 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Relational Self-Supervised Learning on Graphs
Aug 21, 2022
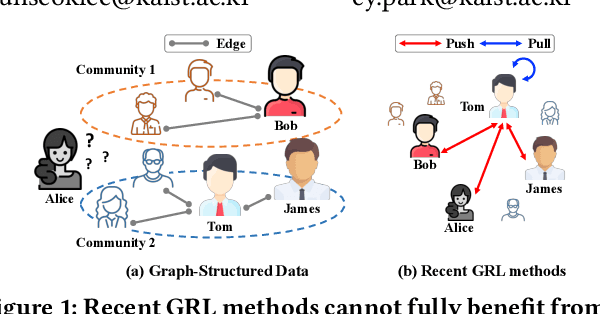

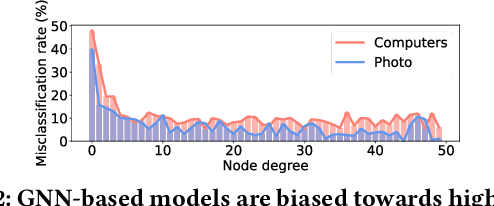
Over the past few years, graph representation learning (GRL) has been a powerful strategy for analyzing graph-structured data. Recently, GRL methods have shown promising results by adopting self-supervised learning methods developed for learning representations of images. Despite their success, existing GRL methods tend to overlook an inherent distinction between images and graphs, i.e., images are assumed to be independently and identically distributed, whereas graphs exhibit relational information among data instances, i.e., nodes. To fully benefit from the relational information inherent in the graph-structured data, we propose a novel GRL method, called RGRL, that learns from the relational information generated from the graph itself. RGRL learns node representations such that the relationship among nodes is invariant to augmentations, i.e., augmentation-invariant relationship, which allows the node representations to vary as long as the relationship among the nodes is preserved. By considering the relationship among nodes in both global and local perspectives, RGRL overcomes limitations of previous contrastive and non-contrastive methods, and achieves the best of both worlds. Extensive experiments on fourteen benchmark datasets over various downstream tasks demonstrate the superiority of RGRL over state-of-the-art baselines. The source code for RGRL is available at https://github.com/Namkyeong/RGRL.
On the User Behavior Leakage from Recommender Exposure
Oct 16, 2022
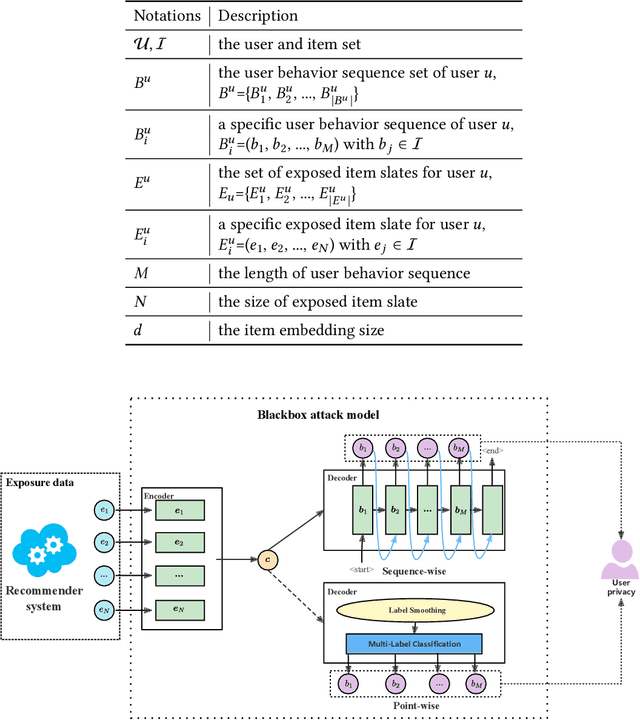
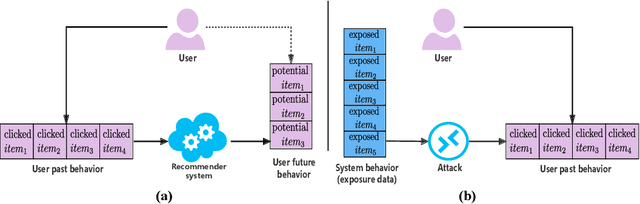
Modern recommender systems are trained to predict users potential future interactions from users historical behavior data. During the interaction process, despite the data coming from the user side recommender systems also generate exposure data to provide users with personalized recommendation slates. Compared with the sparse user behavior data, the system exposure data is much larger in volume since only very few exposed items would be clicked by the user. Besides, the users historical behavior data is privacy sensitive and is commonly protected with careful access authorization. However, the large volume of recommender exposure data usually receives less attention and could be accessed within a relatively larger scope of various information seekers. In this paper, we investigate the problem of user behavior leakage in recommender systems. We show that the privacy sensitive user past behavior data can be inferred through the modeling of system exposure. Besides, one can infer which items the user have clicked just from the observation of current system exposure for this user. Given the fact that system exposure data could be widely accessed from a relatively larger scope, we believe that the user past behavior privacy has a high risk of leakage in recommender systems. More precisely, we conduct an attack model whose input is the current recommended item slate (i.e., system exposure) for the user while the output is the user's historical behavior. Experimental results on two real-world datasets indicate a great danger of user behavior leakage. To address the risk, we propose a two-stage privacy-protection mechanism which firstly selects a subset of items from the exposure slate and then replaces the selected items with uniform or popularity-based exposure. Experimental evaluation reveals a trade-off effect between the recommendation accuracy and the privacy disclosure risk.
Efficient Cross-Modal Video Retrieval with Meta-Optimized Frames
Oct 16, 2022
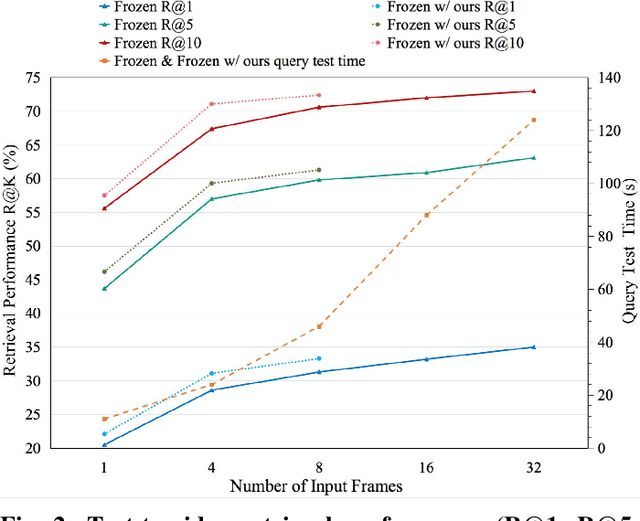
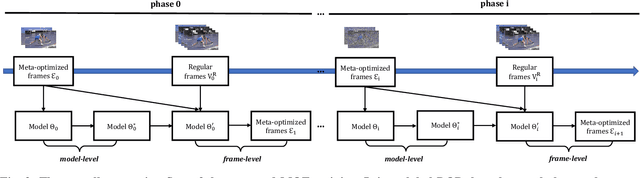
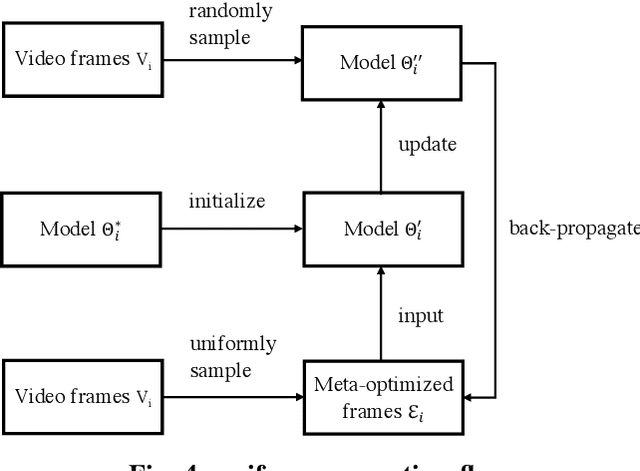
Cross-modal video retrieval aims to retrieve the semantically relevant videos given a text as a query, and is one of the fundamental tasks in Multimedia. Most of top-performing methods primarily leverage Visual Transformer (ViT) to extract video features [1, 2, 3], suffering from high computational complexity of ViT especially for encoding long videos. A common and simple solution is to uniformly sample a small number (say, 4 or 8) of frames from the video (instead of using the whole video) as input to ViT. The number of frames has a strong influence on the performance of ViT, e.g., using 8 frames performs better than using 4 frames yet needs more computational resources, resulting in a trade-off. To get free from this trade-off, this paper introduces an automatic video compression method based on a bilevel optimization program (BOP) consisting of both model-level (i.e., base-level) and frame-level (i.e., meta-level) optimizations. The model-level learns a cross-modal video retrieval model whose input is the "compressed frames" learned by frame-level optimization. In turn, the frame-level optimization is through gradient descent using the meta loss of video retrieval model computed on the whole video. We call this BOP method as well as the "compressed frames" as Meta-Optimized Frames (MOF). By incorporating MOF, the video retrieval model is able to utilize the information of whole videos (for training) while taking only a small number of input frames in actual implementation. The convergence of MOF is guaranteed by meta gradient descent algorithms. For evaluation, we conduct extensive experiments of cross-modal video retrieval on three large-scale benchmarks: MSR-VTT, MSVD, and DiDeMo. Our results show that MOF is a generic and efficient method to boost multiple baseline methods, and can achieve a new state-of-the-art performance.
Energy-Efficiency Maximization for a WPT-D2D Pair in a MISO-NOMA Downlink Network
Oct 08, 2022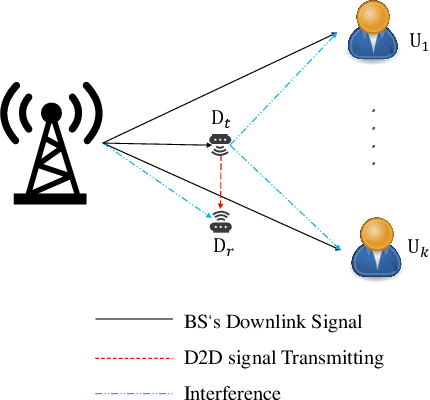
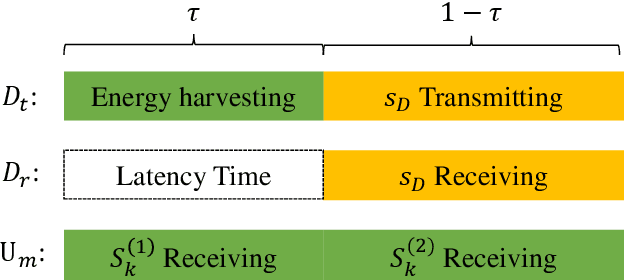
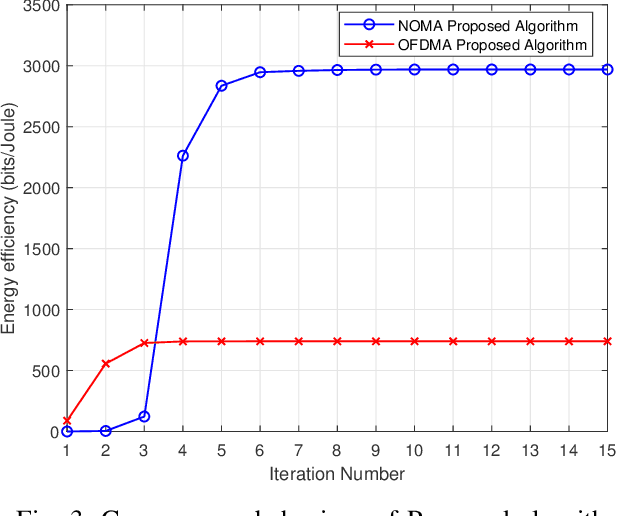
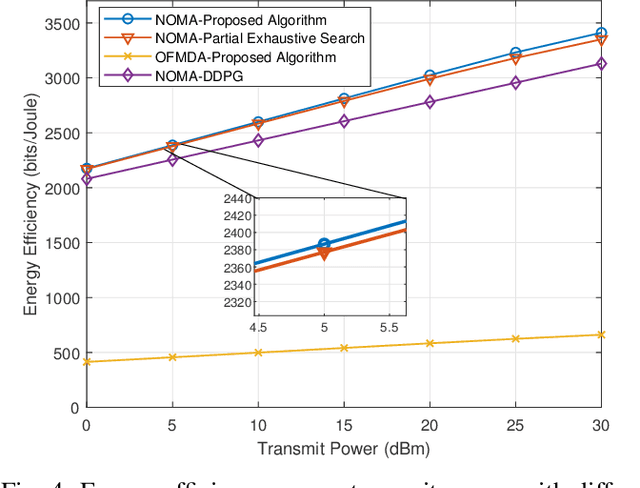
The combination of non-orthogonal multiple access (NOMA) and wireless power transfer (WPT) is a promising solution to enhance the energy efficiency of Device-to-Device (D2D) enabled wireless communication networks. In this paper, we focus on maximizing the energy efficiency of a WPT-D2D pair in a multiple-input single-output (MISO)-NOMA downlink network, by alternatively optimizing the beamforming vectors of the base station (BS) and the time switching coefficient of the WPT assisted D2D transmitter. The formulated energy efficiency maximization problem is non-convex due to the highly coupled variables. To efficiently address the non-convex problem, we first divide it into two subproblems. Afterwards, an alternating algorithm based on the Dinkelbach method and quadratic transform is proposed to solve the two subproblems iteratively. To verify the proposed alternating algorithm's accuracy, partial exhaustive search algorithm is proposed as a benchmark. We also utilize a deep reinforcement learning (DRL) method to solve the non-convex problem and compare it with the proposed algorithm. To demonstrate the respective superiority of the proposed algorithm and DRL-based method, simulations are performed for two scenarios of perfect and imperfect channel state information (CSI). Simulation results are provided to compare NOMA and orthogonal multiple access (OMA), which demonstrate the superior performance of energy efficiency of the NOMA scheme.
Improving Fine-Grain Segmentation via Interpretable Modifications: A Case Study in Fossil Segmentation
Oct 08, 2022
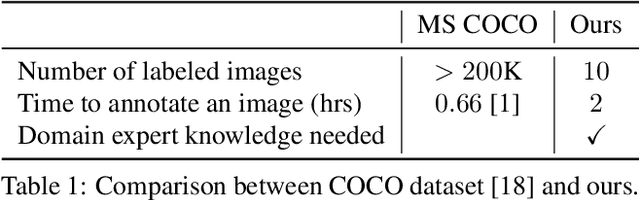
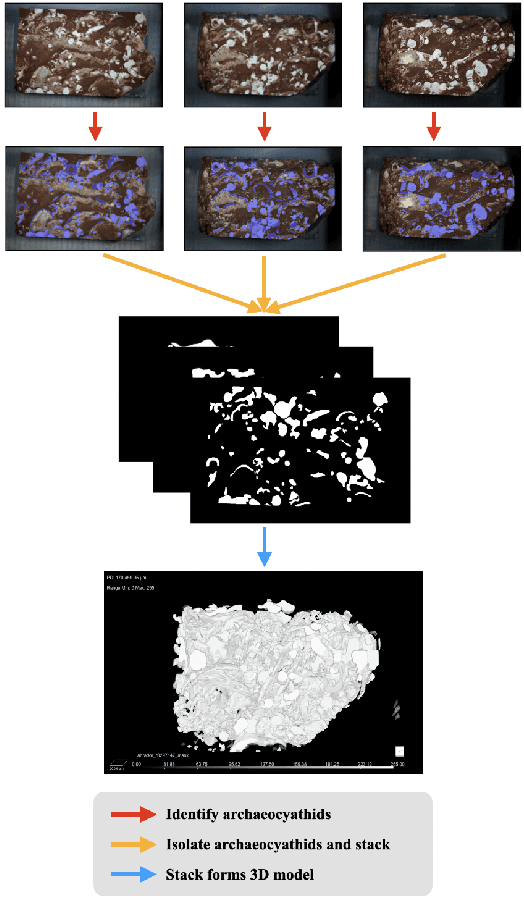
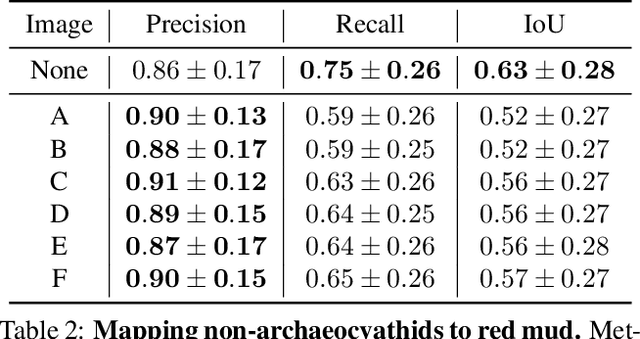
Most interpretability research focuses on datasets containing thousands of images of commonplace objects. However, many high-impact datasets, such as those in medicine and the geosciences, contain fine-grain objects that require domain-expert knowledge to recognize and are time-consuming to collect and annotate. As a result, these datasets contain few annotated images, and current machine vision models cannot train intensively on them. Thus, adapting interpretability techniques to maximize the amount of information that models can learn from small, fine-grain datasets is an important endeavor. Using a Mask R-CNN to segment ancient reef fossils in rock sample images, we present a general paradigm for identifying and mitigating model weaknesses. Specifically, we apply image perturbations to expose the Mask R-CNN's inability to distinguish between different classes of fossils and its inconsistency in segmenting fossils with different textures. To address these shortcomings, we extend an existing model-editing method for correcting systematic mistakes in image classification to image segmentation and introduce a novel application of the technique: encouraging a greater separation between positive and negative pixels for a given class. Through extensive experiments, we find that editing the model by perturbing all pixels for a given class in one image is most effective (compared to using multiple images and/or fewer pixels). Our paradigm may also generalize to other segmentation models trained on small, fine-grain datasets.
LW-ISP: A Lightweight Model with ISP and Deep Learning
Oct 08, 2022

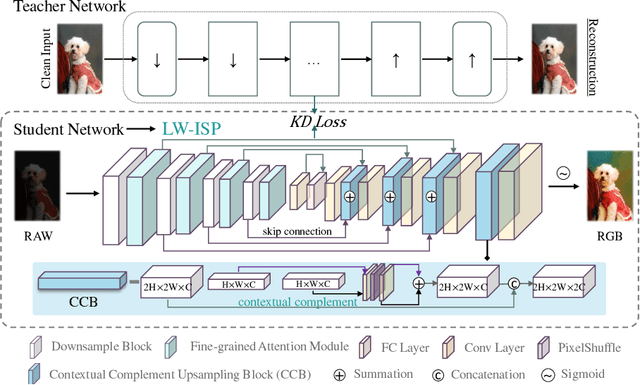

The deep learning (DL)-based methods of low-level tasks have many advantages over the traditional camera in terms of hardware prospects, error accumulation and imaging effects. Recently, the application of deep learning to replace the image signal processing (ISP) pipeline has appeared one after another; however, there is still a long way to go towards real landing. In this paper, we show the possibility of learning-based method to achieve real-time high-performance processing in the ISP pipeline. We propose LW-ISP, a novel architecture designed to implicitly learn the image mapping from RAW data to RGB image. Based on U-Net architecture, we propose the fine-grained attention module and a plug-and-play upsampling block suitable for low-level tasks. In particular, we design a heterogeneous distillation algorithm to distill the implicit features and reconstruction information of the clean image, so as to guide the learning of the student model. Our experiments demonstrate that LW-ISP has achieved a 0.38 dB improvement in PSNR compared to the previous best method, while the model parameters and calculation have been reduced by 23 times and 81 times. The inference efficiency has been accelerated by at least 15 times. Without bells and whistles, LW-ISP has achieved quite competitive results in ISP subtasks including image denoising and enhancement.
ArabSign: A Multi-modality Dataset and Benchmark for Continuous Arabic Sign Language Recognition
Oct 08, 2022

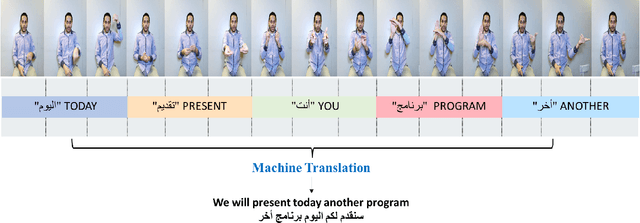
Sign language recognition has attracted the interest of researchers in recent years. While numerous approaches have been proposed for European and Asian sign languages recognition, very limited attempts have been made to develop similar systems for the Arabic sign language (ArSL). This can be attributed partly to the lack of a dataset at the sentence level. In this paper, we aim to make a significant contribution by proposing ArabSign, a continuous ArSL dataset. The proposed dataset consists of 9,335 samples performed by 6 signers. The total time of the recorded sentences is around 10 hours and the average sentence's length is 3.1 signs. ArabSign dataset was recorded using a Kinect V2 camera that provides three types of information (color, depth, and skeleton joint points) recorded simultaneously for each sentence. In addition, we provide the annotation of the dataset according to ArSL and Arabic language structures that can help in studying the linguistic characteristics of ArSL. To benchmark this dataset, we propose an encoder-decoder model for Continuous ArSL recognition. The model has been evaluated on the proposed dataset, and the obtained results show that the encoder-decoder model outperformed the attention mechanism with an average word error rate (WER) of 0.50 compared with 0.62 with the attention mechanism. The data and code are available at github.com/Hamzah-Luqman/ArabSign
AdaptivePose++: A Powerful Single-Stage Network for Multi-Person Pose Regression
Oct 08, 2022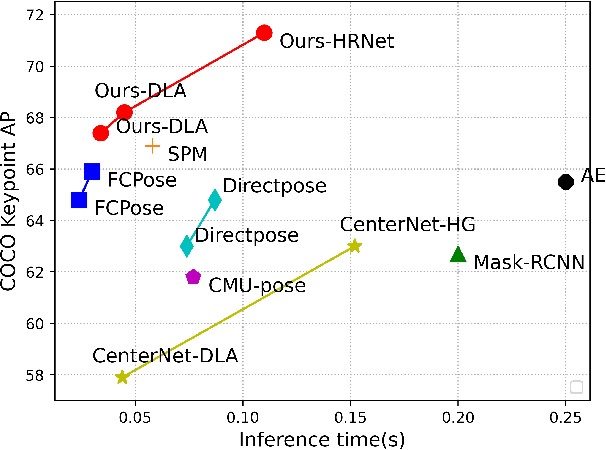

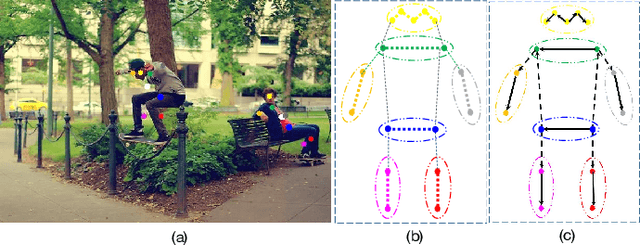
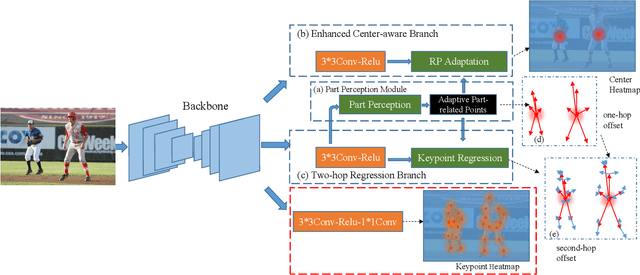
Multi-person pose estimation generally follows top-down and bottom-up paradigms. Both of them use an extra stage ($\boldsymbol{e.g.,}$ human detection in top-down paradigm or grouping process in bottom-up paradigm) to build the relationship between the human instance and corresponding keypoints, thus leading to the high computation cost and redundant two-stage pipeline. To address the above issue, we propose to represent the human parts as adaptive points and introduce a fine-grained body representation method. The novel body representation is able to sufficiently encode the diverse pose information and effectively model the relationship between the human instance and corresponding keypoints in a single-forward pass. With the proposed body representation, we further deliver a compact single-stage multi-person pose regression network, termed as AdaptivePose. During inference, our proposed network only needs a single-step decode operation to form the multi-person pose without complex post-processes and refinements. We employ AdaptivePose for both 2D/3D multi-person pose estimation tasks to verify the effectiveness of AdaptivePose. Without any bells and whistles, we achieve the most competitive performance on MS COCO and CrowdPose in terms of accuracy and speed. Furthermore, the outstanding performance on MuCo-3DHP and MuPoTS-3D further demonstrates the effectiveness and generalizability on 3D scenes. Code is available at https://github.com/buptxyb666/AdaptivePose.
Attention Distillation: self-supervised vision transformer students need more guidance
Oct 03, 2022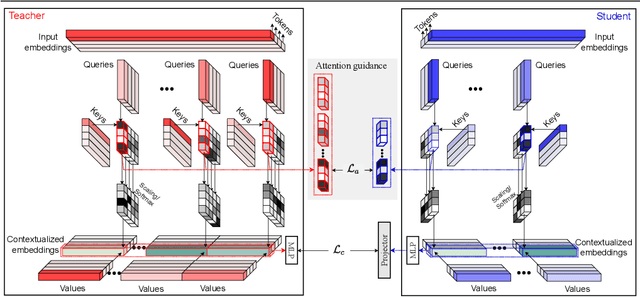
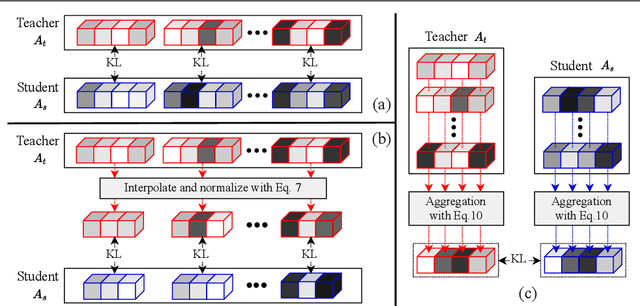
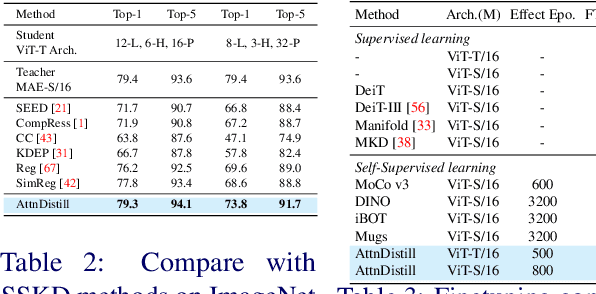
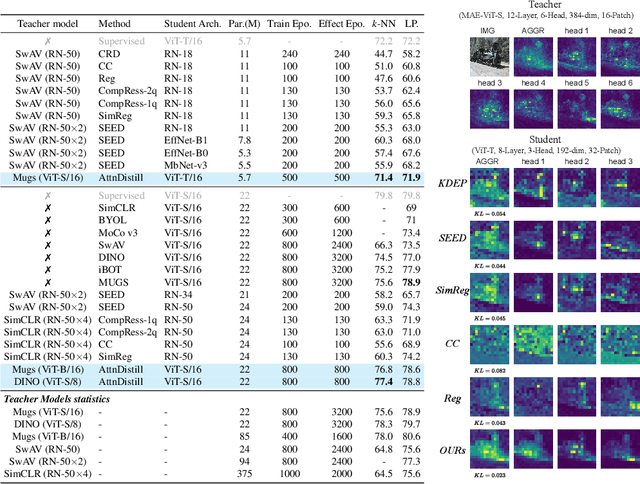
Self-supervised learning has been widely applied to train high-quality vision transformers. Unleashing their excellent performance on memory and compute constraint devices is therefore an important research topic. However, how to distill knowledge from one self-supervised ViT to another has not yet been explored. Moreover, the existing self-supervised knowledge distillation (SSKD) methods focus on ConvNet based architectures are suboptimal for ViT knowledge distillation. In this paper, we study knowledge distillation of self-supervised vision transformers (ViT-SSKD). We show that directly distilling information from the crucial attention mechanism from teacher to student can significantly narrow the performance gap between both. In experiments on ImageNet-Subset and ImageNet-1K, we show that our method AttnDistill outperforms existing self-supervised knowledge distillation (SSKD) methods and achieves state-of-the-art k-NN accuracy compared with self-supervised learning (SSL) methods learning from scratch (with the ViT-S model). We are also the first to apply the tiny ViT-T model on self-supervised learning. Moreover, AttnDistill is independent of self-supervised learning algorithms, it can be adapted to ViT based SSL methods to improve the performance in future research. The code is here: https://github.com/wangkai930418/attndistill
Efficient Bayes Inference in Neural Networks through Adaptive Importance Sampling
Oct 03, 2022

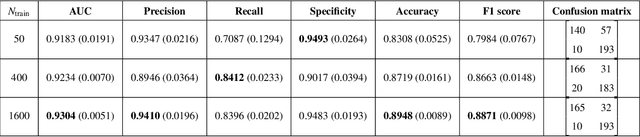
Bayesian neural networks (BNNs) have received an increased interest in the last years. In BNNs, a complete posterior distribution of the unknown weight and bias parameters of the network is produced during the training stage. This probabilistic estimation offers several advantages with respect to point-wise estimates, in particular, the ability to provide uncertainty quantification when predicting new data. This feature inherent to the Bayesian paradigm, is useful in countless machine learning applications. It is particularly appealing in areas where decision-making has a crucial impact, such as medical healthcare or autonomous driving. The main challenge of BNNs is the computational cost of the training procedure since Bayesian techniques often face a severe curse of dimensionality. Adaptive importance sampling (AIS) is one of the most prominent Monte Carlo methodologies benefiting from sounded convergence guarantees and ease for adaptation. This work aims to show that AIS constitutes a successful approach for designing BNNs. More precisely, we propose a novel algorithm PMCnet that includes an efficient adaptation mechanism, exploiting geometric information on the complex (often multimodal) posterior distribution. Numerical results illustrate the excellent performance and the improved exploration capabilities of the proposed method for both shallow and deep neural networks.