 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DOTIE -- Detecting Objects through Temporal Isolation of Events using a Spiking Architecture
Oct 03, 2022
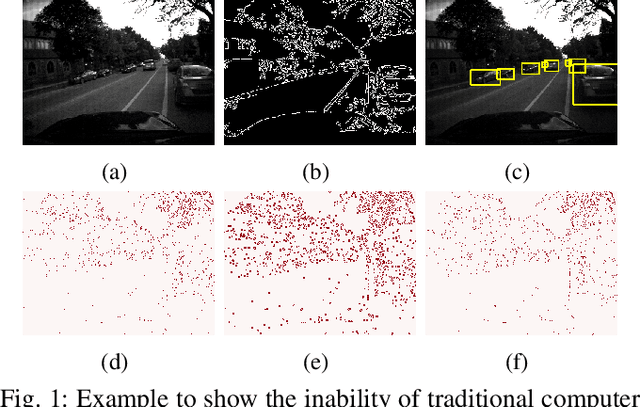
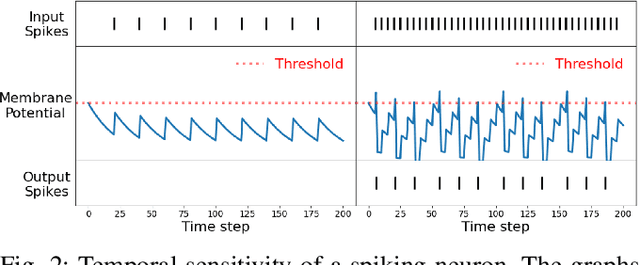
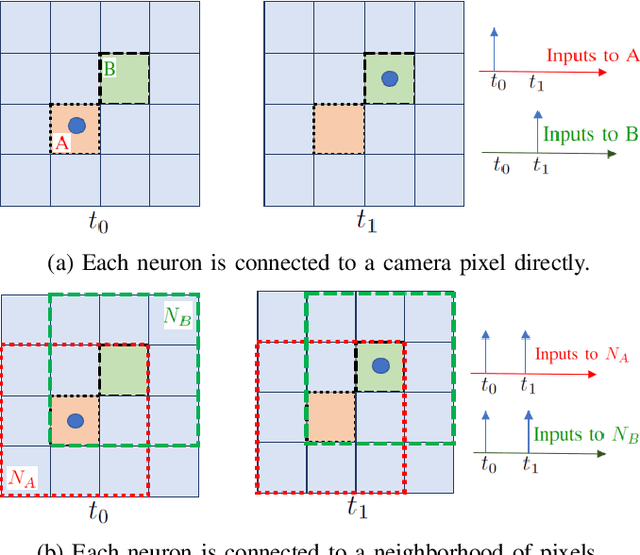
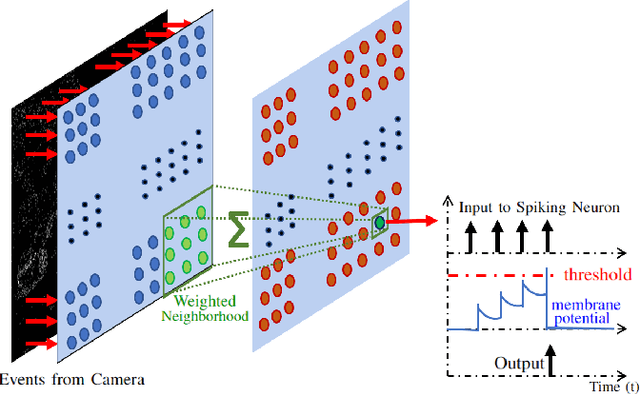
Vision-based autonomous navigation systems rely on fast and accurate object detection algorithms to avoid obstacles. Algorithms and sensors designed for such systems need to be computationally efficient, due to the limited energy of the hardware used for deployment. Biologically inspired event cameras are a good candidate as a vision sensor for such systems due to their speed, energy efficiency, and robustness to varying lighting conditions. However, traditional computer vision algorithms fail to work on event-based outputs, as they lack photometric features such as light intensity and texture. In this work, we propose a novel technique that utilizes the temporal information inherently present in the events to efficiently detect moving objects. Our technique consists of a lightweight spiking neural architecture that is able to separate events based on the speed of the corresponding objects. These separated events are then further grouped spatially to determine object boundaries. This method of object detection is both asynchronous and robust to camera noise. In addition, it shows good performance in scenarios with events generated by static objects in the background, where existing event-based algorithms fail. We show that by utilizing our architecture, autonomous navigation systems can have minimal latency and energy overheads for performing object detection.
Multi-view object pose estimation from correspondence distributions and epipolar geometry
Oct 03, 2022

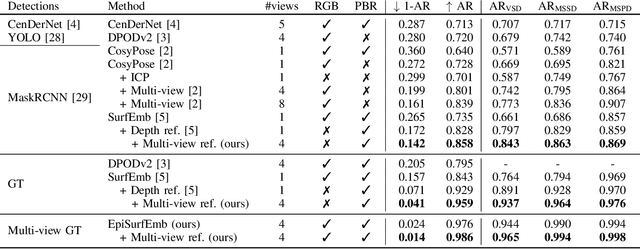
In many automation tasks involving manipulation of rigid objects, the poses of the objects must be acquired. Vision-based pose estimation using a single RGB or RGB-D sensor is especially popular due to its broad applicability. However, single-view pose estimation is inherently limited by depth ambiguity and ambiguities imposed by various phenomena like occlusion, self-occlusion, reflections, etc. Aggregation of information from multiple views can potentially resolve these ambiguities, but the current state-of-the-art multi-view pose estimation method only uses multiple views to aggregate single-view pose estimates, and thus rely on obtaining good single-view estimates. We present a multi-view pose estimation method which aggregates learned 2D-3D distributions from multiple views for both the initial estimate and optional refinement. Our method performs probabilistic sampling of 3D-3D correspondences under epipolar constraints using learned 2D-3D correspondence distributions which are implicitly trained to respect visual ambiguities such as symmetry. Evaluation on the T-LESS dataset shows that our method reduces pose estimation errors by 80-91% compared to the best single-view method, and we present state-of-the-art results on T-LESS with four views, even compared with methods using five and eight views.
NAS-based Recursive Stage Partial Network (RSPNet) for Light-Weight Semantic Segmentation
Oct 03, 2022

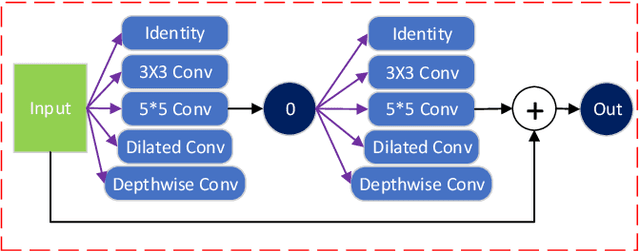
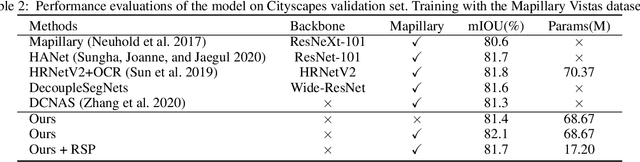
Current NAS-based semantic segmentation methods focus on accuracy improvements rather than light-weight design. In this paper, we proposed a two-stage framework to design our NAS-based RSPNet model for light-weight semantic segmentation. The first architecture search determines the inner cell structure, and the second architecture search considers exponentially growing paths to finalize the outer structure of the network. It was shown in the literature that the fusion of high- and low-resolution feature maps produces stronger representations. To find the expected macro structure without manual design, we adopt a new path-attention mechanism to efficiently search for suitable paths to fuse useful information for better segmentation. Our search for repeatable micro-structures from cells leads to a superior network architecture in semantic segmentation. In addition, we propose an RSP (recursive Stage Partial) architecture to search a light-weight design for NAS-based semantic segmentation. The proposed architecture is very efficient, simple, and effective that both the macro- and micro- structure searches can be completed in five days of computation on two V100 GPUs. The light-weight NAS architecture with only 1/4 parameter size of SoTA architectures can achieve SoTA performance on semantic segmentation on the Cityscapes dataset without using any backbones.
The ReturnZero System for VoxCeleb Speaker Recognition Challenge 2022
Sep 21, 2022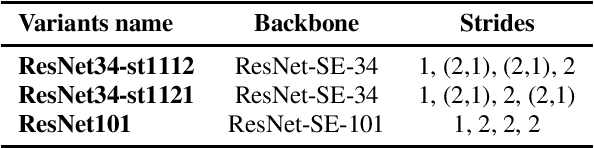
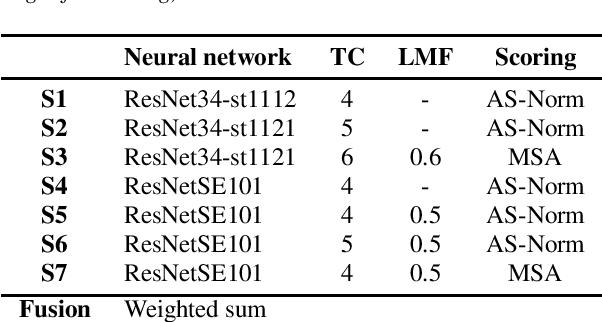
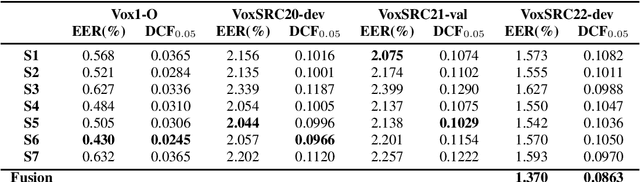
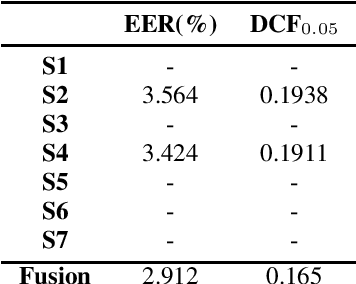
In this paper, we describe the top-scoring submissions for team RTZR VoxCeleb Speaker Recognition Challenge 2022 (VoxSRC-22) in the closed dataset, speaker verification Track 1. The top performed system is a fusion of 7 models, which contains 3 different types of model architectures. We focus on training models to learn extra-temporal information. Therefore, all models were trained with 4-6 second frames for each utterance. Also, we apply the Large Margin Fine-tuning strategy which has shown good performance on the previous challenges for some of our fusion models. While the evaluation process, we apply the scoring methods with adaptive symmetric normalization (AS-Norm) and matrix score average (MSA). Finally, we mix up models with logistic regression to fuse all the trained models. The final submission achieves 0.165 DCF and 2.912% EER on the VoxSRC22 test set.
Reconstructing Missing EHRs Using Time-Aware Within- and Cross-Visit Information for Septic Shock Early Prediction
Mar 15, 2022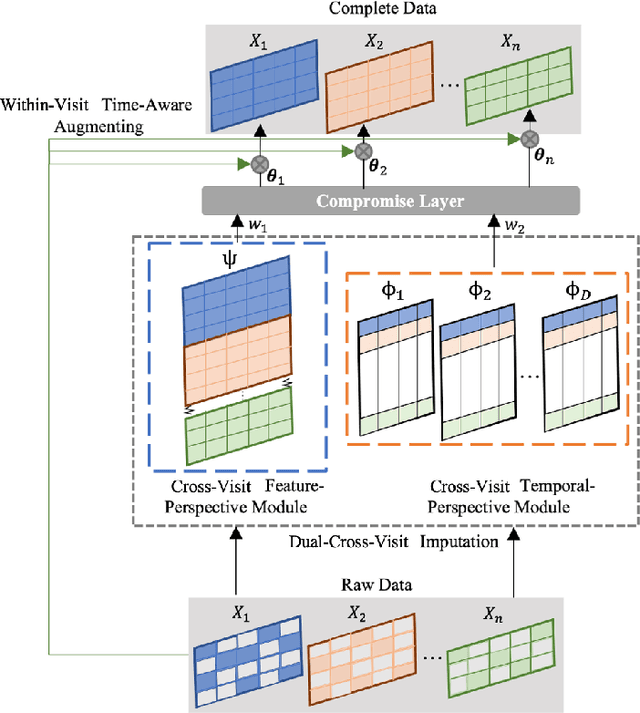
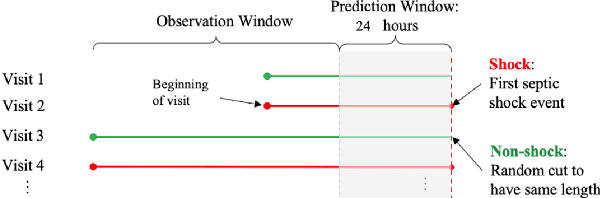
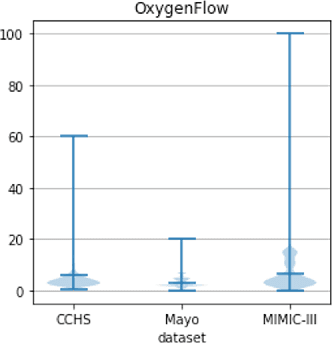
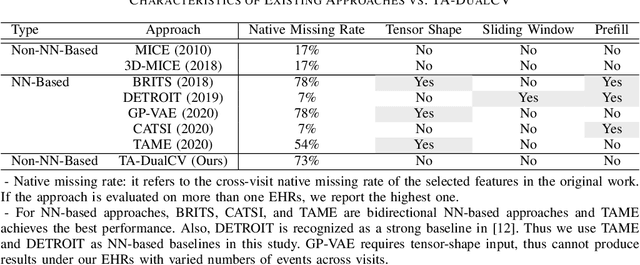
Real-world Electronic Health Records (EHRs) are often plagued by a high rate of missing data. In our EHRs, for example, the missing rates can be as high as 90% for some features, with an average missing rate of around 70% across all features. We propose a Time-Aware Dual-Cross-Visit missing value imputation method, named TA-DualCV, which spontaneously leverages multivariate dependencies across features and longitudinal dependencies both within- and cross-visit to maximize the information extracted from limited observable records in EHRs. Specifically, TA-DualCV captures the latent structure of missing patterns across measurements of different features and it also considers the time continuity and capture the latent temporal missing patterns based on both time-steps and irregular time-intervals. TA-DualCV is evaluated using three large real-world EHRs on two types of tasks: an unsupervised imputation task by varying mask rates up to 90% and a supervised 24-hour early prediction of septic shock using Long Short-Term Memory (LSTM). Our results show that TA-DualCV performs significantly better than all of the existing state-of-the-art imputation baselines, such as DETROIT and TAME, on both types of tasks.
Mapping STI ecosystems via Open Data: overcoming the limitations of conflicting taxonomies. A case study for Climate Change Research in Denmark
Sep 19, 2022Science, Technology and Innovation (STI) decision-makers often need to have a clear vision of what is researched and by whom to design effective policies. Such a vision is provided by effective and comprehensive mappings of the research activities carried out within their institutional boundaries. A major challenge to be faced in this context is the difficulty in accessing the relevant data and in combining information coming from different sources: indeed, traditionally, STI data has been confined within closed data sources and, when available, it is categorised with different taxonomies. Here, we present a proof-of-concept study of the use of Open Resources to map the research landscape on the Sustainable Development Goal (SDG) 13-Climate Action, for an entire country, Denmark, and we map it on the 25 ERC panels.
Two-Step Color-Polarization Demosaicking Network
Sep 13, 2022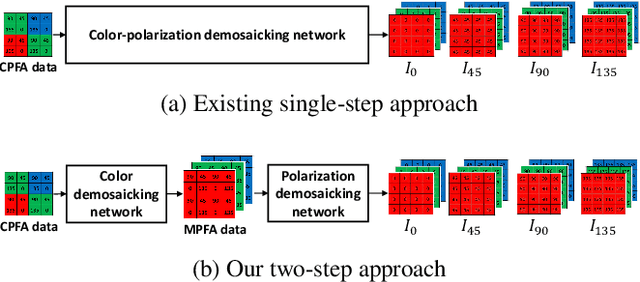
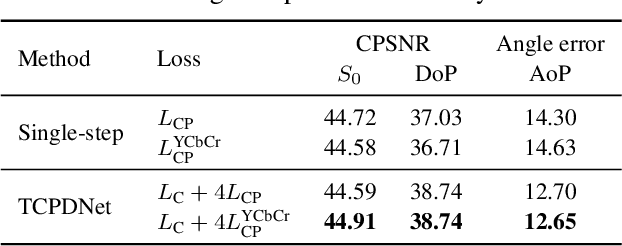
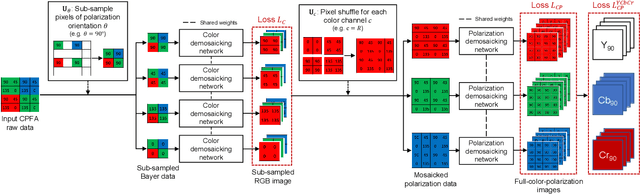
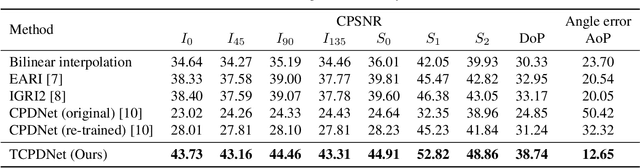
Polarization information of light in a scene is valuable for various image processing and computer vision tasks. A division-of-focal-plane polarimeter is a promising approach to capture the polarization images of different orientations in one shot, while it requires color-polarization demosaicking. In this paper, we propose a two-step color-polarization demosaicking network~(TCPDNet), which consists of two sub-tasks of color demosaicking and polarization demosaicking. We also introduce a reconstruction loss in the YCbCr color space to improve the performance of TCPDNet. Experimental comparisons demonstrate that TCPDNet outperforms existing methods in terms of the image quality of polarization images and the accuracy of Stokes parameters.
NeuralMarker: A Framework for Learning General Marker Correspondence
Sep 19, 2022
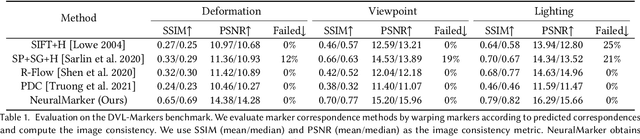

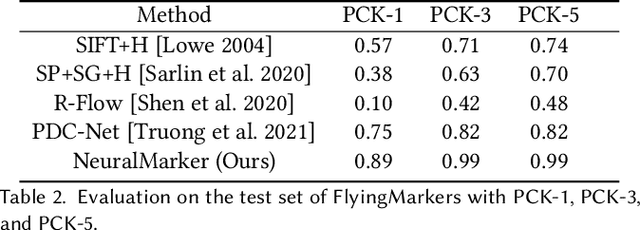
We tackle the problem of estimating correspondences from a general marker, such as a movie poster, to an image that captures such a marker. Conventionally, this problem is addressed by fitting a homography model based on sparse feature matching. However, they are only able to handle plane-like markers and the sparse features do not sufficiently utilize appearance information. In this paper, we propose a novel framework NeuralMarker, training a neural network estimating dense marker correspondences under various challenging conditions, such as marker deformation, harsh lighting, etc. Besides, we also propose a novel marker correspondence evaluation method circumstancing annotations on real marker-image pairs and create a new benchmark. We show that NeuralMarker significantly outperforms previous methods and enables new interesting applications, including Augmented Reality (AR) and video editing.
A PDE approach for regret bounds under partial monitoring
Sep 02, 2022In this paper, we study a learning problem in which a forecaster only observes partial information. By properly rescaling the problem, we heuristically derive a limiting PDE on Wasserstein space which characterizes the asymptotic behavior of the regret of the forecaster. Using a verification type argument, we show that the problem of obtaining regret bounds and efficient algorithms can be tackled by finding appropriate smooth sub/supersolutions of this parabolic PDE.
Capsule Network based Contrastive Learning of Unsupervised Visual Representations
Sep 22, 2022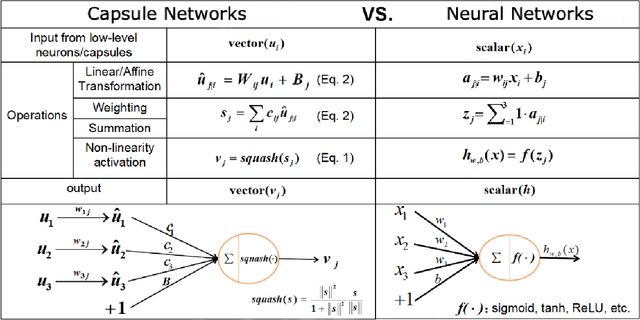

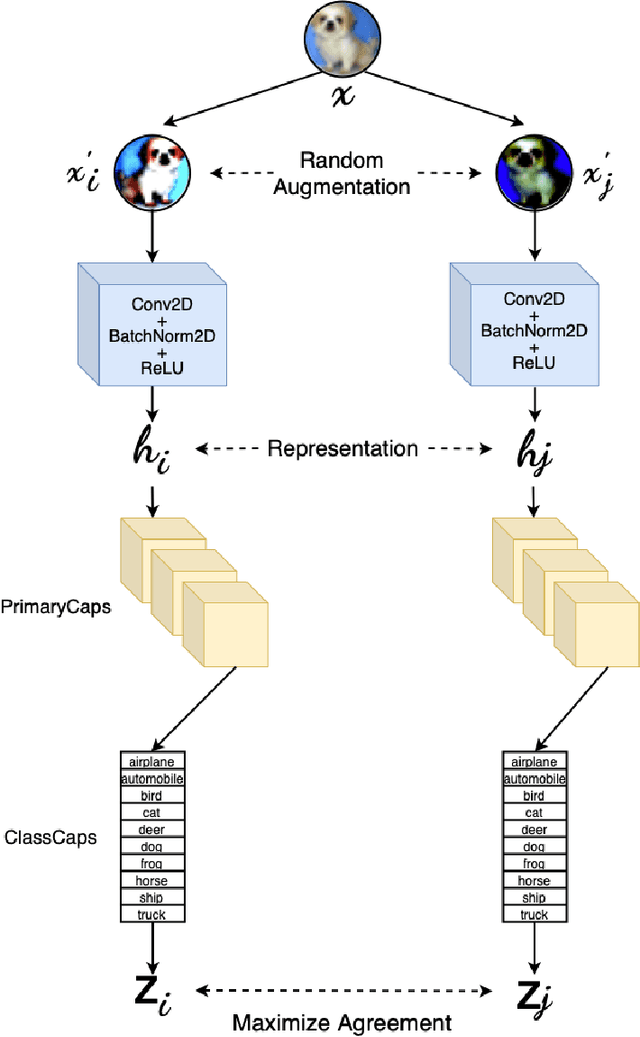
Capsule Networks have shown tremendous advancement in the past decade, outperforming the traditional CNNs in various task due to it's equivariant properties. With the use of vector I/O which provides information of both magnitude and direction of an object or it's part, there lies an enormous possibility of using Capsule Networks in unsupervised learning environment for visual representation tasks such as multi class image classification. In this paper, we propose Contrastive Capsule (CoCa) Model which is a Siamese style Capsule Network using Contrastive loss with our novel architecture, training and testing algorithm. We evaluate the model on unsupervised image classification CIFAR-10 dataset and achieve a top-1 test accuracy of 70.50% and top-5 test accuracy of 98.10%. Due to our efficient architecture our model has 31 times less parameters and 71 times less FLOPs than the current SOTA in both supervised and unsupervised learning.