 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CBAG: An Efficient Genetic Algorithm for the Graph Burning Problem
Aug 06, 2022
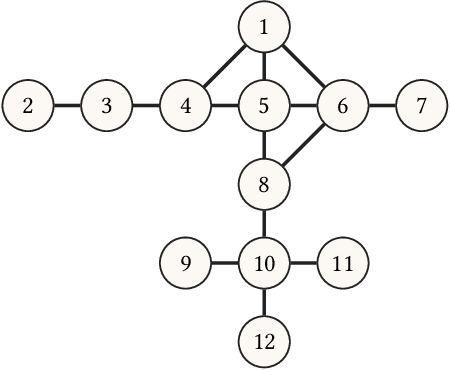
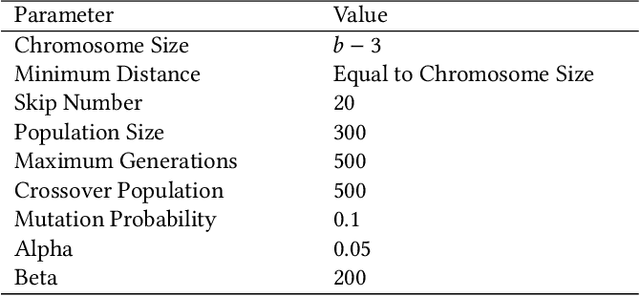
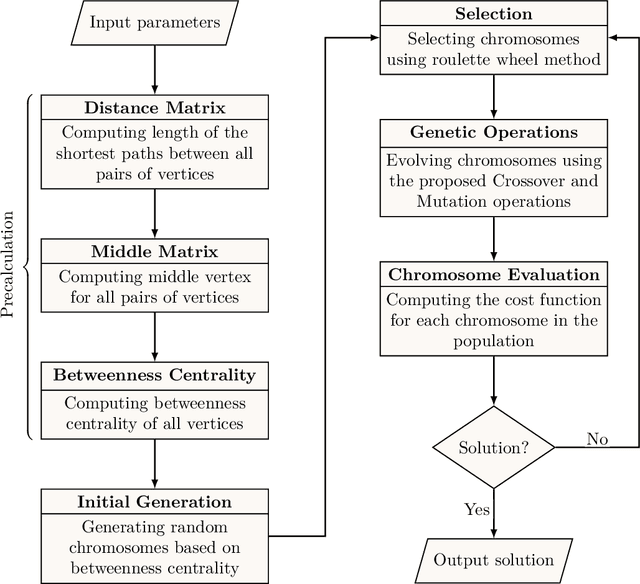

Information spread is an intriguing topic to study in network science, which investigates how information, influence, or contagion propagate through networks. Graph burning is a simplified deterministic model for how information spreads within networks. The complicated NP-complete nature of the problem makes it computationally difficult to solve using exact algorithms. Accordingly, a number of heuristics and approximation algorithms have been proposed in the literature for the graph burning problem. In this paper, we propose an efficient genetic algorithm called Centrality BAsed Genetic-algorithm (CBAG) for solving the graph burning problem. Considering the unique characteristics of the graph burning problem, we introduce novel genetic operators, chromosome representation, and evaluation method. In the proposed algorithm, the well-known betweenness centrality is used as the backbone of our chromosome initialization procedure. The proposed algorithm is implemented and compared with previous heuristics and approximation algorithms on 15 benchmark graphs of different sizes. Based on the results, it can be seen that the proposed algorithm achieves better performance in comparison to the previous state-of-the-art heuristics. The complete source code is available online and can be used to find optimal or near-optimal solutions for the graph burning problem.
Multifaceted Hierarchical Report Identification for Non-Functional Bugs in Deep Learning Frameworks
Oct 04, 2022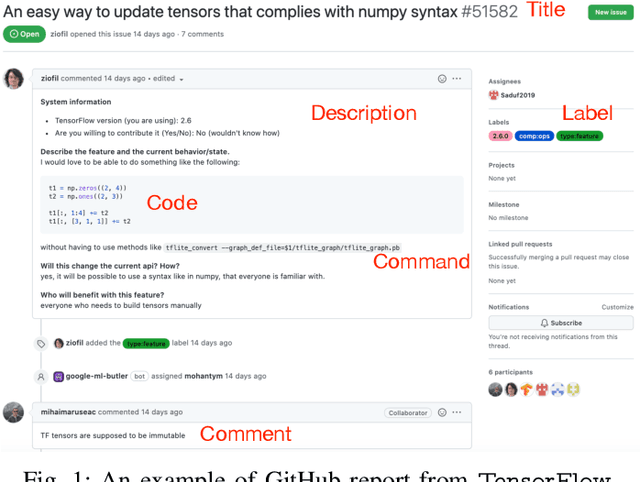

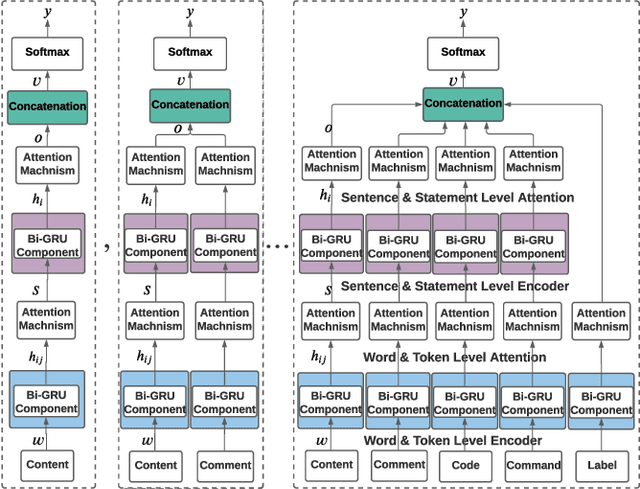
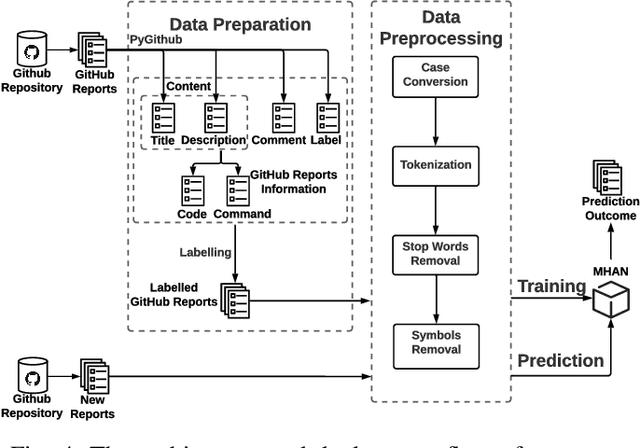
Non-functional bugs (e.g., performance- or accuracy-related bugs) in Deep Learning (DL) frameworks can lead to some of the most devastating consequences. Reporting those bugs on a repository such as GitHub is a standard route to fix them. Yet, given the growing number of new GitHub reports for DL frameworks, it is intrinsically difficult for developers to distinguish those that reveal non-functional bugs among the others, and assign them to the right contributor for investigation in a timely manner. In this paper, we propose MHNurf - an end-to-end tool for automatically identifying non-functional bug related reports in DL frameworks. The core of MHNurf is a Multifaceted Hierarchical Attention Network (MHAN) that tackles three unaddressed challenges: (1) learning the semantic knowledge, but doing so by (2) considering the hierarchy (e.g., words/tokens in sentences/statements) and focusing on the important parts (i.e., words, tokens, sentences, and statements) of a GitHub report, while (3) independently extracting information from different types of features, i.e., content, comment, code, command, and label. To evaluate MHNurf, we leverage 3,721 GitHub reports from five DL frameworks for conducting experiments. The results show that MHNurf works the best with a combination of content, comment, and code, which considerably outperforms the classic HAN where only the content is used. MHNurf also produces significantly more accurate results than nine other state-of-the-art classifiers with strong statistical significance, i.e., up to 71% AUC improvement and has the best Scott-Knott rank on four frameworks while 2nd on the remaining one. To facilitate reproduction and promote future research, we have made our dataset, code, and detailed supplementary results publicly available at: https://github.com/ideas-labo/APSEC2022-MHNurf.
GaitFM: Fine-grained Motion Representation for Gait Recognition
Sep 18, 2022
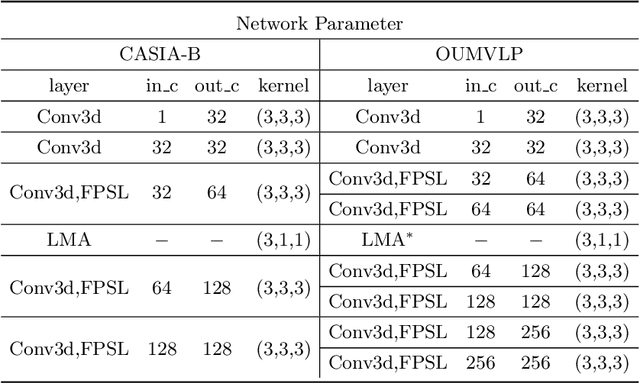
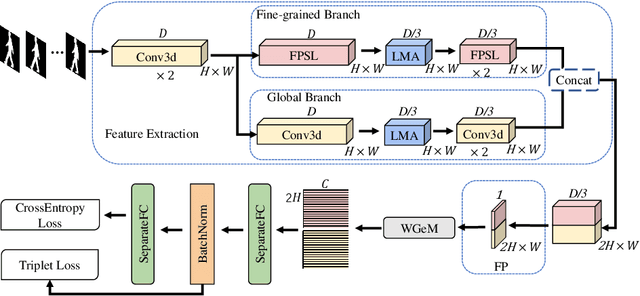
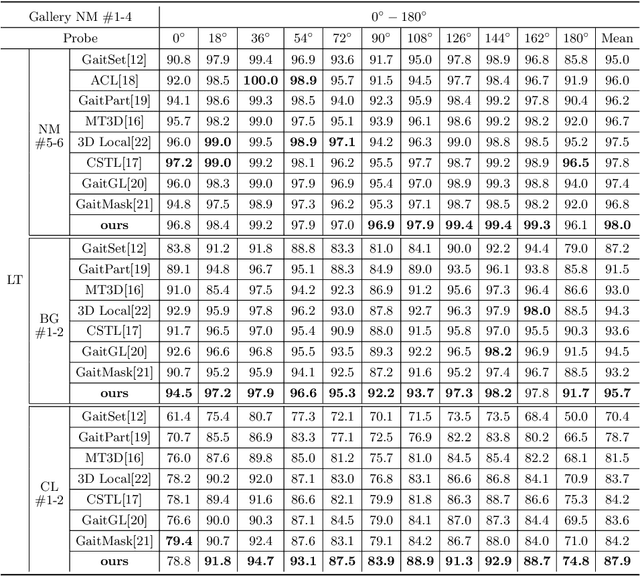
Gait recognition aims at identifying individual-specific walking patterns, which is highly dependent on the observation of the different periodic movements of each body part. However, most existing methods treat each part equally and neglect the data redundancy due to the high sampling rate of gait sequences. In this work, we propose a fine-grained motion representation network (GaitFM) to improve gait recognition performance in three aspects. First, a fine-grained part sequence learning (FPSL) module is designed to explore part-independent spatio-temporal representations. Secondly, a frame-wise compression strategy, called local motion aggregation (LMA), is used to enhance motion variations. Finally, a weighted generalized mean pooling (WGeM) layer works to adaptively keep more discriminative information in the spatial downsampling. Experiments on two public datasets, CASIA-B and OUMVLP, show that our approach reaches state-of-the-art performances. On the CASIA-B dataset, our method achieves rank-1 accuracies of 98.0%, 95.7% and 87.9% for normal walking, walking with a bag and walking with a coat, respectively. On the OUMVLP dataset, our method achieved a rank-1 accuracy of 90.5%.
VIPHY: Probing "Visible" Physical Commonsense Knowledge
Sep 15, 2022
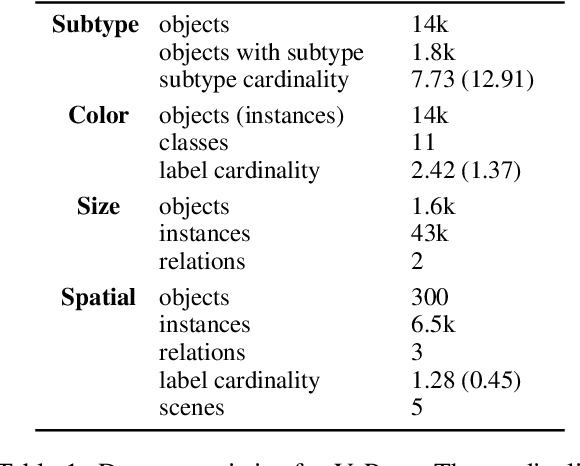
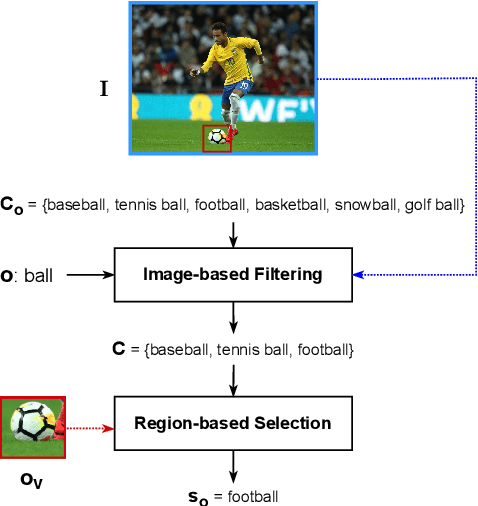

In recent years, vision-language models (VLMs) have shown remarkable performance on visual reasoning tasks (e.g. attributes, location). While such tasks measure the requisite knowledge to ground and reason over a given visual instance, they do not, however, measure the ability of VLMs to retain and generalize such knowledge. In this work, we evaluate their ability to acquire "visible" physical knowledge -- the information that is easily accessible from images of static scenes, particularly across the dimensions of object color, size and space. We build an automatic pipeline to derive a comprehensive knowledge resource for calibrating and probing these models. Our results indicate a severe gap between model and human performance across all three tasks. Furthermore, our caption pretrained baseline (CapBERT) significantly outperforms VLMs on both size and spatial tasks -- highlighting that despite sufficient access to ground language with visual modality, they struggle to retain such knowledge. The dataset and code are available at https://github.com/Axe--/ViPhy .
Quantile-constrained Wasserstein projections for robust interpretability of numerical and machine learning models
Sep 23, 2022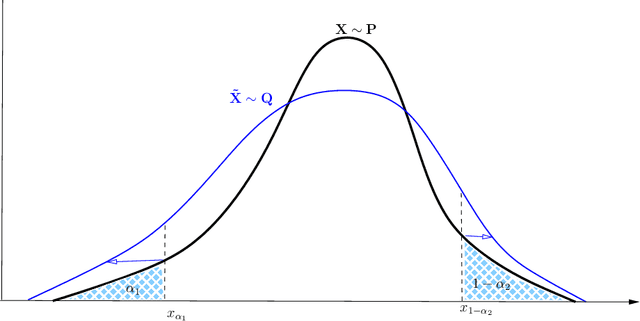

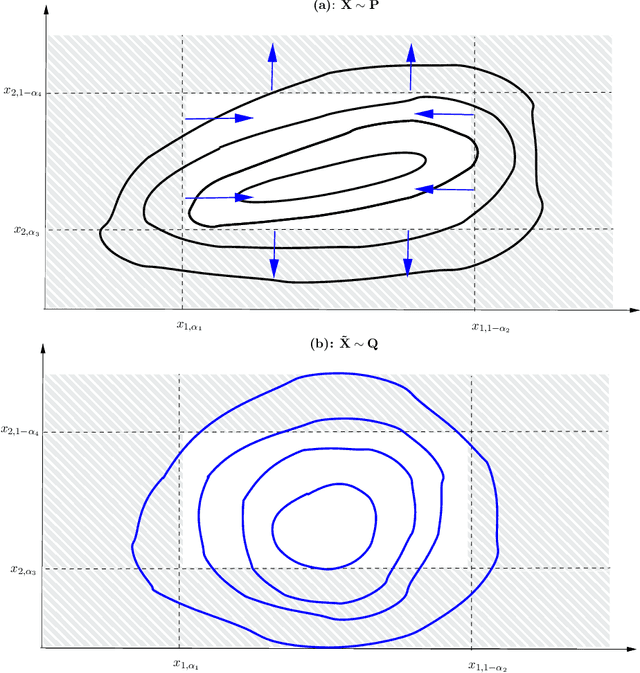
Robustness studies of black-box models is recognized as a necessary task for numerical models based on structural equations and predictive models learned from data. These studies must assess the model's robustness to possible misspecification of regarding its inputs (e.g., covariate shift). The study of black-box models, through the prism of uncertainty quantification (UQ), is often based on sensitivity analysis involving a probabilistic structure imposed on the inputs, while ML models are solely constructed from observed data. Our work aim at unifying the UQ and ML interpretability approaches, by providing relevant and easy-to-use tools for both paradigms. To provide a generic and understandable framework for robustness studies, we define perturbations of input information relying on quantile constraints and projections with respect to the Wasserstein distance between probability measures, while preserving their dependence structure. We show that this perturbation problem can be analytically solved. Ensuring regularity constraints by means of isotonic polynomial approximations leads to smoother perturbations, which can be more suitable in practice. Numerical experiments on real case studies, from the UQ and ML fields, highlight the computational feasibility of such studies and provide local and global insights on the robustness of black-box models to input perturbations.
Clustering-Induced Generative Incomplete Image-Text Clustering (CIGIT-C)
Sep 28, 2022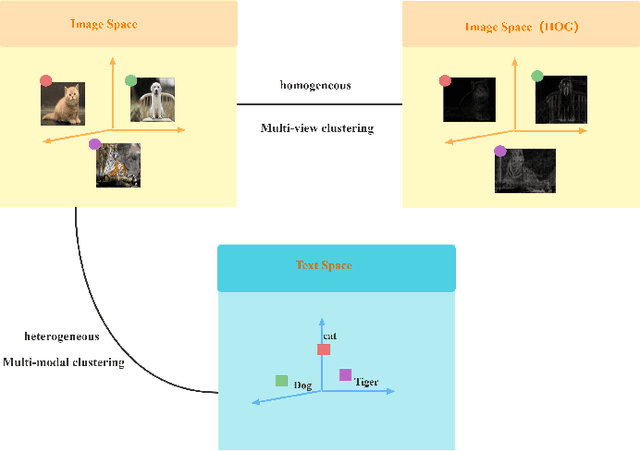

The target of image-text clustering (ITC) is to find correct clusters by integrating complementary and consistent information of multi-modalities for these heterogeneous samples. However, the majority of current studies analyse ITC on the ideal premise that the samples in every modality are complete. This presumption, however, is not always valid in real-world situations. The missing data issue degenerates the image-text feature learning performance and will finally affect the generalization abilities in ITC tasks. Although a series of methods have been proposed to address this incomplete image text clustering issue (IITC), the following problems still exist: 1) most existing methods hardly consider the distinct gap between heterogeneous feature domains. 2) For missing data, the representations generated by existing methods are rarely guaranteed to suit clustering tasks. 3) Existing methods do not tap into the latent connections both inter and intra modalities. In this paper, we propose a Clustering-Induced Generative Incomplete Image-Text Clustering(CIGIT-C) network to address the challenges above. More specifically, we first use modality-specific encoders to map original features to more distinctive subspaces. The latent connections between intra and inter-modalities are thoroughly explored by using the adversarial generating network to produce one modality conditional on the other modality. Finally, we update the corresponding modalityspecific encoders using two KL divergence losses. Experiment results on public image-text datasets demonstrated that the suggested method outperforms and is more effective in the IITC job.
A Secure and Efficient Multi-Object Grasping Detection Approach for Robotic Arms
Sep 08, 2022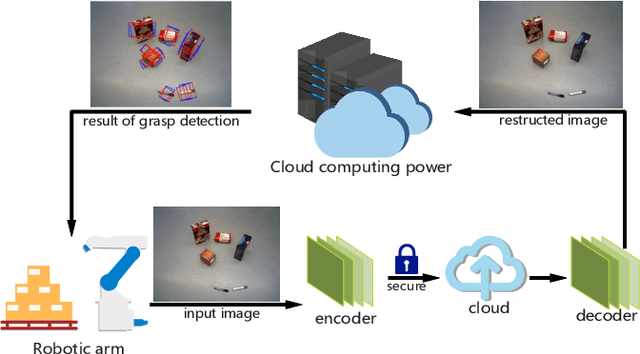



Robotic arms are widely used in automatic industries. However, with wide applications of deep learning in robotic arms, there are new challenges such as the allocation of grasping computing power and the growing demand for security. In this work, we propose a robotic arm grasping approach based on deep learning and edge-cloud collaboration. This approach realizes the arbitrary grasp planning of the robot arm and considers the grasp efficiency and information security. In addition, the encoder and decoder trained by GAN enable the images to be encrypted while compressing, which ensures the security of privacy. The model achieves 92% accuracy on the OCID dataset, the image compression ratio reaches 0.03%, and the structural difference value is higher than 0.91.
SmartKex: Machine Learning Assisted SSH Keys Extraction From The Heap Dump
Sep 13, 2022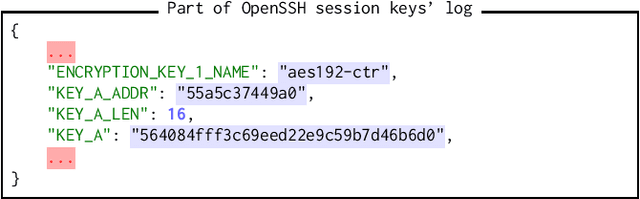

Digital forensics is the process of extracting, preserving, and documenting evidence in digital devices. A commonly used method in digital forensics is to extract data from the main memory of a digital device. However, the main challenge is identifying the important data to be extracted. Several pieces of crucial information reside in the main memory, like usernames, passwords, and cryptographic keys such as SSH session keys. In this paper, we propose SmartKex, a machine-learning assisted method to extract session keys from heap memory snapshots of an OpenSSH process. In addition, we release an openly available dataset and the corresponding toolchain for creating additional data. Finally, we compare SmartKex with naive brute-force methods and empirically show that SmartKex can extract the session keys with high accuracy and high throughput. With the provided resources, we intend to strengthen the research on the intersection between digital forensics, cybersecurity, and machine learning.
Personalized Saliency in Task-Oriented Semantic Communications: Image Transmission and Performance Analysis
Sep 25, 2022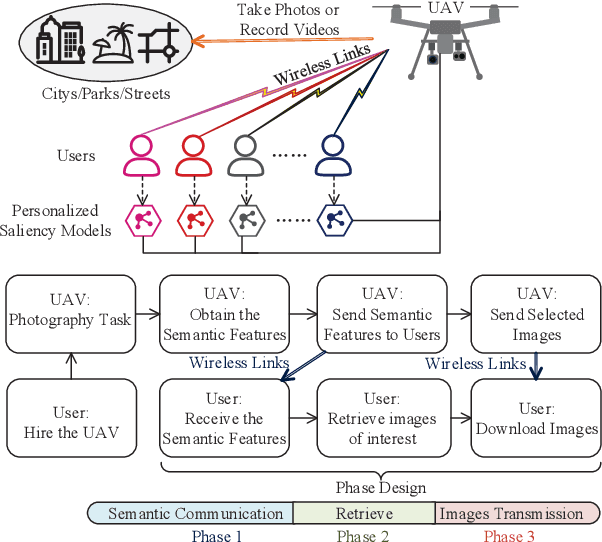
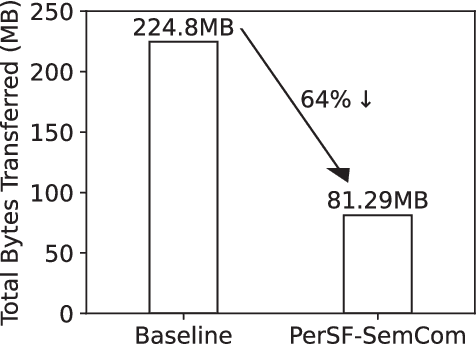
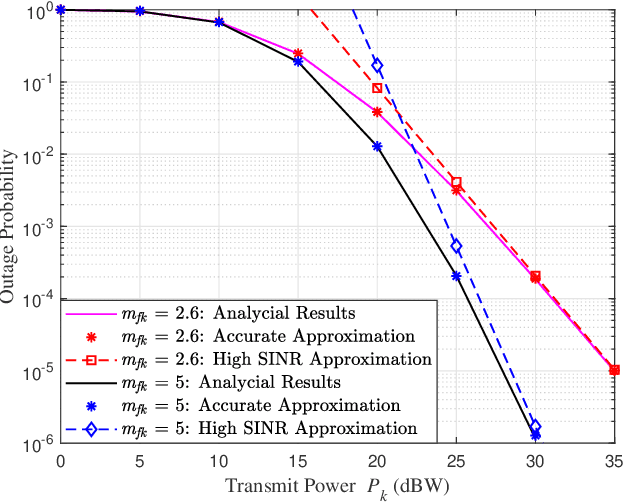
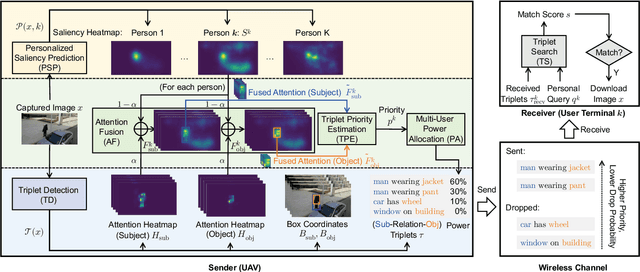
Semantic communication, as a promising technology, has emerged to break through the Shannon limit, which is envisioned as the key enabler and fundamental paradigm for future 6G networks and applications, e.g., smart healthcare. In this paper, we focus on UAV image-sensing-driven task-oriented semantic communications scenarios. The majority of existing work has focused on designing advanced algorithms for high-performance semantic communication. However, the challenges, such as energy-hungry and efficiency-limited image retrieval manner, and semantic encoding without considering user personality, have not been explored yet. These challenges have hindered the widespread adoption of semantic communication. To address the above challenges, at the semantic level, we first design an energy-efficient task-oriented semantic communication framework with a triple-based {\color{black}scene graph} for image information. We then design a new personalized semantic encoder based on user interests to meet the requirements of personalized saliency. Moreover, at the communication level, we study the effects of dynamic wireless fading channels on semantic transmission mathematically and thus design an optimal multi-user resource allocation scheme by using game theory. Numerical results based on real-world datasets clearly indicate that the proposed framework and schemes significantly enhance the personalization and anti-interference performance of semantic communication, and are also efficient to improve the communication quality of semantic communication services.
Neighborhood Gradient Clustering: An Efficient Decentralized Learning Method for Non-IID Data Distributions
Sep 30, 2022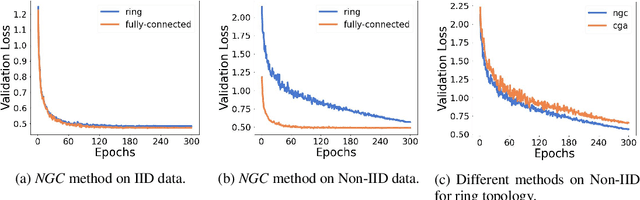
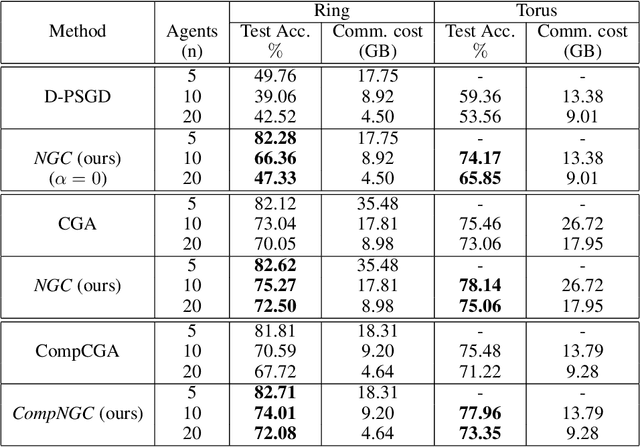
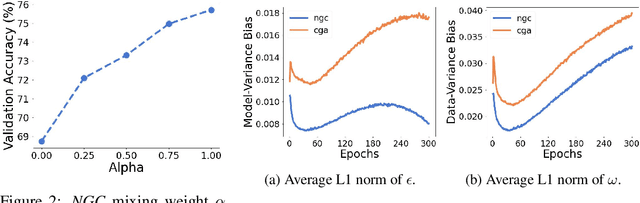
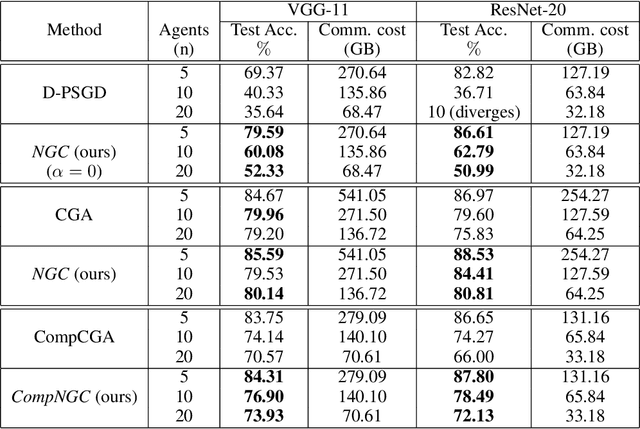
Decentralized learning algorithms enable the training of deep learning models over large distributed datasets generated at different devices and locations, without the need for a central server. In practical scenarios, the distributed datasets can have significantly different data distributions across the agents. The current state-of-the-art decentralized algorithms mostly assume the data distributions to be Independent and Identically Distributed (IID). This paper focuses on improving decentralized learning over non-IID data distributions with minimal compute and memory overheads. We propose Neighborhood Gradient Clustering (NGC), a novel decentralized learning algorithm that modifies the local gradients of each agent using self- and cross-gradient information. In particular, the proposed method replaces the local gradients of the model with the weighted mean of the self-gradients, model-variant cross-gradients (derivatives of the received neighbors' model parameters with respect to the local dataset), and data-variant cross-gradients (derivatives of the local model with respect to its neighbors' datasets). Further, we present CompNGC, a compressed version of NGC that reduces the communication overhead by $32 \times$ by compressing the cross-gradients. We demonstrate the empirical convergence and efficiency of the proposed technique over non-IID data distributions sampled from the CIFAR-10 dataset on various model architectures and graph topologies. Our experiments demonstrate that NGC and CompNGC outperform the existing state-of-the-art (SoTA) decentralized learning algorithm over non-IID data by $1-5\%$ with significantly less compute and memory requirements. Further, we also show that the proposed NGC method outperforms the baseline by $5-40\%$ with no additional communication.