 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
ReX: A Framework for Generating Local Explanations to Recurrent Neural Networks
Sep 08, 2022
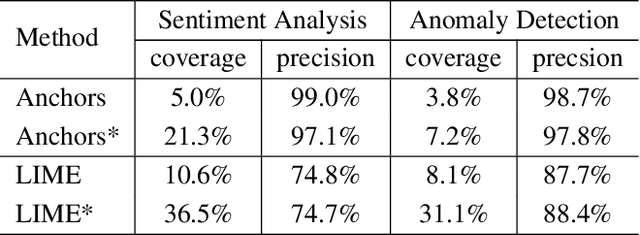
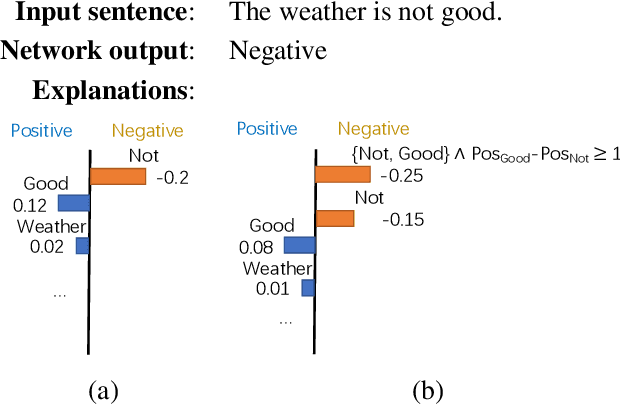


We propose a general framework to adapt various local explanation techniques to recurrent neural networks. In particular, our explanations add temporal information, which expand explanations generated from existing techniques to cover data points that have different lengths compared to the original input data point. Our approach is general as it only modifies the perturbation model and feature representation of existing techniques without touching their core algorithms. We have instantiated our approach on LIME and Anchors. Our empirical evaluation shows that it effectively improves the usefulness of explanations generated by these two techniques on a sentiment analysis network and an anomaly detection network.
AiM: Taking Answers in Mind to Correct Chinese Cloze Tests in Educational Applications
Aug 26, 2022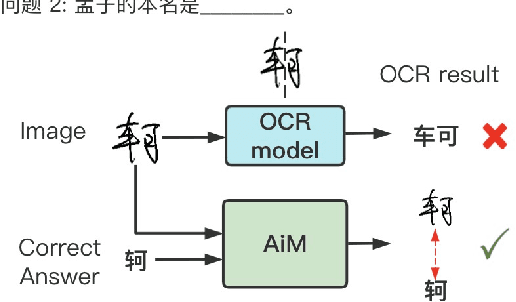
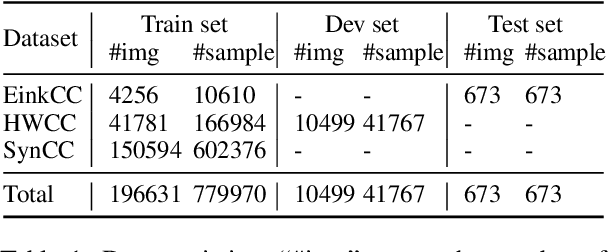
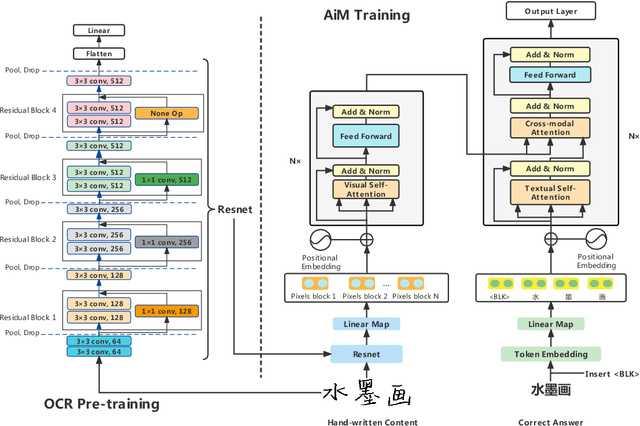
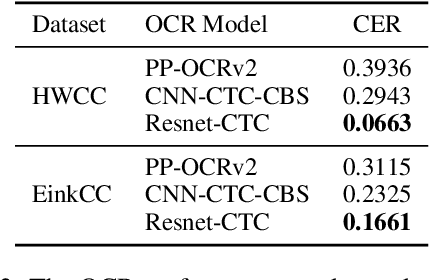
To automatically correct handwritten assignments, the traditional approach is to use an OCR model to recognize characters and compare them to answers. The OCR model easily gets confused on recognizing handwritten Chinese characters, and the textual information of the answers is missing during the model inference. However, teachers always have these answers in mind to review and correct assignments. In this paper, we focus on the Chinese cloze tests correction and propose a multimodal approach (named AiM). The encoded representations of answers interact with the visual information of students' handwriting. Instead of predicting 'right' or 'wrong', we perform the sequence labeling on the answer text to infer which answer character differs from the handwritten content in a fine-grained way. We take samples of OCR datasets as the positive samples for this task, and develop a negative sample augmentation method to scale up the training data. Experimental results show that AiM outperforms OCR-based methods by a large margin. Extensive studies demonstrate the effectiveness of our multimodal approach.
Semi-Supervised Disentanglement of Tactile Contact~Geometry from Sliding-Induced Shear
Aug 26, 2022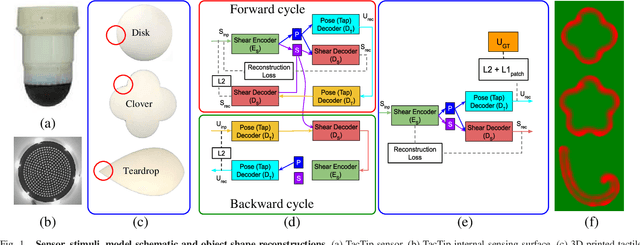
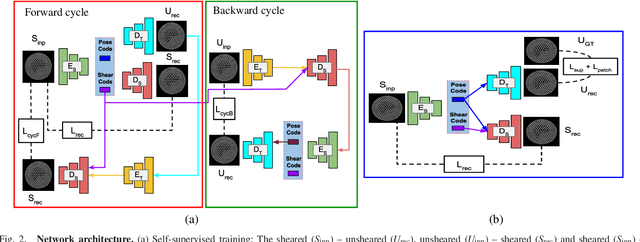
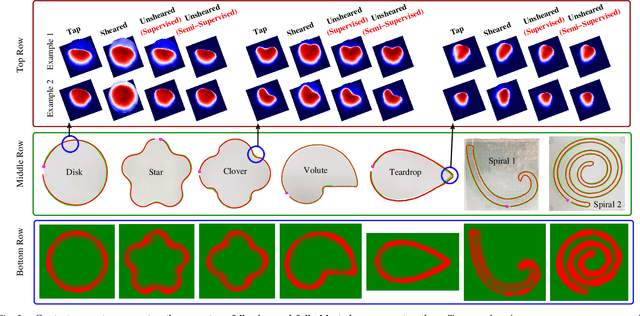

The sense of touch is fundamental to human dexterity. When mimicked in robotic touch, particularly by use of soft optical tactile sensors, it suffers from distortion due to motion-dependent shear. This complicates tactile tasks like shape reconstruction and exploration that require information about contact geometry. In this work, we pursue a semi-supervised approach to remove shear while preserving contact-only information. We validate our approach by showing a match between the model-generated unsheared images with their counterparts from vertically tapping onto the object. The model-generated unsheared images give faithful reconstruction of contact-geometry otherwise masked by shear, along with robust estimation of object pose then used for sliding exploration and full reconstruction of several planar shapes. We show that our semi-supervised approach achieves comparable performance to its fully supervised counterpart across all validation tasks with an order of magnitude less supervision. The semi-supervised method is thus more computational and labeled sample-efficient. We expect it will have broad applicability to wide range of complex tactile exploration and manipulation tasks performed via a shear-sensitive sense of touch.
DELTAR: Depth Estimation from a Light-weight ToF Sensor and RGB Image
Sep 27, 2022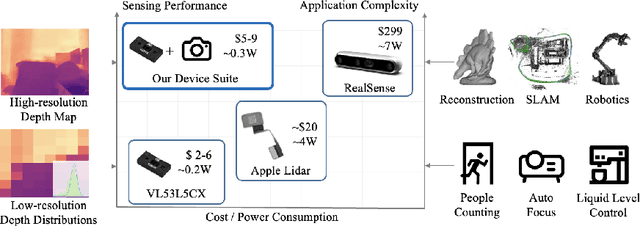
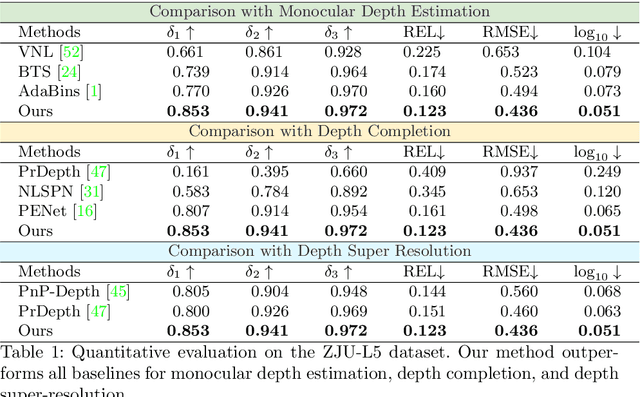
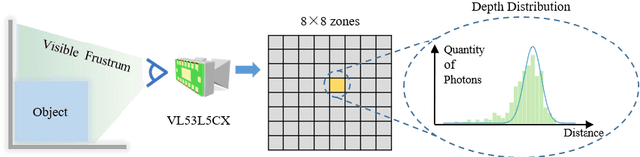
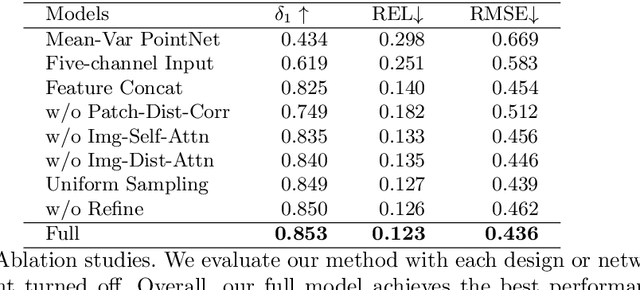
Light-weight time-of-flight (ToF) depth sensors are small, cheap, low-energy and have been massively deployed on mobile devices for the purposes like autofocus, obstacle detection, etc. However, due to their specific measurements (depth distribution in a region instead of the depth value at a certain pixel) and extremely low resolution, they are insufficient for applications requiring high-fidelity depth such as 3D reconstruction. In this paper, we propose DELTAR, a novel method to empower light-weight ToF sensors with the capability of measuring high resolution and accurate depth by cooperating with a color image. As the core of DELTAR, a feature extractor customized for depth distribution and an attention-based neural architecture is proposed to fuse the information from the color and ToF domain efficiently. To evaluate our system in real-world scenarios, we design a data collection device and propose a new approach to calibrate the RGB camera and ToF sensor. Experiments show that our method produces more accurate depth than existing frameworks designed for depth completion and depth super-resolution and achieves on par performance with a commodity-level RGB-D sensor. Code and data are available at https://zju3dv.github.io/deltar/.
Uncertainty-aware Label Distribution Learning for Facial Expression Recognition
Sep 21, 2022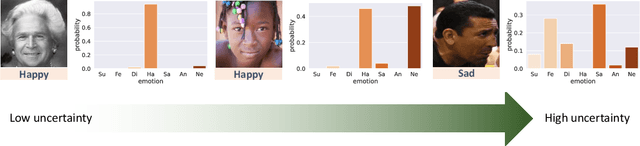
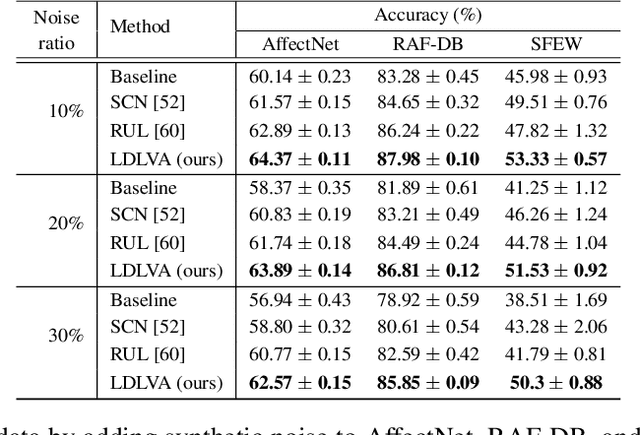
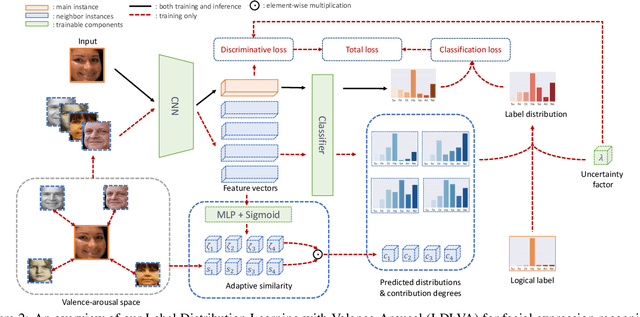
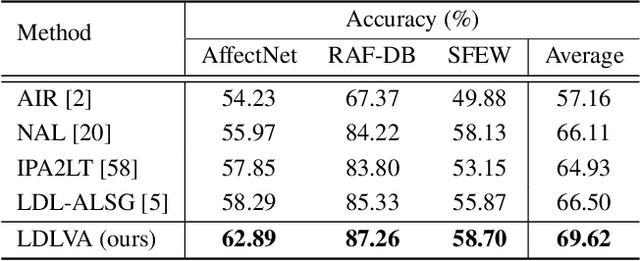
Despite significant progress over the past few years, ambiguity is still a key challenge in Facial Expression Recognition (FER). It can lead to noisy and inconsistent annotation, which hinders the performance of deep learning models in real-world scenarios. In this paper, we propose a new uncertainty-aware label distribution learning method to improve the robustness of deep models against uncertainty and ambiguity. We leverage neighborhood information in the valence-arousal space to adaptively construct emotion distributions for training samples. We also consider the uncertainty of provided labels when incorporating them into the label distributions. Our method can be easily integrated into a deep network to obtain more training supervision and improve recognition accuracy. Intensive experiments on several datasets under various noisy and ambiguous settings show that our method achieves competitive results and outperforms recent state-of-the-art approaches. Our code and models are available at https://github.com/minhnhatvt/label-distribution-learning-fer-tf.
A Simulation Method for MMW Radar Sensing in Traffic Intersection Based on BART Algorithm
Aug 29, 2022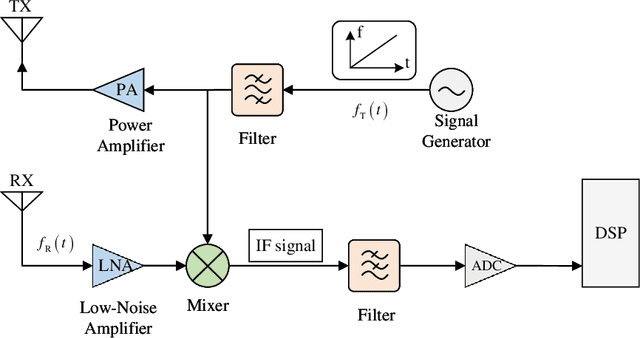

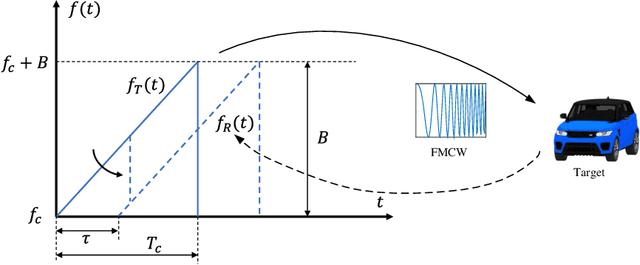
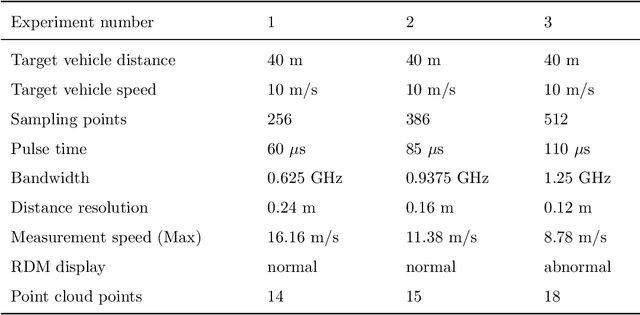
Millimeter-wave (mmw) radar is indispensable for Intelligent Transportation Systems (ITS), which can monitor traffic conditions in all weathers. An end-to-end simulation method for mmw radar monitoring and identification at traffic intersections is proposed in this paper. In this method, a virtual intersection scenario model is constructed, and the scattering coefficient of the target is calculated using the Bidirectional Analytical Ray Tracing (BART) algorithm. Combined with the generation of time-domain waveforms, the operation of frequency-domain convolution is simplified by inverse Fourier transform, and the echo signals received by the sparse array are simulated. After raw signal processing, point cloud images containing target position information and Range-Doppler Map (RDM) containing target state feature are obtained. The performance of mmw radar in detecting the specific location information of the target is evaluated by analyzing point cloud images. In addition, a self-defined convolutional neural network is introduced in this paper to evaluate the object recognition performance of the RDM. After the training of the neural network, the classification accuracy of this method for four types of vehicle targets can reach 92%.
GP-net: Grasp Proposal for Mobile Manipulators
Sep 21, 2022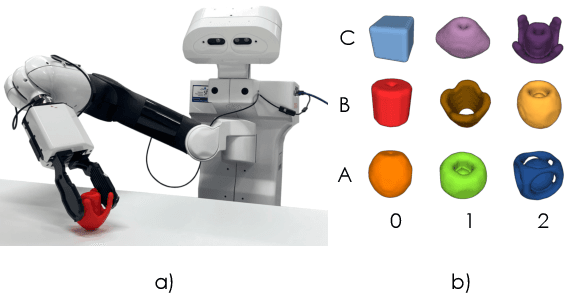
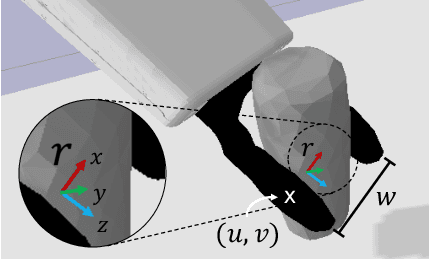
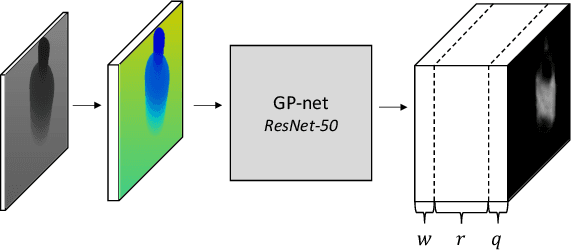
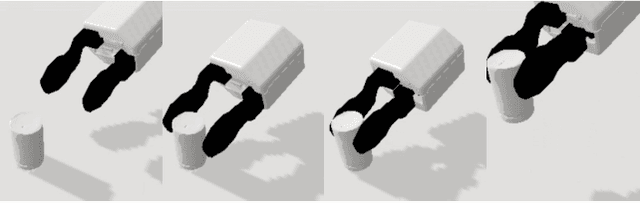
We present the Grasp Proposal Network (GP-net), a Convolutional Neural Network model which can generate 6-DOF grasps for mobile manipulators. To train GP-net, we synthetically generate a dataset containing depth-images and ground-truth grasp information for more than 1400 objects. In real-world experiments we use the EGAD! grasping benchmark to evaluate GP-net against two commonly used algorithms, the Volumetric Grasping Network (VGN) and the Grasp Pose Detection package (GPD), on a PAL TIAGo mobile manipulator. GP-net achieves grasp success rates of 82.2% compared to 57.8% for VGN and 63.3% with GPD. In contrast to the state-of-the-art methods in robotic grasping, GP-net can be used out-of-the-box for grasping objects with mobile manipulators without limiting the workspace, requiring table segmentation or needing a high-end GPU. To encourage the usage of GP-net, we provide a ROS package along with our code and pre-trained models at https://aucoroboticsmu.github.io/GP-net/.
Open-Ended Diverse Solution Discovery with Regulated Behavior Patterns for Cross-Domain Adaptation
Sep 24, 2022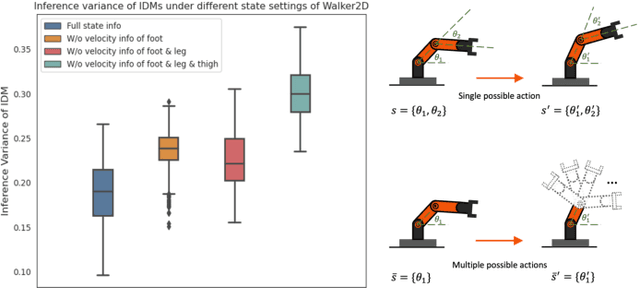
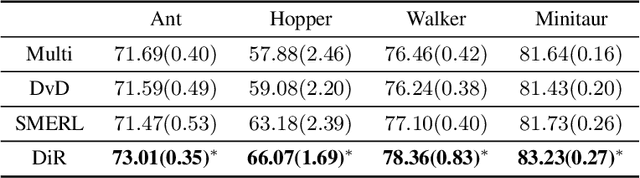
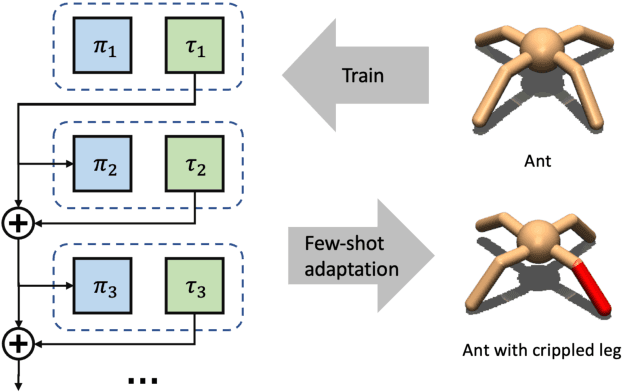
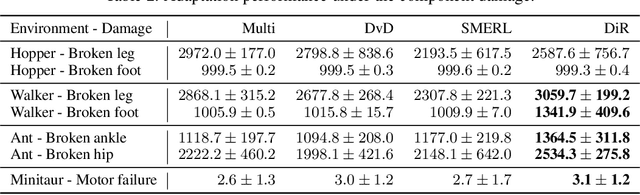
While Reinforcement Learning can achieve impressive results for complex tasks, the learned policies are generally prone to fail in downstream tasks with even minor model mismatch or unexpected perturbations. Recent works have demonstrated that a policy population with diverse behavior characteristics can generalize to downstream environments with various discrepancies. However, such policies might result in catastrophic damage during the deployment in practical scenarios like real-world systems due to the unrestricted behaviors of trained policies. Furthermore, training diverse policies without regulation of the behavior can result in inadequate feasible policies for extrapolating to a wide range of test conditions with dynamics shifts. In this work, we aim to train diverse policies under the regularization of the behavior patterns. We motivate our paradigm by observing the inverse dynamics in the environment with partial state information and propose Diversity in Regulation(DiR) training diverse policies with regulated behaviors to discover desired patterns that benefit the generalization. Considerable empirical results on various variations of different environments indicate that our method attains improvements over other diversity-driven counterparts.
Large-Scale Multi-Document Summarization with Information Extraction and Compression
May 01, 2022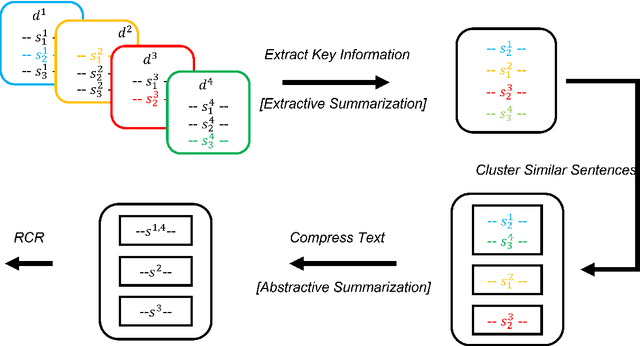
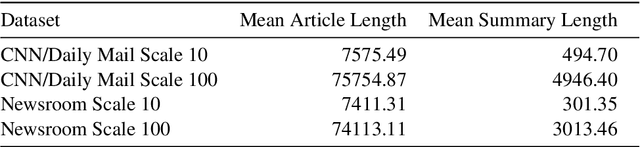
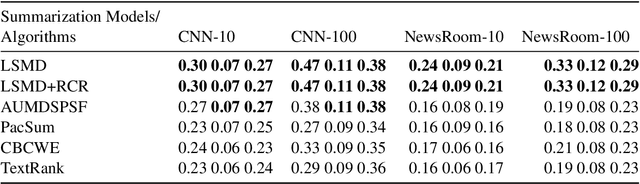
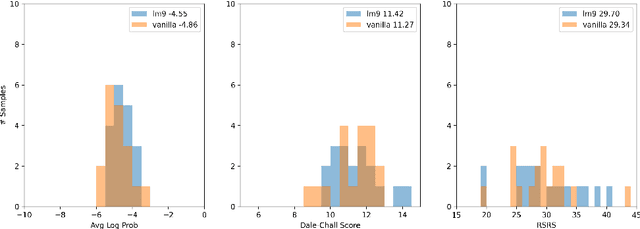
We develop an abstractive summarization framework independent of labeled data for multiple heterogeneous documents. Unlike existing multi-document summarization methods, our framework processes documents telling different stories instead of documents on the same topic. We also enhance an existing sentence fusion method with a uni-directional language model to prioritize fused sentences with higher sentence probability with the goal of increasing readability. Lastly, we construct a total of twelve dataset variations based on CNN/Daily Mail and the NewsRoom datasets, where each document group contains a large and diverse collection of documents to evaluate the performance of our model in comparison with other baseline systems. Our experiments demonstrate that our framework outperforms current state-of-the-art methods in this more generic setting.
FNeVR: Neural Volume Rendering for Face Animation
Sep 21, 2022
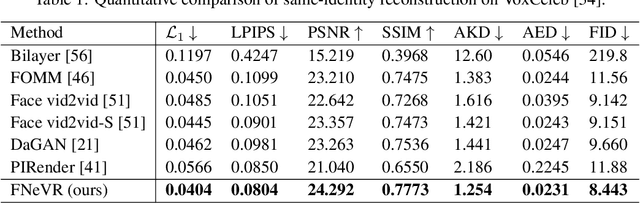
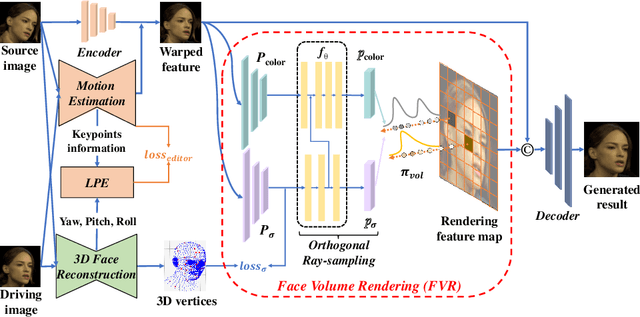
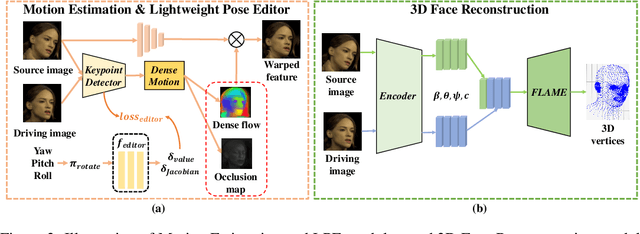
Face animation, one of the hottest topics in computer vision, has achieved a promising performance with the help of generative models. However, it remains a critical challenge to generate identity preserving and photo-realistic images due to the sophisticated motion deformation and complex facial detail modeling. To address these problems, we propose a Face Neural Volume Rendering (FNeVR) network to fully explore the potential of 2D motion warping and 3D volume rendering in a unified framework. In FNeVR, we design a 3D Face Volume Rendering (FVR) module to enhance the facial details for image rendering. Specifically, we first extract 3D information with a well-designed architecture, and then introduce an orthogonal adaptive ray-sampling module for efficient rendering. We also design a lightweight pose editor, enabling FNeVR to edit the facial pose in a simple yet effective way. Extensive experiments show that our FNeVR obtains the best overall quality and performance on widely used talking-head benchmarks.