 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Cross-Geography Generalization of Machine Learning Methods for Classification of Flooded Regions in Aerial Images
Oct 04, 2022
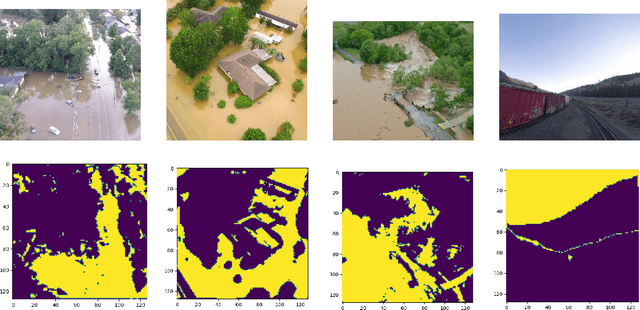
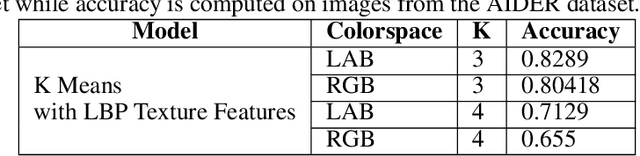
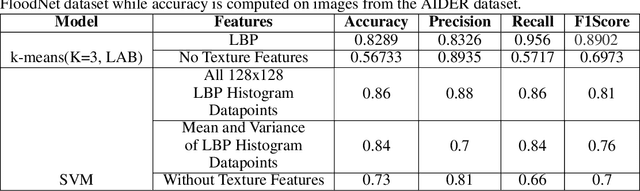
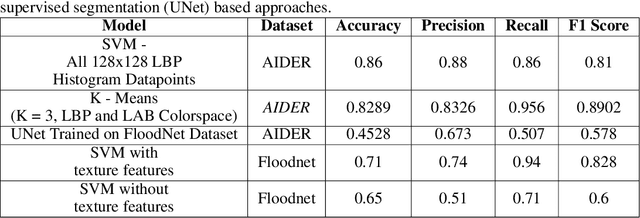
Identification of regions affected by floods is a crucial piece of information required for better planning and management of post-disaster relief and rescue efforts. Traditionally, remote sensing images are analysed to identify the extent of damage caused by flooding. The data acquired from sensors onboard earth observation satellites are analyzed to detect the flooded regions, which can be affected by low spatial and temporal resolution. However, in recent years, the images acquired from Unmanned Aerial Vehicles (UAVs) have also been utilized to assess post-disaster damage. Indeed, a UAV based platform can be rapidly deployed with a customized flight plan and minimum dependence on the ground infrastructure. This work proposes two approaches for identifying flooded regions in UAV aerial images. The first approach utilizes texture-based unsupervised segmentation to detect flooded areas, while the second uses an artificial neural network on the texture features to classify images as flooded and non-flooded. Unlike the existing works where the models are trained and tested on images of the same geographical regions, this work studies the performance of the proposed model in identifying flooded regions across geographical regions. An F1-score of 0.89 is obtained using the proposed segmentation-based approach which is higher than existing classifiers. The robustness of the proposed approach demonstrates that it can be utilized to identify flooded regions of any region with minimum or no user intervention.
Relation Embedding based Graph Neural Networks for Handling Heterogeneous Graph
Sep 23, 2022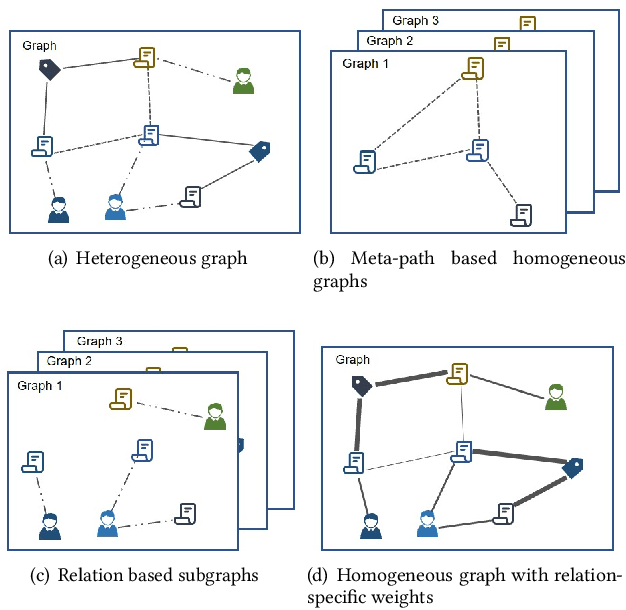
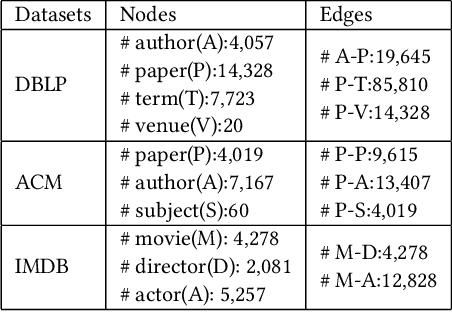
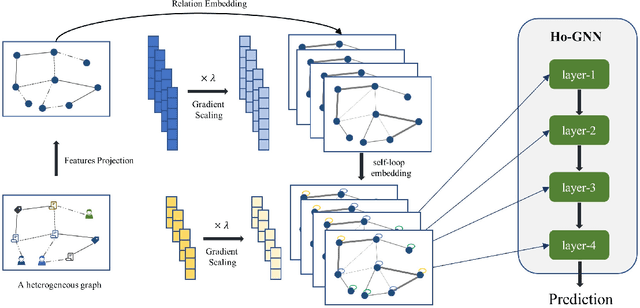
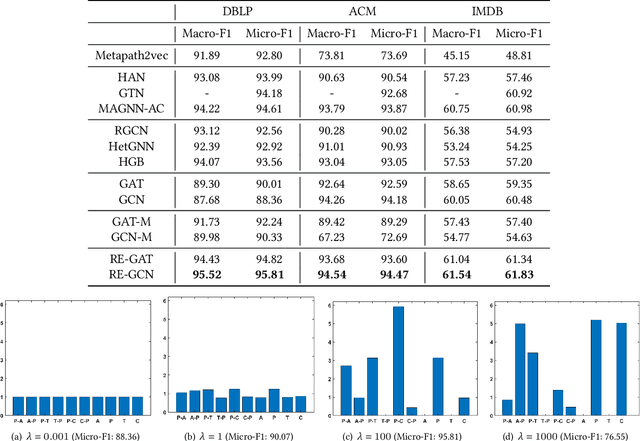
Heterogeneous graph learning has drawn significant attentions in recent years, due to the success of graph neural networks (GNNs) and the broad applications of heterogeneous information networks. Various heterogeneous graph neural networks have been proposed to generalize GNNs for processing the heterogeneous graphs. Unfortunately, these approaches model the heterogeneity via various complicated modules. This paper aims to propose a simple yet efficient framework to make the homogeneous GNNs have adequate ability to handle heterogeneous graphs. Specifically, we propose Relation Embedding based Graph Neural Networks (RE-GNNs), which employ only one parameter per relation to embed the importance of edge type relations and self-loop connections. To optimize these relation embeddings and the other parameters simultaneously, a gradient scaling factor is proposed to constrain the embeddings to converge to suitable values. Besides, we theoretically demonstrate that our RE-GNNs have more expressive power than the meta-path based heterogeneous GNNs. Extensive experiments on the node classification tasks validate the effectiveness of our proposed method.
Engineering Semantic Communication: A Survey
Aug 12, 2022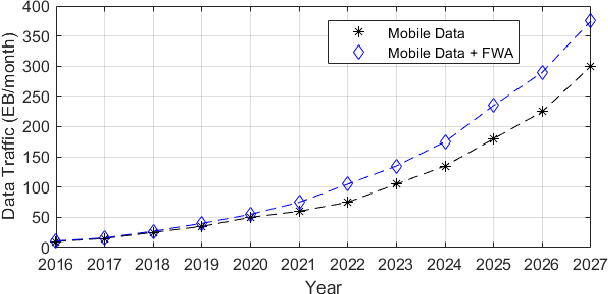

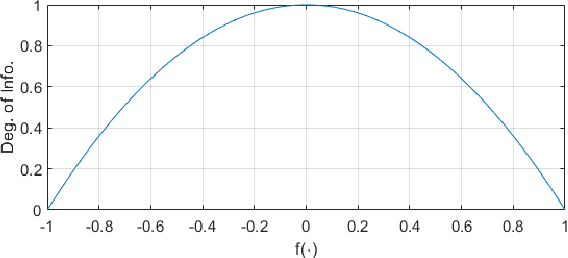
As the global demand for data has continued to rise exponentially, some have begun turning to the idea of semantic communication as a means of efficiently meeting this demand. Pushing beyond the boundaries of conventional communication systems, semantic communication focuses on the accurate recovery of the meaning conveyed from source to receiver, as opposed to the accurate recovery of transmitted symbols. In this work, we aim to provide a comprehensive view of the history and current state of semantic communication and the techniques for engineering this higher level of communication. A survey of the current literature reveals four broad approaches to engineering semantic communication. We term the earliest of these approaches classical semantic information, which seeks to extend information-theoretic results to include semantic information. A second approach makes use of knowledge graphs to achieve semantic communication, and a third utilizes the power of modern deep learning techniques to facilitate this communication. The fourth approach focuses on the significance of information, rather than its meaning, to achieve efficient, goal-oriented communication. We discuss each of these four approaches and their corresponding works in detail, and provide some challenges and opportunities that pertain to each approach. Finally, we introduce a novel approach to semantic communication, which we term context-based semantic communication. Inspired by the way in which humans naturally communicate with one another, this context-based approach provides a general, optimization-based design framework for semantic communication systems. Together, this survey provides a useful guide for the design and implementation of semantic communication systems.
An Ontology for Defect Detection in Metal Additive Manufacturing
Sep 29, 2022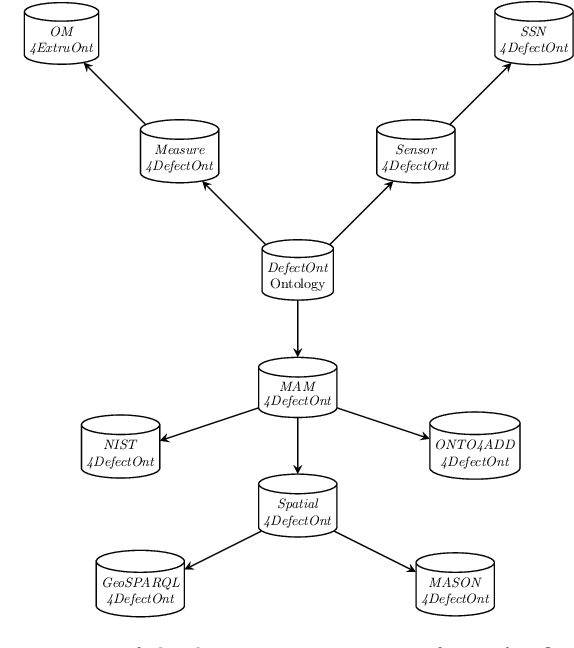
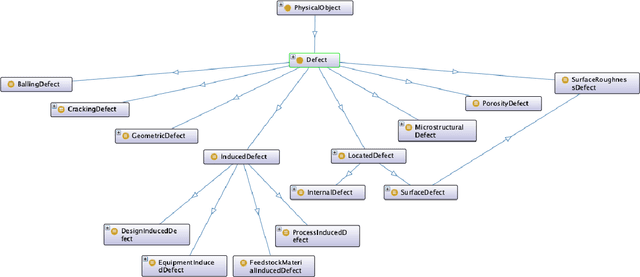

A key challenge for Industry 4.0 applications is to develop control systems for automated manufacturing services that are capable of addressing both data integration and semantic interoperability issues, as well as monitoring and decision making tasks. To address such an issue in advanced manufacturing systems, principled knowledge representation approaches based on formal ontologies have been proposed as a foundation to information management and maintenance in presence of heterogeneous data sources. In addition, ontologies provide reasoning and querying capabilities to aid domain experts and end users in the context of constraint validation and decision making. Finally, ontology-based approaches to advanced manufacturing services can support the explainability and interpretability of the behaviour of monitoring, control, and simulation systems that are based on black-box machine learning algorithms. In this work, we provide a novel ontology for the classification of process-induced defects known from the metal additive manufacturing literature. Together with a formal representation of the characterising features and sources of defects, we integrate our knowledge base with state-of-the-art ontologies in the field. Our knowledge base aims at enhancing the modelling capabilities of additive manufacturing ontologies by adding further defect analysis terminology and diagnostic inference features.
Soft-labeling Strategies for Rapid Sub-Typing
Sep 23, 2022

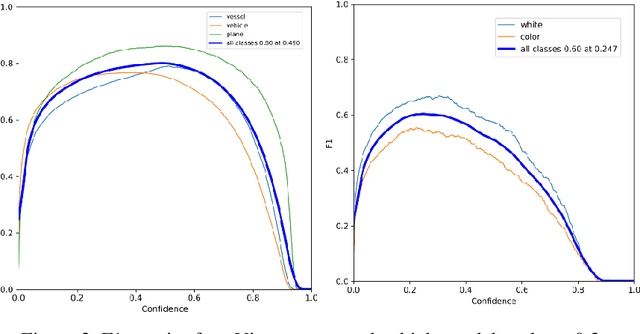

The challenge of labeling large example datasets for computer vision continues to limit the availability and scope of image repositories. This research provides a new method for automated data collection, curation, labeling, and iterative training with minimal human intervention for the case of overhead satellite imagery and object detection. The new operational scale effectively scanned an entire city (68 square miles) in grid search and yielded a prediction of car color from space observations. A partially trained yolov5 model served as an initial inference seed to output further, more refined model predictions in iterative cycles. Soft labeling here refers to accepting label noise as a potentially valuable augmentation to reduce overfitting and enhance generalized predictions to previously unseen test data. The approach takes advantage of a real-world instance where a cropped image of a car can automatically receive sub-type information as white or colorful from pixel values alone, thus completing an end-to-end pipeline without overdependence on human labor.
Deep Reinforcement Learning for Optimal Power Flow with Renewables Using Spatial-Temporal Graph Information
Dec 22, 2021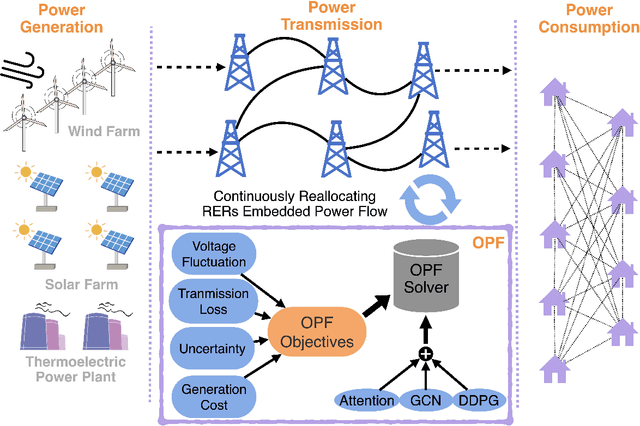
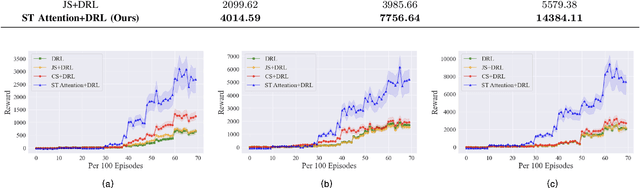
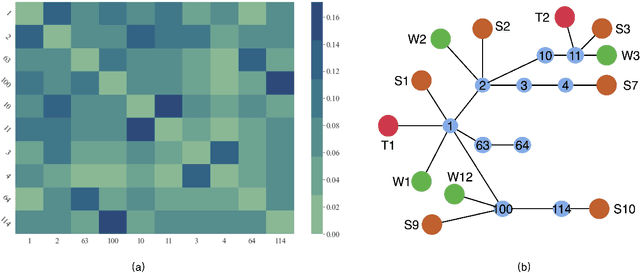
Renewable energy resources (RERs) have been increasingly integrated into modern power systems, especially in large-scale distribution networks (DNs). In this paper, we propose a deep reinforcement learning (DRL)-based approach to dynamically search for the optimal operation point, i.e., optimal power flow (OPF), in DNs with a high uptake of RERs. Considering uncertainties and voltage fluctuation issues caused by RERs, we formulate OPF into a multi-objective optimization (MOO) problem. To solve the MOO problem, we develop a novel DRL algorithm leveraging the graphical information of the distribution network. Specifically, we employ the state-of-the-art DRL algorithm, i.e., deep deterministic policy gradient (DDPG), to learn an optimal strategy for OPF. Since power flow reallocation in the DN is a consecutive process, where nodes are self-correlated and interrelated in temporal and spatial views, to make full use of DNs' graphical information, we develop a multi-grained attention-based spatial-temporal graph convolution network (MG-ASTGCN) for spatial-temporal graph information extraction, preparing for its sequential DDPG. We validate our proposed DRL-based approach in modified IEEE 33, 69, and 118-bus radial distribution systems (RDSs) and show that our DRL-based approach outperforms other benchmark algorithms. Our experimental results also reveal that MG-ASTGCN can significantly accelerate the DDPG training process and improve DDPG's capability in reallocating power flow for OPF. The proposed DRL-based approach also promotes DNs' stability in the presence of node faults, especially for large-scale DNs.
Efficient Approximate Kernel Based Spike Sequence Classification
Sep 11, 2022
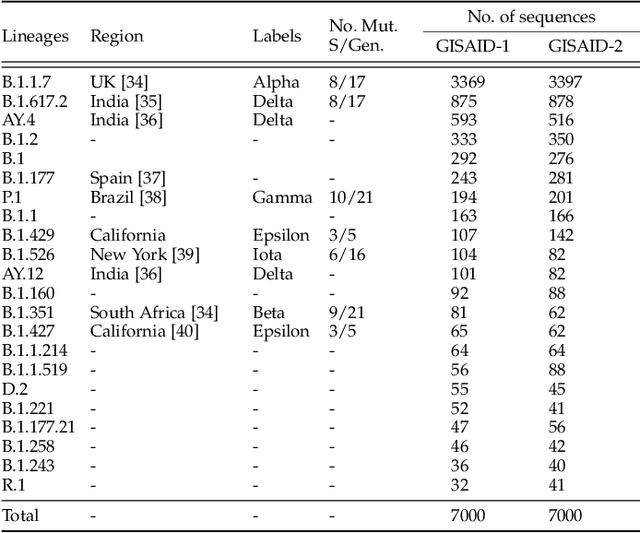
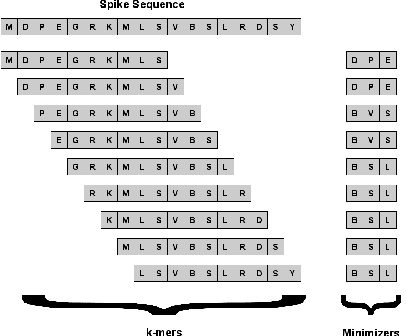
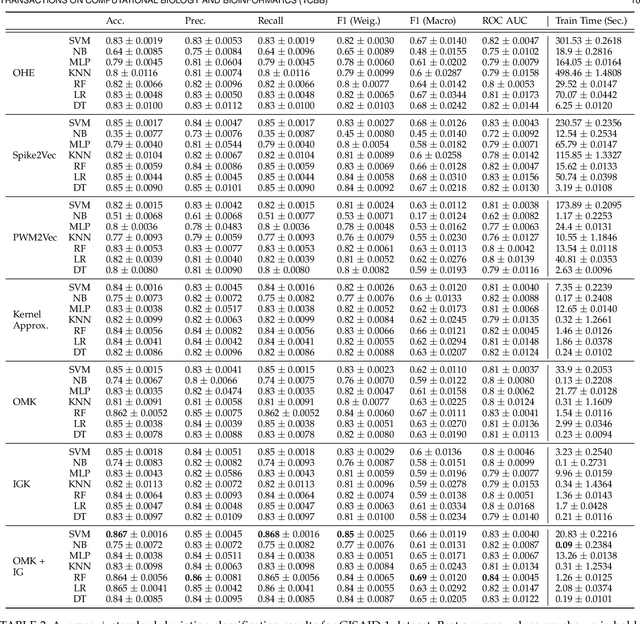
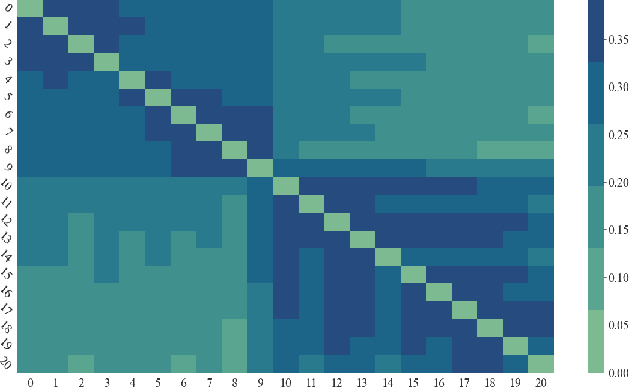
Machine learning (ML) models, such as SVM, for tasks like classification and clustering of sequences, require a definition of distance/similarity between pairs of sequences. Several methods have been proposed to compute the similarity between sequences, such as the exact approach that counts the number of matches between $k$-mers (sub-sequences of length $k$) and an approximate approach that estimates pairwise similarity scores. Although exact methods yield better classification performance, they pose high computational costs, limiting their applicability to a small number of sequences. The approximate algorithms are proven to be more scalable and perform comparably to (sometimes better than) the exact methods -- they are designed in a "general" way to deal with different types of sequences (e.g., music, protein, etc.). Although general applicability is a desired property of an algorithm, it is not the case in all scenarios. For example, in the current COVID-19 (coronavirus) pandemic, there is a need for an approach that can deal specifically with the coronavirus. To this end, we propose a series of ways to improve the performance of the approximate kernel (using minimizers and information gain) in order to enhance its predictive performance pm coronavirus sequences. More specifically, we improve the quality of the approximate kernel using domain knowledge (computed using information gain) and efficient preprocessing (using minimizers computation) to classify coronavirus spike protein sequences corresponding to different variants (e.g., Alpha, Beta, Gamma). We report results using different classification and clustering algorithms and evaluate their performance using multiple evaluation metrics. Using two datasets, we show that our proposed method helps improve the kernel's performance compared to the baseline and state-of-the-art approaches in the healthcare domain.
Private Read Update Write (PRUW) in Federated Submodel Learning (FSL): Communication Efficient Schemes With and Without Sparsification
Sep 09, 2022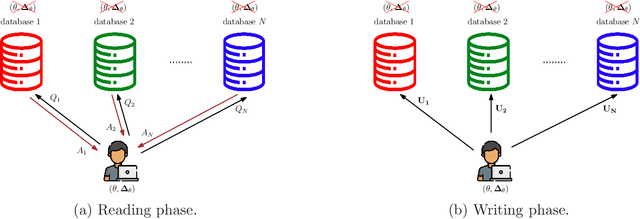
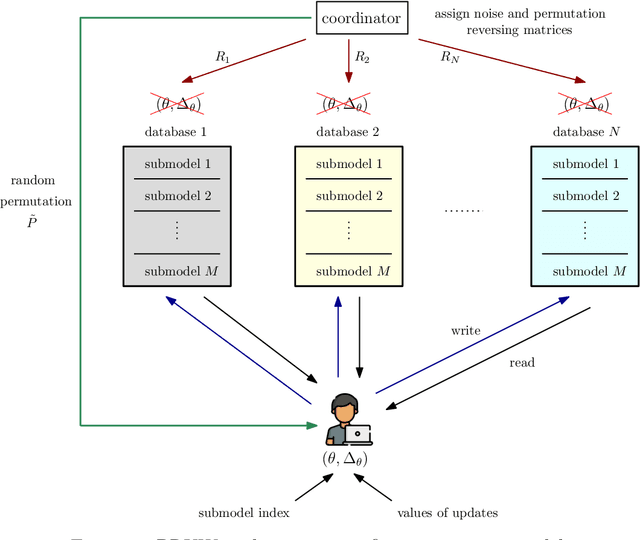
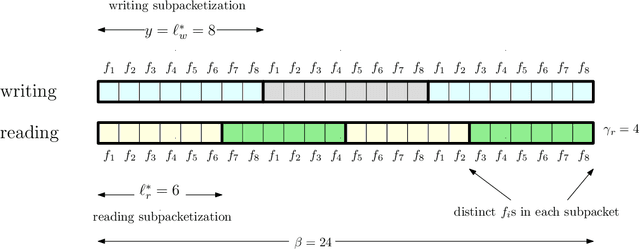
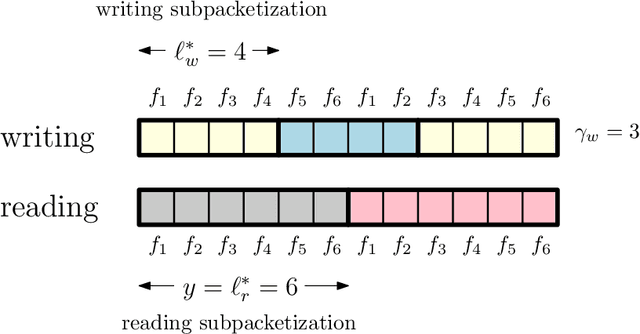
We investigate the problem of private read update write (PRUW) in relation to private federated submodel learning (FSL), where a machine learning model is divided into multiple submodels based on the different types of data used to train the model. In PRUW, each user downloads the required submodel without revealing its index in the reading phase, and uploads the updates of the submodel without revealing the submodel index or the values of the updates in the writing phase. In this work, we first provide a basic communication efficient PRUW scheme, and study further means of reducing the communication cost via sparsification. Gradient sparsification is a widely used concept in learning applications, where only a selected set of parameters is downloaded and updated, which significantly reduces the communication cost. In this paper, we study how the concept of sparsification can be incorporated in private FSL with the goal of reducing the communication cost, while guaranteeing information theoretic privacy of the updated submodel index as well as the values of the updates. To this end, we introduce two schemes: PRUW with top $r$ sparsification and PRUW with random sparsification. The former communicates only the most significant parameters/updates among the servers and the users, while the latter communicates a randomly selected set of parameters/updates. The two proposed schemes introduce novel techniques such as parameter/update (noisy) permutations to handle the additional sources of information leakage in PRUW caused by sparsification. Both schemes result in significantly reduced communication costs compared to that of the basic (non-sparse) PRUW scheme.
Using Whole Slide Image Representations from Self-Supervised Contrastive Learning for Melanoma Concordance Regression
Oct 10, 2022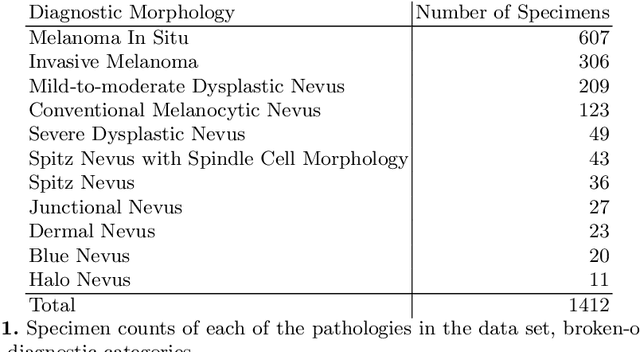
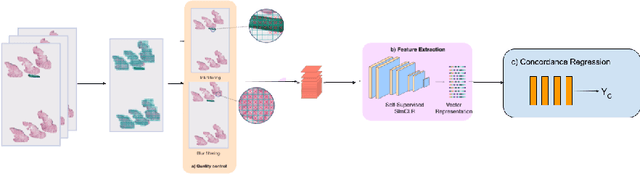

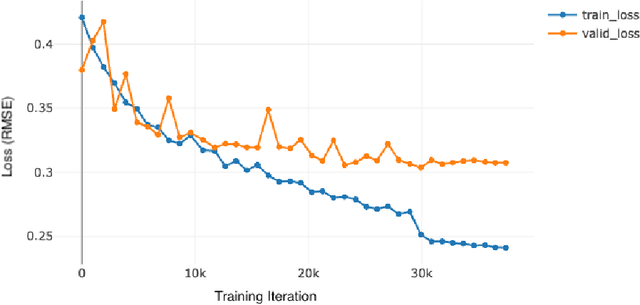
Although melanoma occurs more rarely than several other skin cancers, patients' long term survival rate is extremely low if the diagnosis is missed. Diagnosis is complicated by a high discordance rate among pathologists when distinguishing between melanoma and benign melanocytic lesions. A tool that provides potential concordance information to healthcare providers could help inform diagnostic, prognostic, and therapeutic decision-making for challenging melanoma cases. We present a melanoma concordance regression deep learning model capable of predicting the concordance rate of invasive melanoma or melanoma in-situ from digitized Whole Slide Images (WSIs). The salient features corresponding to melanoma concordance were learned in a self-supervised manner with the contrastive learning method, SimCLR. We trained a SimCLR feature extractor with 83,356 WSI tiles randomly sampled from 10,895 specimens originating from four distinct pathology labs. We trained a separate melanoma concordance regression model on 990 specimens with available concordance ground truth annotations from three pathology labs and tested the model on 211 specimens. We achieved a Root Mean Squared Error (RMSE) of 0.28 +/- 0.01 on the test set. We also investigated the performance of using the predicted concordance rate as a malignancy classifier, and achieved a precision and recall of 0.85 +/- 0.05 and 0.61 +/- 0.06, respectively, on the test set. These results are an important first step for building an artificial intelligence (AI) system capable of predicting the results of consulting a panel of experts and delivering a score based on the degree to which the experts would agree on a particular diagnosis. Such a system could be used to suggest additional testing or other action such as ordering additional stains or genetic tests.
Deep CLSTM for Predictive Beamforming in Integrated Sensing and Communication-enabled Vehicular Networks
Sep 26, 2022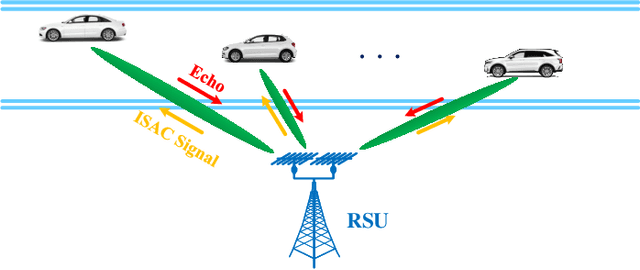
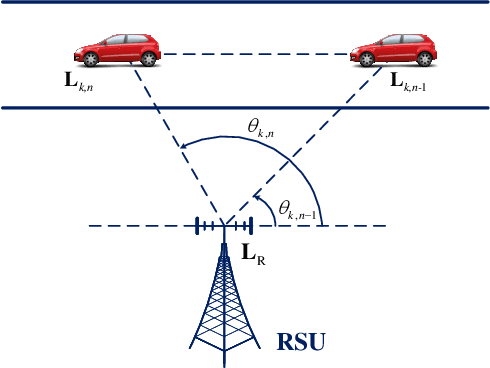
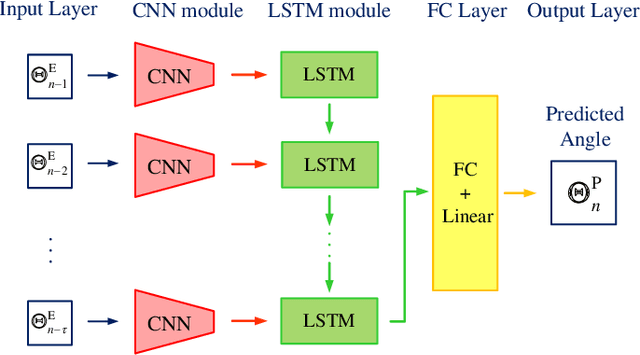
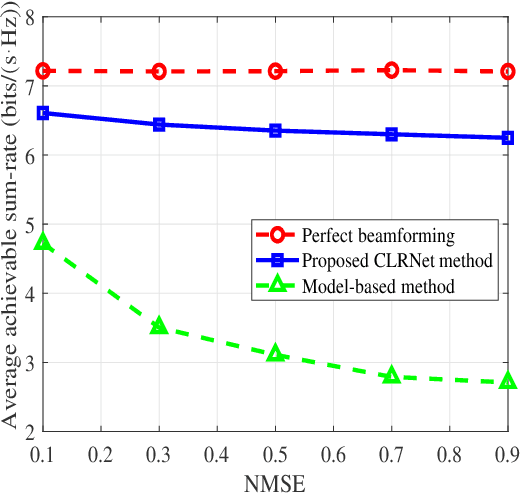
Predictive beamforming design is an essential task in realizing high-mobility integrated sensing and communication (ISAC), which highly depends on the accuracy of the channel prediction (CP), i.e., predicting the angular parameters of users. However, the performance of CP highly depends on the estimated historical channel stated information (CSI) with estimation errors, resulting in the performance degradation for most traditional CP methods. To further improve the prediction accuracy, in this paper, we focus on the ISAC in vehicle networks and propose a convolutional long-short term (CLSTM) recurrent neural network (CLRNet) to predict the angle of vehicles for the design of predictive beamforming. In the developed CLRNet, both the convolutional neural network (CNN) module and the LSTM module are adopted to exploit the spatial features and the temporal dependency from the estimated historical angles of vehicles to facilitate the angle prediction. Finally, numerical results demonstrate that the developed CLRNet-based method is robust to the estimation error and can significantly outperform the state-of-the-art benchmarks, achieving an excellent sum-rate performance for ISAC systems.