 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
The Eyecandies Dataset for Unsupervised Multimodal Anomaly Detection and Localization
Oct 10, 2022

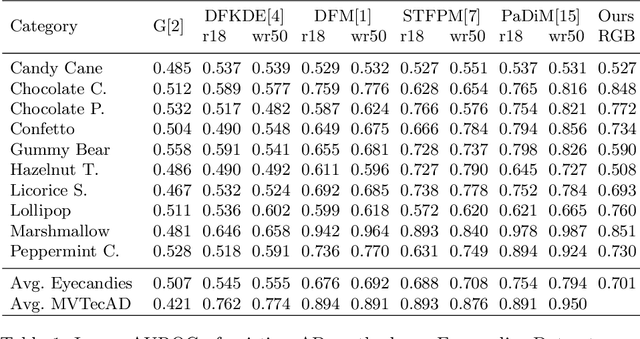
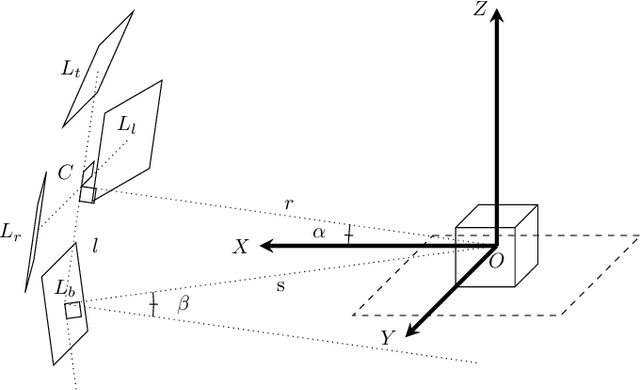
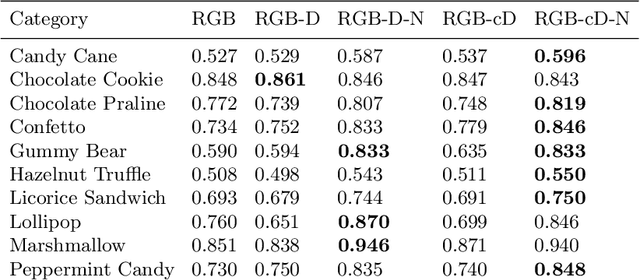
We present Eyecandies, a novel synthetic dataset for unsupervised anomaly detection and localization. Photo-realistic images of procedurally generated candies are rendered in a controlled environment under multiple lightning conditions, also providing depth and normal maps in an industrial conveyor scenario. We make available anomaly-free samples for model training and validation, while anomalous instances with precise ground-truth annotations are provided only in the test set. The dataset comprises ten classes of candies, each showing different challenges, such as complex textures, self-occlusions and specularities. Furthermore, we achieve large intra-class variation by randomly drawing key parameters of a procedural rendering pipeline, which enables the creation of an arbitrary number of instances with photo-realistic appearance. Likewise, anomalies are injected into the rendering graph and pixel-wise annotations are automatically generated, overcoming human-biases and possible inconsistencies. We believe this dataset may encourage the exploration of original approaches to solve the anomaly detection task, e.g. by combining color, depth and normal maps, as they are not provided by most of the existing datasets. Indeed, in order to demonstrate how exploiting additional information may actually lead to higher detection performance, we show the results obtained by training a deep convolutional autoencoder to reconstruct different combinations of inputs.
Accented Speech Recognition under the Indian context
Sep 11, 2022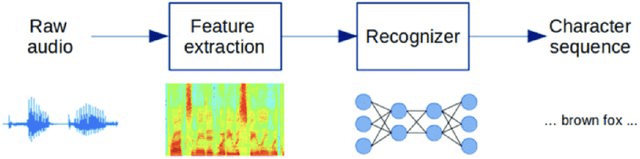
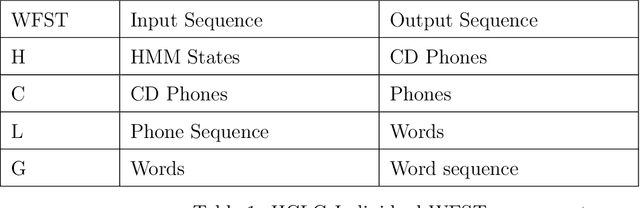
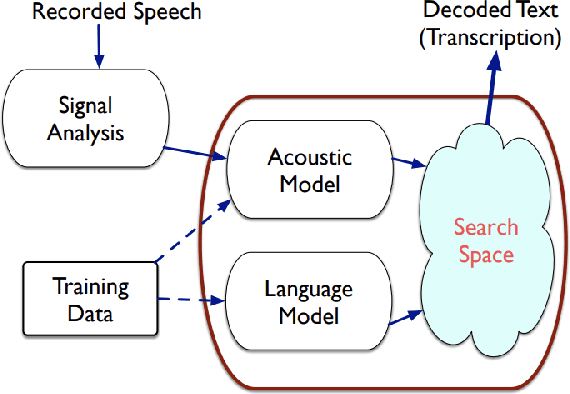
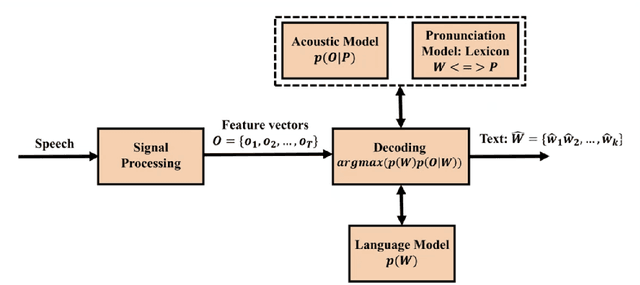
Accent forms an integral part of identifying cultures, emotions, behavior'ss, etc. People often perceive each other in a different manner due to their accent. The accent itself can be a conveyor of status, pride, and other emotional information which can be captured through Speech itself. Accent itself can be defined as: "the way in which people in a particular area, country, or social group pronounce words" or "a special emphasis given to a syllable in a word, word in a sentence, or note in a set of musical notes". Accented Speech Recognition is one the most important problems in the domain of Speech Recognition. Speech recognition is an interdisciplinary sub-field of Computer Science and Linguistics research where the main aim is to develop technologies which enable conversion of speech into text. The speech can be of any form such as read speech or spontaneous speech, conversational speech. As all instances of language utterances are present speech is very diverse and exhibits many traits of variability. This diversity stems from the environmental conditions, variabilities from speaker to speaker, channel noise, differences in Speech production due to disabilities, presence of disfluencies. Speech therefore is indeed a rich source of information waiting to be exploited.
Unsupervised Video Domain Adaptation: A Disentanglement Perspective
Aug 15, 2022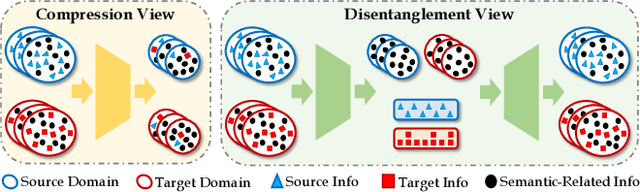
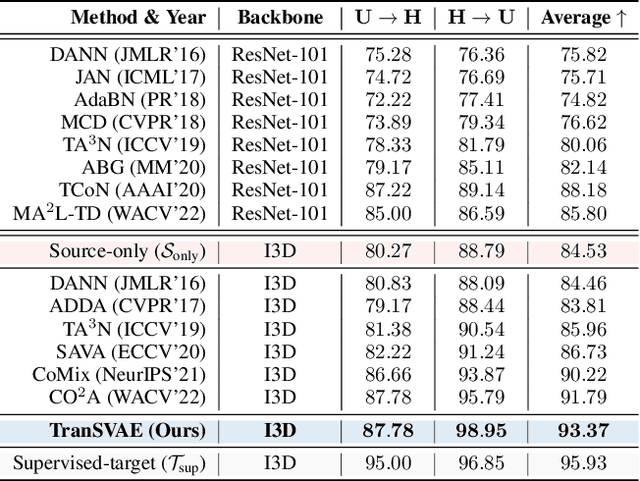
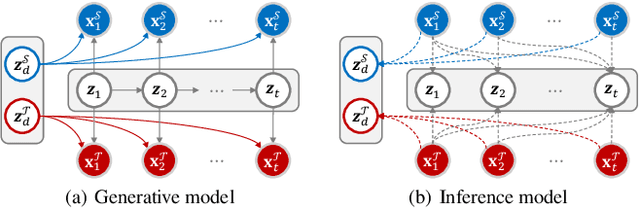
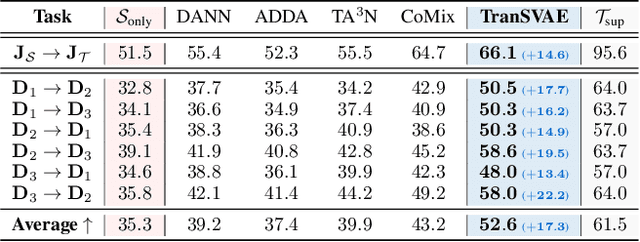
Unsupervised video domain adaptation is a practical yet challenging task. In this work, for the first time, we tackle it from a disentanglement view. Our key idea is to disentangle the domain-related information from the data during the adaptation process. Specifically, we consider the generation of cross-domain videos from two sets of latent factors, one encoding the static domain-related information and another encoding the temporal and semantic-related information. A Transfer Sequential VAE (TranSVAE) framework is then developed to model such generation. To better serve for adaptation, we further propose several objectives to constrain the latent factors in TranSVAE. Extensive experiments on the UCF-HMDB, Jester, and Epic-Kitchens datasets verify the effectiveness and superiority of TranSVAE compared with several state-of-the-art methods. Code is publicly available at https://github.com/ldkong1205/TranSVAE.
On The Robustness of Self-Supervised Representations for Spoken Language Modeling
Sep 30, 2022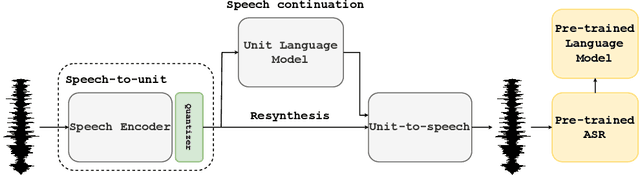
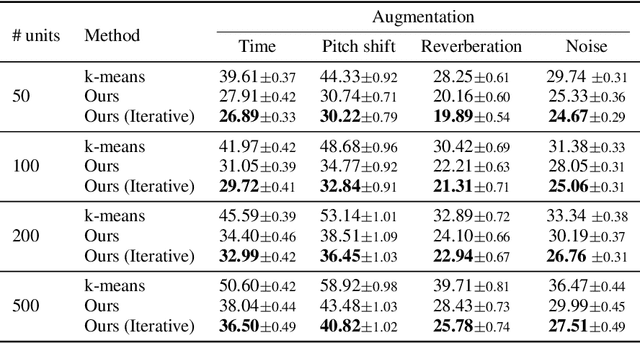
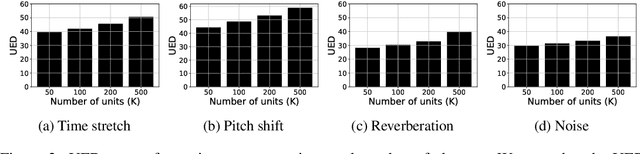
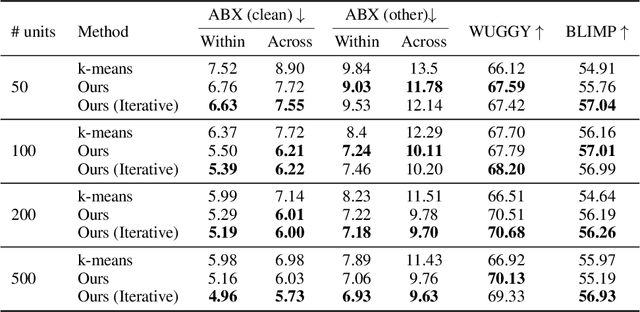
Self-supervised representations have been extensively studied for discriminative and generative tasks. However, their robustness capabilities have not been extensively investigated. This work focuses on self-supervised representations for spoken generative language models. First, we empirically demonstrate how current state-of-the-art speech representation models lack robustness to basic signal variations that do not alter the spoken information. To overcome this, we propose an effective and efficient method to learn robust self-supervised speech representation for generative spoken language modeling. The proposed approach is based on applying a set of signal transformations to the speech signal and optimizing the model using an iterative pseudo-labeling scheme. Our method significantly improves over the evaluated baselines when considering encoding metrics. We additionally evaluate our method on the speech-to-speech translation task. We consider Spanish-English and French-English conversions and empirically demonstrate the benefits of following the proposed approach.
Adaptive Sparse and Monotonic Attention for Transformer-based Automatic Speech Recognition
Sep 30, 2022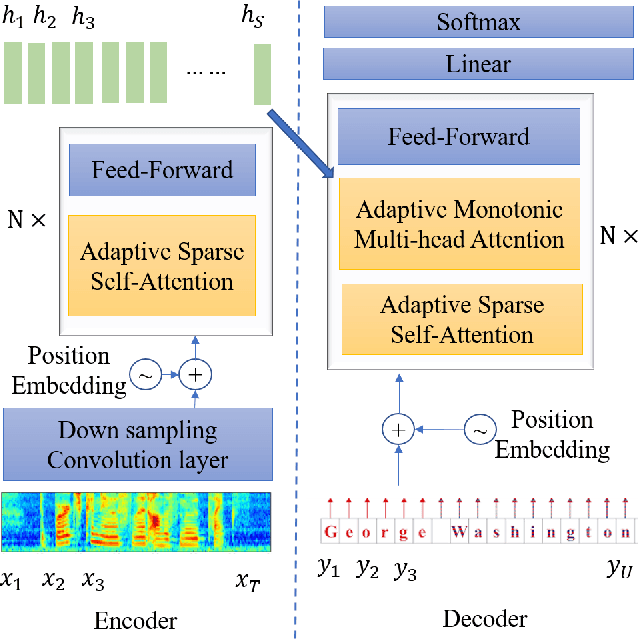
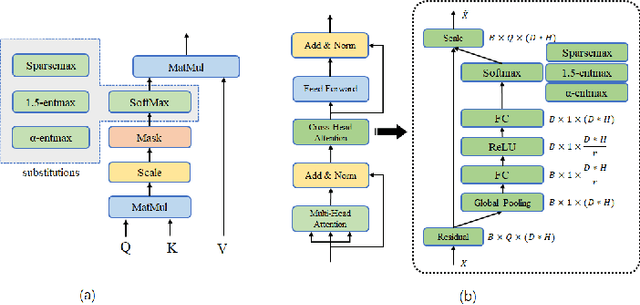
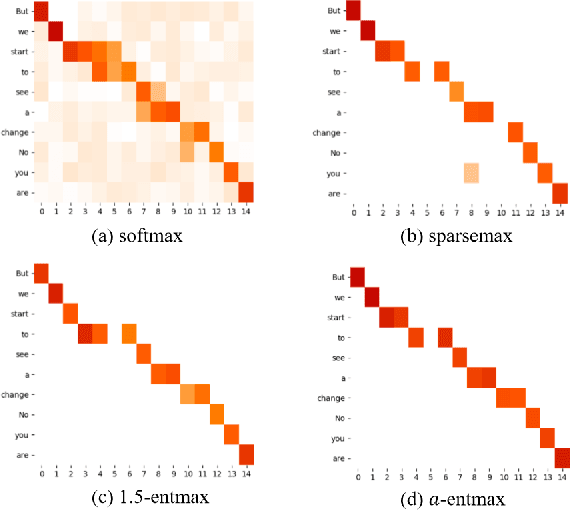
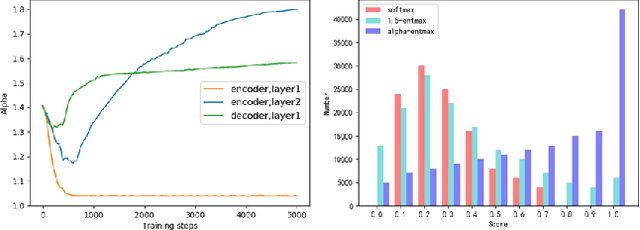
The Transformer architecture model, based on self-attention and multi-head attention, has achieved remarkable success in offline end-to-end Automatic Speech Recognition (ASR). However, self-attention and multi-head attention cannot be easily applied for streaming or online ASR. For self-attention in Transformer ASR, the softmax normalization function-based attention mechanism makes it impossible to highlight important speech information. For multi-head attention in Transformer ASR, it is not easy to model monotonic alignments in different heads. To overcome these two limits, we integrate sparse attention and monotonic attention into Transformer-based ASR. The sparse mechanism introduces a learned sparsity scheme to enable each self-attention structure to fit the corresponding head better. The monotonic attention deploys regularization to prune redundant heads for the multi-head attention structure. The experiments show that our method can effectively improve the attention mechanism on widely used benchmarks of speech recognition.
Many-Body Approximation for Tensors
Sep 30, 2022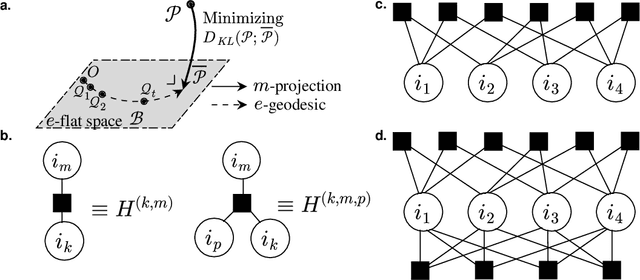
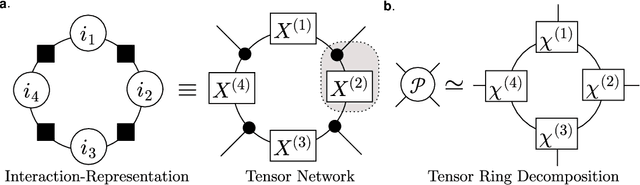
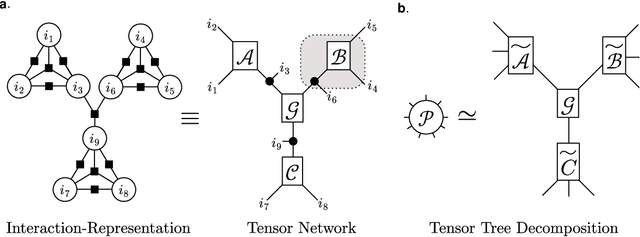
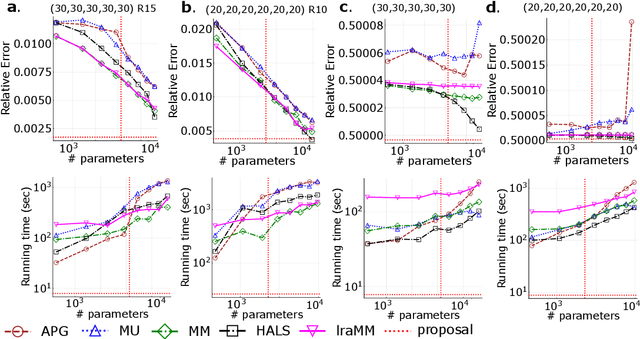
We propose a nonnegative tensor decomposition with focusing on the relationship between the modes of tensors. Traditional decomposition methods assume low-rankness in the representation, resulting in difficulties in global optimization and target rank selection. To address these problems, we present an alternative way to decompose tensors, a many-body approximation for tensors, based on an information geometric formulation. A tensor is treated via an energy-based model, where the tensor and its mode correspond to a probability distribution and a random variable, respectively, and many-body approximation is performed on it by taking the interaction between variables into account. Our model can be globally optimized in polynomial time in terms of the KL divergence minimization, which is empirically faster than low-rank approximations keeping comparable reconstruction error. Furthermore, we visualize interactions between modes as tensor networks and reveal a nontrivial relationship between many-body approximation and low-rank approximation.
ARRID: ANN-based Rotordynamics for Robust and Integrated Design
Aug 25, 2022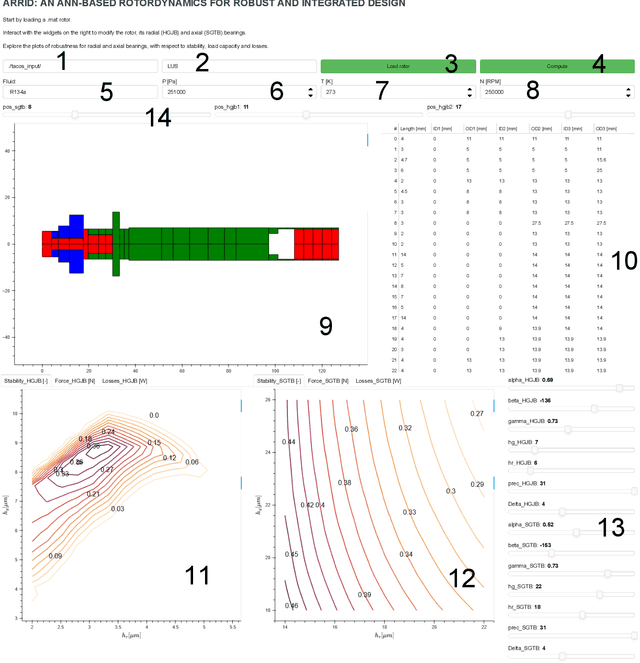
The purpose of this study is to introduce ANN-based software for the fast evaluation of rotordynamics in the context of robust and integrated design. It is based on a surrogate model made of ensembles of artificial neural networks running in a Bokeh web application. The use of a surrogate model has sped up the computation by three orders of magnitude compared to the current models. ARRID offers fast performance information, including the effect of manufacturing deviations. As such, it helps the designer to make optimal design choices early in the design process. The designer can manipulate the parameters of the design and the operating conditions to obtain performance information in a matter of seconds.
Song Emotion Recognition: a Performance Comparison Between Audio Features and Artificial Neural Networks
Sep 24, 2022
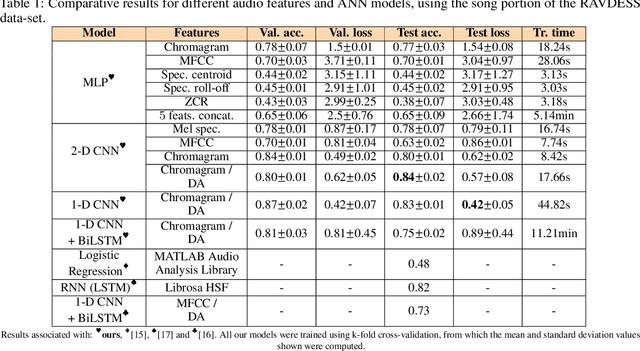
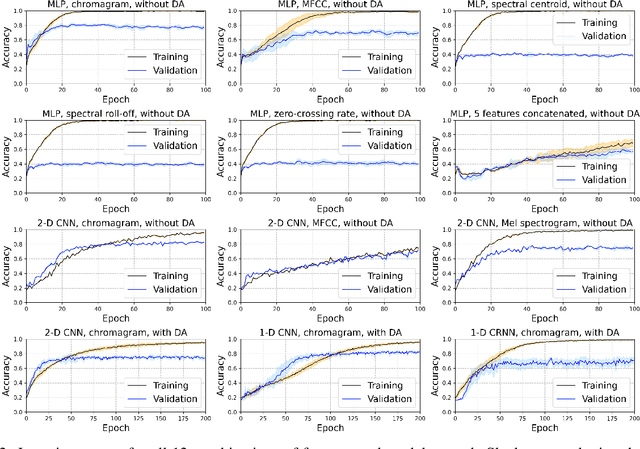
When songs are composed or performed, there is often an intent by the singer/songwriter of expressing feelings or emotions through it. For humans, matching the emotiveness in a musical composition or performance with the subjective perception of an audience can be quite challenging. Fortunately, the machine learning approach for this problem is simpler. Usually, it takes a data-set, from which audio features are extracted to present this information to a data-driven model, that will, in turn, train to predict what is the probability that a given song matches a target emotion. In this paper, we studied the most common features and models used in recent publications to tackle this problem, revealing which ones are best suited for recognizing emotion in a cappella songs.
Matrix Adaptive Synthesis Filter for Uniform Filter Bank
Sep 22, 2022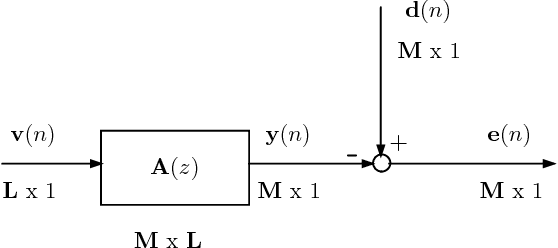
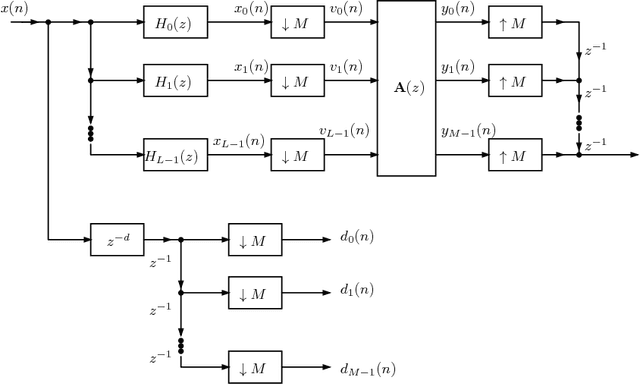
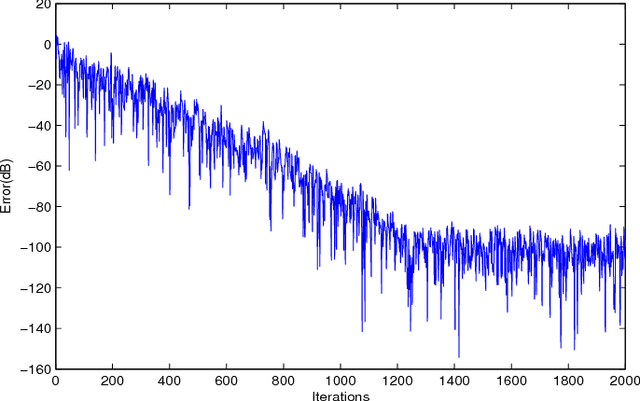
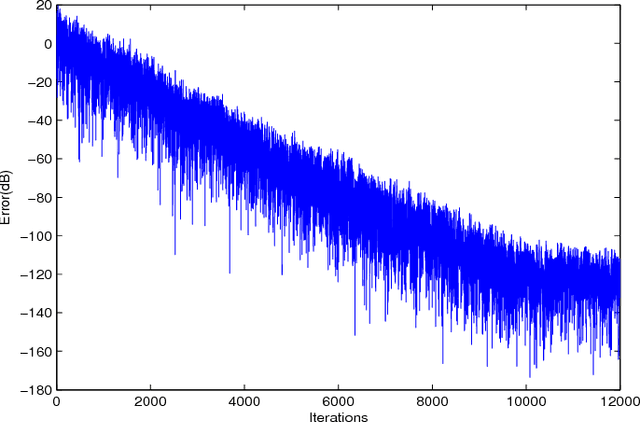
In this paper, we use a matrix adaptive filter as the synthesis stage of a Uniform Filter Bank (UFB) to reconstruct the input signal. We first develop the mathematical theory behind it by applying the model of optimal filtering at the synthesis stage of the UFB and obtaining an expression for the matrix Wiener filter. We have developed a theorem which we use to simplify the expression further. In the absence of required information about the analysis stage, we use adaptive filtering to arrive at the Wiener solution. We use the Least Mean Square (LMS) algorithm to update the filter coefficients. Through experimental results, we find that the adaptive filter is convergent for a stable Wiener filter.
Differentially Private Bootstrap: New Privacy Analysis and Inference Strategies
Oct 12, 2022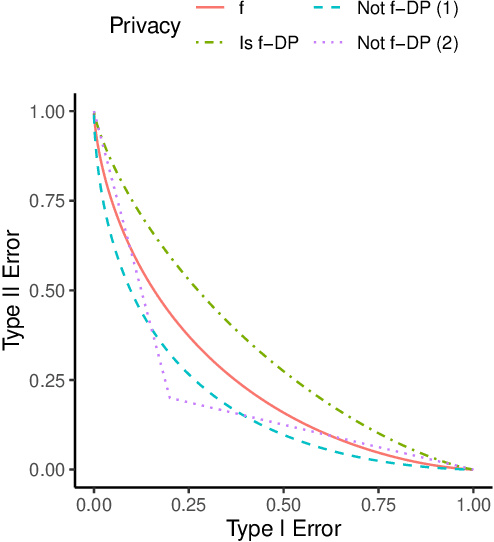

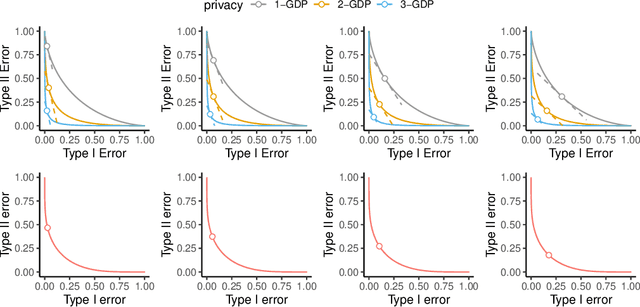
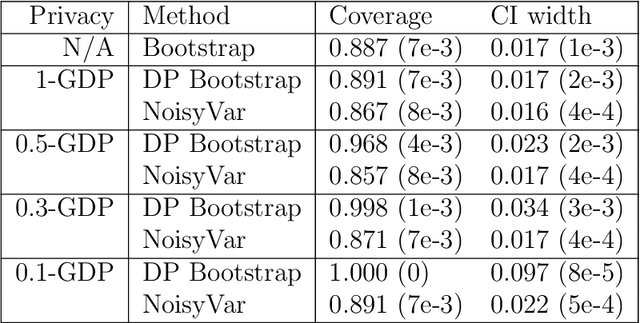
Differential private (DP) mechanisms protect individual-level information by introducing randomness into the statistical analysis procedure. While there are now many DP tools for various statistical problems, there is still a lack of general techniques to understand the sampling distribution of a DP estimator, which is crucial for uncertainty quantification in statistical inference. We analyze a DP bootstrap procedure that releases multiple private bootstrap estimates to infer the sampling distribution and construct confidence intervals. Our privacy analysis includes new results on the privacy cost of a single DP bootstrap estimate applicable to incorporate arbitrary DP mechanisms and identifies some misuses of the bootstrap in the existing literature. We show that the release of $B$ DP bootstrap estimates from mechanisms satisfying $(\mu/\sqrt{(2-2/\mathrm{e})B})$-Gaussian DP asymptotically satisfies $\mu$-Gaussian DP as $B$ goes to infinity. We also develop a statistical procedure based on the DP bootstrap estimates to correctly infer the sampling distribution using techniques related to the deconvolution of probability measures, an approach which is novel in analyzing DP procedures. From our density estimate, we construct confidence intervals and compare them to existing methods through simulations and real-world experiments using the 2016 Canada Census Public Use Microdata. The coverage of our private confidence intervals achieves the nominal confidence level, while other methods fail to meet this guarantee.