 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Mutual information neural estimation for unsupervised multi-modal registration of brain images
Jan 25, 2022
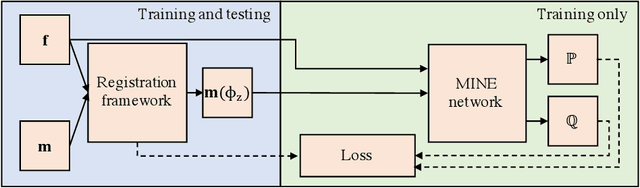
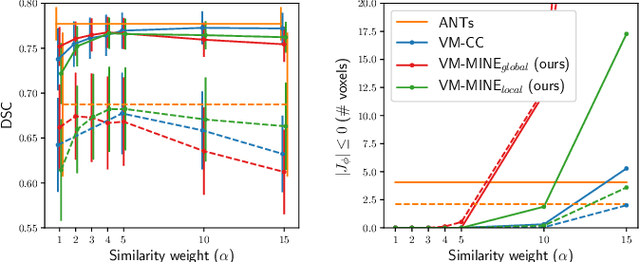
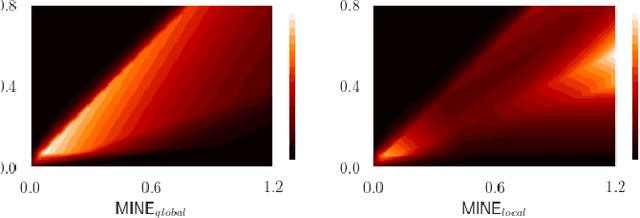
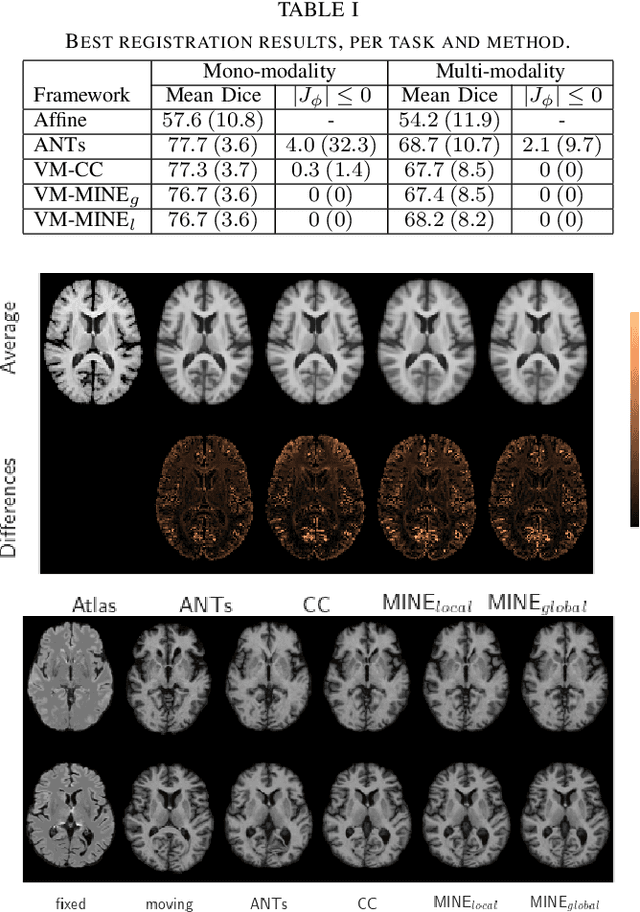
Many applications in image-guided surgery and therapy require fast and reliable non-linear, multi-modal image registration. Recently proposed unsupervised deep learning-based registration methods have demonstrated superior performance compared to iterative methods in just a fraction of the time. Most of the learning-based methods have focused on mono-modal image registration. The extension to multi-modal registration depends on the use of an appropriate similarity function, such as the mutual information (MI). We propose guiding the training of a deep learning-based registration method with MI estimation between an image-pair in an end-to-end trainable network. Our results show that a small, 2-layer network produces competitive results in both mono- and multimodal registration, with sub-second run-times. Comparisons to both iterative and deep learning-based methods show that our MI-based method produces topologically and qualitatively superior results with an extremely low rate of non-diffeomorphic transformations. Real-time clinical application will benefit from a better visual matching of anatomical structures and less registration failures/outliers.
Dialog Acts for Task-Driven Embodied Agents
Sep 26, 2022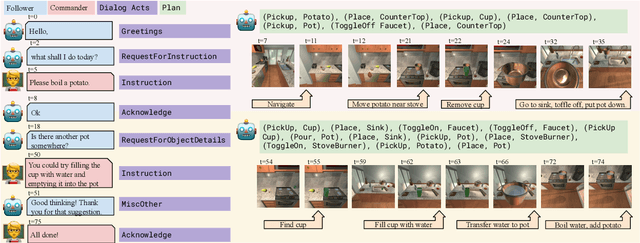
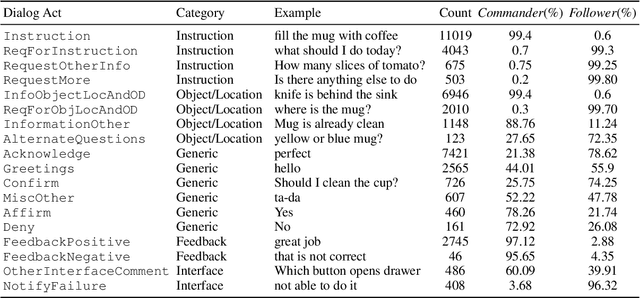

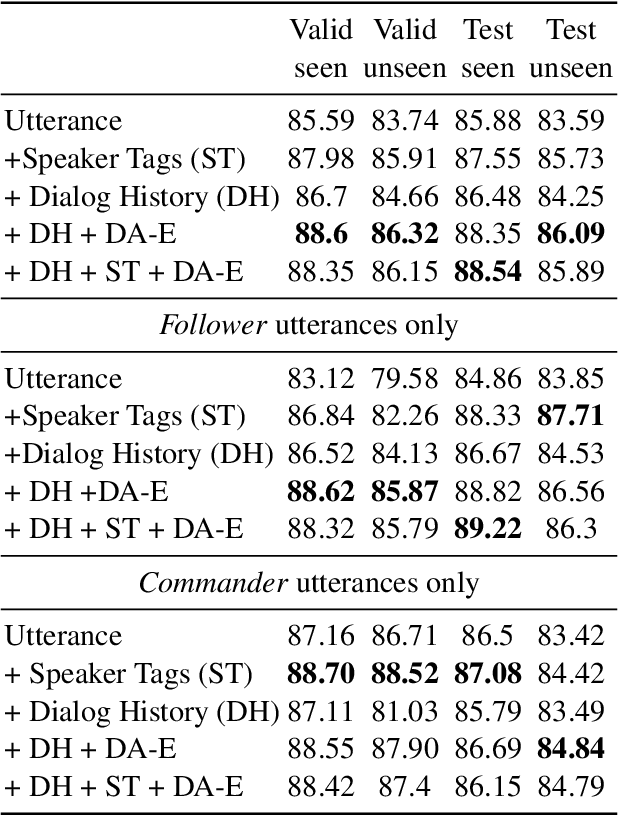
Embodied agents need to be able to interact in natural language understanding task descriptions and asking appropriate follow up questions to obtain necessary information to be effective at successfully accomplishing tasks for a wide range of users. In this work, we propose a set of dialog acts for modelling such dialogs and annotate the TEACh dataset that includes over 3,000 situated, task oriented conversations (consisting of 39.5k utterances in total) with dialog acts. TEACh-DA is one of the first large scale dataset of dialog act annotations for embodied task completion. Furthermore, we demonstrate the use of this annotated dataset in training models for tagging the dialog acts of a given utterance, predicting the dialog act of the next response given a dialog history, and use the dialog acts to guide agent's non-dialog behaviour. In particular, our experiments on the TEACh Execution from Dialog History task where the model predicts the sequence of low level actions to be executed in the environment for embodied task completion, demonstrate that dialog acts can improve end task success rate by up to 2 points compared to the system without dialog acts.
Improving Micro-video Recommendation by Controlling Position Bias
Aug 09, 2022
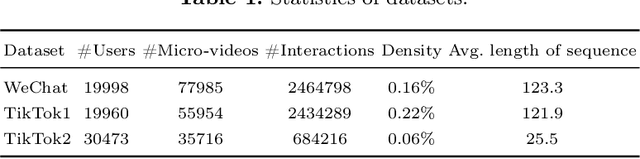
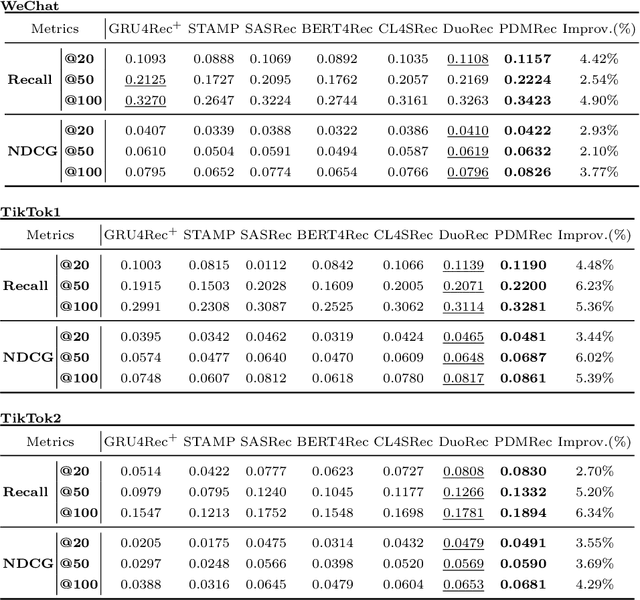
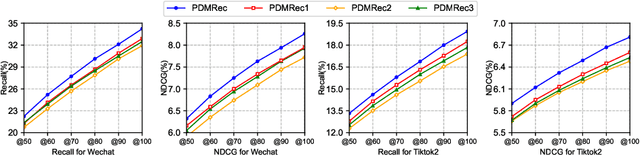
As the micro-video apps become popular, the numbers of micro-videos and users increase rapidly, which highlights the importance of micro-video recommendation. Although the micro-video recommendation can be naturally treated as the sequential recommendation, the previous sequential recommendation models do not fully consider the characteristics of micro-video apps, and in their inductive biases, the role of positions is not in accord with the reality in the micro-video scenario. Therefore, in the paper, we present a model named PDMRec (Position Decoupled Micro-video Recommendation). PDMRec applies separate self-attention modules to model micro-video information and the positional information and then aggregate them together, avoid the noisy correlations between micro-video semantics and positional information being encoded into the sequence embeddings. Moreover, PDMRec proposes contrastive learning strategies which closely match with the characteristics of the micro-video scenario, thus reducing the interference from micro-video positions in sequences. We conduct the extensive experiments on two real-world datasets. The experimental results shows that PDMRec outperforms existing multiple state-of-the-art models and achieves significant performance improvements.
TwHIN-BERT: A Socially-Enriched Pre-trained Language Model for Multilingual Tweet Representations
Sep 15, 2022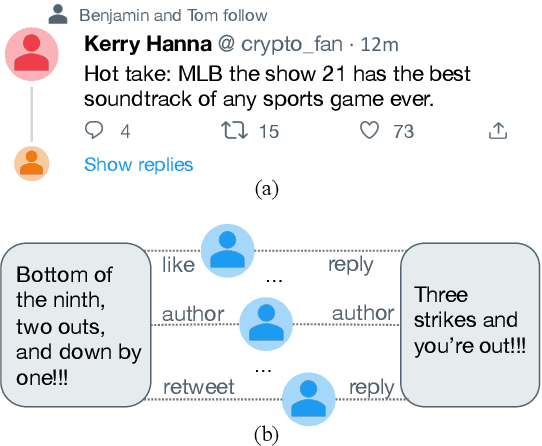
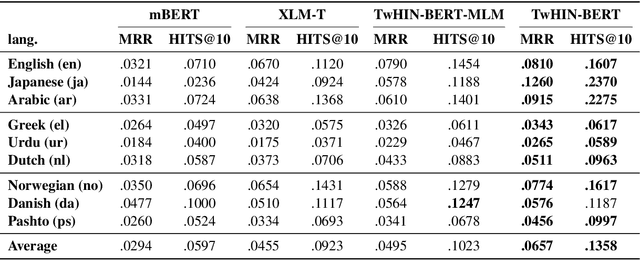
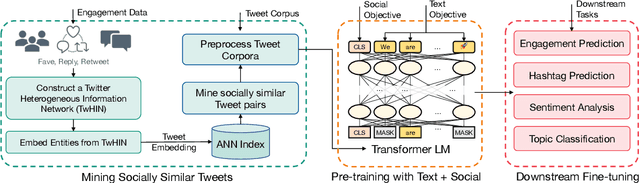
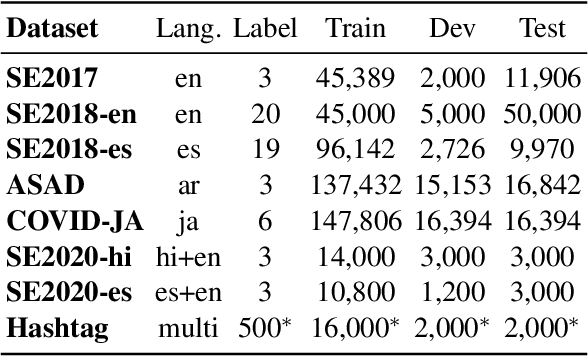
We present TwHIN-BERT, a multilingual language model trained on in-domain data from the popular social network Twitter. TwHIN-BERT differs from prior pre-trained language models as it is trained with not only text-based self-supervision, but also with a social objective based on the rich social engagements within a Twitter heterogeneous information network (TwHIN). Our model is trained on 7 billion tweets covering over 100 distinct languages providing a valuable representation to model short, noisy, user-generated text. We evaluate our model on a variety of multilingual social recommendation and semantic understanding tasks and demonstrate significant metric improvement over established pre-trained language models. We will freely open-source TwHIN-BERT and our curated hashtag prediction and social engagement benchmark datasets to the research community.
Center Feature Fusion: Selective Multi-Sensor Fusion of Center-based Objects
Sep 26, 2022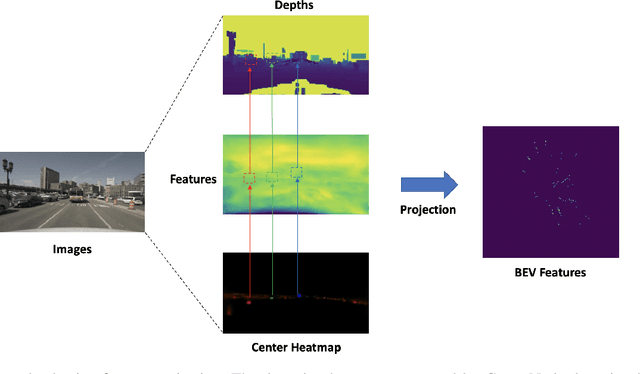
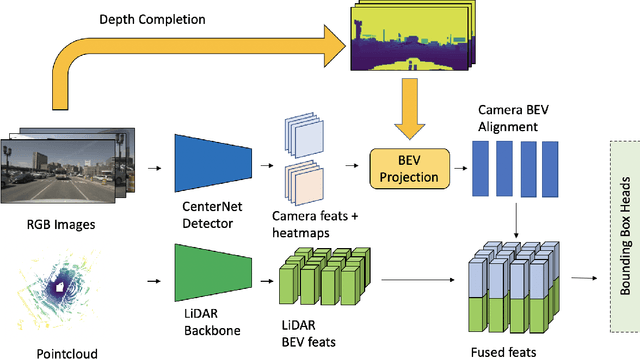

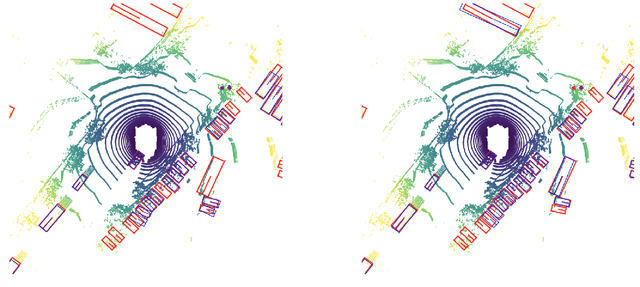
Leveraging multi-modal fusion, especially between camera and LiDAR, has become essential for building accurate and robust 3D object detection systems for autonomous vehicles. Until recently, point decorating approaches, in which point clouds are augmented with camera features, have been the dominant approach in the field. However, these approaches fail to utilize the higher resolution images from cameras. Recent works projecting camera features to the bird's-eye-view (BEV) space for fusion have also been proposed, however they require projecting millions of pixels, most of which only contain background information. In this work, we propose a novel approach Center Feature Fusion (CFF), in which we leverage center-based detection networks in both the camera and LiDAR streams to identify relevant object locations. We then use the center-based detection to identify the locations of pixel features relevant to object locations, a small fraction of the total number in the image. These are then projected and fused in the BEV frame. On the nuScenes dataset, we outperform the LiDAR-only baseline by 4.9% mAP while fusing up to 100x fewer features than other fusion methods.
Paging with Succinct Predictions
Oct 06, 2022Paging is a prototypical problem in the area of online algorithms. It has also played a central role in the development of learning-augmented algorithms -- a recent line of research that aims to ameliorate the shortcomings of classical worst-case analysis by giving algorithms access to predictions. Such predictions can typically be generated using a machine learning approach, but they are inherently imperfect. Previous work on learning-augmented paging has investigated predictions on (i) when the current page will be requested again (reoccurrence predictions), (ii) the current state of the cache in an optimal algorithm (state predictions), (iii) all requests until the current page gets requested again, and (iv) the relative order in which pages are requested. We study learning-augmented paging from the new perspective of requiring the least possible amount of predicted information. More specifically, the predictions obtained alongside each page request are limited to one bit only. We consider two natural such setups: (i) discard predictions, in which the predicted bit denotes whether or not it is ``safe'' to evict this page, and (ii) phase predictions, where the bit denotes whether the current page will be requested in the next phase (for an appropriate partitioning of the input into phases). We develop algorithms for each of the two setups that satisfy all three desirable properties of learning-augmented algorithms -- that is, they are consistent, robust and smooth -- despite being limited to a one-bit prediction per request. We also present lower bounds establishing that our algorithms are essentially best possible.
Large-Scale Multi-Document Summarization with Information Extraction and Compression
May 01, 2022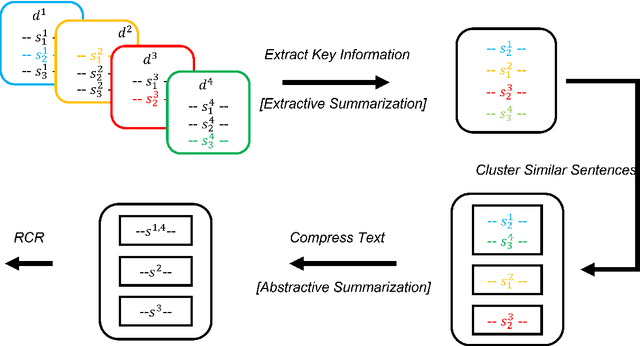
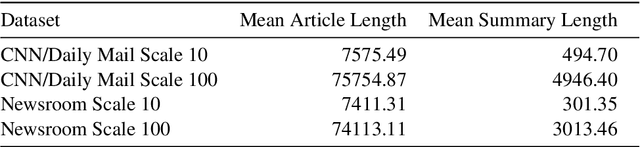
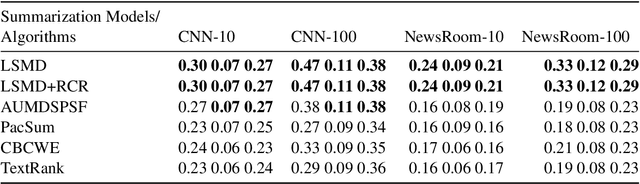
We develop an abstractive summarization framework independent of labeled data for multiple heterogeneous documents. Unlike existing multi-document summarization methods, our framework processes documents telling different stories instead of documents on the same topic. We also enhance an existing sentence fusion method with a uni-directional language model to prioritize fused sentences with higher sentence probability with the goal of increasing readability. Lastly, we construct a total of twelve dataset variations based on CNN/Daily Mail and the NewsRoom datasets, where each document group contains a large and diverse collection of documents to evaluate the performance of our model in comparison with other baseline systems. Our experiments demonstrate that our framework outperforms current state-of-the-art methods in this more generic setting.
SVNet: Where SO(3) Equivariance Meets Binarization on Point Cloud Representation
Sep 20, 2022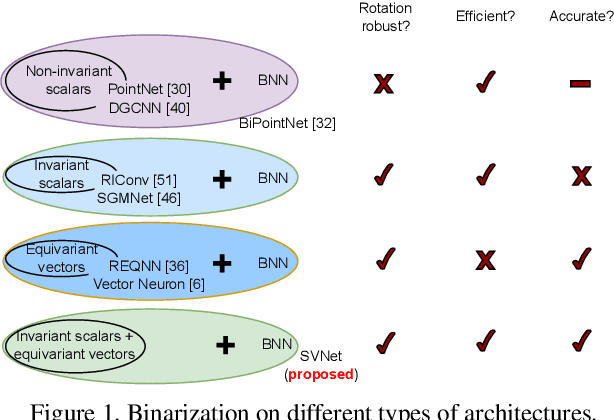


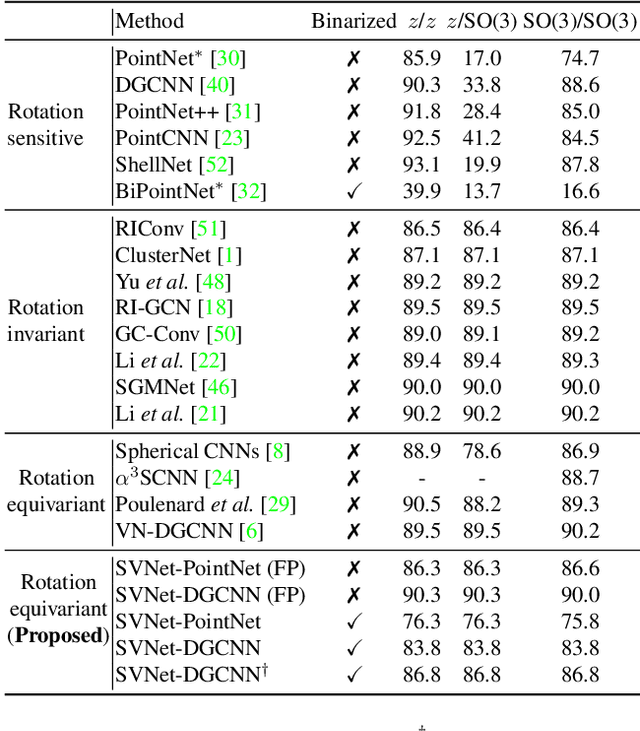
Efficiency and robustness are increasingly needed for applications on 3D point clouds, with the ubiquitous use of edge devices in scenarios like autonomous driving and robotics, which often demand real-time and reliable responses. The paper tackles the challenge by designing a general framework to construct 3D learning architectures with SO(3) equivariance and network binarization. However, a naive combination of equivariant networks and binarization either causes sub-optimal computational efficiency or geometric ambiguity. We propose to locate both scalar and vector features in our networks to avoid both cases. Precisely, the presence of scalar features makes the major part of the network binarizable, while vector features serve to retain rich structural information and ensure SO(3) equivariance. The proposed approach can be applied to general backbones like PointNet and DGCNN. Meanwhile, experiments on ModelNet40, ShapeNet, and the real-world dataset ScanObjectNN, demonstrated that the method achieves a great trade-off between efficiency, rotation robustness, and accuracy. The codes are available at https://github.com/zhuoinoulu/svnet.
Physics-based Digital Twins for Autonomous Thermal Food Processing: Efficient, Non-intrusive Reduced-order Modeling
Sep 07, 2022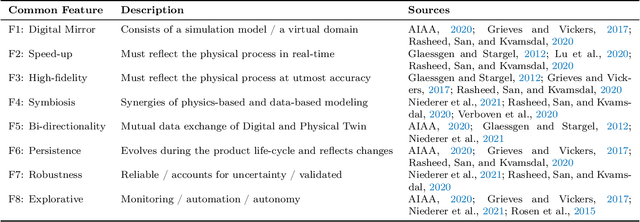
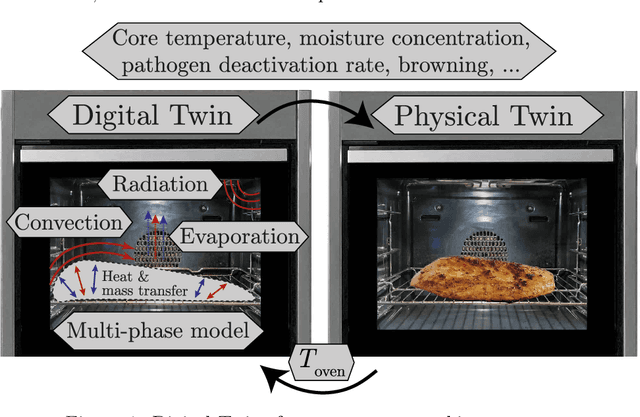

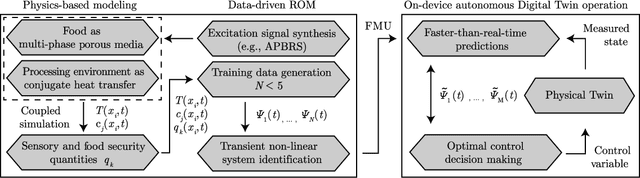
One possible way of making thermal processing controllable is to gather real-time information on the product's current state. Often, sensory equipment cannot capture all relevant information easily or at all. Digital Twins close this gap with virtual probes in real-time simulations, synchronized with the process. This paper proposes a physics-based, data-driven Digital Twin framework for autonomous food processing. We suggest a lean Digital Twin concept that is executable at the device level, entailing minimal computational load, data storage, and sensor data requirements. This study focuses on a parsimonious experimental design for training non-intrusive reduced-order models (ROMs) of a thermal process. A correlation ($R=-0.76$) between a high standard deviation of the surface temperatures in the training data and a low root mean square error in ROM testing enables efficient selection of training data. The mean test root mean square error of the best ROM is less than 1 Kelvin (0.2 % mean average percentage error) on representative test sets. Simulation speed-ups of Sp $\approx$ 1.8E4 allow on-device model predictive control. The proposed Digital Twin framework is designed to be applicable within the industry. Typically, non-intrusive reduced-order modeling is required as soon as the modeling of the process is performed in software, where root-level access to the solver is not provided, such as commercial simulation software. The data-driven training of the reduced-order model is achieved with only one data set, as correlations are utilized to predict the training success a priori.
Neighborhood-aware Scalable Temporal Network Representation Learning
Sep 05, 2022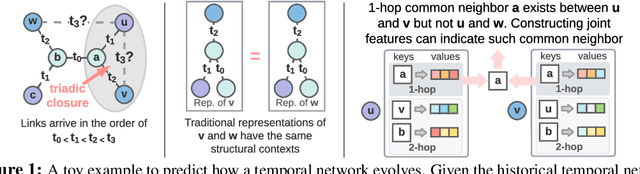
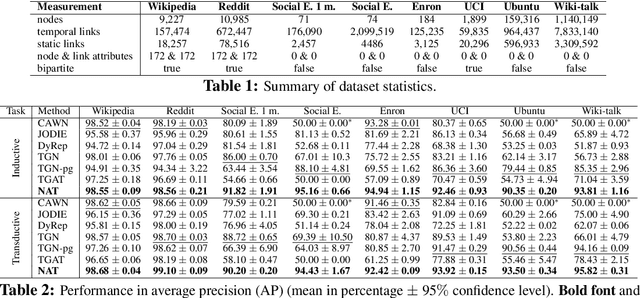
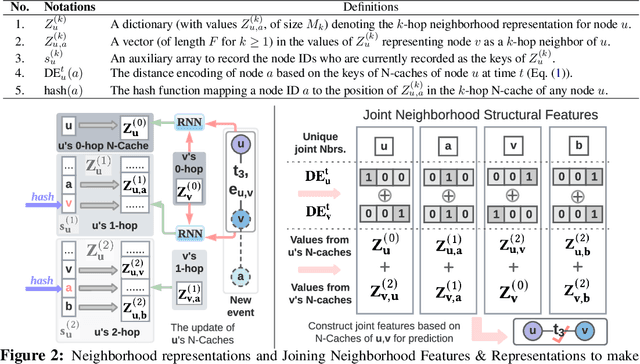
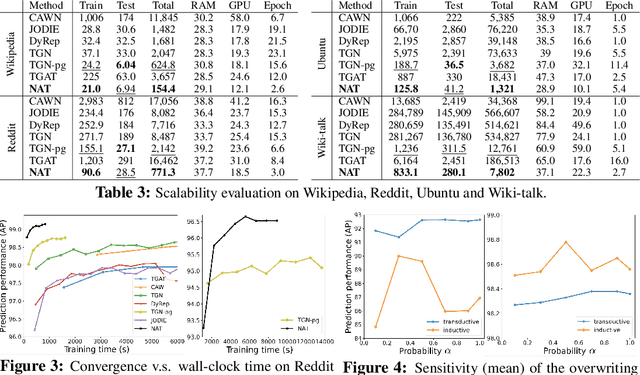
Temporal networks have been widely used to model real-world complex systems such as financial systems and e-commerce systems. In a temporal network, the joint neighborhood of a set of nodes often provides crucial structural information on predicting whether they may interact at a certain time. However, recent representation learning methods for temporal networks often fail to extract such information or depend on extremely time-consuming feature construction approaches. To address the issue, this work proposes Neighborhood-Aware Temporal network model (NAT). For each node in the network, NAT abandons the commonly-used one-single-vector-based representation while adopting a novel dictionary-type neighborhood representation. Such a dictionary representation records a down-sampled set of the neighboring nodes as keys, and allows fast construction of structural features for a joint neighborhood of multiple nodes. We also design dedicated data structure termed N-cache to support parallel access and update of those dictionary representations on GPUs. NAT gets evaluated over seven real-world large-scale temporal networks. NAT not only outperforms all cutting-edge baselines by averaged 5.9% and 6.0% in transductive and inductive link prediction accuracy, respectively, but also keeps scalable by achieving a speed-up of 4.1-76.7x against the baselines that adopts joint structural features and achieves a speed-up of 1.6-4.0x against the baselines that cannot adopt those features. The link to the code: https://github.com/Graph-COM/Neighborhood-Aware-Temporal-Network.