 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Speaker Embedding-aware Neural Diarization for Flexible Number of Speakers with Textual Information
Nov 28, 2021
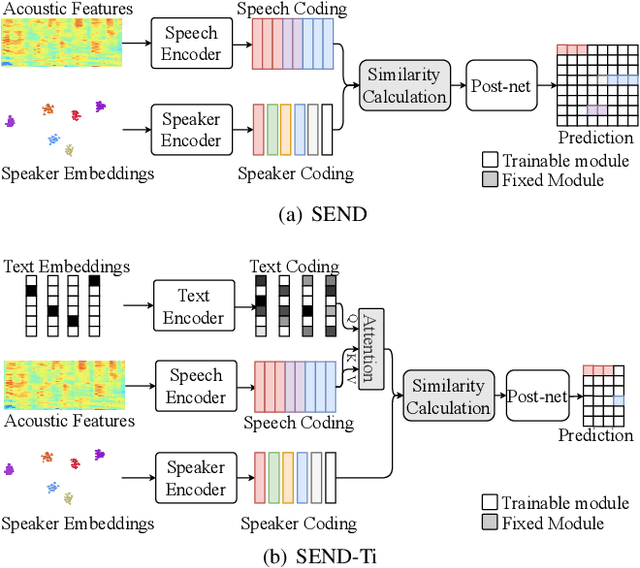

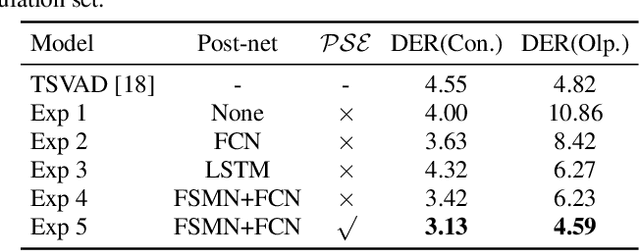
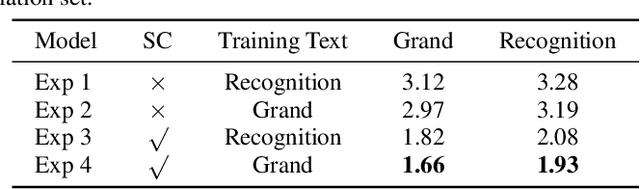
Overlapping speech diarization is always treated as a multi-label classification problem. In this paper, we reformulate this task as a single-label prediction problem by encoding the multi-speaker labels with power set. Specifically, we propose the speaker embedding-aware neural diarization (SEND) method, which predicts the power set encoded labels according to the similarities between speech features and given speaker embeddings. Our method is further extended and integrated with downstream tasks by utilizing the textual information, which has not been well studied in previous literature. The experimental results show that our method achieves lower diarization error rate than the target-speaker voice activity detection. When textual information is involved, the diarization errors can be further reduced. For the real meeting scenario, our method can achieve 34.11% relative improvement compared with the Bayesian hidden Markov model based clustering algorithm.
Adaptation of Autoencoder for Sparsity Reduction From Clinical Notes Representation Learning
Sep 26, 2022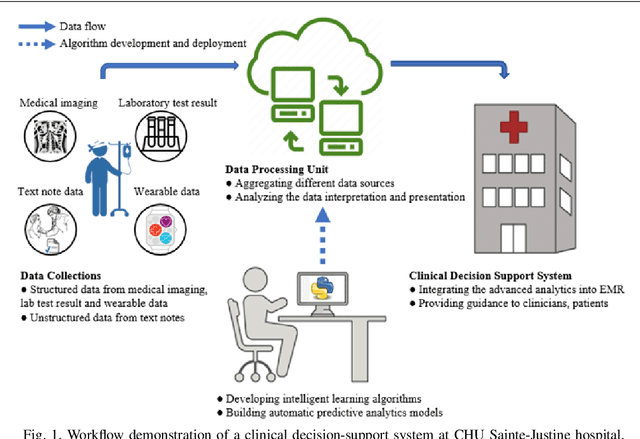
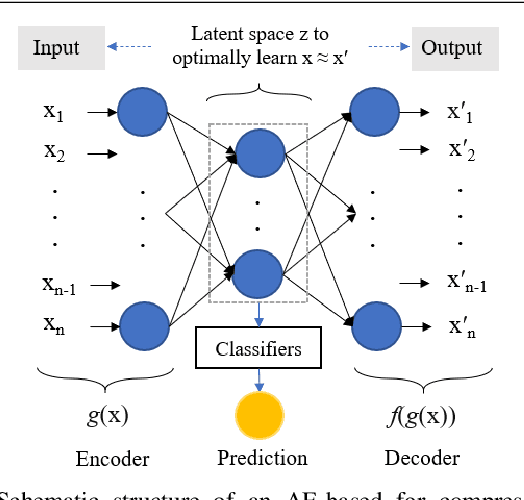
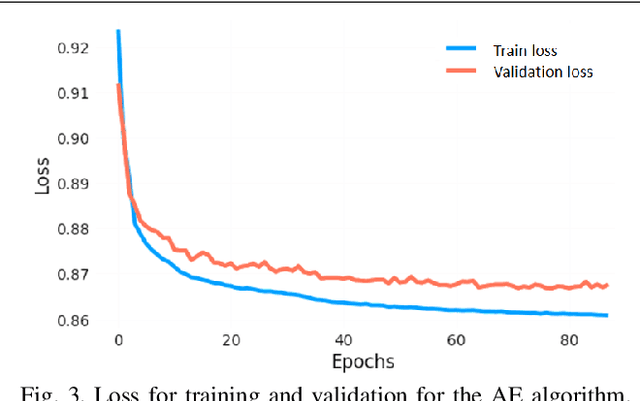
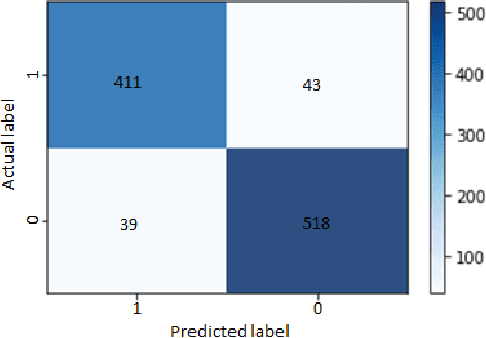
When dealing with clinical text classification on a small dataset recent studies have confirmed that a well-tuned multilayer perceptron outperforms other generative classifiers, including deep learning ones. To increase the performance of the neural network classifier, feature selection for the learning representation can effectively be used. However, most feature selection methods only estimate the degree of linear dependency between variables and select the best features based on univariate statistical tests. Furthermore, the sparsity of the feature space involved in the learning representation is ignored. Goal: Our aim is therefore to access an alternative approach to tackle the sparsity by compressing the clinical representation feature space, where limited French clinical notes can also be dealt with effectively. Methods: This study proposed an autoencoder learning algorithm to take advantage of sparsity reduction in clinical note representation. The motivation was to determine how to compress sparse, high-dimensional data by reducing the dimension of the clinical note representation feature space. The classification performance of the classifiers was then evaluated in the trained and compressed feature space. Results: The proposed approach provided overall performance gains of up to 3% for each evaluation. Finally, the classifier achieved a 92% accuracy, 91% recall, 91% precision, and 91% f1-score in detecting the patient's condition. Furthermore, the compression working mechanism and the autoencoder prediction process were demonstrated by applying the theoretic information bottleneck framework.
View-Invariant Localization using Semantic Objects in Changing Environments
Sep 28, 2022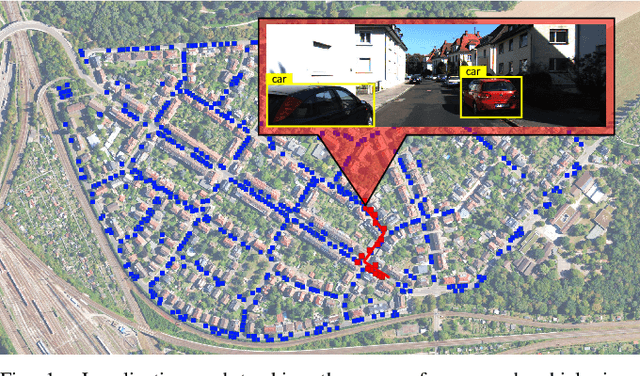
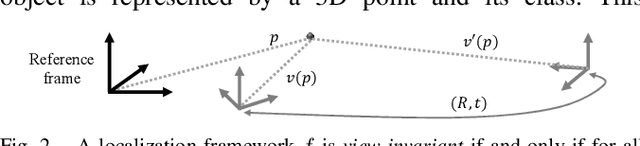
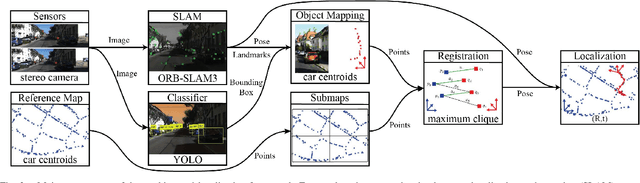
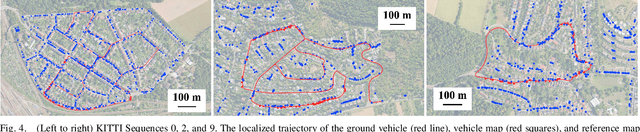
This paper proposes a novel framework for real-time localization and egomotion tracking of a vehicle in a reference map. The core idea is to map the semantic objects observed by the vehicle and register them to their corresponding objects in the reference map. While several recent works have leveraged semantic information for cross-view localization, the main contribution of this work is a view-invariant formulation that makes the approach directly applicable to any viewpoint configuration for which objects are detectable. Another distinctive feature is robustness to changes in the environment/objects due to a data association scheme suited for extreme outlier regimes (e.g., 90% association outliers). To demonstrate our framework, we consider an example of localizing a ground vehicle in a reference object map using only cars as objects. While only a stereo camera is used for the ground vehicle, we consider reference maps constructed a priori from ground viewpoints using stereo cameras and Lidar scans, and georeferenced aerial images captured at a different date to demonstrate the framework's robustness to different modalities, viewpoints, and environment changes. Evaluations on the KITTI dataset show that over a 3.7 km trajectory, localization occurs in 36 sec and is followed by real-time egomotion tracking with an average position error of 8.5 m in a Lidar reference map, and on an aerial object map where 77% of objects are outliers, localization is achieved in 71 sec with an average position error of 7.9 m.
Discriminative Mutual Information Estimation for the Design of Channel Capacity Driven Autoencoders
Nov 15, 2021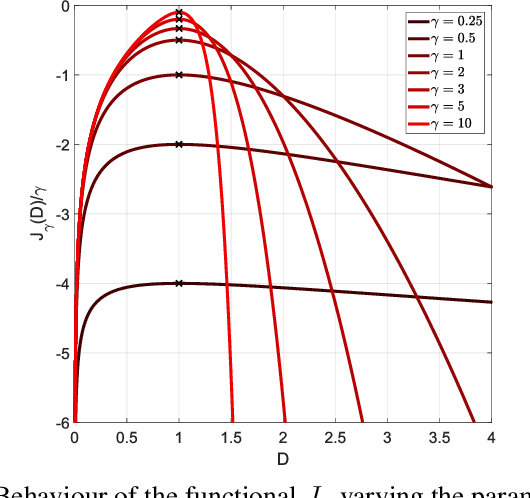
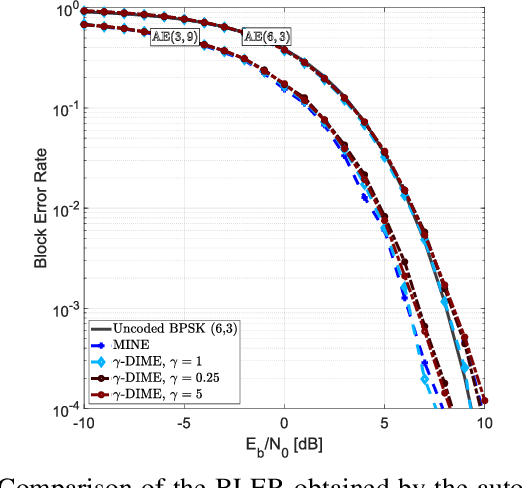
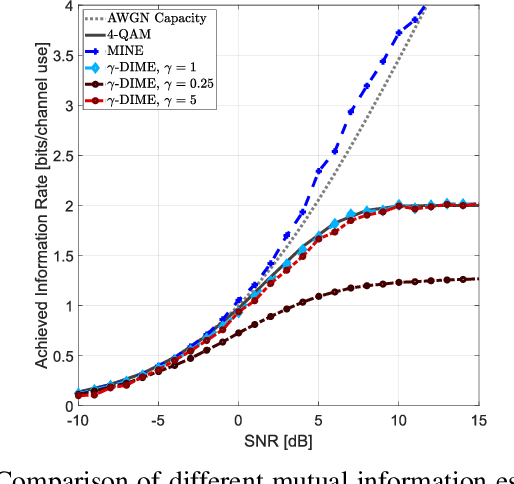
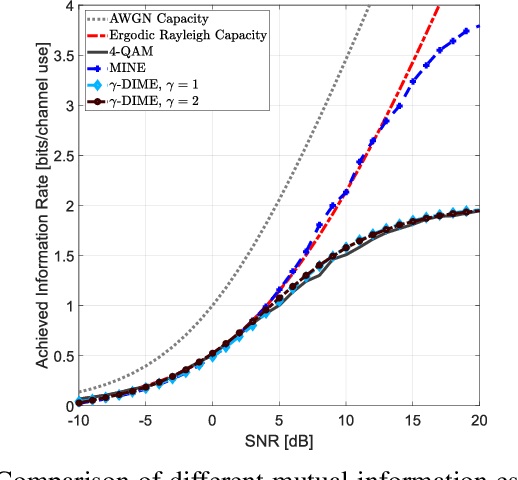
The development of optimal and efficient machine learning-based communication systems is likely to be a key enabler of beyond 5G communication technologies. In this direction, physical layer design has been recently reformulated under a deep learning framework where the autoencoder paradigm foresees the full communication system as an end-to-end coding-decoding problem. Given the loss function, the autoencoder jointly learns the coding and decoding optimal blocks under a certain channel model. Because performance in communications typically refers to achievable rates and channel capacity, the mutual information between channel input and output can be included in the end-to-end training process, thus, its estimation becomes essential. In this paper, we present a set of novel discriminative mutual information estimators and we discuss how to exploit them to design capacity-approaching codes and ultimately estimate the channel capacity.
Modeling Polyp Activity of Paragorgia arborea Using Supervised Learning
Sep 26, 2022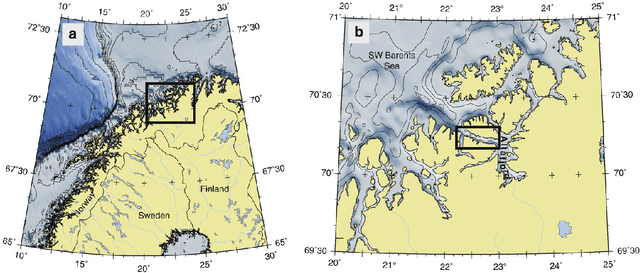
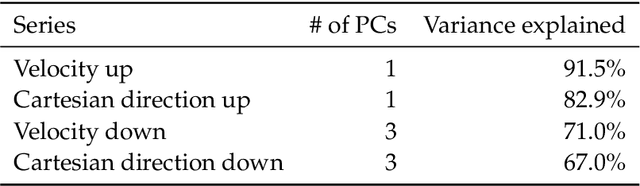
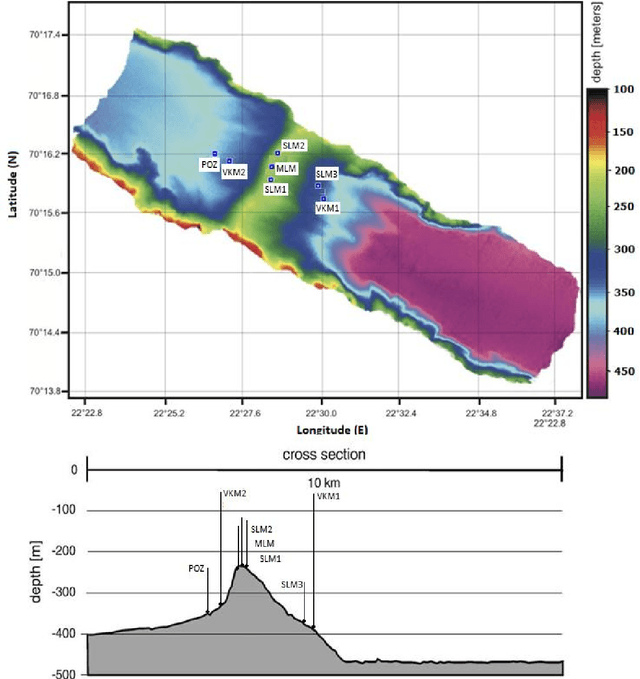
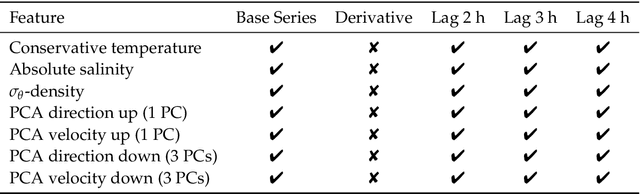
While the distribution patterns of cold-water corals, such as Paragorgia arborea, have received increasing attention in recent studies, little is known about their in situ activity patterns. In this paper, we examine polyp activity in P. arborea using machine learning techniques to analyze high-resolution time series data and photographs obtained from an autonomous lander cluster deployed in the Stjernsund, Norway. An interactive illustration of the models derived in this paper is provided online as supplementary material. We find that the best predictor of the degree of extension of the coral polyps is current direction with a lag of three hours. Other variables that are not directly associated with water currents, such as temperature and salinity, offer much less information concerning polyp activity. Interestingly, the degree of polyp extension can be predicted more reliably by sampling the laminar flows in the water column above the measurement site than by sampling the more turbulent flows in the direct vicinity of the corals. Our results show that the activity patterns of the P. arborea polyps are governed by the strong tidal current regime of the Stjernsund. It appears that P. arborea does not react to shorter changes in the ambient current regime but instead adjusts its behavior in accordance with the large-scale pattern of the tidal cycle itself in order to optimize nutrient uptake.
* 25 pages
A Survey of Recommender System Techniques and the Ecommerce Domain
Aug 15, 2022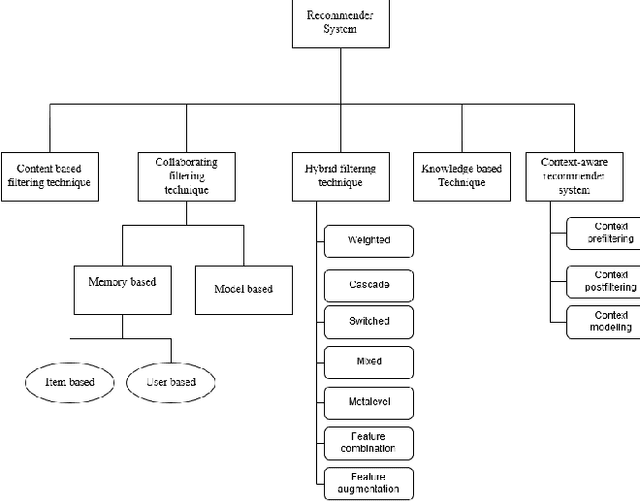

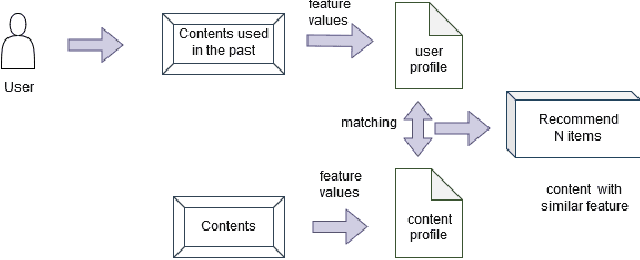
In this big data era, it is hard for the current generation to find the right data from the huge amount of data contained within online platforms. In such a situation, there is a need for an information filtering system that might help them find the information they are looking for. In recent years, a research field has emerged known as recommender systems. Recommenders have become important as they have many real-life applications. This paper reviews the different techniques and developments of recommender systems in e-commerce, e-tourism, e-resources, e-government, e-learning, and e-library. By analyzing recent work on this topic, we will be able to provide a detailed overview of current developments and identify existing difficulties in recommendation systems. The final results give practitioners and researchers the necessary guidance and insights into the recommendation system and its application.
Deep Speech Synthesis from Articulatory Representations
Sep 13, 2022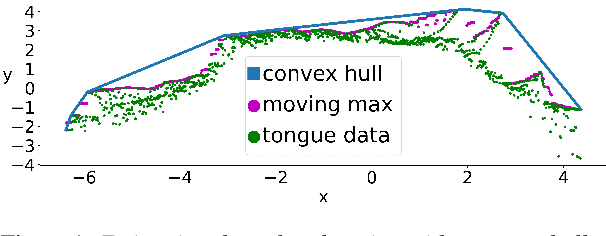

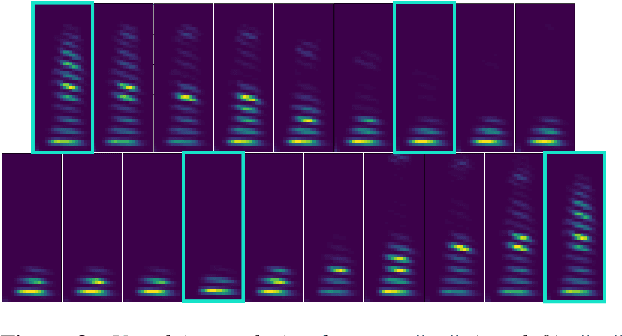
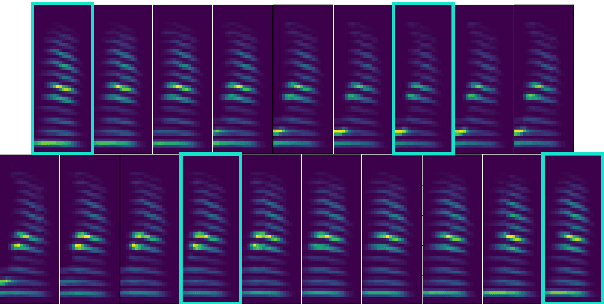
In the articulatory synthesis task, speech is synthesized from input features containing information about the physical behavior of the human vocal tract. This task provides a promising direction for speech synthesis research, as the articulatory space is compact, smooth, and interpretable. Current works have highlighted the potential for deep learning models to perform articulatory synthesis. However, it remains unclear whether these models can achieve the efficiency and fidelity of the human speech production system. To help bridge this gap, we propose a time-domain articulatory synthesis methodology and demonstrate its efficacy with both electromagnetic articulography (EMA) and synthetic articulatory feature inputs. Our model is computationally efficient and achieves a transcription word error rate (WER) of 18.5% for the EMA-to-speech task, yielding an improvement of 11.6% compared to prior work. Through interpolation experiments, we also highlight the generalizability and interpretability of our approach.
Bias amplification in experimental social networks is reduced by resampling
Aug 15, 2022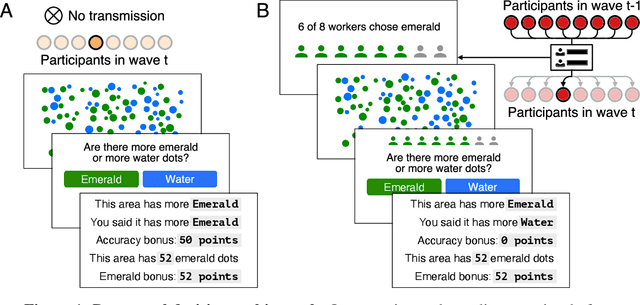
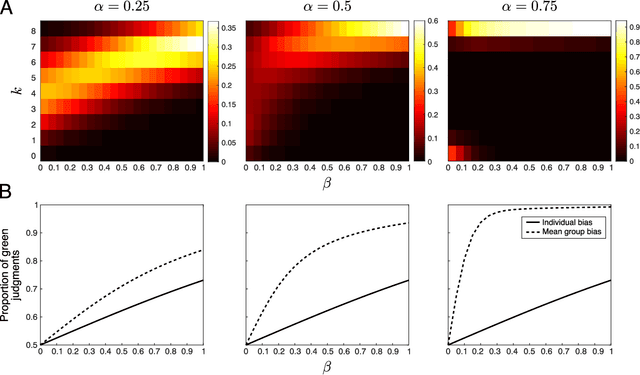
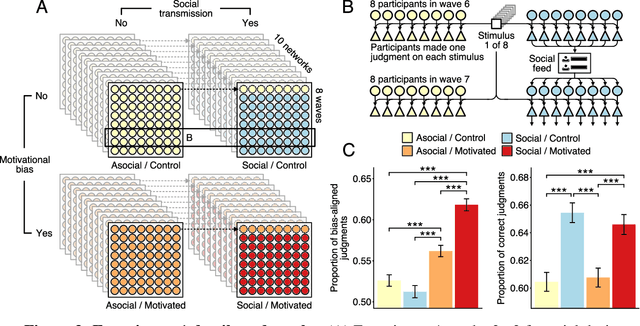
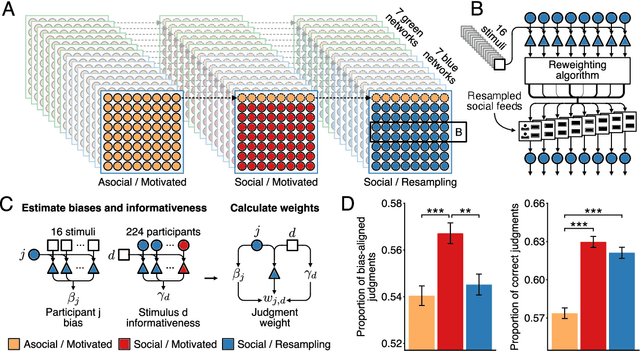
Large-scale social networks are thought to contribute to polarization by amplifying people's biases. However, the complexity of these technologies makes it difficult to identify the mechanisms responsible and to evaluate mitigation strategies. Here we show under controlled laboratory conditions that information transmission through social networks amplifies motivational biases on a simple perceptual decision-making task. Participants in a large behavioral experiment showed increased rates of biased decision-making when part of a social network relative to asocial participants, across 40 independently evolving populations. Drawing on techniques from machine learning and Bayesian statistics, we identify a simple adjustment to content-selection algorithms that is predicted to mitigate bias amplification. This algorithm generates a sample of perspectives from within an individual's network that is more representative of the population as a whole. In a second large experiment, this strategy reduced bias amplification while maintaining the benefits of information sharing.
Physics-Informed Graph Neural Network for Spatial-temporal Production Forecasting
Sep 23, 2022

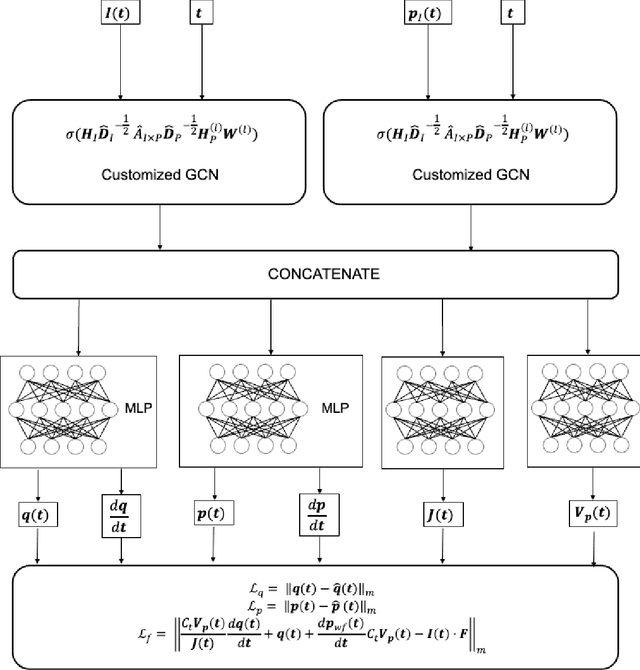
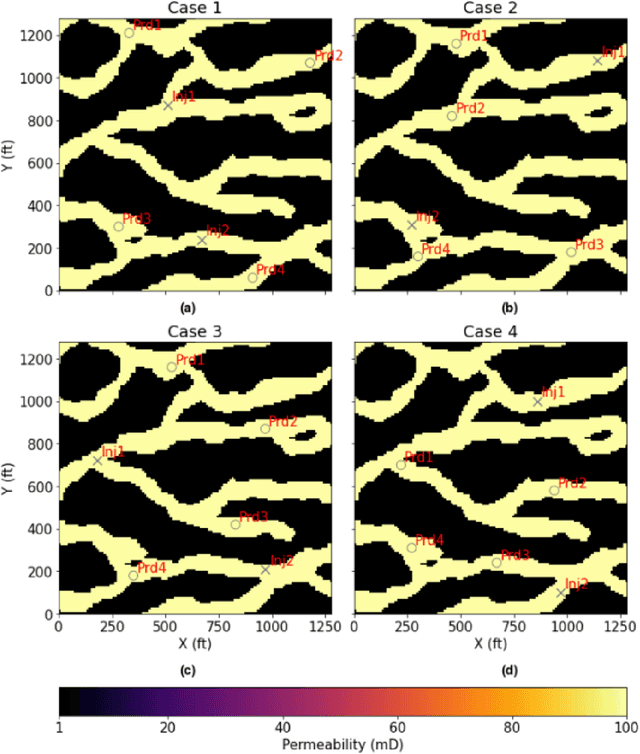
Production forecast based on historical data provides essential value for developing hydrocarbon resources. Classic history matching workflow is often computationally intense and geometry-dependent. Analytical data-driven models like decline curve analysis (DCA) and capacitance resistance models (CRM) provide a grid-free solution with a relatively simple model capable of integrating some degree of physics constraints. However, the analytical solution may ignore subsurface geometries and is appropriate only for specific flow regimes and otherwise may violate physics conditions resulting in degraded model prediction accuracy. Machine learning-based predictive model for time series provides non-parametric, assumption-free solutions for production forecasting, but are prone to model overfit due to training data sparsity; therefore may be accurate over short prediction time intervals. We propose a grid-free, physics-informed graph neural network (PI-GNN) for production forecasting. A customized graph convolution layer aggregates neighborhood information from historical data and has the flexibility to integrate domain expertise into the data-driven model. The proposed method relaxes the dependence on close-form solutions like CRM and honors the given physics-based constraints. Our proposed method is robust, with improved performance and model interpretability relative to the conventional CRM and GNN baseline without physics constraints.
CSSAM: U-net Network for Application and Segmentation of Welding Engineering Drawings
Sep 28, 2022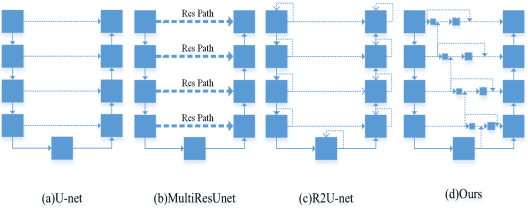
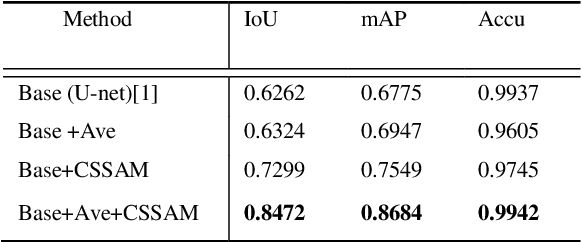
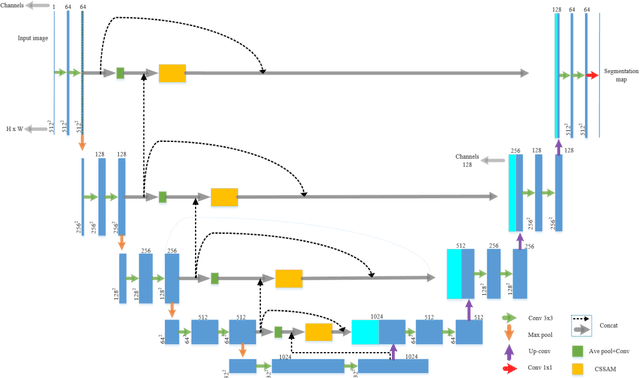

Heavy equipment manufacturing splits specific contours in drawings and cuts sheet metal to scale for welding. Currently, most of the segmentation and extraction of weld map contours is achieved manually. Its efficiency is greatly reduced. Therefore, we propose a U-net-based contour segmentation and extraction method for welding engineering drawings. The contours of the parts required for engineering drawings can be automatically divided and blanked, which significantly improves manufacturing efficiency. U-net includes an encoder-decoder, which implements end-to-end mapping through semantic differences and spatial location feature information between the encoder and decoder. While U-net excels at segmenting medical images, our extensive experiments on the Welding Structural Diagram dataset show that the classic U-Net architecture falls short in segmenting welding engineering drawings. Therefore, we design a novel Channel Spatial Sequence Attention Module (CSSAM) and improve on the classic U-net. At the same time, vertical max pooling and average horizontal pooling are proposed. Pass the pooling operation through two equal convolutions into the CSSAM module. The output and the features before pooling are fused by semantic clustering, which replaces the traditional jump structure and effectively narrows the semantic gap between the encoder and the decoder, thereby improving the segmentation performance of welding engineering drawings. We use vgg16 as the backbone network. Compared with the classic U-net, our network has good performance in engineering drawing dataset segmentation.