 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Collaborative Decision Making Using Action Suggestions
Sep 27, 2022
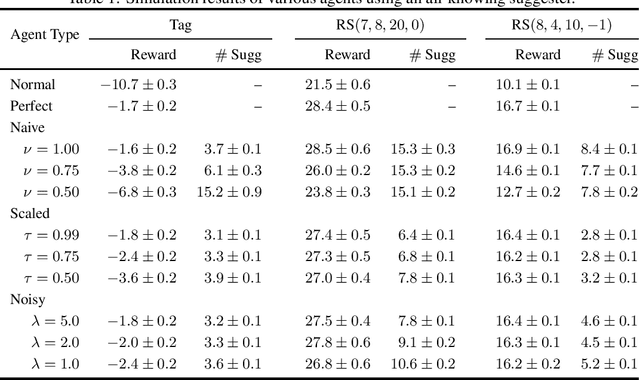
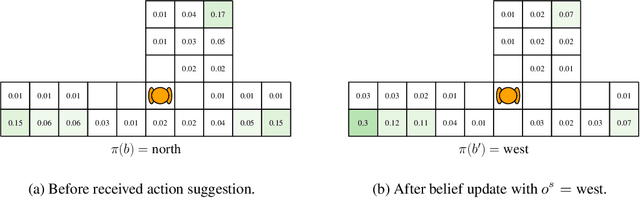
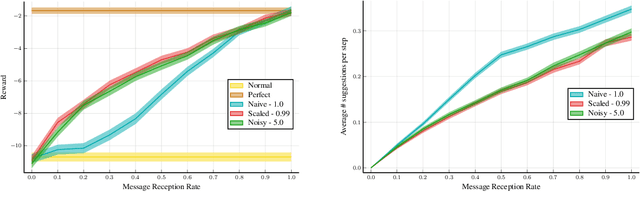
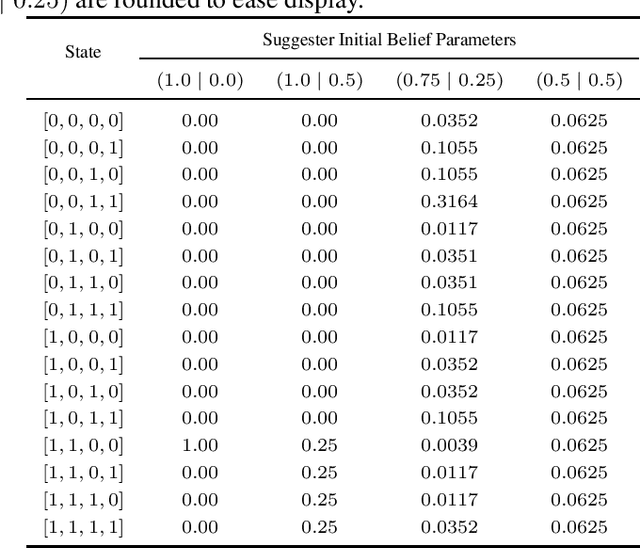
The level of autonomy is increasing in systems spanning multiple domains, but these systems still experience failures. One way to mitigate the risk of failures is to integrate human oversight of the autonomous systems and rely on the human to take control when the autonomy fails. In this work, we formulate a method of collaborative decision making through action suggestions that improves action selection without taking control of the system. Our approach uses each suggestion efficiently by incorporating the implicit information shared through suggestions to modify the agent's belief and achieves better performance with fewer suggestions than naively following the suggested actions. We assume collaborative agents share the same objective and communicate through valid actions. By assuming the suggested action is dependent only on the state, we can incorporate the suggested action as an independent observation of the environment. The assumption of a collaborative environment enables us to use the agent's policy to estimate the distribution over action suggestions. We propose two methods that use suggested actions and demonstrate the approach through simulated experiments. The proposed methodology results in increased performance while also being robust to suboptimal suggestions.
Integrating Auxiliary Information in Self-supervised Learning
Jun 05, 2021



This paper presents to integrate the auxiliary information (e.g., additional attributes for data such as the hashtags for Instagram images) in the self-supervised learning process. We first observe that the auxiliary information may bring us useful information about data structures: for instance, the Instagram images with the same hashtags can be semantically similar. Hence, to leverage the structural information from the auxiliary information, we present to construct data clusters according to the auxiliary information. Then, we introduce the Clustering InfoNCE (Cl-InfoNCE) objective that learns similar representations for augmented variants of data from the same cluster and dissimilar representations for data from different clusters. Our approach contributes as follows: 1) Comparing to conventional self-supervised representations, the auxiliary-information-infused self-supervised representations bring the performance closer to the supervised representations; 2) The presented Cl-InfoNCE can also work with unsupervised constructed clusters (e.g., k-means clusters) and outperform strong clustering-based self-supervised learning approaches, such as the Prototypical Contrastive Learning (PCL) method; 3) We show that Cl-InfoNCE may be a better approach to leverage the data clustering information, by comparing it to the baseline approach - learning to predict the clustering assignments with cross-entropy loss. For analysis, we connect the goodness of the learned representations with the statistical relationships: i) the mutual information between the labels and the clusters and ii) the conditional entropy of the clusters given the labels.
HAZE-Net: High-Frequency Attentive Super-Resolved Gaze Estimation in Low-Resolution Face Images
Sep 21, 2022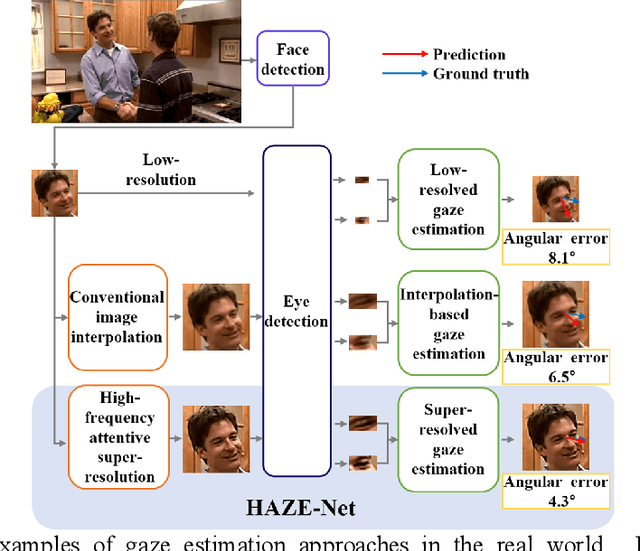

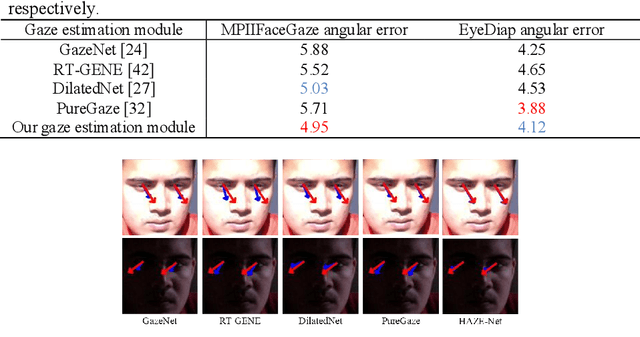
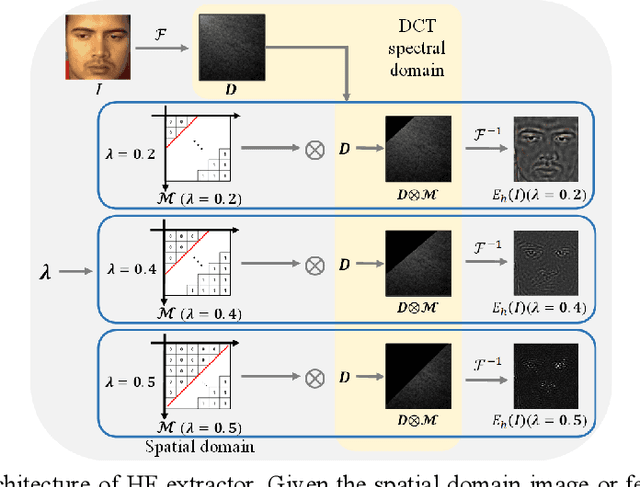
Although gaze estimation methods have been developed with deep learning techniques, there has been no such approach as aim to attain accurate performance in low-resolution face images with a pixel width of 50 pixels or less. To solve a limitation under the challenging low-resolution conditions, we propose a high-frequency attentive super-resolved gaze estimation network, i.e., HAZE-Net. Our network improves the resolution of the input image and enhances the eye features and those boundaries via a proposed super-resolution module based on a high-frequency attention block. In addition, our gaze estimation module utilizes high-frequency components of the eye as well as the global appearance map. We also utilize the structural location information of faces to approximate head pose. The experimental results indicate that the proposed method exhibits robust gaze estimation performance even in low-resolution face images with 28x28 pixels. The source code of this work is available at https://github.com/dbseorms16/HAZE_Net/.
Towards Multimodal Multitask Scene Understanding Models for Indoor Mobile Agents
Sep 27, 2022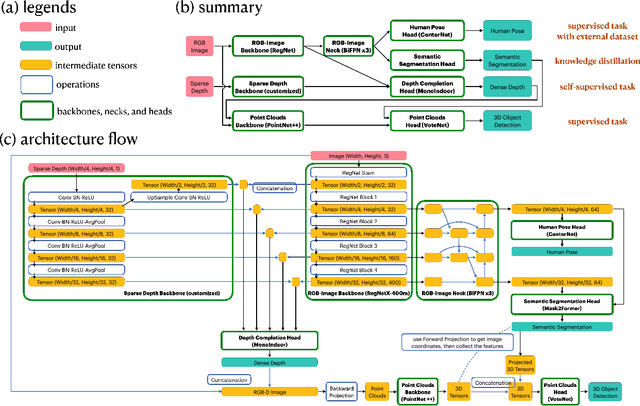
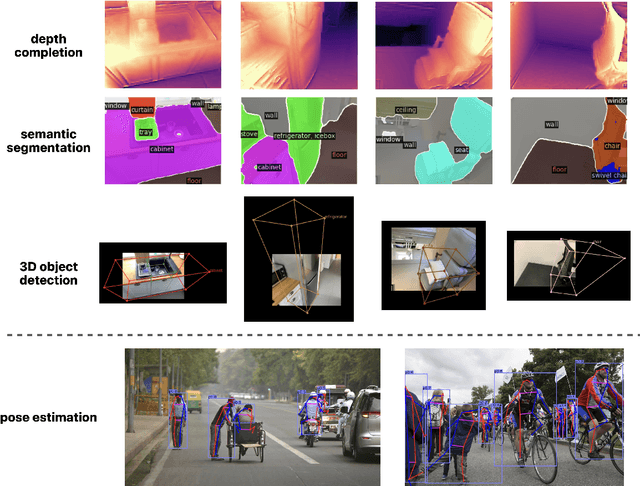
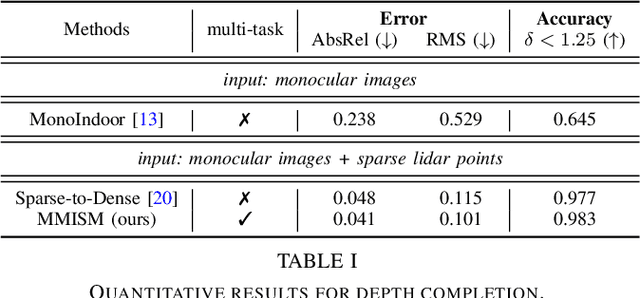
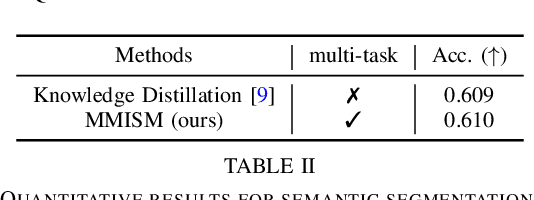
The perception system in personalized mobile agents requires developing indoor scene understanding models, which can understand 3D geometries, capture objectiveness, analyze human behaviors, etc. Nonetheless, this direction has not been well-explored in comparison with models for outdoor environments (e.g., the autonomous driving system that includes pedestrian prediction, car detection, traffic sign recognition, etc.). In this paper, we first discuss the main challenge: insufficient, or even no, labeled data for real-world indoor environments, and other challenges such as fusion between heterogeneous sources of information (e.g., RGB images and Lidar point clouds), modeling relationships between a diverse set of outputs (e.g., 3D object locations, depth estimation, and human poses), and computational efficiency. Then, we describe MMISM (Multi-modality input Multi-task output Indoor Scene understanding Model) to tackle the above challenges. MMISM considers RGB images as well as sparse Lidar points as inputs and 3D object detection, depth completion, human pose estimation, and semantic segmentation as output tasks. We show that MMISM performs on par or even better than single-task models; e.g., we improve the baseline 3D object detection results by 11.7% on the benchmark ARKitScenes dataset.
Subject-Independent 3D Hand Kinematics Reconstruction using Pre-Movement EEG Signals for Grasp And Lift Task
Sep 05, 2022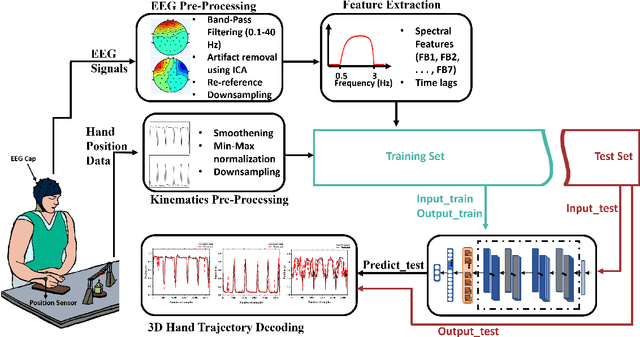
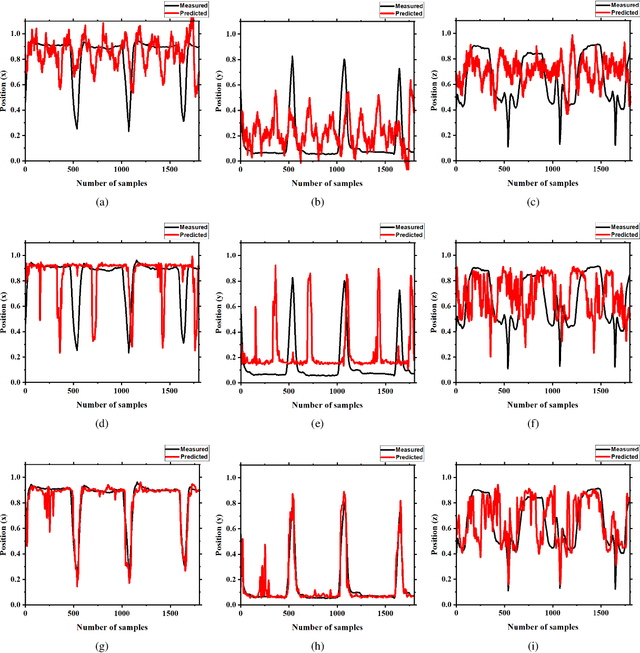
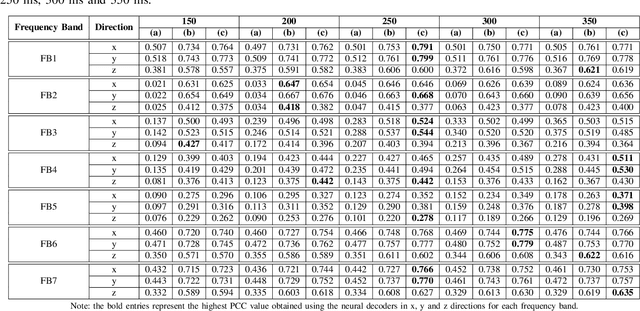
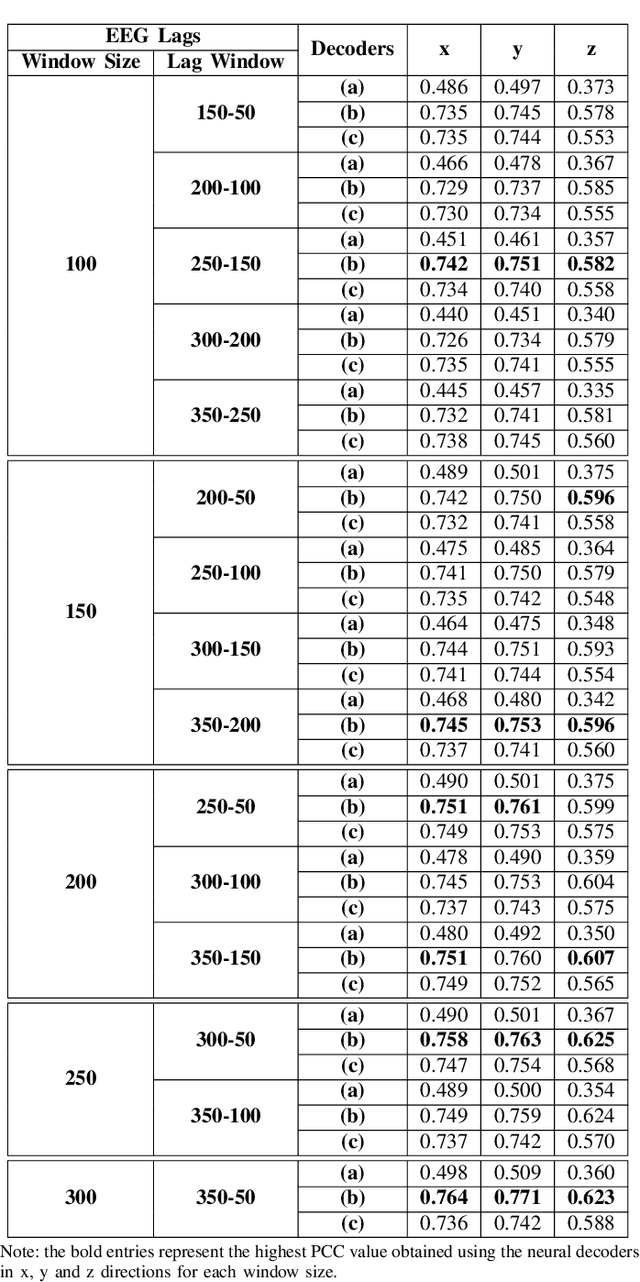
Brain-computer interface (BCI) systems can be utilized for kinematics decoding from scalp brain activation to control rehabilitation or power-augmenting devices. In this study, the hand kinematics decoding for grasp and lift task is performed in three-dimensional (3D) space using scalp electroencephalogram (EEG) signals. Twelve subjects from the publicly available database WAY-EEG-GAL, has been utilized in this study. In particular, multi-layer perceptron (MLP) and convolutional neural network-long short-term memory (CNN-LSTM) based deep learning frameworks are proposed that utilize the motor-neural information encoded in the pre-movement EEG data. Spectral features are analyzed for hand kinematics decoding using EEG data filtered in seven frequency ranges. The best performing frequency band spectral features has been considered for further analysis with different EEG window sizes and lag windows. Appropriate lag windows from movement onset, make the approach pre-movement in true sense. Additionally, inter-subject hand trajectory decoding analysis is performed using leave-one-subject-out (LOSO) approach. The Pearson correlation coefficient and hand trajectory are considered as performance metric to evaluate decoding performance for the neural decoders. This study explores the feasibility of inter-subject 3-D hand trajectory decoding using EEG signals only during reach and grasp task, probably for the first time. The results may provide the viable information to decode 3D hand kinematics using pre-movement EEG signals for practical BCI applications such as exoskeleton/exosuit and prosthesis.
Sparsification of the regularized magnetic Laplacian with multi-type spanning forests
Aug 31, 2022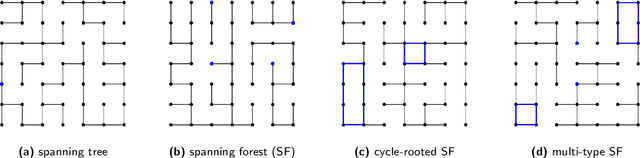



In this paper, we consider a ${\rm U}(1)$-connection graph, that is, a graph where each oriented edge is endowed with a unit modulus complex number which is simply conjugated under orientation flip. A natural replacement for the combinatorial Laplacian is then the so-called magnetic Laplacian, an Hermitian matrix that includes information about the graph's connection. Connection graphs and magnetic Laplacians appear, e.g., in the problem of angular synchronization. In the context of large and dense graphs, we study here sparsifiers of the magnetic Laplacian, i.e., spectral approximations based on subgraphs with few edges. Our approach relies on sampling multi-type spanning forests (MTSFs) using a custom determinantal point process, a distribution over edges that favours diversity. In a word, an MTSF is a spanning subgraph whose connected components are either trees or cycle-rooted trees. The latter partially capture the angular inconsistencies of the connection graph, and thus provide a way to compress information contained in the connection. Interestingly, when this connection graph has weakly inconsistent cycles, samples of this distribution can be obtained by using a random walk with cycle popping. We provide statistical guarantees for a choice of natural estimators of the connection Laplacian, and investigate the practical application of our sparsifiers in two applications.
Spotlight: Mobile UI Understanding using Vision-Language Models with a Focus
Sep 29, 2022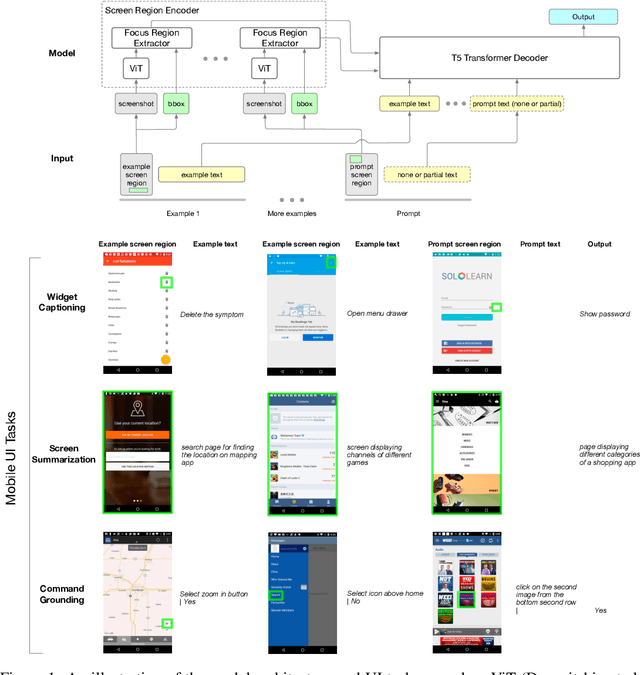

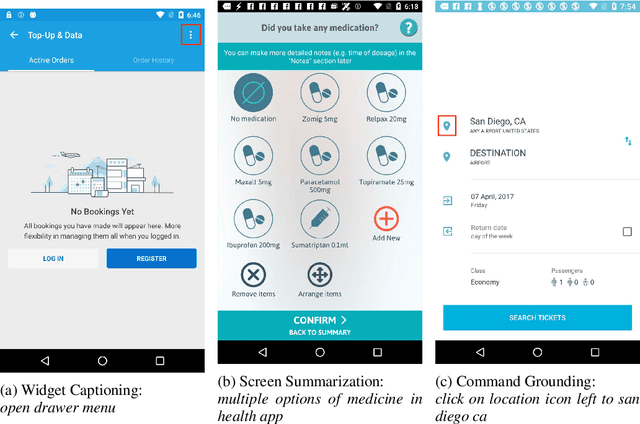

Mobile UI understanding is important for enabling various interaction tasks such as UI automation and accessibility. Previous mobile UI modeling often depends on the view hierarchy information of a screen, which directly provides the structural data of the UI, with the hope to bypass challenging tasks of visual modeling from screen pixels. However, view hierarchy is not always available, and is often corrupted with missing object descriptions or misaligned bounding box positions. As a result, although using view hierarchy offers some short-term gains, it may ultimately hinder the applicability and performance of the model. In this paper, we propose Spotlight, a vision-only approach for mobile UI understanding. Specifically, we enhance a vision-language model that only takes the screenshot of the UI and a region of interest on the screen -- the focus -- as the input. This general architecture is easily scalable and capable of performing a range of UI modeling tasks. Our experiments show that our model obtains SoTA results on several representative UI tasks and outperforms previous methods that use both screenshots and view hierarchies as input. Furthermore, we explore the multi-task learning and few-shot prompting capacity of the proposed models, demonstrating promising results in the multi-task learning direction.
Domain-Unified Prompt Representations for Source-Free Domain Generalization
Sep 29, 2022
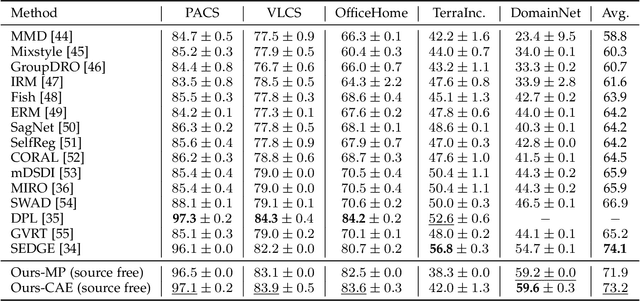


Domain generalization (DG), aiming to make models work on unseen domains, is a surefire way toward general artificial intelligence. Limited by the scale and diversity of current DG datasets, it is difficult for existing methods to scale to diverse domains in open-world scenarios (e.g., science fiction and pixelate style). Therefore, the source-free domain generalization (SFDG) task is necessary and challenging. To address this issue, we propose an approach based on large-scale vision-language pretraining models (e.g., CLIP), which exploits the extensive domain information embedded in it. The proposed scheme generates diverse prompts from a domain bank that contains many more diverse domains than existing DG datasets. Furthermore, our method yields domain-unified representations from these prompts, thus being able to cope with samples from open-world domains. Extensive experiments on mainstream DG datasets, namely PACS, VLCS, OfficeHome, and DomainNet, show that the proposed method achieves competitive performance compared to state-of-the-art (SOTA) DG methods that require source domain data for training. Besides, we collect a small datasets consists of two domains to evaluate the open-world domain generalization ability of the proposed method. The source code and the dataset will be made publicly available at https://github.com/muse1998/Source-Free-Domain-Generalization
Distribution Aware Metrics for Conditional Natural Language Generation
Sep 29, 2022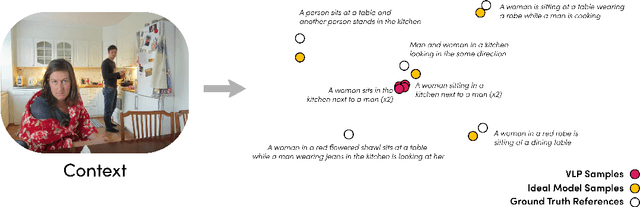
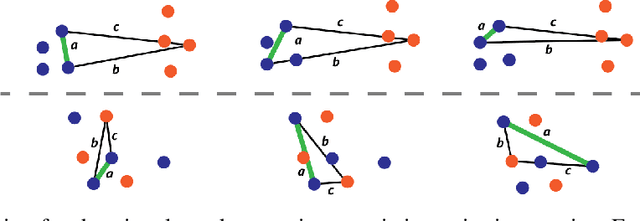

Traditional automated metrics for evaluating conditional natural language generation use pairwise comparisons between a single generated text and the best-matching gold-standard ground truth text. When multiple ground truths are available, scores are aggregated using an average or max operation across references. While this approach works well when diversity in the ground truth data (i.e. dispersion of the distribution of conditional texts) can be ascribed to noise, such as in automated speech recognition, it does not allow for robust evaluation in the case where diversity in the ground truths represents signal for the model. In this work we argue that existing metrics are not appropriate for domains such as visual description or summarization where ground truths are semantically diverse, and where the diversity in those captions captures useful additional information about the context. We propose a novel paradigm for multi-candidate evaluation of conditional language generation models, and a new family of metrics that compare the distributions of reference and model-generated caption sets using small sample sets of each. We demonstrate the utility of our approach with a case study in visual description: where we show that existing models optimize for single-description quality over diversity, and gain some insights into how sampling methods and temperature impact description quality and diversity.
Capacity Analysis and Sum Rate Maximization for the SCMA Cellular Network Coexisting with D2D Communications
Sep 21, 2022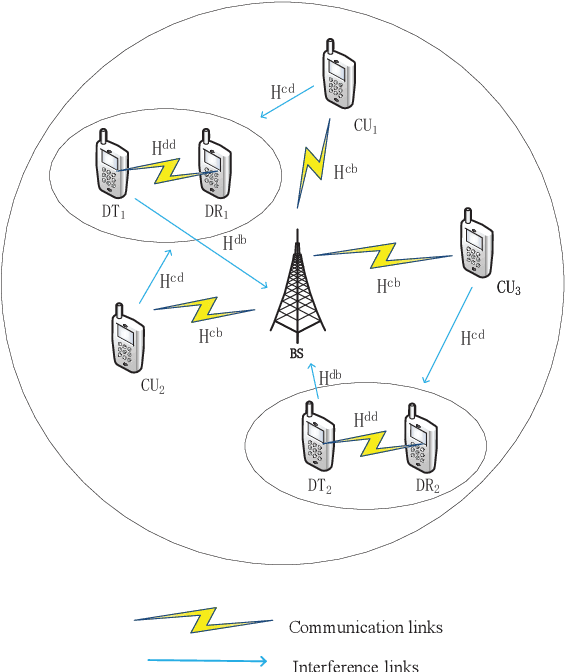
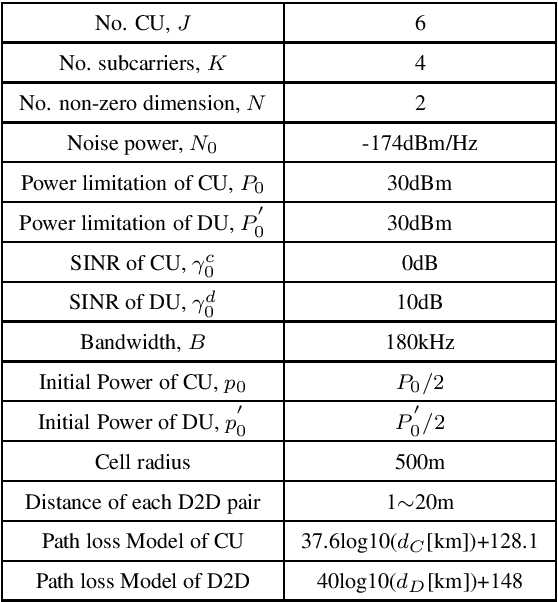
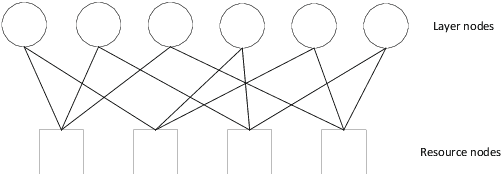
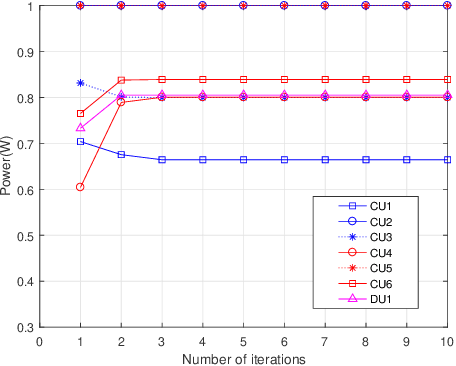
Sparse code multiple access (SCMA) is the most concerning scheme among non-orthogonal multiple access (NOMA) technologies for 5G wireless communication new interface. Another efficient technique in 5G aimed to improve spectral efficiency for local communications is device-to-device (D2D) communications. Therefore, we utilize the SCMA cellular network coexisting with D2D communications for the connection demand of the Internet of things (IOT), and improve the system sum rate performance of the hybrid network. We first derive the information-theoretic expression of the capacity for all users and find the capacity bound of cellular users based on the mutual interference between cellular users and D2D users. Then we consider the power optimization problem for the cellular users and D2D users jointly to maximize the system sum rate. To tackle the non-convex optimization problem, we propose a geometric programming (GP) based iterative power allocation algorithm. Simulation results demonstrate that the proposed algorithm converges fast and well improves the sum rate performance.