 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Vec2Face-v2: Unveil Human Faces from their Blackbox Features via Attention-based Network in Face Recognition
Sep 11, 2022
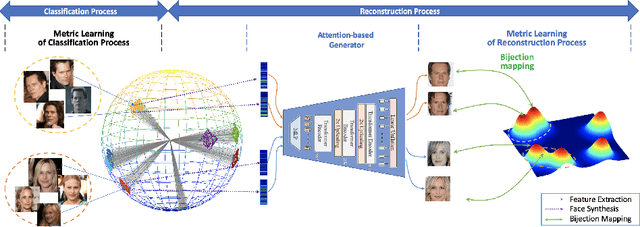

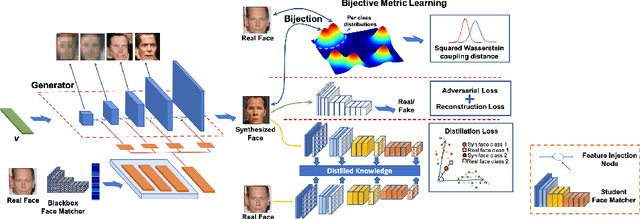
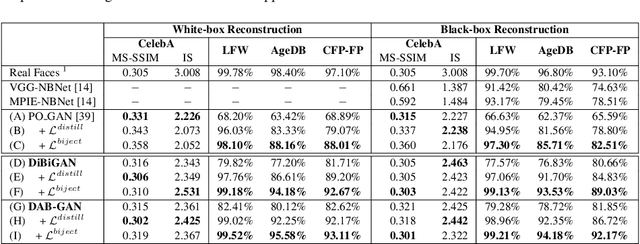
In this work, we investigate the problem of face reconstruction given a facial feature representation extracted from a blackbox face recognition engine. Indeed, it is very challenging problem in practice due to the limitations of abstracted information from the engine. We therefore introduce a new method named Attention-based Bijective Generative Adversarial Networks in a Distillation framework (DAB-GAN) to synthesize faces of a subject given his/her extracted face recognition features. Given any unconstrained unseen facial features of a subject, the DAB-GAN can reconstruct his/her faces in high definition. The DAB-GAN method includes a novel attention-based generative structure with the new defined Bijective Metrics Learning approach. The framework starts by introducing a bijective metric so that the distance measurement and metric learning process can be directly adopted in image domain for an image reconstruction task. The information from the blackbox face recognition engine will be optimally exploited using the global distillation process. Then an attention-based generator is presented for a highly robust generator to synthesize realistic faces with ID preservation. We have evaluated our method on the challenging face recognition databases, i.e. CelebA, LFW, AgeDB, CFP-FP, and consistently achieved the state-of-the-art results. The advancement of DAB-GAN is also proven on both image realism and ID preservation properties.
Self-Relation Attention and Temporal Awareness for Emotion Recognition via Vocal Burst
Sep 26, 2022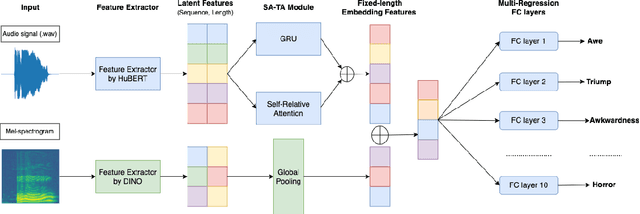

The technical report presents our emotion recognition pipeline for high-dimensional emotion task (A-VB High) in The ACII Affective Vocal Bursts (A-VB) 2022 Workshop \& Competition. Our proposed method contains three stages. Firstly, we extract the latent features from the raw audio signal and its Mel-spectrogram by self-supervised learning methods. Then, the features from the raw signal are fed to the self-relation attention and temporal awareness (SA-TA) module for learning the valuable information between these latent features. Finally, we concatenate all the features and utilize a fully-connected layer to predict each emotion's score. By empirical experiments, our proposed method achieves a mean concordance correlation coefficient (CCC) of 0.7295 on the test set, compared to 0.5686 on the baseline model. The code of our method is available at https://github.com/linhtd812/A-VB2022.
Guided-deconvolution for Correlative Light and Electron Microscopy
Aug 19, 2022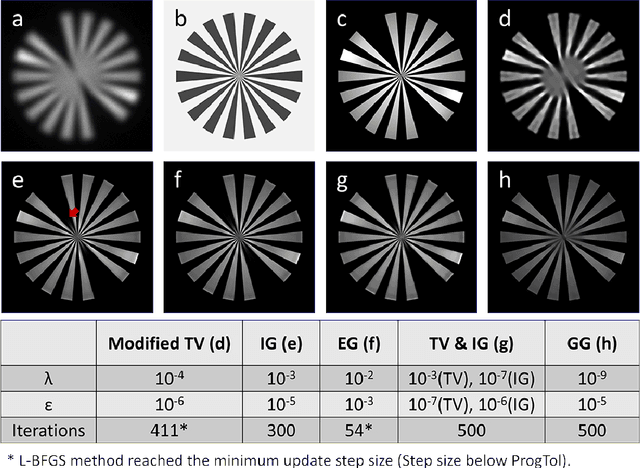
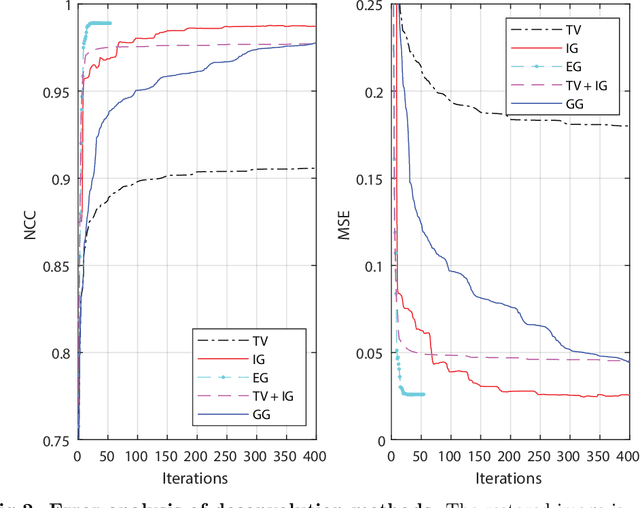

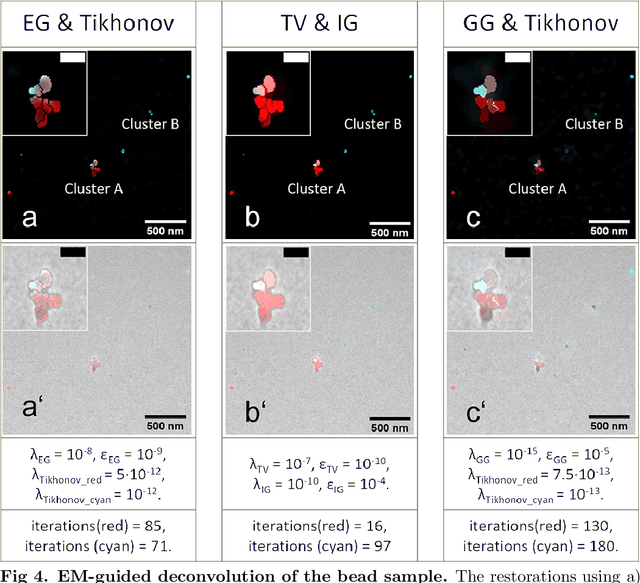
Correlative light and electron microscopy is a powerful tool to study the internal structure of cells. It combines the mutual benefit of correlating light (LM) and electron (EM) microscopy information. However, the classical approach of overlaying LM onto EM images to assign functional to structural information is hampered by the large discrepancy in structural detail visible in the LM images. This paper aims at investigating an optimized approach which we call EM-guided deconvolution. It attempts to automatically assign fluorescence-labelled structures to details visible in the EM image to bridge the gaps in both resolution and specificity between the two imaging modes.
PERI: Part Aware Emotion Recognition In The Wild
Oct 18, 2022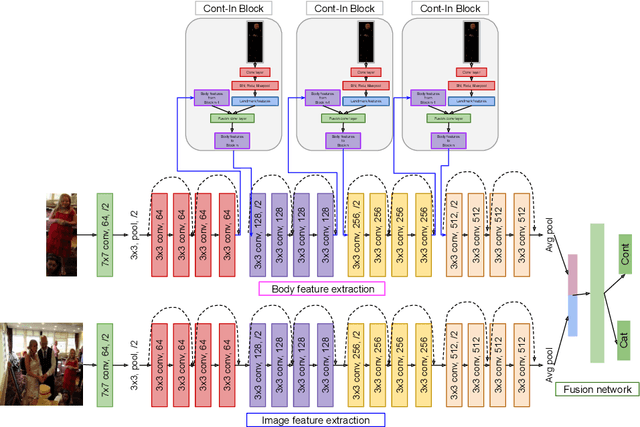
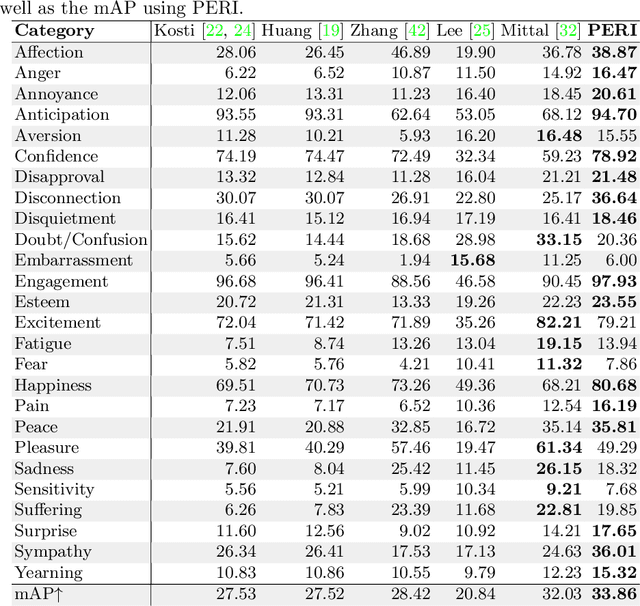
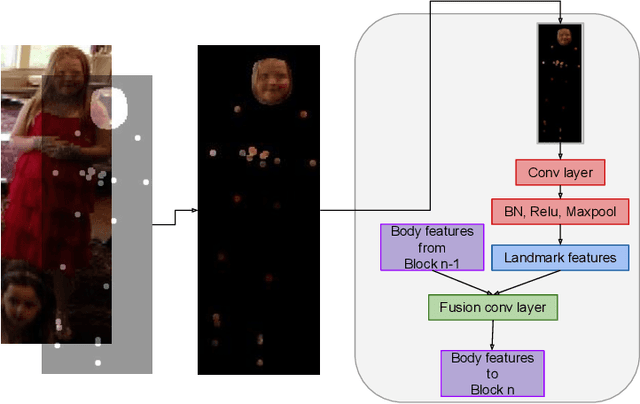
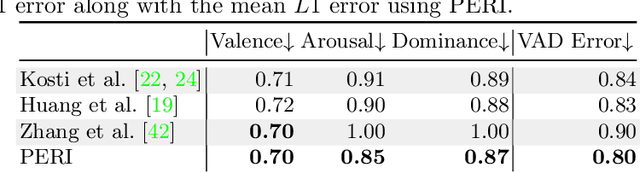
Emotion recognition aims to interpret the emotional states of a person based on various inputs including audio, visual, and textual cues. This paper focuses on emotion recognition using visual features. To leverage the correlation between facial expression and the emotional state of a person, pioneering methods rely primarily on facial features. However, facial features are often unreliable in natural unconstrained scenarios, such as in crowded scenes, as the face lacks pixel resolution and contains artifacts due to occlusion and blur. To address this, in the wild emotion recognition exploits full-body person crops as well as the surrounding scene context. In a bid to use body pose for emotion recognition, such methods fail to realize the potential that facial expressions, when available, offer. Thus, the aim of this paper is two-fold. First, we demonstrate our method, PERI, to leverage both body pose and facial landmarks. We create part aware spatial (PAS) images by extracting key regions from the input image using a mask generated from both body pose and facial landmarks. This allows us to exploit body pose in addition to facial context whenever available. Second, to reason from the PAS images, we introduce context infusion (Cont-In) blocks. These blocks attend to part-specific information, and pass them onto the intermediate features of an emotion recognition network. Our approach is conceptually simple and can be applied to any existing emotion recognition method. We provide our results on the publicly available in the wild EMOTIC dataset. Compared to existing methods, PERI achieves superior performance and leads to significant improvements in the mAP of emotion categories, while decreasing Valence, Arousal and Dominance errors. Importantly, we observe that our method improves performance in both images with fully visible faces as well as in images with occluded or blurred faces.
ToupleGDD: A Fine-Designed Solution of Influence Maximization by Deep Reinforcement Learning
Oct 18, 2022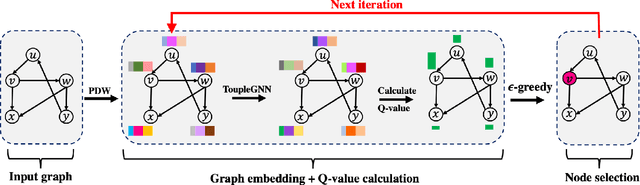
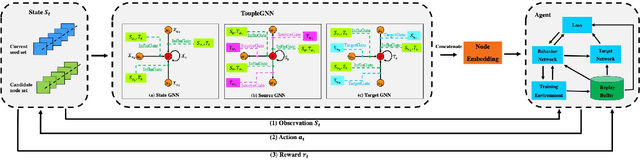
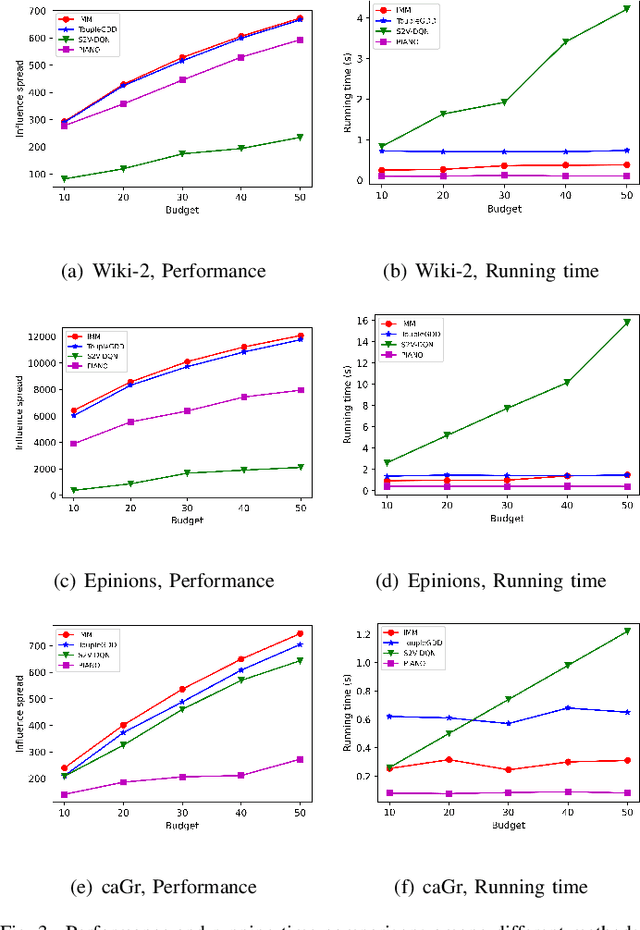
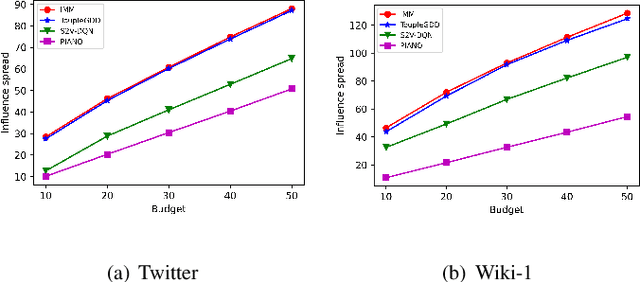
Online social platforms have become more and more popular, and the dissemination of information on social networks has attracted wide attention of the industries and academia. Aiming at selecting a small subset of nodes with maximum influence on networks, the Influence Maximization (IM) problem has been extensively studied. Since it is #P-hard to compute the influence spread given a seed set, the state-of-art methods, including heuristic and approximation algorithms, faced with great difficulties such as theoretical guarantee, time efficiency, generalization, etc. This makes it unable to adapt to large-scale networks and more complex applications. With the latest achievements of Deep Reinforcement Learning (DRL) in artificial intelligence and other fields, a lot of works has focused on exploiting DRL to solve the combinatorial optimization problems. Inspired by this, we propose a novel end-to-end DRL framework, ToupleGDD, to address the IM problem in this paper, which incorporates three coupled graph neural networks for network embedding and double deep Q-networks for parameters learning. Previous efforts to solve the IM problem with DRL trained their models on the subgraph of the whole network, and then tested their performance on the whole graph, which makes the performance of their models unstable among different networks. However, our model is trained on several small randomly generated graphs and tested on completely different networks, and can obtain results that are very close to the state-of-the-art methods. In addition, our model is trained with a small budget, and it can perform well under various large budgets in the test, showing strong generalization ability. Finally, we conduct entensive experiments on synthetic and realistic datasets, and the experimental results prove the effectiveness and superiority of our model.
$O(T^{-1})$ Convergence of Optimistic-Follow-the-Regularized-Leader in Two-Player Zero-Sum Markov Games
Sep 26, 2022We prove that optimistic-follow-the-regularized-leader (OFTRL), together with smooth value updates, finds an $O(T^{-1})$-approximate Nash equilibrium in $T$ iterations for two-player zero-sum Markov games with full information. This improves the $\tilde{O}(T^{-5/6})$ convergence rate recently shown in the paper Zhang et al (2022). The refined analysis hinges on two essential ingredients. First, the sum of the regrets of the two players, though not necessarily non-negative as in normal-form games, is approximately non-negative in Markov games. This property allows us to bound the second-order path lengths of the learning dynamics. Second, we prove a tighter algebraic inequality regarding the weights deployed by OFTRL that shaves an extra $\log T$ factor. This crucial improvement enables the inductive analysis that leads to the final $O(T^{-1})$ rate.
Model Selection in High-Dimensional Block-Sparse Linear Regression
Sep 03, 2022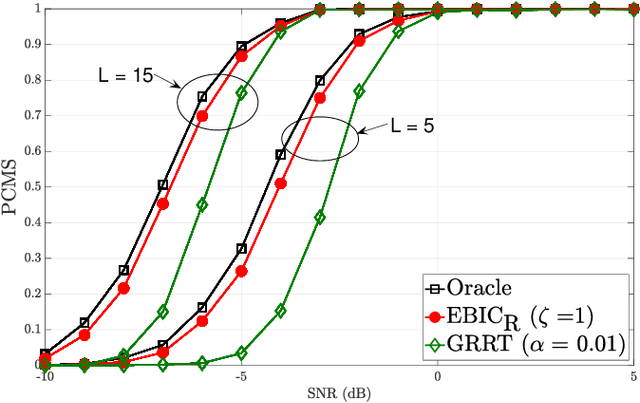
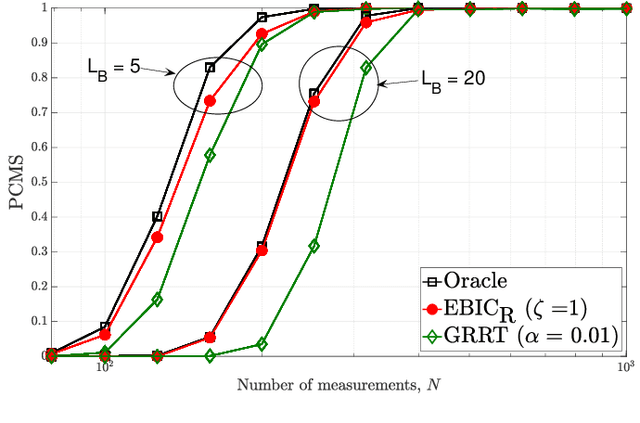
Model selection is an indispensable part of data analysis dealing very frequently with fitting and prediction purposes. In this paper, we tackle the problem of model selection in a general linear regression where the parameter matrix possesses a block-sparse structure, i.e., the non-zero entries occur in clusters or blocks and the number of such non-zero blocks is very small compared to the parameter dimension. Furthermore, a high-dimensional setting is considered where the parameter dimension is quite large compared to the number of available measurements. To perform model selection in this setting, we present an information criterion that is a generalization of the Extended Bayesian Information Criterion-Robust (EBIC-R) and it takes into account both the block structure and the high-dimensionality scenario. The analytical steps for deriving the EBIC-R for this setting are provided. Simulation results show that the proposed method performs considerably better than the existing state-of-the-art methods and achieves empirical consistency at large sample sizes and/or at high-SNR.
Look where you look! Saliency-guided Q-networks for visual RL tasks
Sep 29, 2022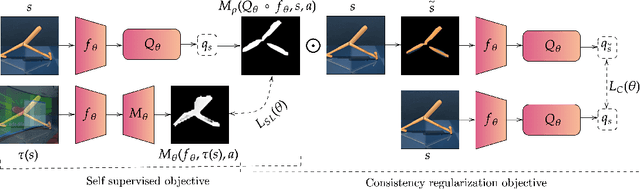
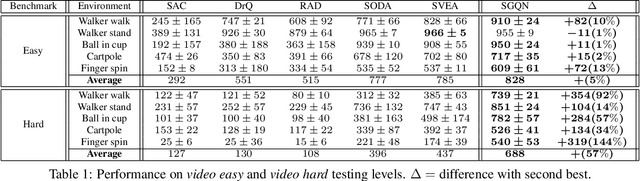

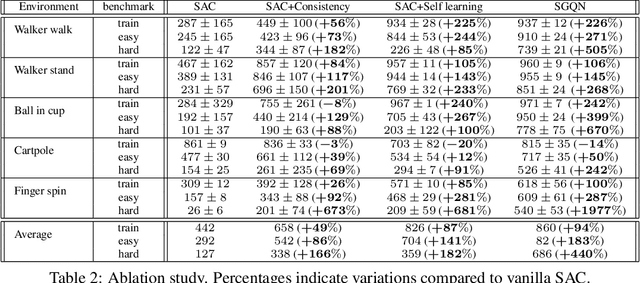
Deep reinforcement learning policies, despite their outstanding efficiency in simulated visual control tasks, have shown disappointing ability to generalize across disturbances in the input training images. Changes in image statistics or distracting background elements are pitfalls that prevent generalization and real-world applicability of such control policies. We elaborate on the intuition that a good visual policy should be able to identify which pixels are important for its decision, and preserve this identification of important sources of information across images. This implies that training of a policy with small generalization gap should focus on such important pixels and ignore the others. This leads to the introduction of saliency-guided Q-networks (SGQN), a generic method for visual reinforcement learning, that is compatible with any value function learning method. SGQN vastly improves the generalization capability of Soft Actor-Critic agents and outperforms existing stateof-the-art methods on the Deepmind Control Generalization benchmark, setting a new reference in terms of training efficiency, generalization gap, and policy interpretability.
Fuse: In-Situ Sensemaking Support in the Browser
Aug 31, 2022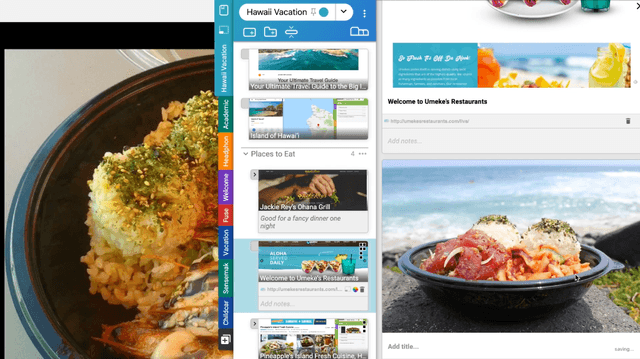

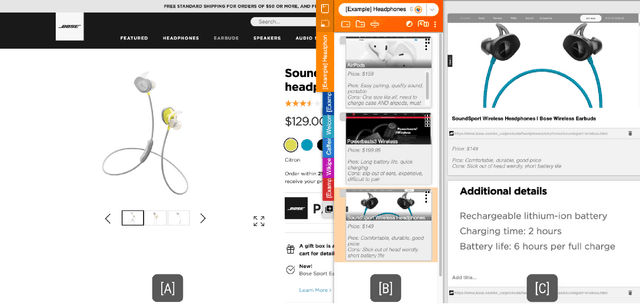
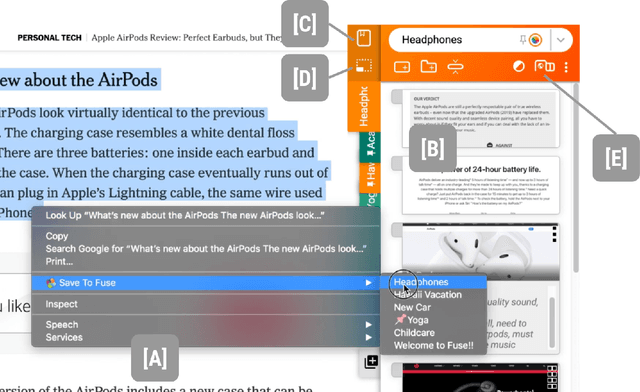
People spend a significant amount of time trying to make sense of the internet, collecting content from a variety of sources and organizing it to make decisions and achieve their goals. While humans are able to fluidly iterate on collecting and organizing information in their minds, existing tools and approaches introduce significant friction into the process. We introduce Fuse, a browser extension that externalizes users' working memory by combining low-cost collection with lightweight organization of content in a compact card-based sidebar that is always available. Fuse helps users simultaneously extract key web content and structure it in a lightweight and visual way. We discuss how these affordances help users externalize more of their mental model into the system (e.g., saving, annotating, and structuring items) and support fast reviewing and resumption of task contexts. Our 22-month public deployment and follow-up interviews provide longitudinal insights into the structuring behaviors of real-world users conducting information foraging tasks.
MOSAIC: Mobile Segmentation via decoding Aggregated Information and encoded Context
Dec 22, 2021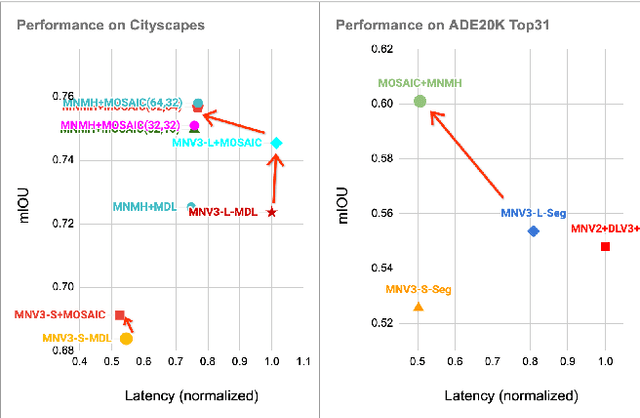
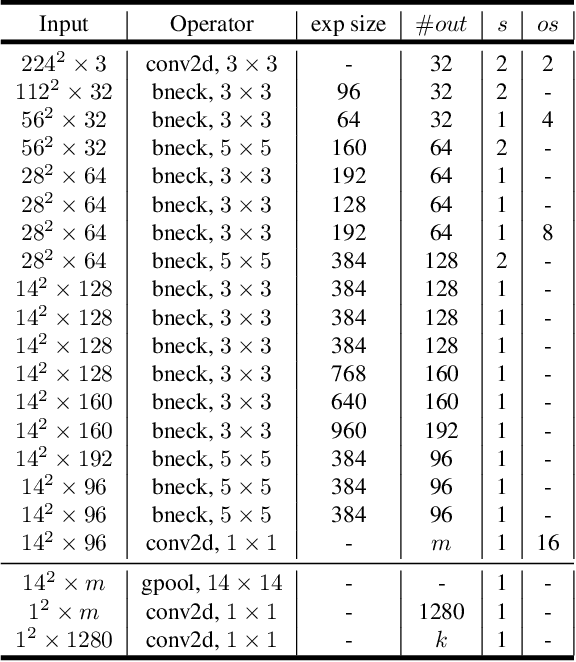
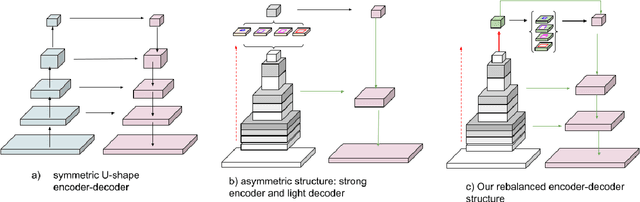
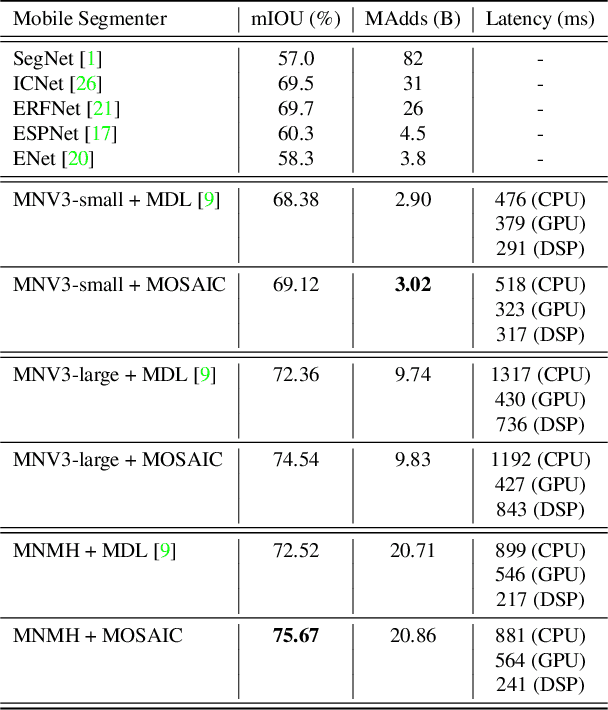
We present a next-generation neural network architecture, MOSAIC, for efficient and accurate semantic image segmentation on mobile devices. MOSAIC is designed using commonly supported neural operations by diverse mobile hardware platforms for flexible deployment across various mobile platforms. With a simple asymmetric encoder-decoder structure which consists of an efficient multi-scale context encoder and a light-weight hybrid decoder to recover spatial details from aggregated information, MOSAIC achieves new state-of-the-art performance while balancing accuracy and computational cost. Deployed on top of a tailored feature extraction backbone based on a searched classification network, MOSAIC achieves a 5% absolute accuracy gain surpassing the current industry standard MLPerf models and state-of-the-art architectures.