 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
An Effective System for Multi-format Information Extraction
Aug 16, 2021
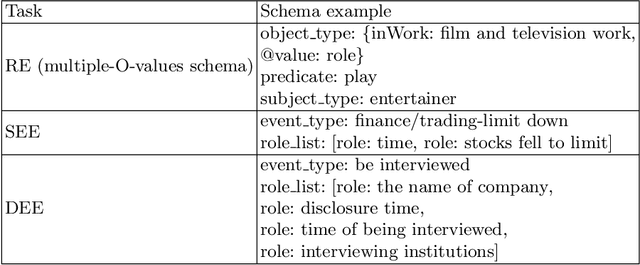
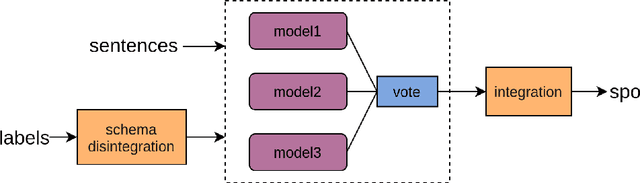
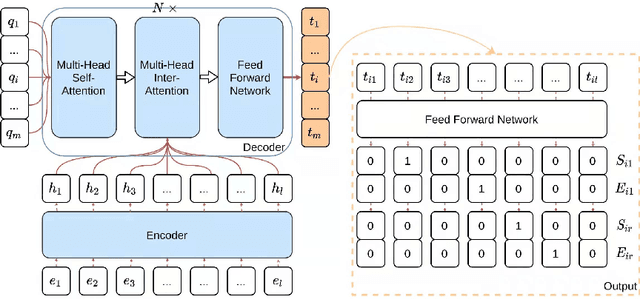

The multi-format information extraction task in the 2021 Language and Intelligence Challenge is designed to comprehensively evaluate information extraction from different dimensions. It consists of an multiple slots relation extraction subtask and two event extraction subtasks that extract events from both sentence-level and document-level. Here we describe our system for this multi-format information extraction competition task. Specifically, for the relation extraction subtask, we convert it to a traditional triple extraction task and design a voting based method that makes full use of existing models. For the sentence-level event extraction subtask, we convert it to a NER task and use a pointer labeling based method for extraction. Furthermore, considering the annotated trigger information may be helpful for event extraction, we design an auxiliary trigger recognition model and use the multi-task learning mechanism to integrate the trigger features into the event extraction model. For the document-level event extraction subtask, we design an Encoder-Decoder based method and propose a Transformer-alike decoder. Finally,our system ranks No.4 on the test set leader-board of this multi-format information extraction task, and its F1 scores for the subtasks of relation extraction, event extractions of sentence-level and document-level are 79.887%, 85.179%, and 70.828% respectively. The codes of our model are available at {https://github.com/neukg/MultiIE}.
Attention Distillation: self-supervised vision transformer students need more guidance
Oct 03, 2022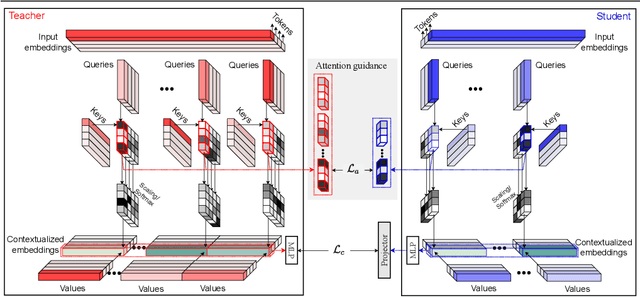
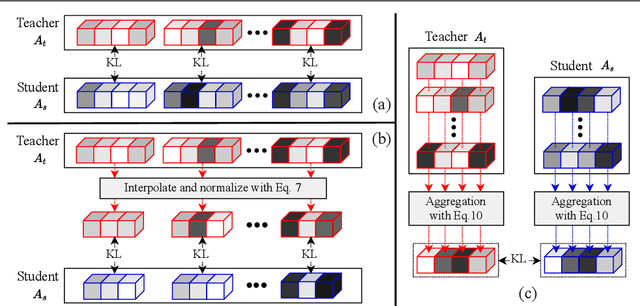
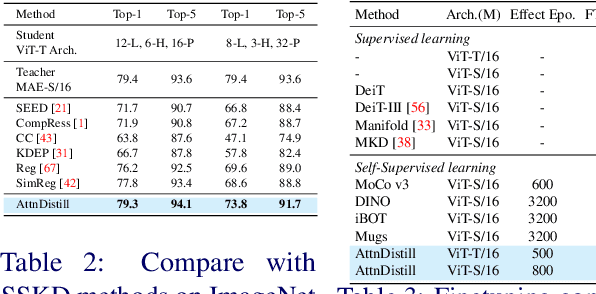
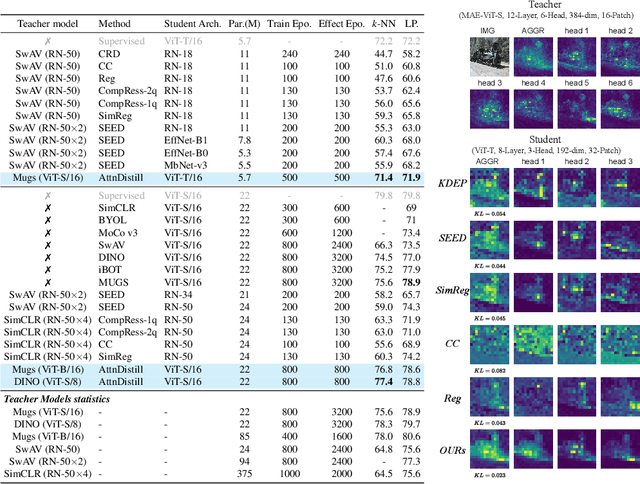
Self-supervised learning has been widely applied to train high-quality vision transformers. Unleashing their excellent performance on memory and compute constraint devices is therefore an important research topic. However, how to distill knowledge from one self-supervised ViT to another has not yet been explored. Moreover, the existing self-supervised knowledge distillation (SSKD) methods focus on ConvNet based architectures are suboptimal for ViT knowledge distillation. In this paper, we study knowledge distillation of self-supervised vision transformers (ViT-SSKD). We show that directly distilling information from the crucial attention mechanism from teacher to student can significantly narrow the performance gap between both. In experiments on ImageNet-Subset and ImageNet-1K, we show that our method AttnDistill outperforms existing self-supervised knowledge distillation (SSKD) methods and achieves state-of-the-art k-NN accuracy compared with self-supervised learning (SSL) methods learning from scratch (with the ViT-S model). We are also the first to apply the tiny ViT-T model on self-supervised learning. Moreover, AttnDistill is independent of self-supervised learning algorithms, it can be adapted to ViT based SSL methods to improve the performance in future research. The code is here: https://github.com/wangkai930418/attndistill
Efficient Bayes Inference in Neural Networks through Adaptive Importance Sampling
Oct 03, 2022

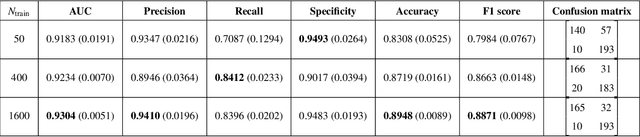
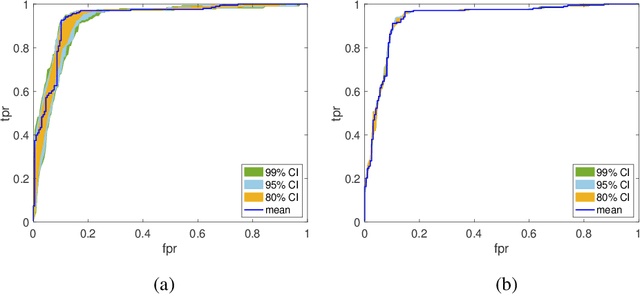
Bayesian neural networks (BNNs) have received an increased interest in the last years. In BNNs, a complete posterior distribution of the unknown weight and bias parameters of the network is produced during the training stage. This probabilistic estimation offers several advantages with respect to point-wise estimates, in particular, the ability to provide uncertainty quantification when predicting new data. This feature inherent to the Bayesian paradigm, is useful in countless machine learning applications. It is particularly appealing in areas where decision-making has a crucial impact, such as medical healthcare or autonomous driving. The main challenge of BNNs is the computational cost of the training procedure since Bayesian techniques often face a severe curse of dimensionality. Adaptive importance sampling (AIS) is one of the most prominent Monte Carlo methodologies benefiting from sounded convergence guarantees and ease for adaptation. This work aims to show that AIS constitutes a successful approach for designing BNNs. More precisely, we propose a novel algorithm PMCnet that includes an efficient adaptation mechanism, exploiting geometric information on the complex (often multimodal) posterior distribution. Numerical results illustrate the excellent performance and the improved exploration capabilities of the proposed method for both shallow and deep neural networks.
MEGCF: Multimodal Entity Graph Collaborative Filtering for Personalized Recommendation
Oct 14, 2022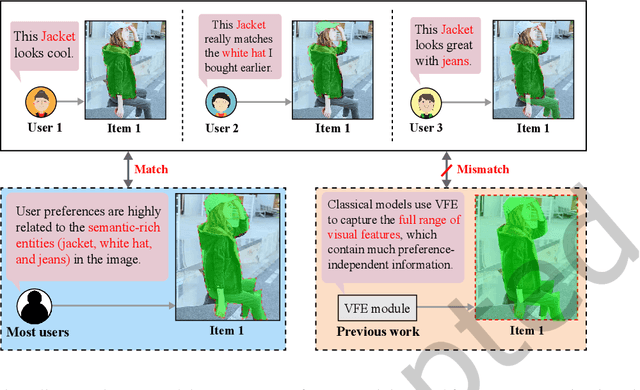
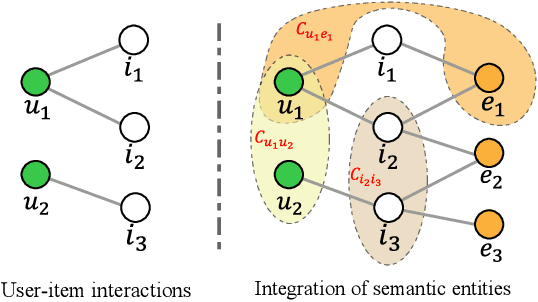
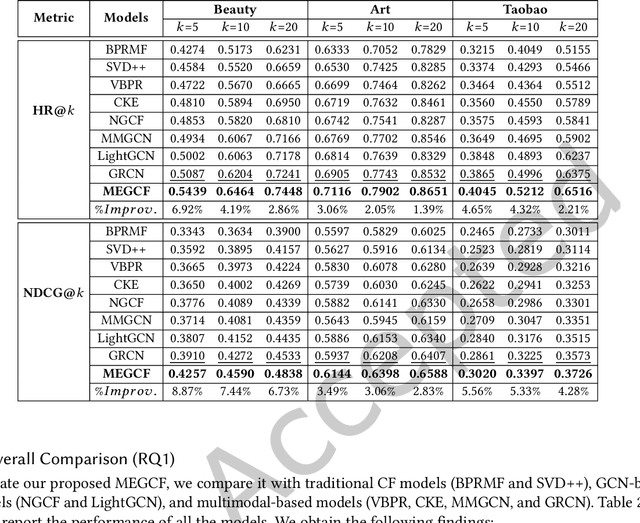
In most E-commerce platforms, whether the displayed items trigger the user's interest largely depends on their most eye-catching multimodal content. Consequently, increasing efforts focus on modeling multimodal user preference, and the pressing paradigm is to incorporate complete multimodal deep features of the items into the recommendation module. However, the existing studies ignore the mismatch problem between multimodal feature extraction (MFE) and user interest modeling (UIM). That is, MFE and UIM have different emphases. Specifically, MFE is migrated from and adapted to upstream tasks such as image classification. In addition, it is mainly a content-oriented and non-personalized process, while UIM, with its greater focus on understanding user interaction, is essentially a user-oriented and personalized process. Therefore, the direct incorporation of MFE into UIM for purely user-oriented tasks, tends to introduce a large number of preference-independent multimodal noise and contaminate the embedding representations in UIM. This paper aims at solving the mismatch problem between MFE and UIM, so as to generate high-quality embedding representations and better model multimodal user preferences. Towards this end, we develop a novel model, MEGCF. The UIM of the proposed model captures the semantic correlation between interactions and the features obtained from MFE, thus making a better match between MFE and UIM. More precisely, semantic-rich entities are first extracted from the multimodal data, since they are more relevant to user preferences than other multimodal information. These entities are then integrated into the user-item interaction graph. Afterwards, a symmetric linear Graph Convolution Network (GCN) module is constructed to perform message propagation over the graph, in order to capture both high-order semantic correlation and collaborative filtering signals.
KeypartX: Graph-based Perception (Text) Representation
Sep 23, 2022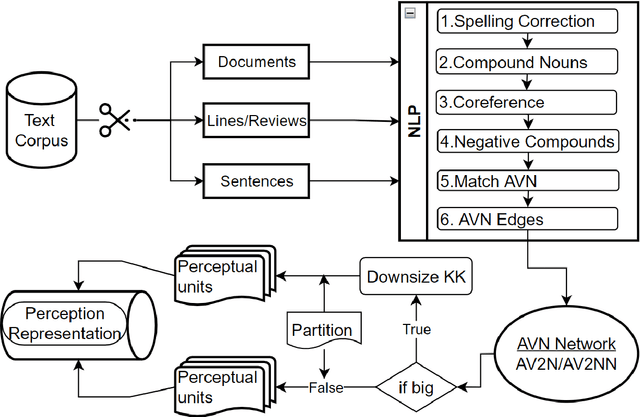

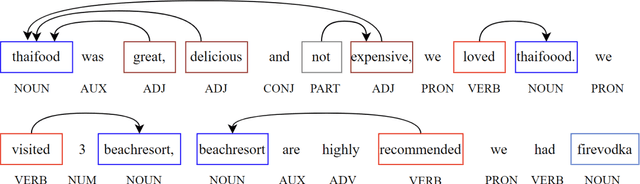
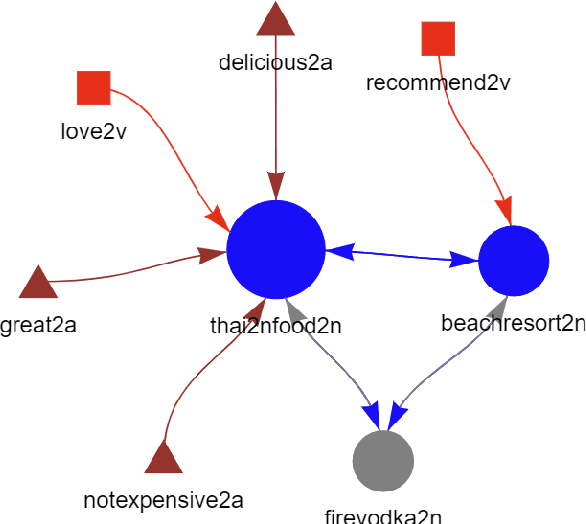
The availability of big data has opened up big opportunities for individuals, businesses and academics to view big into what is happening in their world. Previous works of text representation mostly focused on informativeness from massive words' frequency or cooccurrence. However, big data is a double-edged sword which is big in volume but unstructured in format. The unstructured edge requires specific techniques to transform 'big' into meaningful instead of informative alone. This study presents KeypartX, a graph-based approach to represent perception (text in general) by key parts of speech. Different from bag-of-words/vector-based machine learning, this technique is human-like learning that could extracts meanings from linguistic (semantic, syntactic and pragmatic) information. Moreover, KeypartX is big-data capable but not hungry, which is even applicable to the minimum unit of text:sentence.
Category-orthogonal object features guide information processing in recurrent neural networks trained for object categorization
Nov 15, 2021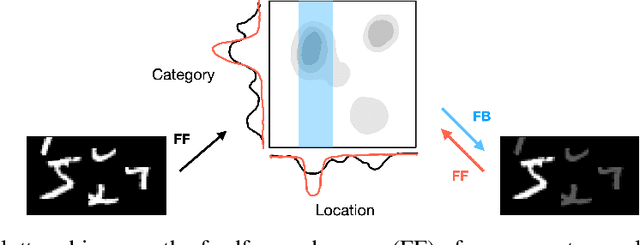
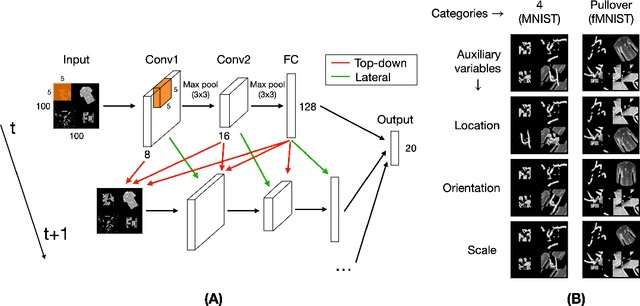
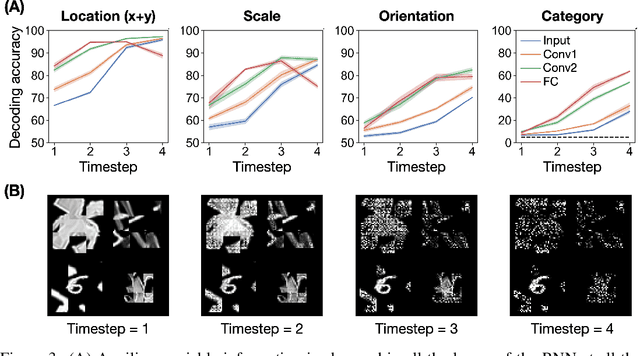
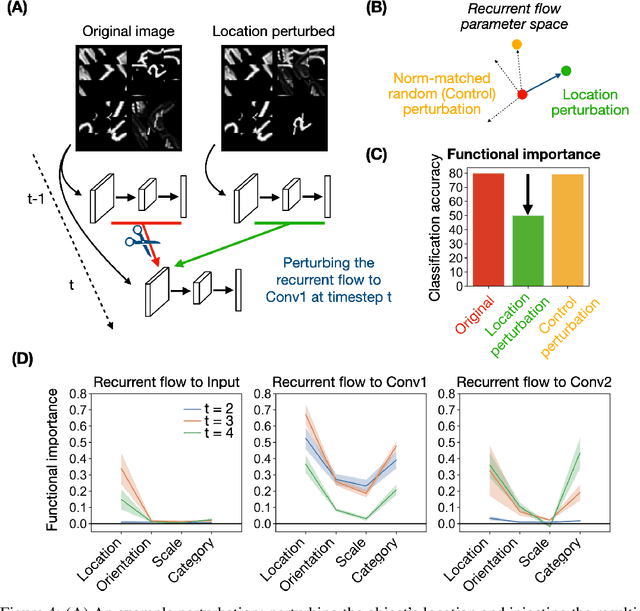
Recurrent neural networks (RNNs) have been shown to perform better than feedforward architectures in visual object categorization tasks, especially in challenging conditions such as cluttered images. However, little is known about the exact computational role of recurrent information flow in these conditions. Here we test RNNs trained for object categorization on the hypothesis that recurrence iteratively aids object categorization via the communication of category-orthogonal auxiliary variables (the location, orientation, and scale of the object). Using diagnostic linear readouts, we find that: (a) information about auxiliary variables increases across time in all network layers, (b) this information is indeed present in the recurrent information flow, and (c) its manipulation significantly affects task performance. These observations confirm the hypothesis that category-orthogonal auxiliary variable information is conveyed through recurrent connectivity and is used to optimize category inference in cluttered environments.
DDoS: A Graph Neural Network based Drug Synergy Prediction Algorithm
Oct 10, 2022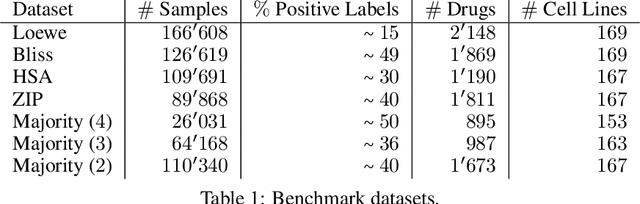
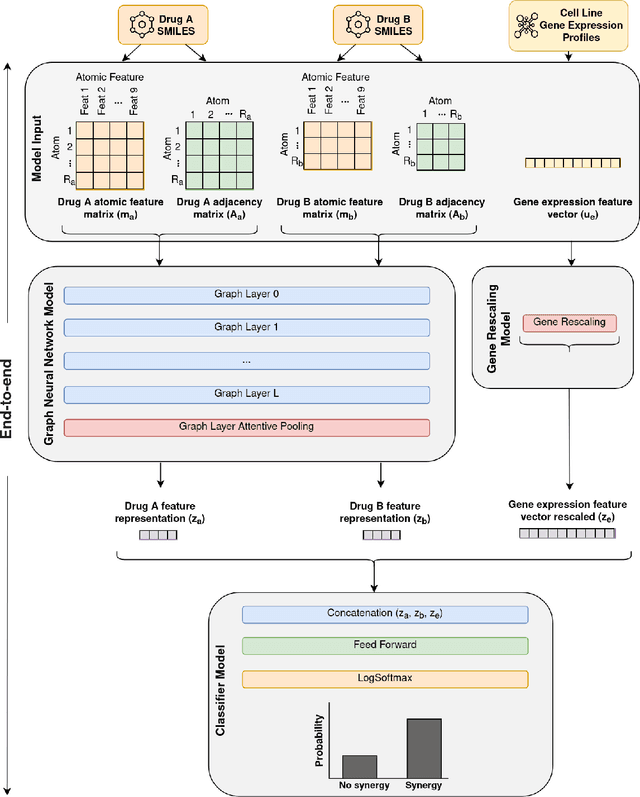
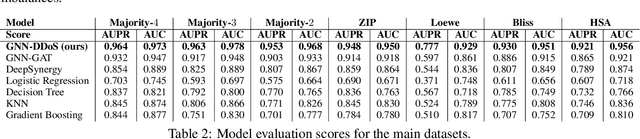
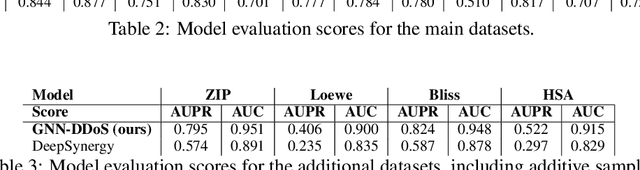
Background: Drug synergy occurs when the combined effect of two drugs is greater than the sum of the individual drugs' effect. While cell line data measuring the effect of single drugs are readily available, there is relatively less comparable data on drug synergy given the vast amount of possible drug combinations. Thus, there is interest to use computational approaches to predict drug synergy for untested pairs of drugs. Methods: We introduce a Graph Neural Network (GNN) based model for drug synergy prediction, which utilizes drug chemical structures and cell line gene expression data. We use information from the largest drug combination database available (DrugComb), combining drug synergy scores in order to construct high confidence benchmark datasets. Results: Our proposed solution for drug synergy predictions offers a number of benefits: 1) It utilizes a combination of 34 distinct drug synergy datasets to learn on a wide variety of drugs and cell lines representations. 2) It is trained on constructed high confidence benchmark datasets. 3) It learns task-specific drug representations, instead of relying on generalized and pre-computed chemical drug features. 4) It achieves similar or better prediction performance (AUPR scores ranging from 0.777 to 0.964) compared to state-of-the-art baseline models when tested on various benchmark datasets. Conclusions: We demonstrate that a GNN based model can provide state-of-the-art drug synergy predictions by learning task-specific representations of drugs.
Graph2Vid: Flow graph to Video Grounding forWeakly-supervised Multi-Step Localization
Oct 10, 2022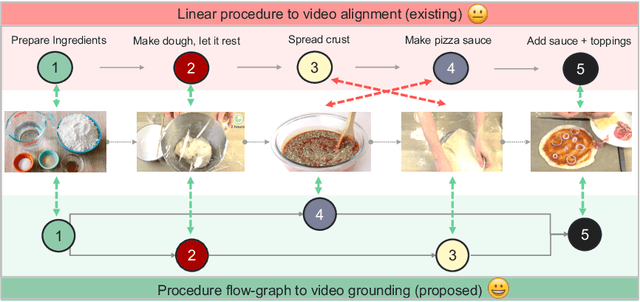
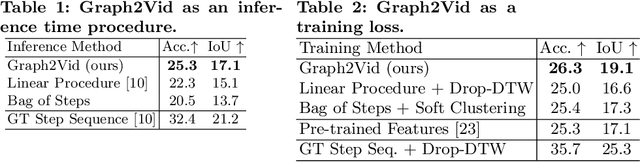

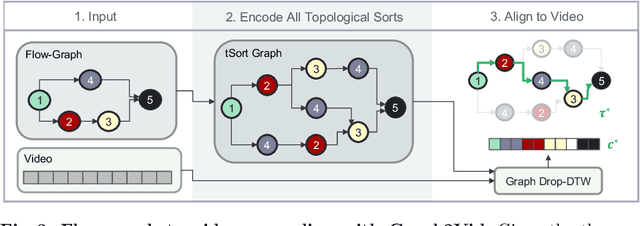
In this work, we consider the problem of weakly-supervised multi-step localization in instructional videos. An established approach to this problem is to rely on a given list of steps. However, in reality, there is often more than one way to execute a procedure successfully, by following the set of steps in slightly varying orders. Thus, for successful localization in a given video, recent works require the actual order of procedure steps in the video, to be provided by human annotators at both training and test times. Instead, here, we only rely on generic procedural text that is not tied to a specific video. We represent the various ways to complete the procedure by transforming the list of instructions into a procedure flow graph which captures the partial order of steps. Using the flow graphs reduces both training and test time annotation requirements. To this end, we introduce the new problem of flow graph to video grounding. In this setup, we seek the optimal step ordering consistent with the procedure flow graph and a given video. To solve this problem, we propose a new algorithm - Graph2Vid - that infers the actual ordering of steps in the video and simultaneously localizes them. To show the advantage of our proposed formulation, we extend the CrossTask dataset with procedure flow graph information. Our experiments show that Graph2Vid is both more efficient than the baselines and yields strong step localization results, without the need for step order annotation.
* ECCV'22, oral
Stock Volatility Prediction using Time Series and Deep Learning Approach
Oct 05, 2022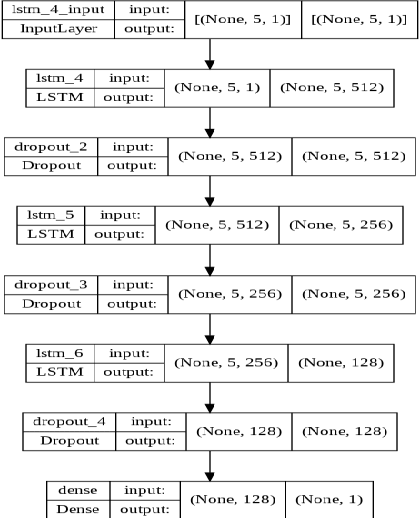
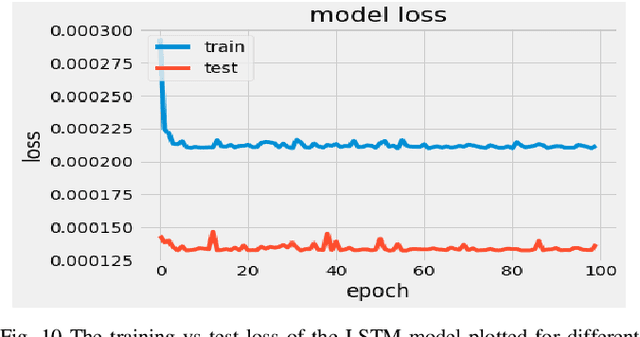
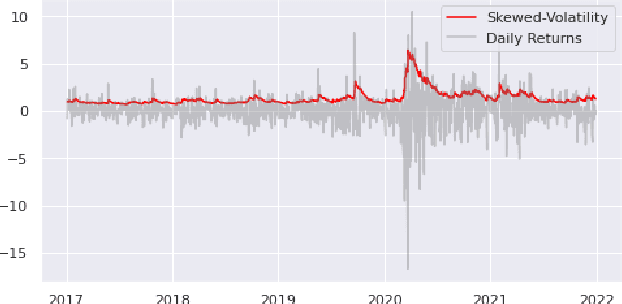
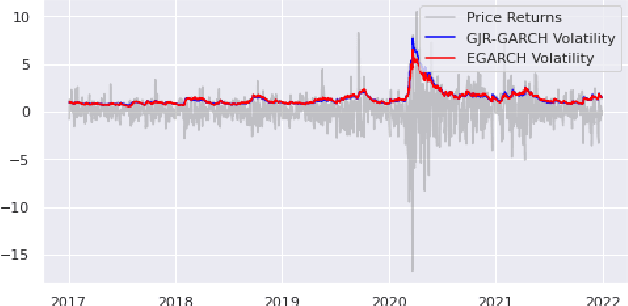
Volatility clustering is a crucial property that has a substantial impact on stock market patterns. Nonetheless, developing robust models for accurately predicting future stock price volatility is a difficult research topic. For predicting the volatility of three equities listed on India's national stock market (NSE), we propose multiple volatility models depending on the generalized autoregressive conditional heteroscedasticity (GARCH), Glosten-Jagannathan-GARCH (GJR-GARCH), Exponential general autoregressive conditional heteroskedastic (EGARCH), and LSTM framework. Sector-wise stocks have been chosen in our study. The sectors which have been considered are banking, information technology (IT), and pharma. yahoo finance has been used to obtain stock price data from Jan 2017 to Dec 2021. Among the pulled-out records, the data from Jan 2017 to Dec 2020 have been taken for training, and data from 2021 have been chosen for testing our models. The performance of predicting the volatility of stocks of three sectors has been evaluated by implementing three different types of GARCH models as well as by the LSTM model are compared. It has been observed the LSTM performed better in predicting volatility in pharma over banking and IT sectors. In tandem, it was also observed that E-GARCH performed better in the case of the banking sector and for IT and pharma, GJR-GARCH performed better.
Exploiting Temporal Side Information in Massive IoT Connectivity
Jan 05, 2022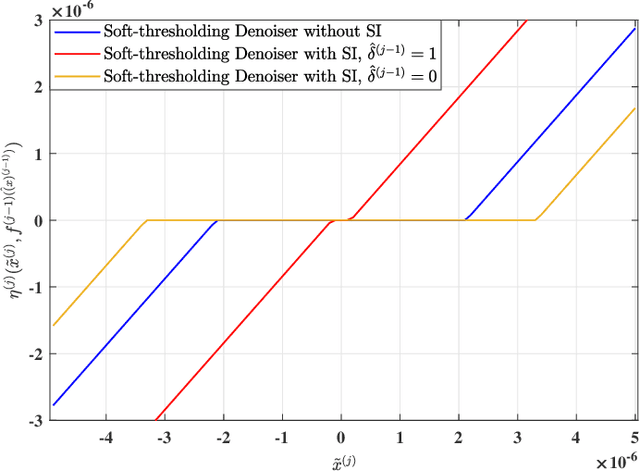
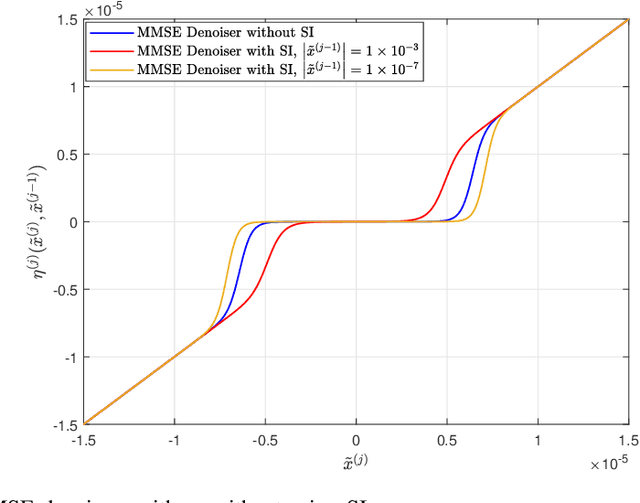
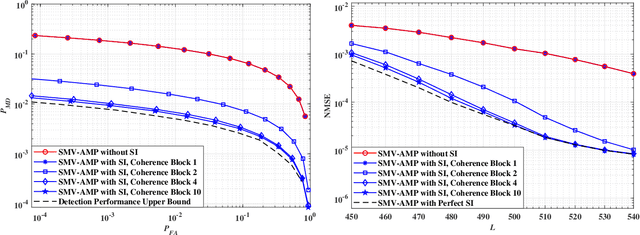
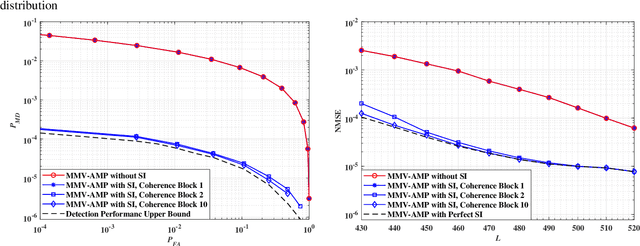
This paper considers the joint device activity detection and channel estimation problem in a massive Internet of Things (IoT) connectivity system, where a large number of IoT devices exist but merely a random subset of them become active for short-packet transmission in each coherence block. In particular, we propose to leverage the temporal correlation in device activity, e.g., a device active in the previous coherence block is more likely to be still active in the current coherence block, to improve the detection and estimation performance. However, it is challenging to utilize this temporal correlation as side information (SI), which relies on the knowledge about the exact statistical relation between the estimated activity pattern for the previous coherence block (which may be imperfect with unknown error) and the true activity pattern in the current coherence block. To tackle this challenge, we establish a novel SI-aided multiple measurement vector approximate message passing (MMV-AMP) framework. Specifically, thanks to the state evolution of the MMV-AMP algorithm, the correlation between the activity pattern estimated by the MMV-AMP algorithm in the previous coherence block and the real activity pattern in the current coherence block is quantified explicitly. Based on the well-defined temporal correlation, we further manage to embed this useful SI into the denoiser design under the MMV-AMP framework. Specifically, the SI-based soft-thresholding denoisers with binary thresholds and the SI-based minimum mean-squared error (MMSE) denoisers are characterized for the cases without and with the knowledge of the channel distribution, respectively. Numerical results are given to show the significant gain in device activity detection and channel estimation performance brought by our proposed SI-aided MMV-AMP framework.