 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
An Efficient FPGA Accelerator for Point Cloud
Oct 14, 2022
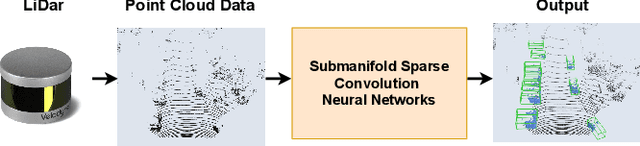
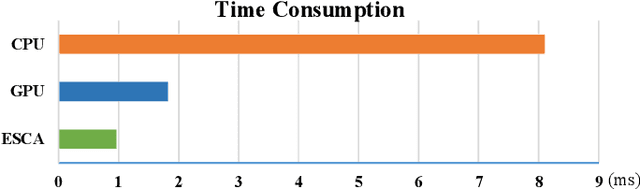
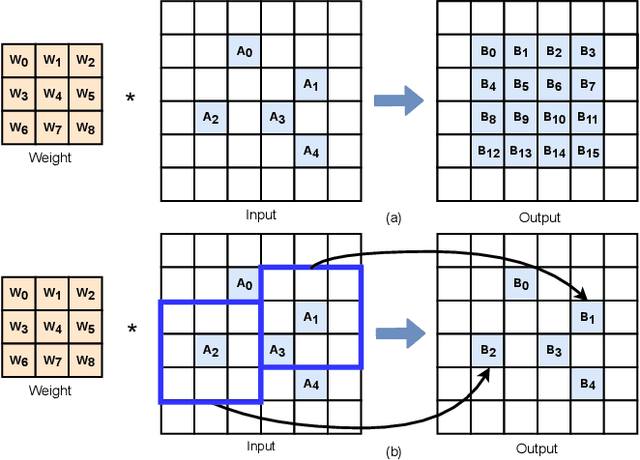
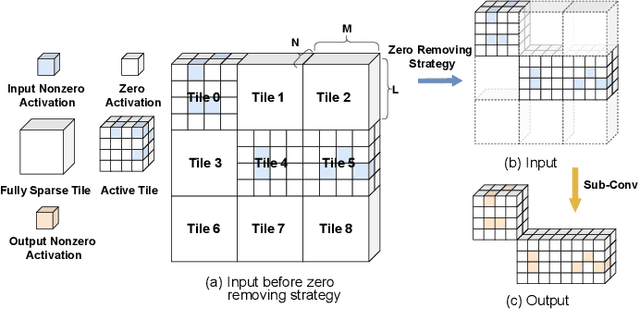
Deep learning-based point cloud processing plays an important role in various vision tasks, such as autonomous driving, virtual reality (VR), and augmented reality (AR). The submanifold sparse convolutional network (SSCN) has been widely used for the point cloud due to its unique advantages in terms of visual results. However, existing convolutional neural network accelerators suffer from non-trivial performance degradation when employed to accelerate SSCN because of the extreme and unstructured sparsity, and the complex computational dependency between the sparsity of the central activation and the neighborhood ones. In this paper, we propose a high performance FPGA-based accelerator for SSCN. Firstly, we develop a zero removing strategy to remove the coarse-grained redundant regions, thus significantly improving computational efficiency. Secondly, we propose a concise encoding scheme to obtain the matching information for efficient point-wise multiplications. Thirdly, we develop a sparse data matching unit and a computing core based on the proposed encoding scheme, which can convert the irregular sparse operations into regular multiply-accumulate operations. Finally, an efficient hardware architecture for the submanifold sparse convolutional layer is developed and implemented on the Xilinx ZCU102 field-programmable gate array board, where the 3D submanifold sparse U-Net is taken as the benchmark. The experimental results demonstrate that our design drastically improves computational efficiency, and can dramatically improve the power efficiency by 51 times compared to GPU.
HashFormers: Towards Vocabulary-independent Pre-trained Transformers
Oct 14, 2022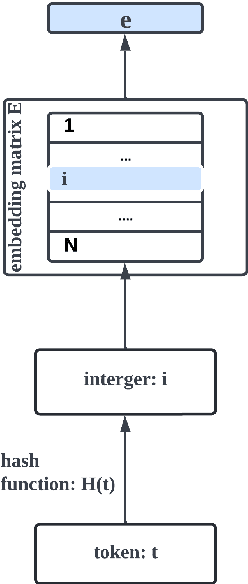
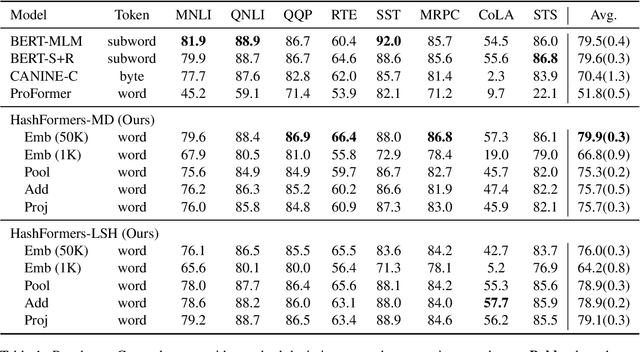
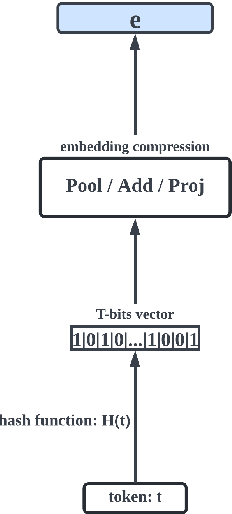
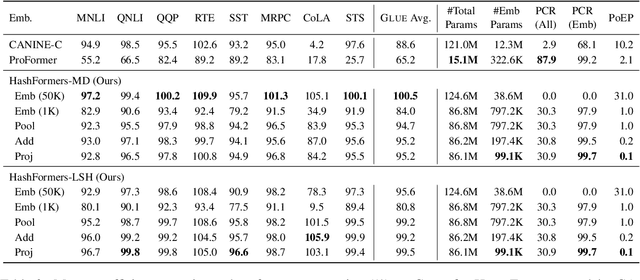
Transformer-based pre-trained language models are vocabulary-dependent, mapping by default each token to its corresponding embedding. This one-to-one mapping results into embedding matrices that occupy a lot of memory (i.e. millions of parameters) and grow linearly with the size of the vocabulary. Previous work on on-device transformers dynamically generate token embeddings on-the-fly without embedding matrices using locality-sensitive hashing over morphological information. These embeddings are subsequently fed into transformer layers for text classification. However, these methods are not pre-trained. Inspired by this line of work, we propose HashFormers, a new family of vocabulary-independent pre-trained transformers that support an unlimited vocabulary (i.e. all possible tokens in a corpus) given a substantially smaller fixed-sized embedding matrix. We achieve this by first introducing computationally cheap hashing functions that bucket together individual tokens to embeddings. We also propose three variants that do not require an embedding matrix at all, further reducing the memory requirements. We empirically demonstrate that HashFormers are more memory efficient compared to standard pre-trained transformers while achieving comparable predictive performance when fine-tuned on multiple text classification tasks. For example, our most efficient HashFormer variant has a negligible performance degradation (0.4\% on GLUE) using only 99.1K parameters for representing the embeddings compared to 12.3-38M parameters of state-of-the-art models.
The Surprisingly Straightforward Scene Text Removal Method With Gated Attention and Region of Interest Generation: A Comprehensive Prominent Model Analysis
Oct 14, 2022
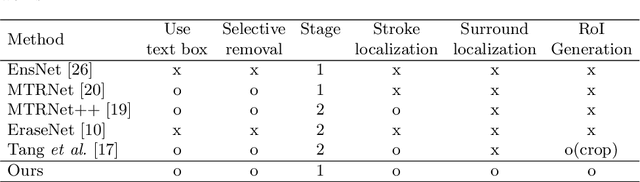
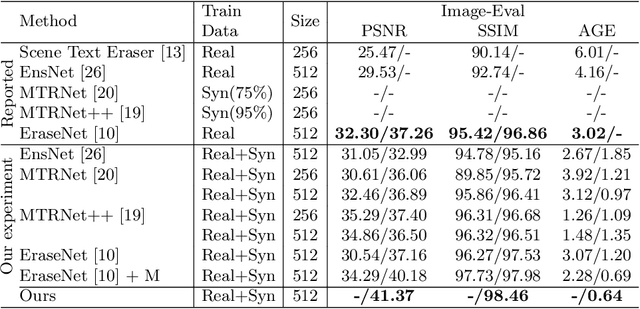
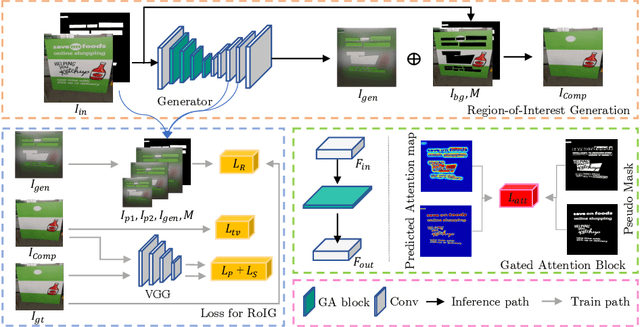
Scene text removal (STR), a task of erasing text from natural scene images, has recently attracted attention as an important component of editing text or concealing private information such as ID, telephone, and license plate numbers. While there are a variety of different methods for STR actively being researched, it is difficult to evaluate superiority because previously proposed methods do not use the same standardized training/evaluation dataset. We use the same standardized training/testing dataset to evaluate the performance of several previous methods after standardized re-implementation. We also introduce a simple yet extremely effective Gated Attention (GA) and Region-of-Interest Generation (RoIG) methodology in this paper. GA uses attention to focus on the text stroke as well as the textures and colors of the surrounding regions to remove text from the input image much more precisely. RoIG is applied to focus on only the region with text instead of the entire image to train the model more efficiently. Experimental results on the benchmark dataset show that our method significantly outperforms existing state-of-the-art methods in almost all metrics with remarkably higher-quality results. Furthermore, because our model does not generate a text stroke mask explicitly, there is no need for additional refinement steps or sub-models, making our model extremely fast with fewer parameters. The dataset and code are available at this https://github.com/naver/garnet.
BioIE: Biomedical Information Extraction with Multi-head Attention Enhanced Graph Convolutional Network
Oct 26, 2021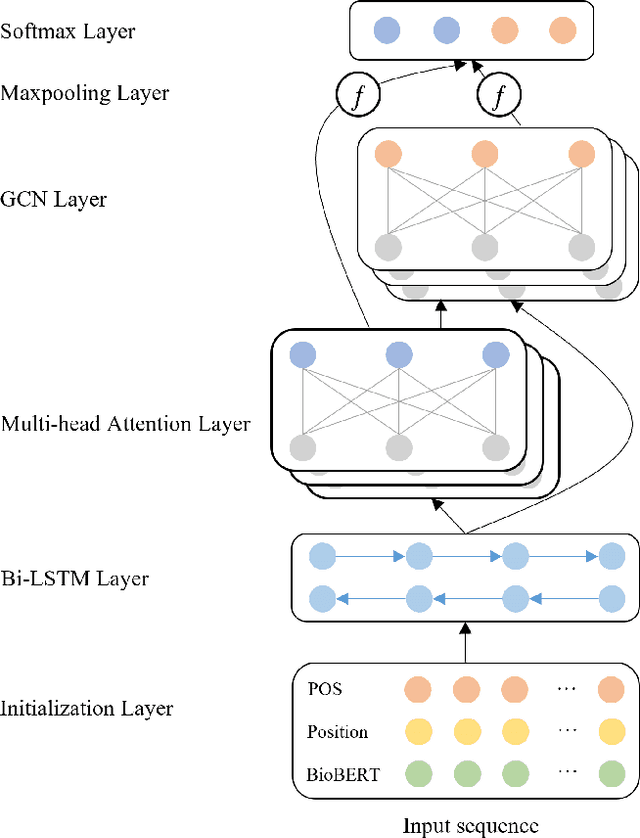

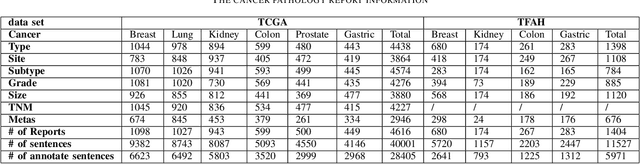

Constructing large-scaled medical knowledge graphs can significantly boost healthcare applications for medical surveillance, bring much attention from recent research. An essential step in constructing large-scale MKG is extracting information from medical reports. Recently, information extraction techniques have been proposed and show promising performance in biomedical information extraction. However, these methods only consider limited types of entity and relation due to the noisy biomedical text data with complex entity correlations. Thus, they fail to provide enough information for constructing MKGs and restrict the downstream applications. To address this issue, we propose Biomedical Information Extraction, a hybrid neural network to extract relations from biomedical text and unstructured medical reports. Our model utilizes a multi-head attention enhanced graph convolutional network to capture the complex relations and context information while resisting the noise from the data. We evaluate our model on two major biomedical relationship extraction tasks, chemical-disease relation and chemical-protein interaction, and a cross-hospital pan-cancer pathology report corpus. The results show that our method achieves superior performance than baselines. Furthermore, we evaluate the applicability of our method under a transfer learning setting and show that BioIE achieves promising performance in processing medical text from different formats and writing styles.
Cost-effective photonic super-resolution millimeter-wave joint radar-communication system using self-coherent detection
Oct 09, 2022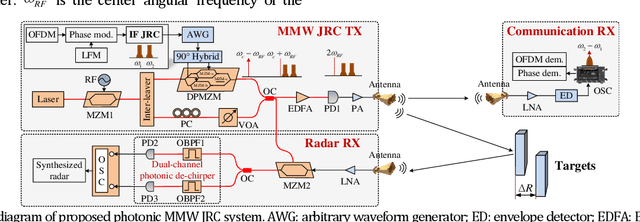
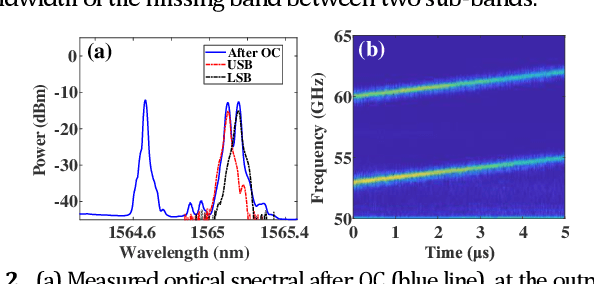
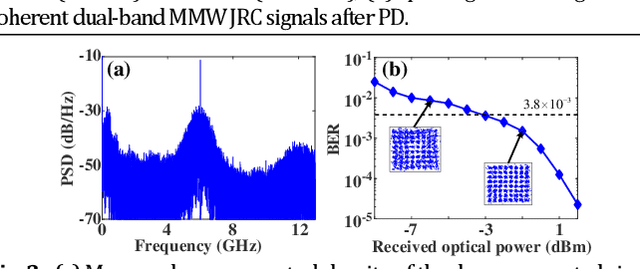
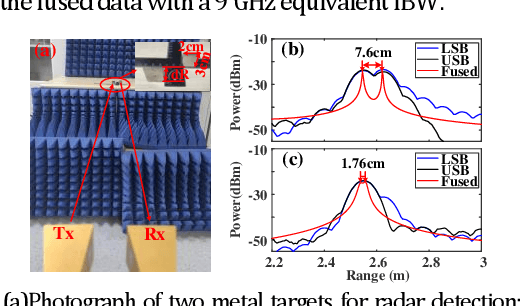
A cost-effective millimeter-wave (MMW) joint radar-communication (JRC) system with super resolution is proposed and experimentally demonstrated, using optical heterodyne up-conversion and self-coherent detection down-conversion techniques. The point lies in the designed coherent dual-band constant envelope linear frequency modulation-orthogonal frequency division multiplexing (LFM-OFDM) signal with opposite phase modulation indexes for the JRC system. Then the self-coherent detection, as a simple and low-cost means, is accordingly facilitated for both de-chirping of MMW radar and frequency down-conversion reception of MMW communication, which circumvents the costly high-speed mixers along with MMW local oscillators and more significantly achieves the real-time decomposition of radar and communication information. Furthermore, a super resolution radar range profile is realized through the coherent fusion processing of dual-band JRC signal. In experiments, a dual-band LFM-OFDM JRC signal centered at 54-GHz and 61-GHz is generated. The dual bands are featured with an identical instantaneous bandwidth of 2 GHz and carry an OFDM signal of 1 GBaud, which help to achieve a 6-Gbit/s data rate for communication and a 1.76-cm range resolution for radar.
Let Images Give You More:Point Cloud Cross-Modal Training for Shape Analysis
Oct 09, 2022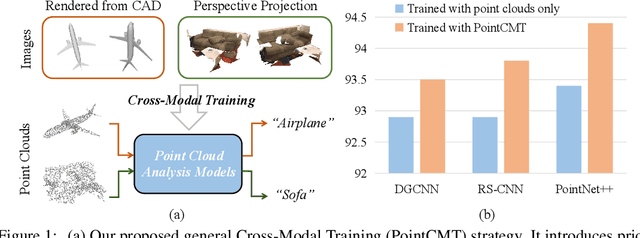
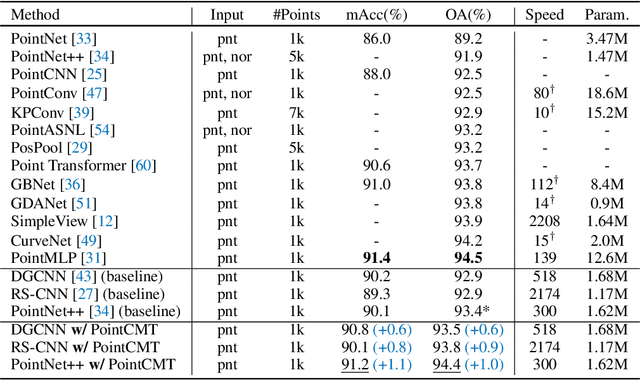
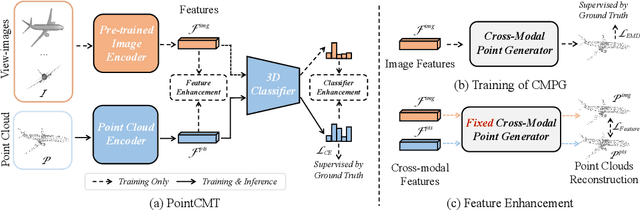
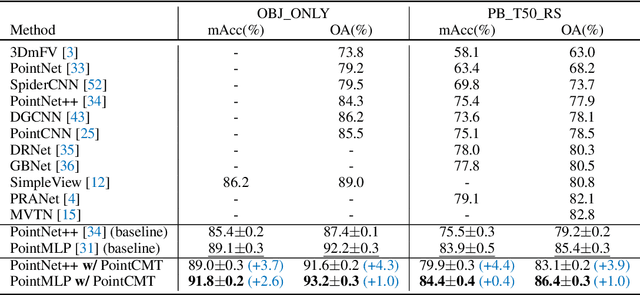
Although recent point cloud analysis achieves impressive progress, the paradigm of representation learning from a single modality gradually meets its bottleneck. In this work, we take a step towards more discriminative 3D point cloud representation by fully taking advantages of images which inherently contain richer appearance information, e.g., texture, color, and shade. Specifically, this paper introduces a simple but effective point cloud cross-modality training (PointCMT) strategy, which utilizes view-images, i.e., rendered or projected 2D images of the 3D object, to boost point cloud analysis. In practice, to effectively acquire auxiliary knowledge from view images, we develop a teacher-student framework and formulate the cross modal learning as a knowledge distillation problem. PointCMT eliminates the distribution discrepancy between different modalities through novel feature and classifier enhancement criteria and avoids potential negative transfer effectively. Note that PointCMT effectively improves the point-only representation without architecture modification. Sufficient experiments verify significant gains on various datasets using appealing backbones, i.e., equipped with PointCMT, PointNet++ and PointMLP achieve state-of-the-art performance on two benchmarks, i.e., 94.4% and 86.7% accuracy on ModelNet40 and ScanObjectNN, respectively. Code will be made available at https://github.com/ZhanHeshen/PointCMT.
KSAT: Knowledge-infused Self Attention Transformer -- Integrating Multiple Domain-Specific Contexts
Oct 09, 2022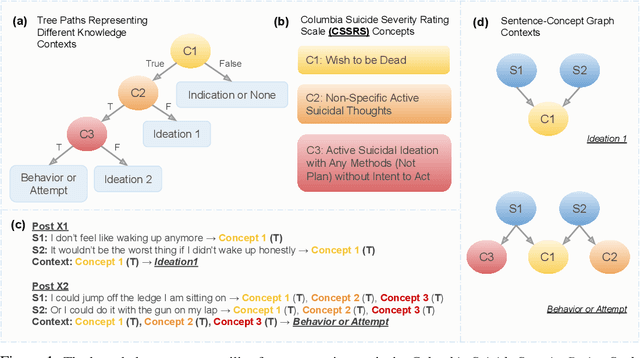

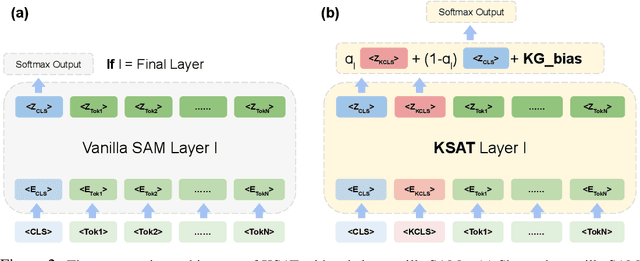
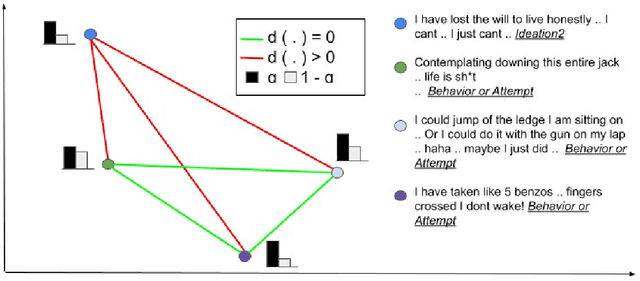
Domain-specific language understanding requires integrating multiple pieces of relevant contextual information. For example, we see both suicide and depression-related behavior (multiple contexts) in the text ``I have a gun and feel pretty bad about my life, and it wouldn't be the worst thing if I didn't wake up tomorrow''. Domain specificity in self-attention architectures is handled by fine-tuning on excerpts from relevant domain specific resources (datasets and external knowledge - medical textbook chapters on mental health diagnosis related to suicide and depression). We propose a modified self-attention architecture Knowledge-infused Self Attention Transformer (KSAT) that achieves the integration of multiple domain-specific contexts through the use of external knowledge sources. KSAT introduces knowledge-guided biases in dedicated self-attention layers for each knowledge source to accomplish this. In addition, KSAT provides mechanics for controlling the trade-off between learning from data and learning from knowledge. Our quantitative and qualitative evaluations show that (1) the KSAT architecture provides novel human-understandable ways to precisely measure and visualize the contributions of the infused domain contexts, and (2) KSAT performs competitively with other knowledge-infused baselines and significantly outperforms baselines that use fine-tuning for domain-specific tasks.
STAR: Zero-Shot Chinese Character Recognition with Stroke- and Radical-Level Decompositions
Oct 16, 2022
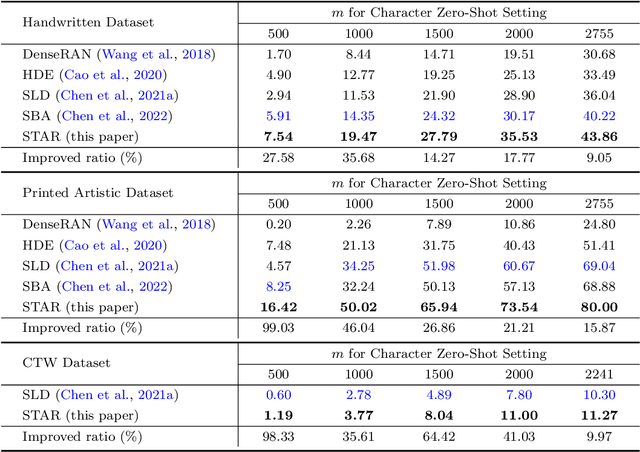
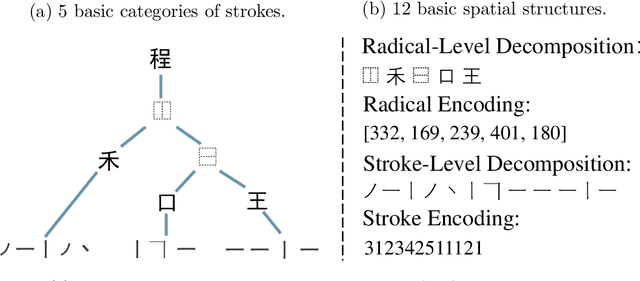
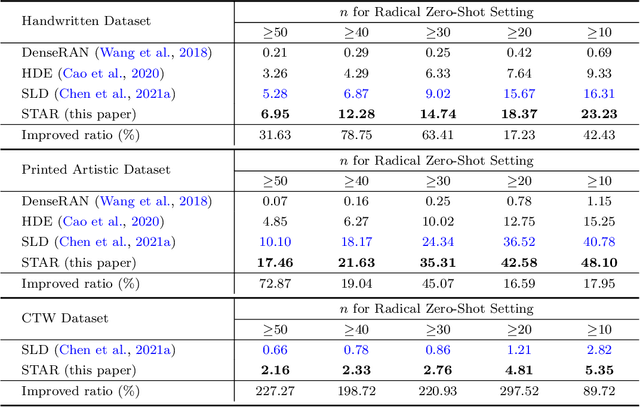
Zero-shot Chinese character recognition has attracted rising attention in recent years. Existing methods for this problem are mainly based on either certain low-level stroke-based decomposition or medium-level radical-based decomposition. Considering that the stroke- and radical-level decompositions can provide different levels of information, we propose an effective zero-shot Chinese character recognition method by combining them. The proposed method consists of a training stage and an inference stage. In the training stage, we adopt two similar encoder-decoder models to yield the estimates of stroke and radical encodings, which together with the true encodings are then used to formalize the associated stroke and radical losses for training. A similarity loss is introduced to regularize stroke and radical encoders to yield features of the same characters with high correlation. In the inference stage, two key modules, i.e., the stroke screening module (SSM) and feature matching module (FMM) are introduced to tackle the deterministic and confusing cases respectively. In particular, we introduce an effective stroke rectification scheme in FMM to enlarge the candidate set of characters for final inference. Numerous experiments over three benchmark datasets covering the handwritten, printed artistic and street view scenarios are conducted to demonstrate the effectiveness of the proposed method. Numerical results show that the proposed method outperforms the state-of-the-art methods in both character and radical zero-shot settings, and maintains competitive performance in the traditional seen character setting.
InTEn-LOAM: Intensity and Temporal Enhanced LiDAR Odometry and Mapping
Sep 13, 2022
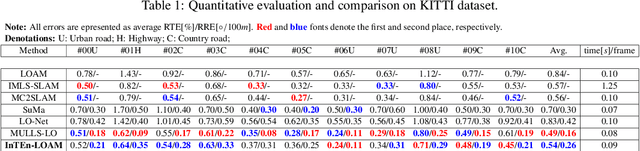
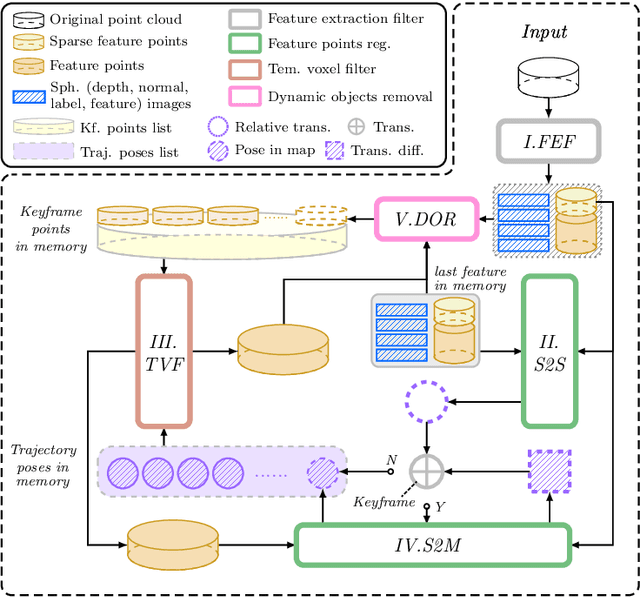
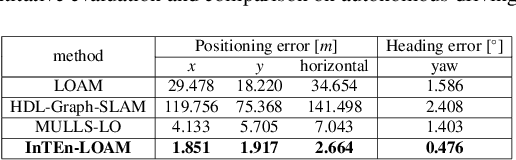
Traditional LiDAR odometry (LO) systems mainly leverage geometric information obtained from the traversed surroundings to register laser scans and estimate LiDAR ego-motion, while it may be unreliable in dynamic or unstructured environments. This paper proposes InTEn-LOAM, a low-drift and robust LiDAR odometry and mapping method that fully exploits implicit information of laser sweeps (i.e., geometric, intensity, and temporal characteristics). Scanned points are projected to cylindrical images, which facilitate the efficient and adaptive extraction of various types of features, i.e., ground, beam, facade, and reflector. We propose a novel intensity-based points registration algorithm and incorporate it into the LiDAR odometry, enabling the LO system to jointly estimate the LiDAR ego-motion using both geometric and intensity feature points. To eliminate the interference of dynamic objects, we propose a temporal-based dynamic object removal approach to filter them out before map update. Moreover, the local map is organized and downsampled using a temporal-related voxel grid filter to maintain the similarity between the current scan and the static local map. Extensive experiments are conducted on both simulated and real-world datasets. The results show that the proposed method achieves similar or better accuracy w.r.t the state-of-the-arts in normal driving scenarios and outperforms geometric-based LO in unstructured environments.
Probing Cross-modal Semantics Alignment Capability from the Textual Perspective
Oct 18, 2022

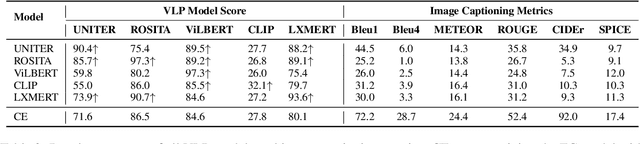
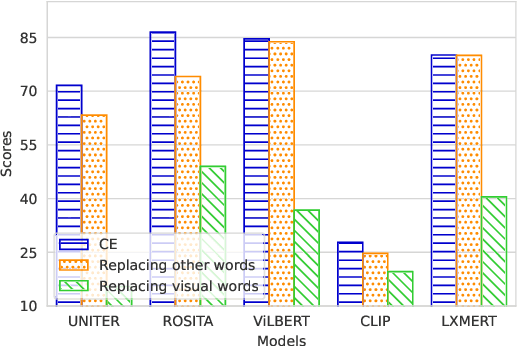
In recent years, vision and language pre-training (VLP) models have advanced the state-of-the-art results in a variety of cross-modal downstream tasks. Aligning cross-modal semantics is claimed to be one of the essential capabilities of VLP models. However, it still remains unclear about the inner working mechanism of alignment in VLP models. In this paper, we propose a new probing method that is based on image captioning to first empirically study the cross-modal semantics alignment of VLP models. Our probing method is built upon the fact that given an image-caption pair, the VLP models will give a score, indicating how well two modalities are aligned; maximizing such scores will generate sentences that VLP models believe are of good alignment. Analyzing these sentences thus will reveal in what way different modalities are aligned and how well these alignments are in VLP models. We apply our probing method to five popular VLP models, including UNITER, ROSITA, ViLBERT, CLIP, and LXMERT, and provide a comprehensive analysis of the generated captions guided by these models. Our results show that VLP models (1) focus more on just aligning objects with visual words, while neglecting global semantics; (2) prefer fixed sentence patterns, thus ignoring more important textual information including fluency and grammar; and (3) deem the captions with more visual words are better aligned with images. These findings indicate that VLP models still have weaknesses in cross-modal semantics alignment and we hope this work will draw researchers' attention to such problems when designing a new VLP model.