 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Dual Graph Attention based Disentanglement Multiple Instance Learning for Brain Age Estimation
Mar 02, 2024
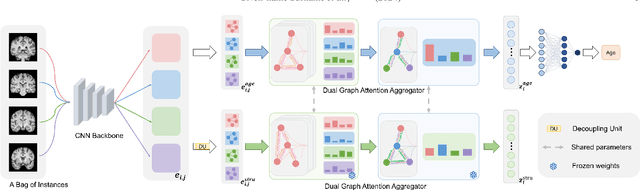

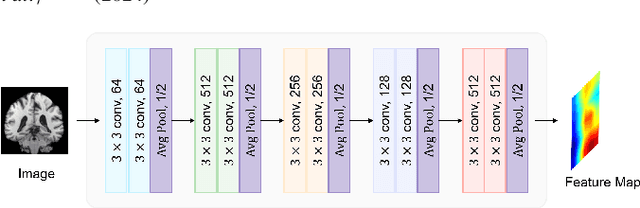
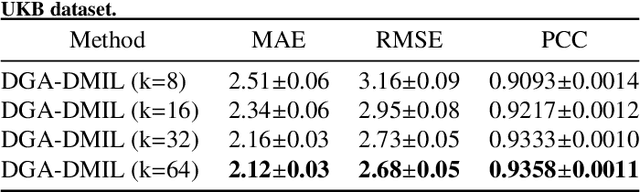
Deep learning techniques have demonstrated great potential for accurately estimating brain age by analyzing Magnetic Resonance Imaging (MRI) data from healthy individuals. However, current methods for brain age estimation often directly utilize whole input images, overlooking two important considerations: 1) the heterogeneous nature of brain aging, where different brain regions may degenerate at different rates, and 2) the existence of age-independent redundancies in brain structure. To overcome these limitations, we propose a Dual Graph Attention based Disentanglement Multi-instance Learning (DGA-DMIL) framework for improving brain age estimation. Specifically, the 3D MRI data, treated as a bag of instances, is fed into a 2D convolutional neural network backbone, to capture the unique aging patterns in MRI. A dual graph attention aggregator is then proposed to learn the backbone features by exploiting the intra- and inter-instance relationships. Furthermore, a disentanglement branch is introduced to separate age-related features from age-independent structural representations to ameliorate the interference of redundant information on age prediction. To verify the effectiveness of the proposed framework, we evaluate it on two datasets, UK Biobank and ADNI, containing a total of 35,388 healthy individuals. Our proposed model demonstrates exceptional accuracy in estimating brain age, achieving a remarkable mean absolute error of 2.12 years in the UK Biobank. The results establish our approach as state-of-the-art compared to other competing brain age estimation models. In addition, the instance contribution scores identify the varied importance of brain areas for aging prediction, which provides deeper insights into the understanding of brain aging.
Auxiliary Tasks Enhanced Dual-affinity Learning for Weakly Supervised Semantic Segmentation
Mar 02, 2024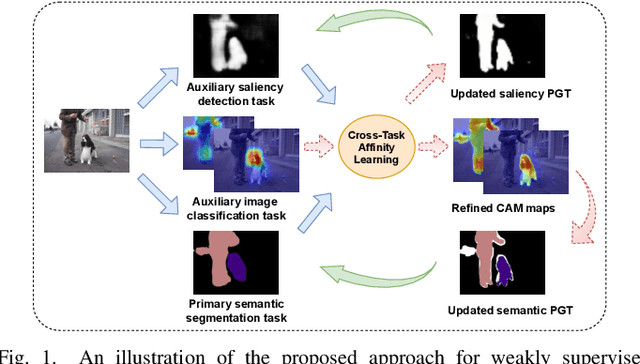
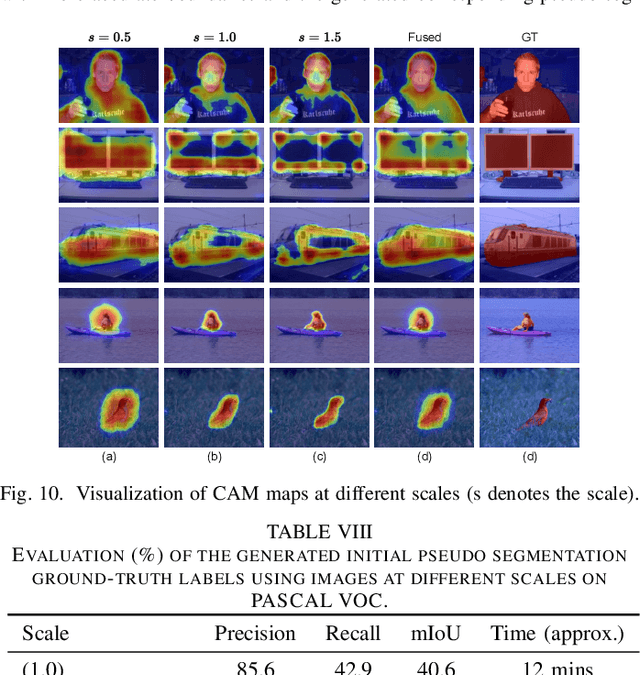

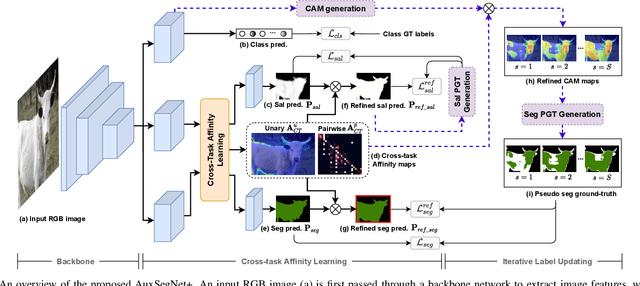
Most existing weakly supervised semantic segmentation (WSSS) methods rely on Class Activation Mapping (CAM) to extract coarse class-specific localization maps using image-level labels. Prior works have commonly used an off-line heuristic thresholding process that combines the CAM maps with off-the-shelf saliency maps produced by a general pre-trained saliency model to produce more accurate pseudo-segmentation labels. We propose AuxSegNet+, a weakly supervised auxiliary learning framework to explore the rich information from these saliency maps and the significant inter-task correlation between saliency detection and semantic segmentation. In the proposed AuxSegNet+, saliency detection and multi-label image classification are used as auxiliary tasks to improve the primary task of semantic segmentation with only image-level ground-truth labels. We also propose a cross-task affinity learning mechanism to learn pixel-level affinities from the saliency and segmentation feature maps. In particular, we propose a cross-task dual-affinity learning module to learn both pairwise and unary affinities, which are used to enhance the task-specific features and predictions by aggregating both query-dependent and query-independent global context for both saliency detection and semantic segmentation. The learned cross-task pairwise affinity can also be used to refine and propagate CAM maps to provide better pseudo labels for both tasks. Iterative improvement of segmentation performance is enabled by cross-task affinity learning and pseudo-label updating. Extensive experiments demonstrate the effectiveness of the proposed approach with new state-of-the-art WSSS results on the challenging PASCAL VOC and MS COCO benchmarks.
Benchmarking LLMs on the Semantic Overlap Summarization Task
Feb 26, 2024Semantic Overlap Summarization (SOS) is a constrained multi-document summarization task, where the constraint is to capture the common/overlapping information between two alternative narratives. While recent advancements in Large Language Models (LLMs) have achieved superior performance in numerous summarization tasks, a benchmarking study of the SOS task using LLMs is yet to be performed. As LLMs' responses are sensitive to slight variations in prompt design, a major challenge in conducting such a benchmarking study is to systematically explore a variety of prompts before drawing a reliable conclusion. Fortunately, very recently, the TELeR taxonomy has been proposed which can be used to design and explore various prompts for LLMs. Using this TELeR taxonomy and 15 popular LLMs, this paper comprehensively evaluates LLMs on the SOS Task, assessing their ability to summarize overlapping information from multiple alternative narratives. For evaluation, we report well-established metrics like ROUGE, BERTscore, and SEM-F1$ on two different datasets of alternative narratives. We conclude the paper by analyzing the strengths and limitations of various LLMs in terms of their capabilities in capturing overlapping information The code and datasets used to conduct this study are available at https://anonymous.4open.science/r/llm_eval-E16D.
Channel Measurements and Modeling for Dynamic Vehicular ISAC Scenarios at 28 GHz
Mar 01, 2024Integrated sensing and communication (ISAC) is a promising technology for 6G, with the goal of providing end-to-end information processing and inherent perception capabilities for future communication systems. Within ISAC emerging application scenarios, vehicular ISAC technologies have the potential to enhance traffic efficiency and safety through integration of communication and synchronized perception abilities. To establish a foundational theoretical support for vehicular ISAC system design and standardization, it is necessary to conduct channel measurements, and modeling to obtain a deep understanding of the radio propagation. In this paper, a dynamic statistical channel model is proposed for vehicular ISAC scenarios, incorporating Sensing Multipath Components (S-MPCs) and Clutter Multipath Components (C-MPCs), which are identified by the proposed tracking algorithm. Based on actual vehicular ISAC channel measurements at 28 GHz, time-varying sensing characteristics in front, left, and right directions are investigated. To model the dynamic evolution process of channel, number of new S-MPCs, lifetimes, initial power and delay positions, dynamic variations within their lifetimes, clustering, power decay, and fading of C-MPCs are statistically characterized. Finally, the paper provides implementation of dynamic vehicular ISAC model and validates it by comparing key simulation statistics between measurements and simulations.
A Semantic Distance Metric Learning approach for Lexical Semantic Change Detection
Mar 01, 2024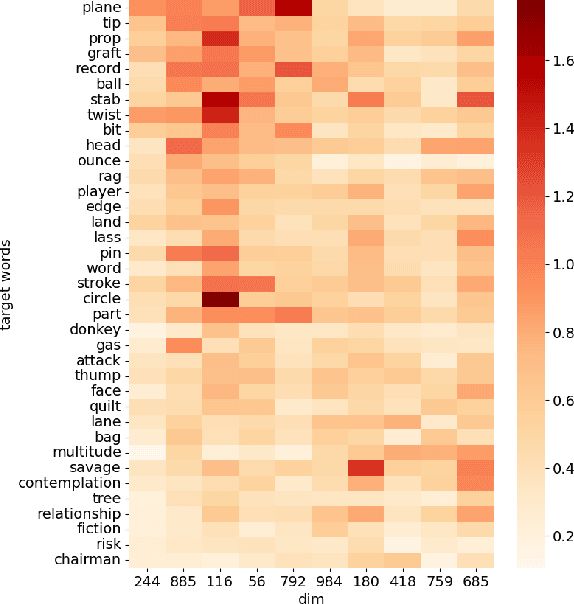
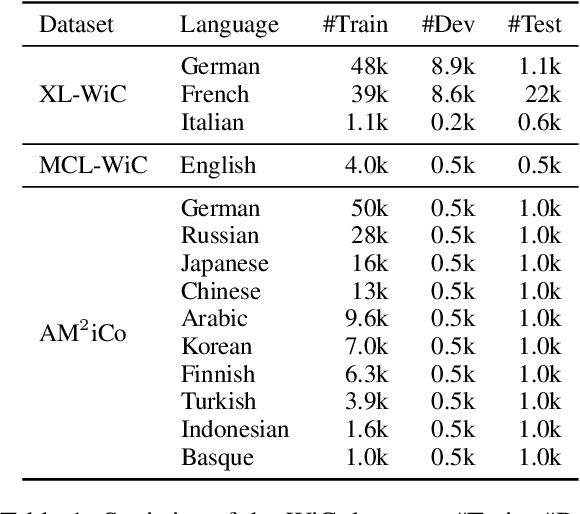
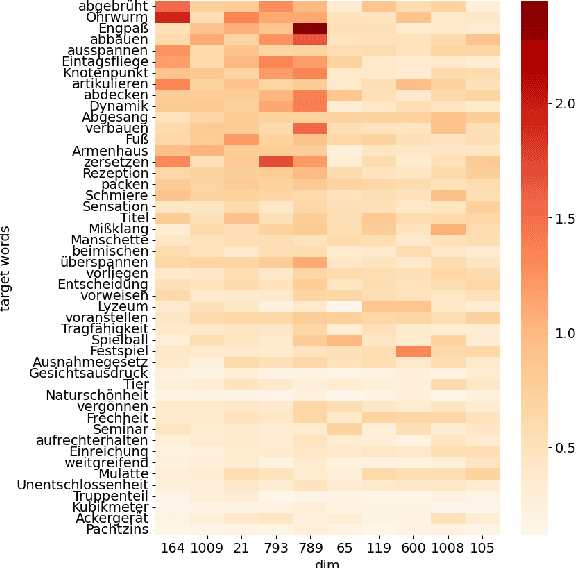
Detecting temporal semantic changes of words is an important task for various NLP applications that must make time-sensitive predictions. Lexical Semantic Change Detection (SCD) task considers the problem of predicting whether a given target word, $w$, changes its meaning between two different text corpora, $C_1$ and $C_2$. For this purpose, we propose a supervised two-staged SCD method that uses existing Word-in-Context (WiC) datasets. In the first stage, for a target word $w$, we learn two sense-aware encoder that represents the meaning of $w$ in a given sentence selected from a corpus. Next, in the second stage, we learn a sense-aware distance metric that compares the semantic representations of a target word across all of its occurrences in $C_1$ and $C_2$. Experimental results on multiple benchmark datasets for SCD show that our proposed method consistently outperforms all previously proposed SCD methods for multiple languages, establishing a novel state-of-the-art for SCD. Interestingly, our findings imply that there are specialised dimensions that carry information related to semantic changes of words in the sense-aware embedding space. Source code is available at https://github.com/a1da4/svp-sdml .
Point Could Mamba: Point Cloud Learning via State Space Model
Mar 01, 2024
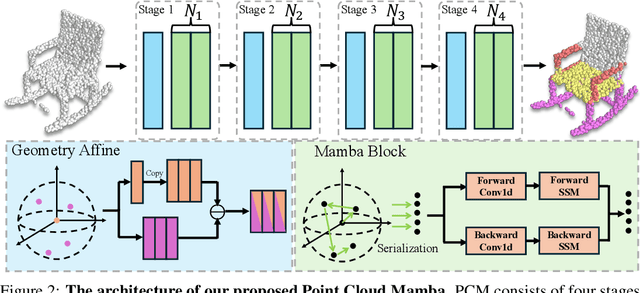
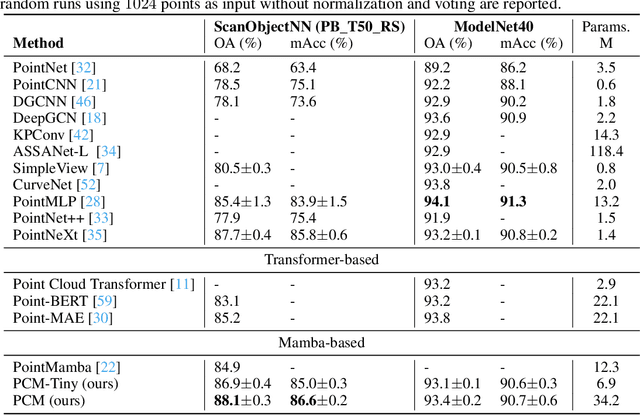
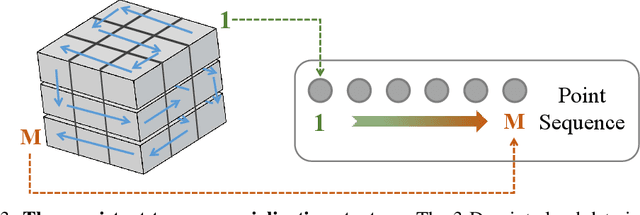
In this work, for the first time, we demonstrate that Mamba-based point cloud methods can outperform point-based methods. Mamba exhibits strong global modeling capabilities and linear computational complexity, making it highly attractive for point cloud analysis. To enable more effective processing of 3-D point cloud data by Mamba, we propose a novel Consistent Traverse Serialization to convert point clouds into 1-D point sequences while ensuring that neighboring points in the sequence are also spatially adjacent. Consistent Traverse Serialization yields six variants by permuting the order of x, y, and z coordinates, and the synergistic use of these variants aids Mamba in comprehensively observing point cloud data. Furthermore, to assist Mamba in handling point sequences with different orders more effectively, we introduce point prompts to inform Mamba of the sequence's arrangement rules. Finally, we propose positional encoding based on spatial coordinate mapping to inject positional information into point cloud sequences better. Based on these improvements, we construct a point cloud network named Point Cloud Mamba, which combines local and global modeling. Point Cloud Mamba surpasses the SOTA point-based method PointNeXt and achieves new SOTA performance on the ScanObjectNN, ModelNet40, and ShapeNetPart datasets.
Tri-Modal Motion Retrieval by Learning a Joint Embedding Space
Mar 01, 2024
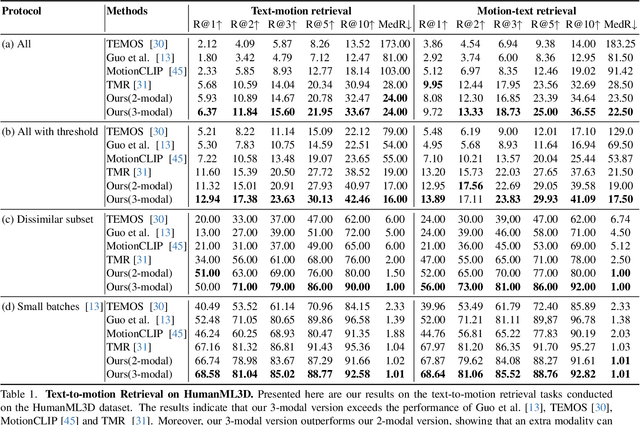
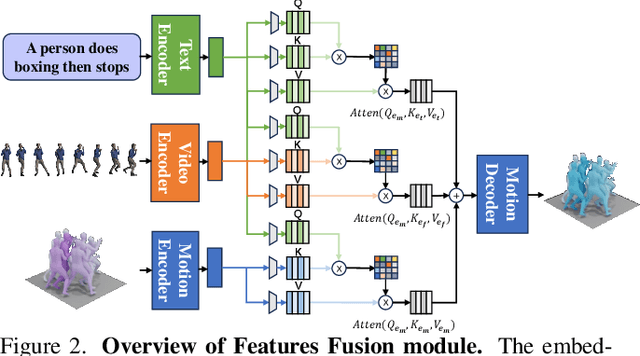
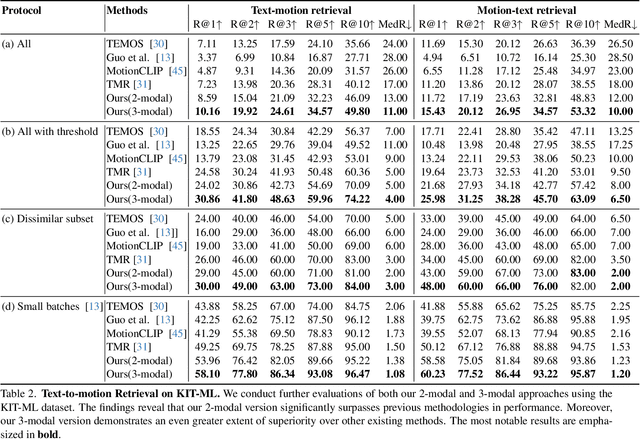
Information retrieval is an ever-evolving and crucial research domain. The substantial demand for high-quality human motion data especially in online acquirement has led to a surge in human motion research works. Prior works have mainly concentrated on dual-modality learning, such as text and motion tasks, but three-modality learning has been rarely explored. Intuitively, an extra introduced modality can enrich a model's application scenario, and more importantly, an adequate choice of the extra modality can also act as an intermediary and enhance the alignment between the other two disparate modalities. In this work, we introduce LAVIMO (LAnguage-VIdeo-MOtion alignment), a novel framework for three-modality learning integrating human-centric videos as an additional modality, thereby effectively bridging the gap between text and motion. Moreover, our approach leverages a specially designed attention mechanism to foster enhanced alignment and synergistic effects among text, video, and motion modalities. Empirically, our results on the HumanML3D and KIT-ML datasets show that LAVIMO achieves state-of-the-art performance in various motion-related cross-modal retrieval tasks, including text-to-motion, motion-to-text, video-to-motion and motion-to-video.
Formulation Comparison for Timeline Construction using LLMs
Mar 01, 2024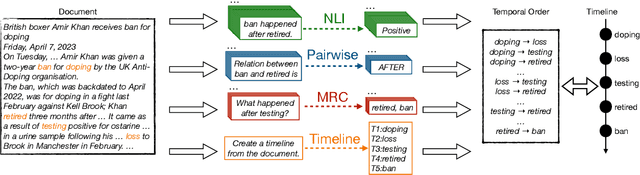

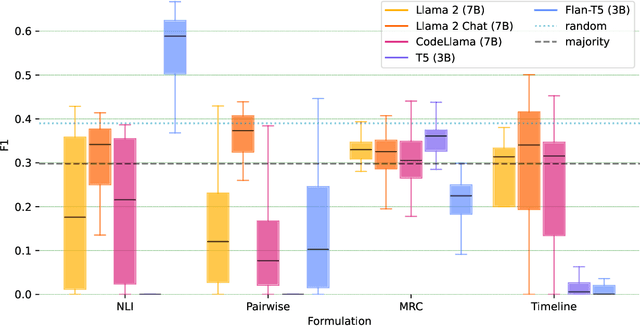
Constructing a timeline requires identifying the chronological order of events in an article. In prior timeline construction datasets, temporal orders are typically annotated by either event-to-time anchoring or event-to-event pairwise ordering, both of which suffer from missing temporal information. To mitigate the issue, we develop a new evaluation dataset, TimeSET, consisting of single-document timelines with document-level order annotation. TimeSET features saliency-based event selection and partial ordering, which enable a practical annotation workload. Aiming to build better automatic timeline construction systems, we propose a novel evaluation framework to compare multiple task formulations with TimeSET by prompting open LLMs, i.e., Llama 2 and Flan-T5. Considering that identifying temporal orders of events is a core subtask in timeline construction, we further benchmark open LLMs on existing event temporal ordering datasets to gain a robust understanding of their capabilities. Our experiments show that (1) NLI formulation with Flan-T5 demonstrates a strong performance among others, while (2) timeline construction and event temporal ordering are still challenging tasks for few-shot LLMs. Our code and data are available at https://github.com/kimihiroh/timeset.
NeRF-VPT: Learning Novel View Representations with Neural Radiance Fields via View Prompt Tuning
Mar 02, 2024
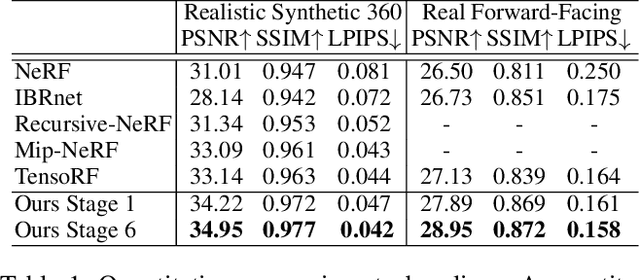
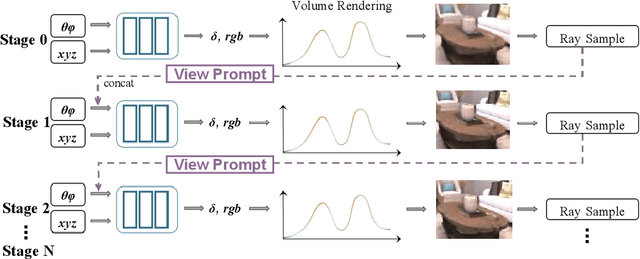
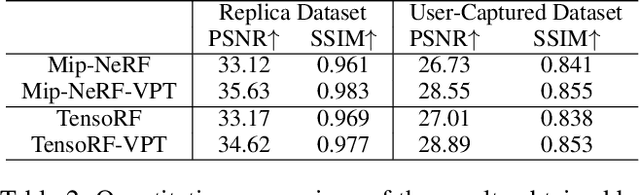
Neural Radiance Fields (NeRF) have garnered remarkable success in novel view synthesis. Nonetheless, the task of generating high-quality images for novel views persists as a critical challenge. While the existing efforts have exhibited commendable progress, capturing intricate details, enhancing textures, and achieving superior Peak Signal-to-Noise Ratio (PSNR) metrics warrant further focused attention and advancement. In this work, we propose NeRF-VPT, an innovative method for novel view synthesis to address these challenges. Our proposed NeRF-VPT employs a cascading view prompt tuning paradigm, wherein RGB information gained from preceding rendering outcomes serves as instructive visual prompts for subsequent rendering stages, with the aspiration that the prior knowledge embedded in the prompts can facilitate the gradual enhancement of rendered image quality. NeRF-VPT only requires sampling RGB data from previous stage renderings as priors at each training stage, without relying on extra guidance or complex techniques. Thus, our NeRF-VPT is plug-and-play and can be readily integrated into existing methods. By conducting comparative analyses of our NeRF-VPT against several NeRF-based approaches on demanding real-scene benchmarks, such as Realistic Synthetic 360, Real Forward-Facing, Replica dataset, and a user-captured dataset, we substantiate that our NeRF-VPT significantly elevates baseline performance and proficiently generates more high-quality novel view images than all the compared state-of-the-art methods. Furthermore, the cascading learning of NeRF-VPT introduces adaptability to scenarios with sparse inputs, resulting in a significant enhancement of accuracy for sparse-view novel view synthesis. The source code and dataset are available at \url{https://github.com/Freedomcls/NeRF-VPT}.
OpenGraph: Towards Open Graph Foundation Models
Mar 02, 2024
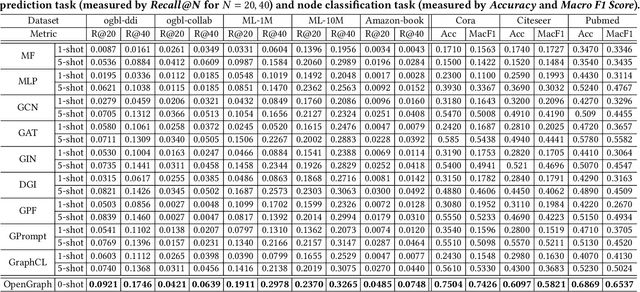
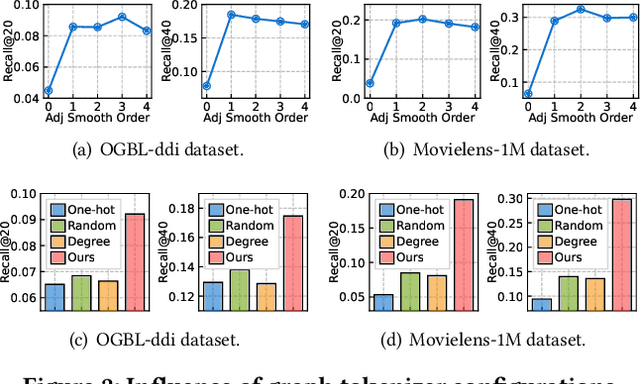
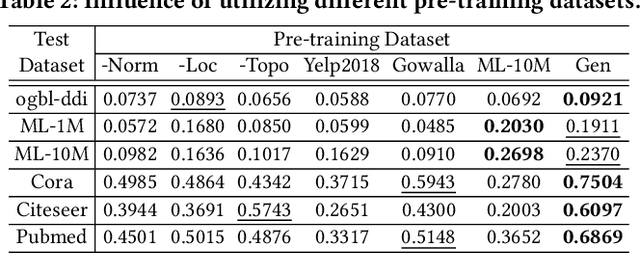
Graph learning has become indispensable for interpreting and harnessing relational data in diverse fields, ranging from recommendation systems to social network analysis. In this context, a variety of GNNs have emerged as promising methodologies for encoding the structural information of graphs. By effectively capturing the graph's underlying structure, these GNNs have shown great potential in enhancing performance in graph learning tasks, such as link prediction and node classification. However, despite their successes, a significant challenge persists: these advanced methods often face difficulties in generalizing to unseen graph data that significantly differs from the training instances. In this work, our aim is to advance the graph learning paradigm by developing a general graph foundation model. This model is designed to understand the complex topological patterns present in diverse graph data, enabling it to excel in zero-shot graph learning tasks across different downstream datasets. To achieve this goal, we address several key technical challenges in our OpenGraph model. Firstly, we propose a unified graph tokenizer to adapt our graph model to generalize well on unseen graph data, even when the underlying graph properties differ significantly from those encountered during training. Secondly, we develop a scalable graph transformer as the foundational encoder, which effectively captures node-wise dependencies within the global topological context. Thirdly, we introduce a data augmentation mechanism enhanced by a LLM to alleviate the limitations of data scarcity in real-world scenarios. Extensive experiments validate the effectiveness of our framework. By adapting our OpenGraph to new graph characteristics and comprehending the nuances of diverse graphs, our approach achieves remarkable zero-shot graph learning performance across various settings and domains.