 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
ssFPN: Scale Sequence (S^2) Feature Based-Feature Pyramid Network for Object Detection
Aug 25, 2022
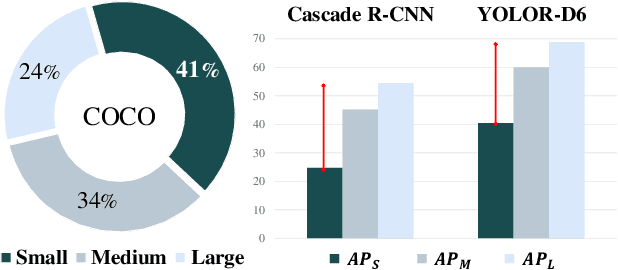
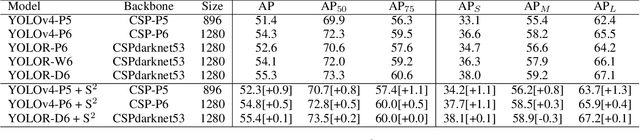
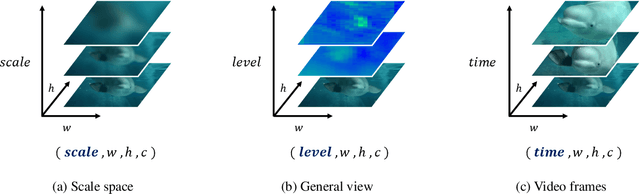
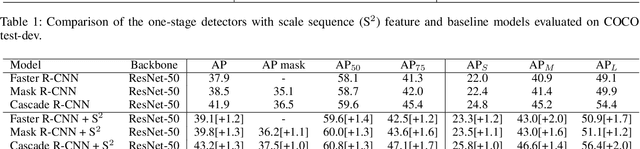
Feature Pyramid Network (FPN) has been an essential module for object detection models to consider various scales of an object. However, average precision (AP) on small objects is relatively lower than AP on medium and large objects. The reason is why the deeper layer of CNN causes information loss as feature extraction level. We propose a new scale sequence (S^2) feature extraction of FPN to strengthen feature information of small objects. We consider FPN structure as scale-space and extract scale sequence (S^2) feature by 3D convolution on the level axis of FPN. It is basically scale invariant feature and is built on high-resolution pyramid feature map for small objects. Furthermore, the proposed S^2 feature can be extended to most object detection models based on FPN. We demonstrate the proposed S2 feature can improve the performance of both one-stage and two-stage detectors on MS COCO dataset. Based on the proposed S2 feature, we achieve upto 1.3% and 1.1% of AP improvement for YOLOv4-P5 and YOLOv4-P6, respectively. For Faster RCNN and Mask R-CNN, we observe upto 2.0% and 1.6% of AP improvement with the suggested S^2 feature, respectively.
FR: Folded Rationalization with a Unified Encoder
Sep 20, 2022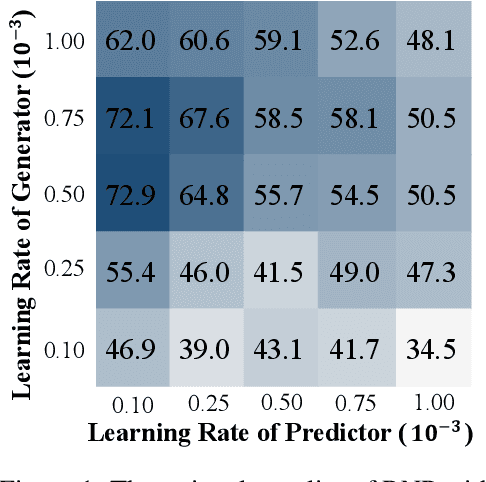
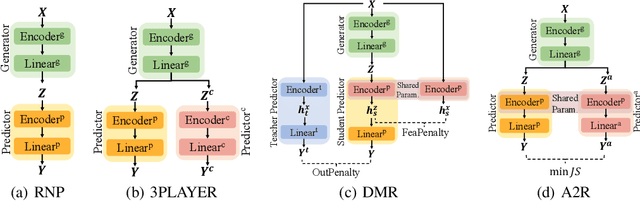
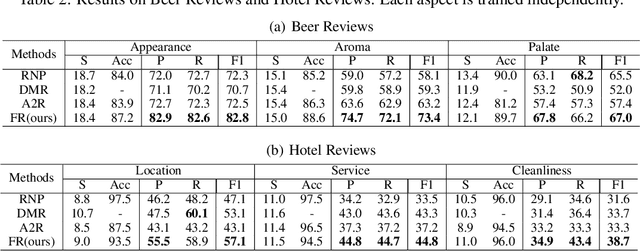
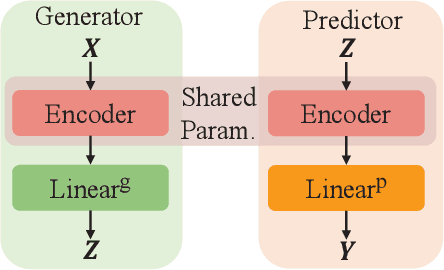
Conventional works generally employ a two-phase model in which a generator selects the most important pieces, followed by a predictor that makes predictions based on the selected pieces. However, such a two-phase model may incur the degeneration problem where the predictor overfits to the noise generated by a not yet well-trained generator and in turn, leads the generator to converge to a sub-optimal model that tends to select senseless pieces. To tackle this challenge, we propose Folded Rationalization (FR) that folds the two phases of the rationale model into one from the perspective of text semantic extraction. The key idea of FR is to employ a unified encoder between the generator and predictor, based on which FR can facilitate a better predictor by access to valuable information blocked by the generator in the traditional two-phase model and thus bring a better generator. Empirically, we show that FR improves the F1 score by up to 10.3% as compared to state-of-the-art methods.
Semi-automatic Data Annotation System for Multi-Target Multi-Camera Vehicle Tracking
Sep 20, 2022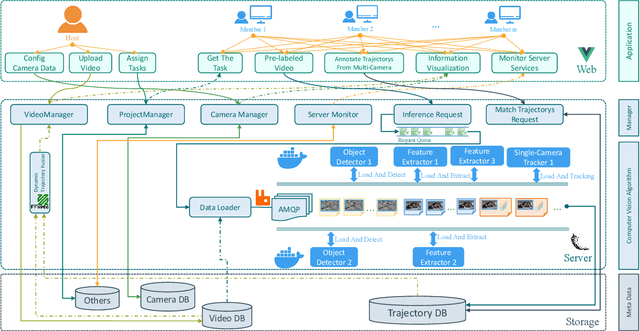
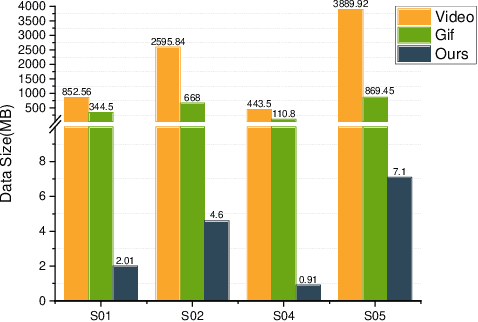
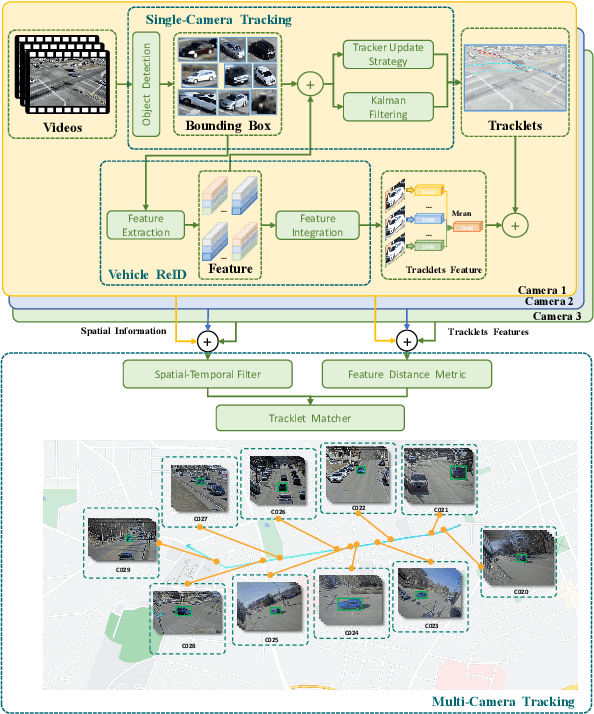
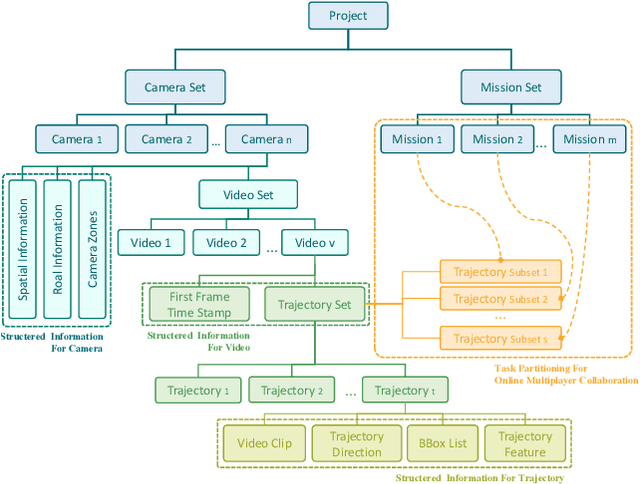
Multi-target multi-camera tracking (MTMCT) plays an important role in intelligent video analysis, surveillance video retrieval, and other application scenarios. Nowadays, the deep-learning-based MTMCT has been the mainstream and has achieved fascinating improvements regarding tracking accuracy and efficiency. However, according to our investigation, the lacking of datasets focusing on real-world application scenarios limits the further improvements for current learning-based MTMCT models. Specifically, the learning-based MTMCT models training by common datasets usually cannot achieve satisfactory results in real-world application scenarios. Motivated by this, this paper presents a semi-automatic data annotation system to facilitate the real-world MTMCT dataset establishment. The proposed system first employs a deep-learning-based single-camera trajectory generation method to automatically extract trajectories from surveillance videos. Subsequently, the system provides a recommendation list in the following manual cross-camera trajectory matching process. The recommendation list is generated based on side information, including camera location, timestamp relation, and background scene. In the experimental stage, extensive results further demonstrate the efficiency of the proposed system.
Multilayer deep feature extraction for visual texture recognition
Aug 22, 2022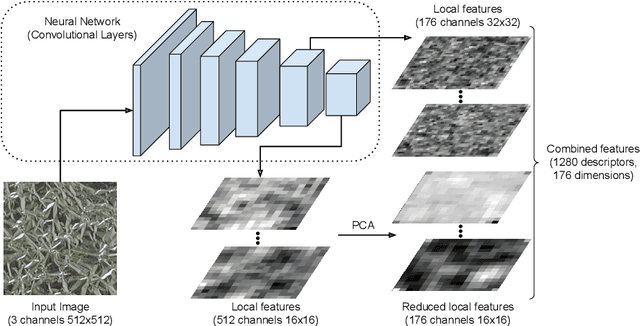
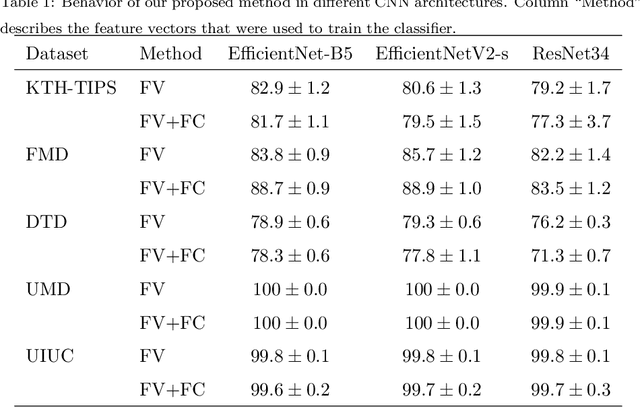
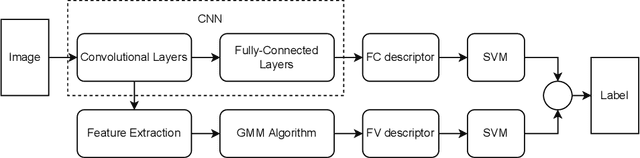
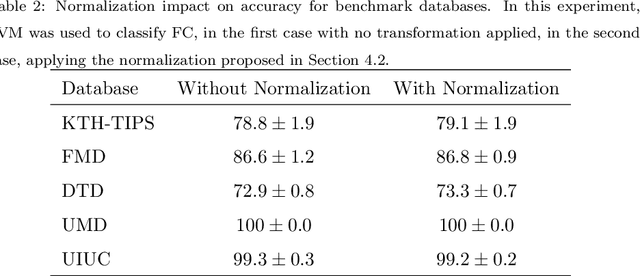
Convolutional neural networks have shown successful results in image classification achieving real-time results superior to the human level. However, texture images still pose some challenge to these models due, for example, to the limited availability of data for training in several problems where these images appear, high inter-class similarity, the absence of a global viewpoint of the object represented, and others. In this context, the present paper is focused on improving the accuracy of convolutional neural networks in texture classification. This is done by extracting features from multiple convolutional layers of a pretrained neural network and aggregating such features using Fisher vector. The reason for using features from earlier convolutional layers is obtaining information that is less domain specific. We verify the effectiveness of our method on texture classification of benchmark datasets, as well as on a practical task of Brazilian plant species identification. In both scenarios, Fisher vectors calculated on multiple layers outperform state-of-art methods, confirming that early convolutional layers provide important information about the texture image for classification.
Translation, Scale and Rotation: Cross-Modal Alignment Meets RGB-Infrared Vehicle Detection
Sep 28, 2022
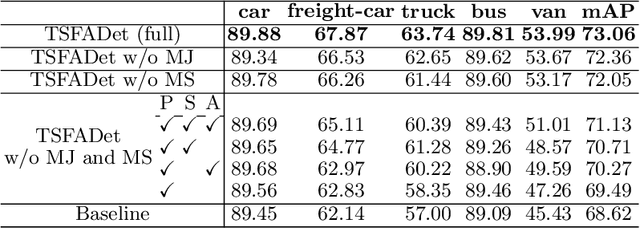
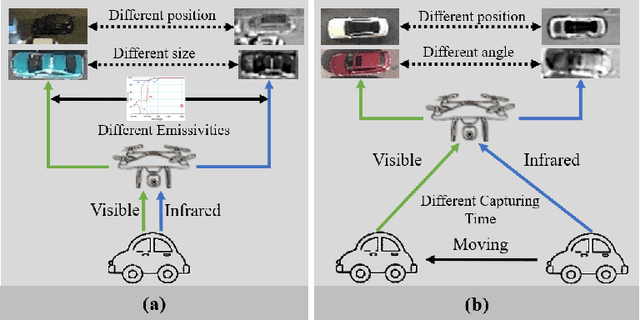

Integrating multispectral data in object detection, especially visible and infrared images, has received great attention in recent years. Since visible (RGB) and infrared (IR) images can provide complementary information to handle light variations, the paired images are used in many fields, such as multispectral pedestrian detection, RGB-IR crowd counting and RGB-IR salient object detection. Compared with natural RGB-IR images, we find detection in aerial RGB-IR images suffers from cross-modal weakly misalignment problems, which are manifested in the position, size and angle deviations of the same object. In this paper, we mainly address the challenge of cross-modal weakly misalignment in aerial RGB-IR images. Specifically, we firstly explain and analyze the cause of the weakly misalignment problem. Then, we propose a Translation-Scale-Rotation Alignment (TSRA) module to address the problem by calibrating the feature maps from these two modalities. The module predicts the deviation between two modality objects through an alignment process and utilizes Modality-Selection (MS) strategy to improve the performance of alignment. Finally, a two-stream feature alignment detector (TSFADet) based on the TSRA module is constructed for RGB-IR object detection in aerial images. With comprehensive experiments on the public DroneVehicle datasets, we verify that our method reduces the effect of the cross-modal misalignment and achieve robust detection results.
Machine Reading, Fast and Slow: When Do Models "Understand" Language?
Sep 15, 2022
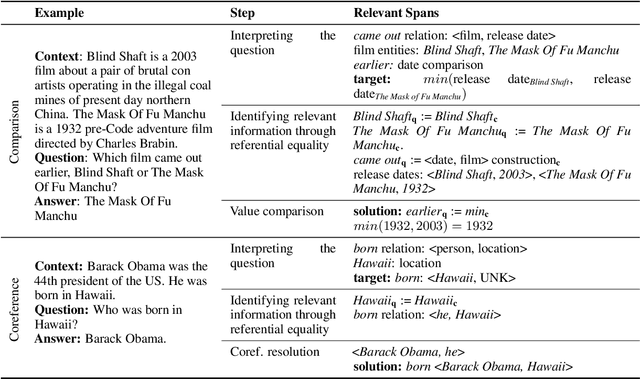
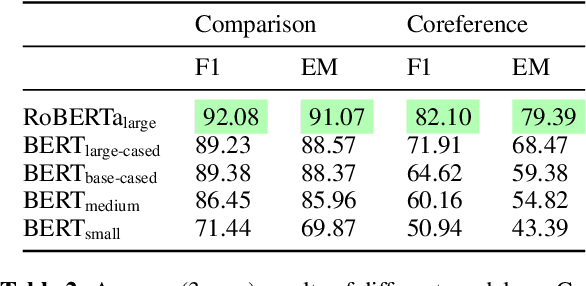

Two of the most fundamental challenges in Natural Language Understanding (NLU) at present are: (a) how to establish whether deep learning-based models score highly on NLU benchmarks for the 'right' reasons; and (b) to understand what those reasons would even be. We investigate the behavior of reading comprehension models with respect to two linguistic 'skills': coreference resolution and comparison. We propose a definition for the reasoning steps expected from a system that would be 'reading slowly', and compare that with the behavior of five models of the BERT family of various sizes, observed through saliency scores and counterfactual explanations. We find that for comparison (but not coreference) the systems based on larger encoders are more likely to rely on the 'right' information, but even they struggle with generalization, suggesting that they still learn specific lexical patterns rather than the general principles of comparison.
From One to Many: Dynamic Cross Attention Networks for LiDAR and Camera Fusion
Sep 25, 2022
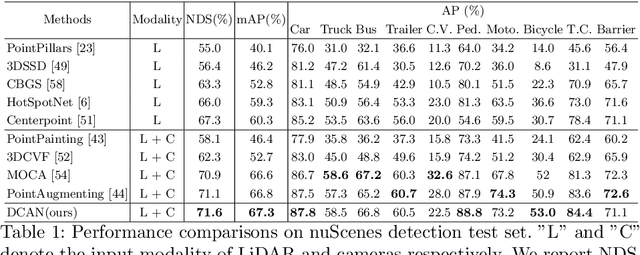
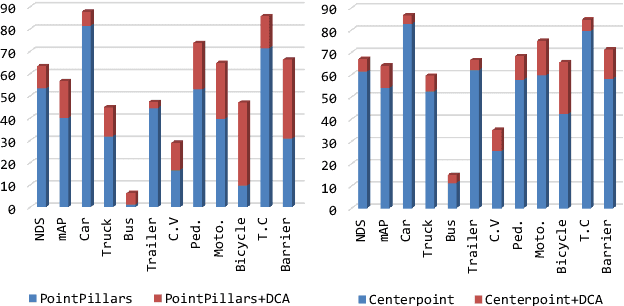
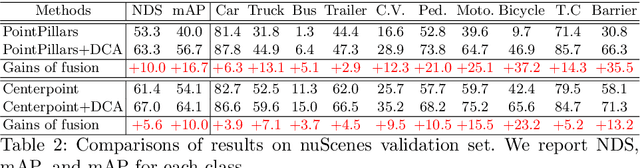
LiDAR and cameras are two complementary sensors for 3D perception in autonomous driving. LiDAR point clouds have accurate spatial and geometry information, while RGB images provide textural and color data for context reasoning. To exploit LiDAR and cameras jointly, existing fusion methods tend to align each 3D point to only one projected image pixel based on calibration, namely one-to-one mapping. However, the performance of these approaches highly relies on the calibration quality, which is sensitive to the temporal and spatial synchronization of sensors. Therefore, we propose a Dynamic Cross Attention (DCA) module with a novel one-to-many cross-modality mapping that learns multiple offsets from the initial projection towards the neighborhood and thus develops tolerance to calibration error. Moreover, a \textit{dynamic query enhancement} is proposed to perceive the model-independent calibration, which further strengthens DCA's tolerance to the initial misalignment. The whole fusion architecture named Dynamic Cross Attention Network (DCAN) exploits multi-level image features and adapts to multiple representations of point clouds, which allows DCA to serve as a plug-in fusion module. Extensive experiments on nuScenes and KITTI prove DCA's effectiveness. The proposed DCAN outperforms state-of-the-art methods on the nuScenes detection challenge.
GPatch: Patching Graph Neural Networks for Cold-Start Recommendations
Sep 25, 2022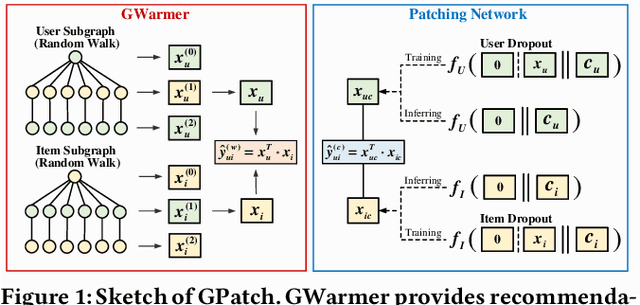
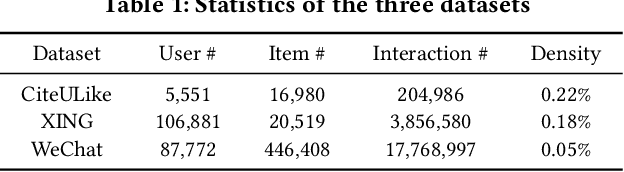

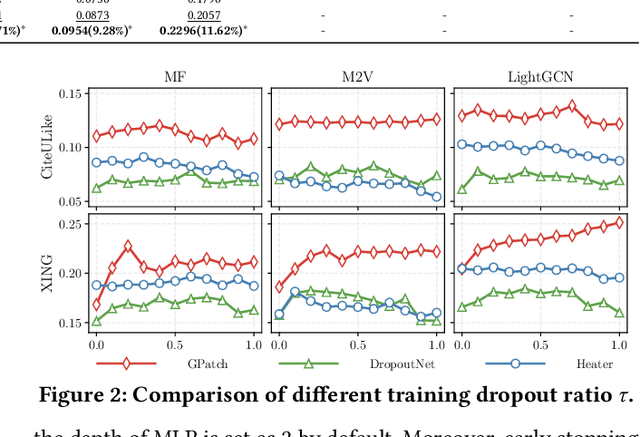
Cold start is an essential and persistent problem in recommender systems. State-of-the-art solutions rely on training hybrid models for both cold-start and existing users/items, based on the auxiliary information. Such a hybrid model would compromise the performance of existing users/items, which might make these solutions not applicable in real-worlds recommender systems where the experience of existing users/items must be guaranteed. Meanwhile, graph neural networks (GNNs) have been demonstrated to perform effectively warm (non-cold-start) recommendations. However, they have never been applied to handle the cold-start problem in a user-item bipartite graph. This is a challenging but rewarding task since cold-start users/items do not have links. Besides, it is nontrivial to design an appropriate GNN to conduct cold-start recommendations while maintaining the performance for existing users/items. To bridge the gap, we propose a tailored GNN-based framework (GPatch) that contains two separate but correlated components. First, an efficient GNN architecture -- GWarmer, is designed to model the warm users/items. Second, we construct correlated Patching Networks to simulate and patch GWarmer by conducting cold-start recommendations. Experiments on benchmark and large-scale commercial datasets demonstrate that GPatch is significantly superior in providing recommendations for both existing and cold-start users/items.
A Generative Shape Compositional Framework: Towards Representative Populations of Virtual Heart Chimaeras
Oct 04, 2022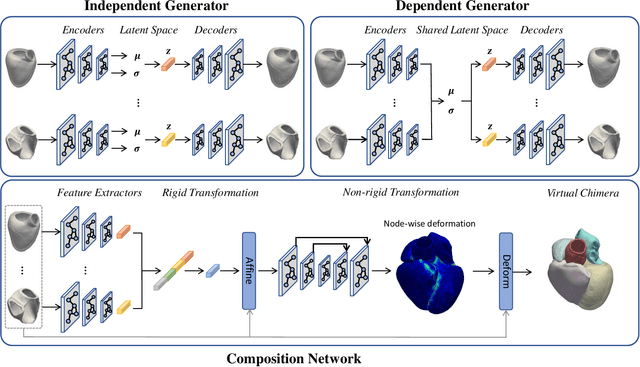
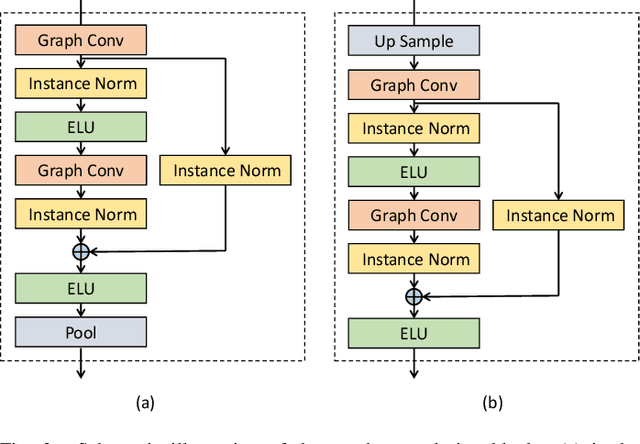
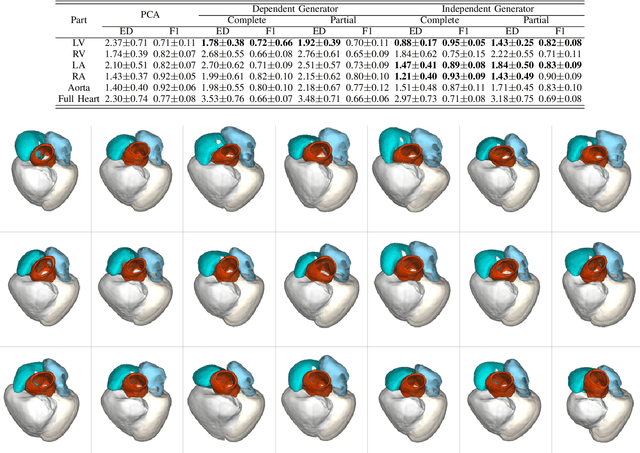
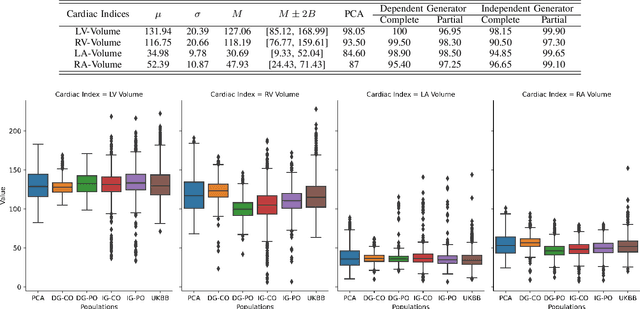
Generating virtual populations of anatomy that capture sufficient variability while remaining plausible is essential for conducting in-silico trials of medical devices. However, not all anatomical shapes of interest are always available for each individual in a population. Hence, missing/partially-overlapping anatomical information is often available across individuals in a population. We introduce a generative shape model for complex anatomical structures, learnable from datasets of unpaired datasets. The proposed generative model can synthesise complete whole complex shape assemblies coined virtual chimaeras, as opposed to natural human chimaeras. We applied this framework to build virtual chimaeras from databases of whole-heart shape assemblies that each contribute samples for heart substructures. Specifically, we propose a generative shape compositional framework which comprises two components - a part-aware generative shape model which captures the variability in shape observed for each structure of interest in the training population; and a spatial composition network which assembles/composes the structures synthesised by the former into multi-part shape assemblies (viz. virtual chimaeras). We also propose a novel self supervised learning scheme that enables the spatial composition network to be trained with partially overlapping data and weak labels. We trained and validated our approach using shapes of cardiac structures derived from cardiac magnetic resonance images available in the UK Biobank. Our approach significantly outperforms a PCA-based shape model (trained with complete data) in terms of generalisability and specificity. This demonstrates the superiority of the proposed approach as the synthesised cardiac virtual populations are more plausible and capture a greater degree of variability in shape than those generated by the PCA-based shape model.
Persistent Homology Guided Monte-Carlo Tree Search for Effective Non-Prehensile Manipulation
Oct 04, 2022
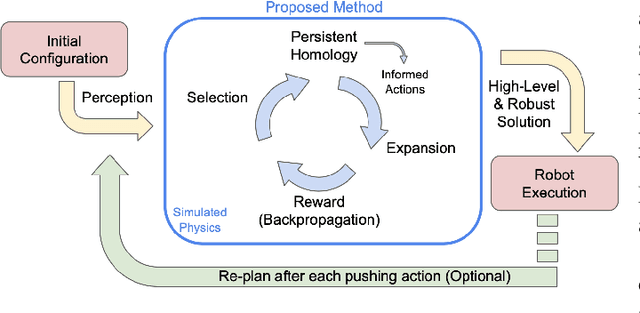
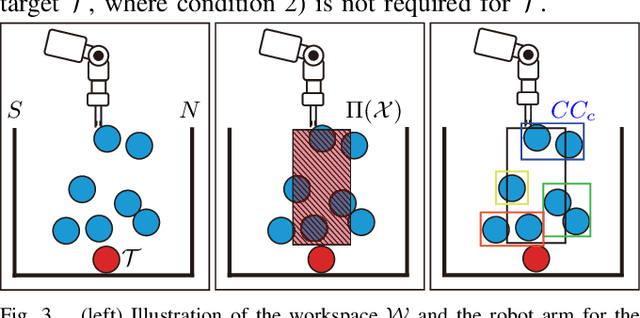

Performing object retrieval tasks in messy real-world workspaces involves the challenges of \emph{uncertainty} and \emph{clutter}. One option is to solve retrieval problems via a sequence of prehensile pick-n-place operations, which can be computationally expensive to compute in highly-cluttered scenarios and also inefficient to execute. The proposed framework selects the option of performing non-prehensile actions, such as pushing, to clean a cluttered workspace to allow a robotic arm to retrieve a target object. Non-prehensile actions, allow to interact simultaneously with multiple objects, which can speed up execution. At the same time, they can significantly increase uncertainty as it is not easy to accurately estimate the outcome of a pushing operation in clutter. The proposed framework integrates topological tools and Monte-Carlo tree search to achieve effective and robust pushing for object retrieval problems. In particular, it proposes using persistent homology to automatically identify manageable clustering of blocking objects in the workspace without the need for manually adjusting hyper-parameters. Furthermore, MCTS uses this information to explore feasible actions to push groups of objects together, aiming to minimize the number of pushing actions needed to clear the path to the target object. Real-world experiments using a Baxter robot, which involves some noise in actuation, show that the proposed framework achieves a higher success rate in solving retrieval tasks in dense clutter compared to state-of-the-art alternatives. Moreover, it produces high-quality solutions with a small number of pushing actions improving the overall execution time. More critically, it is robust enough that it allows to plan the sequence of actions offline and then execute them reliably online with Baxter.