 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
TRUST: An Accurate and End-to-End Table structure Recognizer Using Splitting-based Transformers
Aug 31, 2022
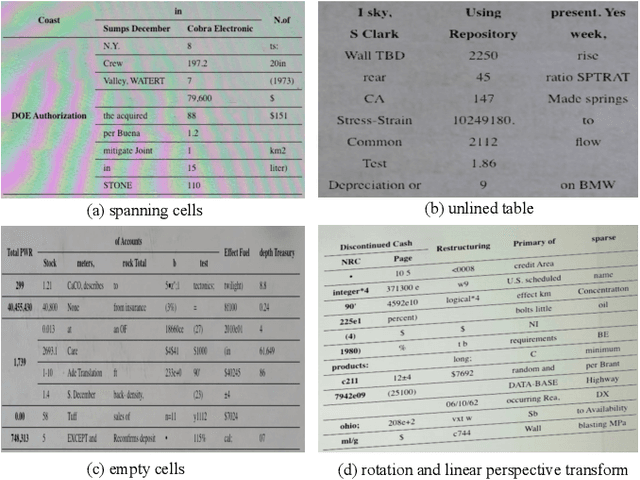
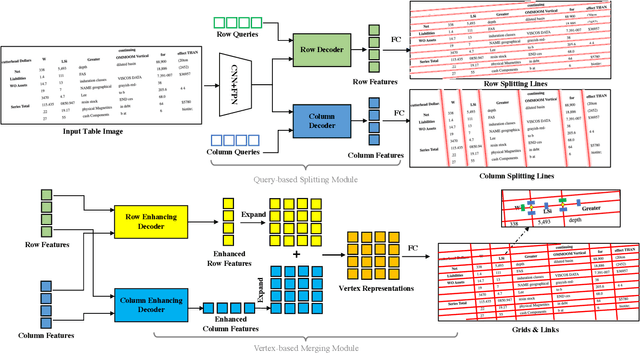
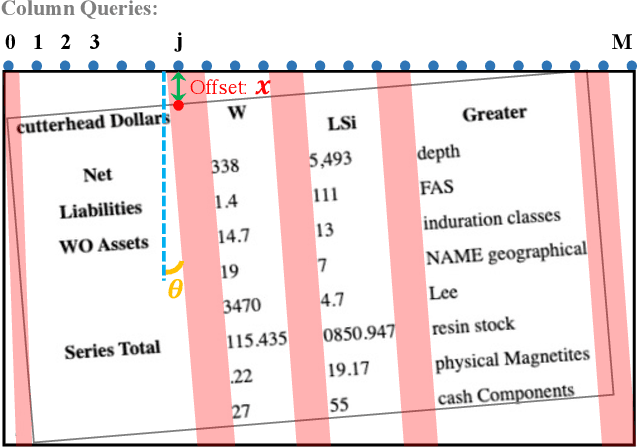
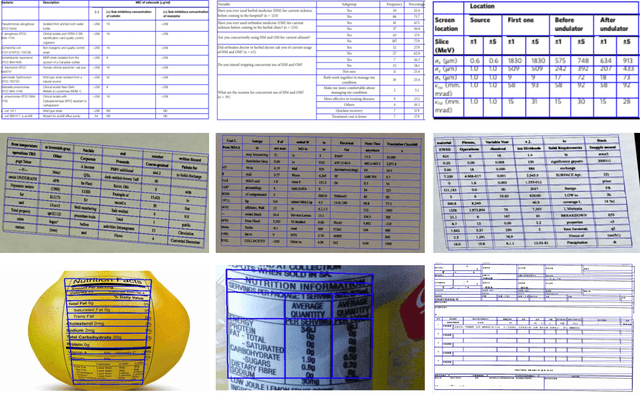
Table structure recognition is a crucial part of document image analysis domain. Its difficulty lies in the need to parse the physical coordinates and logical indices of each cell at the same time. However, the existing methods are difficult to achieve both these goals, especially when the table splitting lines are blurred or tilted. In this paper, we propose an accurate and end-to-end transformer-based table structure recognition method, referred to as TRUST. Transformers are suitable for table structure recognition because of their global computations, perfect memory, and parallel computation. By introducing novel Transformer-based Query-based Splitting Module and Vertex-based Merging Module, the table structure recognition problem is decoupled into two joint optimization sub-tasks: multi-oriented table row/column splitting and table grid merging. The Query-based Splitting Module learns strong context information from long dependencies via Transformer networks, accurately predicts the multi-oriented table row/column separators, and obtains the basic grids of the table accordingly. The Vertex-based Merging Module is capable of aggregating local contextual information between adjacent basic grids, providing the ability to merge basic girds that belong to the same spanning cell accurately. We conduct experiments on several popular benchmarks including PubTabNet and SynthTable, our method achieves new state-of-the-art results. In particular, TRUST runs at 10 FPS on PubTabNet, surpassing the previous methods by a large margin.
3DPCT: 3D Point Cloud Transformer with Dual Self-attention
Sep 21, 2022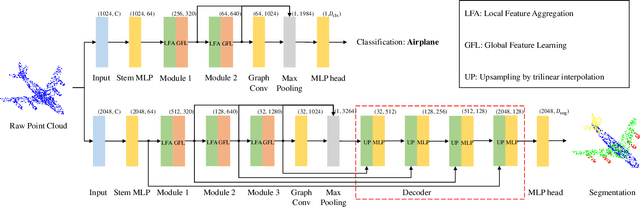
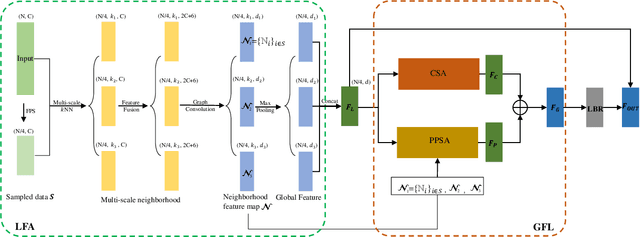
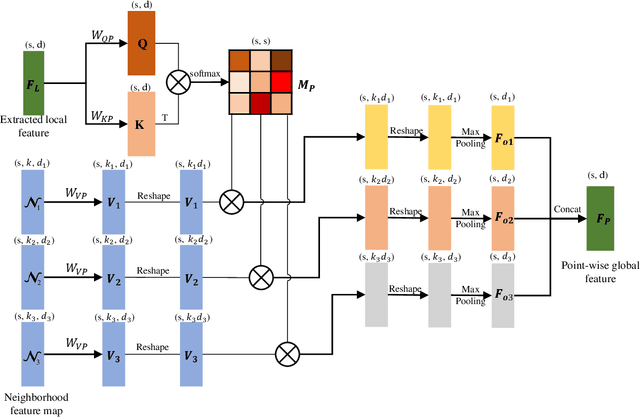
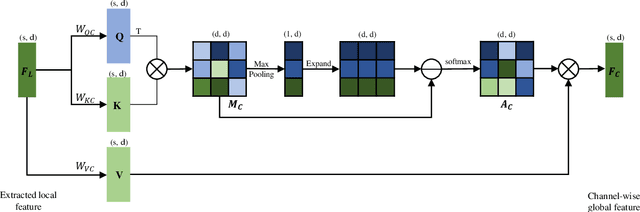
Transformers have resulted in remarkable achievements in the field of image processing. Inspired by this great success, the application of Transformers to 3D point cloud processing has drawn more and more attention. This paper presents a novel point cloud representational learning network, 3D Point Cloud Transformer with Dual Self-attention (3DPCT) and an encoder-decoder structure. Specifically, 3DPCT has a hierarchical encoder, which contains two local-global dual-attention modules for the classification task (three modules for the segmentation task), with each module consisting of a Local Feature Aggregation (LFA) block and a Global Feature Learning (GFL) block. The GFL block is dual self-attention, with both point-wise and channel-wise self-attention to improve feature extraction. Moreover, in LFA, to better leverage the local information extracted, a novel point-wise self-attention model, named as Point-Patch Self-Attention (PPSA), is designed. The performance is evaluated on both classification and segmentation datasets, containing both synthetic and real-world data. Extensive experiments demonstrate that the proposed method achieved state-of-the-art results on both classification and segmentation tasks.
Dynamic Hybrid Beamforming Design for Dual-Function Radar-Communication Systems
Sep 11, 2022
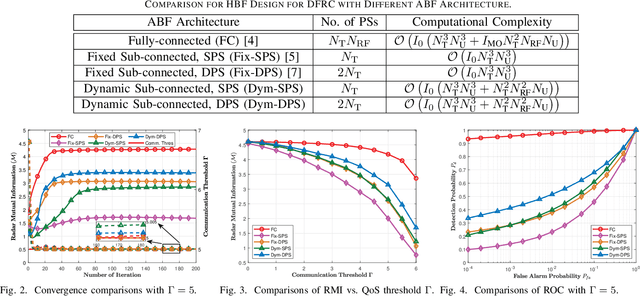
This paper investigates dynamic hybrid beamforming (HBF) for a dual-function radar-communication (DFRC) system, where the DFRC base station (BS) simultaneously serves multiple single-antenna users and senses a target in the presence of multiple clutters. Particularly, we apply a HBF architecture with dynamic subarrays and double phase shifters in the DFRC BS. Aiming at maximizing the radar mutual information, we consider jointly designing the dynamic HBF of the DFRC system, subject to the constraints of communication quality of service (QoS), transmit power, and analog beamformer. To solve the complicated non-convex optimization, an efficient alternating optimization algorithm based on the majorization-minimization methods is developed. Simulation results verify the advancement of the considered HBF architecture and the effectiveness of the proposed design method.
More Interpretable Graph Similarity Computation via Maximum Common Subgraph Inference
Aug 09, 2022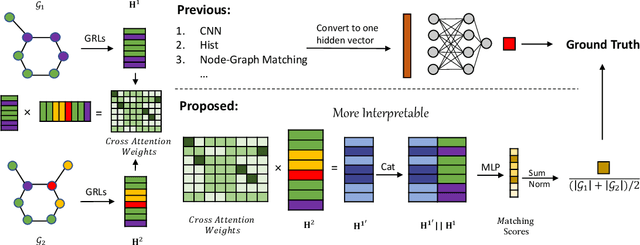
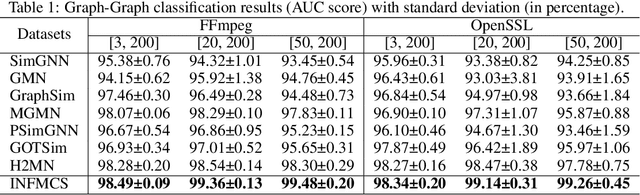
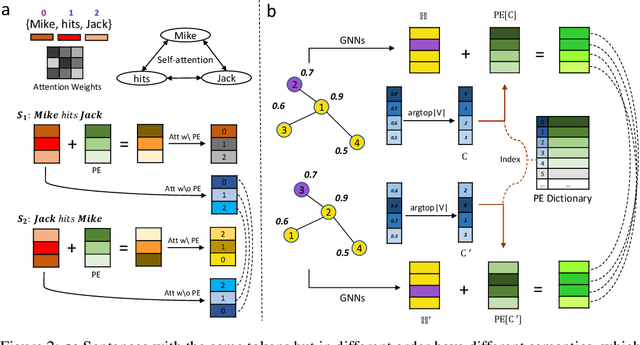
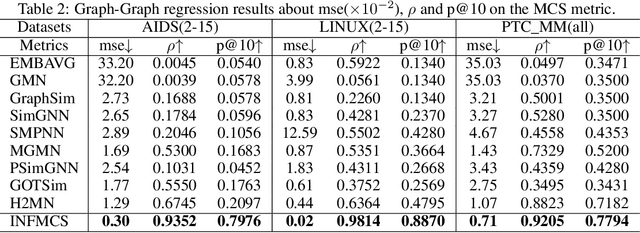
Graph similarity measurement, which computes the distance/similarity between two graphs, arises in various graph-related tasks. Recent learning-based methods lack interpretability, as they directly transform interaction information between two graphs into one hidden vector and then map it to similarity. To cope with this problem, this study proposes a more interpretable end-to-end paradigm for graph similarity learning, named Similarity Computation via Maximum Common Subgraph Inference (INFMCS). Our critical insight into INFMCS is the strong correlation between similarity score and Maximum Common Subgraph (MCS). We implicitly infer MCS to obtain the normalized MCS size, with the supervision information being only the similarity score during training. To capture more global information, we also stack some vanilla transformer encoder layers with graph convolution layers and propose a novel permutation-invariant node Positional Encoding. The entire model is quite simple yet effective. Comprehensive experiments demonstrate that INFMCS consistently outperforms state-of-the-art baselines for graph-graph classification and regression tasks. Ablation experiments verify the effectiveness of the proposed computation paradigm and other components. Also, visualization and statistics of results reveal the interpretability of INFMCS.
Blind Quality Assessment of 3D Dense Point Clouds with Structure Guided Resampling
Aug 31, 2022
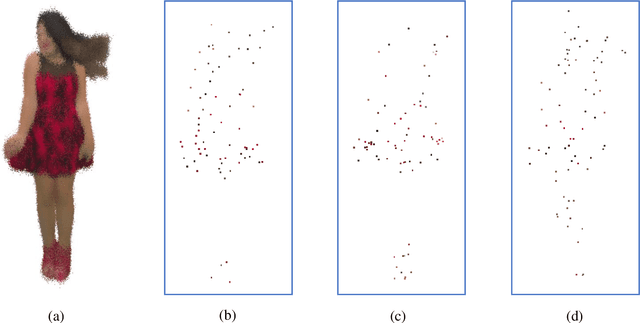
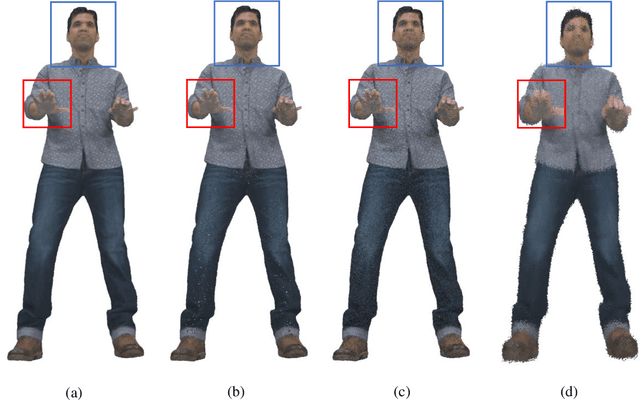
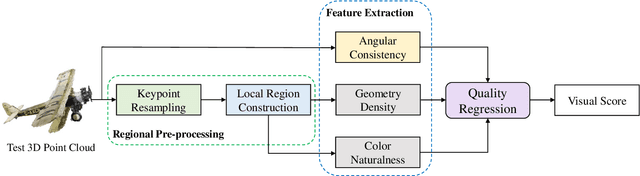
Objective quality assessment of 3D point clouds is essential for the development of immersive multimedia systems in real-world applications. Despite the success of perceptual quality evaluation for 2D images and videos, blind/no-reference metrics are still scarce for 3D point clouds with large-scale irregularly distributed 3D points. Therefore, in this paper, we propose an objective point cloud quality index with Structure Guided Resampling (SGR) to automatically evaluate the perceptually visual quality of 3D dense point clouds. The proposed SGR is a general-purpose blind quality assessment method without the assistance of any reference information. Specifically, considering that the human visual system (HVS) is highly sensitive to structure information, we first exploit the unique normal vectors of point clouds to execute regional pre-processing which consists of keypoint resampling and local region construction. Then, we extract three groups of quality-related features, including: 1) geometry density features; 2) color naturalness features; 3) angular consistency features. Both the cognitive peculiarities of the human brain and naturalness regularity are involved in the designed quality-aware features that can capture the most vital aspects of distorted 3D point clouds. Extensive experiments on several publicly available subjective point cloud quality databases validate that our proposed SGR can compete with state-of-the-art full-reference, reduced-reference, and no-reference quality assessment algorithms.
Multimedia Generative Script Learning for Task Planning
Aug 25, 2022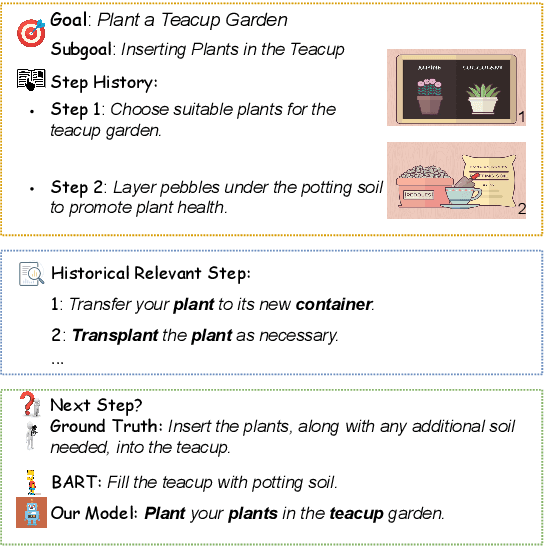
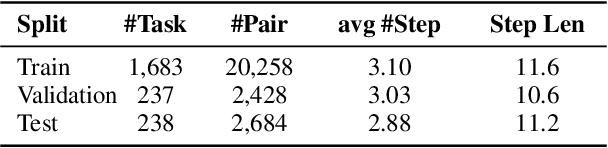
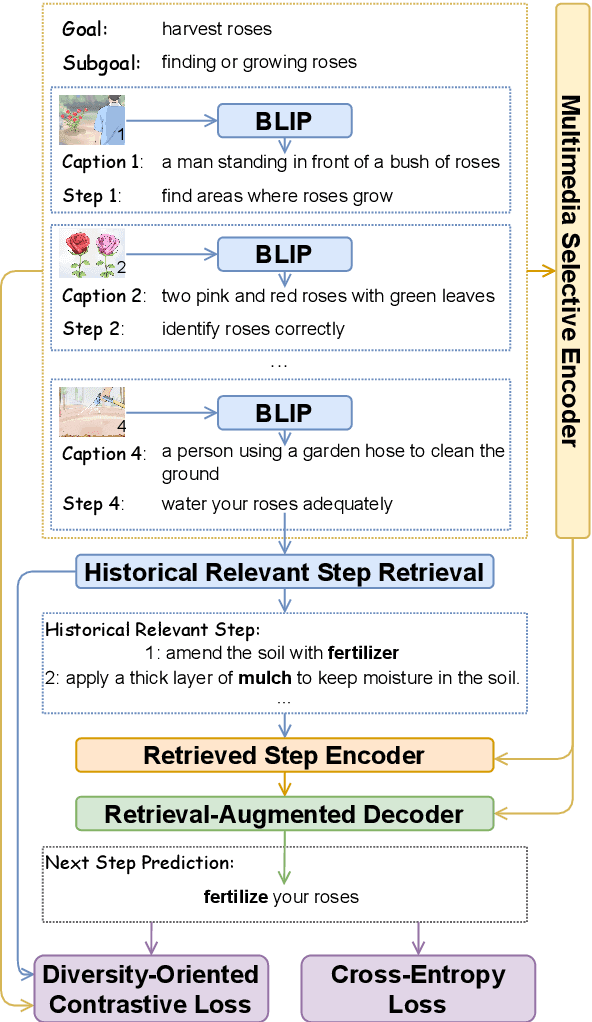
Goal-oriented generative script learning aims to generate subsequent steps based on a goal, which is an essential task to assist robots in performing stereotypical activities of daily life. We show that the performance of this task can be improved if historical states are not just captured by the linguistic instructions given to people, but are augmented with the additional information provided by accompanying images. Therefore, we propose a new task, Multimedia Generative Script Learning, to generate subsequent steps by tracking historical states in both text and vision modalities, as well as presenting the first benchmark containing 2,338 tasks and 31,496 steps with descriptive images. We aim to generate scripts that are visual-state trackable, inductive for unseen tasks, and diverse in their individual steps. We propose to encode visual state changes through a multimedia selective encoder, transferring knowledge from previously observed tasks using a retrieval-augmented decoder, and presenting the distinct information at each step by optimizing a diversity-oriented contrastive learning objective. We define metrics to evaluate both generation quality and inductive quality. Experiment results demonstrate that our approach significantly outperforms strong baselines.
Multi-Modal Experience Inspired AI Creation
Sep 02, 2022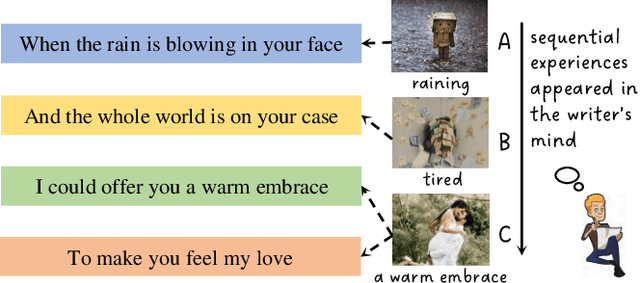
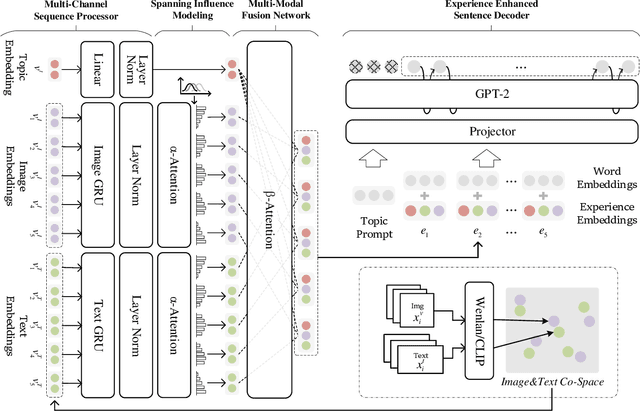
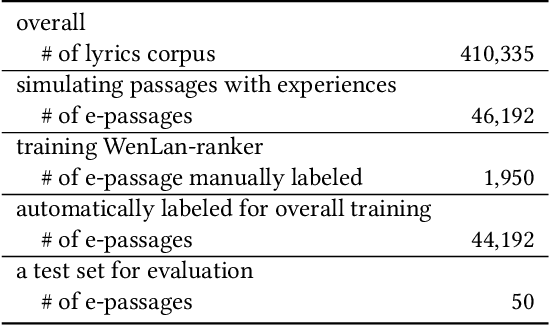
AI creation, such as poem or lyrics generation, has attracted increasing attention from both industry and academic communities, with many promising models proposed in the past few years. Existing methods usually estimate the outputs based on single and independent visual or textual information. However, in reality, humans usually make creations according to their experiences, which may involve different modalities and be sequentially correlated. To model such human capabilities, in this paper, we define and solve a novel AI creation problem based on human experiences. More specifically, we study how to generate texts based on sequential multi-modal information. Compared with the previous works, this task is much more difficult because the designed model has to well understand and adapt the semantics among different modalities and effectively convert them into the output in a sequential manner. To alleviate these difficulties, we firstly design a multi-channel sequence-to-sequence architecture equipped with a multi-modal attention network. For more effective optimization, we then propose a curriculum negative sampling strategy tailored for the sequential inputs. To benchmark this problem and demonstrate the effectiveness of our model, we manually labeled a new multi-modal experience dataset. With this dataset, we conduct extensive experiments by comparing our model with a series of representative baselines, where we can demonstrate significant improvements in our model based on both automatic and human-centered metrics. The code and data are available at: \url{https://github.com/Aman-4-Real/MMTG}.
ERASE-Net: Efficient Segmentation Networks for Automotive Radar Signals
Sep 26, 2022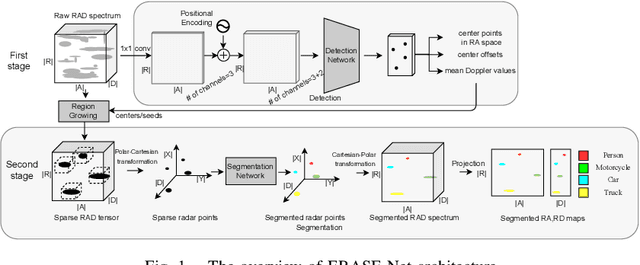
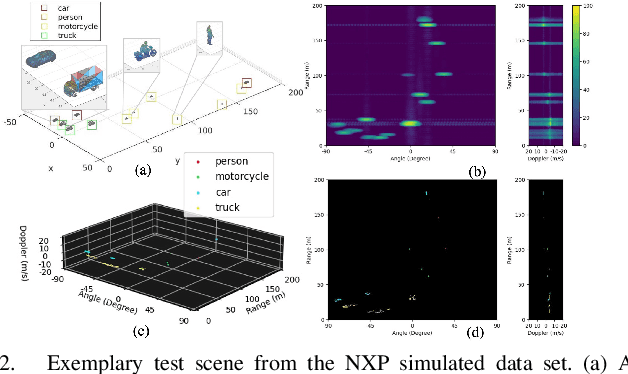
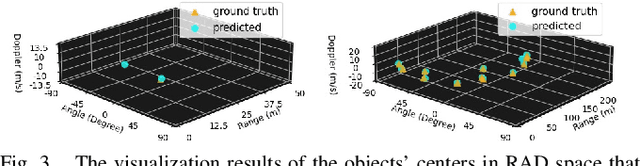
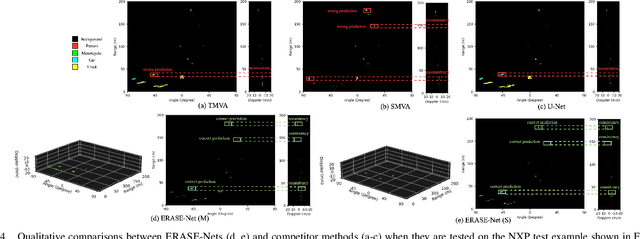
Among various sensors for assisted and autonomous driving systems, automotive radar has been considered as a robust and low-cost solution even in adverse weather or lighting conditions. With the recent development of radar technologies and open-sourced annotated data sets, semantic segmentation with radar signals has become very promising. However, existing methods are either computationally expensive or discard significant amounts of valuable information from raw 3D radar signals by reducing them to 2D planes via averaging. In this work, we introduce ERASE-Net, an Efficient RAdar SEgmentation Network to segment the raw radar signals semantically. The core of our approach is the novel detect-then-segment method for raw radar signals. It first detects the center point of each object, then extracts a compact radar signal representation, and finally performs semantic segmentation. We show that our method can achieve superior performance on radar semantic segmentation task compared to the state-of-the-art (SOTA) technique. Furthermore, our approach requires up to 20x less computational resources. Finally, we show that the proposed ERASE-Net can be compressed by 40% without significant loss in performance, significantly more than the SOTA network, which makes it a more promising candidate for practical automotive applications.
LatentGaze: Cross-Domain Gaze Estimation through Gaze-Aware Analytic Latent Code Manipulation
Sep 21, 2022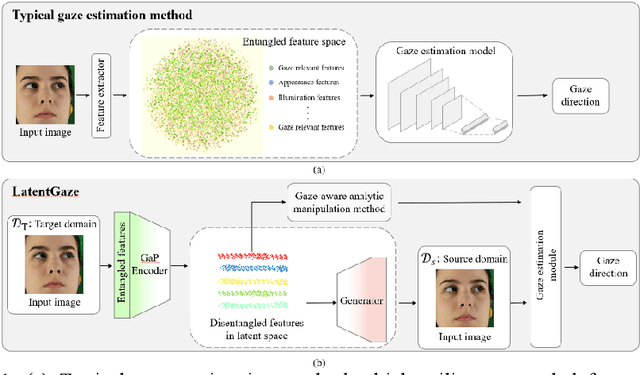
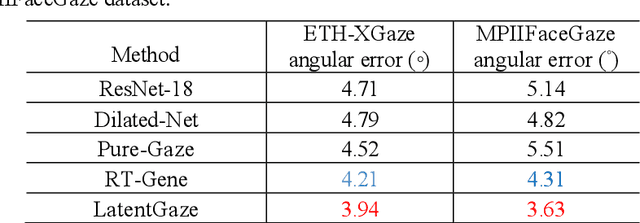
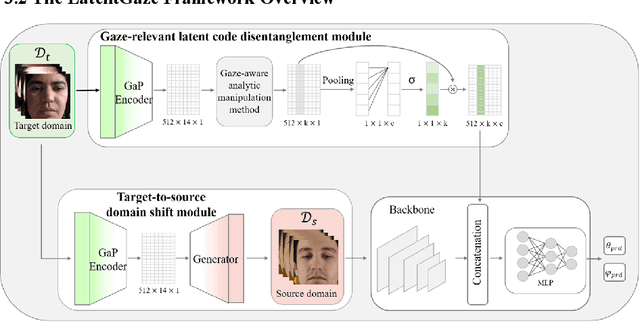
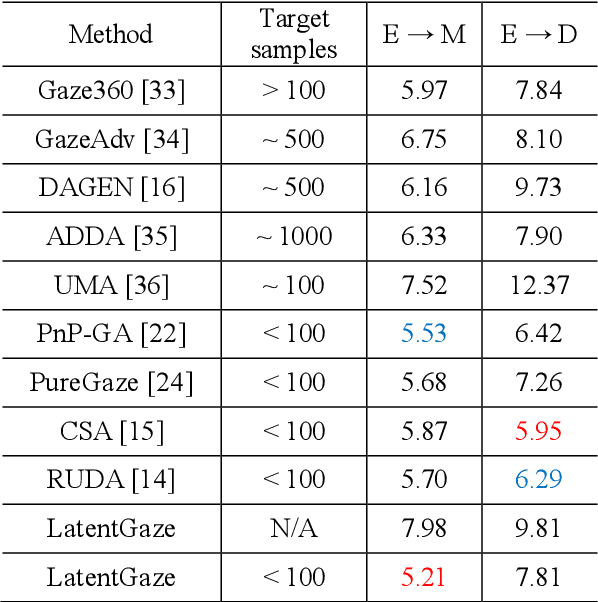
Although recent gaze estimation methods lay great emphasis on attentively extracting gaze-relevant features from facial or eye images, how to define features that include gaze-relevant components has been ambiguous. This obscurity makes the model learn not only gaze-relevant features but also irrelevant ones. In particular, it is fatal for the cross-dataset performance. To overcome this challenging issue, we propose a gaze-aware analytic manipulation method, based on a data-driven approach with generative adversarial network inversion's disentanglement characteristics, to selectively utilize gaze-relevant features in a latent code. Furthermore, by utilizing GAN-based encoder-generator process, we shift the input image from the target domain to the source domain image, which a gaze estimator is sufficiently aware. In addition, we propose gaze distortion loss in the encoder that prevents the distortion of gaze information. The experimental results demonstrate that our method achieves state-of-the-art gaze estimation accuracy in a cross-domain gaze estimation tasks. This code is available at https://github.com/leeisack/LatentGaze/.
It Takes Two: Learning to Plan for Human-Robot Cooperative Carrying
Sep 26, 2022
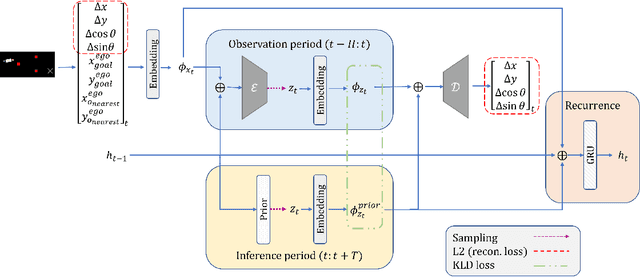
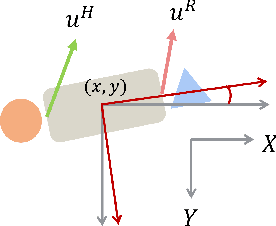
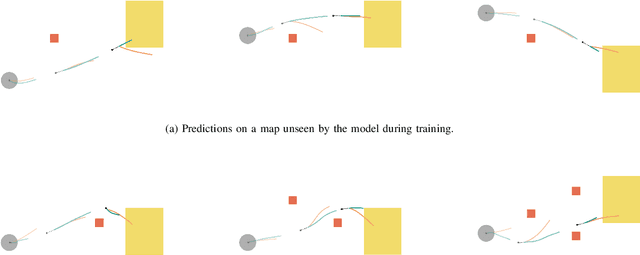
Collaborative table-carrying is a complex task due to the continuous nature of the action and state-spaces, multimodality of strategies, existence of obstacles in the environment, and the need for instantaneous adaptation to other agents. In this work, we present a method for predicting realistic motion plans for cooperative human-robot teams on a table-carrying task. Using a Variational Recurrent Neural Network, VRNN, to model the variation in the trajectory of a human-robot team over time, we are able to capture the distribution over the team's future states while leveraging information from interaction history. The key to our approach is in our model's ability to leverage human demonstration data and generate trajectories that synergize well with humans during test time. We show that the model generates more human-like motion compared to a baseline, centralized sampling-based planner, Rapidly-exploring Random Trees (RRT). Furthermore, we evaluate the VRNN planner with a human partner and show its ability to both generate more human-like paths and achieve higher task success rate than RRT can while planning with a human. Finally, we demonstrate that a LoCoBot using the VRNN planner can complete the task successfully with a human controlling another LoCoBot.