 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Using Entropy Measures for Monitoring the Evolution of Activity Patterns
Oct 05, 2022
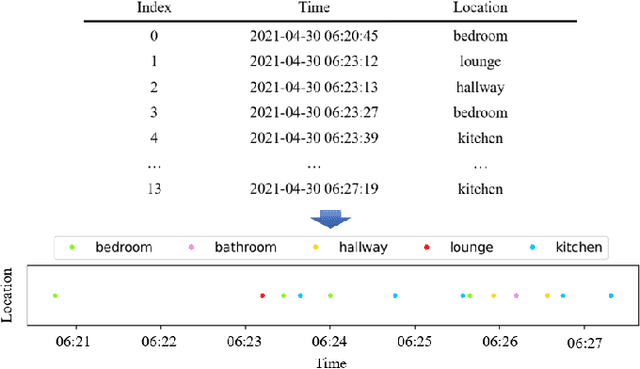
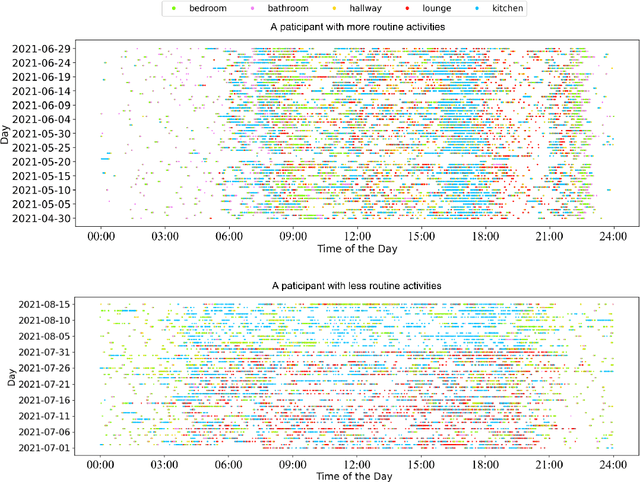
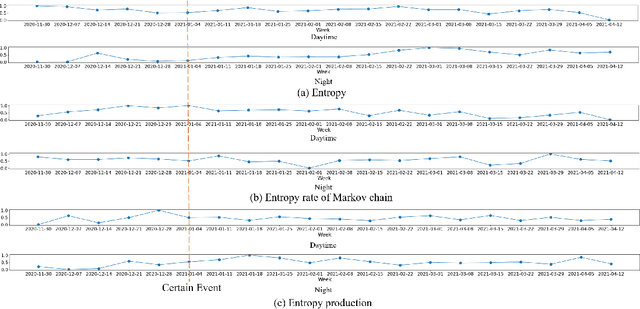
In this work, we apply information theory inspired methods to quantify changes in daily activity patterns. We use in-home movement monitoring data and show how they can help indicate the occurrence of healthcare-related events. Three different types of entropy measures namely Shannon's entropy, entropy rates for Markov chains, and entropy production rate have been utilised. The measures are evaluated on a large-scale in-home monitoring dataset that has been collected within our dementia care clinical study. The study uses Internet of Things (IoT) enabled solutions for continuous monitoring of in-home activity, sleep, and physiology to develop care and early intervention solutions to support people living with dementia (PLWD) in their own homes. Our main goal is to show the applicability of the entropy measures to time-series activity data analysis and to use the extracted measures as new engineered features that can be fed into inference and analysis models. The results of our experiments show that in most cases the combination of these measures can indicate the occurrence of healthcare-related events. We also find that different participants with the same events may have different measures based on one entropy measure. So using a combination of these measures in an inference model will be more effective than any of the single measures.
Phishing URL Detection: A Network-based Approach Robust to Evasion
Sep 03, 2022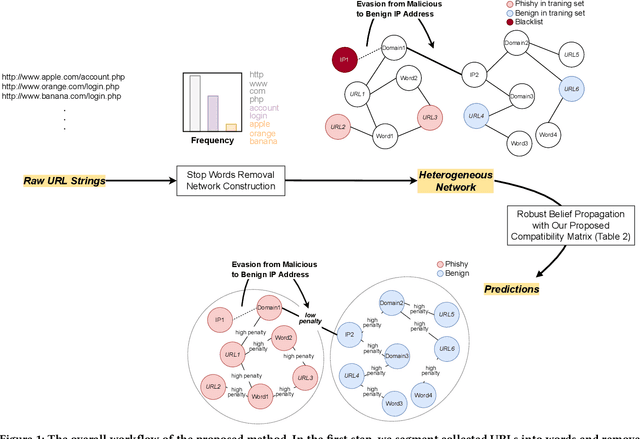

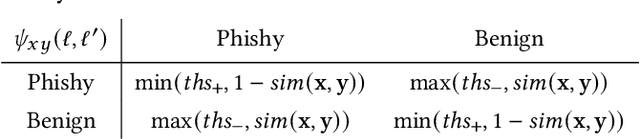
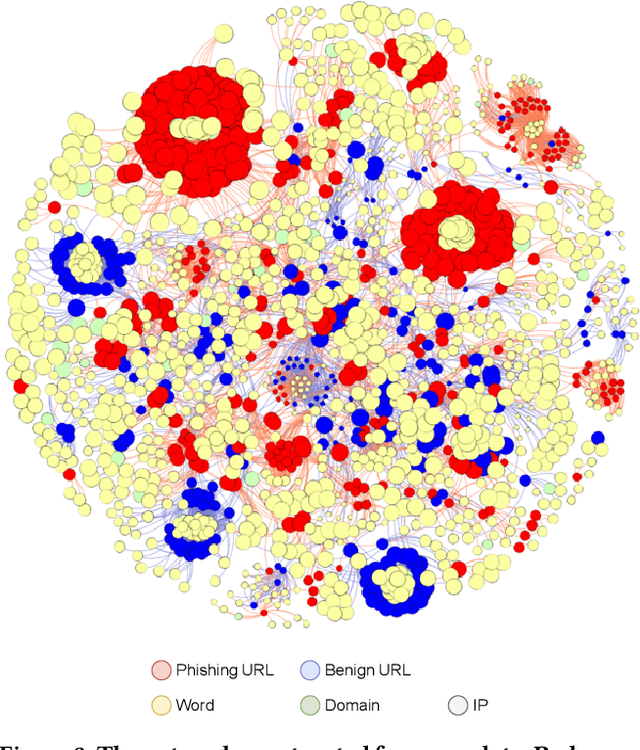
Many cyberattacks start with disseminating phishing URLs. When clicking these phishing URLs, the victim's private information is leaked to the attacker. There have been proposed several machine learning methods to detect phishing URLs. However, it still remains under-explored to detect phishing URLs with evasion, i.e., phishing URLs that pretend to be benign by manipulating patterns. In many cases, the attacker i) reuses prepared phishing web pages because making a completely brand-new set costs non-trivial expenses, ii) prefers hosting companies that do not require private information and are cheaper than others, iii) prefers shared hosting for cost efficiency, and iv) sometimes uses benign domains, IP addresses, and URL string patterns to evade existing detection methods. Inspired by those behavioral characteristics, we present a network-based inference method to accurately detect phishing URLs camouflaged with legitimate patterns, i.e., robust to evasion. In the network approach, a phishing URL will be still identified as phishy even after evasion unless a majority of its neighbors in the network are evaded at the same time. Our method consistently shows better detection performance throughout various experimental tests than state-of-the-art methods, e.g., F-1 of 0.89 for our method vs. 0.84 for the best feature-based method.
Semi-Supervised Domain Generalization for Cardiac Magnetic Resonance Image Segmentation with High Quality Pseudo Labels
Sep 30, 2022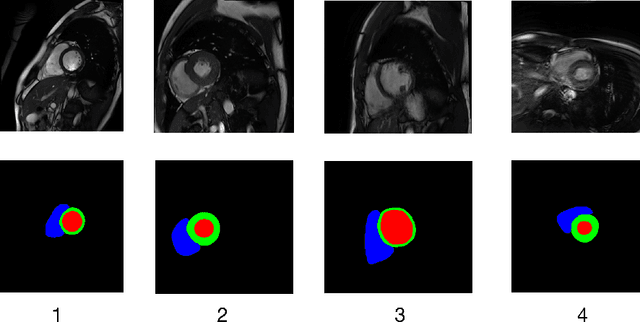

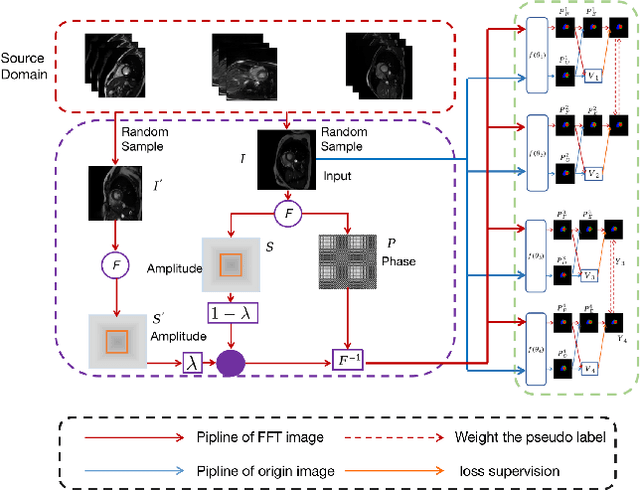
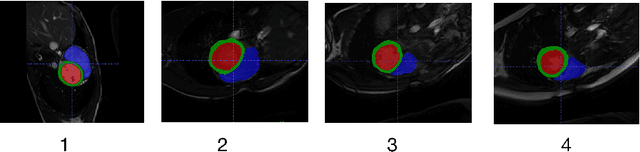
Developing a deep learning method for medical segmentation tasks heavily relies on a large amount of labeled data. However, the annotations require professional knowledge and are limited in number. Recently, semi-supervised learning has demonstrated great potential in medical segmentation tasks. Most existing methods related to cardiac magnetic resonance images only focus on regular images with similar domains and high image quality. A semi-supervised domain generalization method was developed in [2], which enhances the quality of pseudo labels on varied datasets. In this paper, we follow the strategy in [2] and present a domain generalization method for semi-supervised medical segmentation. Our main goal is to improve the quality of pseudo labels under extreme MRI Analysis with various domains. We perform Fourier transformation on input images to learn low-level statistics and cross-domain information. Then we feed the augmented images as input to the double cross pseudo supervision networks to calculate the variance among pseudo labels. We evaluate our method on the CMRxMotion dataset [1]. With only partially labeled data and without domain labels, our approach consistently generates accurate segmentation results of cardiac magnetic resonance images with different respiratory motions. Code will be available after the conference.
PyPose: A Library for Robot Learning with Physics-based Optimization
Sep 30, 2022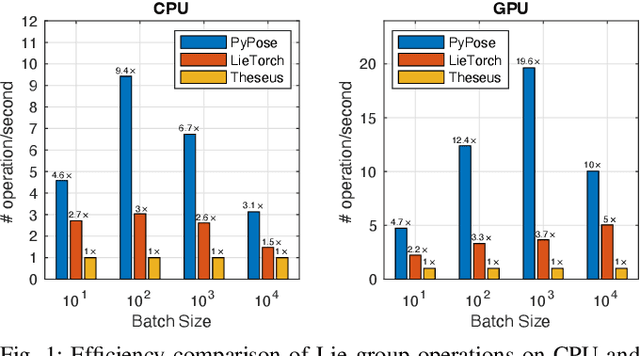
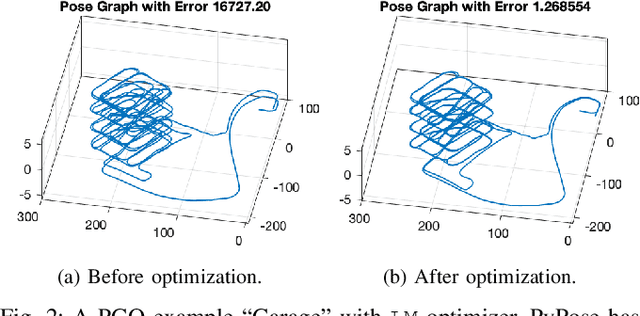
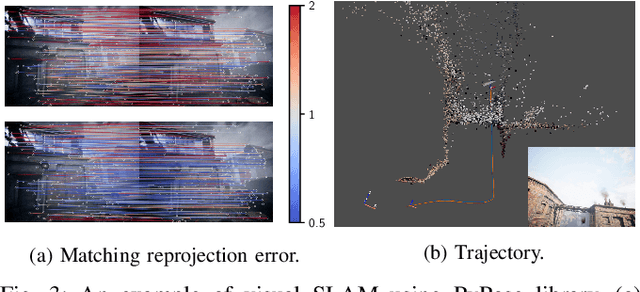
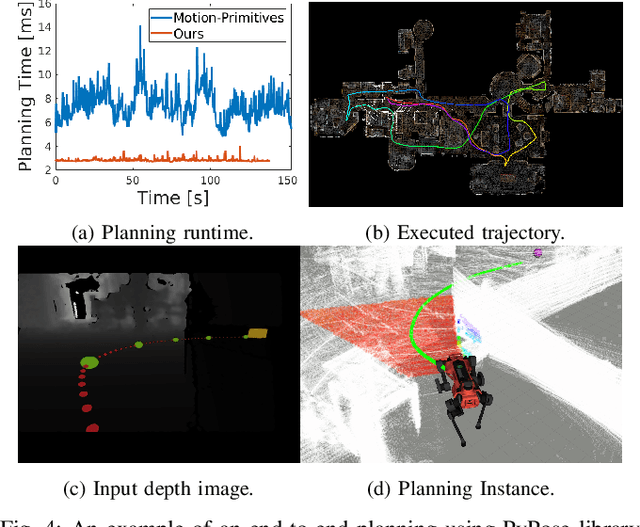
Deep learning has had remarkable success in robotic perception, but its data-centric nature suffers when it comes to generalizing to ever-changing environments. By contrast, physics-based optimization generalizes better, but it does not perform as well in complicated tasks due to the lack of high-level semantic information and the reliance on manual parametric tuning. To take advantage of these two complementary worlds, we present PyPose: a robotics-oriented, PyTorch-based library that combines deep perceptual models with physics-based optimization techniques. Our design goal for PyPose is to make it user-friendly, efficient, and interpretable with a tidy and well-organized architecture. Using an imperative style interface, it can be easily integrated into real-world robotic applications. Besides, it supports parallel computing of any order gradients of Lie groups and Lie algebras and $2^{\text{nd}}$-order optimizers, such as trust region methods. Experiments show that PyPose achieves 3-20$\times$ speedup in computation compared to state-of-the-art libraries. To boost future research, we provide concrete examples across several fields of robotics, including SLAM, inertial navigation, planning, and control.
A Learnable Optimization and Regularization Approach to Massive MIMO CSI Feedback
Sep 30, 2022
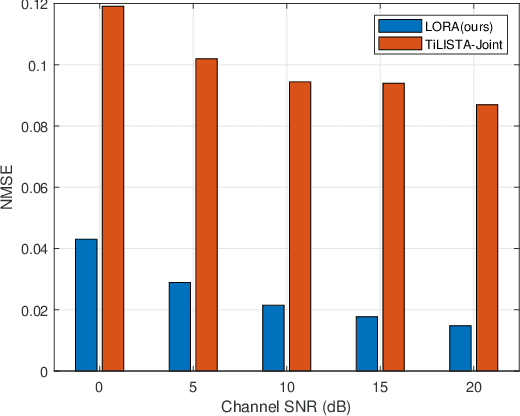
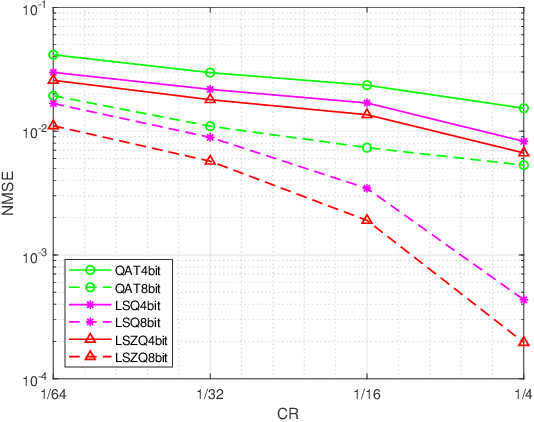
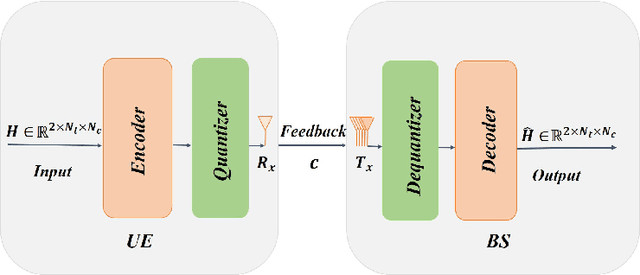
Channel state information (CSI) plays a critical role in achieving the potential benefits of massive multiple input multiple output (MIMO) systems. In frequency division duplex (FDD) massive MIMO systems, the base station (BS) relies on sustained and accurate CSI feedback from the users. However, due to the large number of antennas and users being served in massive MIMO systems, feedback overhead can become a bottleneck. In this paper, we propose a model-driven deep learning method for CSI feedback, called learnable optimization and regularization algorithm (LORA). Instead of using l1-norm as the regularization term, a learnable regularization module is introduced in LORA to automatically adapt to the characteristics of CSI. We unfold the conventional iterative shrinkage-thresholding algorithm (ISTA) to a neural network and learn both the optimization process and regularization term by end-toend training. We show that LORA improves the CSI feedback accuracy and speed. Besides, a novel learnable quantization method and the corresponding training scheme are proposed, and it is shown that LORA can operate successfully at different bit rates, providing flexibility in terms of the CSI feedback overhead. Various realistic scenarios are considered to demonstrate the effectiveness and robustness of LORA through numerical simulations.
Generative Model Watermarking Based on Human Visual System
Sep 30, 2022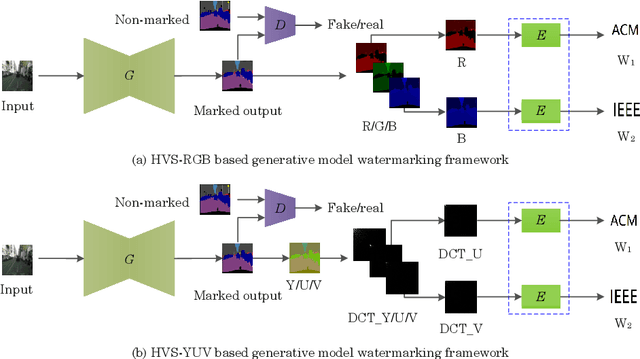
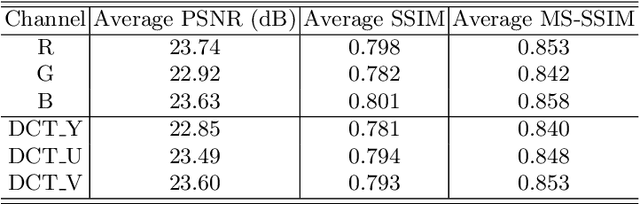


Intellectual property protection of deep neural networks is receiving attention from more and more researchers, and the latest research applies model watermarking to generative models for image processing. However, the existing watermarking methods designed for generative models do not take into account the effects of different channels of sample images on watermarking. As a result, the watermarking performance is still limited. To tackle this problem, in this paper, we first analyze the effects of embedding watermark information on different channels. Then, based on the characteristics of human visual system (HVS), we introduce two HVS-based generative model watermarking methods, which are realized in RGB color space and YUV color space respectively. In RGB color space, the watermark is embedded into the R and B channels based on the fact that HVS is more sensitive to G channel. In YUV color space, the watermark is embedded into the DCT domain of U and V channels based on the fact that HVS is more sensitive to brightness changes. Experimental results demonstrate the effectiveness of the proposed work, which improves the fidelity of the model to be protected and has good universality compared with previous methods.
Preliminary Analysis of Skywave Effects on MF DGNSS R-Mode Signals During Daytime and Nighttime
Sep 30, 2022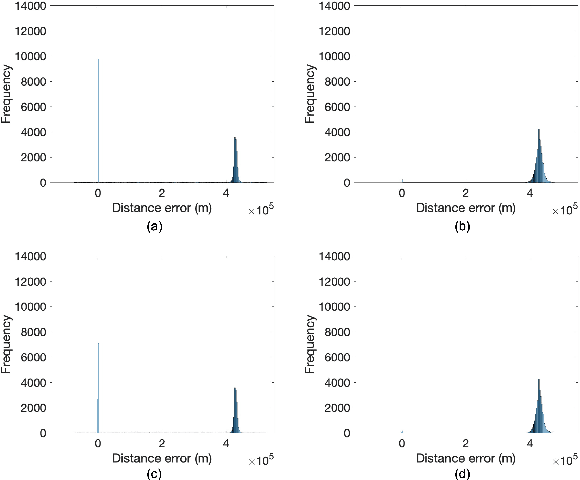
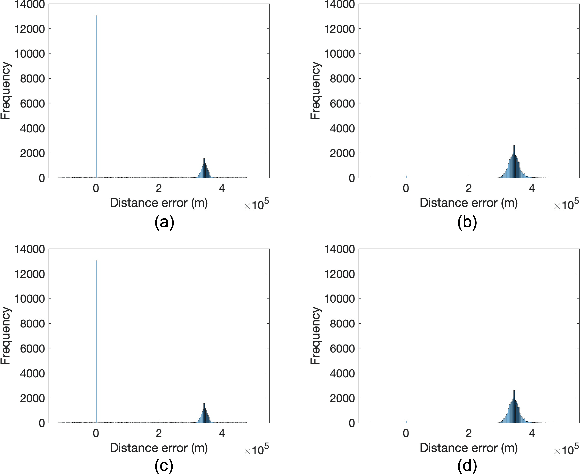
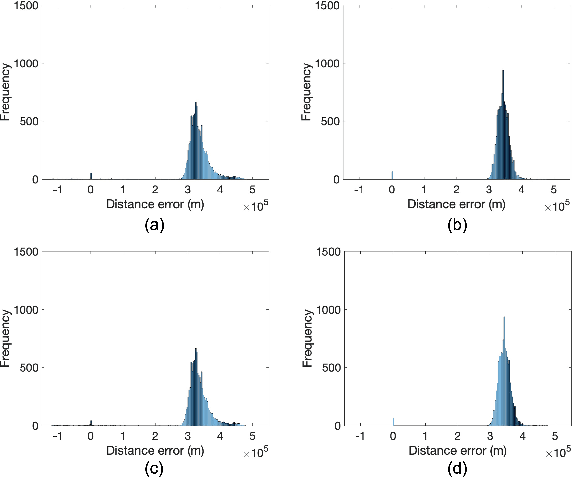
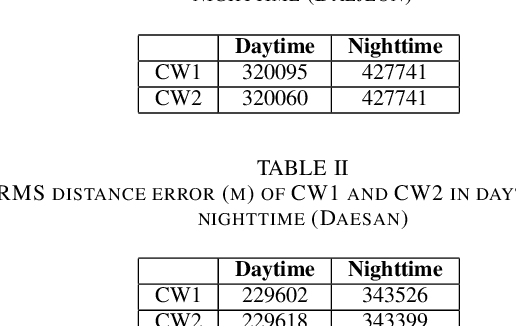
Accurate positioning, navigation, and timing (PNT) performance are prerequisites for several technologies today. In a marine environment, it is difficult to visually identify one's position accurately, leading to safety concerns. Currently, PNT information is provided mainly from Global Navigation Satellite Systems (GNSS); however, it is vulnerable to radio frequency interference, spoofing, and ionospheric anomaly. Therefore, research on a backup system is needed. Ranging Mode (R-Mode), a terrestrial integrated navigation system, is being investigated for use in a marine environment. R-Mode is a positioning technology that integrates terrestrial signals of opportunity such as medium frequency (MF) differential GNSS (DGNSS), very high frequency (VHF) automatic identification system (AIS), and enhanced long-range navigation (eLoran) signals. Previous studies in Europe show that signals in the MF band differ greatly in accuracy between daytime and nighttime. This difference is primarily caused by skywave. In this study, the MF DGNSS R-Mode signal transmitted from Chungju, Korea was received in Daesan and Daejeon, Korea. The skywave effect during daytime and nighttime was compared and investigated. In addition, the continuous wave intensity of the R-Mode signal was increased during the nighttime to compare its effect on the measurement accuracy.
Tradeoffs between convergence rate and noise amplification for momentum-based accelerated optimization algorithms
Sep 24, 2022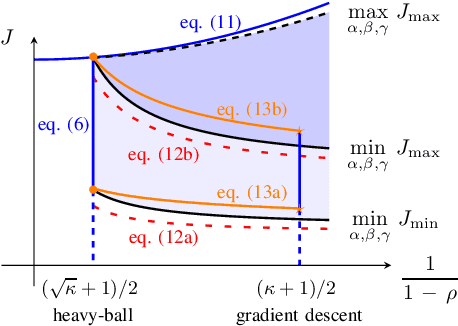
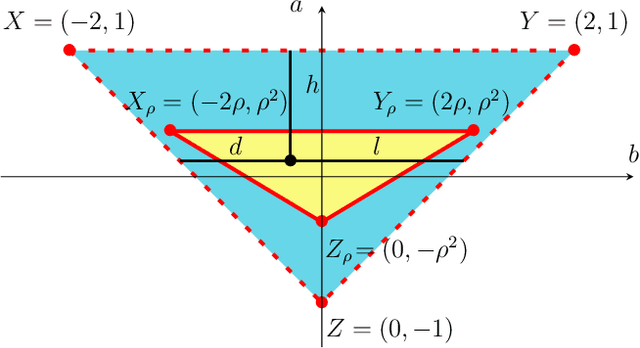

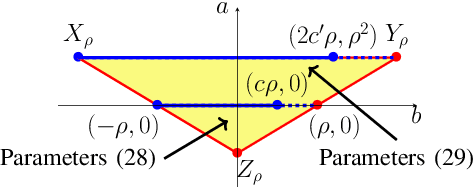
We study momentum-based first-order optimization algorithms in which the iterations utilize information from the two previous steps and are subject to an additive white noise. This class of algorithms includes heavy-ball and Nesterov's accelerated methods as special cases. For strongly convex quadratic problems, we use the steady-state variance of the error in the optimization variable to quantify noise amplification and exploit a novel geometric viewpoint to establish analytical lower bounds on the product between the settling time and the smallest/largest achievable noise amplification. For all stabilizing parameters, these bounds scale quadratically with the condition number. We also use the geometric insight developed in the paper to introduce two parameterized families of algorithms that strike a balance between noise amplification and settling time while preserving order-wise Pareto optimality. Finally, for a class of continuous-time gradient flow dynamics, whose suitable discretization yields two-step momentum algorithm, we establish analogous lower bounds that also scale quadratically with the condition number.
A Compact Pretraining Approach for Neural Language Models
Aug 29, 2022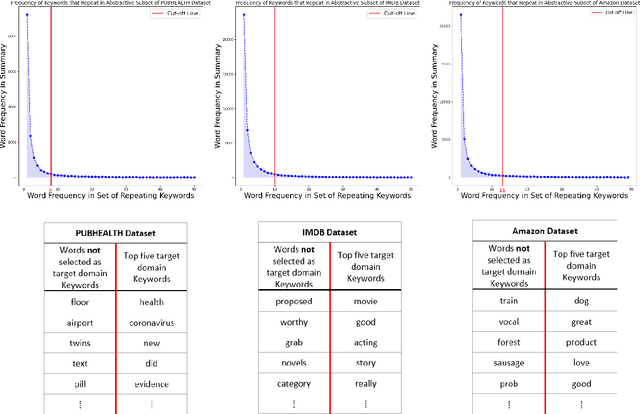
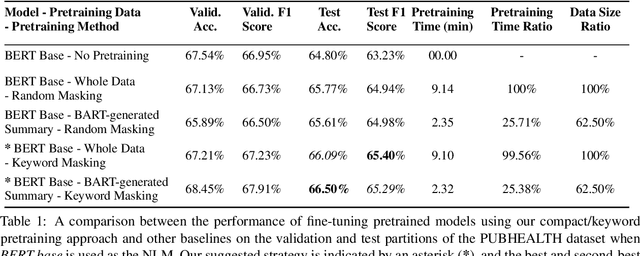
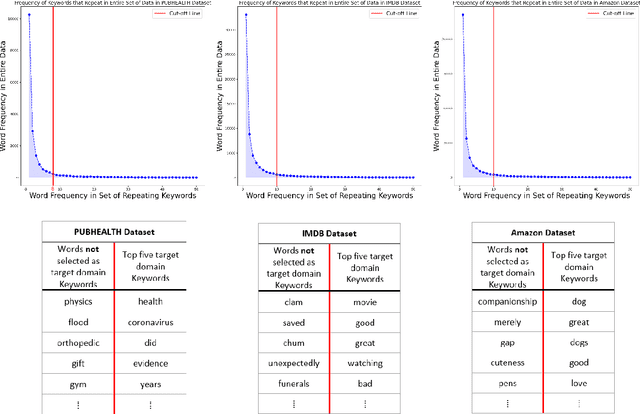
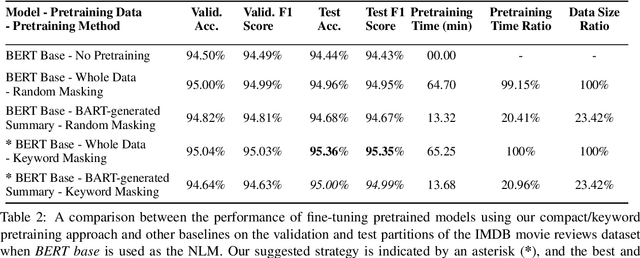
Domain adaptation for large neural language models (NLMs) is coupled with massive amounts of unstructured data in the pretraining phase. In this study, however, we show that pretrained NLMs learn in-domain information more effectively and faster from a compact subset of the data that focuses on the key information in the domain. We construct these compact subsets from the unstructured data using a combination of abstractive summaries and extractive keywords. In particular, we rely on BART to generate abstractive summaries, and KeyBERT to extract keywords from these summaries (or the original unstructured text directly). We evaluate our approach using six different settings: three datasets combined with two distinct NLMs. Our results reveal that the task-specific classifiers trained on top of NLMs pretrained using our method outperform methods based on traditional pretraining, i.e., random masking on the entire data, as well as methods without pretraining. Further, we show that our strategy reduces pretraining time by up to five times compared to vanilla pretraining. The code for all of our experiments is publicly available at https://github.com/shahriargolchin/compact-pretraining.
A general-purpose material property data extraction pipeline from large polymer corpora using Natural Language Processing
Sep 27, 2022



The ever-increasing number of materials science articles makes it hard to infer chemistry-structure-property relations from published literature. We used natural language processing (NLP) methods to automatically extract material property data from the abstracts of polymer literature. As a component of our pipeline, we trained MaterialsBERT, a language model, using 2.4 million materials science abstracts, which outperforms other baseline models in three out of five named entity recognition datasets when used as the encoder for text. Using this pipeline, we obtained ~300,000 material property records from ~130,000 abstracts in 60 hours. The extracted data was analyzed for a diverse range of applications such as fuel cells, supercapacitors, and polymer solar cells to recover non-trivial insights. The data extracted through our pipeline is made available through a web platform at https://polymerscholar.org which can be used to locate material property data recorded in abstracts conveniently. This work demonstrates the feasibility of an automatic pipeline that starts from published literature and ends with a complete set of extracted material property information.