 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Neighborhood-aware Scalable Temporal Network Representation Learning
Sep 05, 2022
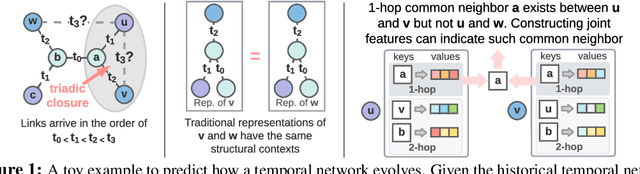
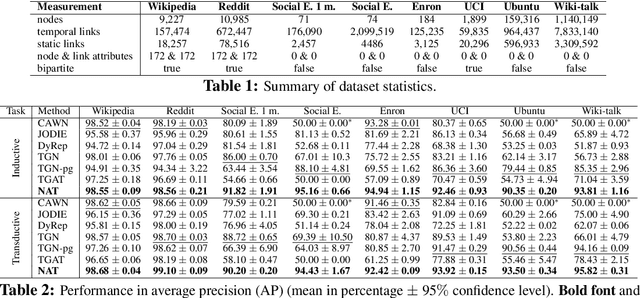
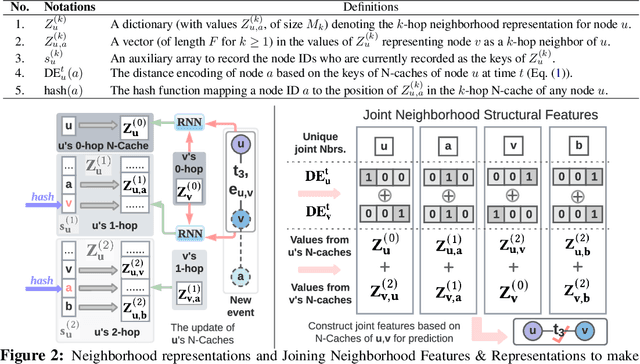
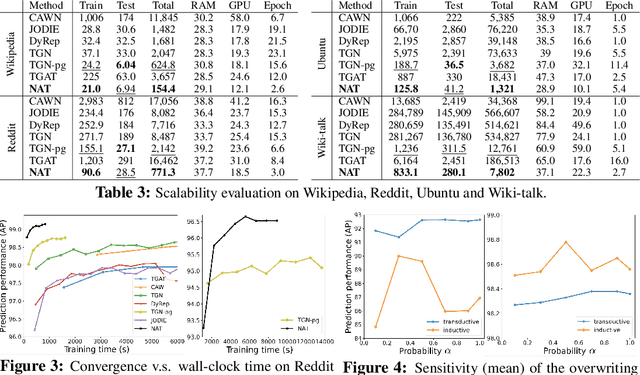
Temporal networks have been widely used to model real-world complex systems such as financial systems and e-commerce systems. In a temporal network, the joint neighborhood of a set of nodes often provides crucial structural information on predicting whether they may interact at a certain time. However, recent representation learning methods for temporal networks often fail to extract such information or depend on extremely time-consuming feature construction approaches. To address the issue, this work proposes Neighborhood-Aware Temporal network model (NAT). For each node in the network, NAT abandons the commonly-used one-single-vector-based representation while adopting a novel dictionary-type neighborhood representation. Such a dictionary representation records a down-sampled set of the neighboring nodes as keys, and allows fast construction of structural features for a joint neighborhood of multiple nodes. We also design dedicated data structure termed N-cache to support parallel access and update of those dictionary representations on GPUs. NAT gets evaluated over seven real-world large-scale temporal networks. NAT not only outperforms all cutting-edge baselines by averaged 5.9% and 6.0% in transductive and inductive link prediction accuracy, respectively, but also keeps scalable by achieving a speed-up of 4.1-76.7x against the baselines that adopts joint structural features and achieves a speed-up of 1.6-4.0x against the baselines that cannot adopt those features. The link to the code: https://github.com/Graph-COM/Neighborhood-Aware-Temporal-Network.
Thermal (and Hybrid Thermal/Audio) Side-Channel Attacks on Keyboard Input
Oct 05, 2022



To date, there has been no systematic investigation of thermal profiles of keyboards, and thus no efforts have been made to secure them. This serves as our main motivation for constructing a means for password harvesting from keyboard thermal emanations. Specifically, we introduce Thermanator: a new post-factum insider attack based on heat transfer caused by a user typing a password on a typical external (plastic) keyboard. We conduct and describe a user study that collected thermal residues from 30 users entering 10 unique passwords (both weak and strong) on 4 popular commodity keyboards. Results show that entire sets of key-presses can be recovered by non-expert users as late as 30 seconds after initial password entry, while partial sets can be recovered as late as 1 minute after entry. However, the thermal residue side-channel lacks information about password length, duplicate key-presses, and key-press ordering. To overcome these limitations, we leverage keyboard acoustic emanations and combine the two to yield AcuTherm, the first hybrid side-channel attack on keyboards. AcuTherm significantly reduces password search without the need for any training on the victim's typing. We report results gathered for many representative passwords based on a user study involving 19 subjects. The takeaway of this work is three-fold: (1) using plastic keyboards to enter secrets (such as passwords and PINs) is even less secure than previously recognized, (2) post-factum thermal imaging attacks are realistic, and (3) hybrid (multiple side-channel) attacks are both realistic and effective.
Mutual information neural estimation for unsupervised multi-modal registration of brain images
Jan 25, 2022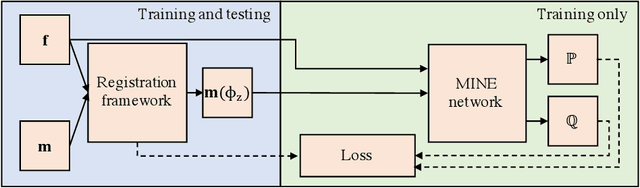
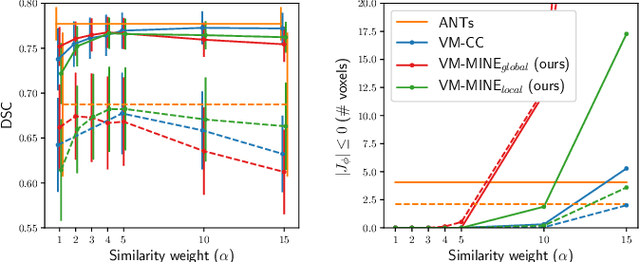
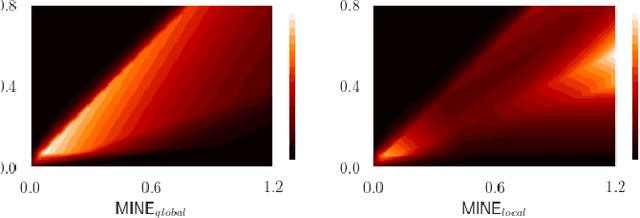
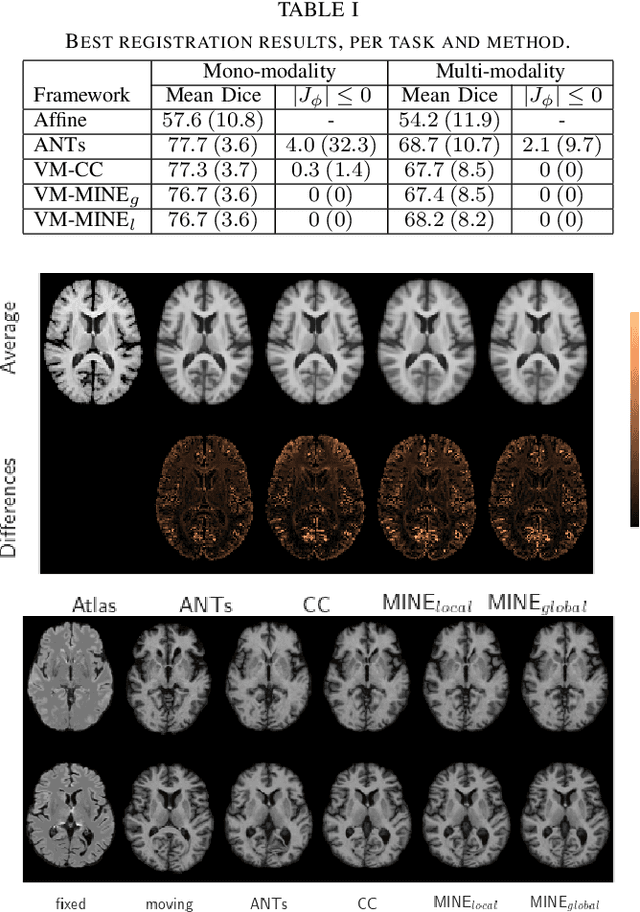
Many applications in image-guided surgery and therapy require fast and reliable non-linear, multi-modal image registration. Recently proposed unsupervised deep learning-based registration methods have demonstrated superior performance compared to iterative methods in just a fraction of the time. Most of the learning-based methods have focused on mono-modal image registration. The extension to multi-modal registration depends on the use of an appropriate similarity function, such as the mutual information (MI). We propose guiding the training of a deep learning-based registration method with MI estimation between an image-pair in an end-to-end trainable network. Our results show that a small, 2-layer network produces competitive results in both mono- and multimodal registration, with sub-second run-times. Comparisons to both iterative and deep learning-based methods show that our MI-based method produces topologically and qualitatively superior results with an extremely low rate of non-diffeomorphic transformations. Real-time clinical application will benefit from a better visual matching of anatomical structures and less registration failures/outliers.
Adaptive and Collaborative Bathymetric Channel-Finding Approach for Multiple Autonomous Marine Vehicle
Sep 20, 2022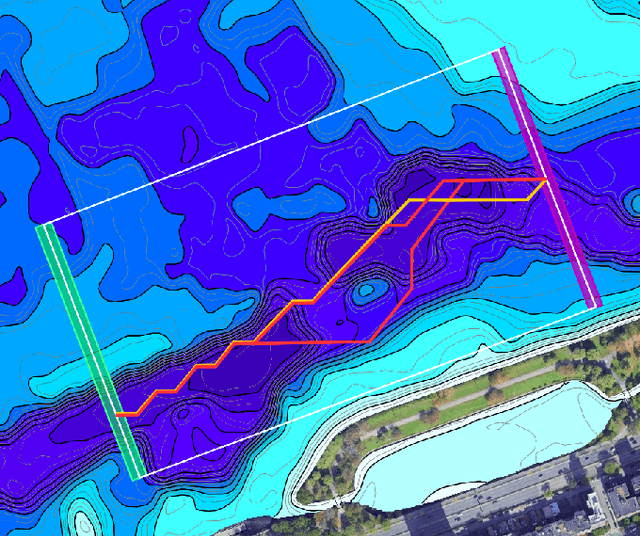

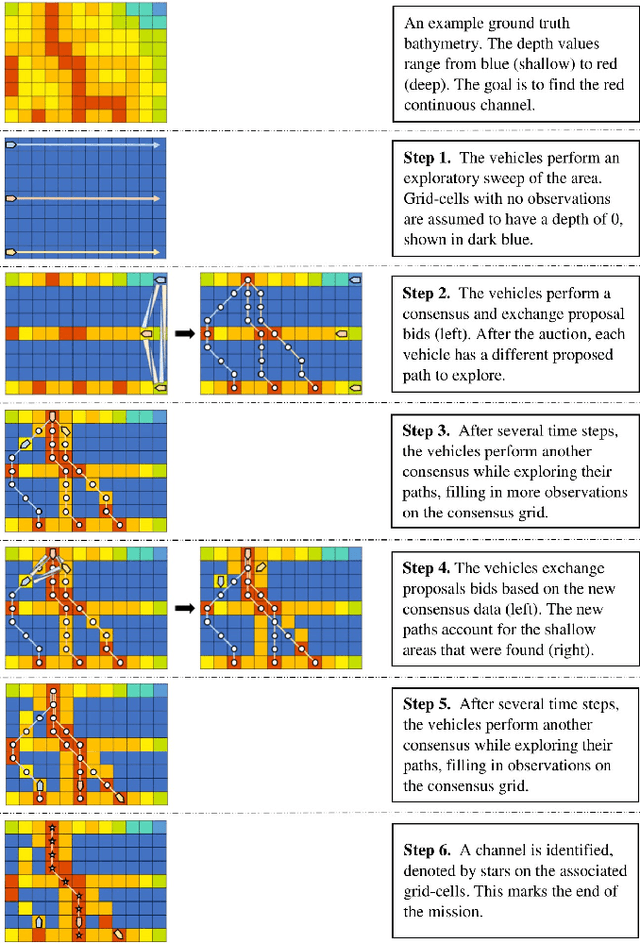
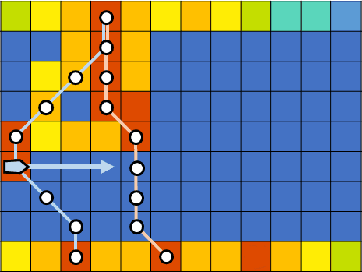
This paper reports an investigation into the problem of rapid identification of a channel that crosses a body of water using one or more Unmanned Surface Vehicles (USV). A new algorithm called Proposal Based Adaptive Channel Search (PBACS) is presented as a potential solution that improves upon current methods. The empirical performance of PBACS is compared to lawnmower surveying and to Markov decision process (MDP) planning with two state-of-the-art reward functions: Upper Confidence Bound (UCB) and Maximum Value Information (MVI). The performance of each method is evaluated through comparison of the time it takes to identify a continuous channel through an area, using one, two, three, or four USVs. The performance of each method is compared across ten simulated bathymetry scenarios and one field area, each with different channel layouts. The results from simulations and field trials indicate that on average multi-vehicle PBACS outperforms lawnmower, UCB, and MVI based methods, especially when at least three vehicles are used.
Deep Model Predictive Variable Impedance Control
Sep 20, 2022
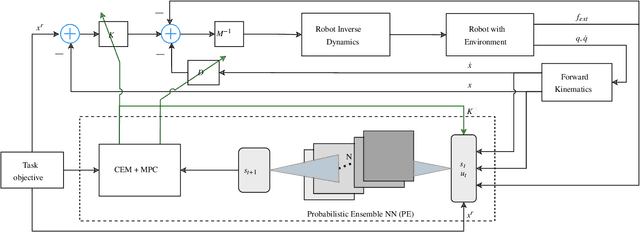
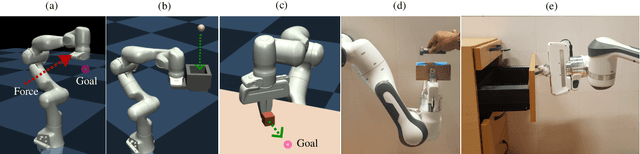
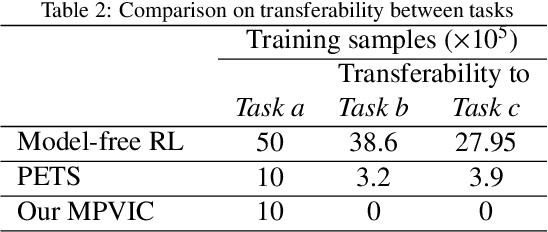
The capability to adapt compliance by varying muscle stiffness is crucial for dexterous manipulation skills in humans. Incorporating compliance in robot motor control is crucial to performing real-world force interaction tasks with human-level dexterity. This work presents a Deep Model Predictive Variable Impedance Controller for compliant robotic manipulation which combines Variable Impedance Control with Model Predictive Control (MPC). A generalized Cartesian impedance model of a robot manipulator is learned using an exploration strategy maximizing the information gain. This model is used within an MPC framework to adapt the impedance parameters of a low-level variable impedance controller to achieve the desired compliance behavior for different manipulation tasks without any retraining or finetuning. The deep Model Predictive Variable Impedance Control approach is evaluated using a Franka Emika Panda robotic manipulator operating on different manipulation tasks in simulations and real experiments. The proposed approach was compared with model-free and model-based reinforcement approaches in variable impedance control for transferability between tasks and performance.
Facial Information Analysis Technology for Gender and Age Estimation
Nov 17, 2021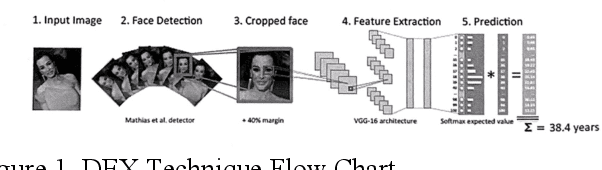
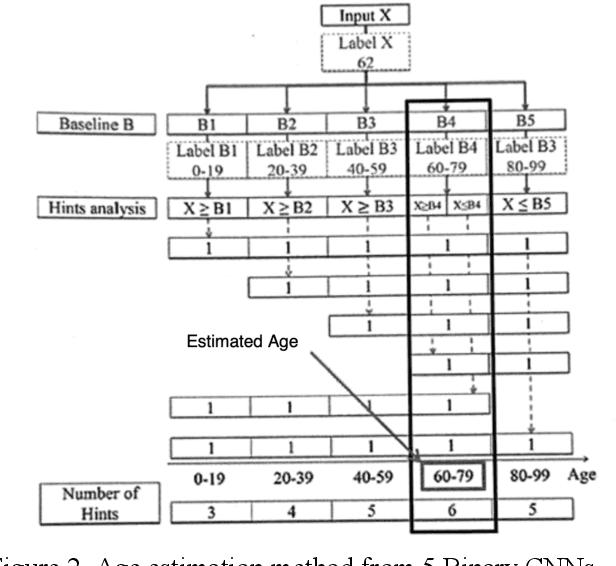
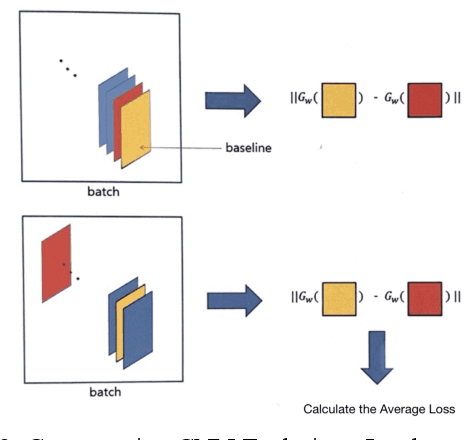
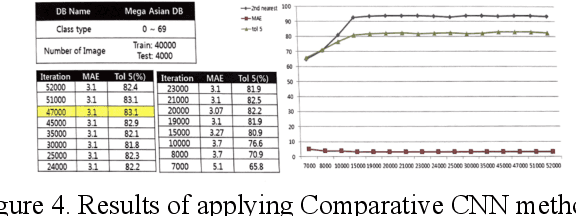
This is a study on facial information analysis technology for estimating gender and age, and poses are estimated using a transformation relationship matrix between the camera coordinate system and the world coordinate system for estimating the pose of a face image. Gender classification was relatively simple compared to age estimation, and age estimation was made possible using deep learning-based facial recognition technology. A comparative CNN was proposed to calculate the experimental results using the purchased database and the public database, and deep learning-based gender classification and age estimation performed at a significant level and was more robust to environmental changes compared to the existing machine learning techniques.
Facilitating Global Team Meetings Between Language-Based Subgroups: When and How Can Machine Translation Help?
Sep 07, 2022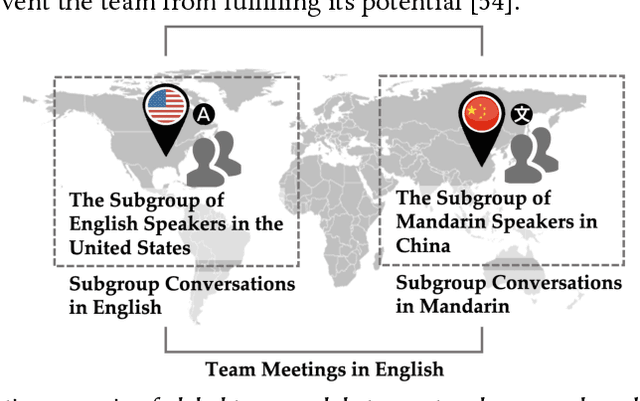
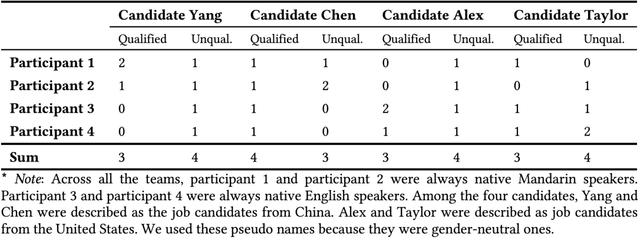

Global teams frequently consist of language-based subgroups who put together complementary information to achieve common goals. Previous research outlines a two-step work communication flow in these teams. There are team meetings using a required common language (i.e., English); in preparation for those meetings, people have subgroup conversations in their native languages. Work communication at team meetings is often less effective than in subgroup conversations. In the current study, we investigate the idea of leveraging machine translation (MT) to facilitate global team meetings. We hypothesize that exchanging subgroup conversation logs before a team meeting offers contextual information that benefits teamwork at the meeting. MT can translate these logs, which enables comprehension at a low cost. To test our hypothesis, we conducted a between-subjects experiment where twenty quartets of participants performed a personnel selection task. Each quartet included two English native speakers (NS) and two non-native speakers (NNS) whose native language was Mandarin. All participants began the task with subgroup conversations in their native languages, then proceeded to team meetings in English. We manipulated the exchange of subgroup conversation logs prior to team meetings: with MT-mediated exchanges versus without. Analysis of participants' subjective experience, task performance, and depth of discussions as reflected through their conversational moves jointly indicates that team meeting quality improved when there were MT-mediated exchanges of subgroup conversation logs as opposed to no exchanges. We conclude with reflections on when and how MT could be applied to enhance global teamwork across a language barrier.
Centralized Feature Pyramid for Object Detection
Oct 05, 2022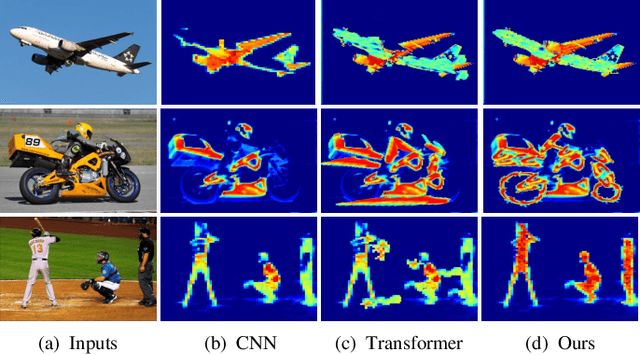
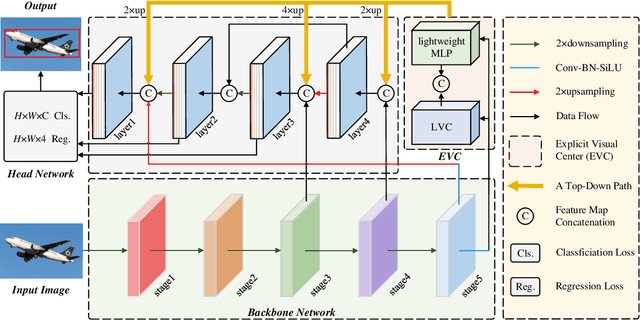
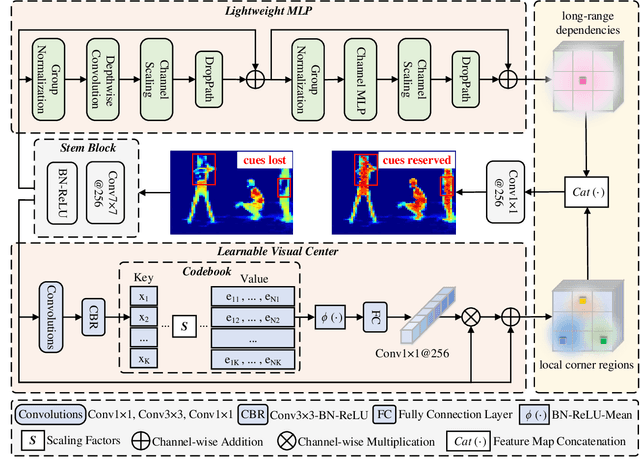
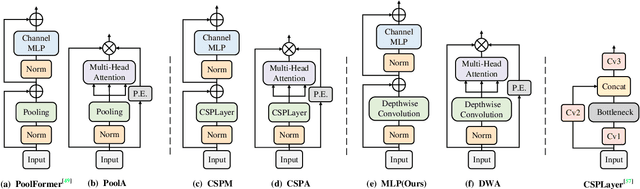
Visual feature pyramid has shown its superiority in both effectiveness and efficiency in a wide range of applications. However, the existing methods exorbitantly concentrate on the inter-layer feature interactions but ignore the intra-layer feature regulations, which are empirically proved beneficial. Although some methods try to learn a compact intra-layer feature representation with the help of the attention mechanism or the vision transformer, they ignore the neglected corner regions that are important for dense prediction tasks. To address this problem, in this paper, we propose a Centralized Feature Pyramid (CFP) for object detection, which is based on a globally explicit centralized feature regulation. Specifically, we first propose a spatial explicit visual center scheme, where a lightweight MLP is used to capture the globally long-range dependencies and a parallel learnable visual center mechanism is used to capture the local corner regions of the input images. Based on this, we then propose a globally centralized regulation for the commonly-used feature pyramid in a top-down fashion, where the explicit visual center information obtained from the deepest intra-layer feature is used to regulate frontal shallow features. Compared to the existing feature pyramids, CFP not only has the ability to capture the global long-range dependencies, but also efficiently obtain an all-round yet discriminative feature representation. Experimental results on the challenging MS-COCO validate that our proposed CFP can achieve the consistent performance gains on the state-of-the-art YOLOv5 and YOLOX object detection baselines.
Learning Cost-maps Made Easy
Sep 26, 2022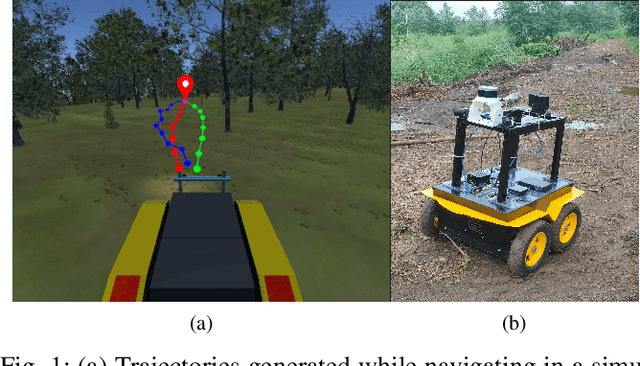
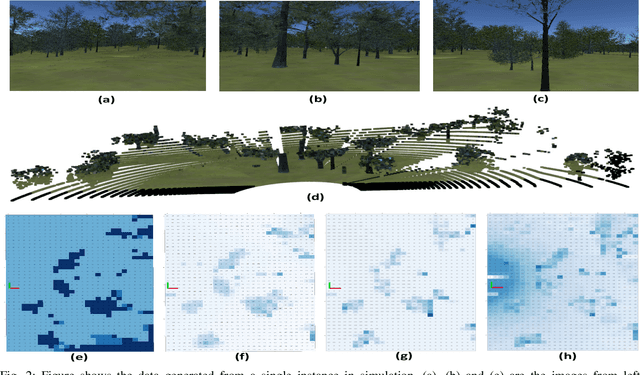
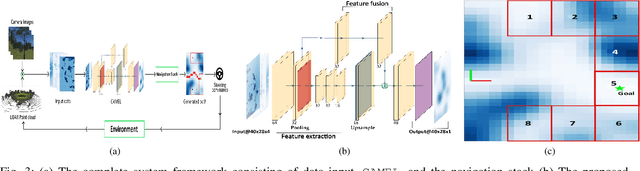
Cost-maps are used by robotic vehicles to plan collision-free paths. The cost associated with each cell in the map represents the sensed environment information which is often determined manually after several trial-and-error efforts. In off-road environments, due to the presence of several types of features, it is challenging to handcraft the cost values associated with each feature. Moreover, different handcrafted cost values can lead to different paths for the same environment which is not desirable. In this paper, we address the problem of learning the cost-map values from the sensed environment for robust vehicle path planning. We propose a novel framework called as CAMEL using deep learning approach that learns the parameters through demonstrations yielding an adaptive and robust cost-map for path planning. CAMEL has been trained on multi-modal datasets such as RELLIS-3D. The evaluation of CAMEL is carried out on an off-road scene simulator (MAVS) and on field data from IISER-B campus. We also perform realworld implementation of CAMEL on a ground rover. The results shows flexible and robust motion of the vehicle without collisions in unstructured terrains.
Improving Micro-video Recommendation by Controlling Position Bias
Aug 09, 2022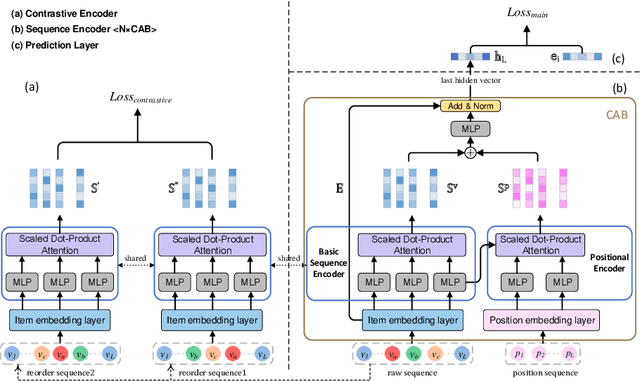
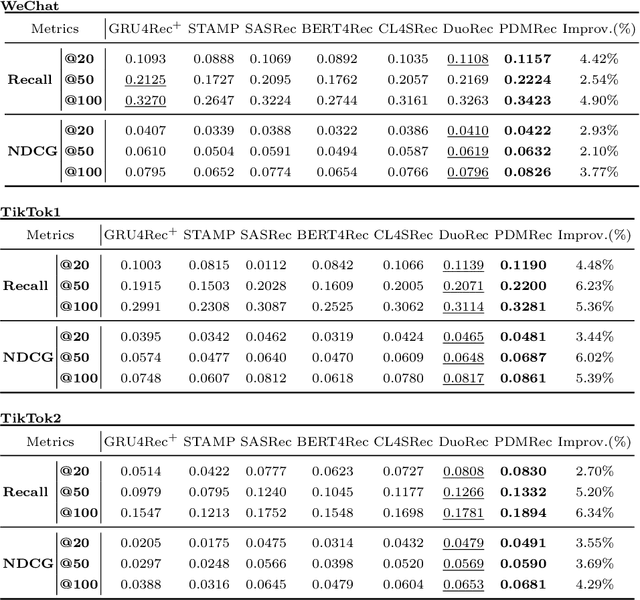
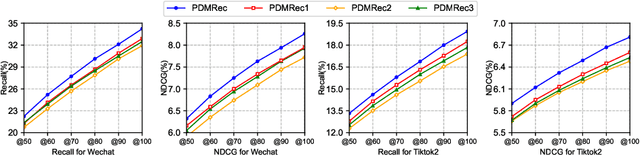
As the micro-video apps become popular, the numbers of micro-videos and users increase rapidly, which highlights the importance of micro-video recommendation. Although the micro-video recommendation can be naturally treated as the sequential recommendation, the previous sequential recommendation models do not fully consider the characteristics of micro-video apps, and in their inductive biases, the role of positions is not in accord with the reality in the micro-video scenario. Therefore, in the paper, we present a model named PDMRec (Position Decoupled Micro-video Recommendation). PDMRec applies separate self-attention modules to model micro-video information and the positional information and then aggregate them together, avoid the noisy correlations between micro-video semantics and positional information being encoded into the sequence embeddings. Moreover, PDMRec proposes contrastive learning strategies which closely match with the characteristics of the micro-video scenario, thus reducing the interference from micro-video positions in sequences. We conduct the extensive experiments on two real-world datasets. The experimental results shows that PDMRec outperforms existing multiple state-of-the-art models and achieves significant performance improvements.