 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Random graph matching at Otter's threshold via counting chandeliers
Sep 25, 2022
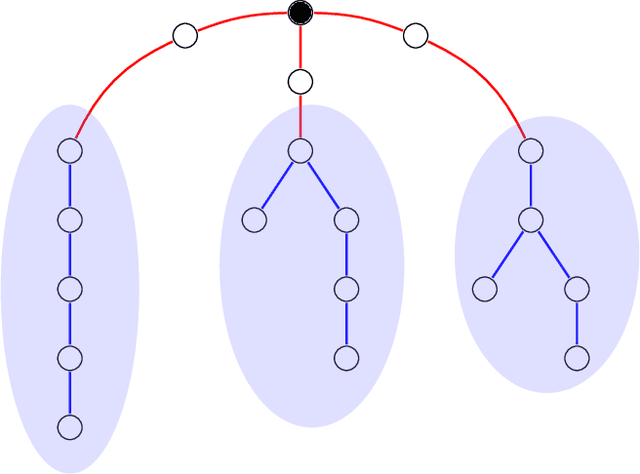
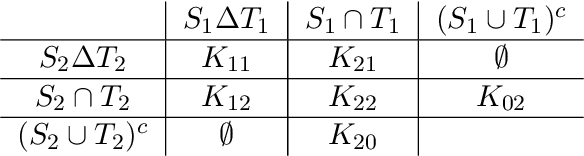
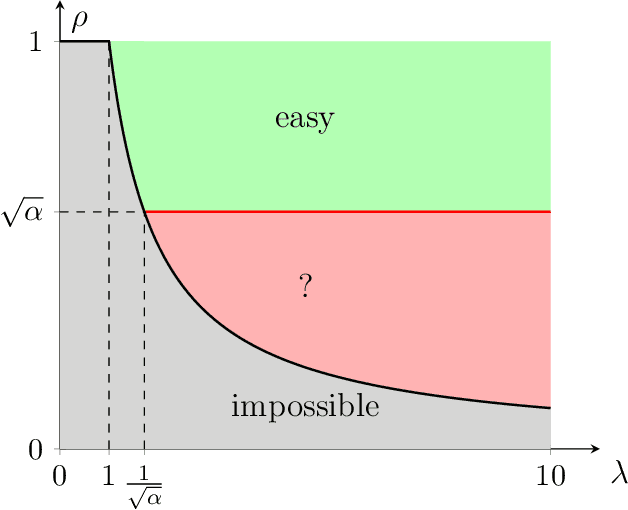
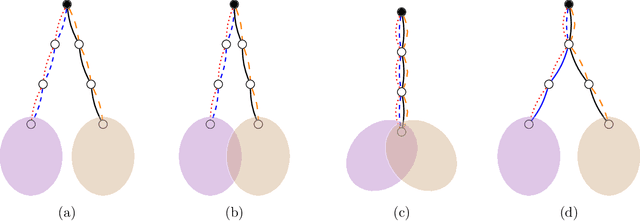
We propose an efficient algorithm for graph matching based on similarity scores constructed from counting a certain family of weighted trees rooted at each vertex. For two Erd\H{o}s-R\'enyi graphs $\mathcal{G}(n,q)$ whose edges are correlated through a latent vertex correspondence, we show that this algorithm correctly matches all but a vanishing fraction of the vertices with high probability, provided that $nq\to\infty$ and the edge correlation coefficient $\rho$ satisfies $\rho^2>\alpha \approx 0.338$, where $\alpha$ is Otter's tree-counting constant. Moreover, this almost exact matching can be made exact under an extra condition that is information-theoretically necessary. This is the first polynomial-time graph matching algorithm that succeeds at an explicit constant correlation and applies to both sparse and dense graphs. In comparison, previous methods either require $\rho=1-o(1)$ or are restricted to sparse graphs. The crux of the algorithm is a carefully curated family of rooted trees called chandeliers, which allows effective extraction of the graph correlation from the counts of the same tree while suppressing the undesirable correlation between those of different trees.
IGNiteR: News Recommendation in Microblogging Applications (Extended Version)
Oct 04, 2022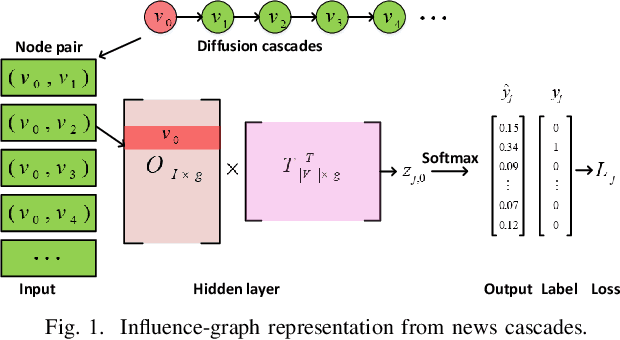
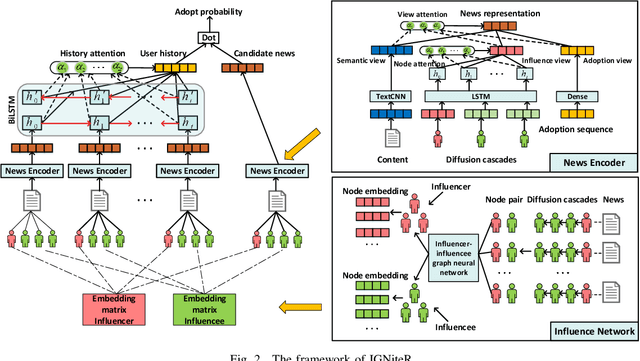
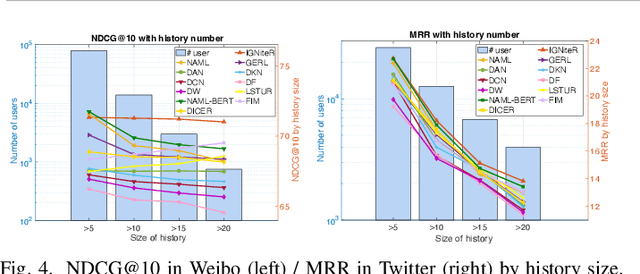
News recommendation is one of the most challenging tasks in recommender systems, mainly due to the ephemeral relevance of news to users. As social media, and particularly microblogging applications like Twitter or Weibo, gains popularity as platforms for news dissemination, personalized news recommendation in this context becomes a significant challenge. We revisit news recommendation in the microblogging scenario, by taking into consideration social interactions and observations tracing how the information that is up for recommendation spreads in an underlying network. We propose a deep-learning based approach that is diffusion and influence-aware, called Influence-Graph News Recommender (IGNiteR). It is a content-based deep recommendation model that jointly exploits all the data facets that may impact adoption decisions, namely semantics, diffusion-related features pertaining to local and global influence among users, temporal attractiveness, and timeliness, as well as dynamic user preferences. To represent the news, a multi-level attention-based encoder is used to reveal the different interests of users. This news encoder relies on a CNN for the news content and on an attentive LSTM for the diffusion traces. For the latter, by exploiting previously observed news diffusions (cascades) in the microblogging medium, users are mapped to a latent space that captures potential influence on others or susceptibility of being influenced for news adoptions. Similarly, a time-sensitive user encoder enables us to capture the dynamic preferences of users with an attention-based bidirectional LSTM. We perform extensive experiments on two real-world datasets, showing that IGNiteR outperforms the state-of-the-art deep-learning based news recommendation methods.
GaitFi: Robust Device-Free Human Identification via WiFi and Vision Multimodal Learning
Aug 30, 2022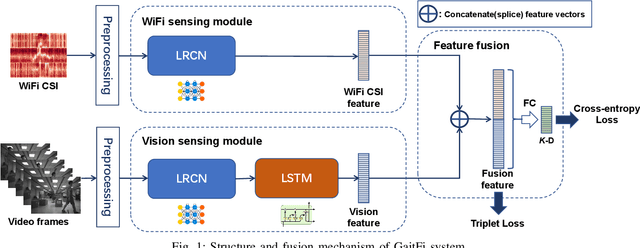

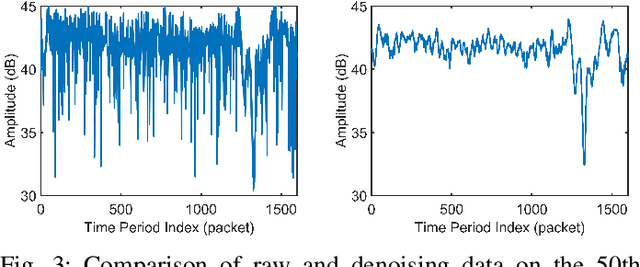
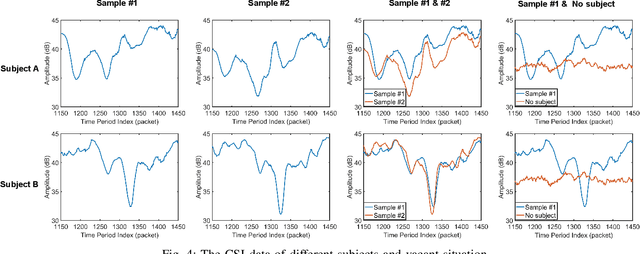
As an important biomarker for human identification, human gait can be collected at a distance by passive sensors without subject cooperation, which plays an essential role in crime prevention, security detection and other human identification applications. At present, most research works are based on cameras and computer vision techniques to perform gait recognition. However, vision-based methods are not reliable when confronting poor illuminations, leading to degrading performances. In this paper, we propose a novel multimodal gait recognition method, namely GaitFi, which leverages WiFi signals and videos for human identification. In GaitFi, Channel State Information (CSI) that reflects the multi-path propagation of WiFi is collected to capture human gaits, while videos are captured by cameras. To learn robust gait information, we propose a Lightweight Residual Convolution Network (LRCN) as the backbone network, and further propose the two-stream GaitFi by integrating WiFi and vision features for the gait retrieval task. The GaitFi is trained by the triplet loss and classification loss on different levels of features. Extensive experiments are conducted in the real world, which demonstrates that the GaitFi outperforms state-of-the-art gait recognition methods based on single WiFi or camera, achieving 94.2% for human identification tasks of 12 subjects.
CNN-based Prediction of Network Robustness With Missing Edges
Aug 25, 2022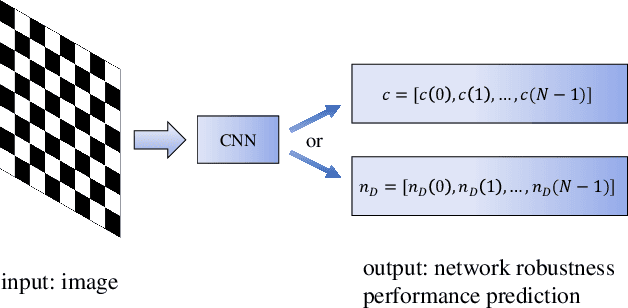
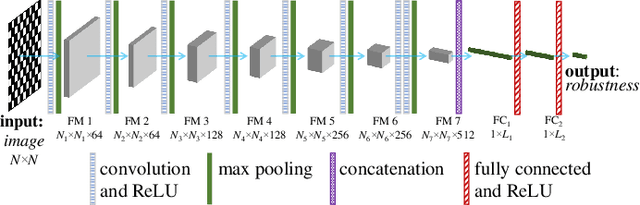
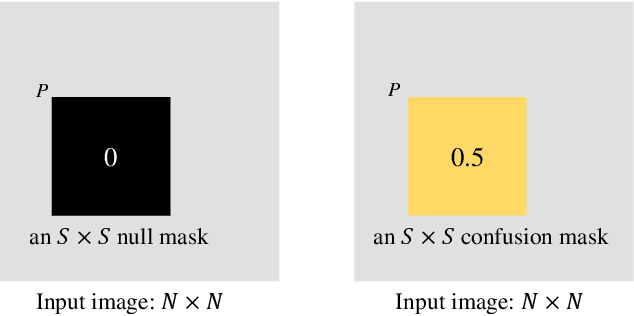
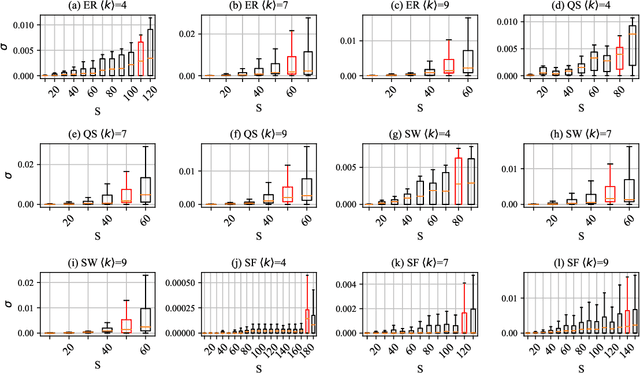
Connectivity and controllability of a complex network are two important issues that guarantee a networked system to function. Robustness of connectivity and controllability guarantees the system to function properly and stably under various malicious attacks. Evaluating network robustness using attack simulations is time consuming, while the convolutional neural network (CNN)-based prediction approach provides a cost-efficient method to approximate the network robustness. In this paper, we investigate the performance of CNN-based approaches for connectivity and controllability robustness prediction, when partial network information is missing, namely the adjacency matrix is incomplete. Extensive experimental studies are carried out. A threshold is explored that if a total amount of more than 7.29\% information is lost, the performance of CNN-based prediction will be significantly degenerated for all cases in the experiments. Two scenarios of missing edge representations are compared, 1) a missing edge is marked `no edge' in the input for prediction, and 2) a missing edge is denoted using a special marker of `unknown'. Experimental results reveal that the first representation is misleading to the CNN-based predictors.
Mutual information neural estimation for unsupervised multi-modal registration of brain images
Jan 25, 2022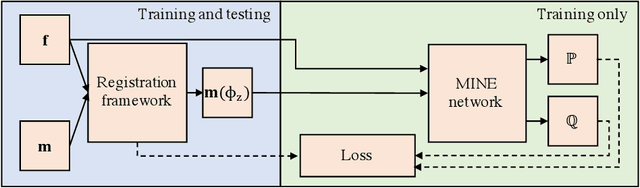
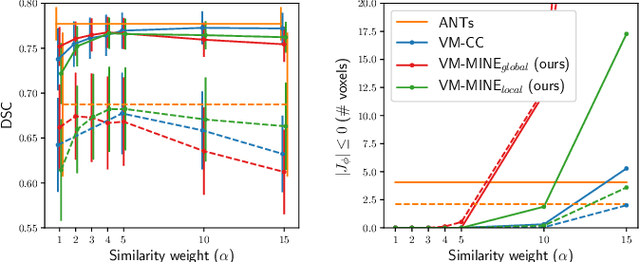
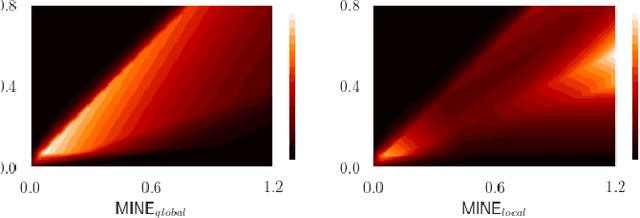
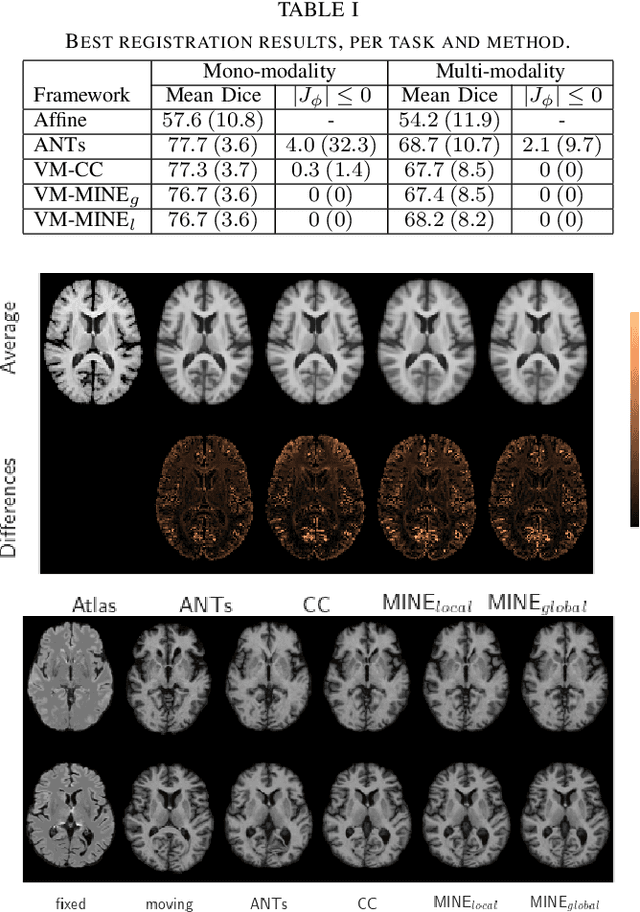
Many applications in image-guided surgery and therapy require fast and reliable non-linear, multi-modal image registration. Recently proposed unsupervised deep learning-based registration methods have demonstrated superior performance compared to iterative methods in just a fraction of the time. Most of the learning-based methods have focused on mono-modal image registration. The extension to multi-modal registration depends on the use of an appropriate similarity function, such as the mutual information (MI). We propose guiding the training of a deep learning-based registration method with MI estimation between an image-pair in an end-to-end trainable network. Our results show that a small, 2-layer network produces competitive results in both mono- and multimodal registration, with sub-second run-times. Comparisons to both iterative and deep learning-based methods show that our MI-based method produces topologically and qualitatively superior results with an extremely low rate of non-diffeomorphic transformations. Real-time clinical application will benefit from a better visual matching of anatomical structures and less registration failures/outliers.
Denoising of 3D MR images using a voxel-wise hybrid residual MLP-CNN model to improve small lesion diagnostic confidence
Sep 28, 2022Small lesions in magnetic resonance imaging (MRI) images are crucial for clinical diagnosis of many kinds of diseases. However, the MRI quality can be easily degraded by various noise, which can greatly affect the accuracy of diagnosis of small lesion. Although some methods for denoising MR images have been proposed, task-specific denoising methods for improving the diagnosis confidence of small lesions are lacking. In this work, we propose a voxel-wise hybrid residual MLP-CNN model to denoise three-dimensional (3D) MR images with small lesions. We combine basic deep learning architecture, MLP and CNN, to obtain an appropriate inherent bias for the image denoising and integrate each output layers in MLP and CNN by adding residual connections to leverage long-range information. We evaluate the proposed method on 720 T2-FLAIR brain images with small lesions at different noise levels. The results show the superiority of our method in both quantitative and visual evaluations on testing dataset compared to state-of-the-art methods. Moreover, two experienced radiologists agreed that at moderate and high noise levels, our method outperforms other methods in terms of recovery of small lesions and overall image denoising quality. The implementation of our method is available at https://github.com/laowangbobo/Residual_MLP_CNN_Mixer.
ProgPrompt: Generating Situated Robot Task Plans using Large Language Models
Sep 22, 2022
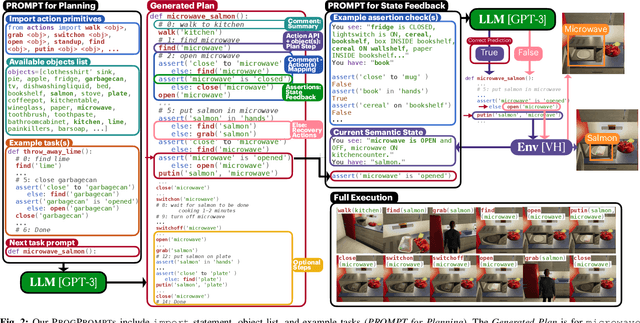


Task planning can require defining myriad domain knowledge about the world in which a robot needs to act. To ameliorate that effort, large language models (LLMs) can be used to score potential next actions during task planning, and even generate action sequences directly, given an instruction in natural language with no additional domain information. However, such methods either require enumerating all possible next steps for scoring, or generate free-form text that may contain actions not possible on a given robot in its current context. We present a programmatic LLM prompt structure that enables plan generation functional across situated environments, robot capabilities, and tasks. Our key insight is to prompt the LLM with program-like specifications of the available actions and objects in an environment, as well as with example programs that can be executed. We make concrete recommendations about prompt structure and generation constraints through ablation experiments, demonstrate state of the art success rates in VirtualHome household tasks, and deploy our method on a physical robot arm for tabletop tasks. Website at progprompt.github.io
Secure Transmission for THz-Empowered RIS-Assisted Non-Terrestrial Networks
Sep 28, 2022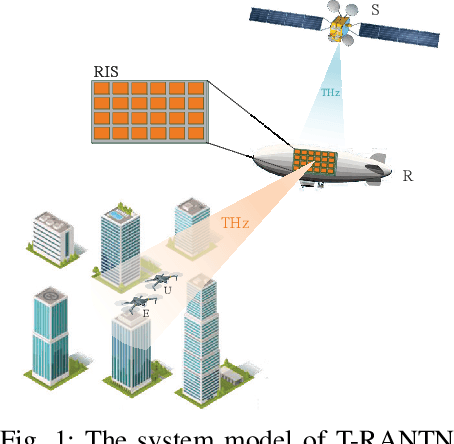
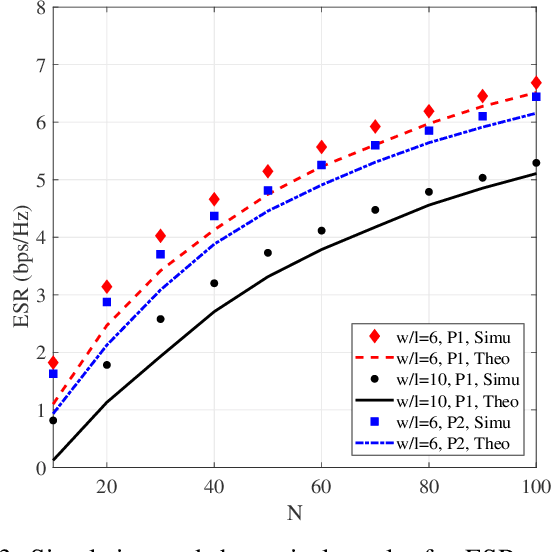
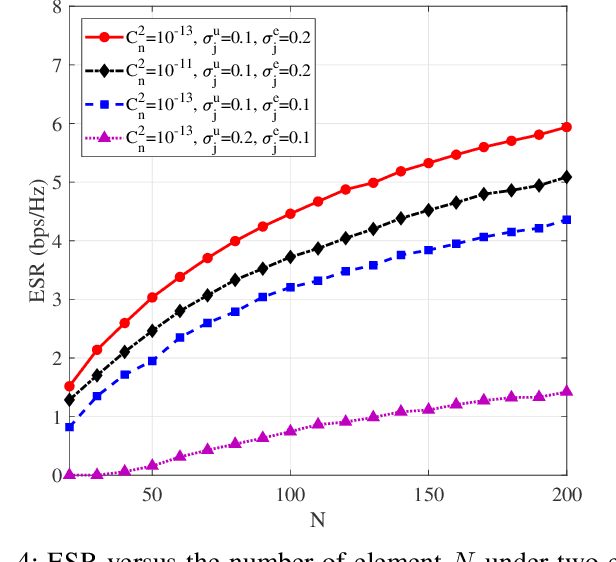
The non-terrestrial networks (NTNs) are recognized as a key component to provide cost-effective and high-capacity ubiquitous connectivity in the future wireless communications. In this paper, we investigate the secure transmission in a terahertz (THz)-empowered reconfigurable intelligent surface (RIS)-assisted NTN (T-RANTN), which is composed of a low-Earth orbit satellite transmitter, an RIS-installed high-altitude platform (HAP) and two unmanned aerial vehicle (UAV) receivers, only one of which is trustworthy. An approximate ergodic secrecy rate (ESR) expression is derived when the atmosphere turbulence and pointing error due to the characteristics of THz as well as the phase errors resulting from finite precision of RIS and imperfect channel estimation are taken into account simultaneously. Furthermore, according to the statistical and perfect channel state information of the untrustworthy receiver, we optimize the phase shifts of RIS to maximize the lower bound of secrecy rate (SR) and instantaneous SR, respectively, by using semidefinite relaxation method. Simulation results show that both the approximate expression for the ESR and the optimization algorithms are serviceable, and even when the jitter standard variance of the trustworthy receiver is greater than that of the untrustworthy one, a positive SR can still be guaranteed.
Collaborative Human-Robot Exploration via Implicit Coordination
Sep 19, 2022

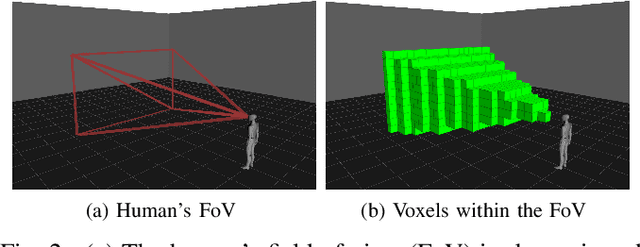
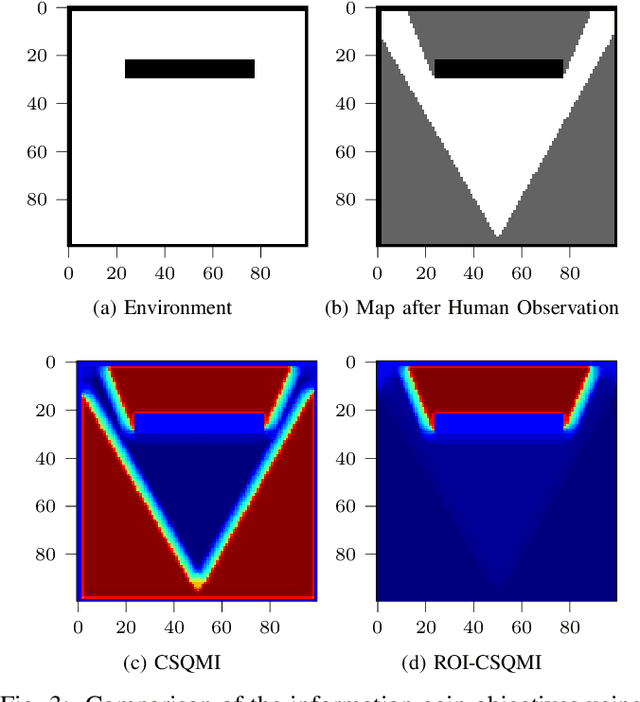
This paper develops a methodology for collaborative human-robot exploration that leverages implicit coordination. Most autonomous single- and multi-robot exploration systems require a remote operator to provide explicit guidance to the robotic team. Few works consider how to embed the human partner alongside robots to provide guidance in the field. A remaining challenge for collaborative human-robot exploration is efficient communication of goals from the human to the robot. In this paper we develop a methodology that implicitly communicates a region of interest from a helmet-mounted depth camera on the human's head to the robot and an information gain-based exploration objective that biases motion planning within the viewpoint provided by the human. The result is an aerial system that safely accesses regions of interest that may not be immediately viewable or reachable by the human. The approach is evaluated in simulation and with hardware experiments in a motion capture arena. Videos of the simulation and hardware experiments are available at: https://youtu.be/7jgkBpVFIoE.
Crowdsourced-based Deep Convolutional Networks for Urban Flood Depth Mapping
Sep 06, 2022
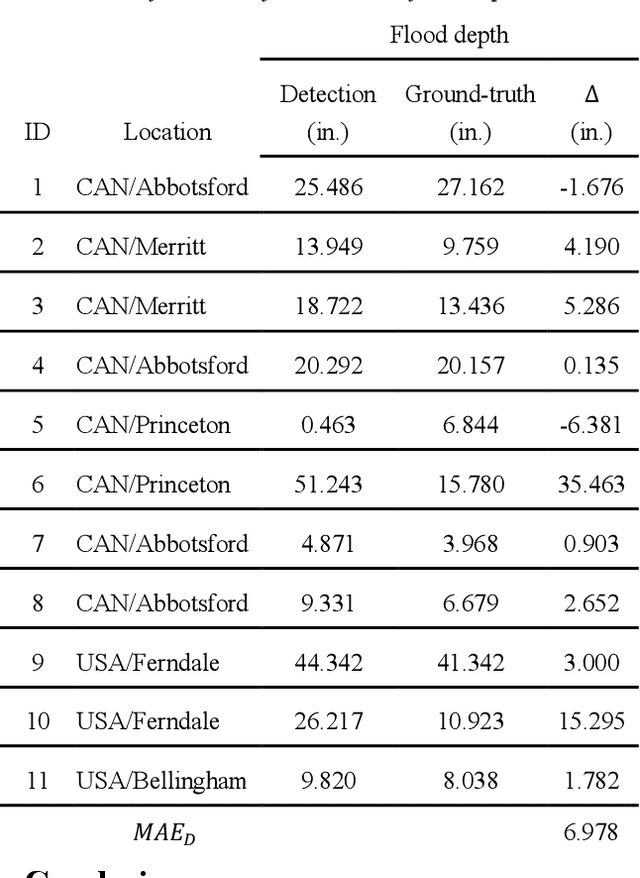
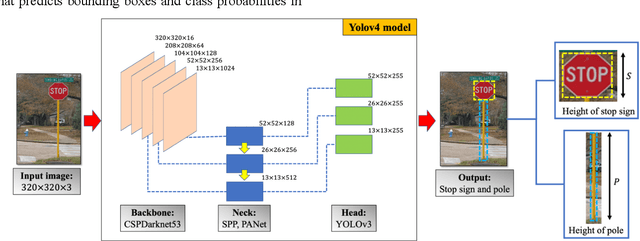

Successful flood recovery and evacuation require access to reliable flood depth information. Most existing flood mapping tools do not provide real-time flood maps of inundated streets in and around residential areas. In this paper, a deep convolutional network is used to determine flood depth with high spatial resolution by analyzing crowdsourced images of submerged traffic signs. Testing the model on photos from a recent flood in the U.S. and Canada yields a mean absolute error of 6.978 in., which is on par with previous studies, thus demonstrating the applicability of this approach to low-cost, accurate, and real-time flood risk mapping.