 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
PlanGPT: Enhancing Urban Planning with Tailored Language Model and Efficient Retrieval
Feb 29, 2024
In the field of urban planning, general-purpose large language models often struggle to meet the specific needs of planners. Tasks like generating urban planning texts, retrieving related information, and evaluating planning documents pose unique challenges. To enhance the efficiency of urban professionals and overcome these obstacles, we introduce PlanGPT, the first specialized Large Language Model tailored for urban and spatial planning. Developed through collaborative efforts with institutions like the Chinese Academy of Urban Planning, PlanGPT leverages a customized local database retrieval framework, domain-specific fine-tuning of base models, and advanced tooling capabilities. Empirical tests demonstrate that PlanGPT has achieved advanced performance, delivering responses of superior quality precisely tailored to the intricacies of urban planning.
Learning to Manipulate under Limited Information
Jan 29, 2024By classic results in social choice theory, any reasonable preferential voting method sometimes gives individuals an incentive to report an insincere preference. The extent to which different voting methods are more or less resistant to such strategic manipulation has become a key consideration for comparing voting methods. Here we measure resistance to manipulation by whether neural networks of varying sizes can learn to profitably manipulate a given voting method in expectation, given different types of limited information about how other voters will vote. We trained nearly 40,000 neural networks of 26 sizes to manipulate against 8 different voting methods, under 6 types of limited information, in committee-sized elections with 5-21 voters and 3-6 candidates. We find that some voting methods, such as Borda, are highly manipulable by networks with limited information, while others, such as Instant Runoff, are not, despite being quite profitably manipulated by an ideal manipulator with full information.
Information-Theoretic Thresholds for Planted Dense Cycles
Feb 01, 2024We study a random graph model for small-world networks which are ubiquitous in social and biological sciences. In this model, a dense cycle of expected bandwidth $n \tau$, representing the hidden one-dimensional geometry of vertices, is planted in an ambient random graph on $n$ vertices. For both detection and recovery of the planted dense cycle, we characterize the information-theoretic thresholds in terms of $n$, $\tau$, and an edge-wise signal-to-noise ratio $\lambda$. In particular, the information-theoretic thresholds differ from the computational thresholds established in a recent work for low-degree polynomial algorithms, thereby justifying the existence of statistical-to-computational gaps for this problem.
ELA: Efficient Local Attention for Deep Convolutional Neural Networks
Mar 02, 2024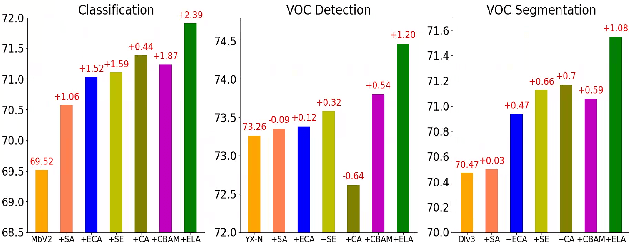

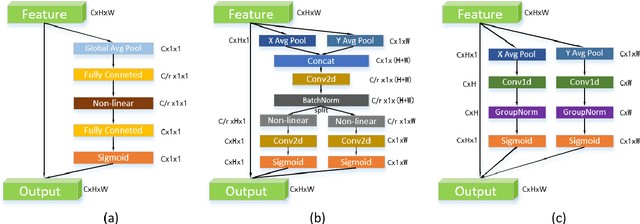
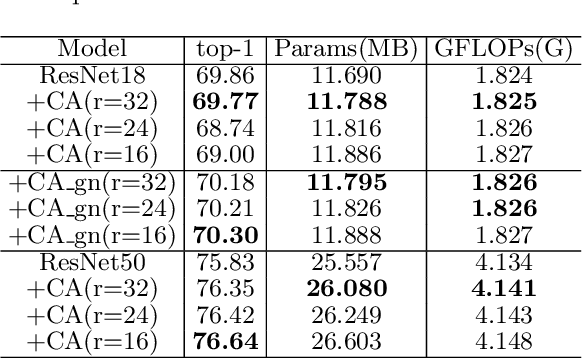
The attention mechanism has gained significant recognition in the field of computer vision due to its ability to effectively enhance the performance of deep neural networks. However, existing methods often struggle to effectively utilize spatial information or, if they do, they come at the cost of reducing channel dimensions or increasing the complexity of neural networks. In order to address these limitations, this paper introduces an Efficient Local Attention (ELA) method that achieves substantial performance improvements with a simple structure. By analyzing the limitations of the Coordinate Attention method, we identify the lack of generalization ability in Batch Normalization, the adverse effects of dimension reduction on channel attention, and the complexity of attention generation process. To overcome these challenges, we propose the incorporation of 1D convolution and Group Normalization feature enhancement techniques. This approach enables accurate localization of regions of interest by efficiently encoding two 1D positional feature maps without the need for dimension reduction, while allowing for a lightweight implementation. We carefully design three hyperparameters in ELA, resulting in four different versions: ELA-T, ELA-B, ELA-S, and ELA-L, to cater to the specific requirements of different visual tasks such as image classification, object detection and sementic segmentation. ELA can be seamlessly integrated into deep CNN networks such as ResNet, MobileNet, and DeepLab. Extensive evaluations on the ImageNet, MSCOCO, and Pascal VOC datasets demonstrate the superiority of the proposed ELA module over current state-of-the-art methods in all three aforementioned visual tasks.
Region-Aware Exposure Consistency Network for Mixed Exposure Correction
Feb 28, 2024Exposure correction aims to enhance images suffering from improper exposure to achieve satisfactory visual effects. Despite recent progress, existing methods generally mitigate either overexposure or underexposure in input images, and they still struggle to handle images with mixed exposure, i.e., one image incorporates both overexposed and underexposed regions. The mixed exposure distribution is non-uniform and leads to varying representation, which makes it challenging to address in a unified process. In this paper, we introduce an effective Region-aware Exposure Correction Network (RECNet) that can handle mixed exposure by adaptively learning and bridging different regional exposure representations. Specifically, to address the challenge posed by mixed exposure disparities, we develop a region-aware de-exposure module that effectively translates regional features of mixed exposure scenarios into an exposure-invariant feature space. Simultaneously, as de-exposure operation inevitably reduces discriminative information, we introduce a mixed-scale restoration unit that integrates exposure-invariant features and unprocessed features to recover local information. To further achieve a uniform exposure distribution in the global image, we propose an exposure contrastive regularization strategy under the constraints of intra-regional exposure consistency and inter-regional exposure continuity. Extensive experiments are conducted on various datasets, and the experimental results demonstrate the superiority and generalization of our proposed method. The code is released at: https://github.com/kravrolens/RECNet.
Benchmarking LLMs on the Semantic Overlap Summarization Task
Feb 26, 2024Semantic Overlap Summarization (SOS) is a constrained multi-document summarization task, where the constraint is to capture the common/overlapping information between two alternative narratives. While recent advancements in Large Language Models (LLMs) have achieved superior performance in numerous summarization tasks, a benchmarking study of the SOS task using LLMs is yet to be performed. As LLMs' responses are sensitive to slight variations in prompt design, a major challenge in conducting such a benchmarking study is to systematically explore a variety of prompts before drawing a reliable conclusion. Fortunately, very recently, the TELeR taxonomy has been proposed which can be used to design and explore various prompts for LLMs. Using this TELeR taxonomy and 15 popular LLMs, this paper comprehensively evaluates LLMs on the SOS Task, assessing their ability to summarize overlapping information from multiple alternative narratives. For evaluation, we report well-established metrics like ROUGE, BERTscore, and SEM-F1$ on two different datasets of alternative narratives. We conclude the paper by analyzing the strengths and limitations of various LLMs in terms of their capabilities in capturing overlapping information The code and datasets used to conduct this study are available at https://anonymous.4open.science/r/llm_eval-E16D.
Prompting Explicit and Implicit Knowledge for Multi-hop Question Answering Based on Human Reading Process
Mar 01, 2024Pre-trained language models (PLMs) leverage chains-of-thought (CoT) to simulate human reasoning and inference processes, achieving proficient performance in multi-hop QA. However, a gap persists between PLMs' reasoning abilities and those of humans when tackling complex problems. Psychological studies suggest a vital connection between explicit information in passages and human prior knowledge during reading. Nevertheless, current research has given insufficient attention to linking input passages and PLMs' pre-training-based knowledge from the perspective of human cognition studies. In this study, we introduce a Prompting Explicit and Implicit knowledge (PEI) framework, which uses prompts to connect explicit and implicit knowledge, aligning with human reading process for multi-hop QA. We consider the input passages as explicit knowledge, employing them to elicit implicit knowledge through unified prompt reasoning. Furthermore, our model incorporates type-specific reasoning via prompts, a form of implicit knowledge. Experimental results show that PEI performs comparably to the state-of-the-art on HotpotQA. Ablation studies confirm the efficacy of our model in bridging and integrating explicit and implicit knowledge.
A Survey of Route Recommendations: Methods, Applications, and Opportunities
Mar 01, 2024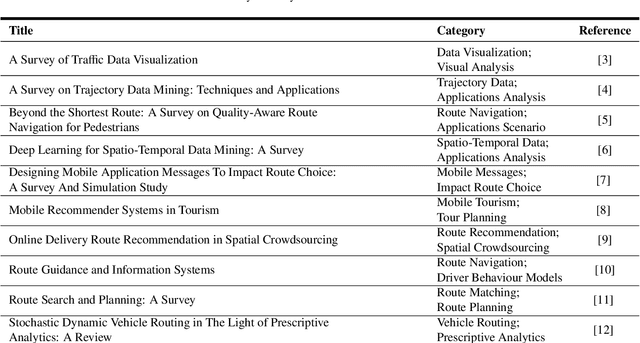
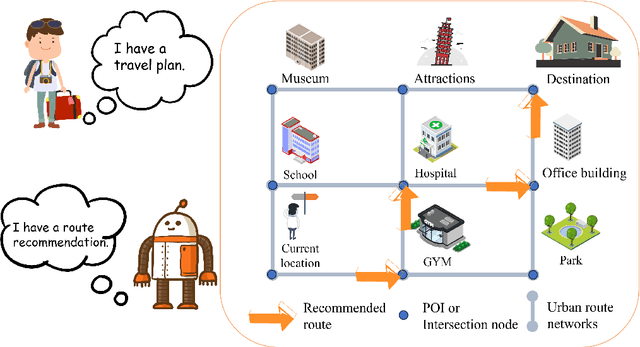
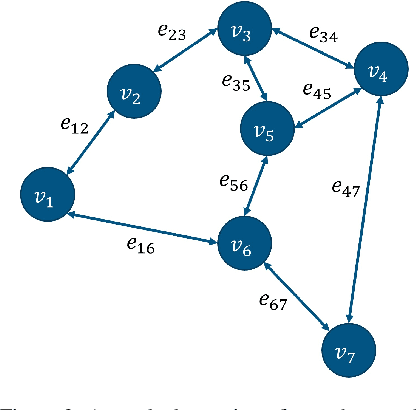
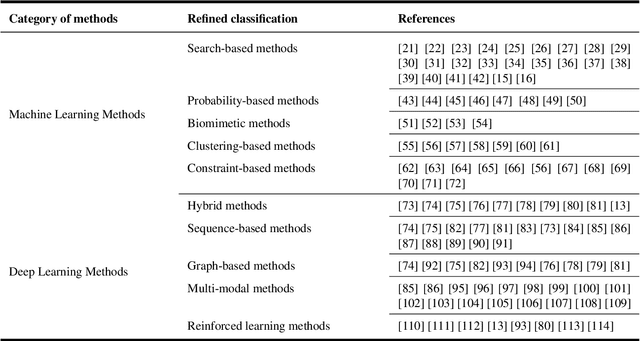
Nowadays, with advanced information technologies deployed citywide, large data volumes and powerful computational resources are intelligentizing modern city development. As an important part of intelligent transportation, route recommendation and its applications are widely used, directly influencing citizens` travel habits. Developing smart and efficient travel routes based on big data (possibly multi-modal) has become a central challenge in route recommendation research. Our survey offers a comprehensive review of route recommendation work based on urban computing. It is organized by the following three parts: 1) Methodology-wise. We categorize a large volume of traditional machine learning and modern deep learning methods. Also, we discuss their historical relations and reveal the edge-cutting progress. 2) Application\-wise. We present numerous novel applications related to route commendation within urban computing scenarios. 3) We discuss current problems and challenges and envision several promising research directions. We believe that this survey can help relevant researchers quickly familiarize themselves with the current state of route recommendation research and then direct them to future research trends.
YOLO-MED : Multi-Task Interaction Network for Biomedical Images
Mar 01, 2024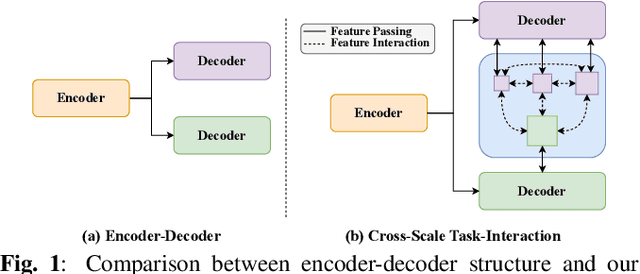
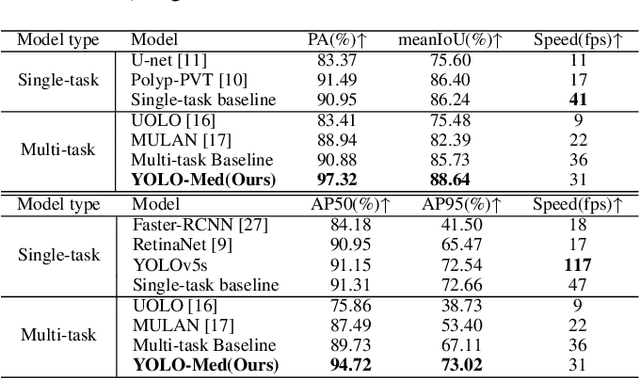
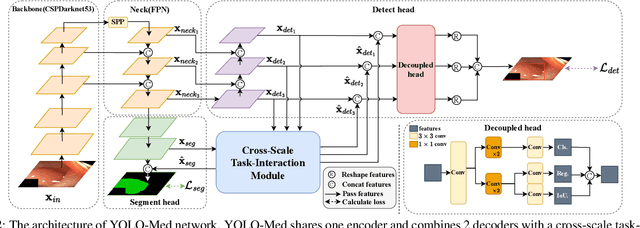
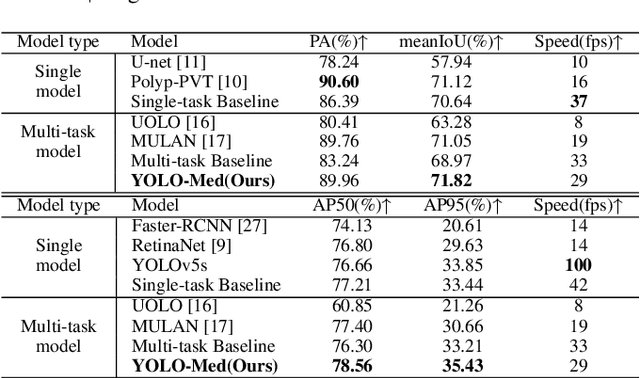
Object detection and semantic segmentation are pivotal components in biomedical image analysis. Current single-task networks exhibit promising outcomes in both detection and segmentation tasks. Multi-task networks have gained prominence due to their capability to simultaneously tackle segmentation and detection tasks, while also accelerating the segmentation inference. Nevertheless, recent multi-task networks confront distinct limitations such as the difficulty in striking a balance between accuracy and inference speed. Additionally, they often overlook the integration of cross-scale features, which is especially important for biomedical image analysis. In this study, we propose an efficient end-to-end multi-task network capable of concurrently performing object detection and semantic segmentation called YOLO-Med. Our model employs a backbone and a neck for multi-scale feature extraction, complemented by the inclusion of two task-specific decoders. A cross-scale task-interaction module is employed in order to facilitate information fusion between various tasks. Our model exhibits promising results in balancing accuracy and speed when evaluated on the Kvasir-seg dataset and a private biomedical image dataset.
Invariant Test-Time Adaptation for Vision-Language Model Generalization
Mar 01, 2024
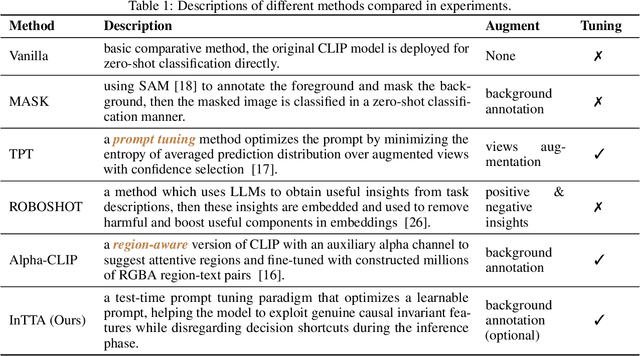

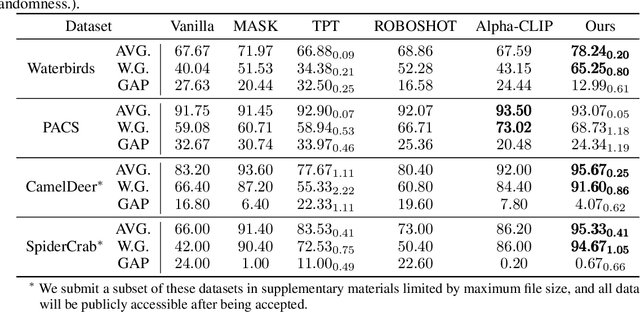
Vision-language foundation models have exhibited remarkable success across a multitude of downstream tasks due to their scalability on extensive image-text paired datasets. However, these models display significant limitations when applied to long-tail tasks, such as fine-grained image classification, as a result of "decision shortcuts" that hinders their generalization capabilities. In this work, we find that the CLIP model possesses a rich set of features, encompassing both \textit{desired invariant causal features} and \textit{undesired decision shortcuts}. Moreover, the underperformance of CLIP on downstream tasks originates from its inability to effectively utilize pre-trained features in accordance with specific task requirements. To address this challenge, this paper introduces a test-time prompt tuning paradigm that optimizes a learnable prompt, thereby compelling the model to exploit genuine causal invariant features while disregarding decision shortcuts during the inference phase. The proposed method effectively alleviates excessive dependence on potentially misleading, task-irrelevant contextual information, while concurrently emphasizing critical, task-related visual cues. We conduct comparative analysis of the proposed method against various approaches which validates its effectiveness.