 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Principled Evaluation Protocol for Comparative Investigation of the Effectiveness of DNN Classification Models on Similar-but-non-identical Datasets
Sep 05, 2022
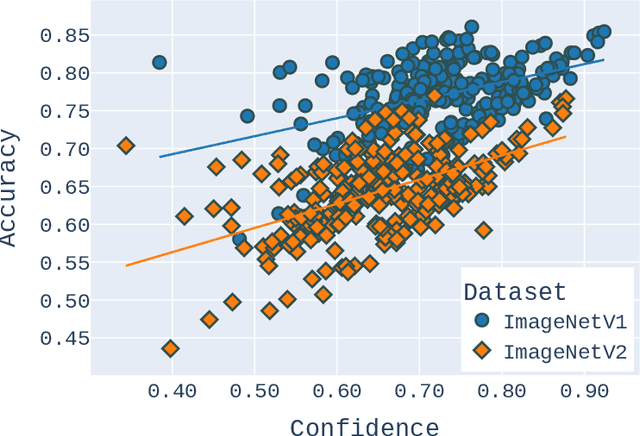


Deep Neural Network (DNN) models are increasingly evaluated using new replication test datasets, which have been carefully created to be similar to older and popular benchmark datasets. However, running counter to expectations, DNN classification models show significant, consistent, and largely unexplained degradation in accuracy on these replication test datasets. While the popular evaluation approach is to assess the accuracy of a model by making use of all the datapoints available in the respective test datasets, we argue that doing so hinders us from adequately capturing the behavior of DNN models and from having realistic expectations about their accuracy. Therefore, we propose a principled evaluation protocol that is suitable for performing comparative investigations of the accuracy of a DNN model on multiple test datasets, leveraging subsets of datapoints that can be selected using different criteria, including uncertainty-related information. By making use of this new evaluation protocol, we determined the accuracy of $564$ DNN models on both (1) the CIFAR-10 and ImageNet datasets and (2) their replication datasets. Our experimental results indicate that the observed accuracy degradation between established benchmark datasets and their replications is consistently lower (that is, models do perform better on the replication test datasets) than the accuracy degradation reported in published works, with these published works relying on conventional evaluation approaches that do not utilize uncertainty-related information.
Diffusion Adversarial Representation Learning for Self-supervised Vessel Segmentation
Sep 29, 2022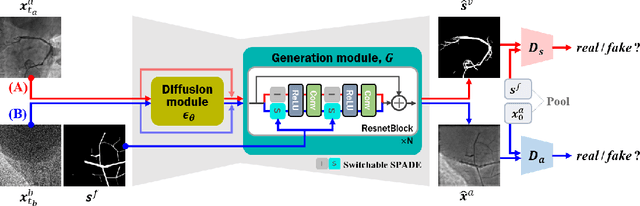
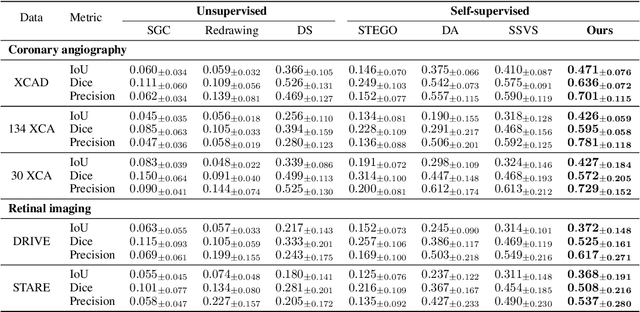
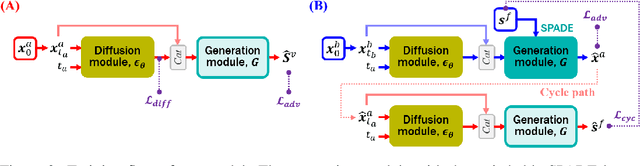
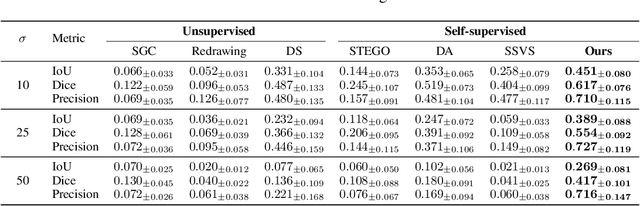
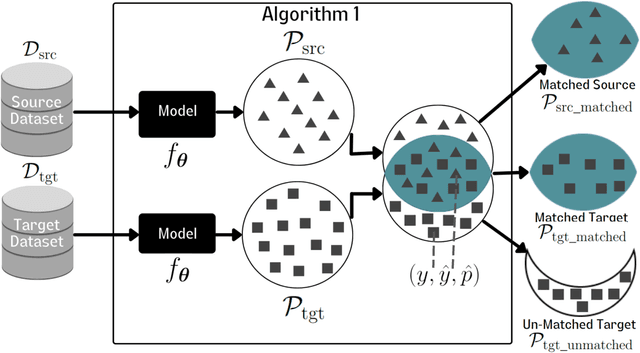
Vessel segmentation in medical images is one of the important tasks in the diagnosis of vascular diseases and therapy planning. Although learning-based segmentation approaches have been extensively studied, a large amount of ground-truth labels are required in supervised methods and confusing background structures make neural networks hard to segment vessels in an unsupervised manner. To address this, here we introduce a novel diffusion adversarial representation learning (DARL) model that leverages a denoising diffusion probabilistic model with adversarial learning, and apply it for vessel segmentation. In particular, for self-supervised vessel segmentation, DARL learns background image distribution using a diffusion module, which lets a generation module effectively provide vessel representations. Also, by adversarial learning based on the proposed switchable spatially-adaptive denormalization, our model estimates synthetic fake vessel images as well as vessel segmentation masks, which further makes the model capture vessel-relevant semantic information. Once the proposed model is trained, the model generates segmentation masks by one step and can be applied to general vascular structure segmentation of coronary angiography and retinal images. Experimental results on various datasets show that our method significantly outperforms existing unsupervised and self-supervised methods in vessel segmentation.
Multi-scale Attention Network for Single Image Super-Resolution
Sep 29, 2022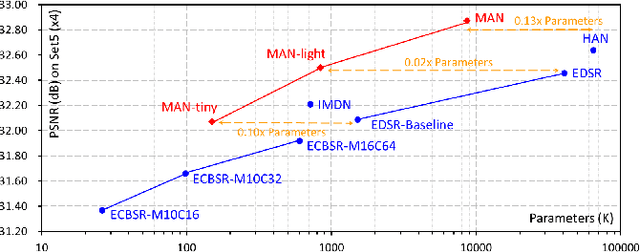
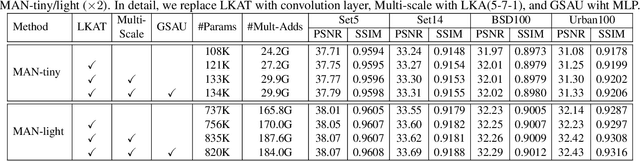

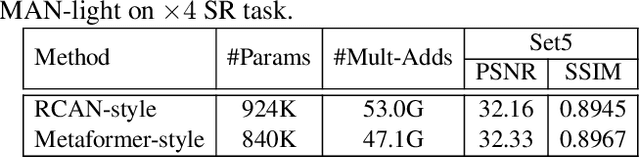
By exploiting large kernel decomposition and attention mechanisms, convolutional neural networks (CNN) can compete with transformer-based methods in many high-level computer vision tasks. However, due to the advantage of long-range modeling, the transformers with self-attention still dominate the low-level vision, including the super-resolution task. In this paper, we propose a CNN-based multi-scale attention network (MAN), which consists of multi-scale large kernel attention (MLKA) and a gated spatial attention unit (GSAU), to improve the performance of convolutional SR networks. Within our MLKA, we rectify LKA with multi-scale and gate schemes to obtain the abundant attention map at various granularity levels, therefore jointly aggregating global and local information and avoiding the potential blocking artifacts. In GSAU, we integrate gate mechanism and spatial attention to remove the unnecessary linear layer and aggregate informative spatial context. To confirm the effectiveness of our designs, we evaluate MAN with multiple complexities by simply stacking different numbers of MLKA and GSAU. Experimental results illustrate that our MAN can achieve varied trade-offs between state-of-the-art performance and computations. Code is available at https://github.com/icandle/MAN.
Edge-Enhanced Dual Discriminator Generative Adversarial Network for Fast MRI with Parallel Imaging Using Multi-view Information
Dec 10, 2021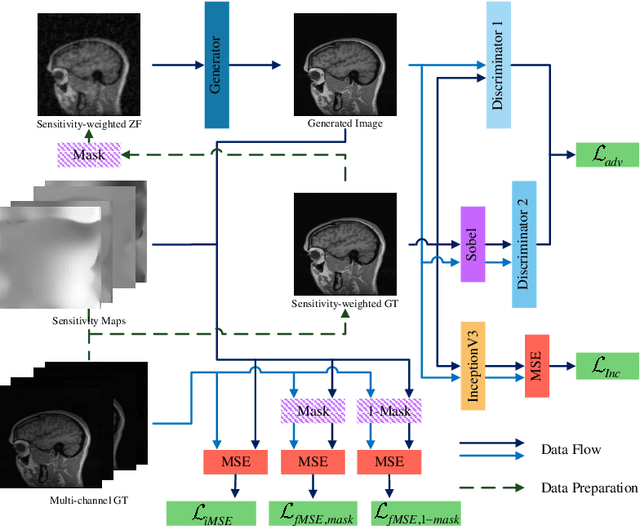
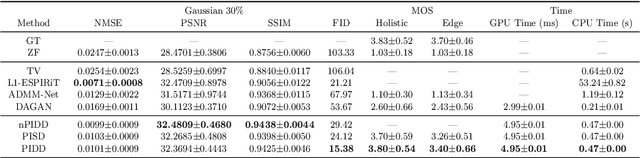
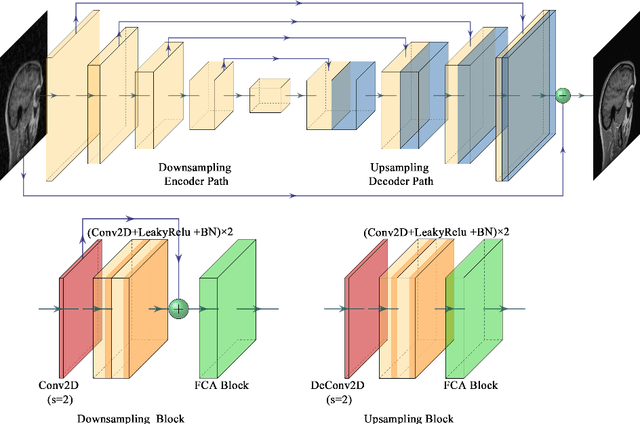
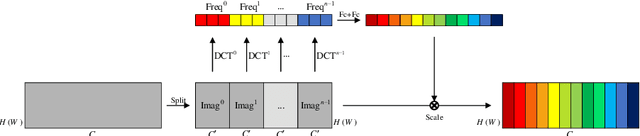
In clinical medicine, magnetic resonance imaging (MRI) is one of the most important tools for diagnosis, triage, prognosis, and treatment planning. However, MRI suffers from an inherent slow data acquisition process because data is collected sequentially in k-space. In recent years, most MRI reconstruction methods proposed in the literature focus on holistic image reconstruction rather than enhancing the edge information. This work steps aside this general trend by elaborating on the enhancement of edge information. Specifically, we introduce a novel parallel imaging coupled dual discriminator generative adversarial network (PIDD-GAN) for fast multi-channel MRI reconstruction by incorporating multi-view information. The dual discriminator design aims to improve the edge information in MRI reconstruction. One discriminator is used for holistic image reconstruction, whereas the other one is responsible for enhancing edge information. An improved U-Net with local and global residual learning is proposed for the generator. Frequency channel attention blocks (FCA Blocks) are embedded in the generator for incorporating attention mechanisms. Content loss is introduced to train the generator for better reconstruction quality. We performed comprehensive experiments on Calgary-Campinas public brain MR dataset and compared our method with state-of-the-art MRI reconstruction methods. Ablation studies of residual learning were conducted on the MICCAI13 dataset to validate the proposed modules. Results show that our PIDD-GAN provides high-quality reconstructed MR images, with well-preserved edge information. The time of single-image reconstruction is below 5ms, which meets the demand of faster processing.
Engineering Semantic Communication: A Survey
Aug 12, 2022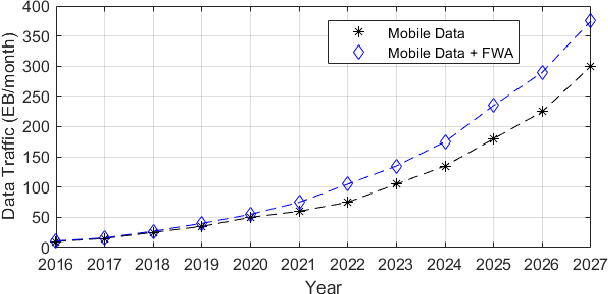

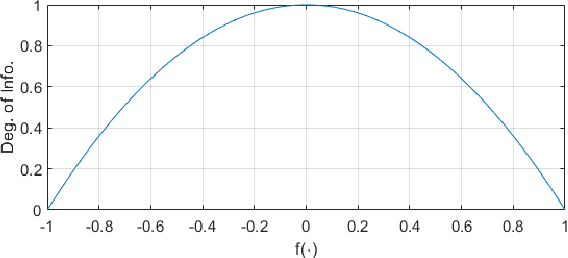
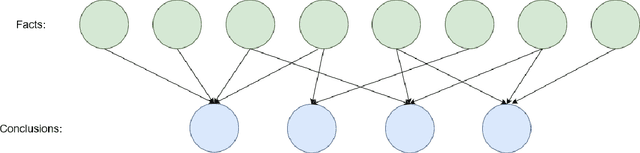
As the global demand for data has continued to rise exponentially, some have begun turning to the idea of semantic communication as a means of efficiently meeting this demand. Pushing beyond the boundaries of conventional communication systems, semantic communication focuses on the accurate recovery of the meaning conveyed from source to receiver, as opposed to the accurate recovery of transmitted symbols. In this work, we aim to provide a comprehensive view of the history and current state of semantic communication and the techniques for engineering this higher level of communication. A survey of the current literature reveals four broad approaches to engineering semantic communication. We term the earliest of these approaches classical semantic information, which seeks to extend information-theoretic results to include semantic information. A second approach makes use of knowledge graphs to achieve semantic communication, and a third utilizes the power of modern deep learning techniques to facilitate this communication. The fourth approach focuses on the significance of information, rather than its meaning, to achieve efficient, goal-oriented communication. We discuss each of these four approaches and their corresponding works in detail, and provide some challenges and opportunities that pertain to each approach. Finally, we introduce a novel approach to semantic communication, which we term context-based semantic communication. Inspired by the way in which humans naturally communicate with one another, this context-based approach provides a general, optimization-based design framework for semantic communication systems. Together, this survey provides a useful guide for the design and implementation of semantic communication systems.
Constrained Resource Allocation Problems in Communications: An Information-assisted Approach
Dec 07, 2021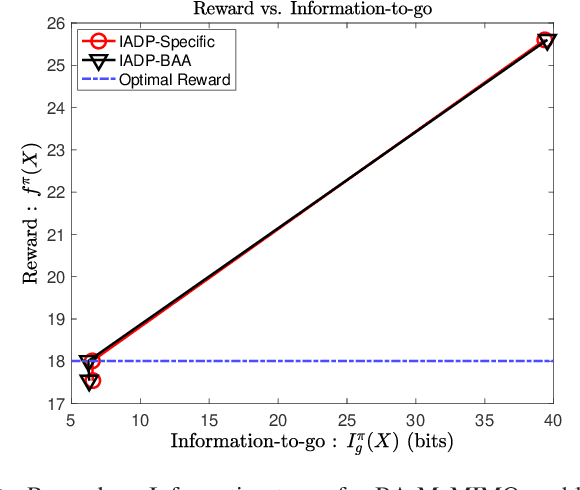
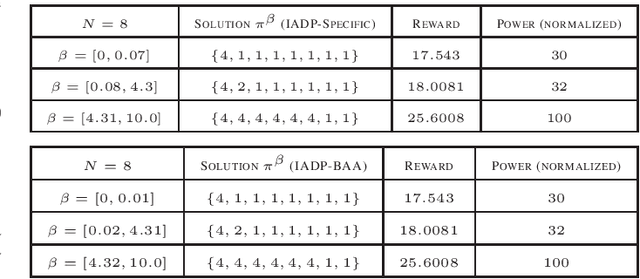
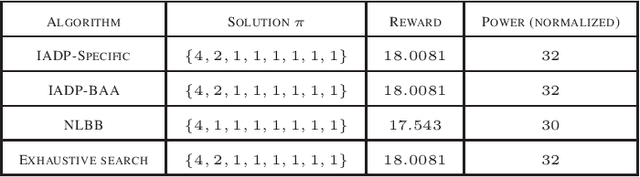
We consider a class of resource allocation problems given a set of unconditional constraints whose objective function satisfies Bellman's optimality principle. Such problems are ubiquitous in wireless communication, signal processing, and networking. These constrained combinatorial optimization problems are, in general, NP-Hard. This paper proposes two algorithms to solve this class of problems using a dynamic programming framework assisted by an information-theoretic measure. We demonstrate that the proposed algorithms ensure optimal solutions under carefully chosen conditions and use significantly reduced computational resources. We substantiate our claims by solving the power-constrained bit allocation problem in 5G massive Multiple-Input Multiple-Output receivers using the proposed approach.
Relation Embedding based Graph Neural Networks for Handling Heterogeneous Graph
Sep 23, 2022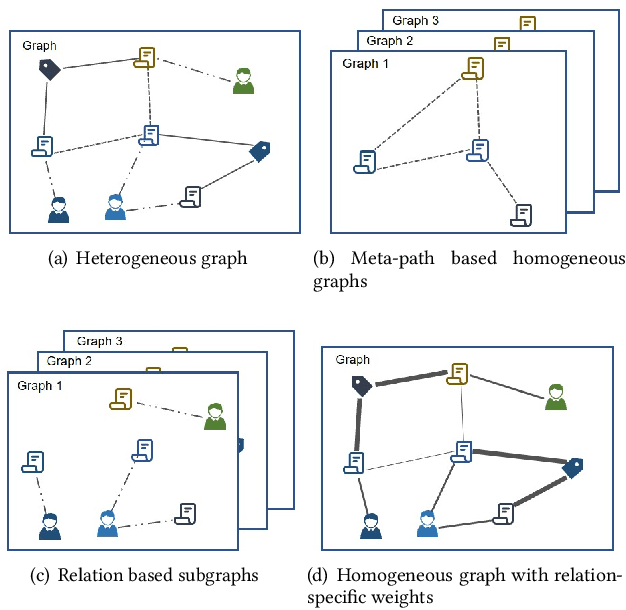
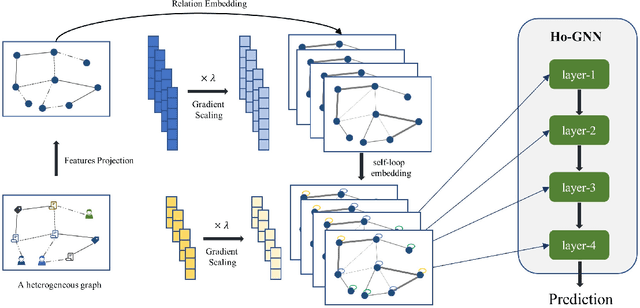
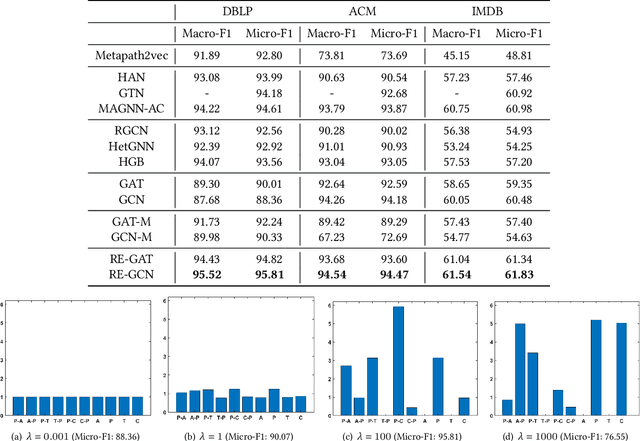
Heterogeneous graph learning has drawn significant attentions in recent years, due to the success of graph neural networks (GNNs) and the broad applications of heterogeneous information networks. Various heterogeneous graph neural networks have been proposed to generalize GNNs for processing the heterogeneous graphs. Unfortunately, these approaches model the heterogeneity via various complicated modules. This paper aims to propose a simple yet efficient framework to make the homogeneous GNNs have adequate ability to handle heterogeneous graphs. Specifically, we propose Relation Embedding based Graph Neural Networks (RE-GNNs), which employ only one parameter per relation to embed the importance of edge type relations and self-loop connections. To optimize these relation embeddings and the other parameters simultaneously, a gradient scaling factor is proposed to constrain the embeddings to converge to suitable values. Besides, we theoretically demonstrate that our RE-GNNs have more expressive power than the meta-path based heterogeneous GNNs. Extensive experiments on the node classification tasks validate the effectiveness of our proposed method.
Quantifying U-Net Uncertainty in Multi-Parametric MRI-based Glioma Segmentation by Spherical Image Projection
Oct 12, 2022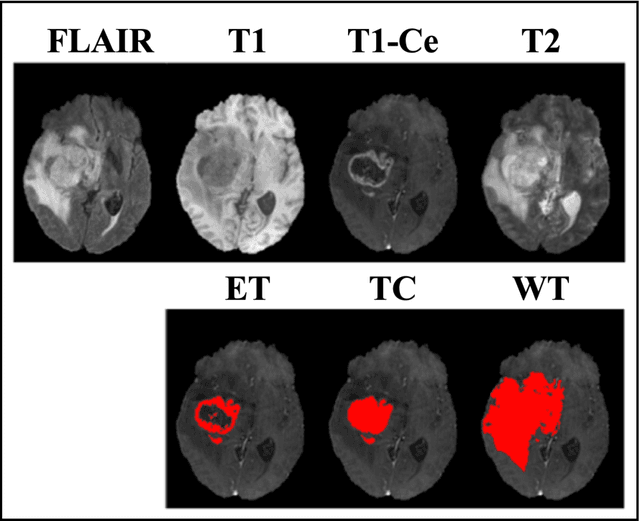

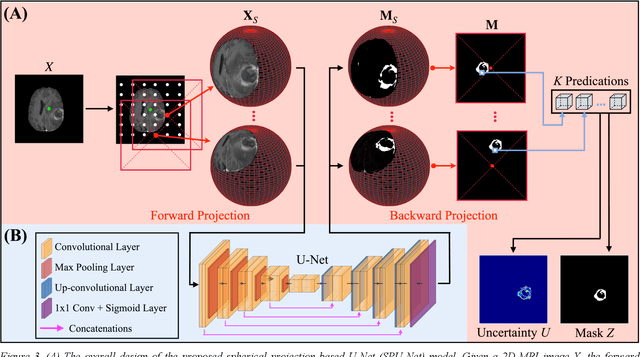
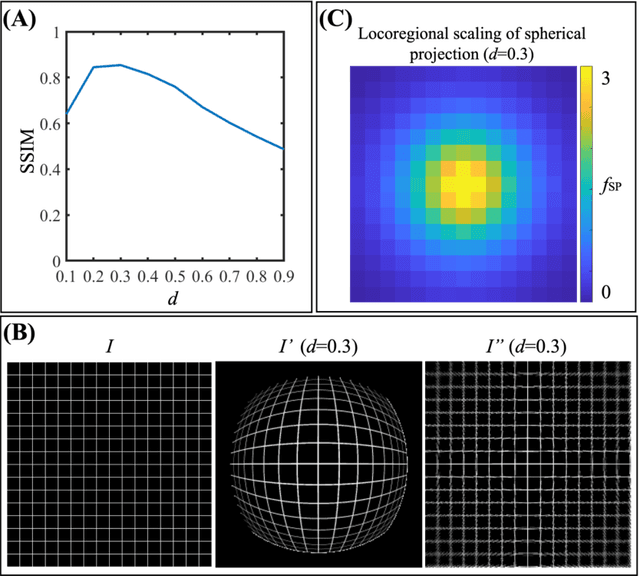
Purpose: To develop a U-Net segmentation uncertainty quantification method based on spherical image projection of multi-parametric MRI (MP-MRI) in glioma segmentation. Methods: The projection of planar MRI onto a spherical surface retains global anatomical information. By incorporating such image transformation in our proposed spherical projection-based U-Net (SPU-Net) segmentation model design, multiple segmentation predictions can be obtained for a single MRI. The final segmentation is the average of all predictions, and the variation can be shown as an uncertainty map. An uncertainty score was introduced to compare the uncertainty measurements' performance. The SPU-Net model was implemented on 369 glioma patients with MP-MRI scans. Three SPU-Nets were trained to segment enhancing tumor (ET), tumor core (TC), and whole tumor (WT), respectively. The SPU-Net was compared with (1) classic U-Net with test-time augmentation (TTA) and (2) linear scaling-based U-Net (LSU-Net) in both segmentation accuracy (Dice coefficient) and uncertainty (uncertainty map and uncertainty score). Results: The SPU-Net achieved low uncertainty for correct segmentation predictions (e.g., tumor interior or healthy tissue interior) and high uncertainty for incorrect results (e.g., tumor boundaries). This model could allow the identification of missed tumor targets or segmentation errors in U-Net. The SPU-Net achieved the highest uncertainty scores for 3 targets (ET/TC/WT): 0.826/0.848/0.936, compared to 0.784/0.643/0.872 for the U-Net with TTA and 0.743/0.702/0.876 for the LSU-Net. The SPU-Net also achieved statistically significantly higher Dice coefficients. Conclusion: The SPU-Net offers a powerful tool to quantify glioma segmentation uncertainty while improving segmentation accuracy. The proposed method can be generalized to other medical image-related deep-learning applications for uncertainty evaluation.
Robust self-healing prediction model for high dimensional data
Oct 04, 2022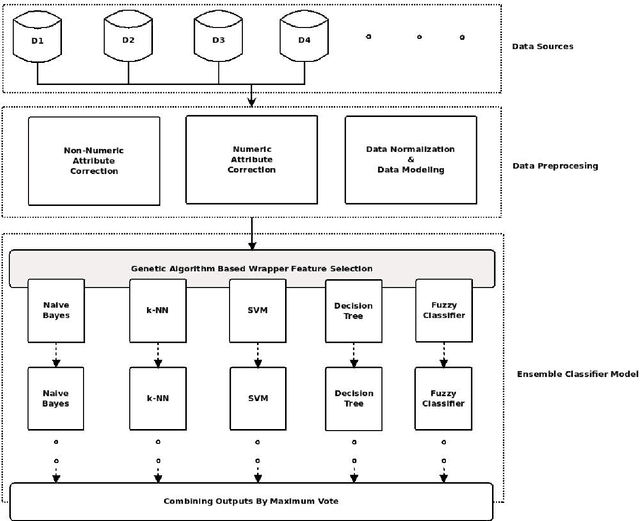
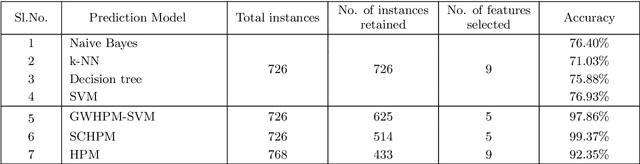
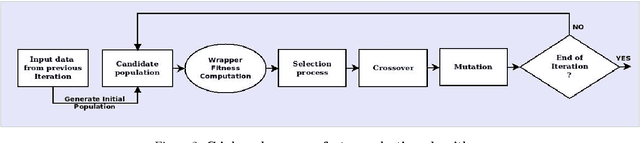
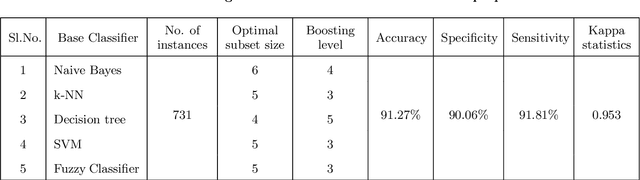
Owing to the advantages of increased accuracy and the potential to detect unseen patterns, provided by data mining techniques they have been widely incorporated for standard classification problems. They have often been used for high precision disease prediction in the medical field, and several hybrid prediction models capable of achieving high accuracies have been proposed. Though this stands true most of the previous models fail to efficiently address the recurring issue of bad data quality which plagues most high dimensional data, and especially proves troublesome in the highly sensitive medical data. This work proposes a robust self healing (RSH) hybrid prediction model which functions by using the data in its entirety by removing errors and inconsistencies from it rather than discarding any data. Initial processing involves data preparation followed by cleansing or scrubbing through context-dependent attribute correction, which ensures that there is no significant loss of relevant information before the feature selection and prediction phases. An ensemble of heterogeneous classifiers, subjected to local boosting, is utilized to build the prediction model and genetic algorithm based wrapper feature selection technique wrapped on the respective classifiers is employed to select the corresponding optimal set of features, which warrant higher accuracy. The proposed method is compared with some of the existing high performing models and the results are analyzed.
Cross-Geography Generalization of Machine Learning Methods for Classification of Flooded Regions in Aerial Images
Oct 04, 2022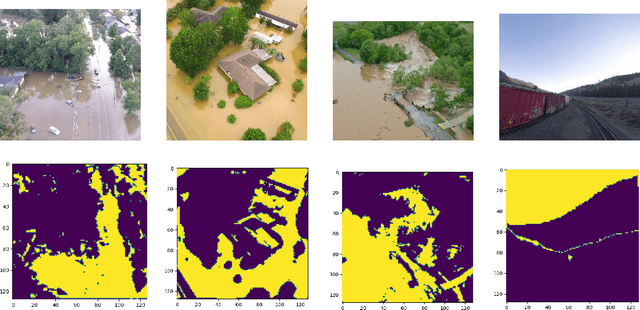
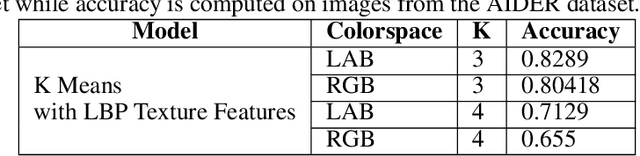
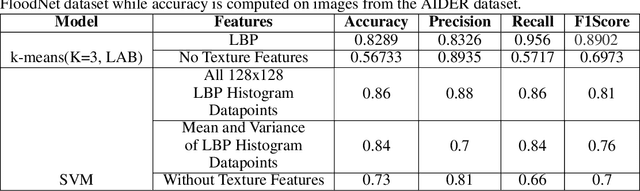
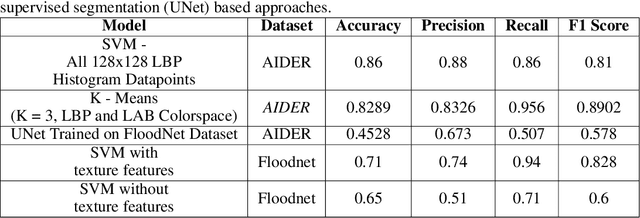
Identification of regions affected by floods is a crucial piece of information required for better planning and management of post-disaster relief and rescue efforts. Traditionally, remote sensing images are analysed to identify the extent of damage caused by flooding. The data acquired from sensors onboard earth observation satellites are analyzed to detect the flooded regions, which can be affected by low spatial and temporal resolution. However, in recent years, the images acquired from Unmanned Aerial Vehicles (UAVs) have also been utilized to assess post-disaster damage. Indeed, a UAV based platform can be rapidly deployed with a customized flight plan and minimum dependence on the ground infrastructure. This work proposes two approaches for identifying flooded regions in UAV aerial images. The first approach utilizes texture-based unsupervised segmentation to detect flooded areas, while the second uses an artificial neural network on the texture features to classify images as flooded and non-flooded. Unlike the existing works where the models are trained and tested on images of the same geographical regions, this work studies the performance of the proposed model in identifying flooded regions across geographical regions. An F1-score of 0.89 is obtained using the proposed segmentation-based approach which is higher than existing classifiers. The robustness of the proposed approach demonstrates that it can be utilized to identify flooded regions of any region with minimum or no user intervention.