 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Synthetic Dataset Generation for Privacy-Preserving Machine Learning
Oct 10, 2022
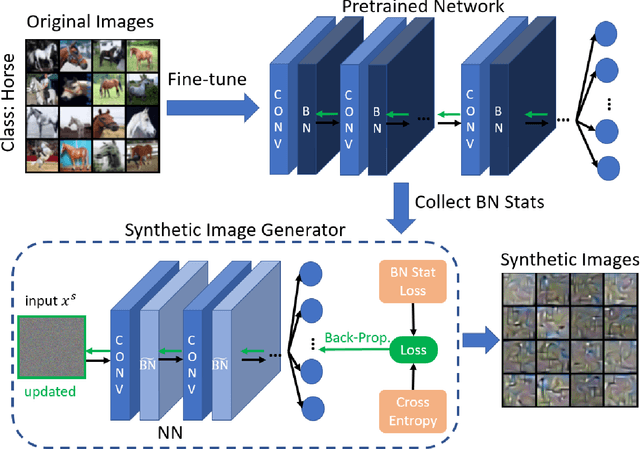



Machine Learning (ML) has achieved enormous success in solving a variety of problems in computer vision, speech recognition, object detection, to name a few. The principal reason for this success is the availability of huge datasets for training deep neural networks (DNNs). However, datasets cannot be publicly released if they contain sensitive information such as medical records, and data privacy becomes a major concern. Encryption methods could be a possible solution, however their deployment on ML applications seriously impacts classification accuracy and results in substantial computational overhead. Alternatively, obfuscation techniques could be used, but maintaining a good trade-off between visual privacy and accuracy is challenging. In this paper, we propose a method to generate secure synthetic datasets from the original private datasets. Given a network with Batch Normalization (BN) layers pretrained on the original dataset, we first record the class-wise BN layer statistics. Next, we generate the synthetic dataset by optimizing random noise such that the synthetic data match the layer-wise statistical distribution of original images. We evaluate our method on image classification datasets (CIFAR10, ImageNet) and show that synthetic data can be used in place of the original CIFAR10/ImageNet data for training networks from scratch, producing comparable classification performance. Further, to analyze visual privacy provided by our method, we use Image Quality Metrics and show high degree of visual dissimilarity between the original and synthetic images. Moreover, we show that our proposed method preserves data-privacy under various privacy-leakage attacks including Gradient Matching Attack, Model Memorization Attack, and GAN-based Attack.
Scientific Machine Learning for Modeling and Simulating Complex Fluids
Oct 10, 2022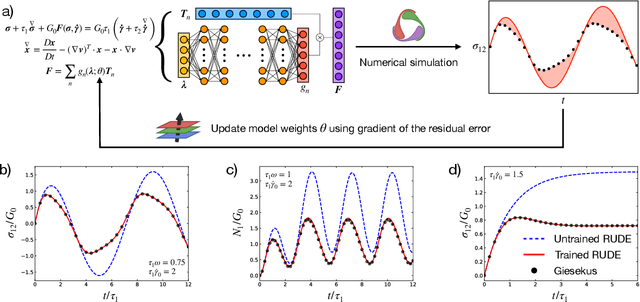
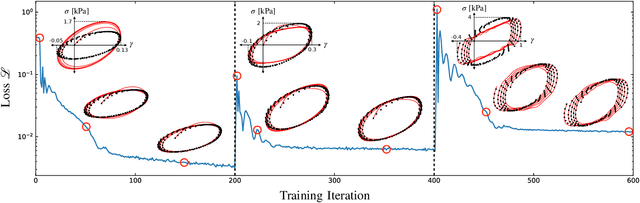
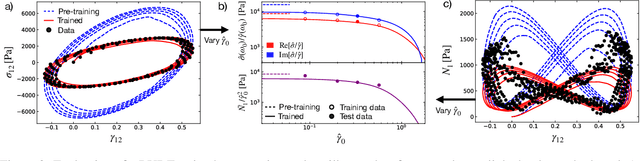
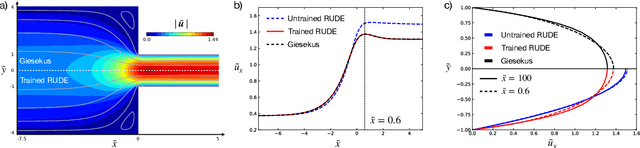
The formulation of rheological constitutive equations -- models that relate internal stresses and deformations in complex fluids -- is a critical step in the engineering of systems involving soft materials. While data-driven models provide accessible alternatives to expensive first-principles models and less accurate empirical models in many engineering disciplines, the development of similar models for complex fluids has lagged. The diversity of techniques for characterizing non-Newtonian fluid dynamics creates a challenge for classical machine learning approaches, which require uniformly structured training data. Consequently, early machine learning constitutive equations have not been portable between different deformation protocols or mechanical observables. Here, we present a data-driven framework that resolves such issues, allowing rheologists to construct learnable models that incorporate essential physical information, while remaining agnostic to details regarding particular experimental protocols or flow kinematics. These scientific machine learning models incorporate a universal approximator within a materially objective tensorial constitutive framework. By construction, these models respect physical constraints, such as frame-invariance and tensor symmetry, required by continuum mechanics. We demonstrate that this framework facilitates the rapid discovery of accurate constitutive equations from limited data, and that the learned models may be used to describe more kinematically complex flows. This inherent flexibility admits the application of these 'digital fluid twins' to a range of material systems and engineering problems. We illustrate this flexibility by deploying a trained model within a multidimensional computational fluid dynamics simulation -- a task that is not achievable using any previously developed data-driven rheological equation of state.
Modeling and Mining Multi-Aspect Graphs With Scalable Streaming Tensor Decomposition
Oct 10, 2022Graphs emerge in almost every real-world application domain, ranging from online social networks all the way to health data and movie viewership patterns. Typically, such real-world graphs are big and dynamic, in the sense that they evolve over time. Furthermore, graphs usually contain multi-aspect information i.e. in a social network, we can have the "means of communication" between nodes, such as who messages whom, who calls whom, and who comments on whose timeline and so on. How can we model and mine useful patterns, such as communities of nodes in that graph, from such multi-aspect graphs? How can we identify dynamic patterns in those graphs, and how can we deal with streaming data, when the volume of data to be processed is very large? In order to answer those questions, in this thesis, we propose novel tensor-based methods for mining static and dynamic multi-aspect graphs. In general, a tensor is a higher-order generalization of a matrix that can represent high-dimensional multi-aspect data such as time-evolving networks, collaboration networks, and spatio-temporal data like Electroencephalography (EEG) brain measurements. The thesis is organized in two synergistic thrusts: First, we focus on static multi-aspect graphs, where the goal is to identify coherent communities and patterns between nodes by leveraging the tensor structure in the data. Second, as our graphs evolve dynamically, we focus on handling such streaming updates in the data without having to re-compute the decomposition, but incrementally update the existing results.
Variation and generality in encoding of syntactic anomaly information in sentence embeddings
Nov 12, 2021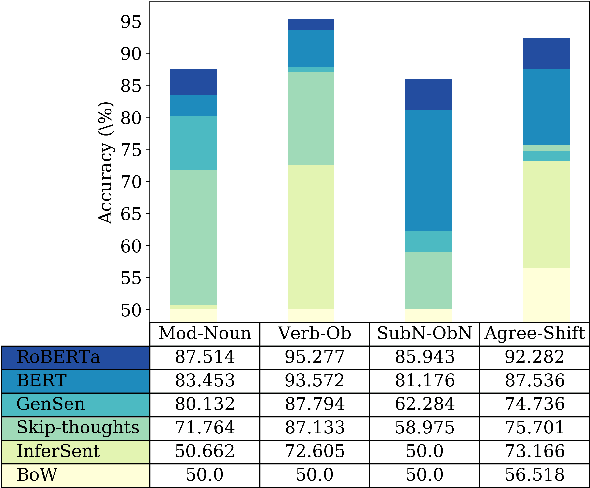

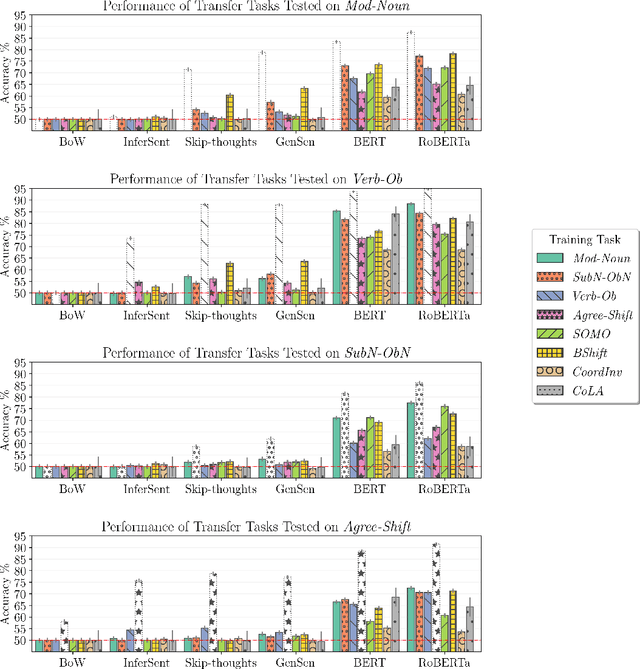

While sentence anomalies have been applied periodically for testing in NLP, we have yet to establish a picture of the precise status of anomaly information in representations from NLP models. In this paper we aim to fill two primary gaps, focusing on the domain of syntactic anomalies. First, we explore fine-grained differences in anomaly encoding by designing probing tasks that vary the hierarchical level at which anomalies occur in a sentence. Second, we test not only models' ability to detect a given anomaly, but also the generality of the detected anomaly signal, by examining transfer between distinct anomaly types. Results suggest that all models encode some information supporting anomaly detection, but detection performance varies between anomalies, and only representations from more recent transformer models show signs of generalized knowledge of anomalies. Follow-up analyses support the notion that these models pick up on a legitimate, general notion of sentence oddity, while coarser-grained word position information is likely also a contributor to the observed anomaly detection.
PCB-RandNet: Rethinking Random Sampling for LIDAR Semantic Segmentation in Autonomous Driving Scene
Sep 28, 2022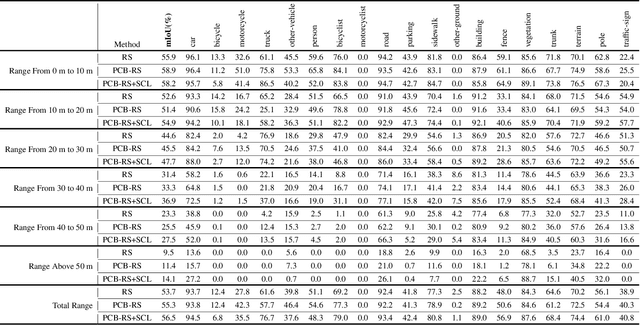
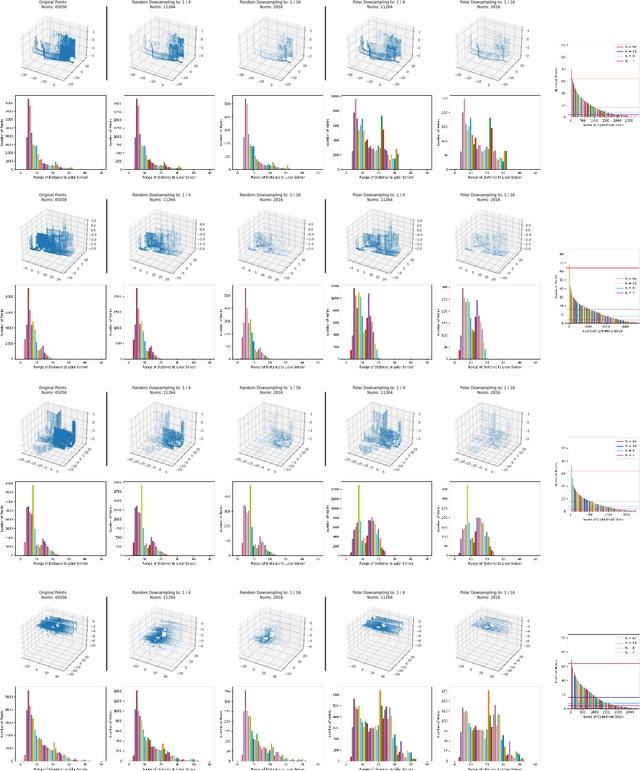
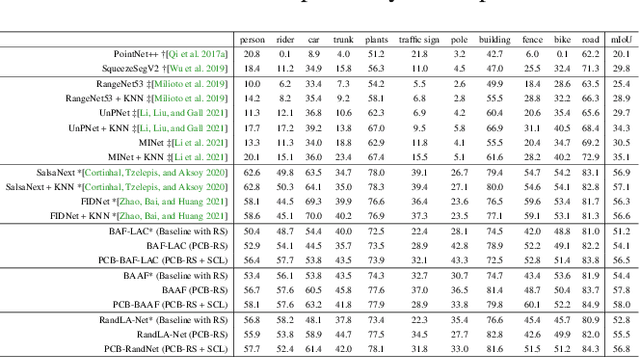
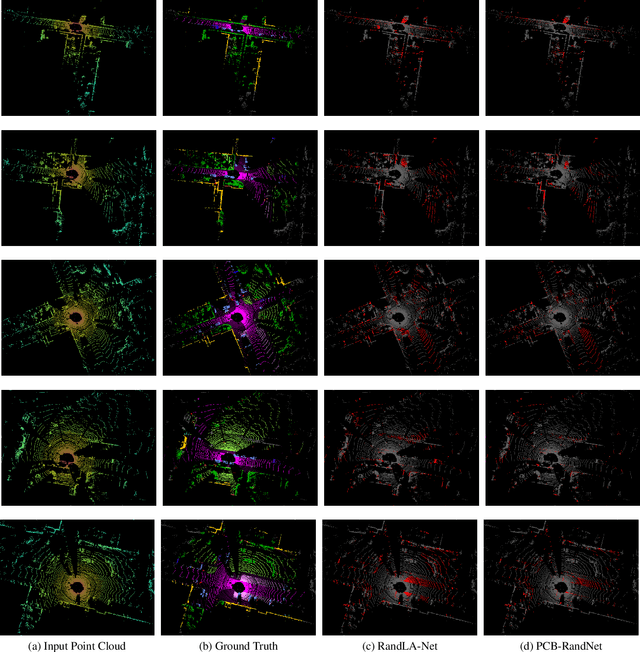
Fast and efficient semantic segmentation of large-scale LiDAR point clouds is a fundamental problem in autonomous driving. To achieve this goal, the existing point-based methods mainly choose to adopt Random Sampling strategy to process large-scale point clouds. However, our quantative and qualitative studies have found that Random Sampling may be less suitable for the autonomous driving scenario, since the LiDAR points follow an uneven or even long-tailed distribution across the space, which prevents the model from capturing sufficient information from points in different distance ranges and reduces the model's learning capability. To alleviate this problem, we propose a new Polar Cylinder Balanced Random Sampling method that enables the downsampled point clouds to maintain a more balanced distribution and improve the segmentation performance under different spatial distributions. In addition, a sampling consistency loss is introduced to further improve the segmentation performance and reduce the model's variance under different sampling methods. Extensive experiments confirm that our approach produces excellent performance on both SemanticKITTI and SemanticPOSS benchmarks, achieving a 2.8% and 4.0% improvement, respectively.
Variational prompt tuning improves generalization of vision-language models
Oct 05, 2022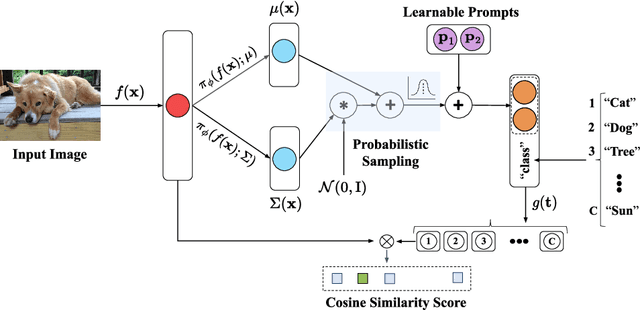
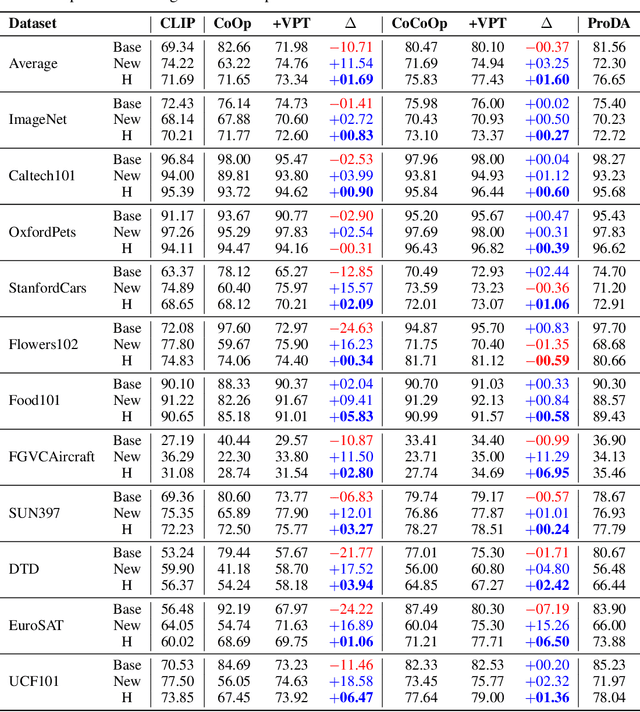
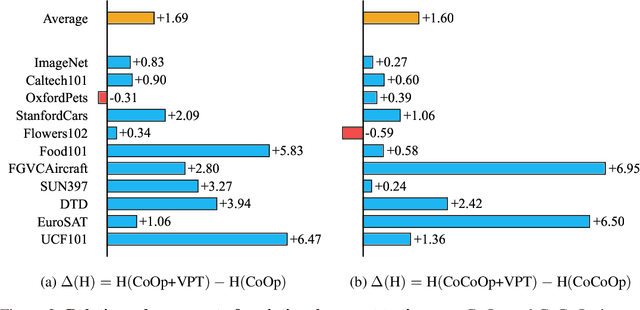
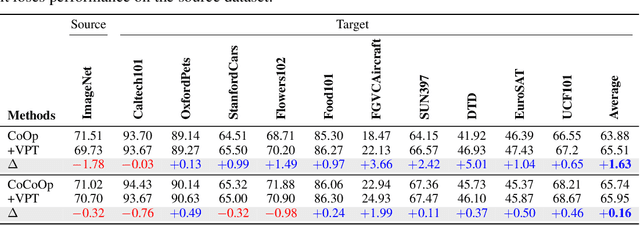
Prompt tuning provides an efficient mechanism to adapt large vision-language models to downstream tasks by treating part of the input language prompts as learnable parameters while freezing the rest of the model. Existing works for prompt tuning are however prone to damaging the generalization capabilities of the foundation models, because the learned prompts lack the capacity of covering certain concepts within the language model. To avoid such limitation, we propose a probabilistic modeling of the underlying distribution of prompts, allowing prompts within the support of an associated concept to be derived through stochastic sampling. This results in a more complete and richer transfer of the information captured by the language model, providing better generalization capabilities for downstream tasks. The resulting algorithm relies on a simple yet powerful variational framework that can be directly integrated with other developments. We show our approach is seamlessly integrated into both standard and conditional prompt learning frameworks, improving the performance on both cases considerably, especially with regards to preserving the generalization capability of the original model. Our method provides the current state-of-the-art for prompt learning, surpassing CoCoOp by 1.6% average Top-1 accuracy on the standard benchmark. Remarkably, it even surpasses the original CLIP model in terms of generalization to new classes. Implementation code will be released.
Reactive Anticipatory Robot Skills with Memory
Sep 23, 2022



Optimal control in robotics has been increasingly popular in recent years and has been applied in many applications involving complex dynamical systems. Closed-loop optimal control strategies include model predictive control (MPC) and time-varying linear controllers optimized through iLQR. However, such feedback controllers rely on the information of the current state, limiting the range of robotic applications where the robot needs to remember what it has done before to act and plan accordingly. The recently proposed system level synthesis (SLS) framework circumvents this limitation via a richer controller structure with memory. In this work, we propose to optimally design reactive anticipatory robot skills with memory by extending SLS to tracking problems involving nonlinear systems and nonquadratic cost functions. We showcase our method with two scenarios exploiting task precisions and object affordances in pick-and-place tasks in a simulated and a real environment with a 7-axis Franka Emika robot.
Text Revealer: Private Text Reconstruction via Model Inversion Attacks against Transformers
Sep 21, 2022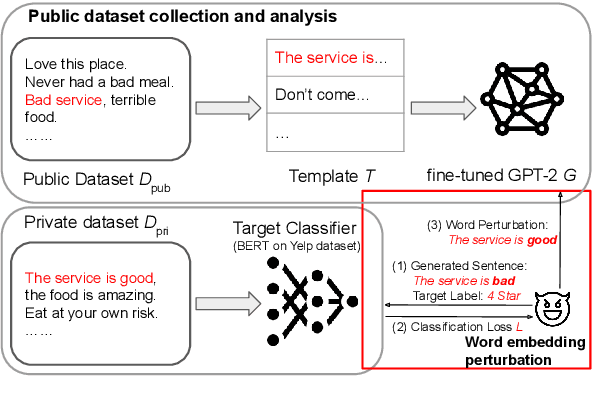

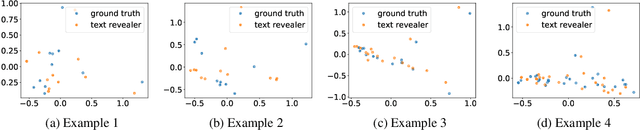
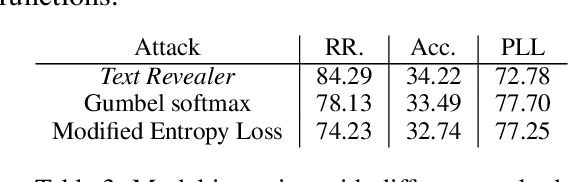
Text classification has become widely used in various natural language processing applications like sentiment analysis. Current applications often use large transformer-based language models to classify input texts. However, there is a lack of systematic study on how much private information can be inverted when publishing models. In this paper, we formulate \emph{Text Revealer} -- the first model inversion attack for text reconstruction against text classification with transformers. Our attacks faithfully reconstruct private texts included in training data with access to the target model. We leverage an external dataset and GPT-2 to generate the target domain-like fluent text, and then perturb its hidden state optimally with the feedback from the target model. Our extensive experiments demonstrate that our attacks are effective for datasets with different text lengths and can reconstruct private texts with accuracy.
Single-source Domain Expansion Network for Cross-Scene Hyperspectral Image Classification
Sep 04, 2022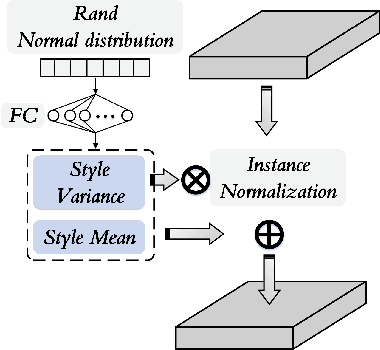
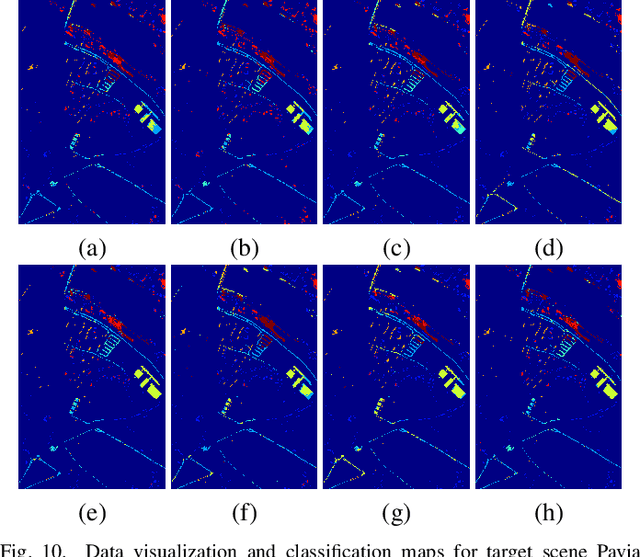
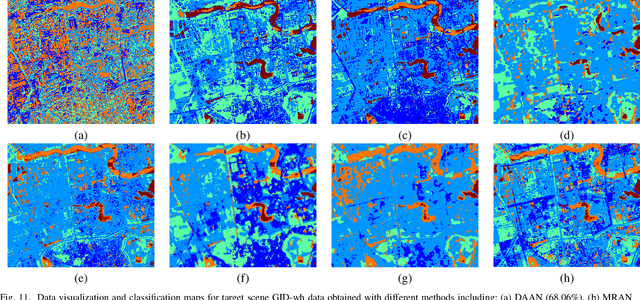
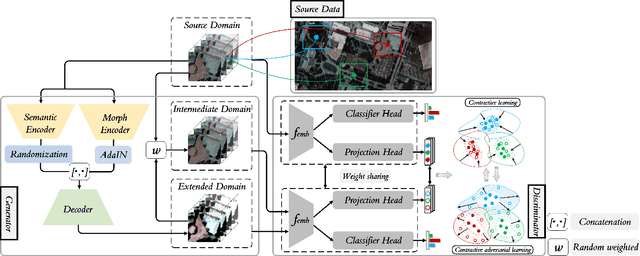
Currently, cross-scene hyperspectral image (HSI) classification has drawn increasing attention. It is necessary to train a model only on source domain (SD) and directly transferring the model to target domain (TD), when TD needs to be processed in real time and cannot be reused for training. Based on the idea of domain generalization, a Single-source Domain Expansion Network (SDEnet) is developed to ensure the reliability and effectiveness of domain extension. The method uses generative adversarial learning to train in SD and test in TD. A generator including semantic encoder and morph encoder is designed to generate the extended domain (ED) based on encoder-randomization-decoder architecture, where spatial and spectral randomization are specifically used to generate variable spatial and spectral information, and the morphological knowledge is implicitly applied as domain invariant information during domain expansion. Furthermore, the supervised contrastive learning is employed in the discriminator to learn class-wise domain invariant representation, which drives intra-class samples of SD and ED. Meanwhile, adversarial training is designed to optimize the generator to drive intra-class samples of SD and ED to be separated. Extensive experiments on two public HSI datasets and one additional multispectral image (MSI) dataset demonstrate the superiority of the proposed method when compared with state-of-the-art techniques.
Selecting Stickers in Open-Domain Dialogue through Multitask Learning
Sep 16, 2022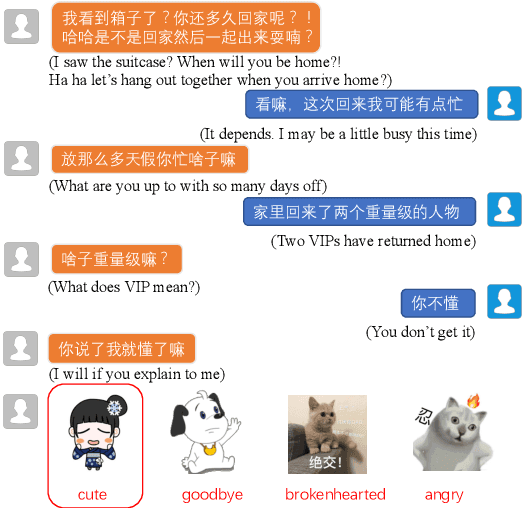
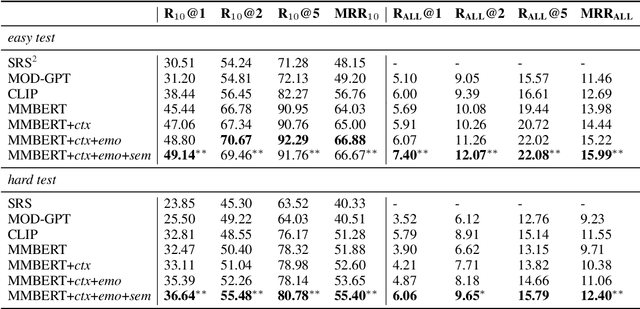
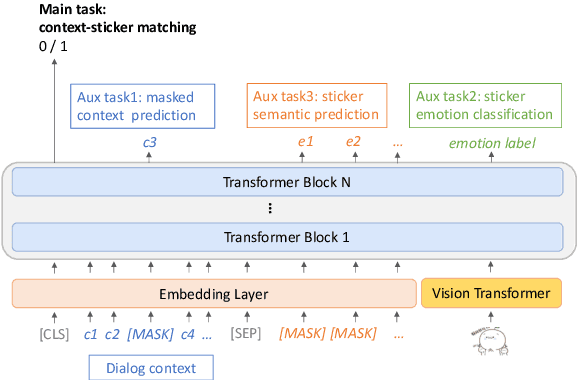
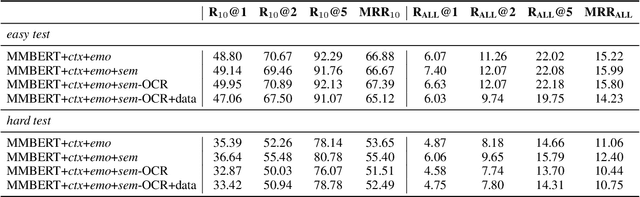
With the increasing popularity of online chatting, stickers are becoming important in our online communication. Selecting appropriate stickers in open-domain dialogue requires a comprehensive understanding of both dialogues and stickers, as well as the relationship between the two types of modalities. To tackle these challenges, we propose a multitask learning method comprised of three auxiliary tasks to enhance the understanding of dialogue history, emotion and semantic meaning of stickers. Extensive experiments conducted on a recent challenging dataset show that our model can better combine the multimodal information and achieve significantly higher accuracy over strong baselines. Ablation study further verifies the effectiveness of each auxiliary task. Our code is available at \url{https://github.com/nonstopfor/Sticker-Selection}