 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Cross-Network Social User Embedding with Hybrid Differential Privacy Guarantees
Sep 04, 2022
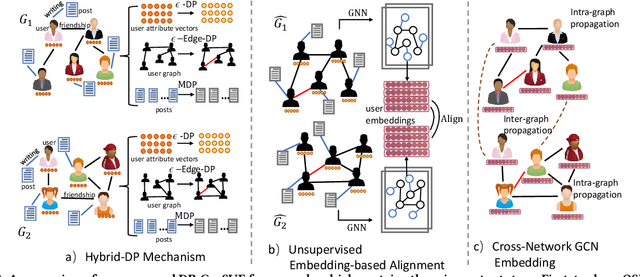

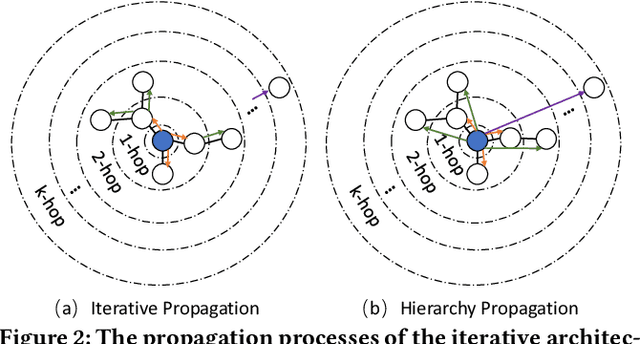
Integrating multiple online social networks (OSNs) has important implications for many downstream social mining tasks, such as user preference modelling, recommendation, and link prediction. However, it is unfortunately accompanied by growing privacy concerns about leaking sensitive user information. How to fully utilize the data from different online social networks while preserving user privacy remains largely unsolved. To this end, we propose a Cross-network Social User Embedding framework, namely DP-CroSUE, to learn the comprehensive representations of users in a privacy-preserving way. We jointly consider information from partially aligned social networks with differential privacy guarantees. In particular, for each heterogeneous social network, we first introduce a hybrid differential privacy notion to capture the variation of privacy expectations for heterogeneous data types. Next, to find user linkages across social networks, we make unsupervised user embedding-based alignment in which the user embeddings are achieved by the heterogeneous network embedding technology. To further enhance user embeddings, a novel cross-network GCN embedding model is designed to transfer knowledge across networks through those aligned users. Extensive experiments on three real-world datasets demonstrate that our approach makes a significant improvement on user interest prediction tasks as well as defending user attribute inference attacks from embedding.
SongDriver: Real-time Music Accompaniment Generation without Logical Latency nor Exposure Bias
Sep 13, 2022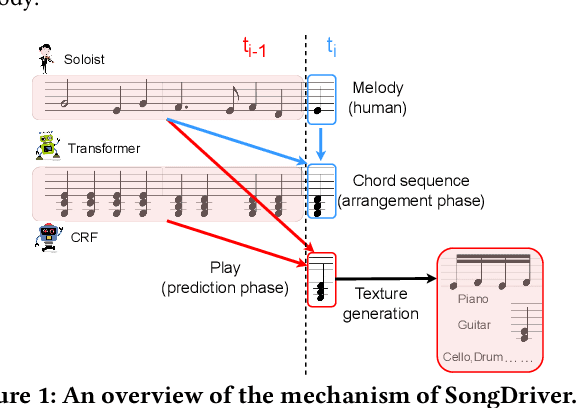
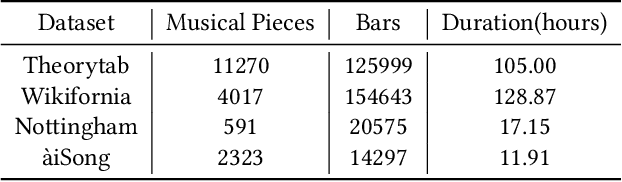
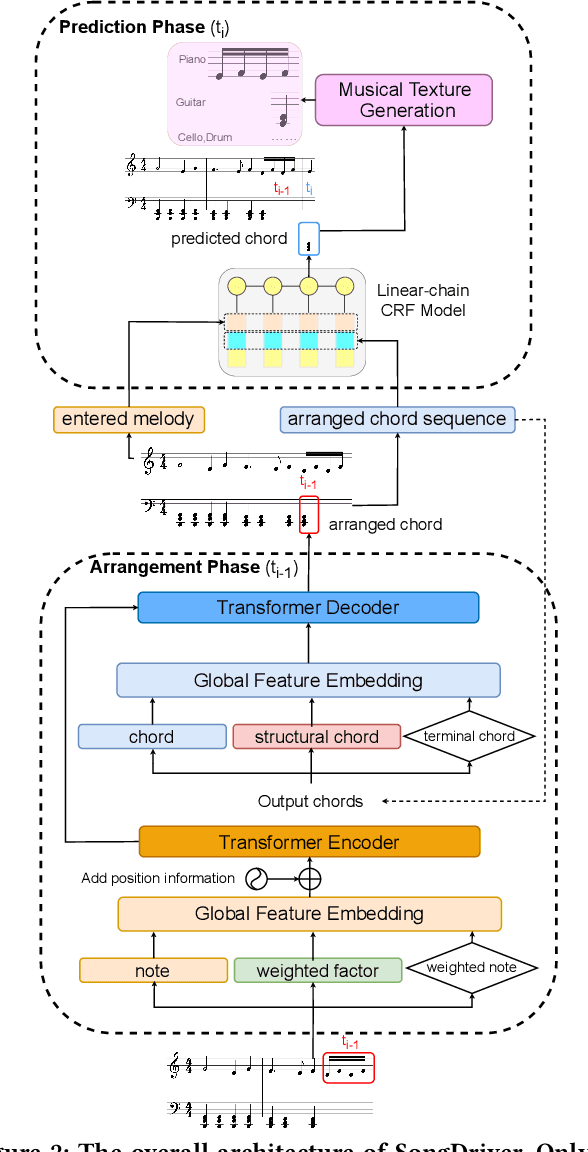
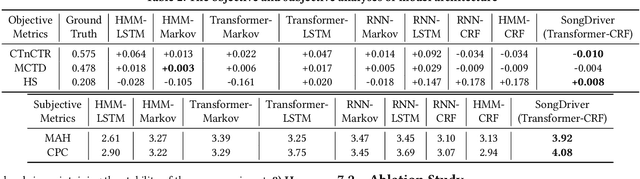
Real-time music accompaniment generation has a wide range of applications in the music industry, such as music education and live performances. However, automatic real-time music accompaniment generation is still understudied and often faces a trade-off between logical latency and exposure bias. In this paper, we propose SongDriver, a real-time music accompaniment generation system without logical latency nor exposure bias. Specifically, SongDriver divides one accompaniment generation task into two phases: 1) The arrangement phase, where a Transformer model first arranges chords for input melodies in real-time, and caches the chords for the next phase instead of playing them out. 2) The prediction phase, where a CRF model generates playable multi-track accompaniments for the coming melodies based on previously cached chords. With this two-phase strategy, SongDriver directly generates the accompaniment for the upcoming melody, achieving zero logical latency. Furthermore, when predicting chords for a timestep, SongDriver refers to the cached chords from the first phase rather than its previous predictions, which avoids the exposure bias problem. Since the input length is often constrained under real-time conditions, another potential problem is the loss of long-term sequential information. To make up for this disadvantage, we extract four musical features from a long-term music piece before the current time step as global information. In the experiment, we train SongDriver on some open-source datasets and an original \`aiSong Dataset built from Chinese-style modern pop music scores. The results show that SongDriver outperforms existing SOTA (state-of-the-art) models on both objective and subjective metrics, meanwhile significantly reducing the physical latency.
Suture Thread Spline Reconstruction from Endoscopic Images for Robotic Surgery with Reliability-driven Keypoint Detection
Sep 27, 2022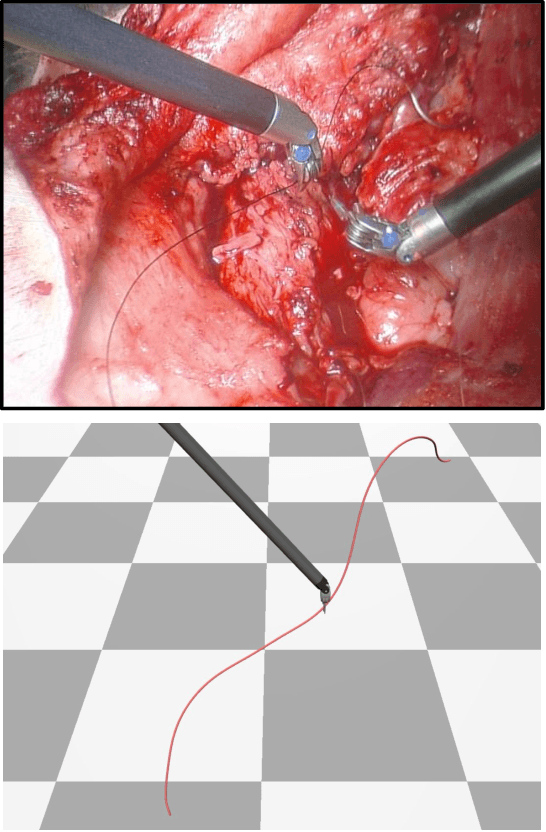
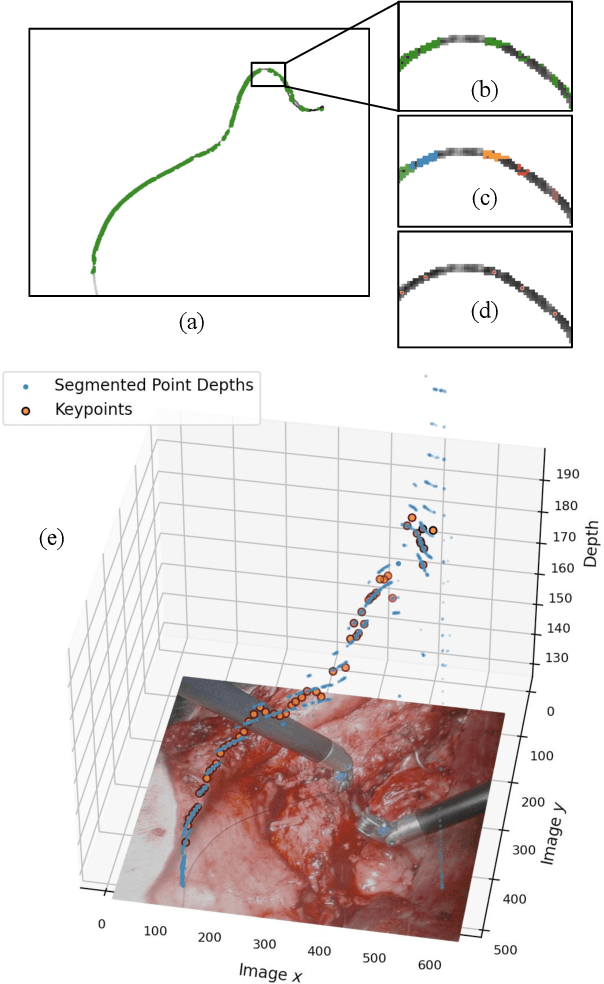
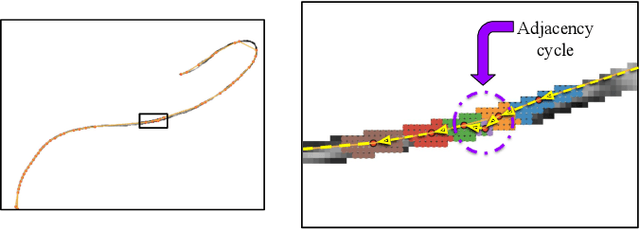
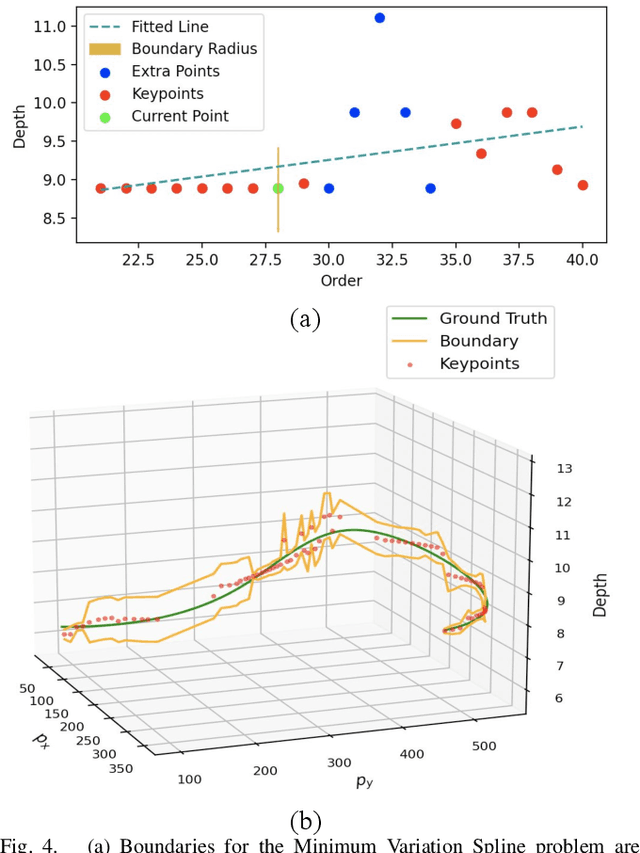
Automating the process of manipulating and delivering sutures during robotic surgery is a prominent problem at the frontier of surgical robotics, as automating this task can significantly reduce surgeons' fatigue during tele-operated surgery and allow them to spend more time addressing higher-level clinical decision making. Accomplishing autonomous suturing and suture manipulation in the real world requires accurate suture thread localization and reconstruction, the process of creating a 3D shape representation of suture thread from 2D stereo camera surgical image pairs. This is a very challenging problem due to how limited pixel information is available for the threads, as well as their sensitivity to lighting and specular reflection. We present a suture thread reconstruction work that uses reliable keypoints and a Minimum Variation Spline (MVS) smoothing optimization to construct a 3D centerline from a segmented surgical image pair. This method is comparable to previous suture thread reconstruction works, with the possible benefit of increased accuracy of grasping point estimation. Our code and datasets will be available at: https://github.com/ucsdarclab/thread-reconstruction.
Inclusive Ethical Design for Recommender Systems
Sep 13, 2022Recommender systems are becoming increasingly central as mediators of information with the potential to profoundly influence societal opinion. While approaches are being developed to ensure these systems are designed in a responsible way, adolescents in particular, represent a potentially vulnerable user group requiring explicit consideration. This is especially important given the nature of their access and use of recommender systems but also their role as providers of content. This paper proposes core principles for the ethical design of recommender systems and evaluates whether current approaches to ensuring adherence to these principles are sufficiently inclusive of the particular needs and potential vulnerabilities of adolescent users.
Multi-Task Vision Transformer for Semi-Supervised Driver Distraction Detection
Sep 19, 2022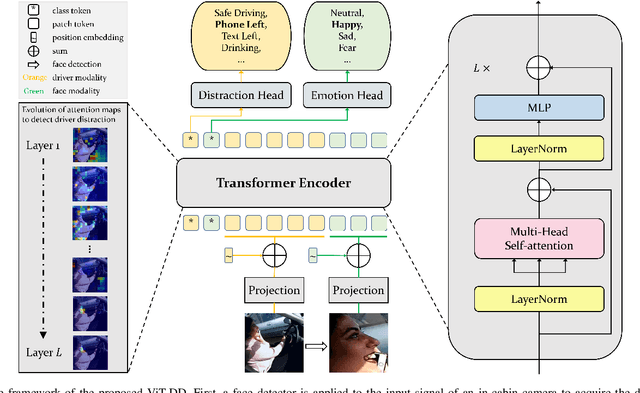


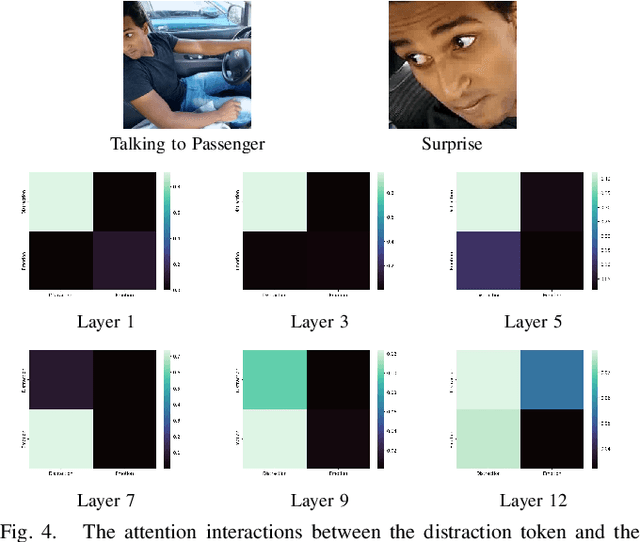
Driver distraction detection is an important computer vision problem that can play a crucial role in enhancing traffic safety and reducing traffic accidents. In this paper, a Vision Transformer (ViT) based approach for driver distraction detection is proposed. Specifically, a multi-modal Vision Transformer (ViT-DD) is developed, which exploits inductive information contained in signals of distraction detection as well as driver emotion recognition. Further, a semi-surprised learning algorithm is designed to include driver data without emotion labels into the supervised multi-task training of ViT-DD. Extensive experiments conducted on the SFDDD and AUCDD datasets demonstrate that the proposed ViT-DD outperforms the state-of-the-art approaches for driver distraction detection by 6.5% and 0.9%, respectively. Our source code is released at https://github.com/PurdueDigitalTwin/ViT-DD.
Local Grammar-Based Coding Revisited
Sep 27, 2022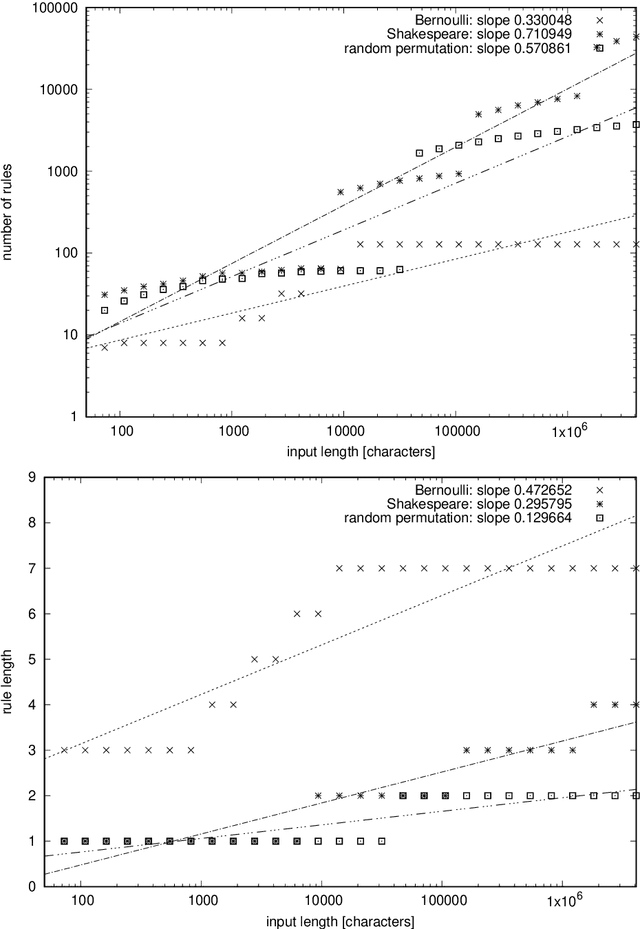
We revisit the problem of minimal local grammar-based coding. In this setting, the local grammar encoder encodes grammars symbol by symbol, whereas the minimal grammar transform minimizes the grammar length in a preset class of grammars as given by the length of local grammar encoding. It is known that such minimal codes are strongly universal for a strictly positive entropy rate, whereas the number of rules in the minimal grammar constitutes an upper bound for the mutual information of the source. Whereas the fully minimal code is likely intractable, the constrained minimal block code can be efficiently computed. In this note, we present a new, simpler, and more general proof of strong universality of the minimal block code, regardless of the entropy rate. The proof is based on a simple Zipfian bound for ranked probabilities. By the way, we also show empirically that the number of rules in the minimal block code cannot clearly discriminate between long-memory and memoryless sources, such as a text in English and a random permutation of its characters. This contradicts our previous expectations.
Global Semantic Descriptors for Zero-Shot Action Recognition
Sep 24, 2022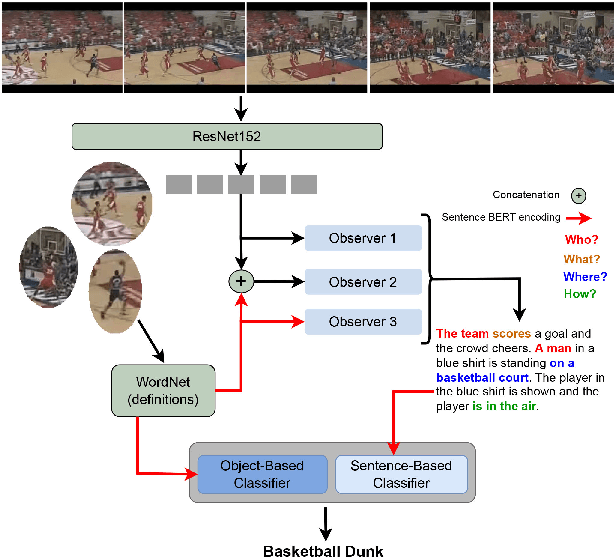
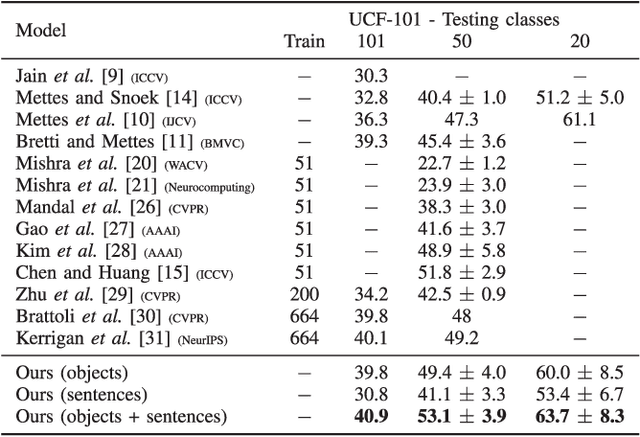
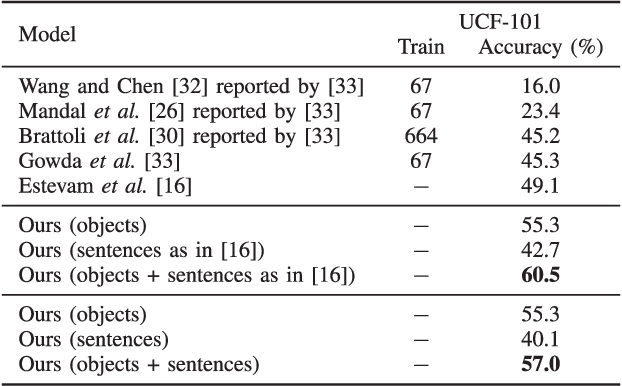
The success of Zero-shot Action Recognition (ZSAR) methods is intrinsically related to the nature of semantic side information used to transfer knowledge, although this aspect has not been primarily investigated in the literature. This work introduces a new ZSAR method based on the relationships of actions-objects and actions-descriptive sentences. We demonstrate that representing all object classes using descriptive sentences generates an accurate object-action affinity estimation when a paraphrase estimation method is used as an embedder. We also show how to estimate probabilities over the set of action classes based only on a set of sentences without hard human labeling. In our method, the probabilities from these two global classifiers (i.e., which use features computed over the entire video) are combined, producing an efficient transfer knowledge model for action classification. Our results are state-of-the-art in the Kinetics-400 dataset and are competitive on UCF-101 under the ZSAR evaluation. Our code is available at https://github.com/valterlej/objsentzsar
Orthogonal Time Frequency Space (OTFS) Modulation for Wireless Communications
Aug 25, 2022
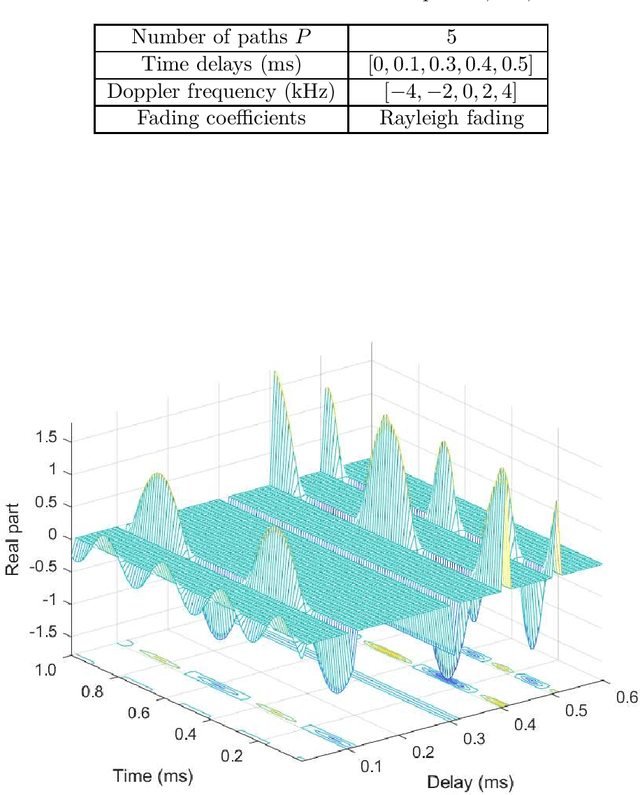
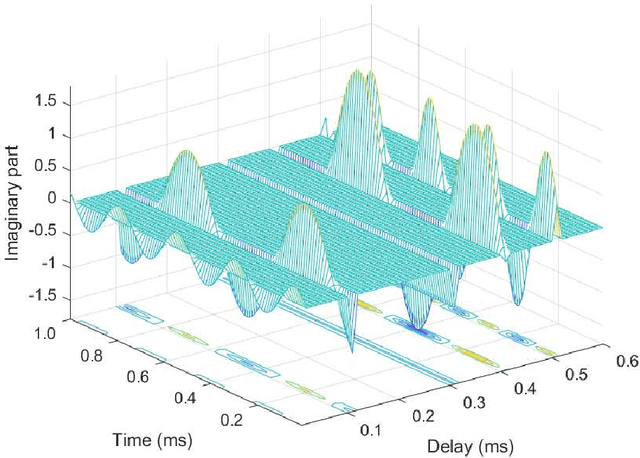
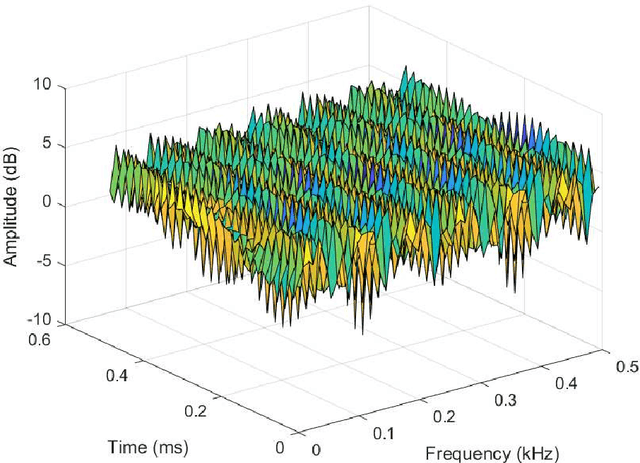
Orthogonal time frequency space (OTFS) modulation is a recently proposed multi-carrier transmission scheme, which innovatively multiplexes the information symbols in the delay-Doppler (DD) domain instead of the conventional time-frequency (TF) domain. The DD domain symbol multiplexing gives rise to a direct interaction between the DD domain information symbols and DD domain channel responses, which are usually quasi-static, compact, separable, and potentially sparse. Therefore, OTFS modulation enjoys appealing advantages over the conventional orthogonal frequency-division multiplexing (OFDM) modulation for wireless communications. In this thesis, we investigate the related subjects of OTFS modulation for wireless communications, specifically focusing on its signal detection, performance analysis, and applications. These important aspects are discussed based on the review of the state-of-the-art and a detailed derivation of OTFS modulation from the discrete Zak transform (DZT). Finally, a summary of future research directions on OTFS modulation are also provided.
Construction of English Resume Corpus and Test with Pre-trained Language Models
Aug 05, 2022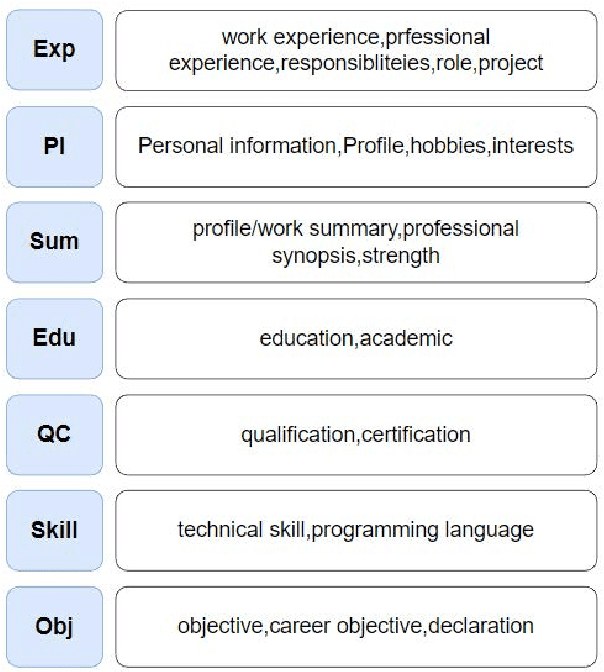

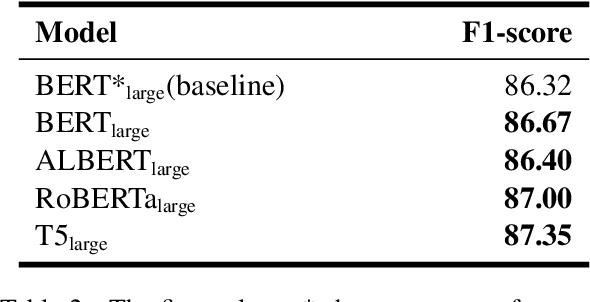
Information extraction(IE) has always been one of the essential tasks of NLP. Moreover, one of the most critical application scenarios of information extraction is the information extraction of resumes. Constructed text is obtained by classifying each part of the resume. It is convenient to store these texts for later search and analysis. Furthermore, the constructed resume data can also be used in the AI resume screening system. Significantly reduce the labor cost of HR. This study aims to transform the information extraction task of resumes into a simple sentence classification task. Based on the English resume dataset produced by the prior study. The classification rules are improved to create a larger and more fine-grained classification dataset of resumes. This corpus is also used to test some current mainstream Pre-training language models (PLMs) performance.Furthermore, in order to explore the relationship between the number of training samples and the correctness rate of the resume dataset, we also performed comparison experiments with training sets of different train set sizes.The final multiple experimental results show that the resume dataset with improved annotation rules and increased sample size of the dataset improves the accuracy of the original resume dataset.
Reconstructing Missing EHRs Using Time-Aware Within- and Cross-Visit Information for Septic Shock Early Prediction
Mar 15, 2022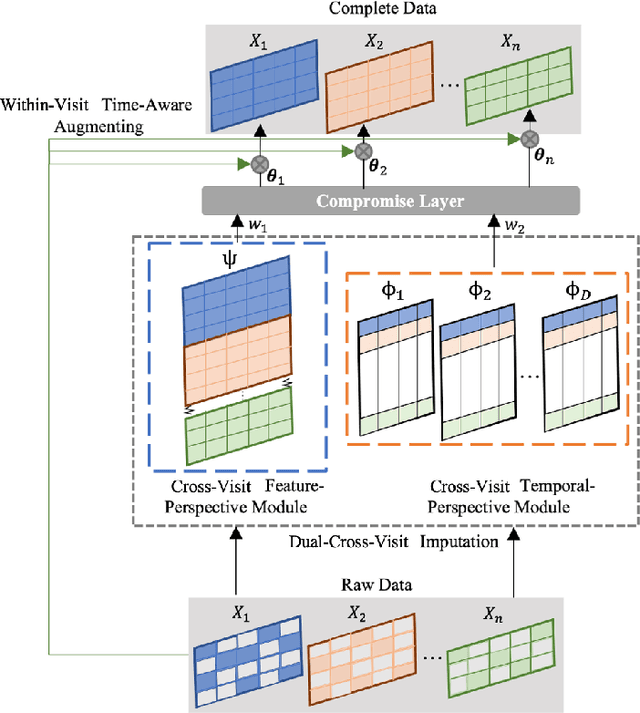
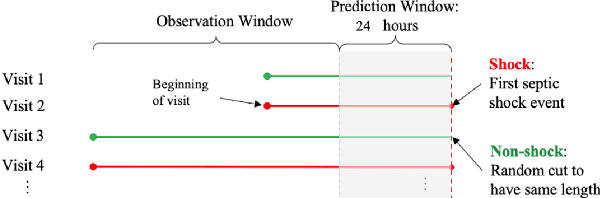
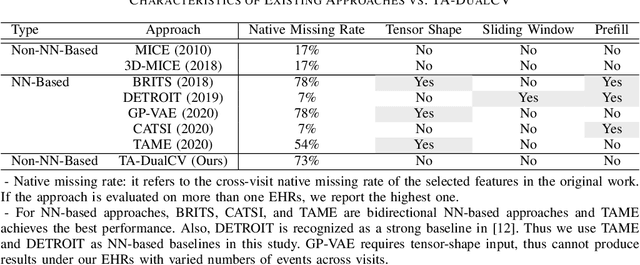
Real-world Electronic Health Records (EHRs) are often plagued by a high rate of missing data. In our EHRs, for example, the missing rates can be as high as 90% for some features, with an average missing rate of around 70% across all features. We propose a Time-Aware Dual-Cross-Visit missing value imputation method, named TA-DualCV, which spontaneously leverages multivariate dependencies across features and longitudinal dependencies both within- and cross-visit to maximize the information extracted from limited observable records in EHRs. Specifically, TA-DualCV captures the latent structure of missing patterns across measurements of different features and it also considers the time continuity and capture the latent temporal missing patterns based on both time-steps and irregular time-intervals. TA-DualCV is evaluated using three large real-world EHRs on two types of tasks: an unsupervised imputation task by varying mask rates up to 90% and a supervised 24-hour early prediction of septic shock using Long Short-Term Memory (LSTM). Our results show that TA-DualCV performs significantly better than all of the existing state-of-the-art imputation baselines, such as DETROIT and TAME, on both types of tasks.