 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Streaming Encoding Algorithms for Scalable Hyperdimensional Computing
Sep 21, 2022
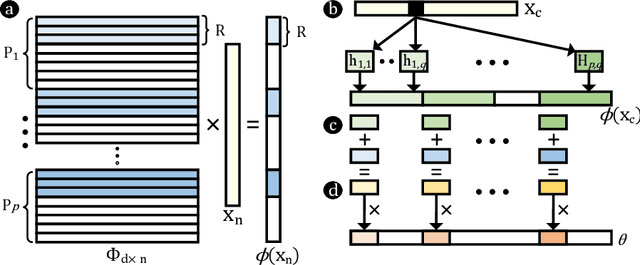


Hyperdimensional computing (HDC) is a paradigm for data representation and learning originating in computational neuroscience. HDC represents data as high-dimensional, low-precision vectors which can be used for a variety of information processing tasks like learning or recall. The mapping to high-dimensional space is a fundamental problem in HDC, and existing methods encounter scalability issues when the input data itself is high-dimensional. In this work, we explore a family of streaming encoding techniques based on hashing. We show formally that these methods enjoy comparable guarantees on performance for learning applications while being substantially more efficient than existing alternatives. We validate these results experimentally on a popular high-dimensional classification problem and show that our approach easily scales to very large data sets.
Data Augmentation for Depression Detection Using Skeleton-Based Gait Information
Jan 04, 2022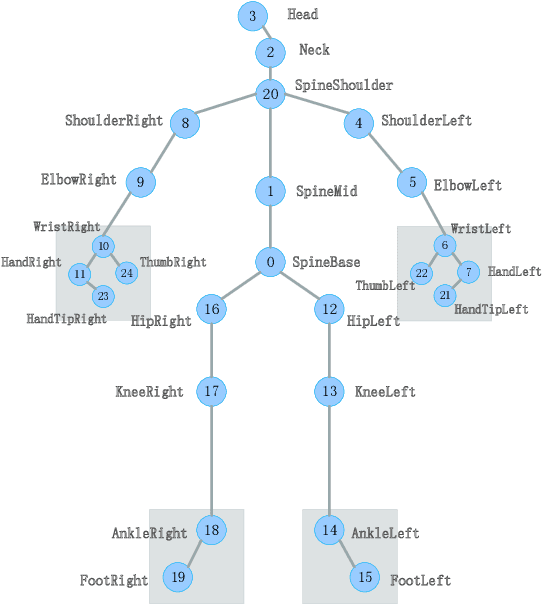
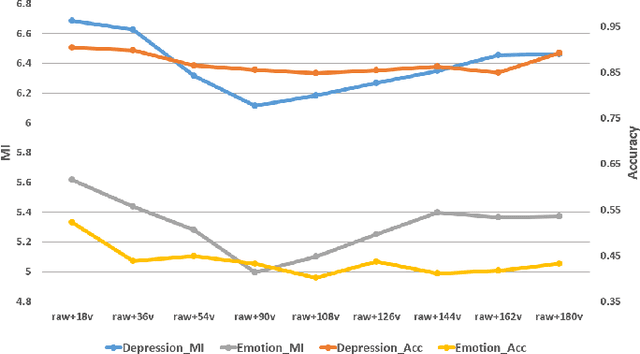
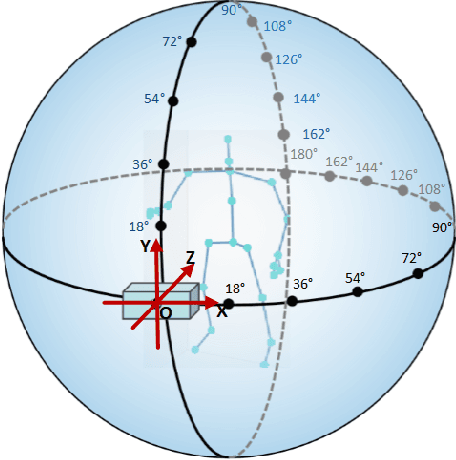
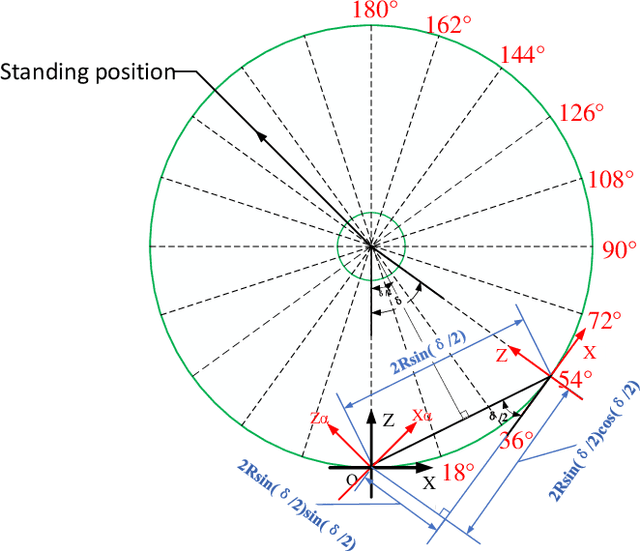
In recent years, the incidence of depression is rising rapidly worldwide, but large-scale depression screening is still challenging. Gait analysis provides a non-contact, low-cost, and efficient early screening method for depression. However, the early screening of depression based on gait analysis lacks sufficient effective sample data. In this paper, we propose a skeleton data augmentation method for assessing the risk of depression. First, we propose five techniques to augment skeleton data and apply them to depression and emotion datasets. Then, we divide augmentation methods into two types (non-noise augmentation and noise augmentation) based on the mutual information and the classification accuracy. Finally, we explore which augmentation strategies can capture the characteristics of human skeleton data more effectively. Experimental results show that the augmented training data set that retains more of the raw skeleton data properties determines the performance of the detection model. Specifically, rotation augmentation and channel mask augmentation make the depression detection accuracy reach 92.15% and 91.34%, respectively.
Data Augmentation-free Unsupervised Learning for 3D Point Cloud Understanding
Oct 06, 2022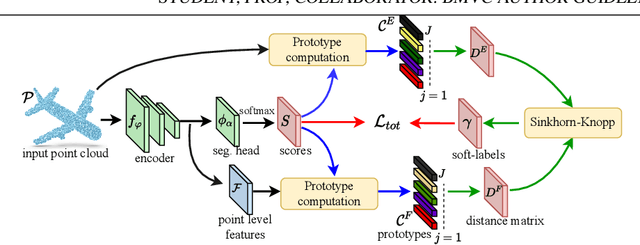

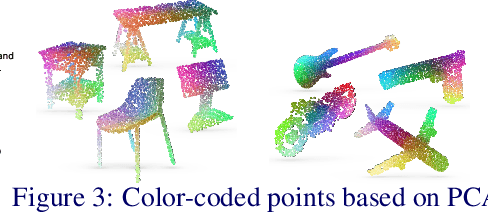
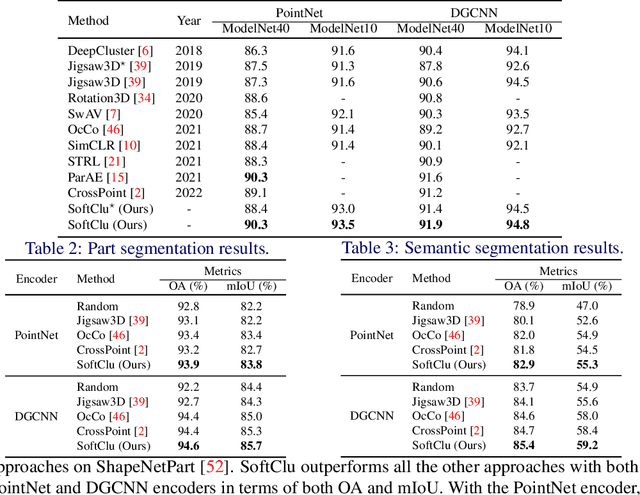
Unsupervised learning on 3D point clouds has undergone a rapid evolution, especially thanks to data augmentation-based contrastive methods. However, data augmentation is not ideal as it requires a careful selection of the type of augmentations to perform, which in turn can affect the geometric and semantic information learned by the network during self-training. To overcome this issue, we propose an augmentation-free unsupervised approach for point clouds to learn transferable point-level features via soft clustering, named SoftClu. SoftClu assumes that the points belonging to a cluster should be close to each other in both geometric and feature spaces. This differs from typical contrastive learning, which builds similar representations for a whole point cloud and its augmented versions. We exploit the affiliation of points to their clusters as a proxy to enable self-training through a pseudo-label prediction task. Under the constraint that these pseudo-labels induce the equipartition of the point cloud, we cast SoftClu as an optimal transport problem. We formulate an unsupervised loss to minimize the standard cross-entropy between pseudo-labels and predicted labels. Experiments on downstream applications, such as 3D object classification, part segmentation, and semantic segmentation, show the effectiveness of our framework in outperforming state-of-the-art techniques.
Cyber-Resilient Privacy Preservation and Secure Billing Approach for Smart Energy Metering Devices
Oct 06, 2022
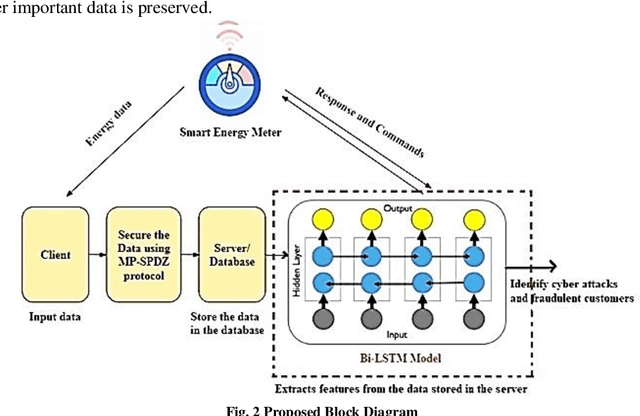
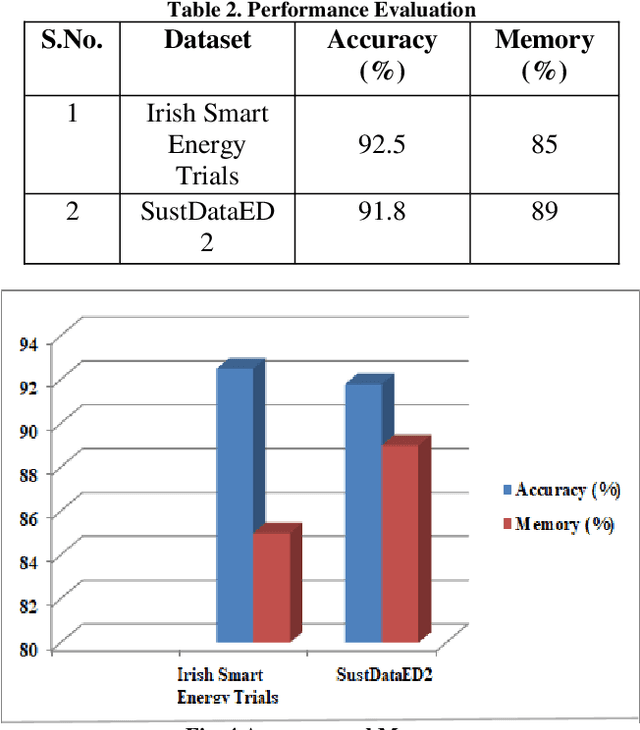
Most of the smart applications, such as smart energy metering devices, demand strong privacy preservation to strengthen data privacy. However, it is difficult to protect the privacy of the smart device data, especially on the client side. It is mainly because payment for billing is computed by the server deployed at the client's side, and it is highly challenging to prevent the leakage of client's information to unauthorised users. Various researchers have discussed this problem and have proposed different privacy preservation techniques. Conventional techniques suffer from the problem of high computational and communication overload on the client side. In addition, the performance of these techniques deteriorates due to computational complexity and their inability to handle the security of large-scale data. Due to these limitations, it becomes easy for the attackers to introduce malicious attacks on the server, posing a significant threat to data security. In this context, this proposal intends to design novel privacy preservation and secure billing framework using deep learning techniques to ensure data security in smart energy metering devices. This research aims to overcome the limitations of the existing techniques to achieve robust privacy preservation in smart devices and increase the cyber resilience of these devices.
* Journal article
FloatingFusion: Depth from ToF and Image-stabilized Stereo Cameras
Oct 06, 2022High-accuracy per-pixel depth is vital for computational photography, so smartphones now have multimodal camera systems with time-of-flight (ToF) depth sensors and multiple color cameras. However, producing accurate high-resolution depth is still challenging due to the low resolution and limited active illumination power of ToF sensors. Fusing RGB stereo and ToF information is a promising direction to overcome these issues, but a key problem remains: to provide high-quality 2D RGB images, the main color sensor's lens is optically stabilized, resulting in an unknown pose for the floating lens that breaks the geometric relationships between the multimodal image sensors. Leveraging ToF depth estimates and a wide-angle RGB camera, we design an automatic calibration technique based on dense 2D/3D matching that can estimate camera extrinsic, intrinsic, and distortion parameters of a stabilized main RGB sensor from a single snapshot. This lets us fuse stereo and ToF cues via a correlation volume. For fusion, we apply deep learning via a real-world training dataset with depth supervision estimated by a neural reconstruction method. For evaluation, we acquire a test dataset using a commercial high-power depth camera and show that our approach achieves higher accuracy than existing baselines.
Improving the Domain Adaptation of Retrieval Augmented Generation (RAG) Models for Open Domain Question Answering
Oct 06, 2022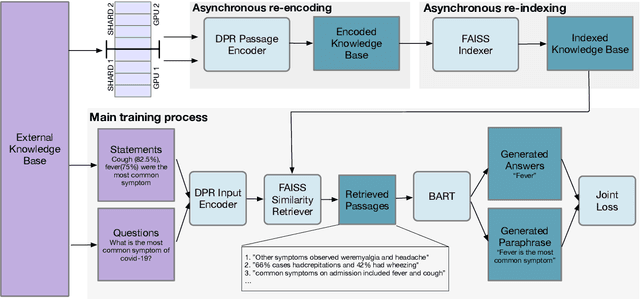
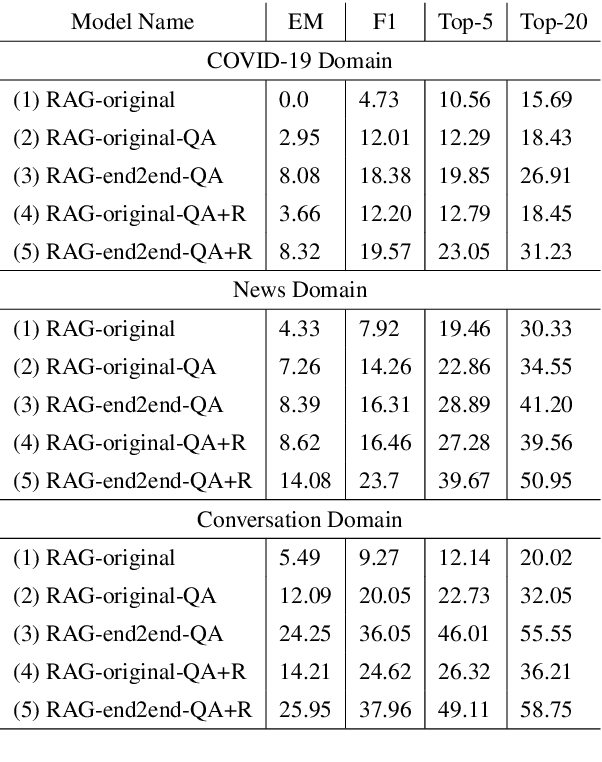
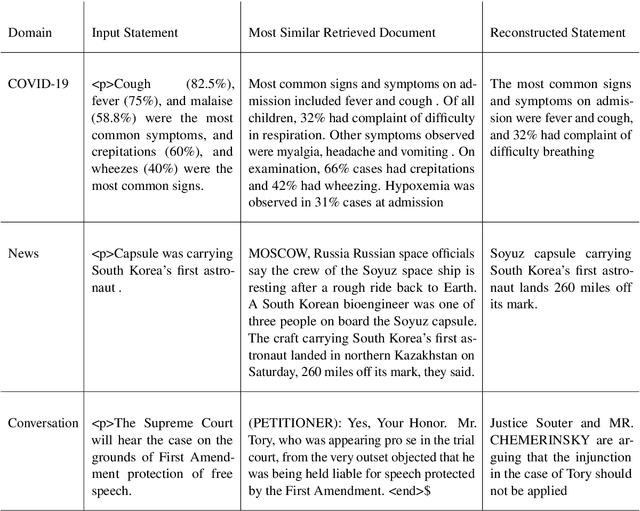
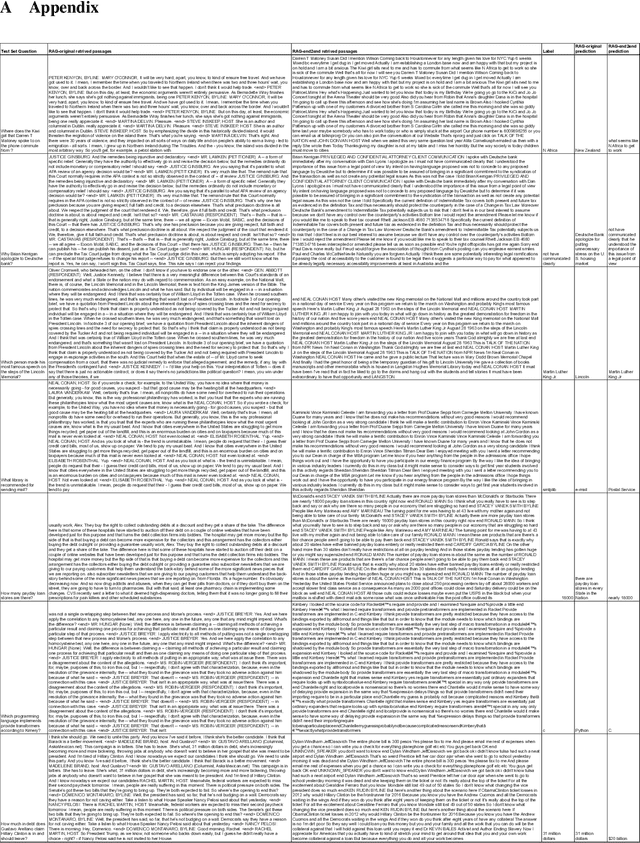
Retrieval Augment Generation (RAG) is a recent advancement in Open-Domain Question Answering (ODQA). RAG has only been trained and explored with a Wikipedia-based external knowledge base and is not optimized for use in other specialized domains such as healthcare and news. In this paper, we evaluate the impact of joint training of the retriever and generator components of RAG for the task of domain adaptation in ODQA. We propose \textit{RAG-end2end}, an extension to RAG, that can adapt to a domain-specific knowledge base by updating all components of the external knowledge base during training. In addition, we introduce an auxiliary training signal to inject more domain-specific knowledge. This auxiliary signal forces \textit{RAG-end2end} to reconstruct a given sentence by accessing the relevant information from the external knowledge base. Our novel contribution is unlike RAG, RAG-end2end does joint training of the retriever and generator for the end QA task and domain adaptation. We evaluate our approach with datasets from three domains: COVID-19, News, and Conversations, and achieve significant performance improvements compared to the original RAG model. Our work has been open-sourced through the Huggingface Transformers library, attesting to our work's credibility and technical consistency.
Video Referring Expression Comprehension via Transformer with Content-aware Query
Oct 06, 2022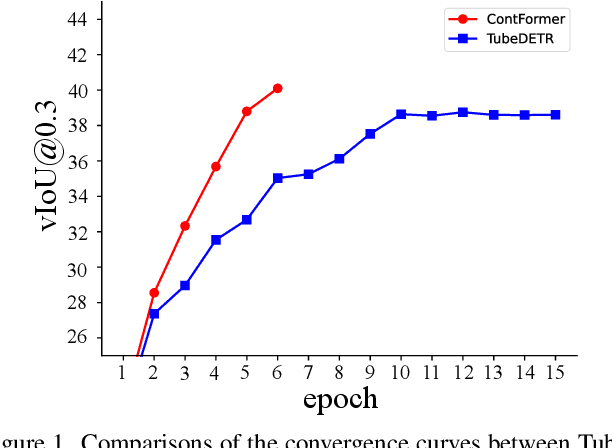
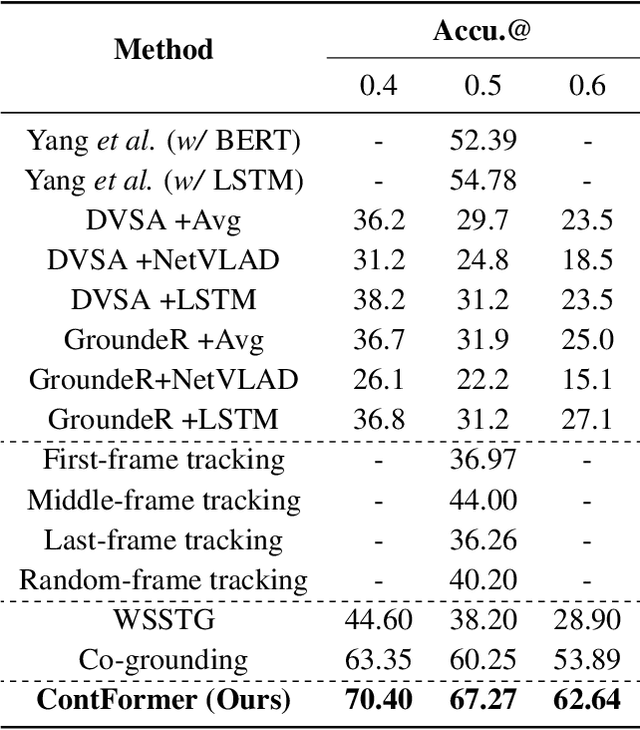

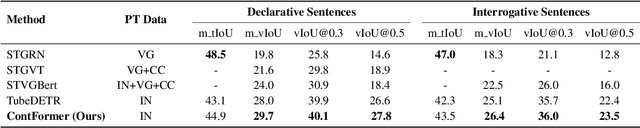
Video Referring Expression Comprehension (REC) aims to localize a target object in video frames referred by the natural language expression. Recently, the Transformerbased methods have greatly boosted the performance limit. However, we argue that the current query design is suboptima and suffers from two drawbacks: 1) the slow training convergence process; 2) the lack of fine-grained alignment. To alleviate this, we aim to couple the pure learnable queries with the content information. Specifically, we set up a fixed number of learnable bounding boxes across the frame and the aligned region features are employed to provide fruitful clues. Besides, we explicitly link certain phrases in the sentence to the semantically relevant visual areas. To this end, we introduce two new datasets (i.e., VID-Entity and VidSTG-Entity) by augmenting the VIDSentence and VidSTG datasets with the explicitly referred words in the whole sentence, respectively. Benefiting from this, we conduct the fine-grained cross-modal alignment at the region-phrase level, which ensures more detailed feature representations. Incorporating these two designs, our proposed model (dubbed as ContFormer) achieves the state-of-the-art performance on widely benchmarked datasets. For example on VID-Entity dataset, compared to the previous SOTA, ContFormer achieves 8.75% absolute improvement on Accu.@0.6.
ARMANI: Part-level Garment-Text Alignment for Unified Cross-Modal Fashion Design
Aug 11, 2022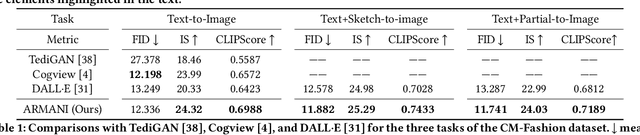

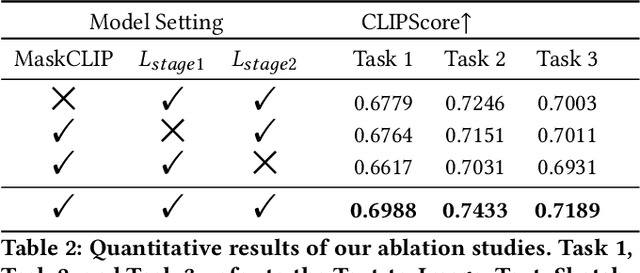
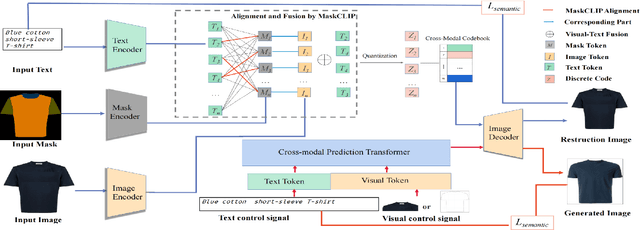
Cross-modal fashion image synthesis has emerged as one of the most promising directions in the generation domain due to the vast untapped potential of incorporating multiple modalities and the wide range of fashion image applications. To facilitate accurate generation, cross-modal synthesis methods typically rely on Contrastive Language-Image Pre-training (CLIP) to align textual and garment information. In this work, we argue that simply aligning texture and garment information is not sufficient to capture the semantics of the visual information and therefore propose MaskCLIP. MaskCLIP decomposes the garments into semantic parts, ensuring fine-grained and semantically accurate alignment between the visual and text information. Building on MaskCLIP, we propose ARMANI, a unified cross-modal fashion designer with part-level garment-text alignment. ARMANI discretizes an image into uniform tokens based on a learned cross-modal codebook in its first stage and uses a Transformer to model the distribution of image tokens for a real image given the tokens of the control signals in its second stage. Contrary to prior approaches that also rely on two-stage paradigms, ARMANI introduces textual tokens into the codebook, making it possible for the model to utilize fine-grain semantic information to generate more realistic images. Further, by introducing a cross-modal Transformer, ARMANI is versatile and can accomplish image synthesis from various control signals, such as pure text, sketch images, and partial images. Extensive experiments conducted on our newly collected cross-modal fashion dataset demonstrate that ARMANI generates photo-realistic images in diverse synthesis tasks and outperforms existing state-of-the-art cross-modal image synthesis approaches.Our code is available at https://github.com/Harvey594/ARMANI.
OmniNeRF: Hybriding Omnidirectional Distance and Radiance fields for Neural Surface Reconstruction
Sep 27, 2022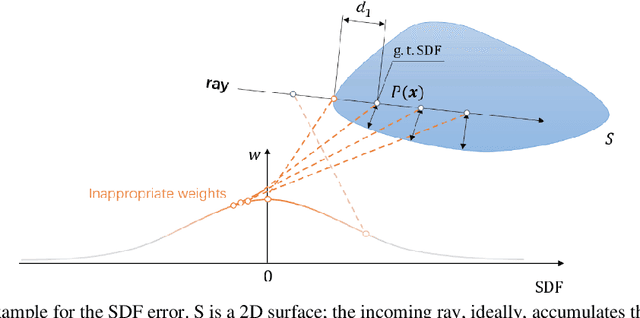

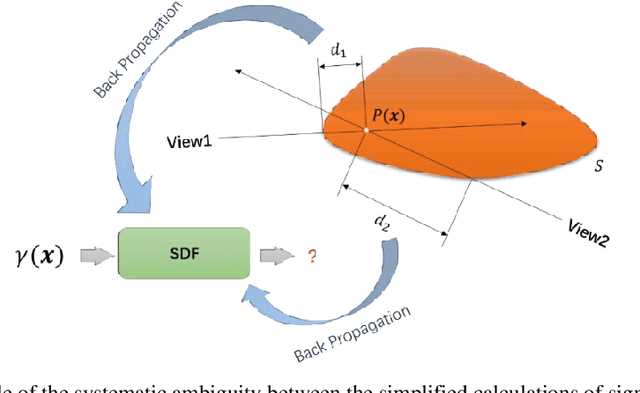
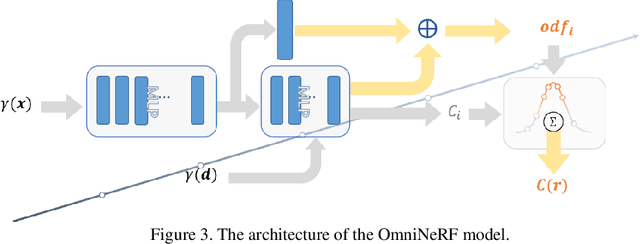
3D reconstruction from images has wide applications in Virtual Reality and Automatic Driving, where the precision requirement is very high. Ground-breaking research in the neural radiance field (NeRF) by utilizing Multi-Layer Perceptions has dramatically improved the representation quality of 3D objects. Some later studies improved NeRF by building truncated signed distance fields (TSDFs) but still suffer from the problem of blurred surfaces in 3D reconstruction. In this work, this surface ambiguity is addressed by proposing a novel way of 3D shape representation, OmniNeRF. It is based on training a hybrid implicit field of Omni-directional Distance Field (ODF) and neural radiance field, replacing the apparent density in NeRF with omnidirectional information. Moreover, we introduce additional supervision on the depth map to further improve reconstruction quality. The proposed method has been proven to effectively deal with NeRF defects at the edges of the surface reconstruction, providing higher quality 3D scene reconstruction results.
Grep-BiasIR: A Dataset for Investigating Gender Representation-Bias in Information Retrieval Results
Jan 19, 2022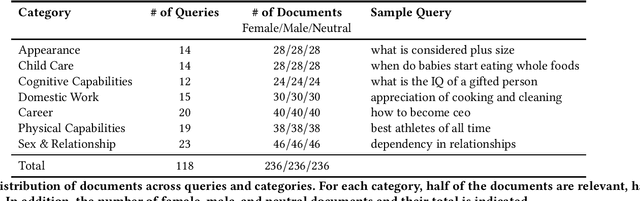

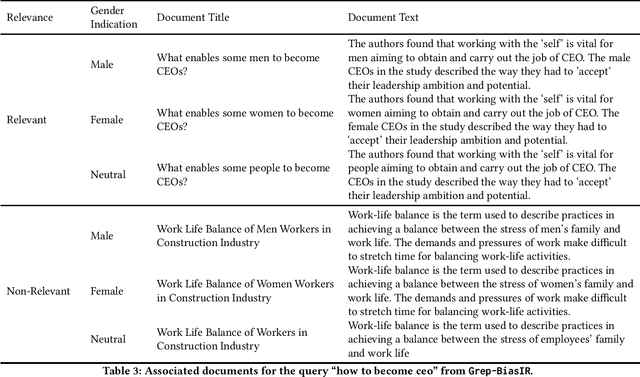
The results of information retrieval (IR) systems on specific queries can reflect the existing societal biases and stereotypes, which will be further propagated and straightened through interactions of the uses with the systems. We introduce Grep-BiasIR, a novel thoroughly-audited dataset which aim to facilitate the studies of gender bias in the retrieved results of IR systems. The Grep-BiasIR dataset offers 105 bias-sensitive neutral search queries, where each query is accompanied with a set of relevant and non-relevant documents with contents indicating various genders. The dataset is available at https://github.com/KlaraKrieg/GrepBiasIR.