 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Capsule Network based Contrastive Learning of Unsupervised Visual Representations
Sep 22, 2022
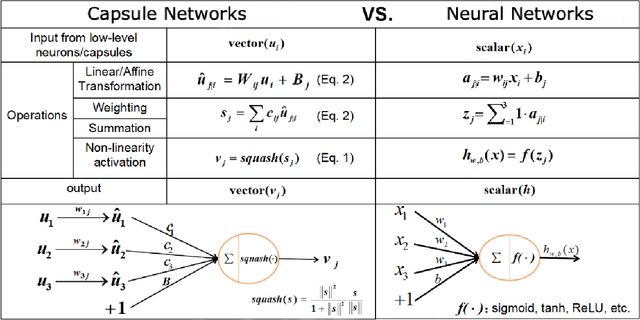

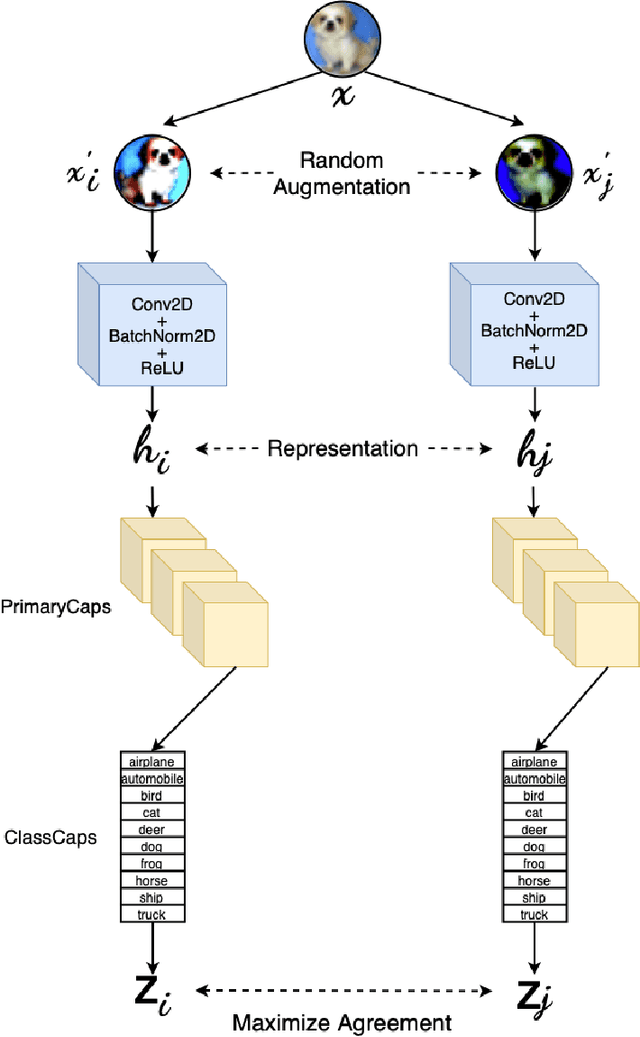
Capsule Networks have shown tremendous advancement in the past decade, outperforming the traditional CNNs in various task due to it's equivariant properties. With the use of vector I/O which provides information of both magnitude and direction of an object or it's part, there lies an enormous possibility of using Capsule Networks in unsupervised learning environment for visual representation tasks such as multi class image classification. In this paper, we propose Contrastive Capsule (CoCa) Model which is a Siamese style Capsule Network using Contrastive loss with our novel architecture, training and testing algorithm. We evaluate the model on unsupervised image classification CIFAR-10 dataset and achieve a top-1 test accuracy of 70.50% and top-5 test accuracy of 98.10%. Due to our efficient architecture our model has 31 times less parameters and 71 times less FLOPs than the current SOTA in both supervised and unsupervised learning.
When Handcrafted Features and Deep Features Meet Mismatched Training and Test Sets for Deepfake Detection
Sep 27, 2022
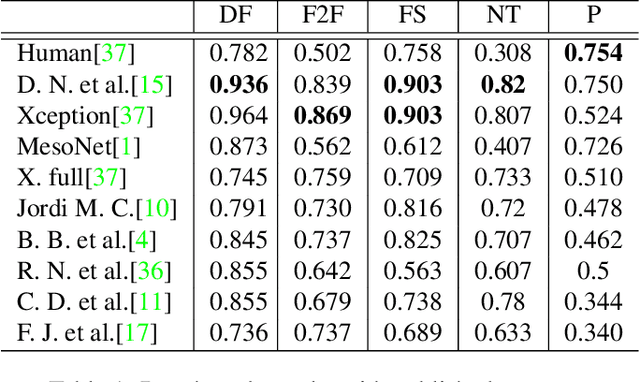
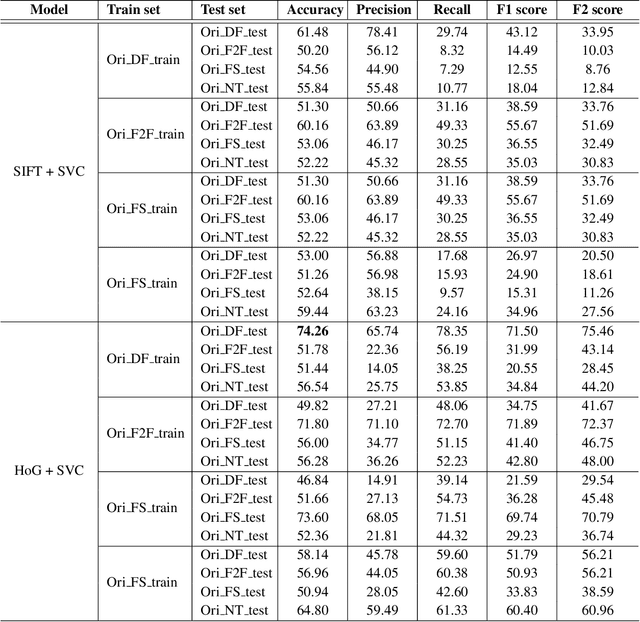
The accelerated growth in synthetic visual media generation and manipulation has now reached the point of raising significant concerns and posing enormous intimidations towards society. There is an imperative need for automatic detection networks towards false digital content and avoid the spread of dangerous artificial information to contend with this threat. In this paper, we utilize and compare two kinds of handcrafted features(SIFT and HoG) and two kinds of deep features(Xception and CNN+RNN) for the deepfake detection task. We also check the performance of these features when there are mismatches between training sets and test sets. Evaluation is performed on the famous FaceForensics++ dataset, which contains four sub-datasets, Deepfakes, Face2Face, FaceSwap and NeuralTextures. The best results are from Xception, where the accuracy could surpass over 99\% when the training and test set are both from the same sub-dataset. In comparison, the results drop dramatically when the training set mismatches the test set. This phenomenon reveals the challenge of creating a universal deepfake detection system.
The mpEDMD Algorithm for Data-Driven Computations of Measure-Preserving Dynamical Systems
Sep 06, 2022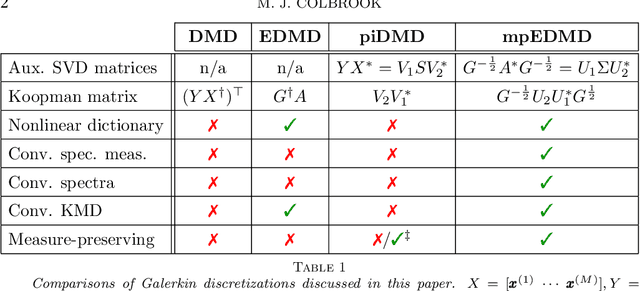
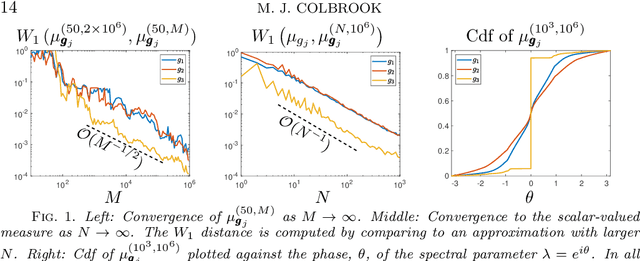
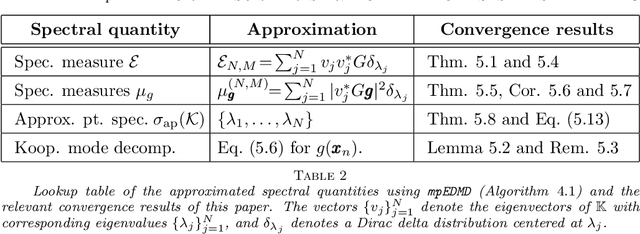
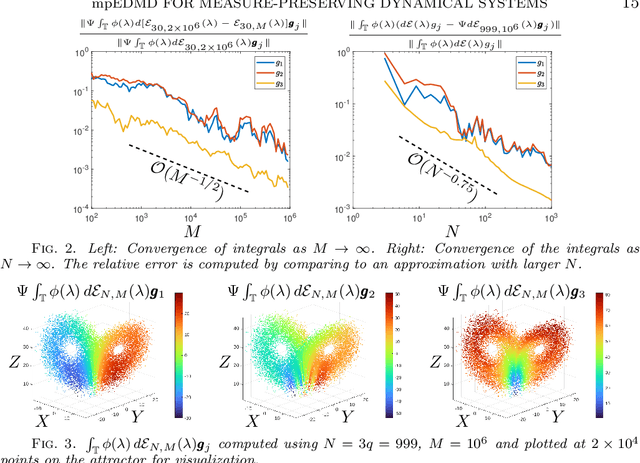
Koopman operators globally linearize nonlinear dynamical systems and their spectral information is a powerful tool for the analysis and decomposition of nonlinear dynamical systems. However, Koopman operators are infinite-dimensional, and computing their spectral information is a considerable challenge. We introduce measure-preserving extended dynamic mode decomposition ($\texttt{mpEDMD}$), the first truncation method whose eigendecomposition converges to the spectral quantities of Koopman operators for general measure-preserving dynamical systems. $\texttt{mpEDMD}$ is a data-driven algorithm based on an orthogonal Procrustes problem that enforces measure-preserving truncations of Koopman operators using a general dictionary of observables. It is flexible and easy to use with any pre-existing DMD-type method, and with different types of data. We prove convergence of $\texttt{mpEDMD}$ for projection-valued and scalar-valued spectral measures, spectra, and Koopman mode decompositions. For the case of delay embedding (Krylov subspaces), our results include the first convergence rates of the approximation of spectral measures as the size of the dictionary increases. We demonstrate $\texttt{mpEDMD}$ on a range of challenging examples, its increased robustness to noise compared with other DMD-type methods, and its ability to capture the energy conservation and cascade of experimental measurements of a turbulent boundary layer flow with Reynolds number $> 6\times 10^4$ and state-space dimension $>10^5$.
Phishing URL Detection: A Network-based Approach Robust to Evasion
Sep 03, 2022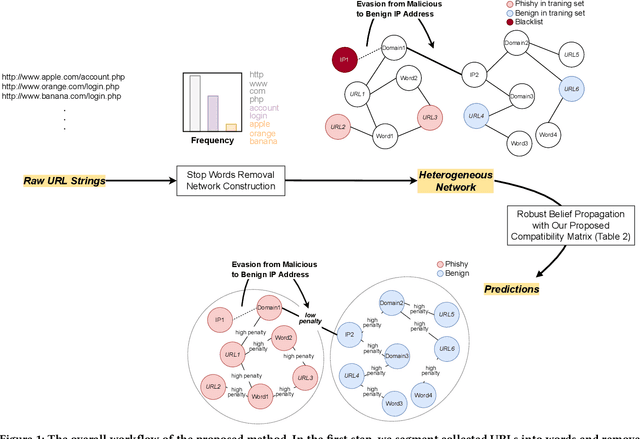

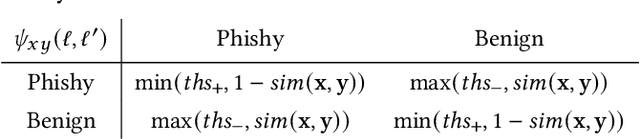
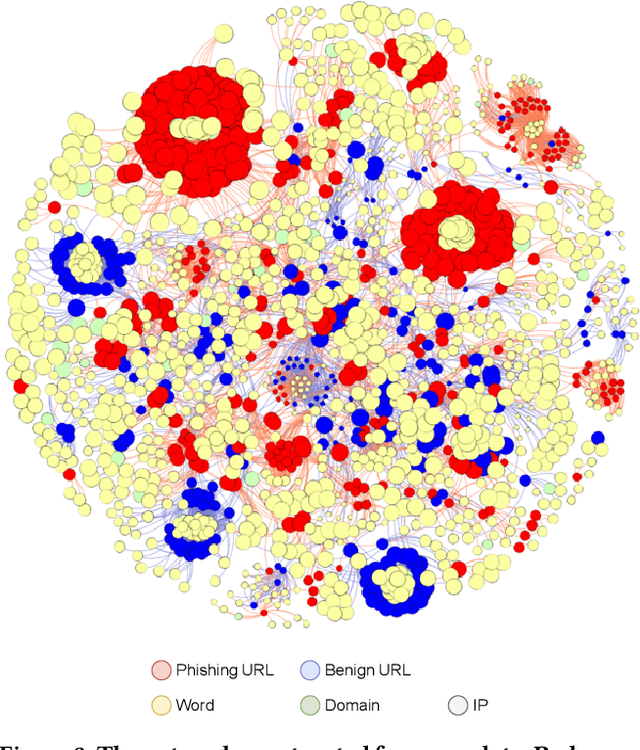
Many cyberattacks start with disseminating phishing URLs. When clicking these phishing URLs, the victim's private information is leaked to the attacker. There have been proposed several machine learning methods to detect phishing URLs. However, it still remains under-explored to detect phishing URLs with evasion, i.e., phishing URLs that pretend to be benign by manipulating patterns. In many cases, the attacker i) reuses prepared phishing web pages because making a completely brand-new set costs non-trivial expenses, ii) prefers hosting companies that do not require private information and are cheaper than others, iii) prefers shared hosting for cost efficiency, and iv) sometimes uses benign domains, IP addresses, and URL string patterns to evade existing detection methods. Inspired by those behavioral characteristics, we present a network-based inference method to accurately detect phishing URLs camouflaged with legitimate patterns, i.e., robust to evasion. In the network approach, a phishing URL will be still identified as phishy even after evasion unless a majority of its neighbors in the network are evaded at the same time. Our method consistently shows better detection performance throughout various experimental tests than state-of-the-art methods, e.g., F-1 of 0.89 for our method vs. 0.84 for the best feature-based method.
A Compact Pretraining Approach for Neural Language Models
Aug 29, 2022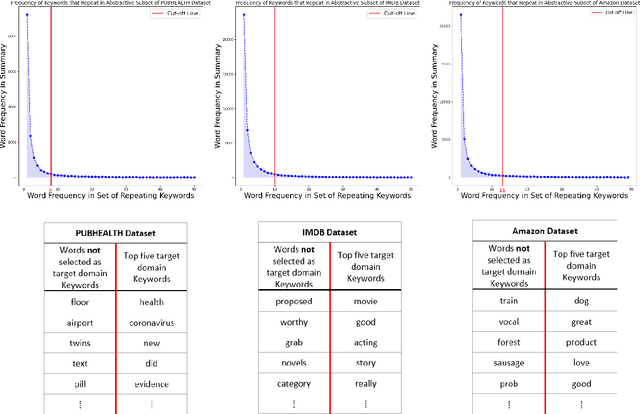
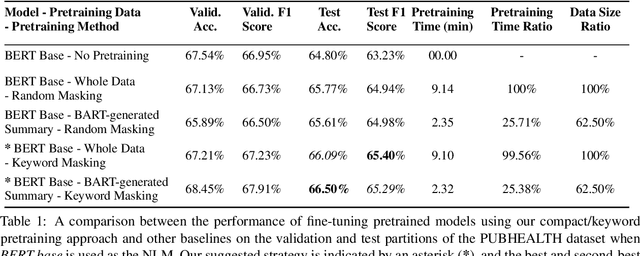
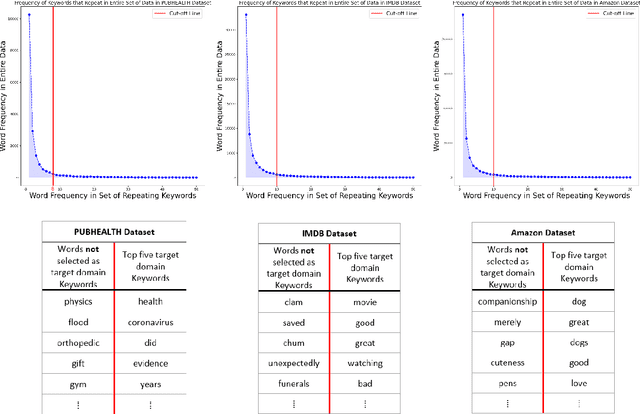
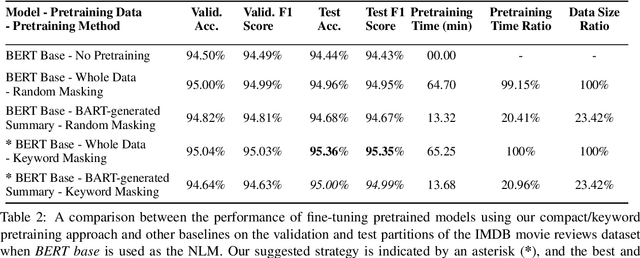
Domain adaptation for large neural language models (NLMs) is coupled with massive amounts of unstructured data in the pretraining phase. In this study, however, we show that pretrained NLMs learn in-domain information more effectively and faster from a compact subset of the data that focuses on the key information in the domain. We construct these compact subsets from the unstructured data using a combination of abstractive summaries and extractive keywords. In particular, we rely on BART to generate abstractive summaries, and KeyBERT to extract keywords from these summaries (or the original unstructured text directly). We evaluate our approach using six different settings: three datasets combined with two distinct NLMs. Our results reveal that the task-specific classifiers trained on top of NLMs pretrained using our method outperform methods based on traditional pretraining, i.e., random masking on the entire data, as well as methods without pretraining. Further, we show that our strategy reduces pretraining time by up to five times compared to vanilla pretraining. The code for all of our experiments is publicly available at https://github.com/shahriargolchin/compact-pretraining.
Deep Reinforcement Learning for Optimal Power Flow with Renewables Using Spatial-Temporal Graph Information
Dec 22, 2021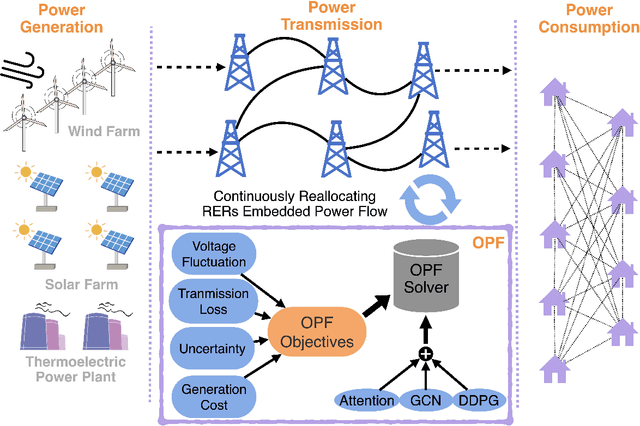
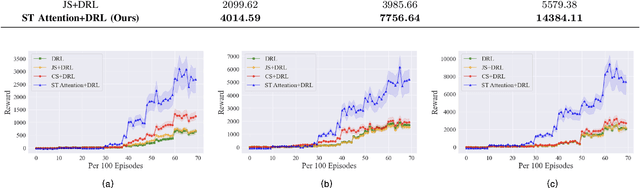
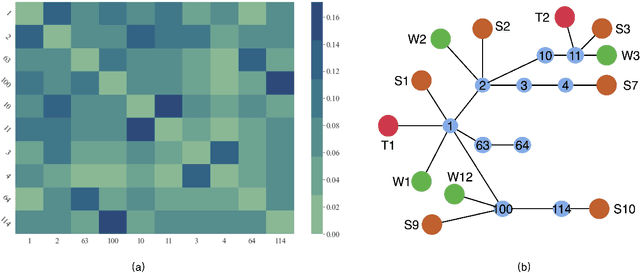
Renewable energy resources (RERs) have been increasingly integrated into modern power systems, especially in large-scale distribution networks (DNs). In this paper, we propose a deep reinforcement learning (DRL)-based approach to dynamically search for the optimal operation point, i.e., optimal power flow (OPF), in DNs with a high uptake of RERs. Considering uncertainties and voltage fluctuation issues caused by RERs, we formulate OPF into a multi-objective optimization (MOO) problem. To solve the MOO problem, we develop a novel DRL algorithm leveraging the graphical information of the distribution network. Specifically, we employ the state-of-the-art DRL algorithm, i.e., deep deterministic policy gradient (DDPG), to learn an optimal strategy for OPF. Since power flow reallocation in the DN is a consecutive process, where nodes are self-correlated and interrelated in temporal and spatial views, to make full use of DNs' graphical information, we develop a multi-grained attention-based spatial-temporal graph convolution network (MG-ASTGCN) for spatial-temporal graph information extraction, preparing for its sequential DDPG. We validate our proposed DRL-based approach in modified IEEE 33, 69, and 118-bus radial distribution systems (RDSs) and show that our DRL-based approach outperforms other benchmark algorithms. Our experimental results also reveal that MG-ASTGCN can significantly accelerate the DDPG training process and improve DDPG's capability in reallocating power flow for OPF. The proposed DRL-based approach also promotes DNs' stability in the presence of node faults, especially for large-scale DNs.
Topics in Deep Learning and Optimization Algorithms for IoT Applications in Smart Transportation
Oct 13, 2022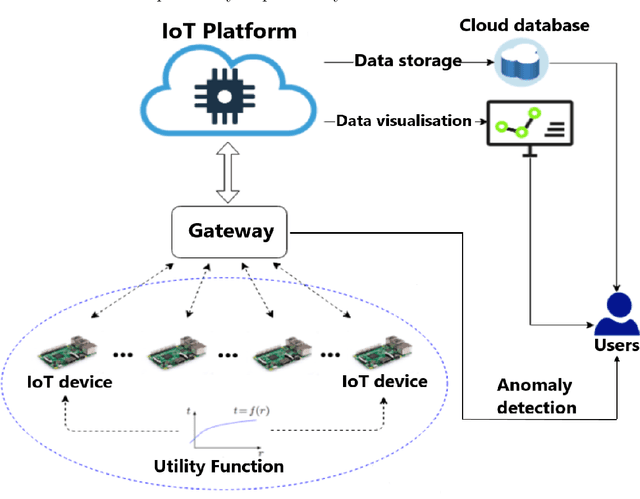

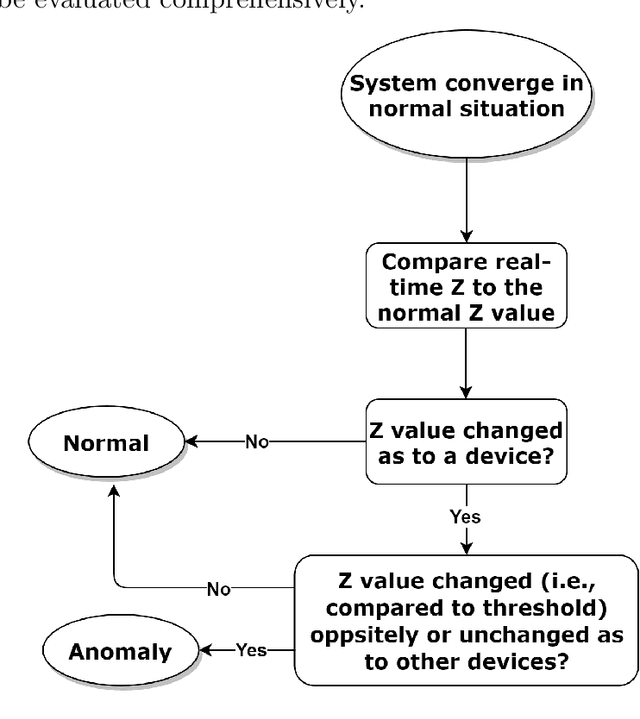

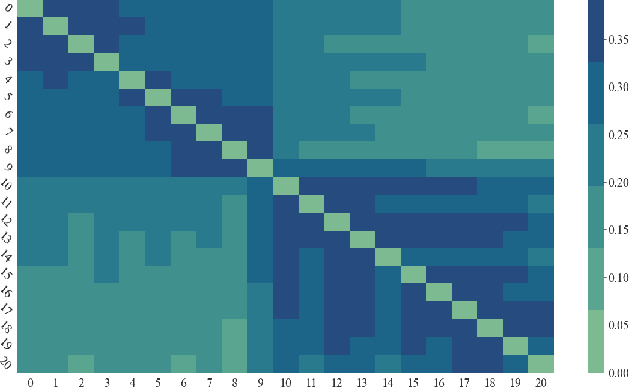
Nowadays, the Internet of Things (IoT) has become one of the most important technologies which enables a variety of connected and intelligent applications in smart cities. The smart decision making process of IoT devices not only relies on the large volume of data collected from their sensors, but also depends on advanced optimization theories and novel machine learning technologies which can process and analyse the collected data in specific network structure. Therefore, it becomes practically important to investigate how different optimization algorithms and machine learning techniques can be leveraged to improve system performance. As one of the most important vertical domains for IoT applications, smart transportation system has played a key role for providing real-world information and services to citizens by making their access to transport facilities easier and thus it is one of the key application areas to be explored in this thesis. In a nutshell, this thesis covers three key topics related to applying mathematical optimization and deep learning methods to IoT networks. In the first topic, we propose an optimal transmission frequency management scheme using decentralized ADMM-based method in a IoT network and introduce a mechanism to identify anomalies in data transmission frequency using an LSTM-based architecture. In the second topic, we leverage graph neural network (GNN) for demand prediction for shared bikes. In particular, we introduce a novel architecture, i.e., attention-based spatial temporal graph convolutional network (AST-GCN), to improve the prediction accuracy in real world datasets. In the last topic, we consider a highway traffic network scenario where frequent lane changing behaviors may occur with probability. A specific GNN based anomaly detector is devised to reveal such a probability driven by data collected in a dedicated mobility simulator.
Using Entropy Measures for Monitoring the Evolution of Activity Patterns
Oct 05, 2022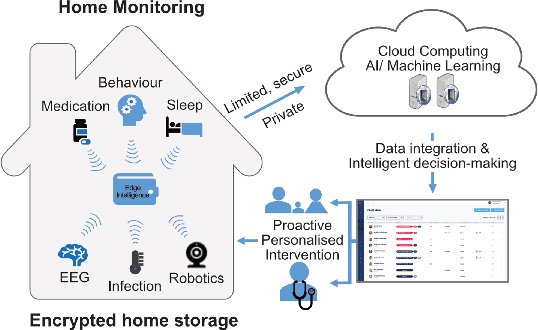
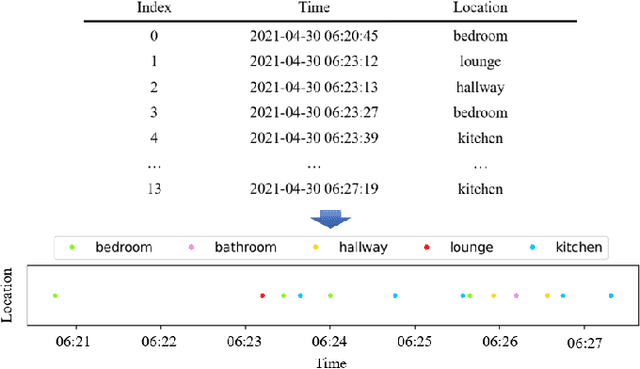
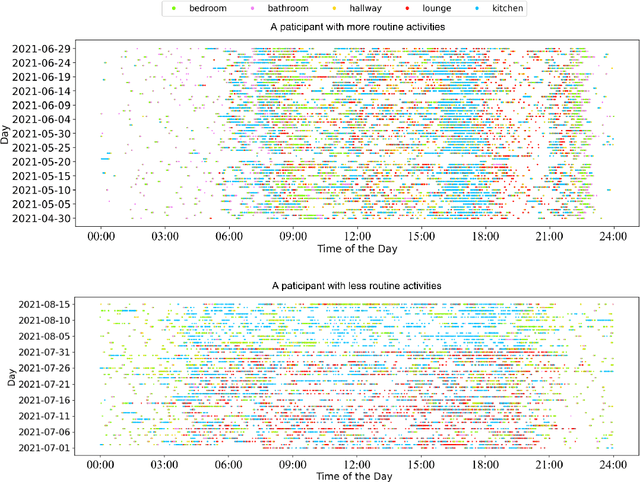
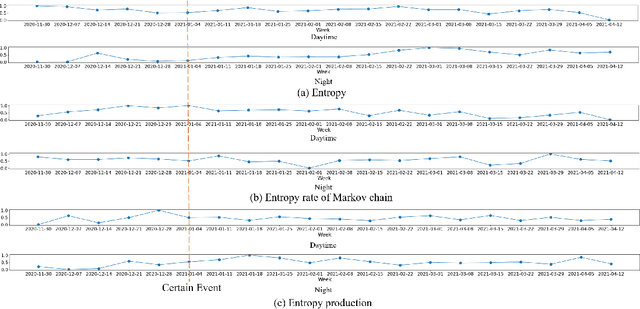
In this work, we apply information theory inspired methods to quantify changes in daily activity patterns. We use in-home movement monitoring data and show how they can help indicate the occurrence of healthcare-related events. Three different types of entropy measures namely Shannon's entropy, entropy rates for Markov chains, and entropy production rate have been utilised. The measures are evaluated on a large-scale in-home monitoring dataset that has been collected within our dementia care clinical study. The study uses Internet of Things (IoT) enabled solutions for continuous monitoring of in-home activity, sleep, and physiology to develop care and early intervention solutions to support people living with dementia (PLWD) in their own homes. Our main goal is to show the applicability of the entropy measures to time-series activity data analysis and to use the extracted measures as new engineered features that can be fed into inference and analysis models. The results of our experiments show that in most cases the combination of these measures can indicate the occurrence of healthcare-related events. We also find that different participants with the same events may have different measures based on one entropy measure. So using a combination of these measures in an inference model will be more effective than any of the single measures.
Tradeoffs between convergence rate and noise amplification for momentum-based accelerated optimization algorithms
Sep 24, 2022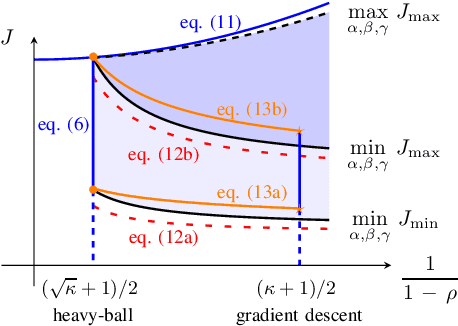
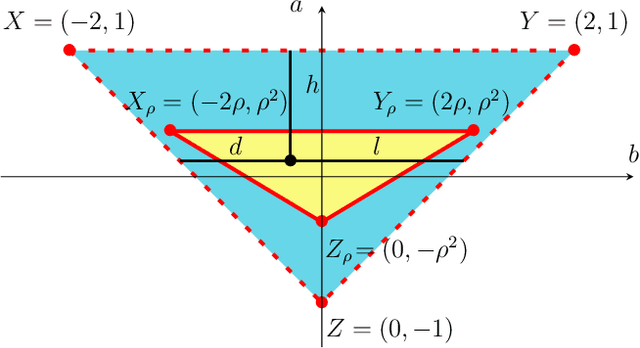

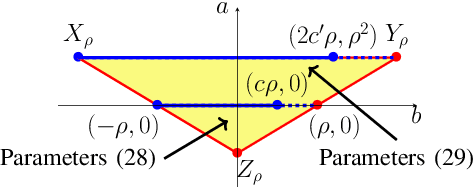
We study momentum-based first-order optimization algorithms in which the iterations utilize information from the two previous steps and are subject to an additive white noise. This class of algorithms includes heavy-ball and Nesterov's accelerated methods as special cases. For strongly convex quadratic problems, we use the steady-state variance of the error in the optimization variable to quantify noise amplification and exploit a novel geometric viewpoint to establish analytical lower bounds on the product between the settling time and the smallest/largest achievable noise amplification. For all stabilizing parameters, these bounds scale quadratically with the condition number. We also use the geometric insight developed in the paper to introduce two parameterized families of algorithms that strike a balance between noise amplification and settling time while preserving order-wise Pareto optimality. Finally, for a class of continuous-time gradient flow dynamics, whose suitable discretization yields two-step momentum algorithm, we establish analogous lower bounds that also scale quadratically with the condition number.
Are disentangled representations all you need to build speaker anonymization systems?
Aug 24, 2022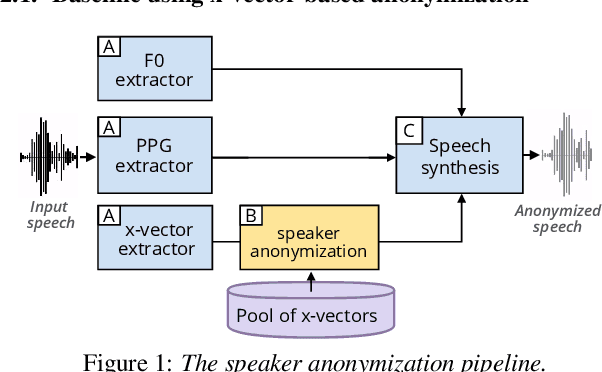
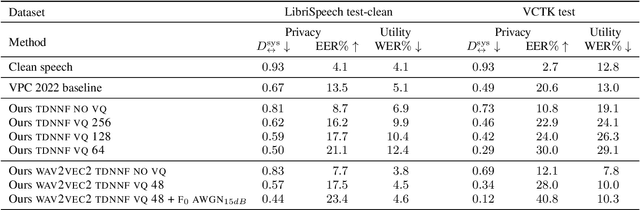
Speech signals contain a lot of sensitive information, such as the speaker's identity, which raises privacy concerns when speech data get collected. Speaker anonymization aims to transform a speech signal to remove the source speaker's identity while leaving the spoken content unchanged. Current methods perform the transformation by relying on content/speaker disentanglement and voice conversion. Usually, an acoustic model from an automatic speech recognition system extracts the content representation while an x-vector system extracts the speaker representation. Prior work has shown that the extracted features are not perfectly disentangled. This paper tackles how to improve features disentanglement, and thus the converted anonymized speech. We propose enhancing the disentanglement by removing speaker information from the acoustic model using vector quantization. Evaluation done using the VoicePrivacy 2022 toolkit showed that vector quantization helps conceal the original speaker identity while maintaining utility for speech recognition.