 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Adaptive QoS of WebRTC for Vehicular Media Communications
Aug 24, 2022
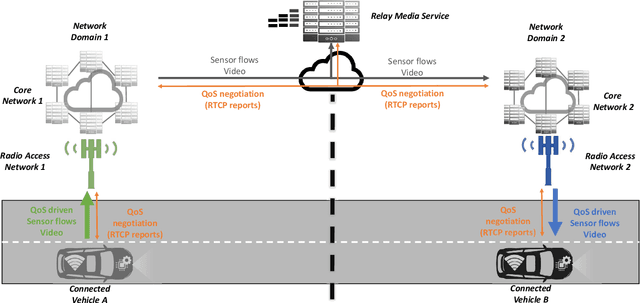


Vehicles shipping sensors for onboard systems are gaining connectivity. This enables information sharing to realize a more comprehensive understanding of the environment. However, peer communication through public cellular networks brings multiple networking hurdles to address, needing in-network systems to relay communications and connect parties that cannot connect directly. Web Real-Time Communication (WebRTC) is a good candidate for media streaming across vehicles as it enables low latency communications, while bringing standard protocols to security handshake, discovering public IPs and transverse Network Address Translation (NAT) systems. However, the end-to-end Quality of Service (QoS) adaptation in an infrastructure where transmission and reception are decoupled by a relay, needs a mechanism to adapt the video stream to the network capacity efficiently. To this end, this paper investigates a mechanism to apply changes on resolution, framerate and bitrate by exploiting the Real Time Transport Control Protocol (RTCP) metrics, such as bandwidth and round-trip time. The solution aims to ensure that the receiving onboard system gets relevant information in time. The impact on end-to-end throughput efficiency and reaction time when applying different approaches to QoS adaptation are analyzed in a real 5G testbed.
A model-agnostic approach for generating Saliency Maps to explain inferred decisions of Deep Learning Models
Sep 27, 2022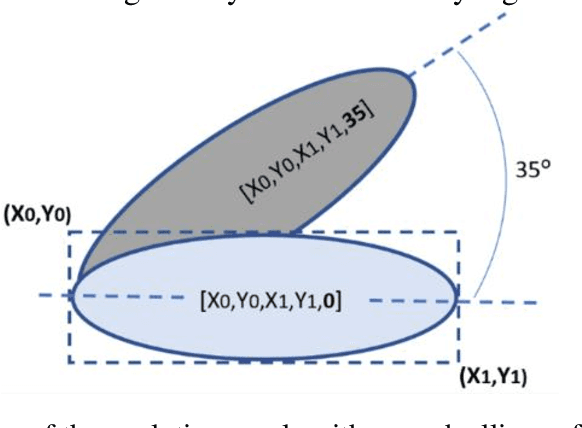
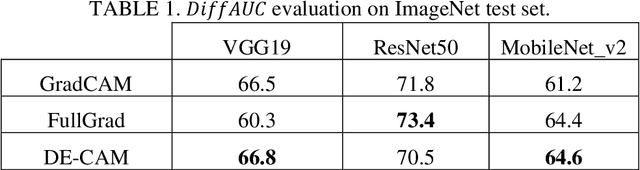

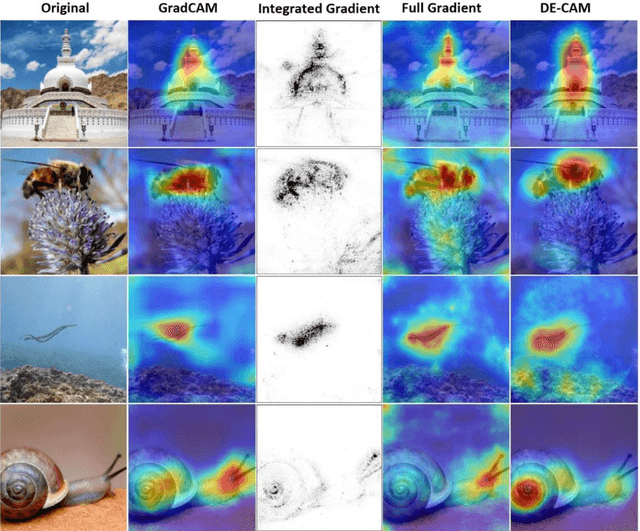
The widespread use of black-box AI models has raised the need for algorithms and methods that explain the decisions made by these models. In recent years, the AI research community is increasingly interested in models' explainability since black-box models take over more and more complicated and challenging tasks. Explainability becomes critical considering the dominance of deep learning techniques for a wide range of applications, including but not limited to computer vision. In the direction of understanding the inference process of deep learning models, many methods that provide human comprehensible evidence for the decisions of AI models have been developed, with the vast majority relying their operation on having access to the internal architecture and parameters of these models (e.g., the weights of neural networks). We propose a model-agnostic method for generating saliency maps that has access only to the output of the model and does not require additional information such as gradients. We use Differential Evolution (DE) to identify which image pixels are the most influential in a model's decision-making process and produce class activation maps (CAMs) whose quality is comparable to the quality of CAMs created with model-specific algorithms. DE-CAM achieves good performance without requiring access to the internal details of the model's architecture at the cost of more computational complexity.
Fusion of Inverse Synthetic Aperture Radar and Camera Images for Automotive Target Tracking
Sep 27, 2022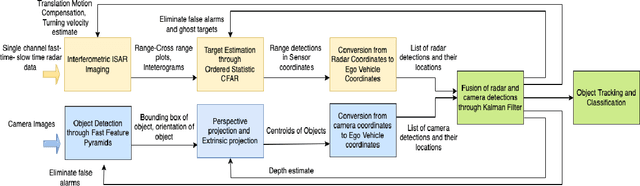
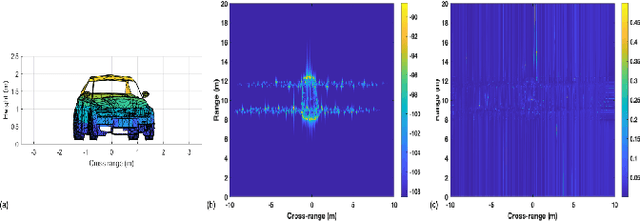

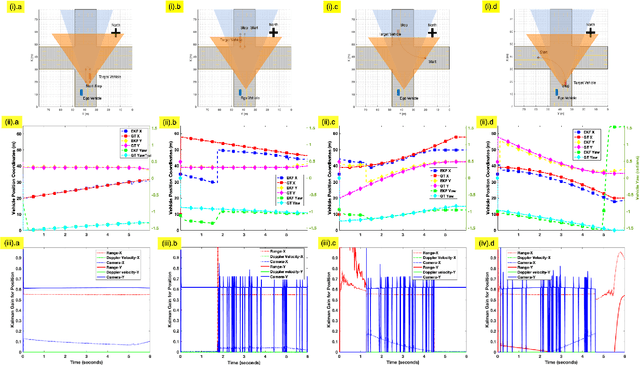
Automotive targets undergoing turns in road junctions offer large synthetic apertures over short dwell times to automotive radars that can be exploited for obtaining fine cross-range resolution. Likewise, the wide bandwidths of the automotive radar signal yield high-range resolution profiles. Together, they are exploited for generating inverse synthetic aperture radar (ISAR) images that offer rich information regarding the target vehicle's size, shape, and trajectory which is useful for object recognition and classification. However, a key requirement for ISAR is translation motion compensation and estimation of the turning velocity of the target. State-of-the-art algorithms for motion compensation trade-off between computational complexity and accuracy. An alternative low complexity method is to use an additional sensor for tracking the target motion. In this work, we propose to exploit computer vision algorithms to identify the radar target object in the sensor field-of-view (FoV) with high accuracy. Further, we propose to track the target vehicle's motion through fusion of vision and radar data. Vision data facilitates the accurate estimation of the lateral position of the target which complements the radar capability of accurate estimation of range and radial velocity. Through simulations and experimental evaluations with a monocular camera and Texas Instrument millimeter wave radar we demonstrate the effectiveness of sensor fusion for accurate target tracking for translational motion compensation and the generation of high-quality ISAR images.
Multi-modal Segment Assemblage Network for Ad Video Editing with Importance-Coherence Reward
Sep 25, 2022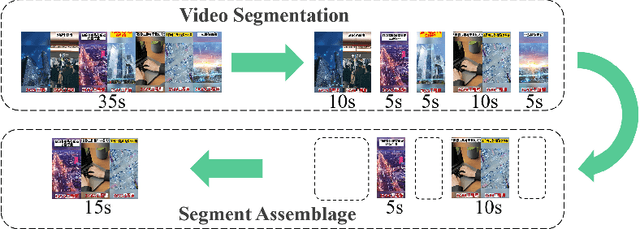

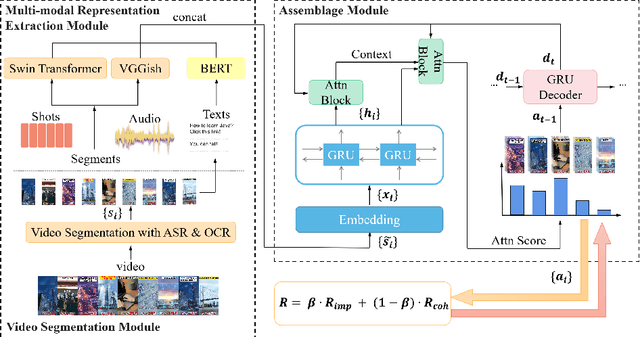
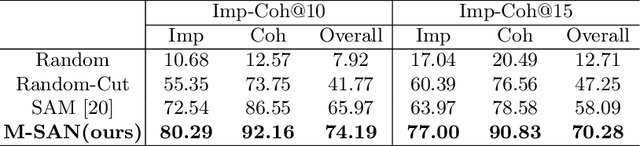
Advertisement video editing aims to automatically edit advertising videos into shorter videos while retaining coherent content and crucial information conveyed by advertisers. It mainly contains two stages: video segmentation and segment assemblage. The existing method performs well at video segmentation stages but suffers from the problems of dependencies on extra cumbersome models and poor performance at the segment assemblage stage. To address these problems, we propose M-SAN (Multi-modal Segment Assemblage Network) which can perform efficient and coherent segment assemblage task end-to-end. It utilizes multi-modal representation extracted from the segments and follows the Encoder-Decoder Ptr-Net framework with the Attention mechanism. Importance-coherence reward is designed for training M-SAN. We experiment on the Ads-1k dataset with 1000+ videos under rich ad scenarios collected from advertisers. To evaluate the methods, we propose a unified metric, Imp-Coh@Time, which comprehensively assesses the importance, coherence, and duration of the outputs at the same time. Experimental results show that our method achieves better performance than random selection and the previous method on the metric. Ablation experiments further verify that multi-modal representation and importance-coherence reward significantly improve the performance. Ads-1k dataset is available at: https://github.com/yunlong10/Ads-1k
Pretrained Domain-Specific Language Model for General Information Retrieval Tasks in the AEC Domain
Mar 09, 2022
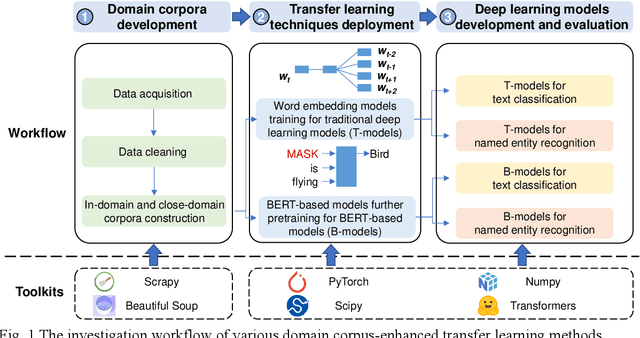
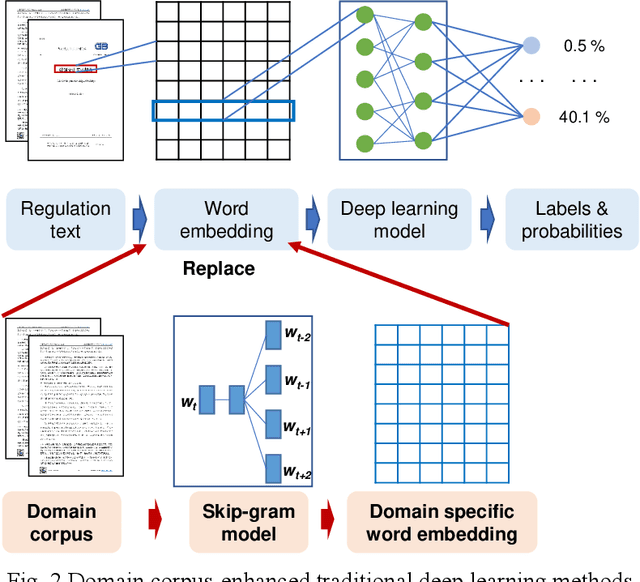

As an essential task for the architecture, engineering, and construction (AEC) industry, information retrieval (IR) from unstructured textual data based on natural language processing (NLP) is gaining increasing attention. Although various deep learning (DL) models for IR tasks have been investigated in the AEC domain, it is still unclear how domain corpora and domain-specific pretrained DL models can improve performance in various IR tasks. To this end, this work systematically explores the impacts of domain corpora and various transfer learning techniques on the performance of DL models for IR tasks and proposes a pretrained domain-specific language model for the AEC domain. First, both in-domain and close-domain corpora are developed. Then, two types of pretrained models, including traditional wording embedding models and BERT-based models, are pretrained based on various domain corpora and transfer learning strategies. Finally, several widely used DL models for IR tasks are further trained and tested based on various configurations and pretrained models. The result shows that domain corpora have opposite effects on traditional word embedding models for text classification and named entity recognition tasks but can further improve the performance of BERT-based models in all tasks. Meanwhile, BERT-based models dramatically outperform traditional methods in all IR tasks, with maximum improvements of 5.4% and 10.1% in the F1 score, respectively. This research contributes to the body of knowledge in two ways: 1) demonstrating the advantages of domain corpora and pretrained DL models and 2) opening the first domain-specific dataset and pretrained language model for the AEC domain, to the best of our knowledge. Thus, this work sheds light on the adoption and application of pretrained models in the AEC domain.
Grad-Align+: Empowering Gradual Network Alignment Using Attribute Augmentation
Aug 24, 2022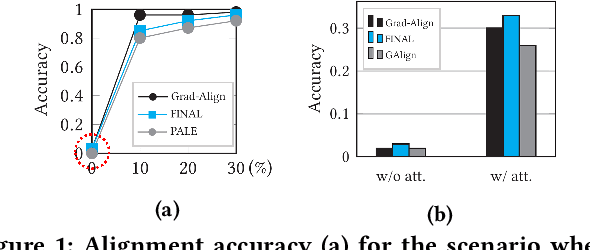
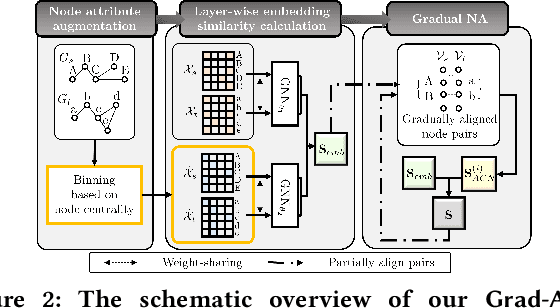
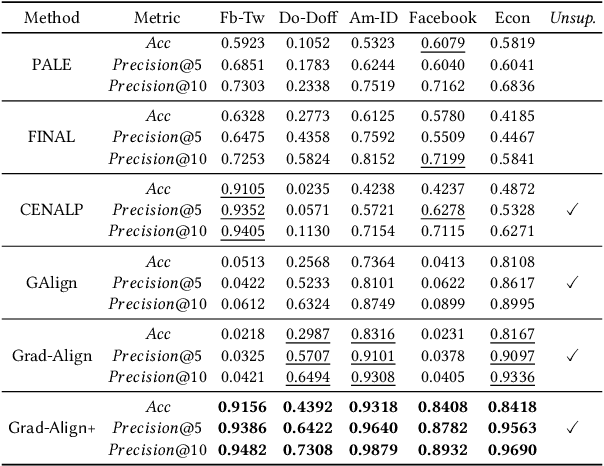
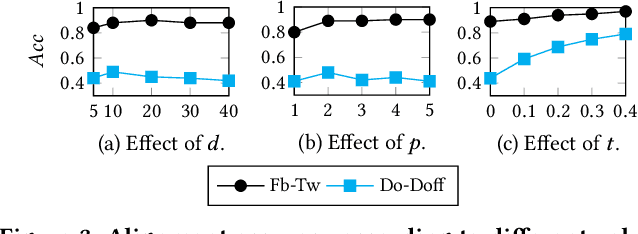
Network alignment (NA) is the task of discovering node correspondences across different networks. Although NA methods have achieved remarkable success in a myriad of scenarios, their satisfactory performance is not without prior anchor link information and/or node attributes, which may not always be available. In this paper, we propose Grad-Align+, a novel NA method using node attribute augmentation that is quite robust to the absence of such additional information. Grad-Align+ is built upon a recent state-of-the-art NA method, the so-called Grad-Align, that gradually discovers only a part of node pairs until all node pairs are found. Specifically, Grad-Align+ is composed of the following key components: 1) augmenting node attributes based on nodes' centrality measures, 2) calculating an embedding similarity matrix extracted from a graph neural network into which the augmented node attributes are fed, and 3) gradually discovering node pairs by calculating similarities between cross-network nodes with respect to the aligned cross-network neighbor-pair. Experimental results demonstrate that Grad-Align+ exhibits (a) superiority over benchmark NA methods, (b) empirical validation of our theoretical findings, and (c) the effectiveness of our attribute augmentation module.
3D-PL: Domain Adaptive Depth Estimation with 3D-aware Pseudo-Labeling
Sep 19, 2022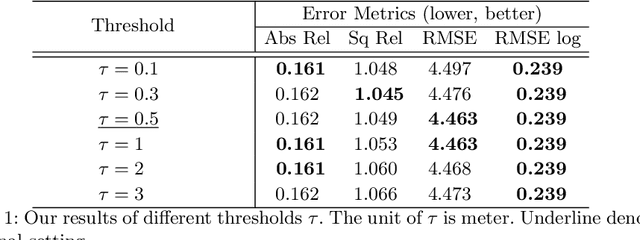

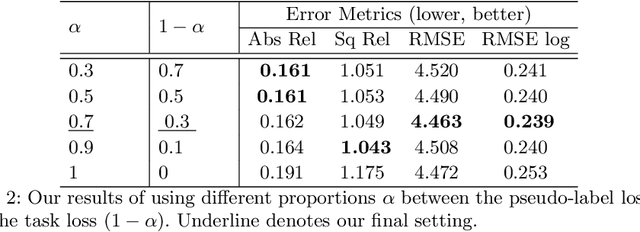

For monocular depth estimation, acquiring ground truths for real data is not easy, and thus domain adaptation methods are commonly adopted using the supervised synthetic data. However, this may still incur a large domain gap due to the lack of supervision from the real data. In this paper, we develop a domain adaptation framework via generating reliable pseudo ground truths of depth from real data to provide direct supervisions. Specifically, we propose two mechanisms for pseudo-labeling: 1) 2D-based pseudo-labels via measuring the consistency of depth predictions when images are with the same content but different styles; 2) 3D-aware pseudo-labels via a point cloud completion network that learns to complete the depth values in the 3D space, thus providing more structural information in a scene to refine and generate more reliable pseudo-labels. In experiments, we show that our pseudo-labeling methods improve depth estimation in various settings, including the usage of stereo pairs during training. Furthermore, the proposed method performs favorably against several state-of-the-art unsupervised domain adaptation approaches in real-world datasets.
Constant regret for sequence prediction with limited advice
Oct 05, 2022
We investigate the problem of cumulative regret minimization for individual sequence prediction with respect to the best expert in a finite family of size K under limited access to information. We assume that in each round, the learner can predict using a convex combination of at most p experts for prediction, then they can observe a posteriori the losses of at most m experts. We assume that the loss function is range-bounded and exp-concave. In the standard multi-armed bandits setting, when the learner is allowed to play only one expert per round and observe only its feedback, known optimal regret bounds are of the order O($\sqrt$ KT). We show that allowing the learner to play one additional expert per round and observe one additional feedback improves substantially the guarantees on regret. We provide a strategy combining only p = 2 experts per round for prediction and observing m $\ge$ 2 experts' losses. Its randomized regret (wrt. internal randomization of the learners' strategy) is of order O (K/m) log(K$\delta$ --1) with probability 1 -- $\delta$, i.e., is independent of the horizon T ("constant" or "fast rate" regret) if (p $\ge$ 2 and m $\ge$ 3). We prove that this rate is optimal up to a logarithmic factor in K. In the case p = m = 2, we provide an upper bound of order O(K 2 log(K$\delta$ --1)), with probability 1 -- $\delta$. Our strategies do not require any prior knowledge of the horizon T nor of the confidence parameter $\delta$. Finally, we show that if the learner is constrained to observe only one expert feedback per round, the worst-case regret is the "slow rate" $\Omega$($\sqrt$ KT), suggesting that synchronous observation of at least two experts per round is necessary to have a constant regret.
Learning New Skills after Deployment: Improving open-domain internet-driven dialogue with human feedback
Aug 16, 2022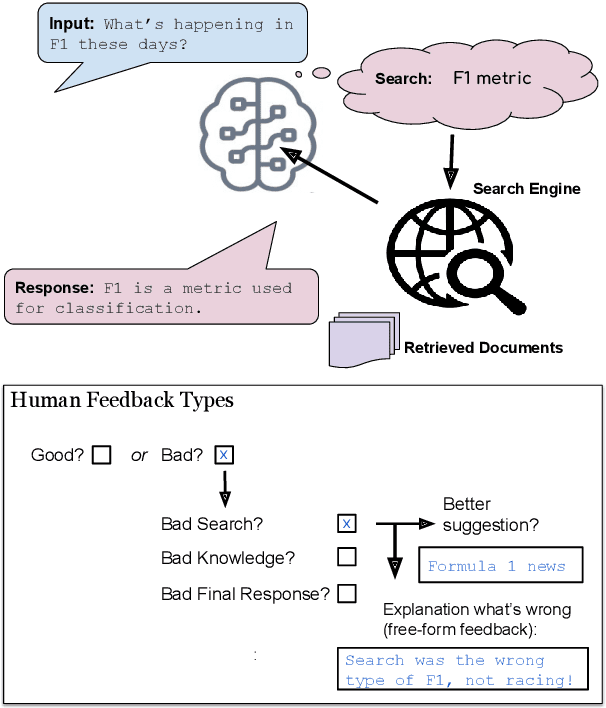
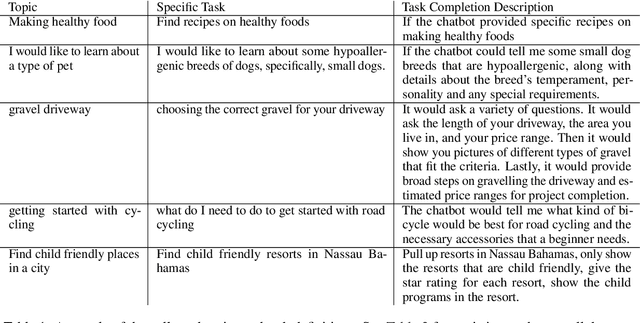
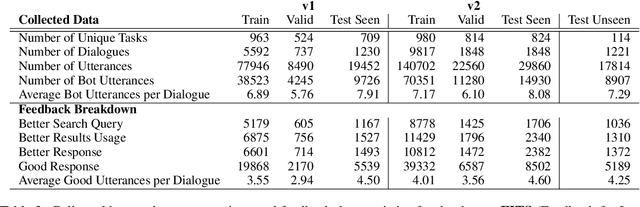
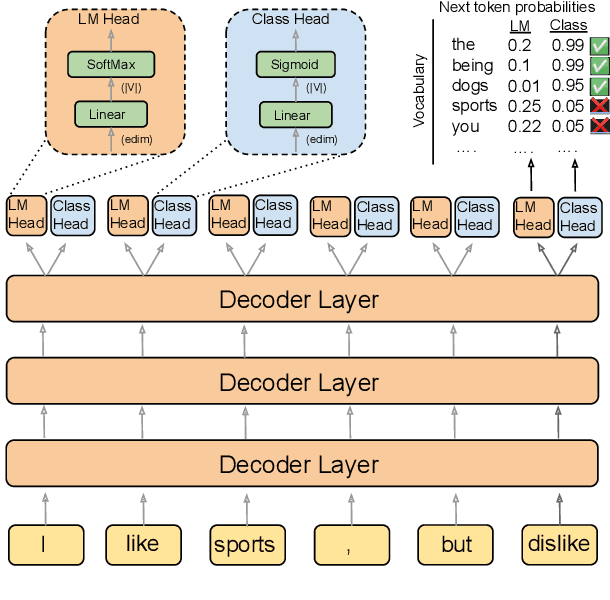
Frozen models trained to mimic static datasets can never improve their performance. Models that can employ internet-retrieval for up-to-date information and obtain feedback from humans during deployment provide the promise of both adapting to new information, and improving their performance. In this work we study how to improve internet-driven conversational skills in such a learning framework. We collect deployment data, which we make publicly available, of human interactions, and collect various types of human feedback -- including binary quality measurements, free-form text feedback, and fine-grained reasons for failure. We then study various algorithms for improving from such feedback, including standard supervised learning, rejection sampling, model-guiding and reward-based learning, in order to make recommendations on which type of feedback and algorithms work best. We find the recently introduced Director model (Arora et al., '22) shows significant improvements over other existing approaches.
Active Inference for Autonomous Decision-Making with Contextual Multi-Armed Bandits
Sep 19, 2022
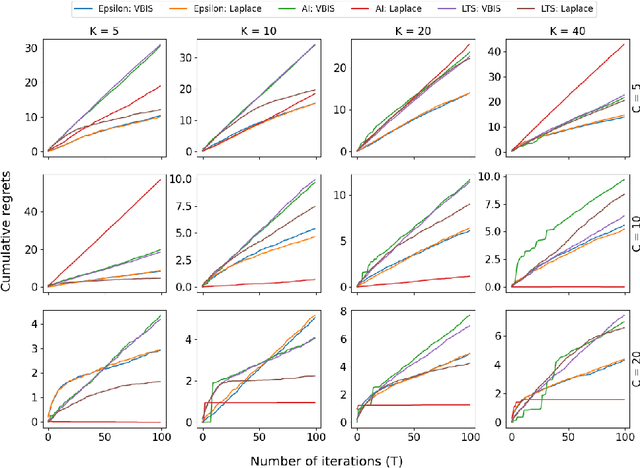
In autonomous robotic decision-making under uncertainty, the tradeoff between exploitation and exploration of available options must be considered. If secondary information associated with options can be utilized, such decision-making problems can often be formulated as a contextual multi-armed bandits (CMABs). In this study, we apply active inference, which has been actively studied in the field of neuroscience in recent years, as an alternative action selection strategy for CMABs. Unlike conventional action selection strategies, it is possible to rigorously evaluate the uncertainty of each option when calculating the expected free energy (EFE) associated with the decision agent's probabilistic model, as derived from the free-energy principle. We specifically address the case where a categorical observation likelihood function is used, such that EFE values are analytically intractable. We introduce new approximation methods for computing the EFE based on variational and Laplace approximations. Extensive simulation study results demonstrate that, compared to other strategies, active inference generally requires far fewer iterations to identify optimal options and generally achieves superior cumulative regret, for relatively low extra computational cost.