 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Fairness via AI: Bias Reduction in Medical Information
Sep 06, 2021
Most Fairness in AI research focuses on exposing biases in AI systems. A broader lens on fairness reveals that AI can serve a greater aspiration: rooting out societal inequities from their source. Specifically, we focus on inequities in health information, and aim to reduce bias in that domain using AI. The AI algorithms under the hood of search engines and social media, many of which are based on recommender systems, have an outsized impact on the quality of medical and health information online. Therefore, embedding bias detection and reduction into these recommender systems serving up medical and health content online could have an outsized positive impact on patient outcomes and wellbeing. In this position paper, we offer the following contributions: (1) we propose a novel framework of Fairness via AI, inspired by insights from medical education, sociology and antiracism; (2) we define a new term, bisinformation, which is related to, but distinct from, misinformation, and encourage researchers to study it; (3) we propose using AI to study, detect and mitigate biased, harmful, and/or false health information that disproportionately hurts minority groups in society; and (4) we suggest several pillars and pose several open problems in order to seed inquiry in this new space. While part (3) of this work specifically focuses on the health domain, the fundamental computer science advances and contributions stemming from research efforts in bias reduction and Fairness via AI have broad implications in all areas of society.
A Local Optimization Framework for Multi-Objective Ergodic Search
Jul 06, 2022
Robots have the potential to perform search for a variety of applications under different scenarios. Our work is motivated by humanitarian assistant and disaster relief (HADR) where often it is critical to find signs of life in the presence of conflicting criteria, objectives, and information. We believe ergodic search can provide a framework for exploiting available information as well as exploring for new information for applications such as HADR, especially when time is of the essence. Ergodic search algorithms plan trajectories such that the time spent in a region is proportional to the amount of information in that region, and is able to naturally balance exploitation (myopically searching high-information areas) and exploration (visiting all locations in the search space for new information). Existing ergodic search algorithms, as well as other information-based approaches, typically consider search using only a single information map. However, in many scenarios, the use of multiple information maps that encode different types of relevant information is common. Ergodic search methods currently do not possess the ability for simultaneous nor do they have a way to balance which information gets priority. This leads us to formulate a Multi-Objective Ergodic Search (MOES) problem, which aims at finding the so-called Pareto-optimal solutions, for the purpose of providing human decision makers various solutions that trade off between conflicting criteria. To efficiently solve MOES, we develop a framework called Sequential Local Ergodic Search (SLES) that converts a MOES problem into a "weight space coverage" problem. It leverages the recent advances in ergodic search methods as well as the idea of local optimization to efficiently approximate the Pareto-optimal front. Our numerical results show that SLES runs distinctly faster than the baseline methods.
A Deep Neural Network for Multiclass Bridge Element Parsing in Inspection Image Analysis
Sep 05, 2022
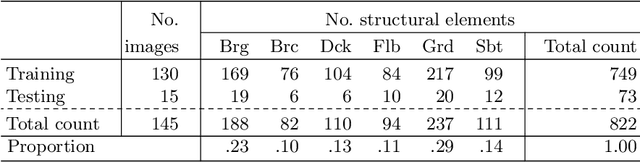


Aerial robots such as drones have been leveraged to perform bridge inspections. Inspection images with both recognizable structural elements and apparent surface defects can be collected by onboard cameras to provide valuable information for the condition assessment. This article aims to determine a suitable deep neural network (DNN) for parsing multiclass bridge elements in inspection images. An extensive set of quantitative evaluations along with qualitative examples show that High-Resolution Net (HRNet) possesses the desired ability. With data augmentation and a training sample of 130 images, a pre-trained HRNet is efficiently transferred to the task of structural element parsing and has achieved a 92.67% mean F1-score and 86.33% mean IoU.
A Tent Lévy Flying Sparrow Search Algorithm for Feature Selection: A COVID-19 Case Study
Sep 20, 2022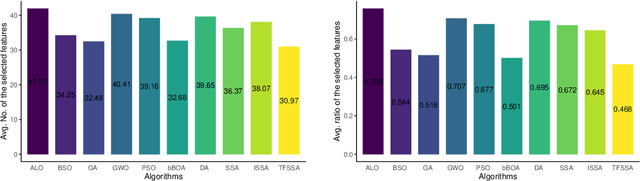
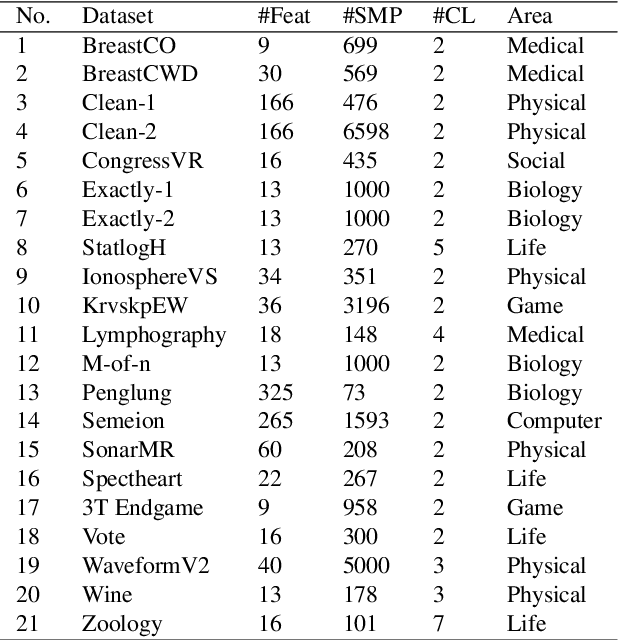

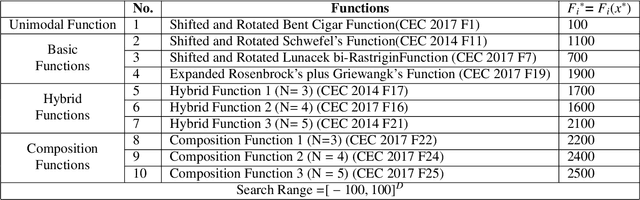
The "Curse of Dimensionality" induced by the rapid development of information science, might have a negative impact when dealing with big datasets. In this paper, we propose a variant of the sparrow search algorithm (SSA), called Tent L\'evy flying sparrow search algorithm (TFSSA), and use it to select the best subset of features in the packing pattern for classification purposes. SSA is a recently proposed algorithm that has not been systematically applied to feature selection problems. After verification by the CEC2020 benchmark function, TFSSA is used to select the best feature combination to maximize classification accuracy and minimize the number of selected features. The proposed TFSSA is compared with nine algorithms in the literature. Nine evaluation metrics are used to properly evaluate and compare the performance of these algorithms on twenty-one datasets from the UCI repository. Furthermore, the approach is applied to the coronavirus disease (COVID-19) dataset, yielding the best average classification accuracy and the average number of feature selections, respectively, of 93.47% and 2.1. Experimental results confirm the advantages of the proposed algorithm in improving classification accuracy and reducing the number of selected features compared to other wrapper-based algorithms.
Intercepting A Flying Target While Avoiding Moving Obstacles: A Unified Control Framework With Deep Manifold Learning
Sep 27, 2022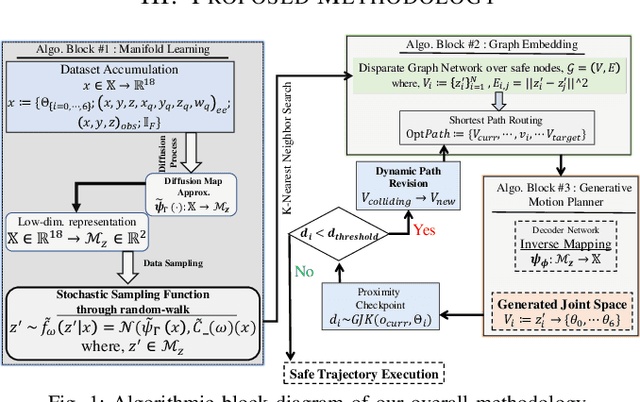
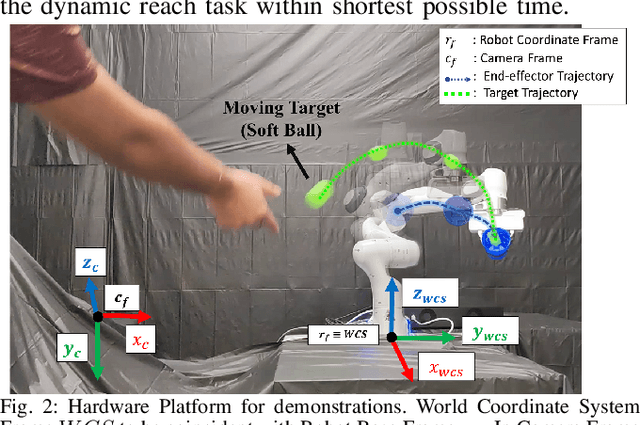
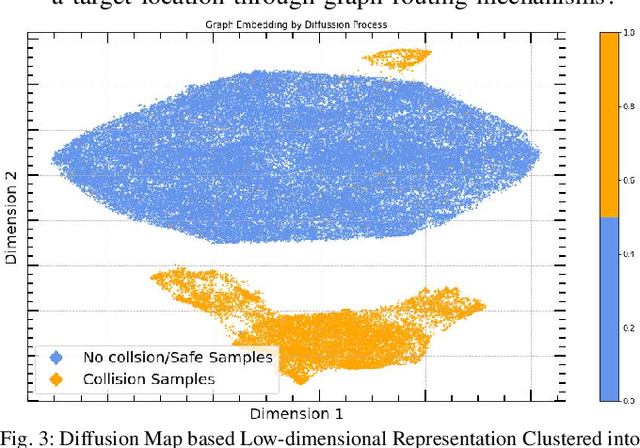
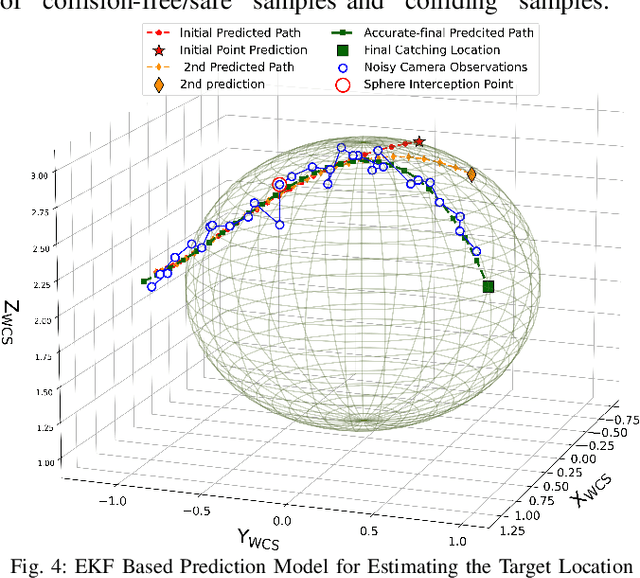
Real-time interception of a fast-moving object by a robotic arm in cluttered environments filled with static or dynamic obstacles permits only tens of milliseconds for reaction times, hence quite challenging and arduous for state-of-the-art robotic planning algorithms to perform multiple robotic skills, for instance, catching the dynamic object and avoiding obstacles, in parallel. This paper proposes an unified framework of robotic path planning through embedding the high-dimensional temporal information contained in the event stream to distinguish between safe and colliding trajectories into a low-dimension space manifested with a pre-constructed 2D densely connected graph. We then leverage a fast graph-traversing strategy to generate the motor commands necessary to effectively avoid the approaching obstacles while simultaneously intercepting a fast-moving objects. The most distinctive feature of our methodology is to conduct both object interception and obstacle avoidance within the same algorithm framework based on deep manifold learning. By leveraging a highly efficient diffusion-map based variational autoencoding and Extended Kalman Filter(EKF), we demonstrate the effectiveness of our approach on an autonomous 7-DoF robotic arm using only onboard sensing and computation. Our robotic manipulator was capable of avoiding multiple obstacles of different sizes and shapes while successfully capturing a fast-moving soft ball thrown by hand at normal speed in different angles. Complete video demonstrations of our experiments can be found in https://sites.google.com/view/multirobotskill/home.
Improving Conversational Recommender System via Contextual and Time-Aware Modeling with Less Domain-Specific Knowledge
Sep 23, 2022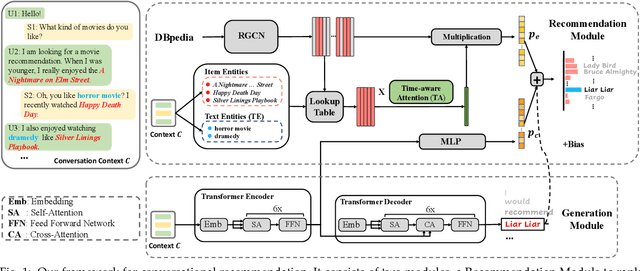
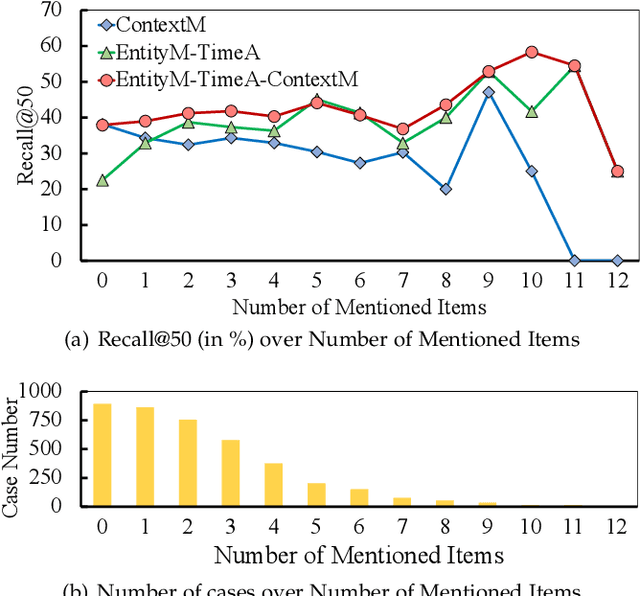
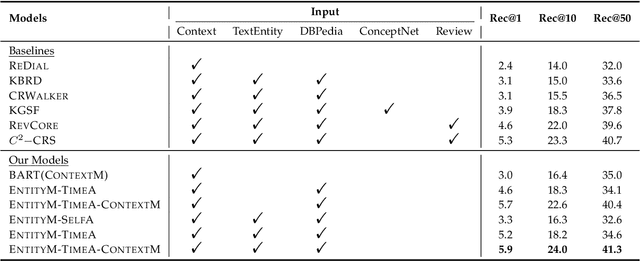
Conversational Recommender Systems (CRS) has become an emerging research topic seeking to perform recommendations through interactive conversations, which generally consist of generation and recommendation modules. Prior work on CRS tends to incorporate more external and domain-specific knowledge like item reviews to enhance performance. Despite the fact that the collection and annotation of the external domain-specific information needs much human effort and degenerates the generalizability, too much extra knowledge introduces more difficulty to balance among them. Therefore, we propose to fully discover and extract internal knowledge from the context. We capture both entity-level and contextual-level representations to jointly model user preferences for the recommendation, where a time-aware attention is designed to emphasize the recently appeared items in entity-level representations. We further use the pre-trained BART to initialize the generation module to alleviate the data scarcity and enhance the context modeling. In addition to conducting experiments on a popular dataset (ReDial), we also include a multi-domain dataset (OpenDialKG) to show the effectiveness of our model. Experiments on both datasets show that our model achieves better performance on most evaluation metrics with less external knowledge and generalizes well to other domains. Additional analyses on the recommendation and generation tasks demonstrate the effectiveness of our model in different scenarios.
Non-Coherent Massive MIMO Integration in Satellite Communication
Sep 20, 2022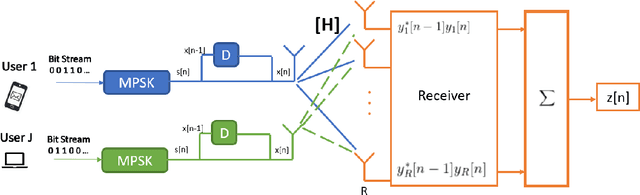
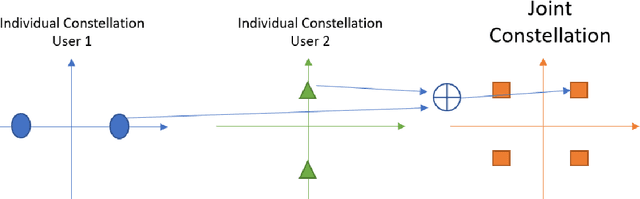

Massive Multiple Input-Multiple Output (mMIMO) technique has been considered an efficient standard to improve the transmission rate significantly for the following wireless communication systems, such as 5G and beyond. However, implementing this technology has been facing a critical issue of acquiring much channel state information. Primarily, this problem becomes more criticising in the integrated satellite and terrestrial networks (3GPP-Release 15) due to the countable high transmission delay. To deal with this challenging problem, the mMIMO-empowered non-coherent technique can be a promising solution. To our best knowledge, this paper is the first work considering employing the non-coherent mMIMO in satellite communication systems. This work aims to analyse the challenges and opportunities emerging with this integration. Moreover, we identified the issues in this conjunction. The preliminary results presented in this work show that the performance measured in bit error rate (BER) and the number of antennas are not far from that required for terrestrial links. Furthermore, thanks to mMIMO in conjunction with the non-coherent approach, we can work in a low signal-to-noise ratio (SNR) regime, which is an excellent advantage for satellite links.
Switchable Self-attention Module
Sep 13, 2022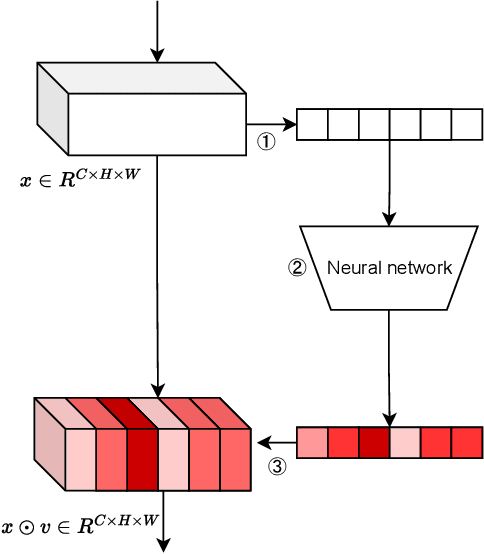
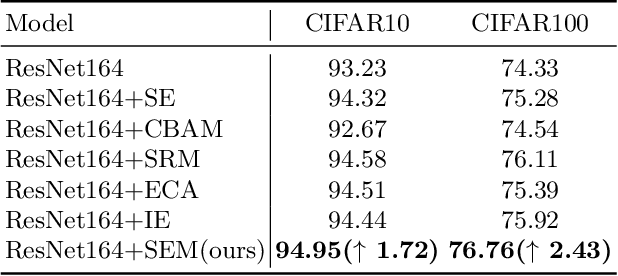
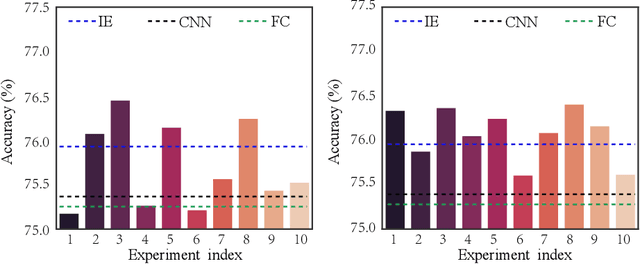
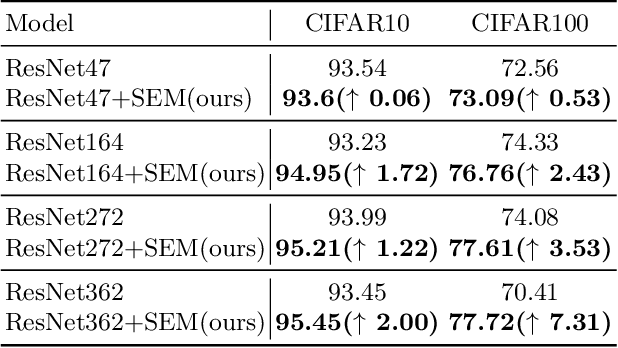
Attention mechanism has gained great success in vision recognition. Many works are devoted to improving the effectiveness of attention mechanism, which finely design the structure of the attention operator. These works need lots of experiments to pick out the optimal settings when scenarios change, which consumes a lot of time and computational resources. In addition, a neural network often contains many network layers, and most studies often use the same attention module to enhance different network layers, which hinders the further improvement of the performance of the self-attention mechanism. To address the above problems, we propose a self-attention module SEM. Based on the input information of the attention module and alternative attention operators, SEM can automatically decide to select and integrate attention operators to compute attention maps. The effectiveness of SEM is demonstrated by extensive experiments on widely used benchmark datasets and popular self-attention networks.
The Royalflush System for VoxCeleb Speaker Recognition Challenge 2022
Sep 20, 2022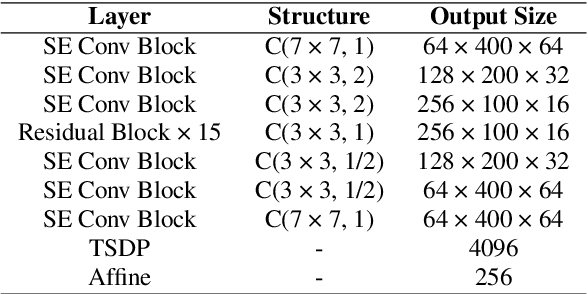
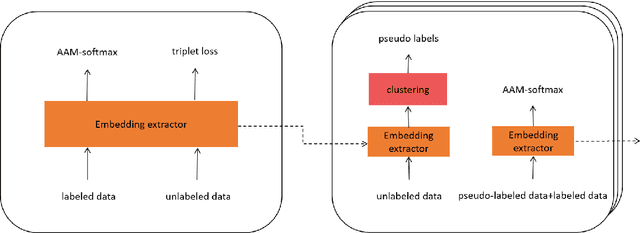
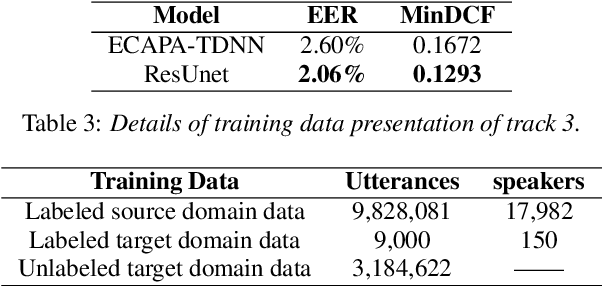

In this technical report, we describe the Royalflush submissions for the VoxCeleb Speaker Recognition Challenge 2022 (VoxSRC-22). Our submissions contain track 1, which is for supervised speaker verification and track 3, which is for semi-supervised speaker verification. For track 1, we develop a powerful U-Net-based speaker embedding extractor with a symmetric architecture. The proposed system achieves 2.06% in EER and 0.1293 in MinDCF on the validation set. Compared with the state-of-the-art ECAPA-TDNN, it obtains a relative improvement of 20.7% in EER and 22.70% in MinDCF. For track 3, we employ the joint training of source domain supervision and target domain self-supervision to get a speaker embedding extractor. The subsequent clustering process can obtain target domain pseudo-speaker labels. We adapt the speaker embedding extractor using all source and target domain data in a supervised manner, where it can fully leverage both domain information. Moreover, clustering and supervised domain adaptation can be repeated until the performance converges on the validation set. Our final submission is a fusion of 10 models and achieves 7.75% EER and 0.3517 MinDCF on the validation set.
Active Particle Filter Networks: Efficient Active Localization in Continuous Action Spaces and Large Maps
Sep 20, 2022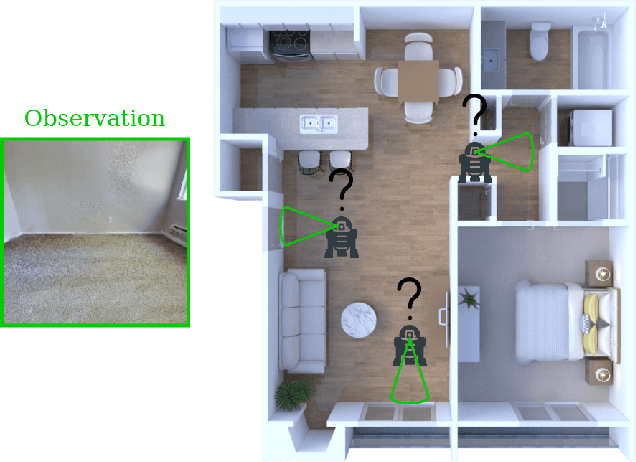
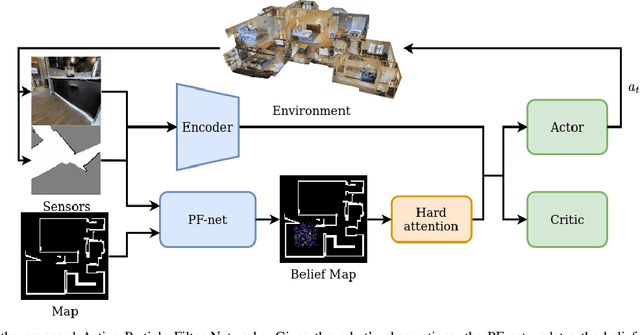
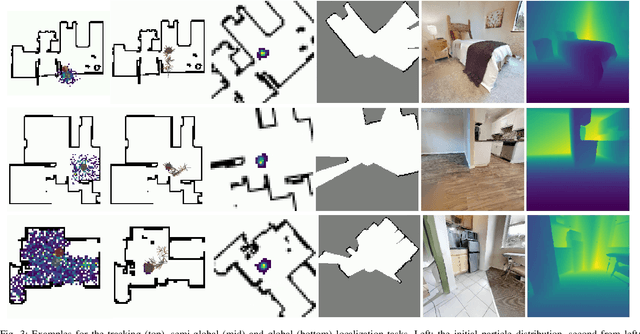
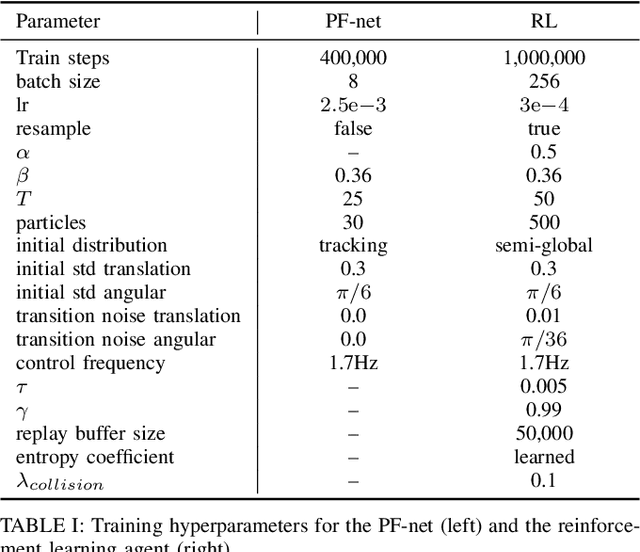
Accurate localization is a critical requirement for most robotic tasks. The main body of existing work is focused on passive localization in which the motions of the robot are assumed given, abstracting from their influence on sampling informative observations. While recent work has shown the benefits of learning motions to disambiguate the robot's poses, these methods are restricted to granular discrete actions and directly depend on the size of the global map. We propose Active Particle Filter Networks (APFN), an approach that only relies on local information for both the likelihood evaluation as well as the decision making. To do so, we couple differentiable particle filters with a reinforcement learning agent that attends to the most relevant parts of the map. The resulting approach inherits the computational benefits of particle filters and can directly act in continuous action spaces while remaining fully differentiable and thereby end-to-end optimizable as well as agnostic to the input modality. We demonstrate the benefits of our approach with extensive experiments in photorealistic indoor environments built from real-world 3D scanned apartments. Videos and code are available at http://apfn.cs.uni-freiburg.de.