 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Neural Network Classifier as Mutual Information Evaluator
Jun 19, 2021
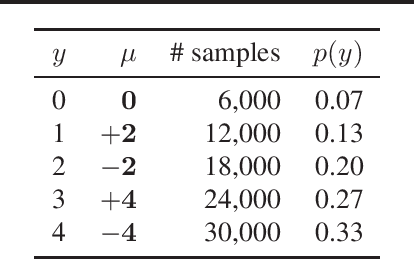
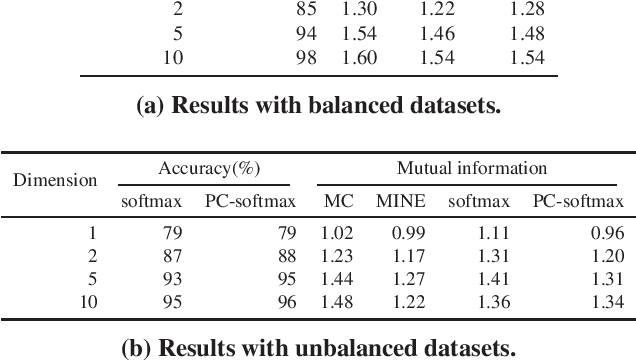
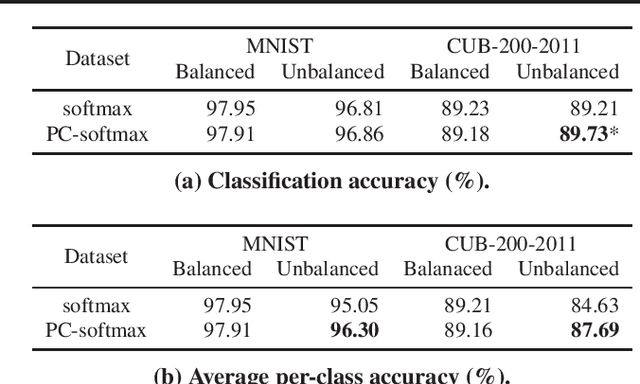
Cross-entropy loss with softmax output is a standard choice to train neural network classifiers. We give a new view of neural network classifiers with softmax and cross-entropy as mutual information evaluators. We show that when the dataset is balanced, training a neural network with cross-entropy maximises the mutual information between inputs and labels through a variational form of mutual information. Thereby, we develop a new form of softmax that also converts a classifier to a mutual information evaluator when the dataset is imbalanced. Experimental results show that the new form leads to better classification accuracy, in particular for imbalanced datasets.
Path-aware Siamese Graph Neural Network for Link Prediction
Aug 10, 2022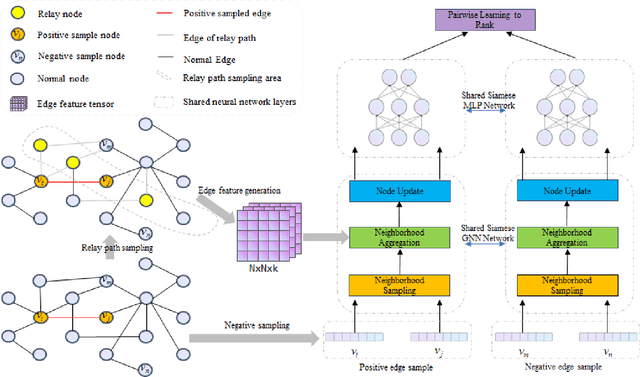

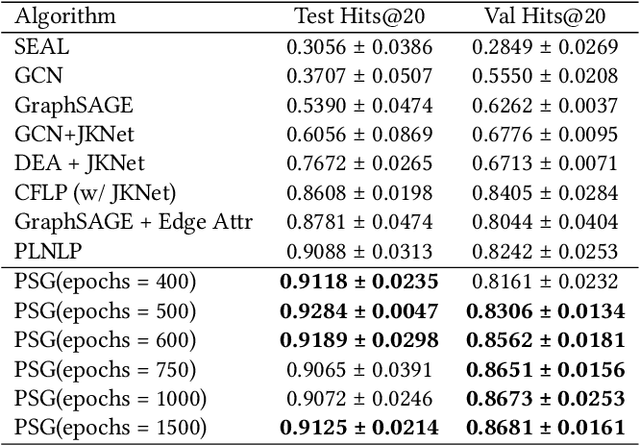
In this paper, we propose an algorithm of Path-aware Siamese Graph neural network(PSG) for link prediction tasks. Firstly, PSG can capture both nodes and edge features for given two nodes, namely the structure information of k-neighborhoods and relay paths information of the nodes. Furthermore, siamese graph neural network is utilized by PSG for representation learning of two contrastive links, which are a positive link and a negative link. We evaluate the proposed algorithm PSG on a link property prediction dataset of Open Graph Benchmark (OGB), ogbl-ddi. PSG achieves top 1 performance on ogbl-ddi. The experimental results verify the superiority of PSG.
One Transformer Can Understand Both 2D & 3D Molecular Data
Oct 04, 2022
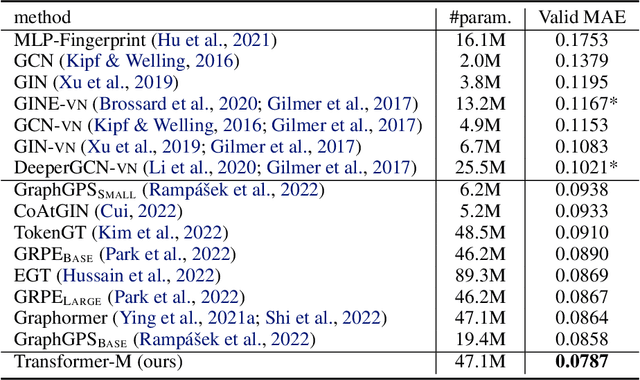
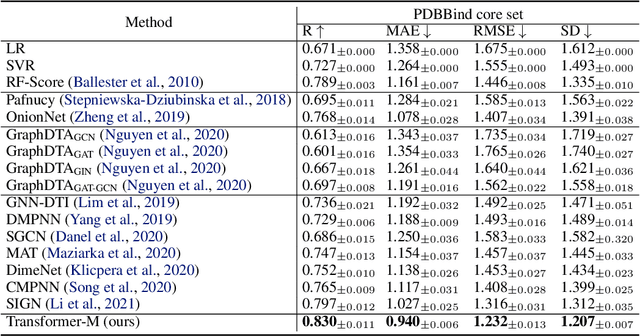
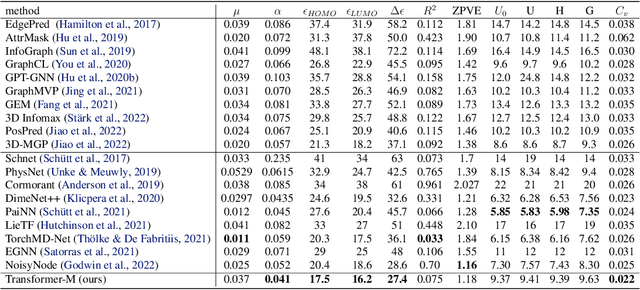
Unlike vision and language data which usually has a unique format, molecules can naturally be characterized using different chemical formulations. One can view a molecule as a 2D graph or define it as a collection of atoms located in a 3D space. For molecular representation learning, most previous works designed neural networks only for a particular data format, making the learned models likely to fail for other data formats. We believe a general-purpose neural network model for chemistry should be able to handle molecular tasks across data modalities. To achieve this goal, in this work, we develop a novel Transformer-based Molecular model called Transformer-M, which can take molecular data of 2D or 3D formats as input and generate meaningful semantic representations. Using the standard Transformer as the backbone architecture, Transformer-M develops two separated channels to encode 2D and 3D structural information and incorporate them with the atom features in the network modules. When the input data is in a particular format, the corresponding channel will be activated, and the other will be disabled. By training on 2D and 3D molecular data with properly designed supervised signals, Transformer-M automatically learns to leverage knowledge from different data modalities and correctly capture the representations. We conducted extensive experiments for Transformer-M. All empirical results show that Transformer-M can simultaneously achieve strong performance on 2D and 3D tasks, suggesting its broad applicability. The code and models will be made publicly available at https://github.com/lsj2408/Transformer-M.
NeuDep: Neural Binary Memory Dependence Analysis
Oct 04, 2022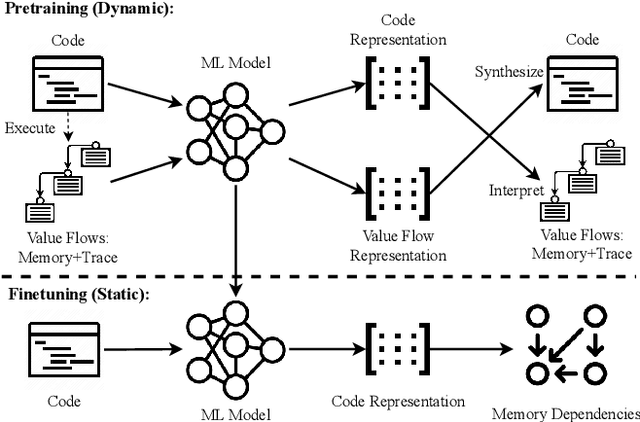

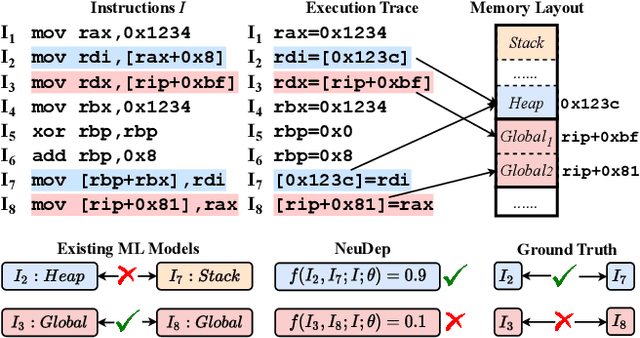
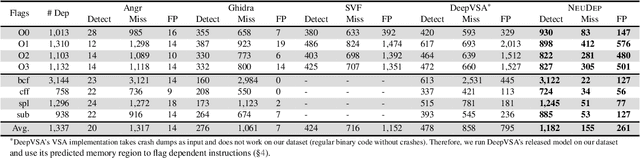
Determining whether multiple instructions can access the same memory location is a critical task in binary analysis. It is challenging as statically computing precise alias information is undecidable in theory. The problem aggravates at the binary level due to the presence of compiler optimizations and the absence of symbols and types. Existing approaches either produce significant spurious dependencies due to conservative analysis or scale poorly to complex binaries. We present a new machine-learning-based approach to predict memory dependencies by exploiting the model's learned knowledge about how binary programs execute. Our approach features (i) a self-supervised procedure that pretrains a neural net to reason over binary code and its dynamic value flows through memory addresses, followed by (ii) supervised finetuning to infer the memory dependencies statically. To facilitate efficient learning, we develop dedicated neural architectures to encode the heterogeneous inputs (i.e., code, data values, and memory addresses from traces) with specific modules and fuse them with a composition learning strategy. We implement our approach in NeuDep and evaluate it on 41 popular software projects compiled by 2 compilers, 4 optimizations, and 4 obfuscation passes. We demonstrate that NeuDep is more precise (1.5x) and faster (3.5x) than the current state-of-the-art. Extensive probing studies on security-critical reverse engineering tasks suggest that NeuDep understands memory access patterns, learns function signatures, and is able to match indirect calls. All these tasks either assist or benefit from inferring memory dependencies. Notably, NeuDep also outperforms the current state-of-the-art on these tasks.
Doubly-Irregular Repeat-Accumulate Codes over Integer Rings for Multi-user Communications
Oct 04, 2022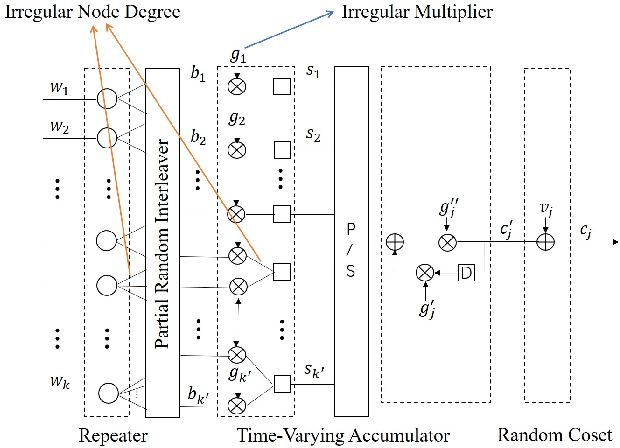
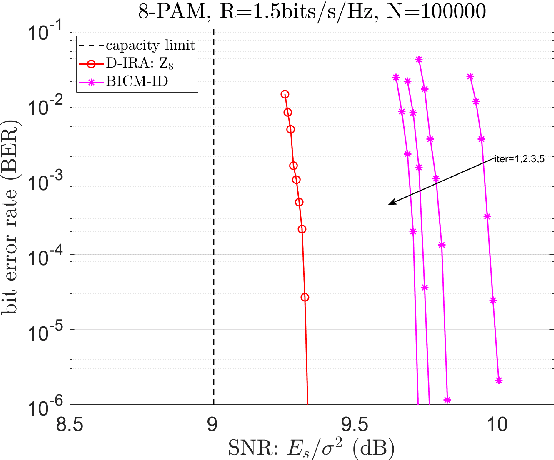
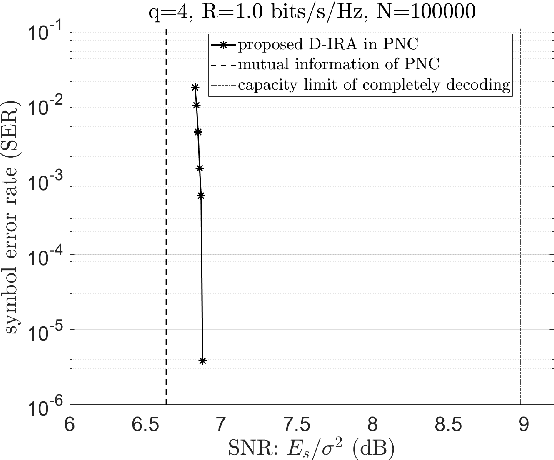
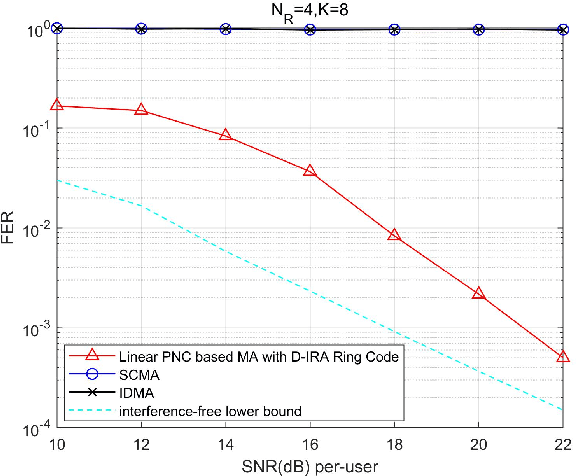
Structured codes based on lattices were shown to provide enlarged capacity for multi-user communication networks. In this paper, we study capacity-approaching irregular repeat accumulate (IRA) codes over integer rings $\mathbb{Z}_{2^{m}}$ for $2^m$-PAM signaling, $m=1,2,\cdots$. Such codes feature the property that the integer sum of $K$ codewords belongs to the extended codebook (or lattice) w.r.t. the base code. With it, \emph{% structured binning} can be utilized and the gains promised in lattice based network information theory can be materialized in practice. In designing IRA ring codes, we first analyze the effect of zero-divisors of integer ring on the iterative belief-propagation (BP) decoding, and show the invalidity of symmetric Gaussian approximation. Then we propose a doubly IRA (D-IRA) ring code structure, consisting of \emph{irregular multiplier distribution} and \emph{irregular node-degree distribution}, that can restore the symmetry and optimize the BP decoding threshold. For point-to-point AWGN channel with $% 2^m $-PAM inputs, D-IRA ring codes perform as low as 0.29 dB to the capacity limits, outperforming existing bit-interleaved coded-modulation (BICM) and IRA modulation codes over GF($2^m$). We then proceed to design D-IRA ring codes for two important multi-user communication setups, namely compute-forward (CF) and dirty paper coding (DPC), with $2^m$-PAM signaling. With it, a physical-layer network coding scheme yields a gap to the CF limit by 0.24 dB, and a simple linear DPC scheme exhibits a gap to the capacity by 0.91 dB.
Centroid Distance Keypoint Detector for Colored Point Clouds
Oct 04, 2022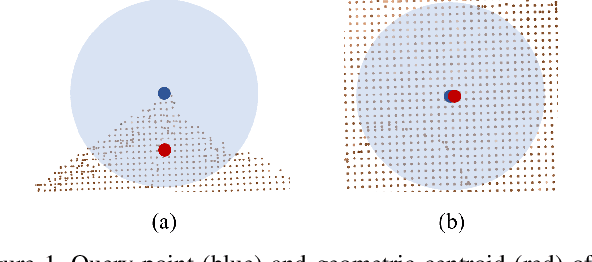
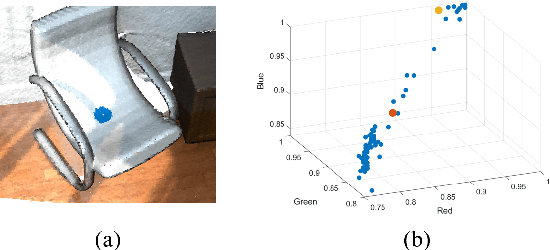
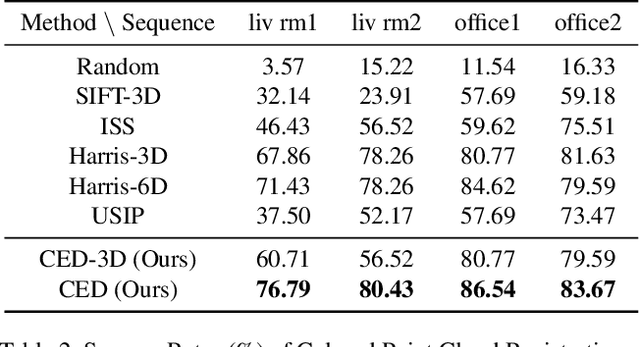
Keypoint detection serves as the basis for many computer vision and robotics applications. Despite the fact that colored point clouds can be readily obtained, most existing keypoint detectors extract only geometry-salient keypoints, which can impede the overall performance of systems that intend to (or have the potential to) leverage color information. To promote advances in such systems, we propose an efficient multi-modal keypoint detector that can extract both geometry-salient and color-salient keypoints in colored point clouds. The proposed CEntroid Distance (CED) keypoint detector comprises an intuitive and effective saliency measure, the centroid distance, that can be used in both 3D space and color space, and a multi-modal non-maximum suppression algorithm that can select keypoints with high saliency in two or more modalities. The proposed saliency measure leverages directly the distribution of points in a local neighborhood and does not require normal estimation or eigenvalue decomposition. We evaluate the proposed method in terms of repeatability and computational efficiency (i.e. running time) against state-of-the-art keypoint detectors on both synthetic and real-world datasets. Results demonstrate that our proposed CED keypoint detector requires minimal computational time while attaining high repeatability. To showcase one of the potential applications of the proposed method, we further investigate the task of colored point cloud registration. Results suggest that our proposed CED detector outperforms state-of-the-art handcrafted and learning-based keypoint detectors in the evaluated scenes. The C++ implementation of the proposed method is made publicly available at https://github.com/UCR-Robotics/CED_Detector.
PIMIP: An Open Source Platform for Pathology Information Management and Integration
Nov 09, 2021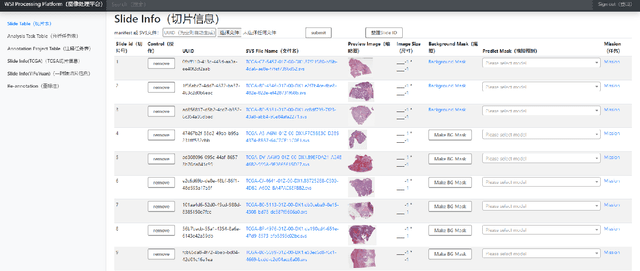
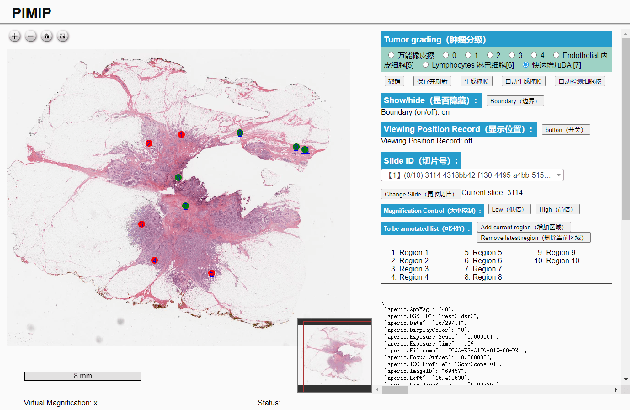
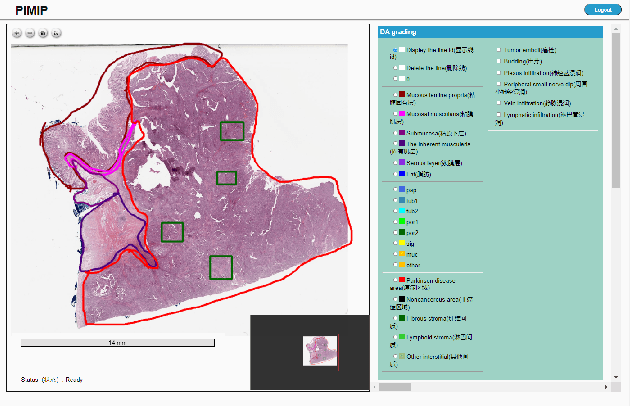
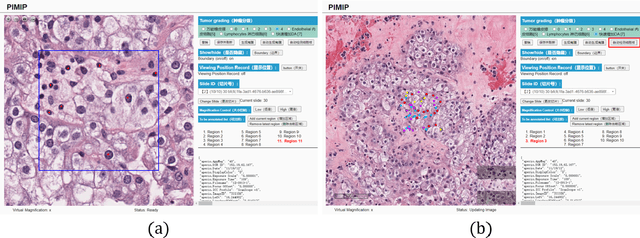
Digital pathology plays a crucial role in the development of artificial intelligence in the medical field. The digital pathology platform can make the pathological resources digital and networked, and realize the permanent storage of visual data and the synchronous browsing processing without the limitation of time and space. It has been widely used in various fields of pathology. However, there is still a lack of an open and universal digital pathology platform to assist doctors in the management and analysis of digital pathological sections, as well as the management and structured description of relevant patient information. Most platforms cannot integrate image viewing, annotation and analysis, and text information management. To solve the above problems, we propose a comprehensive and extensible platform PIMIP. Our PIMIP has developed the image annotation functions based on the visualization of digital pathological sections. Our annotation functions support multi-user collaborative annotation and multi-device annotation, and realize the automation of some annotation tasks. In the annotation task, we invited a professional pathologist for guidance. We introduce a machine learning module for image analysis. The data we collected included public data from local hospitals and clinical examples. Our platform is more clinical and suitable for clinical use. In addition to image data, we also structured the management and display of text information. So our platform is comprehensive. The platform framework is built in a modular way to support users to add machine learning modules independently, which makes our platform extensible.
How to Define the Propagation Environment Semantics and Its Application in Scatterer-Based Beam Prediction
Sep 17, 2022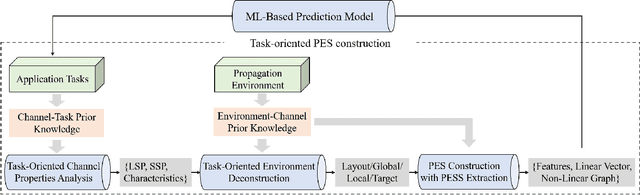
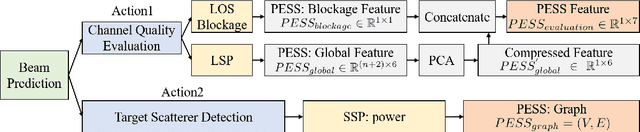
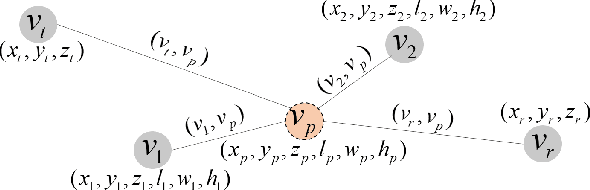
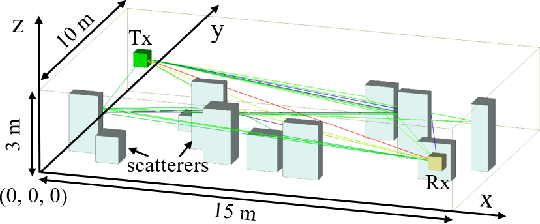
In view of the propagation environment directly determining the channel fading, the application tasks can also be solved with the aid of the environment information. Inspired by task-oriented semantic communication and machine learning (ML) powered environment-channel mapping methods, this work aims to provide a new view of the environment from the semantic level, which defines the propagation environment semantics (PES) as a limited set of propagation environment semantic symbols (PESS) for diverse application tasks. The PESS is extracted oriented to the tasks with channel properties as a foundation. For method validation, the PES-aided beam prediction (PESaBP) is presented in non-line-of-sight (NLOS). The PESS of environment features and graphs are given for the semantic actions of channel quality evaluation and target scatterer detection of maximum power, which can obtain 0.92 and 0.9 precision, respectively, and save over 87% of time cost.
Multi-View Pre-Trained Model for Code Vulnerability Identification
Aug 10, 2022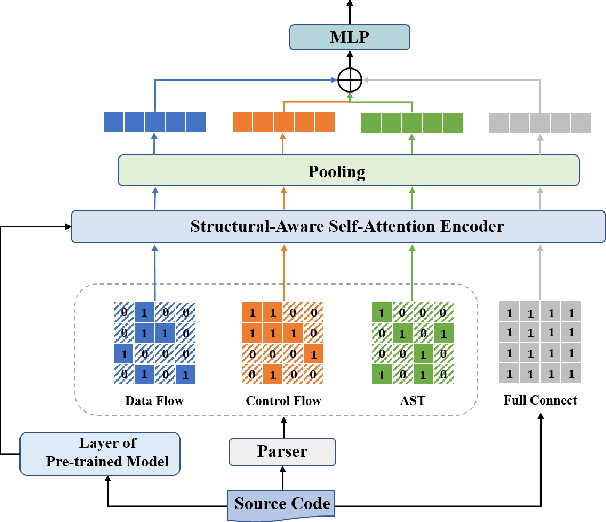
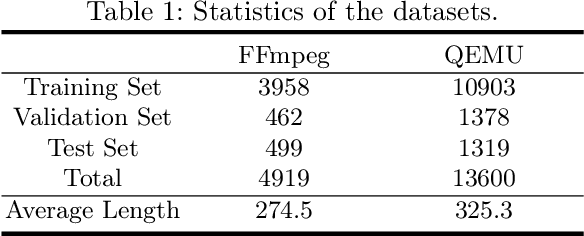
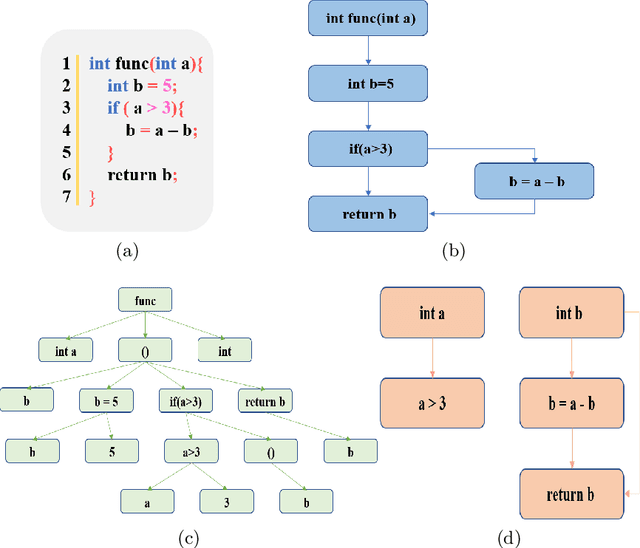
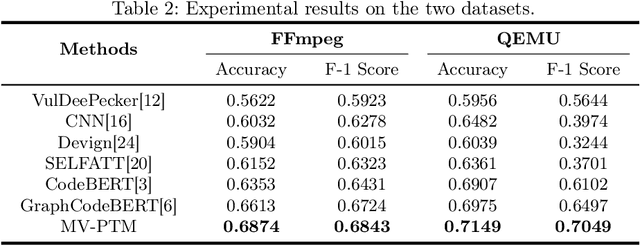
Vulnerability identification is crucial for cyber security in the software-related industry. Early identification methods require significant manual efforts in crafting features or annotating vulnerable code. Although the recent pre-trained models alleviate this issue, they overlook the multiple rich structural information contained in the code itself. In this paper, we propose a novel Multi-View Pre-Trained Model (MV-PTM) that encodes both sequential and multi-type structural information of the source code and uses contrastive learning to enhance code representations. The experiments conducted on two public datasets demonstrate the superiority of MV-PTM. In particular, MV-PTM improves GraphCodeBERT by 3.36\% on average in terms of F1 score.
Learning Parsimonious Dynamics for Generalization in Reinforcement Learning
Sep 29, 2022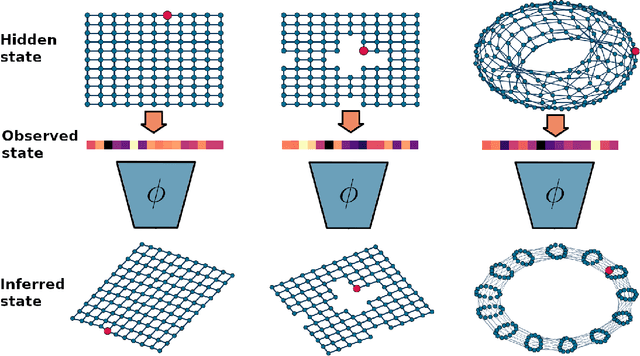
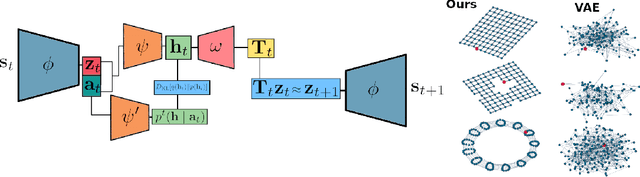
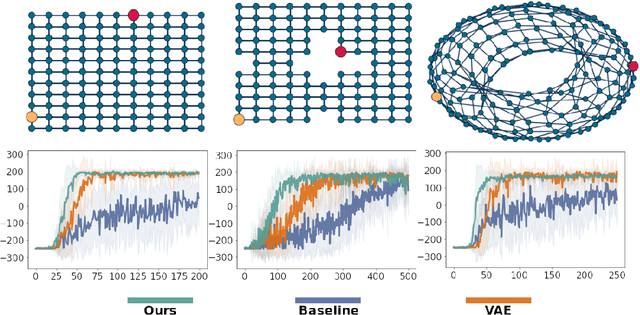
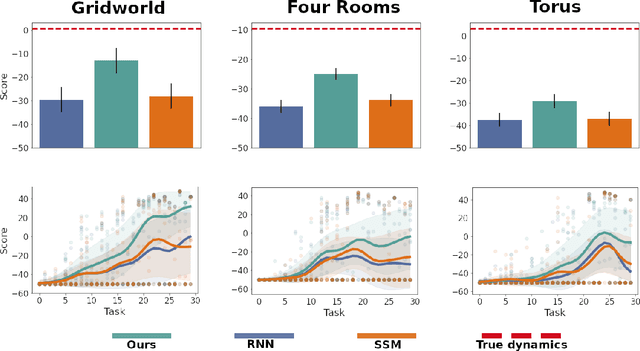
Humans are skillful navigators: We aptly maneuver through new places, realize when we are back at a location we have seen before, and can even conceive of shortcuts that go through parts of our environments we have never visited. Current methods in model-based reinforcement learning on the other hand struggle with generalizing about environment dynamics out of the training distribution. We argue that two principles can help bridge this gap: latent learning and parsimonious dynamics. Humans tend to think about environment dynamics in simple terms -- we reason about trajectories not in reference to what we expect to see along a path, but rather in an abstract latent space, containing information about the places' spatial coordinates. Moreover, we assume that moving around in novel parts of our environment works the same way as in parts we are familiar with. These two principles work together in tandem: it is in the latent space that the dynamics show parsimonious characteristics. We develop a model that learns such parsimonious dynamics. Using a variational objective, our model is trained to reconstruct experienced transitions in a latent space using locally linear transformations, while encouraged to invoke as few distinct transformations as possible. Using our framework, we demonstrate the utility of learning parsimonious latent dynamics models in a range of policy learning and planning tasks.