 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
The Royalflush System for VoxCeleb Speaker Recognition Challenge 2022
Sep 20, 2022
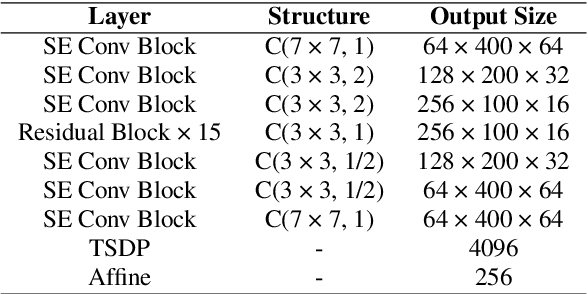
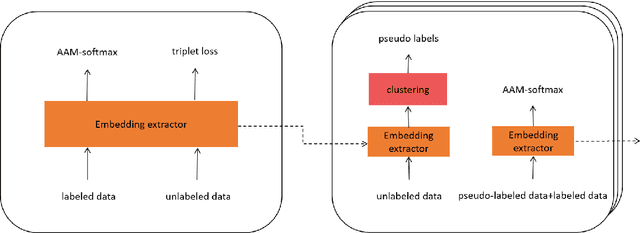
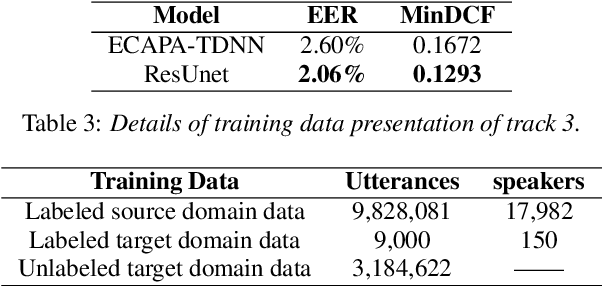

In this technical report, we describe the Royalflush submissions for the VoxCeleb Speaker Recognition Challenge 2022 (VoxSRC-22). Our submissions contain track 1, which is for supervised speaker verification and track 3, which is for semi-supervised speaker verification. For track 1, we develop a powerful U-Net-based speaker embedding extractor with a symmetric architecture. The proposed system achieves 2.06% in EER and 0.1293 in MinDCF on the validation set. Compared with the state-of-the-art ECAPA-TDNN, it obtains a relative improvement of 20.7% in EER and 22.70% in MinDCF. For track 3, we employ the joint training of source domain supervision and target domain self-supervision to get a speaker embedding extractor. The subsequent clustering process can obtain target domain pseudo-speaker labels. We adapt the speaker embedding extractor using all source and target domain data in a supervised manner, where it can fully leverage both domain information. Moreover, clustering and supervised domain adaptation can be repeated until the performance converges on the validation set. Our final submission is a fusion of 10 models and achieves 7.75% EER and 0.3517 MinDCF on the validation set.
Intercepting A Flying Target While Avoiding Moving Obstacles: A Unified Control Framework With Deep Manifold Learning
Sep 27, 2022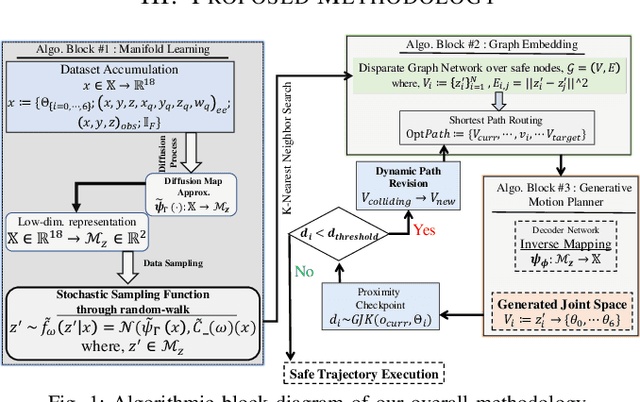
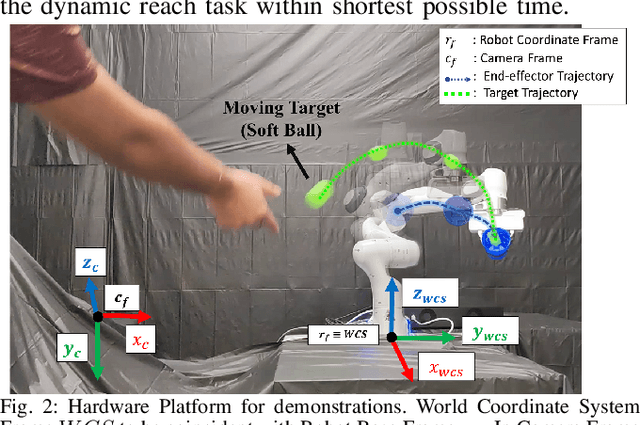
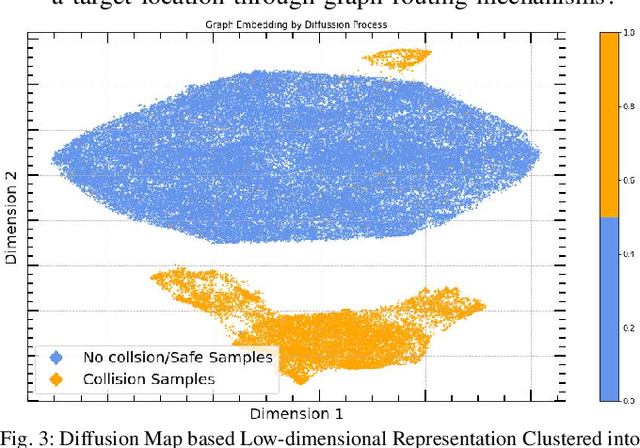
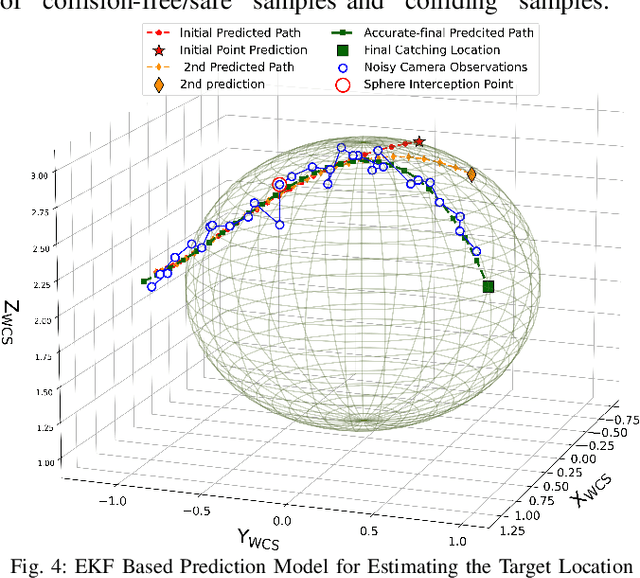
Real-time interception of a fast-moving object by a robotic arm in cluttered environments filled with static or dynamic obstacles permits only tens of milliseconds for reaction times, hence quite challenging and arduous for state-of-the-art robotic planning algorithms to perform multiple robotic skills, for instance, catching the dynamic object and avoiding obstacles, in parallel. This paper proposes an unified framework of robotic path planning through embedding the high-dimensional temporal information contained in the event stream to distinguish between safe and colliding trajectories into a low-dimension space manifested with a pre-constructed 2D densely connected graph. We then leverage a fast graph-traversing strategy to generate the motor commands necessary to effectively avoid the approaching obstacles while simultaneously intercepting a fast-moving objects. The most distinctive feature of our methodology is to conduct both object interception and obstacle avoidance within the same algorithm framework based on deep manifold learning. By leveraging a highly efficient diffusion-map based variational autoencoding and Extended Kalman Filter(EKF), we demonstrate the effectiveness of our approach on an autonomous 7-DoF robotic arm using only onboard sensing and computation. Our robotic manipulator was capable of avoiding multiple obstacles of different sizes and shapes while successfully capturing a fast-moving soft ball thrown by hand at normal speed in different angles. Complete video demonstrations of our experiments can be found in https://sites.google.com/view/multirobotskill/home.
UIT-ViCoV19QA: A Dataset for COVID-19 Community-based Question Answering on Vietnamese Language
Sep 14, 2022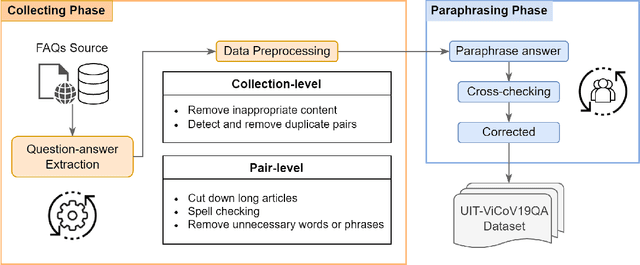
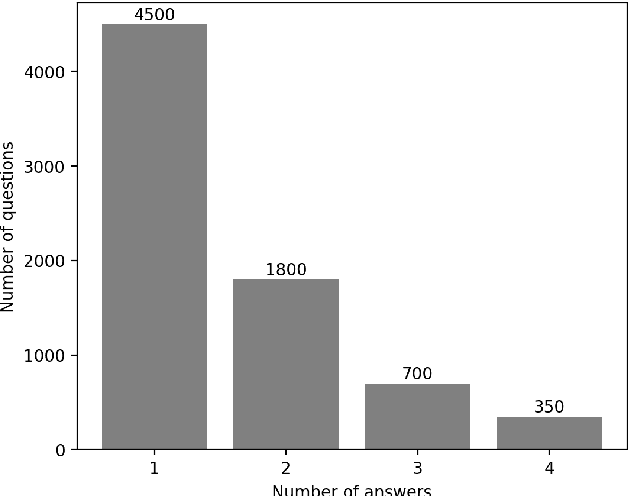
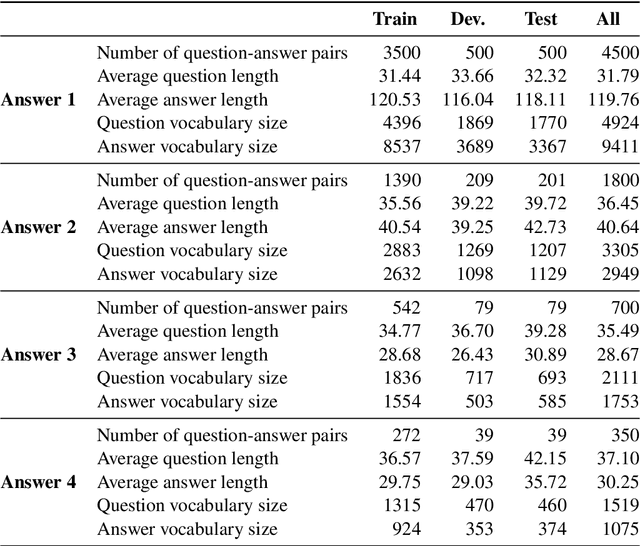
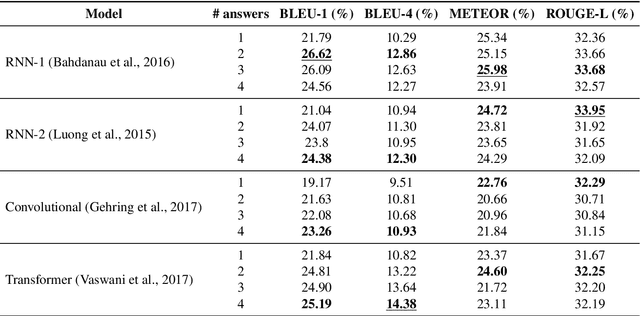
For the last two years, from 2020 to 2021, COVID-19 has broken disease prevention measures in many countries, including Vietnam, and negatively impacted various aspects of human life and the social community. Besides, the misleading information in the community and fake news about the pandemic are also serious situations. Therefore, we present the first Vietnamese community-based question answering dataset for developing question answering systems for COVID-19 called UIT-ViCoV19QA. The dataset comprises 4,500 question-answer pairs collected from trusted medical sources, with at least one answer and at most four unique paraphrased answers per question. Along with the dataset, we set up various deep learning models as baseline to assess the quality of our dataset and initiate the benchmark results for further research through commonly used metrics such as BLEU, METEOR, and ROUGE-L. We also illustrate the positive effects of having multiple paraphrased answers experimented on these models, especially on Transformer - a dominant architecture in the field of study.
GraphTTA: Test Time Adaptation on Graph Neural Networks
Aug 19, 2022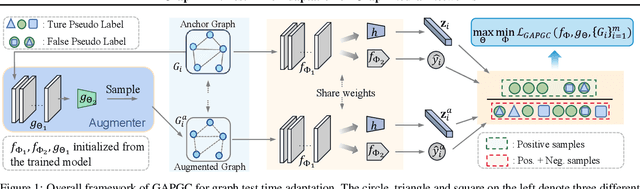
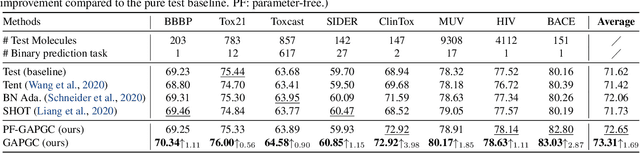
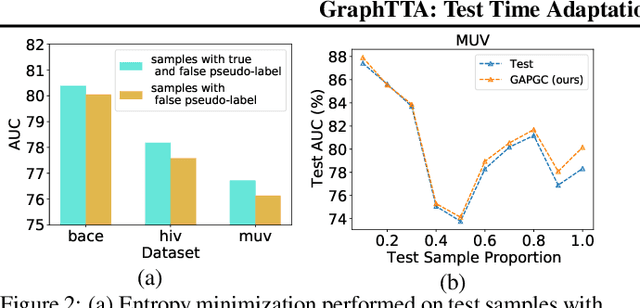

Recently, test time adaptation (TTA) has attracted increasing attention due to its power of handling the distribution shift issue in the real world. Unlike what has been developed for convolutional neural networks (CNNs) for image data, TTA is less explored for Graph Neural Networks (GNNs). There is still a lack of efficient algorithms tailored for graphs with irregular structures. In this paper, we present a novel test time adaptation strategy named Graph Adversarial Pseudo Group Contrast (GAPGC), for graph neural networks TTA, to better adapt to the Out Of Distribution (OOD) test data. Specifically, GAPGC employs a contrastive learning variant as a self-supervised task during TTA, equipped with Adversarial Learnable Augmenter and Group Pseudo-Positive Samples to enhance the relevance between the self-supervised task and the main task, boosting the performance of the main task. Furthermore, we provide theoretical evidence that GAPGC can extract minimal sufficient information for the main task from information theory perspective. Extensive experiments on molecular scaffold OOD dataset demonstrated that the proposed approach achieves state-of-the-art performance on GNNs.
Active Particle Filter Networks: Efficient Active Localization in Continuous Action Spaces and Large Maps
Sep 20, 2022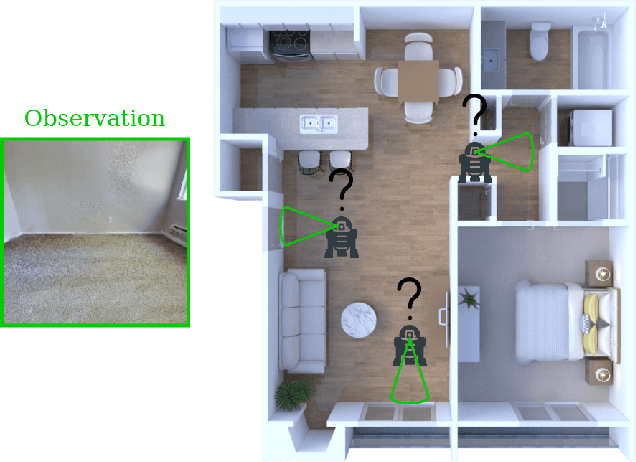
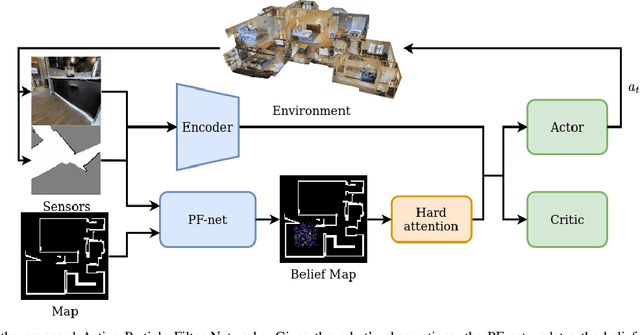
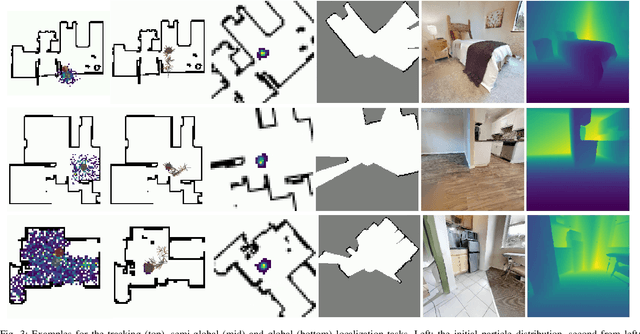
Accurate localization is a critical requirement for most robotic tasks. The main body of existing work is focused on passive localization in which the motions of the robot are assumed given, abstracting from their influence on sampling informative observations. While recent work has shown the benefits of learning motions to disambiguate the robot's poses, these methods are restricted to granular discrete actions and directly depend on the size of the global map. We propose Active Particle Filter Networks (APFN), an approach that only relies on local information for both the likelihood evaluation as well as the decision making. To do so, we couple differentiable particle filters with a reinforcement learning agent that attends to the most relevant parts of the map. The resulting approach inherits the computational benefits of particle filters and can directly act in continuous action spaces while remaining fully differentiable and thereby end-to-end optimizable as well as agnostic to the input modality. We demonstrate the benefits of our approach with extensive experiments in photorealistic indoor environments built from real-world 3D scanned apartments. Videos and code are available at http://apfn.cs.uni-freiburg.de.
Distributed Multi-Robot Obstacle Avoidance via Logarithmic Map-based Deep Reinforcement Learning
Sep 14, 2022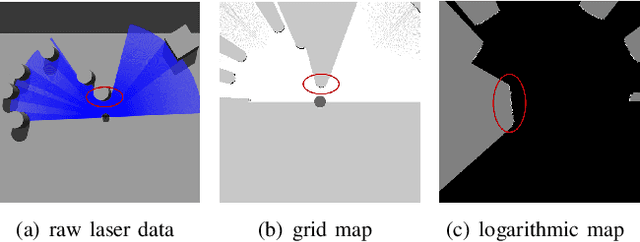

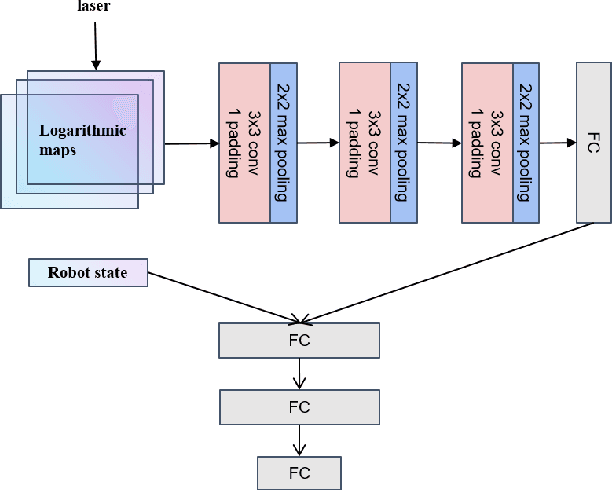
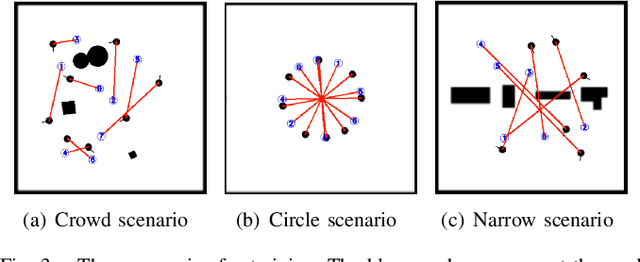
Developing a safe, stable, and efficient obstacle avoidance policy in crowded and narrow scenarios for multiple robots is challenging. Most existing studies either use centralized control or need communication with other robots. In this paper, we propose a novel logarithmic map-based deep reinforcement learning method for obstacle avoidance in complex and communication-free multi-robot scenarios. In particular, our method converts laser information into a logarithmic map. As a step toward improving training speed and generalization performance, our policies will be trained in two specially designed multi-robot scenarios. Compared to other methods, the logarithmic map can represent obstacles more accurately and improve the success rate of obstacle avoidance. We finally evaluate our approach under a variety of simulation and real-world scenarios. The results show that our method provides a more stable and effective navigation solution for robots in complex multi-robot scenarios and pedestrian scenarios. Videos are available at https://youtu.be/r0EsUXe6MZE.
Active Gaze Control for Foveal Scene Exploration
Aug 24, 2022
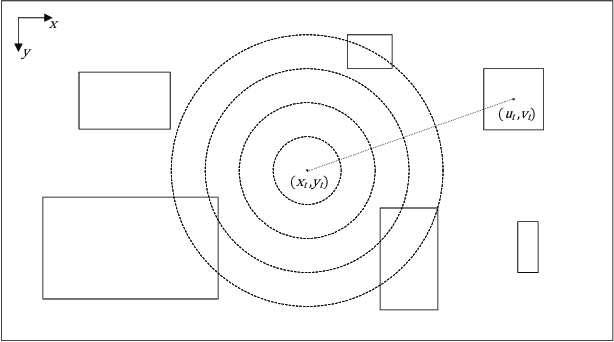
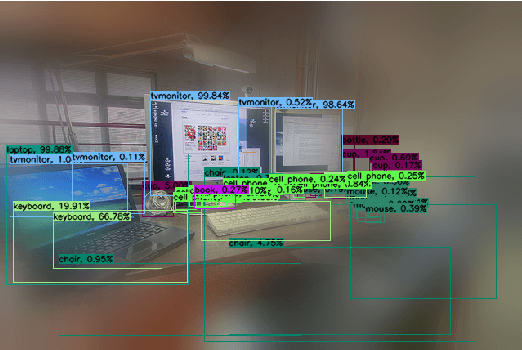

Active perception and foveal vision are the foundations of the human visual system. While foveal vision reduces the amount of information to process during a gaze fixation, active perception will change the gaze direction to the most promising parts of the visual field. We propose a methodology to emulate how humans and robots with foveal cameras would explore a scene, identifying the objects present in their surroundings with in least number of gaze shifts. Our approach is based on three key methods. First, we take an off-the-shelf deep object detector, pre-trained on a large dataset of regular images, and calibrate the classification outputs to the case of foveated images. Second, a body-centered semantic map, encoding the objects classifications and corresponding uncertainties, is sequentially updated with the calibrated detections, considering several data fusion techniques. Third, the next best gaze fixation point is determined based on information-theoretic metrics that aim at minimizing the overall expected uncertainty of the semantic map. When compared to the random selection of next gaze shifts, the proposed method achieves an increase in detection F1-score of 2-3 percentage points for the same number of gaze shifts and reduces to one third the number of required gaze shifts to attain similar performance.
Overparameterized (robust) models from computational constraints
Aug 27, 2022Overparameterized models with millions of parameters have been hugely successful. In this work, we ask: can the need for large models be, at least in part, due to the \emph{computational} limitations of the learner? Additionally, we ask, is this situation exacerbated for \emph{robust} learning? We show that this indeed could be the case. We show learning tasks for which computationally bounded learners need \emph{significantly more} model parameters than what information-theoretic learners need. Furthermore, we show that even more model parameters could be necessary for robust learning. In particular, for computationally bounded learners, we extend the recent result of Bubeck and Sellke [NeurIPS'2021] which shows that robust models might need more parameters, to the computational regime and show that bounded learners could provably need an even larger number of parameters. Then, we address the following related question: can we hope to remedy the situation for robust computationally bounded learning by restricting \emph{adversaries} to also be computationally bounded for sake of obtaining models with fewer parameters? Here again, we show that this could be possible. Specifically, building on the work of Garg, Jha, Mahloujifar, and Mahmoody [ALT'2020], we demonstrate a learning task that can be learned efficiently and robustly against a computationally bounded attacker, while to be robust against an information-theoretic attacker requires the learner to utilize significantly more parameters.
Partially Observable RL with B-Stability: Unified Structural Condition and Sharp Sample-Efficient Algorithms
Sep 29, 2022
Partial Observability -- where agents can only observe partial information about the true underlying state of the system -- is ubiquitous in real-world applications of Reinforcement Learning (RL). Theoretically, learning a near-optimal policy under partial observability is known to be hard in the worst case due to an exponential sample complexity lower bound. Recent work has identified several tractable subclasses that are learnable with polynomial samples, such as Partially Observable Markov Decision Processes (POMDPs) with certain revealing or decodability conditions. However, this line of research is still in its infancy, where (1) unified structural conditions enabling sample-efficient learning are lacking; (2) existing sample complexities for known tractable subclasses are far from sharp; and (3) fewer sample-efficient algorithms are available than in fully observable RL. This paper advances all three aspects above for Partially Observable RL in the general setting of Predictive State Representations (PSRs). First, we propose a natural and unified structural condition for PSRs called \emph{B-stability}. B-stable PSRs encompasses the vast majority of known tractable subclasses such as weakly revealing POMDPs, low-rank future-sufficient POMDPs, decodable POMDPs, and regular PSRs. Next, we show that any B-stable PSR can be learned with polynomial samples in relevant problem parameters. When instantiated in the aforementioned subclasses, our sample complexities improve substantially over the current best ones. Finally, our results are achieved by three algorithms simultaneously: Optimistic Maximum Likelihood Estimation, Estimation-to-Decisions, and Model-Based Optimistic Posterior Sampling. The latter two algorithms are new for sample-efficient learning of POMDPs/PSRs.
Where is Memory Information Stored in the Brain?
Dec 10, 2021Within the scientific research community, memory information in the brain is commonly believed to be stored in the synapse - a hypothesis famously attributed to psychologist Donald Hebb. However, there is a growing minority who postulate that memory is stored inside the neuron at the molecular (RNA or DNA) level - an alternative postulation known as the cell-intrinsic hypothesis, coined by psychologist Randy Gallistel. In this paper, we review a selection of key experimental evidence from both sides of the argument. We begin with Eric Kandel's studies on sea slugs, which provided the first evidence in support of the synaptic hypothesis. Next, we touch on experiments in mice by John O'Keefe (declarative memory and the hippocampus) and Joseph LeDoux (procedural fear memory and the amygdala). Then, we introduce the synapse as the basic building block of today's artificial intelligence neural networks. After that, we describe David Glanzman's study on dissociating memory storage and synaptic change in sea slugs, and Susumu Tonegawa's experiment on reactivating retrograde amnesia in mice using laser. From there, we highlight Germund Hesslow's experiment on conditioned pauses in ferrets, and Beatrice Gelber's experiment on conditioning in single-celled organisms without synapses (Paramecium aurelia). This is followed by a description of David Glanzman's experiment on transplanting memory between sea slugs using RNA. Finally, we provide an overview of Brian Dias and Kerry Ressler's experiment on DNA transfer of fear in mice from parents to offspring. We conclude with some potential implications for the wider field of psychology.