.
Location Sensing and Beamforming Design for IRS-Enabled Multi-User ISAC Systems
Aug 10, 2022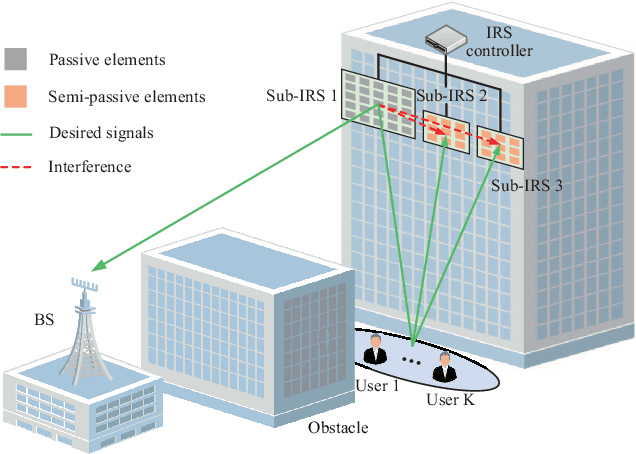
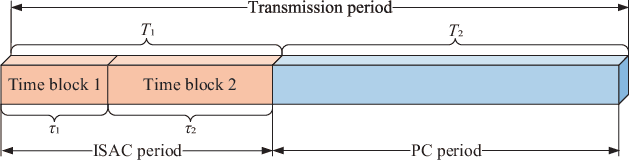
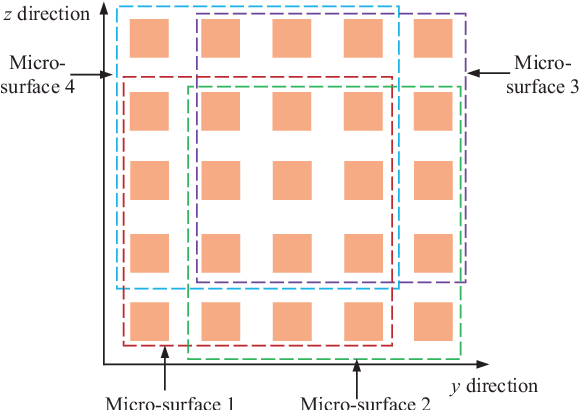
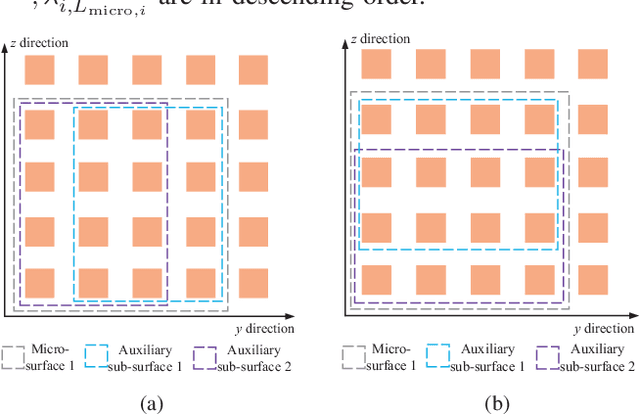
This paper explores the potential of the intelligent reflecting surface (IRS) in realizing multi-user concurrent communication and localization, using the same time-frequency resources. Specifically, we propose an IRS-enabled multi-user integrated sensing and communication (ISAC) framework, where a distributed semi-passive IRS assists the uplink data transmission from multiple users to the base station (BS) and conducts multi-user localization, simultaneously. We first design an ISAC transmission protocol, where the whole transmission period consists of two periods, i.e., the ISAC period for simultaneous uplink communication and multi-user localization, and the pure communication (PC) period for only uplink data transmission. For the ISAC period, we propose a multi-user location sensing algorithm, which utilizes the uplink communication signals unknown to the IRS, thus removing the requirement of dedicated positioning reference signals in conventional location sensing methods. Based on the sensed users' locations, we propose two novel beamforming algorithms for the ISAC period and PC period, respectively, which can work with discrete phase shifts and require no channel state information (CSI) acquisition. Numerical results show that the proposed multi-user location sensing algorithm can achieve up to millimeter-level positioning accuracy, indicating the advantage of the IRS-enabled ISAC framework. Moreover, the proposed beamforming algorithms with sensed location information and discrete phase shifts can achieve comparable performance to the benchmark considering perfect CSI acquisition and continuous phase shifts, demonstrating how the location information can ensure the communication performance.
On the Optimization Landscape of Dynamic Output Feedback: A Case Study for Linear Quadratic Regulator
Sep 12, 2022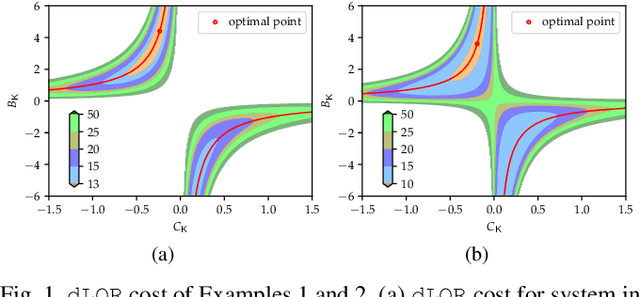
The convergence of policy gradient algorithms in reinforcement learning hinges on the optimization landscape of the underlying optimal control problem. Theoretical insights into these algorithms can often be acquired from analyzing those of linear quadratic control. However, most of the existing literature only considers the optimization landscape for static full-state or output feedback policies (controllers). We investigate the more challenging case of dynamic output-feedback policies for linear quadratic regulation (abbreviated as dLQR), which is prevalent in practice but has a rather complicated optimization landscape. We first show how the dLQR cost varies with the coordinate transformation of the dynamic controller and then derive the optimal transformation for a given observable stabilizing controller. At the core of our results is the uniqueness of the stationary point of dLQR when it is observable, which is in a concise form of an observer-based controller with the optimal similarity transformation. These results shed light on designing efficient algorithms for general decision-making problems with partially observed information.
Statistical CSI-based Beamforming for RIS-Aided Multiuser MISO Systems using Deep Reinforcement Learning
Sep 03, 2022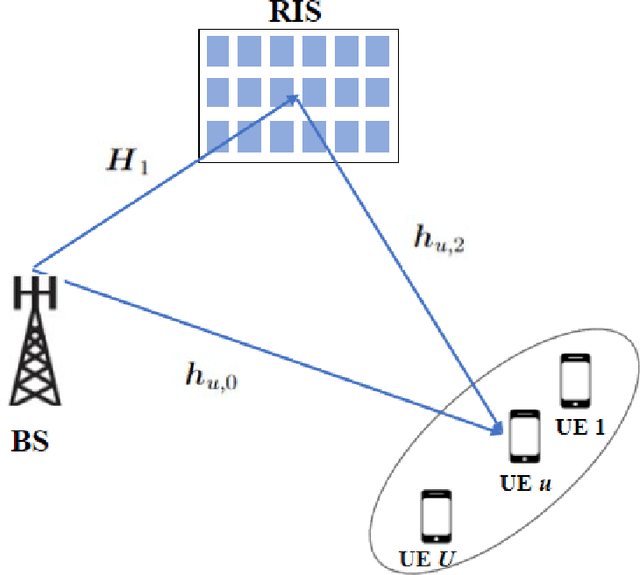
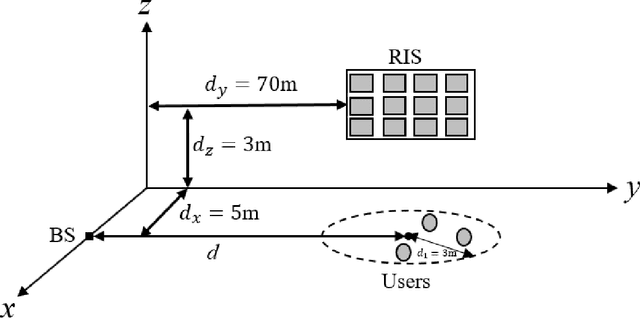
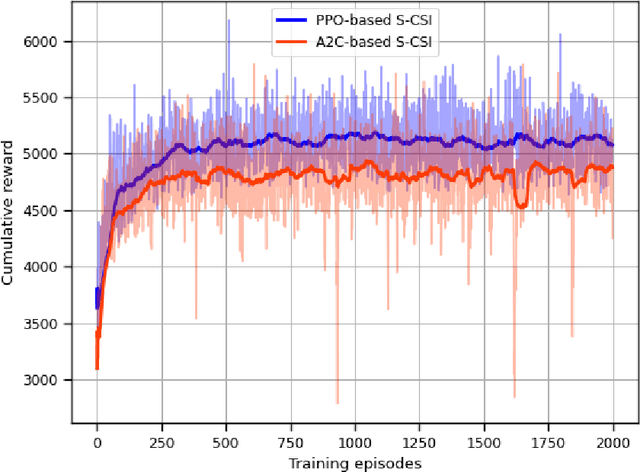
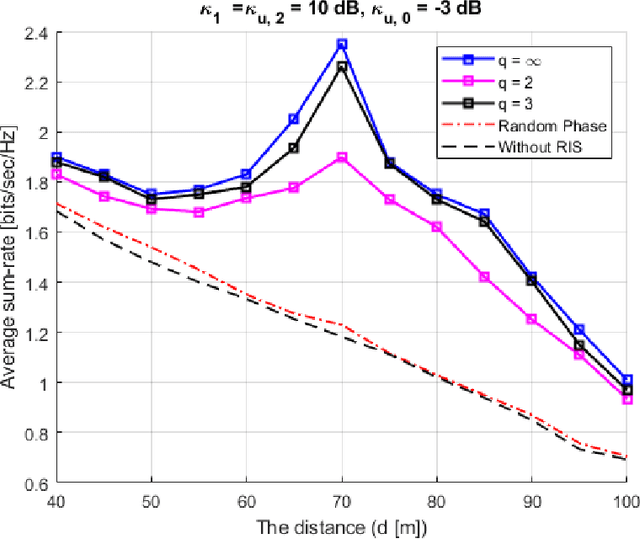
The paper presents a joint beamforming algorithm using statistical channel state information (S-CSI) for reconfigurable intelligent surfaces (RIS) for multiuser MISO wireless communications. We used S-CSI, which is a long-term average of the cascaded channel as opposed to instantaneous CSI utilized in most existing works. Through this method, the overhead of channel estimation is dramatically reduced. We propose a proximal policy optimization (PPO) algorithm which is a well-known actor-critic based reinforcement learning (RL) algorithm to solve the optimization problem. To test the efficacy of this algorithm, simulation results are presented along with evaluations of key system parameters, including the Rician factor and RIS location, on the achievable sum rate of the users.
Fine-grained Classification of Solder Joints with α-skew Jensen-Shannon Divergence
Sep 20, 2022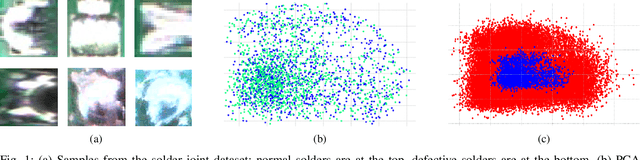
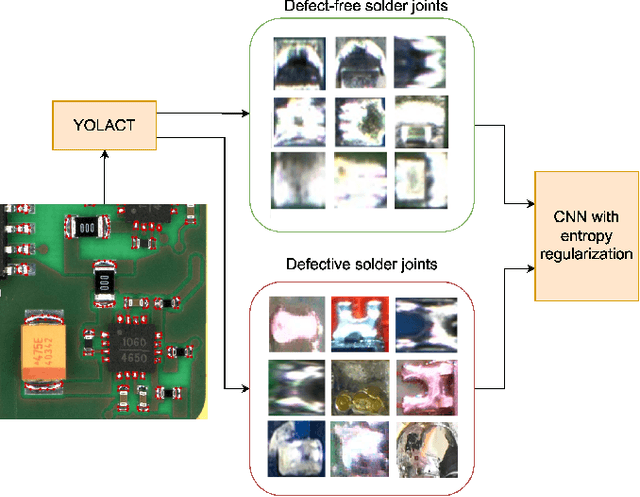
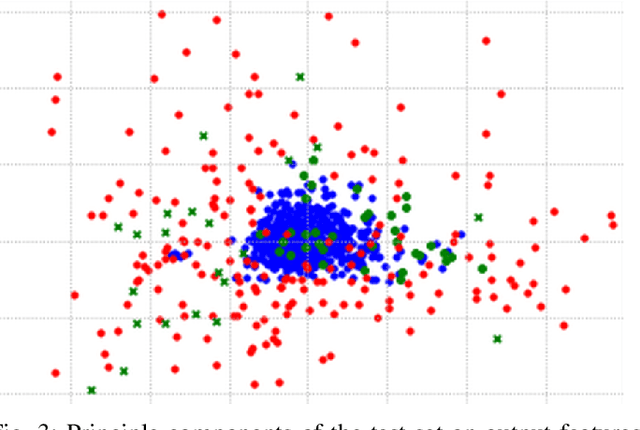
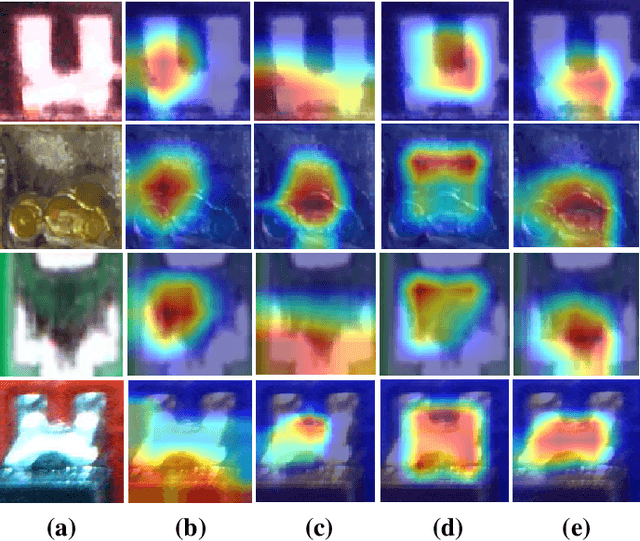
Solder joint inspection (SJI) is a critical process in the production of printed circuit boards (PCB). Detection of solder errors during SJI is quite challenging as the solder joints have very small sizes and can take various shapes. In this study, we first show that solders have low feature diversity, and that the SJI can be carried out as a fine-grained image classification task which focuses on hard-to-distinguish object classes. To improve the fine-grained classification accuracy, penalizing confident model predictions by maximizing entropy was found useful in the literature. Inline with this information, we propose using the {\alpha}-skew Jensen-Shannon divergence ({\alpha}-JS) for penalizing the confidence in model predictions. We compare the {\alpha}-JS regularization with both existing entropyregularization based methods and the methods based on attention mechanism, segmentation techniques, transformer models, and specific loss functions for fine-grained image classification tasks. We show that the proposed approach achieves the highest F1-score and competitive accuracy for different models in the finegrained solder joint classification task. Finally, we visualize the activation maps and show that with entropy-regularization, more precise class-discriminative regions are localized, which are also more resilient to noise. Code will be made available here upon acceptance.
Zero-Shot Information Extraction as a Unified Text-to-Triple Translation
Sep 23, 2021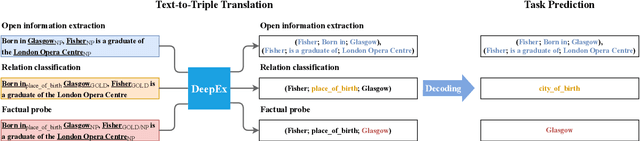
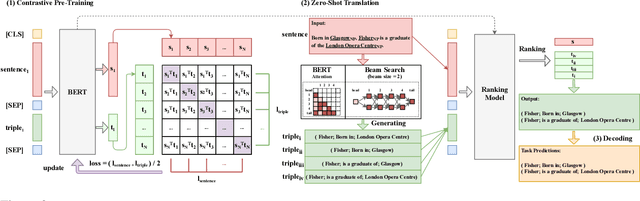

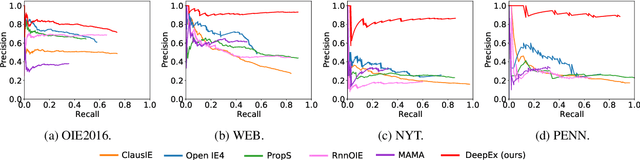
We cast a suite of information extraction tasks into a text-to-triple translation framework. Instead of solving each task relying on task-specific datasets and models, we formalize the task as a translation between task-specific input text and output triples. By taking the task-specific input, we enable a task-agnostic translation by leveraging the latent knowledge that a pre-trained language model has about the task. We further demonstrate that a simple pre-training task of predicting which relational information corresponds to which input text is an effective way to produce task-specific outputs. This enables the zero-shot transfer of our framework to downstream tasks. We study the zero-shot performance of this framework on open information extraction (OIE2016, NYT, WEB, PENN), relation classification (FewRel and TACRED), and factual probe (Google-RE and T-REx). The model transfers non-trivially to most tasks and is often competitive with a fully supervised method without the need for any task-specific training. For instance, we significantly outperform the F1 score of the supervised open information extraction without needing to use its training set.
FedToken: Tokenized Incentives for Data Contribution in Federated Learning
Sep 20, 2022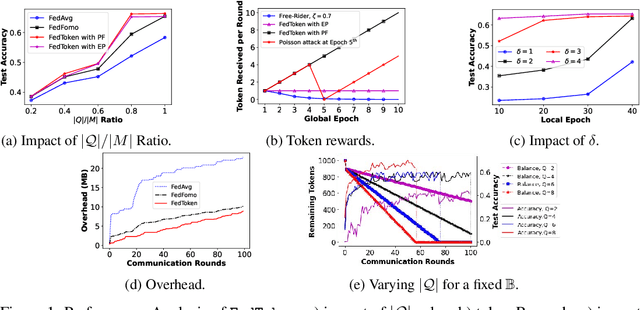
Incentives that compensate for the involved costs in the decentralized training of a Federated Learning (FL) model act as a key stimulus for clients' long-term participation. However, it is challenging to convince clients for quality participation in FL due to the absence of: (i) full information on the client's data quality and properties; (ii) the value of client's data contributions; and (iii) the trusted mechanism for monetary incentive offers. This often leads to poor efficiency in training and communication. While several works focus on strategic incentive designs and client selection to overcome this problem, there is a major knowledge gap in terms of an overall design tailored to the foreseen digital economy, including Web 3.0, while simultaneously meeting the learning objectives. To address this gap, we propose a contribution-based tokenized incentive scheme, namely \texttt{FedToken}, backed by blockchain technology that ensures fair allocation of tokens amongst the clients that corresponds to the valuation of their data during model training. Leveraging the engineered Shapley-based scheme, we first approximate the contribution of local models during model aggregation, then strategically schedule clients lowering the communication rounds for convergence and anchor ways to allocate \emph{affordable} tokens under a constrained monetary budget. Extensive simulations demonstrate the efficacy of our proposed method.