 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Convolutional Bayesian Kernel Inference for 3D Semantic Mapping
Sep 21, 2022
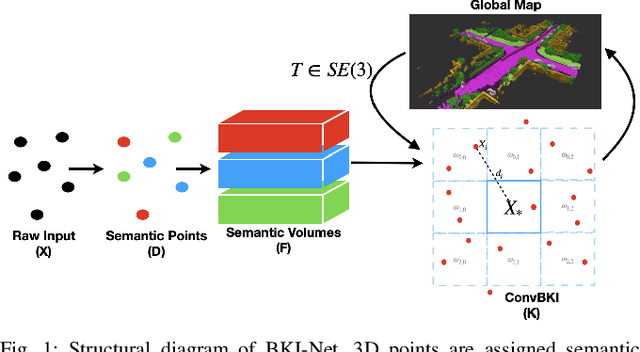
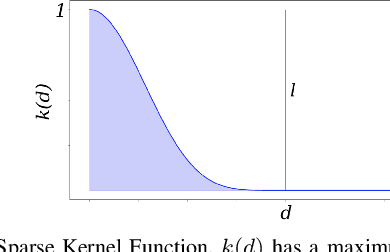
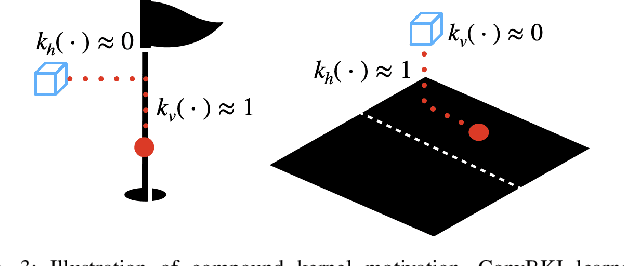
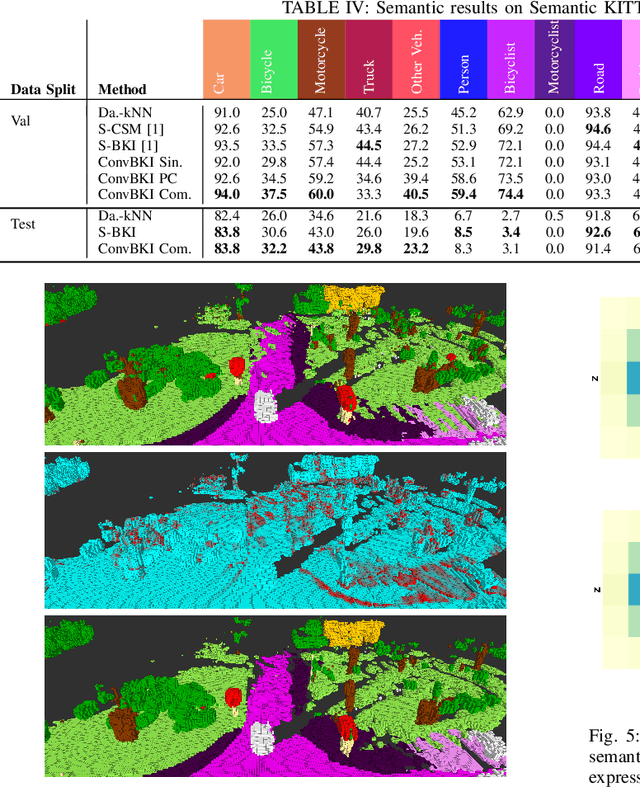
Robotic perception is currently at a cross-roads between modern methods which operate in an efficient latent space, and classical methods which are mathematically founded and provide interpretable, trustworthy results. In this paper, we introduce a Convolutional Bayesian Kernel Inference (ConvBKI) layer which explicitly performs Bayesian inference within a depthwise separable convolution layer to simultaneously maximize efficiency while maintaining reliability. We apply our layer to the task of 3D semantic mapping, where we learn semantic-geometric probability distributions for LiDAR sensor information in real time. We evaluate our network against state-of-the-art semantic mapping algorithms on the KITTI data set, and demonstrate improved latency with comparable semantic results.
Det-SLAM: A semantic visual SLAM for highly dynamic scenes using Detectron2
Oct 01, 2022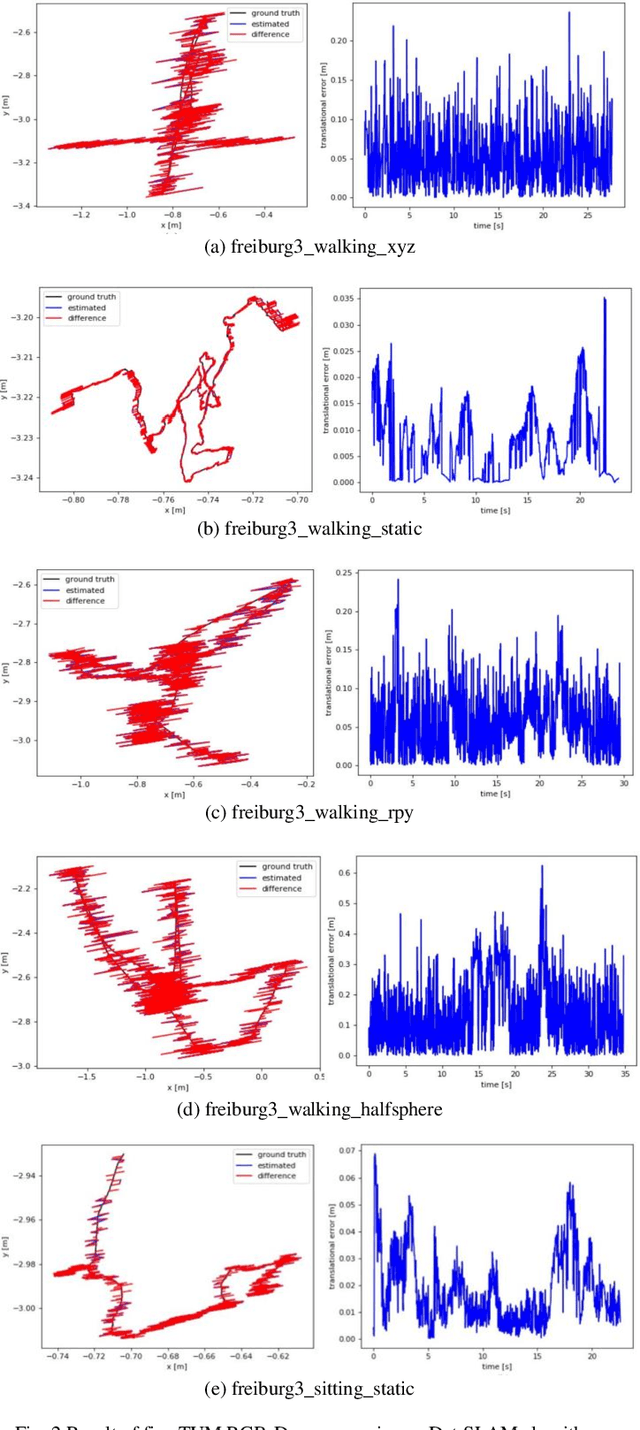
According to experts, Simultaneous Localization and Mapping (SLAM) is an intrinsic part of autonomous robotic systems. Several SLAM systems with impressive performance have been invented and used during the last several decades. However, there are still unresolved issues, such as how to deal with moving objects in dynamic situations. Classic SLAM systems depend on the assumption of a static environment, which becomes unworkable in highly dynamic situations. Several methods have been presented to tackle this issue in recent years, but each has its limitations. This research combines the visual SLAM systems ORB-SLAM3 and Detectron2 to present the Det-SLAM system, which employs depth information and semantic segmentation to identify and eradicate dynamic spots to accomplish semantic SLAM for dynamic situations. Evaluation of public TUM datasets indicates that Det-SLAM is more resilient than previous dynamic SLAM systems and can lower the estimated error of camera posture in dynamic indoor scenarios.
FORBID: Fast Overlap Removal By stochastic gradIent Descent for Graph Drawing
Aug 19, 2022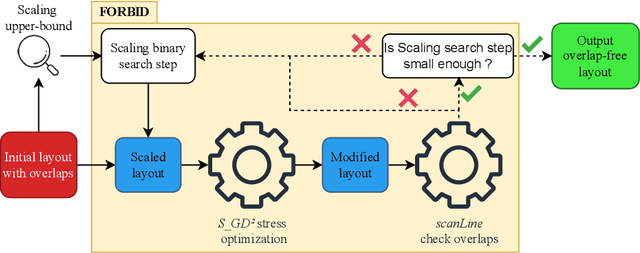
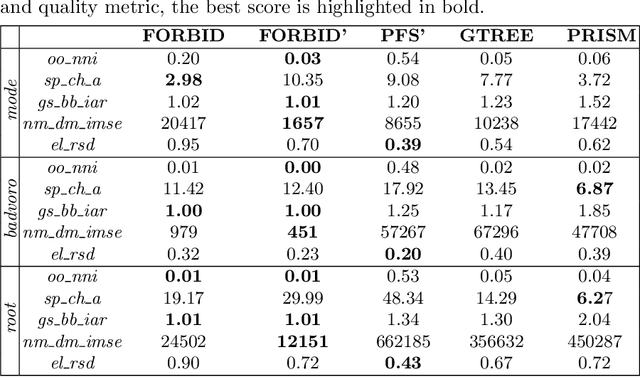
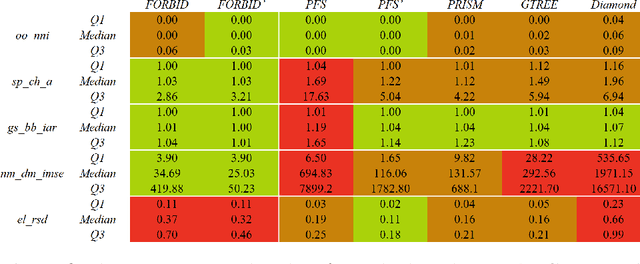

While many graph drawing algorithms consider nodes as points, graph visualization tools often represent them as shapes. These shapes support the display of information such as labels or encode various data with size or color. However, they can create overlaps between nodes which hinder the exploration process by hiding parts of the information. It is therefore of utmost importance to remove these overlaps to improve graph visualization readability. If not handled by the layout process, Overlap Removal (OR) algorithms have been proposed as layout post-processing. As graph layouts usually convey information about their topology, it is important that OR algorithms preserve them as much as possible. We propose a novel algorithm that models OR as a joint stress and scaling optimization problem, and leverages efficient stochastic gradient descent. This approach is compared with state-of-the-art algorithms, and several quality metrics demonstrate its efficiency to quickly remove overlaps while retaining the initial layout structures.
A Large-Scale Annotated Multivariate Time Series Aviation Maintenance Dataset from the NGAFID
Oct 13, 2022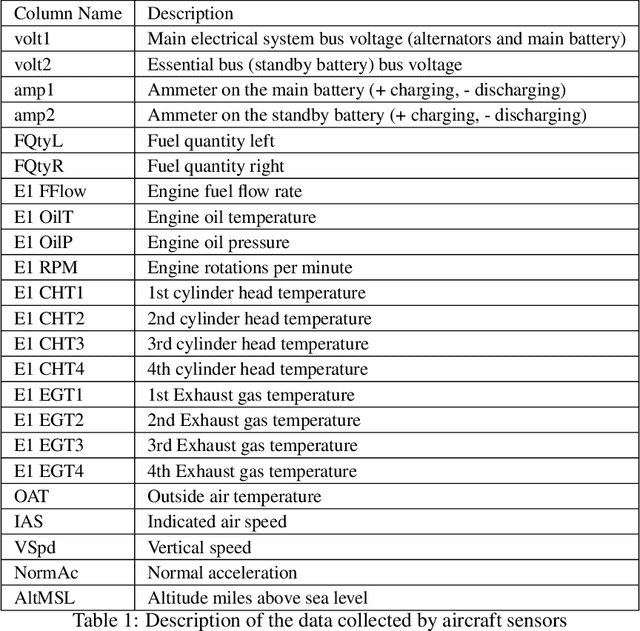
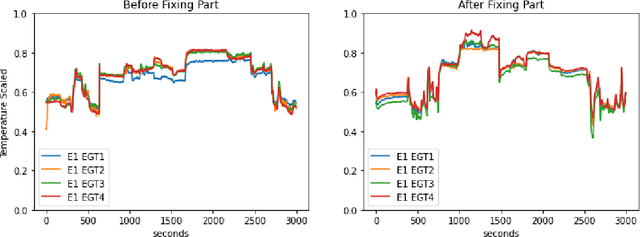
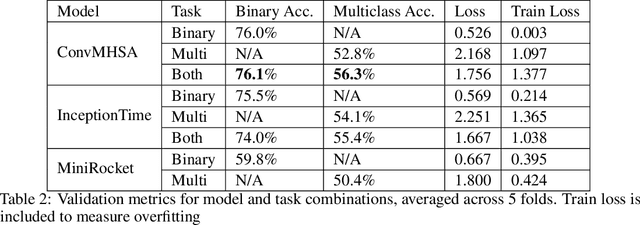
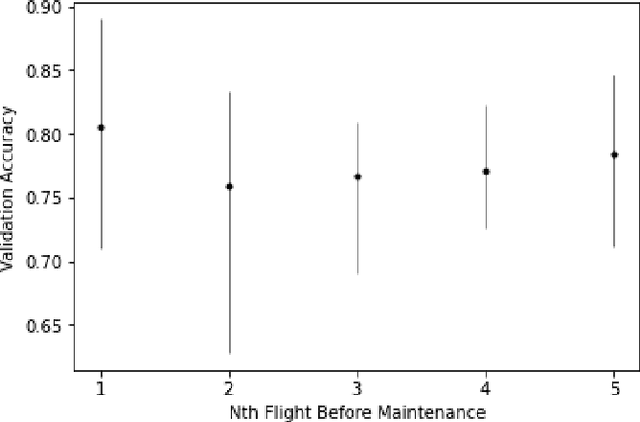
This paper presents the largest publicly available, non-simulated, fleet-wide aircraft flight recording and maintenance log data for use in predicting part failure and maintenance need. We present 31,177 hours of flight data across 28,935 flights, which occur relative to 2,111 unplanned maintenance events clustered into 36 types of maintenance issues. Flights are annotated as before or after maintenance, with some flights occurring on the day of maintenance. Collecting data to evaluate predictive maintenance systems is challenging because it is difficult, dangerous, and unethical to generate data from compromised aircraft. To overcome this, we use the National General Aviation Flight Information Database (NGAFID), which contains flights recorded during regular operation of aircraft, and maintenance logs to construct a part failure dataset. We use a novel framing of Remaining Useful Life (RUL) prediction and consider the probability that the RUL of a part is greater than 2 days. Unlike previous datasets generated with simulations or in laboratory settings, the NGAFID Aviation Maintenance Dataset contains real flight records and maintenance logs from different seasons, weather conditions, pilots, and flight patterns. Additionally, we provide Python code to easily download the dataset and a Colab environment to reproduce our benchmarks on three different models. Our dataset presents a difficult challenge for machine learning researchers and a valuable opportunity to test and develop prognostic health management methods
X-Align: Cross-Modal Cross-View Alignment for Bird's-Eye-View Segmentation
Oct 13, 2022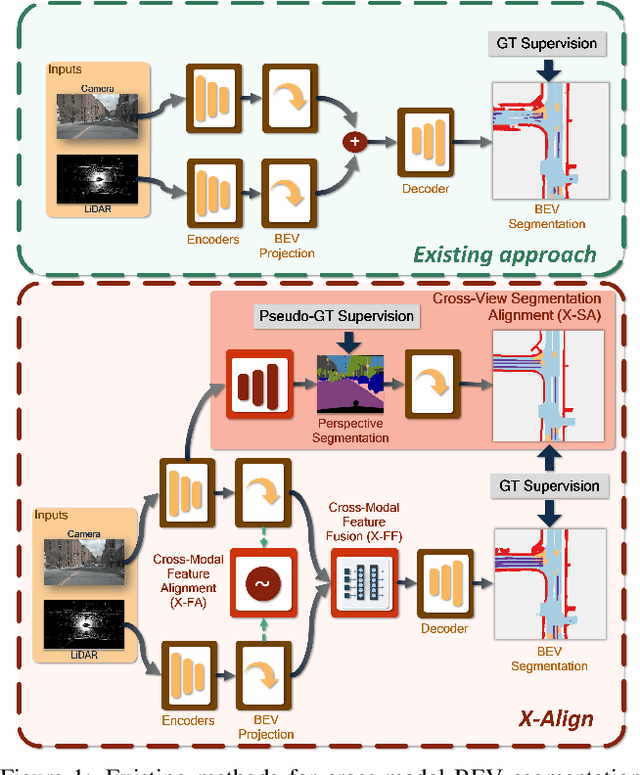
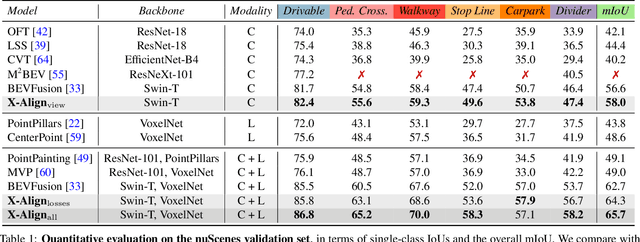
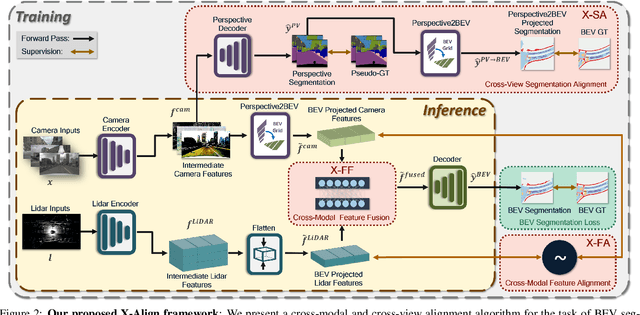

Bird's-eye-view (BEV) grid is a common representation for the perception of road components, e.g., drivable area, in autonomous driving. Most existing approaches rely on cameras only to perform segmentation in BEV space, which is fundamentally constrained by the absence of reliable depth information. Latest works leverage both camera and LiDAR modalities, but sub-optimally fuse their features using simple, concatenation-based mechanisms. In this paper, we address these problems by enhancing the alignment of the unimodal features in order to aid feature fusion, as well as enhancing the alignment between the cameras' perspective view (PV) and BEV representations. We propose X-Align, a novel end-to-end cross-modal and cross-view learning framework for BEV segmentation consisting of the following components: (i) a novel Cross-Modal Feature Alignment (X-FA) loss, (ii) an attention-based Cross-Modal Feature Fusion (X-FF) module to align multi-modal BEV features implicitly, and (iii) an auxiliary PV segmentation branch with Cross-View Segmentation Alignment (X-SA) losses to improve the PV-to-BEV transformation. We evaluate our proposed method across two commonly used benchmark datasets, i.e., nuScenes and KITTI-360. Notably, X-Align significantly outperforms the state-of-the-art by 3 absolute mIoU points on nuScenes. We also provide extensive ablation studies to demonstrate the effectiveness of the individual components.
Data augmentation on-the-fly and active learning in data stream classification
Oct 13, 2022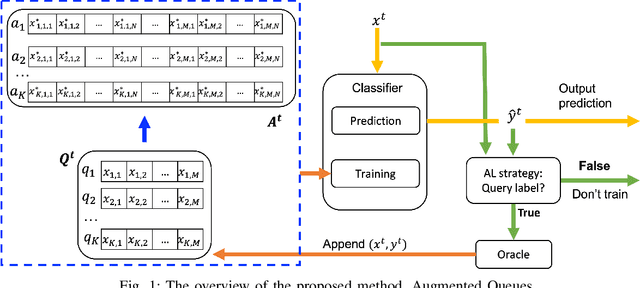
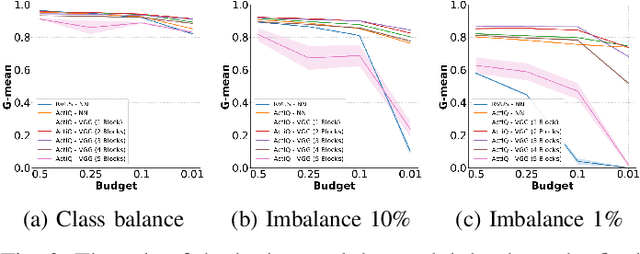
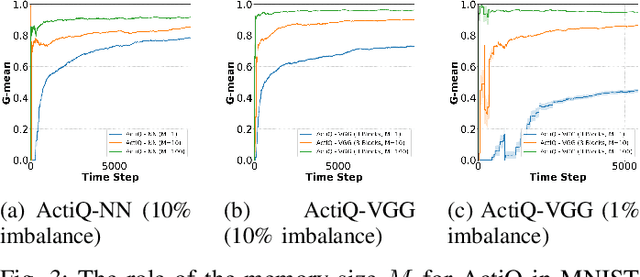
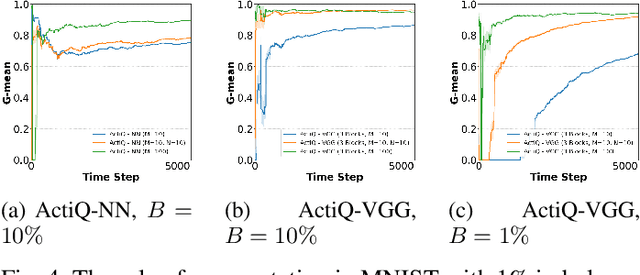
There is an emerging need for predictive models to be trained on-the-fly, since in numerous machine learning applications data are arriving in an online fashion. A critical challenge encountered is that of limited availability of ground truth information (e.g., labels in classification tasks) as new data are observed one-by-one online, while another significant challenge is that of class imbalance. This work introduces the novel Augmented Queues method, which addresses the dual-problem by combining in a synergistic manner online active learning, data augmentation, and a multi-queue memory to maintain separate and balanced queues for each class. We perform an extensive experimental study using image and time-series augmentations, in which we examine the roles of the active learning budget, memory size, imbalance level, and neural network type. We demonstrate two major advantages of Augmented Queues. First, it does not reserve additional memory space as the generation of synthetic data occurs only at training times. Second, learning models have access to more labelled data without the need to increase the active learning budget and / or the original memory size. Learning on-the-fly poses major challenges which, typically, hinder the deployment of learning models. Augmented Queues significantly improves the performance in terms of learning quality and speed. Our code is made publicly available.
* Keywords: incremental learning, active learning, data streams, class imbalance, neural networks
Query-Age-Optimal Scheduling under Sampling and Transmission Constraints
Sep 23, 2022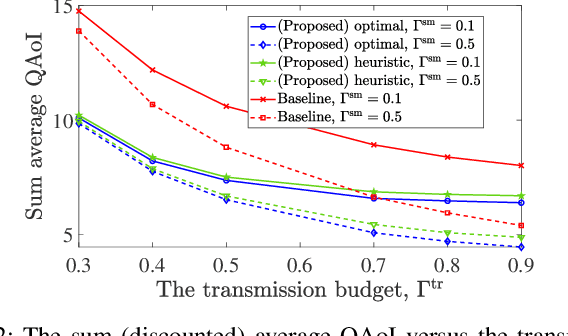
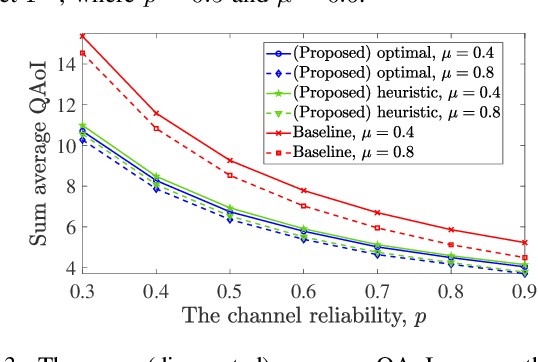
This letter provides query-age-optimal joint sam- pling and transmission scheduling policies for a heterogeneous status update system, consisting of a stochastic arrival and a generate-at-will source, with an unreliable channel. Our main goal is to minimize the average query age of information (QAoI) subject to average sampling, average transmission, and per-slot transmission constraints. To this end, an optimization problem is formulated and solved by casting it into a linear program. We also provide a low-complexity near-optimal policy using the notion of weakly coupled constrained Markov decision processes. The numerical results show up to 32% performance improvement by the proposed policies compared with a benchmark policy.
Reducing safe UAV separation distances with U2U communication and new Remote ID formats
Sep 27, 2022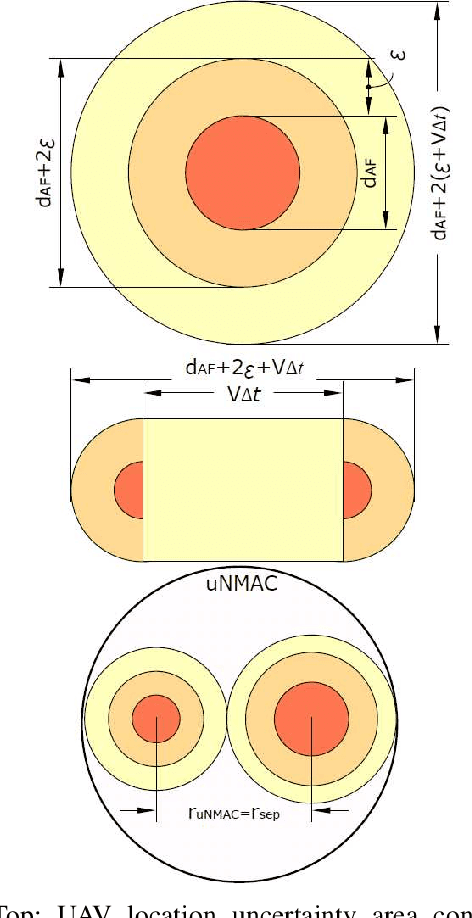
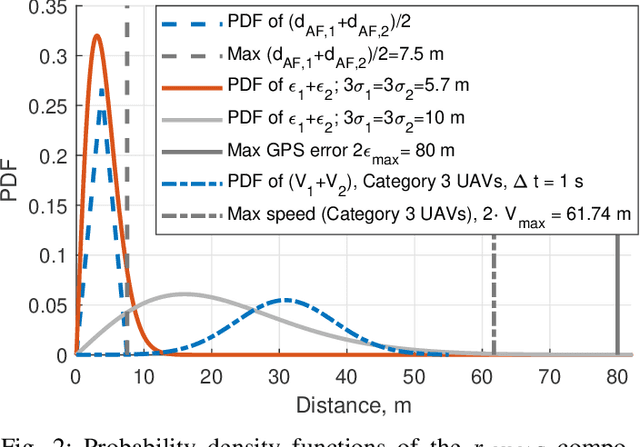
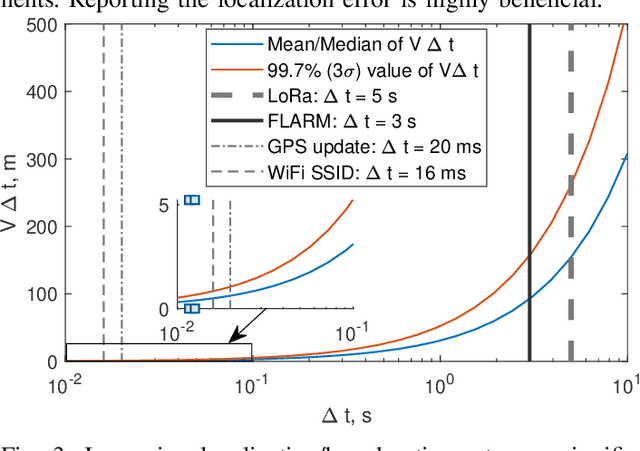
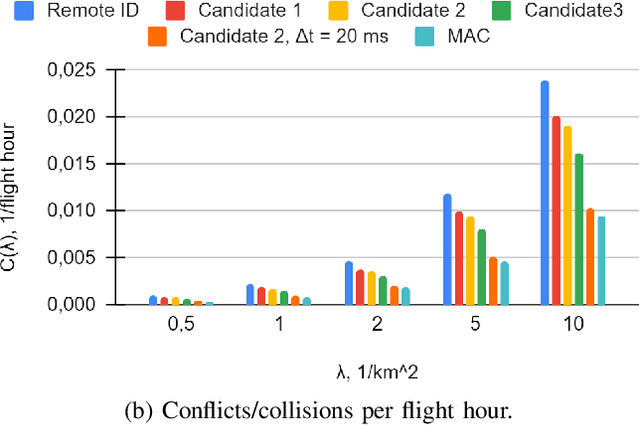
As the number of Unmanned Aerial Vehicles (UAVs) in the airspace grows, ensuring that the aircraft do not collide becomes vital for further technology development. In this work, we propose a new UAV Near Mid-Air collision (uNMAC) safety volume taking into account i) Airframe size, ii) Localization precision, iii) UAV speed/velocity, and iv) wireless technology capabilities. Based on uNMAC, we demonstrate that inter-UAV separation distances can be reduced by using UAV-to-UAV (U2U) communication while the safety levels remain unchanged. Moreover, this work shows that next-generation Remote ID messages should contain additional information (i.e., estimated localization error and, for some applications, movement direction). As frequent broadcasting of Remote ID can further reduce the separation distances, we identified 5G NR Sidelink, Wi-Fi, and Bluetooth as suitable candidates for U2U communication.
TRBoost: A Generic Gradient Boosting Machine based on Trust-region Method
Oct 08, 2022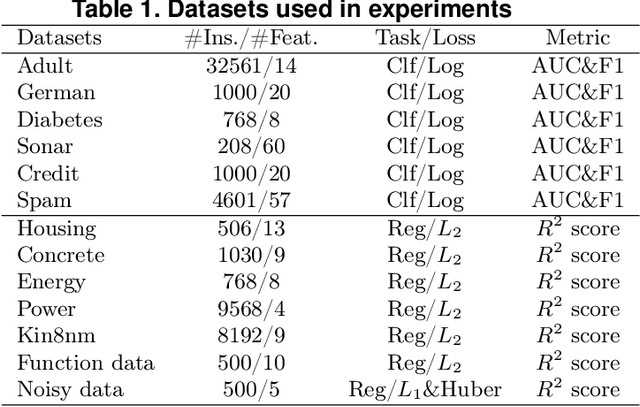
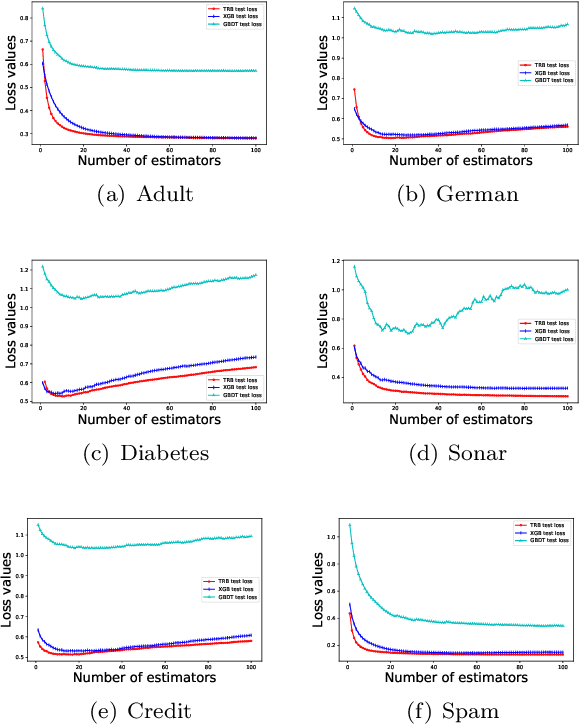
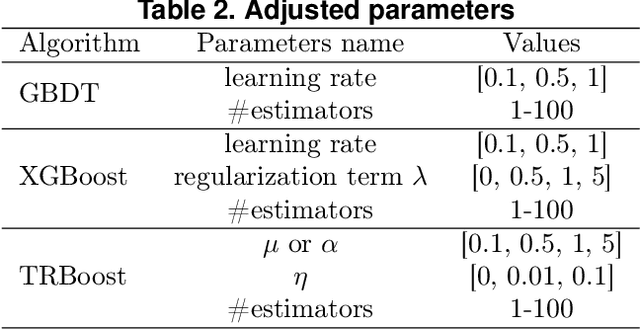
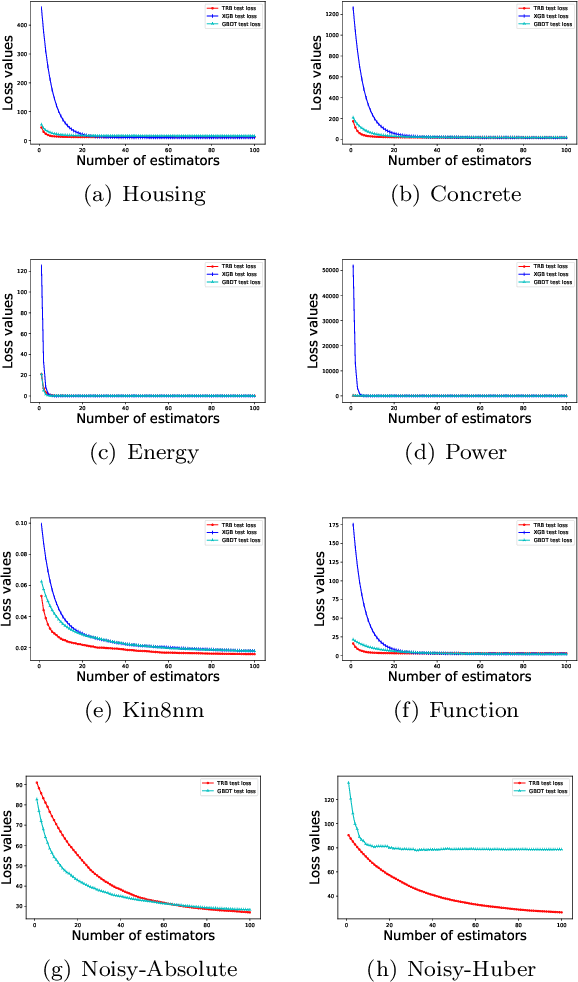
Gradient Boosting Machines (GBMs) are derived from Taylor expansion in functional space and have achieved state-of-the-art results on a variety of problems. However, there is a dilemma for GBMs to maintain a balance between performance and generality. Specifically, gradient descent-based GBMs employ the first-order Taylor expansion to make them appropriate for all loss functions. And Newton's method-based GBMs use the positive hessian information to achieve better performance at the expense of generality. In this paper, a generic Gradient Boosting Machine called Trust-region Boosting (TRBoost) is presented to maintain this balance. In each iteration, we apply a constrained quadratic model to approximate the objective and solve it by the Trust-region algorithm to obtain a new learner. TRBoost offers the benefit that we do not need the hessian to be positive definite, which generalizes GBMs to suit arbitrary loss functions while keeping up the good performance as the second-order algorithm. Several numerical experiments are conducted to confirm that TRBoost is not only as general as the first-order GBMs but also able to get competitive results with the second-order GBMs.
Bottleneck Analysis of Dynamic Graph Neural Network Inference on CPU and GPU
Oct 08, 2022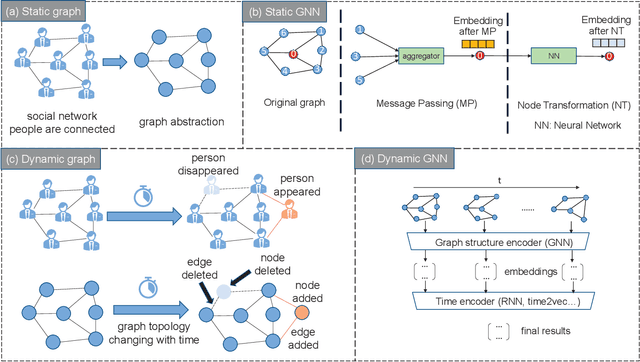
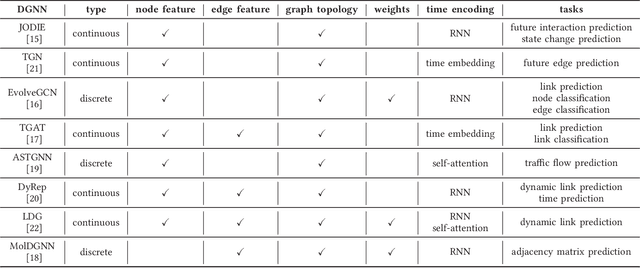
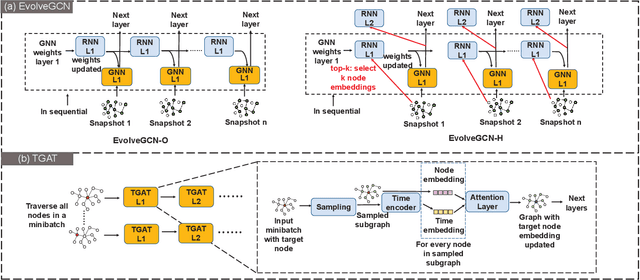
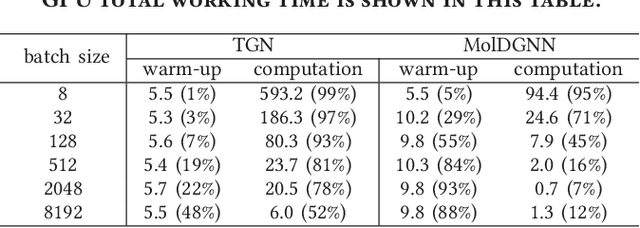
Dynamic graph neural network (DGNN) is becoming increasingly popular because of its widespread use in capturing dynamic features in the real world. A variety of dynamic graph neural networks designed from algorithmic perspectives have succeeded in incorporating temporal information into graph processing. Despite the promising algorithmic performance, deploying DGNNs on hardware presents additional challenges due to the model complexity, diversity, and the nature of the time dependency. Meanwhile, the differences between DGNNs and static graph neural networks make hardware-related optimizations for static graph neural networks unsuitable for DGNNs. In this paper, we select eight prevailing DGNNs with different characteristics and profile them on both CPU and GPU. The profiling results are summarized and analyzed, providing in-depth insights into the bottlenecks of DGNNs on hardware and identifying potential optimization opportunities for future DGNN acceleration. Followed by a comprehensive survey, we provide a detailed analysis of DGNN performance bottlenecks on hardware, including temporal data dependency, workload imbalance, data movement, and GPU warm-up. We suggest several optimizations from both software and hardware perspectives. This paper is the first to provide an in-depth analysis of the hardware performance of DGNN Code is available at https://github.com/sharc-lab/DGNN_analysis.