 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Time-Space Transformers for Video Panoptic Segmentation
Oct 07, 2022
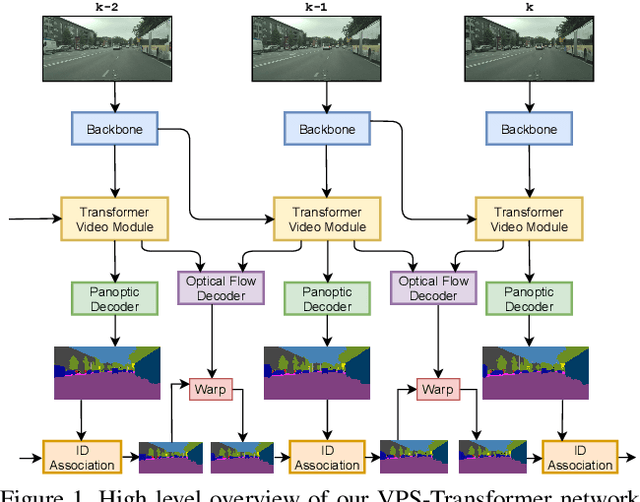
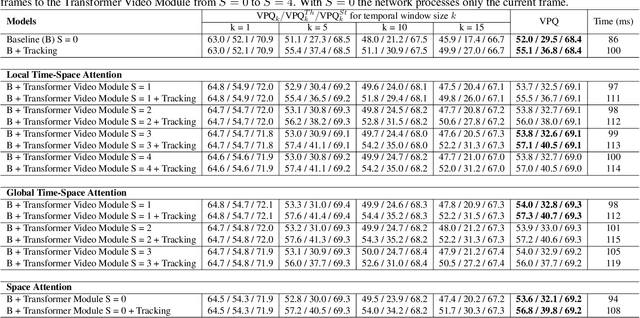
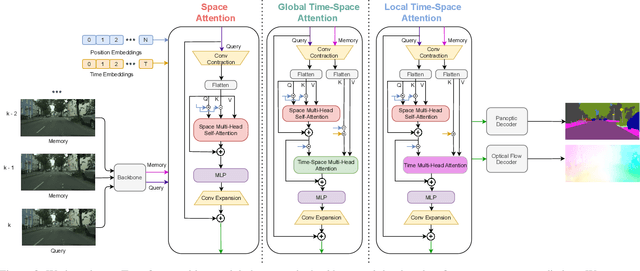
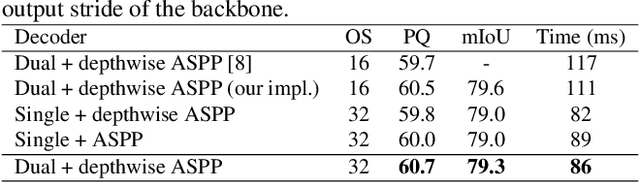
We propose a novel solution for the task of video panoptic segmentation, that simultaneously predicts pixel-level semantic and instance segmentation and generates clip-level instance tracks. Our network, named VPS-Transformer, with a hybrid architecture based on the state-of-the-art panoptic segmentation network Panoptic-DeepLab, combines a convolutional architecture for single-frame panoptic segmentation and a novel video module based on an instantiation of the pure Transformer block. The Transformer, equipped with attention mechanisms, models spatio-temporal relations between backbone output features of current and past frames for more accurate and consistent panoptic estimates. As the pure Transformer block introduces large computation overhead when processing high resolution images, we propose a few design changes for a more efficient compute. We study how to aggregate information more effectively over the space-time volume and we compare several variants of the Transformer block with different attention schemes. Extensive experiments on the Cityscapes-VPS dataset demonstrate that our best model improves the temporal consistency and video panoptic quality by a margin of 2.2%, with little extra computation.
Traffic-Aware Autonomous Driving with Differentiable Traffic Simulation
Oct 07, 2022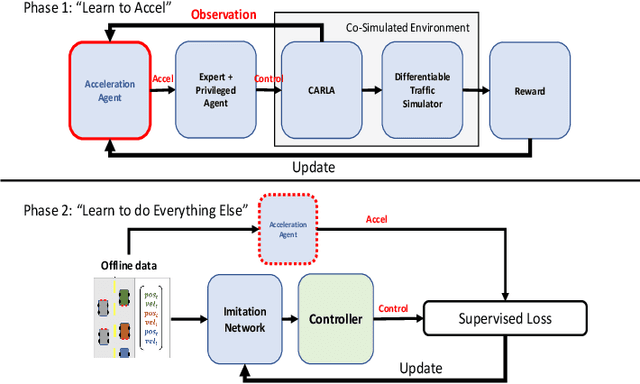
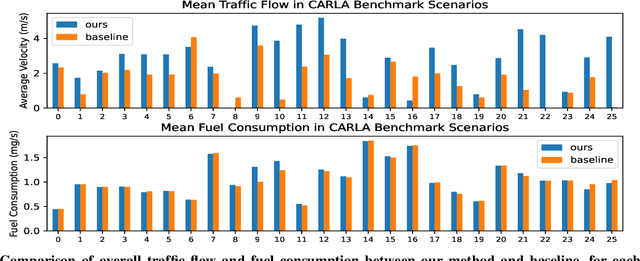
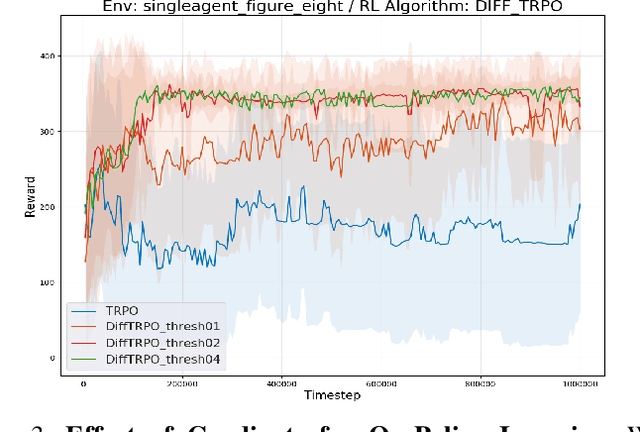
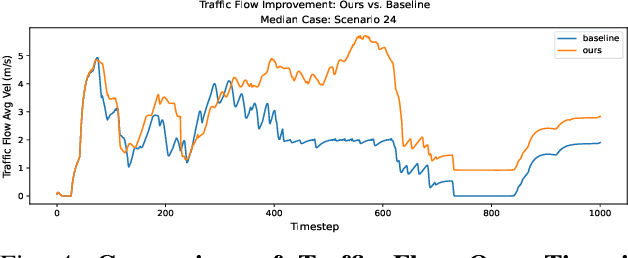
While there have been advancements in autonomous driving control and traffic simulation, there have been little to no works exploring the unification of both with deep learning. Works in both areas seem to focus on entirely different exclusive problems, yet traffic and driving have inherent semantic relations in the real world. In this paper, we present a generalizable distillation-style method for traffic-informed imitation learning that directly optimizes a autonomous driving policy for the overall benefit of faster traffic flow and lower energy consumption. We capitalize on improving the arbitrarily defined supervision of speed control in imitation learning systems, as most driving research focus on perception and steering. Moreover, our method addresses the lack of co-simulation between traffic and driving simulators and lays groundwork for directly involving traffic simulation with autonomous driving in future work. Our results show that, with information from traffic simulation involved in supervision of imitation learning methods, an autonomous vehicle can learn how to accelerate in a fashion that is beneficial for traffic flow and overall energy consumption for all nearby vehicles.
Dynamics-Aware Spatiotemporal Occupancy Prediction in Urban Environments
Sep 27, 2022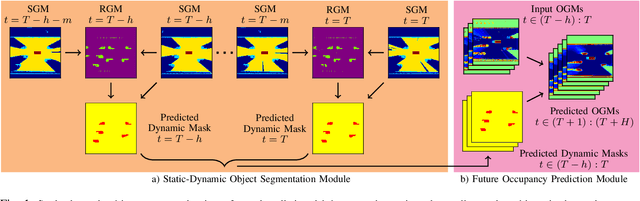

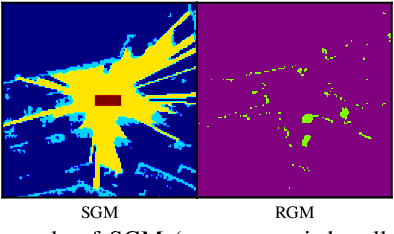
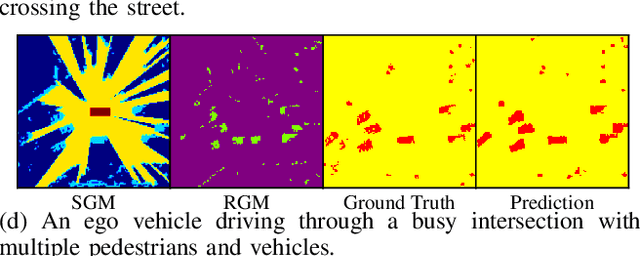
Detection and segmentation of moving obstacles, along with prediction of the future occupancy states of the local environment, are essential for autonomous vehicles to proactively make safe and informed decisions. In this paper, we propose a framework that integrates the two capabilities together using deep neural network architectures. Our method first detects and segments moving objects in the scene, and uses this information to predict the spatiotemporal evolution of the environment around autonomous vehicles. To address the problem of direct integration of both static-dynamic object segmentation and environment prediction models, we propose using occupancy-based environment representations across the whole framework. Our method is validated on the real-world Waymo Open Dataset and demonstrates higher prediction accuracy than baseline methods.
Entity-based Claim Representation Improves Fact-Checking of Medical Content in Tweets
Sep 16, 2022
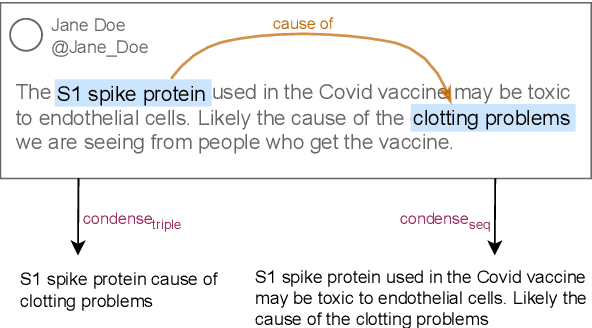
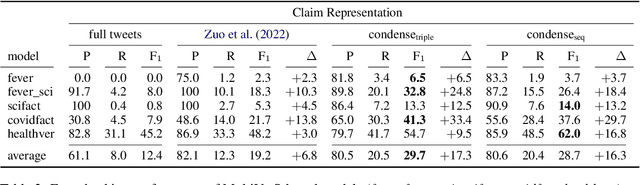
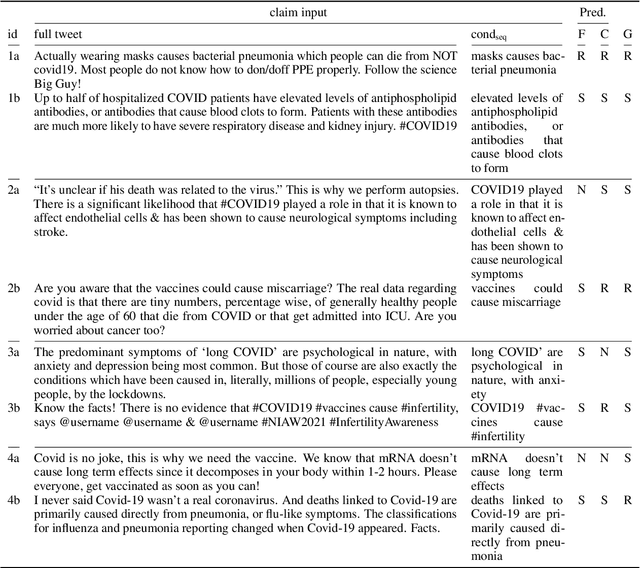
False medical information on social media poses harm to people's health. While the need for biomedical fact-checking has been recognized in recent years, user-generated medical content has received comparably little attention. At the same time, models for other text genres might not be reusable, because the claims they have been trained with are substantially different. For instance, claims in the SciFact dataset are short and focused: "Side effects associated with antidepressants increases risk of stroke". In contrast, social media holds naturally-occurring claims, often embedded in additional context: "`If you take antidepressants like SSRIs, you could be at risk of a condition called serotonin syndrome' Serotonin syndrome nearly killed me in 2010. Had symptoms of stroke and seizure." This showcases the mismatch between real-world medical claims and the input that existing fact-checking systems expect. To make user-generated content checkable by existing models, we propose to reformulate the social-media input in such a way that the resulting claim mimics the claim characteristics in established datasets. To accomplish this, our method condenses the claim with the help of relational entity information and either compiles the claim out of an entity-relation-entity triple or extracts the shortest phrase that contains these elements. We show that the reformulated input improves the performance of various fact-checking models as opposed to checking the tweet text in its entirety.
Distilling Style from Image Pairs for Global Forward and Inverse Tone Mapping
Oct 04, 2022
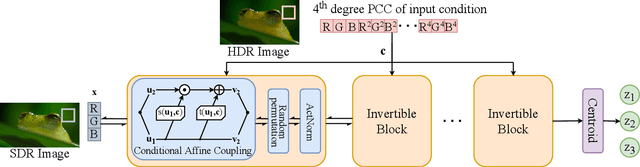


Many image enhancement or editing operations, such as forward and inverse tone mapping or color grading, do not have a unique solution, but instead a range of solutions, each representing a different style. Despite this, existing learning-based methods attempt to learn a unique mapping, disregarding this style. In this work, we show that information about the style can be distilled from collections of image pairs and encoded into a 2- or 3-dimensional vector. This gives us not only an efficient representation but also an interpretable latent space for editing the image style. We represent the global color mapping between a pair of images as a custom normalizing flow, conditioned on a polynomial basis of the pixel color. We show that such a network is more effective than PCA or VAE at encoding image style in low-dimensional space and lets us obtain an accuracy close to 40 dB, which is about 7-10 dB improvement over the state-of-the-art methods.
SecureFedYJ: a safe feature Gaussianization protocol for Federated Learning
Oct 04, 2022

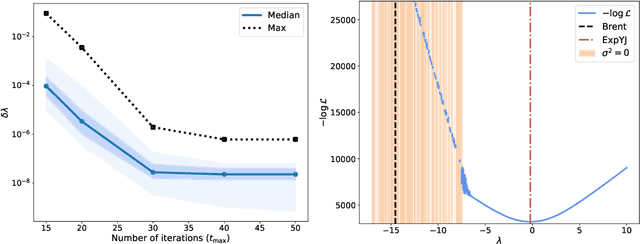
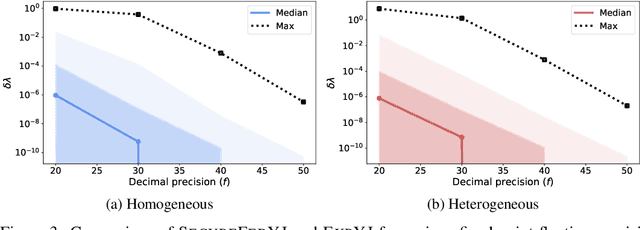
The Yeo-Johnson (YJ) transformation is a standard parametrized per-feature unidimensional transformation often used to Gaussianize features in machine learning. In this paper, we investigate the problem of applying the YJ transformation in a cross-silo Federated Learning setting under privacy constraints. For the first time, we prove that the YJ negative log-likelihood is in fact convex, which allows us to optimize it with exponential search. We numerically show that the resulting algorithm is more stable than the state-of-the-art approach based on the Brent minimization method. Building on this simple algorithm and Secure Multiparty Computation routines, we propose SecureFedYJ, a federated algorithm that performs a pooled-equivalent YJ transformation without leaking more information than the final fitted parameters do. Quantitative experiments on real data demonstrate that, in addition to being secure, our approach reliably normalizes features across silos as well as if data were pooled, making it a viable approach for safe federated feature Gaussianization.
Hyperbolic Deep Reinforcement Learning
Oct 04, 2022
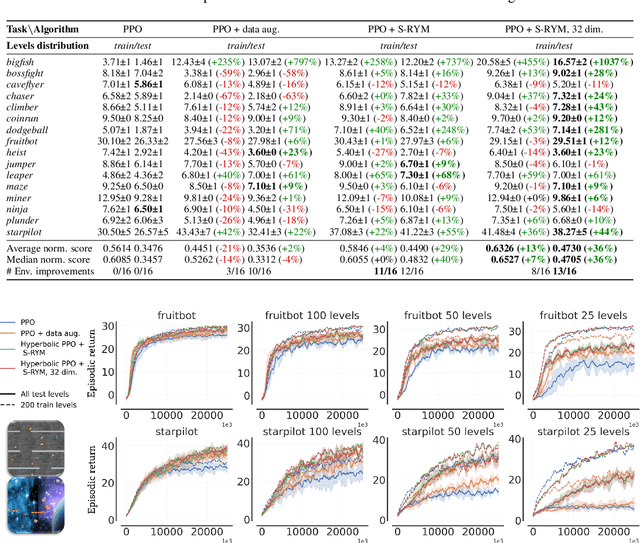
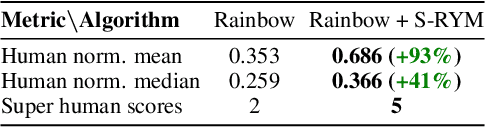
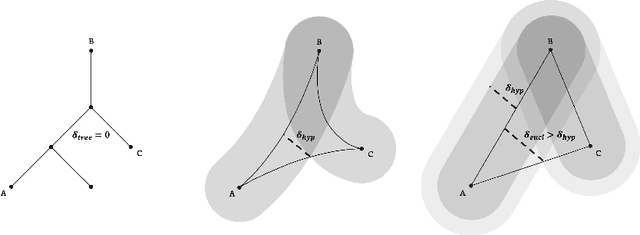
We propose a new class of deep reinforcement learning (RL) algorithms that model latent representations in hyperbolic space. Sequential decision-making requires reasoning about the possible future consequences of current behavior. Consequently, capturing the relationship between key evolving features for a given task is conducive to recovering effective policies. To this end, hyperbolic geometry provides deep RL models with a natural basis to precisely encode this inherently hierarchical information. However, applying existing methodologies from the hyperbolic deep learning literature leads to fatal optimization instabilities due to the non-stationarity and variance characterizing RL gradient estimators. Hence, we design a new general method that counteracts such optimization challenges and enables stable end-to-end learning with deep hyperbolic representations. We empirically validate our framework by applying it to popular on-policy and off-policy RL algorithms on the Procgen and Atari 100K benchmarks, attaining near universal performance and generalization benefits. Given its natural fit, we hope future RL research will consider hyperbolic representations as a standard tool.
Geometry Aligned Variational Transformer for Image-conditioned Layout Generation
Sep 02, 2022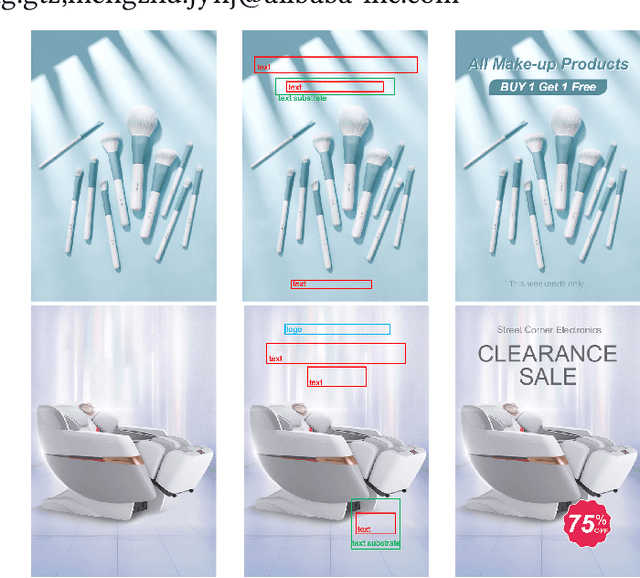
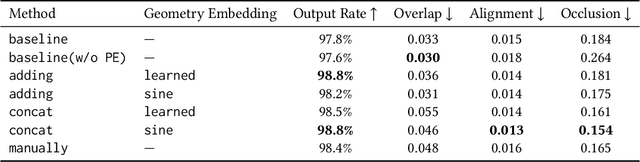
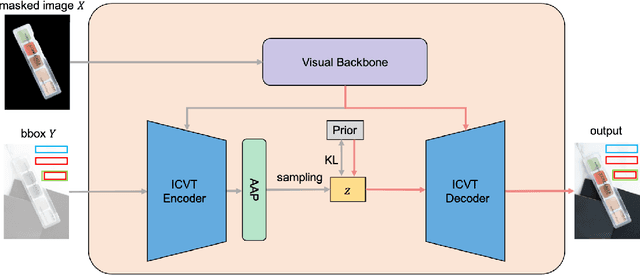

Layout generation is a novel task in computer vision, which combines the challenges in both object localization and aesthetic appraisal, widely used in advertisements, posters, and slides design. An accurate and pleasant layout should consider both the intra-domain relationship within layout elements and the inter-domain relationship between layout elements and the image. However, most previous methods simply focus on image-content-agnostic layout generation, without leveraging the complex visual information from the image. To this end, we explore a novel paradigm entitled image-conditioned layout generation, which aims to add text overlays to an image in a semantically coherent manner. Specifically, we propose an Image-Conditioned Variational Transformer (ICVT) that autoregressively generates various layouts in an image. First, self-attention mechanism is adopted to model the contextual relationship within layout elements, while cross-attention mechanism is used to fuse the visual information of conditional images. Subsequently, we take them as building blocks of conditional variational autoencoder (CVAE), which demonstrates appealing diversity. Second, in order to alleviate the gap between layout elements domain and visual domain, we design a Geometry Alignment module, in which the geometric information of the image is aligned with the layout representation. In addition, we construct a large-scale advertisement poster layout designing dataset with delicate layout and saliency map annotations. Experimental results show that our model can adaptively generate layouts in the non-intrusive area of the image, resulting in a harmonious layout design.
Modeling Multiple Views via Implicitly Preserving Global Consistency and Local Complementarity
Sep 16, 2022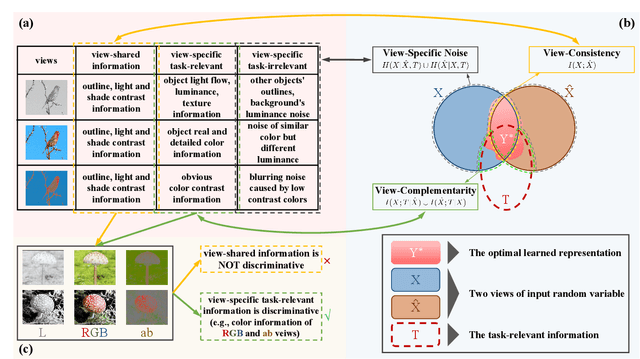
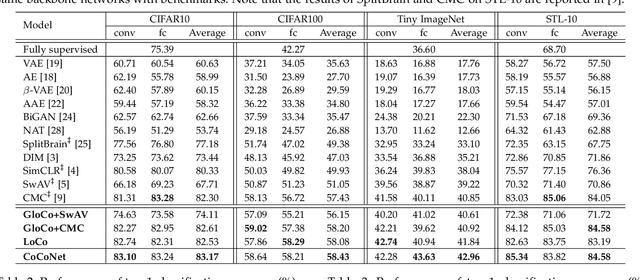
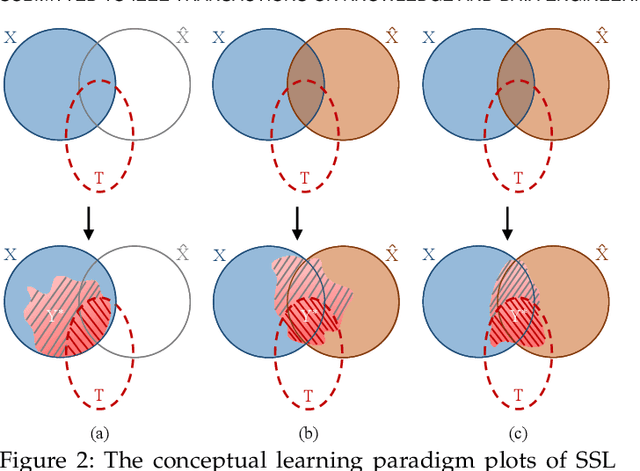
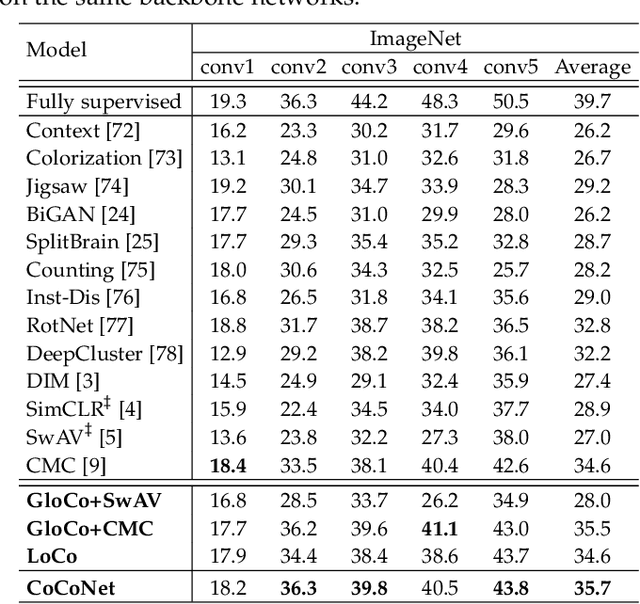
While self-supervised learning techniques are often used to mining implicit knowledge from unlabeled data via modeling multiple views, it is unclear how to perform effective representation learning in a complex and inconsistent context. To this end, we propose a methodology, specifically consistency and complementarity network (CoCoNet), which avails of strict global inter-view consistency and local cross-view complementarity preserving regularization to comprehensively learn representations from multiple views. On the global stage, we reckon that the crucial knowledge is implicitly shared among views, and enhancing the encoder to capture such knowledge from data can improve the discriminability of the learned representations. Hence, preserving the global consistency of multiple views ensures the acquisition of common knowledge. CoCoNet aligns the probabilistic distribution of views by utilizing an efficient discrepancy metric measurement based on the generalized sliced Wasserstein distance. Lastly on the local stage, we propose a heuristic complementarity-factor, which joints cross-view discriminative knowledge, and it guides the encoders to learn not only view-wise discriminability but also cross-view complementary information. Theoretically, we provide the information-theoretical-based analyses of our proposed CoCoNet. Empirically, to investigate the improvement gains of our approach, we conduct adequate experimental validations, which demonstrate that CoCoNet outperforms the state-of-the-art self-supervised methods by a significant margin proves that such implicit consistency and complementarity preserving regularization can enhance the discriminability of latent representations.
Hybrid Graph Models for Logic Optimization via Spatio-Temporal Information
Jan 20, 2022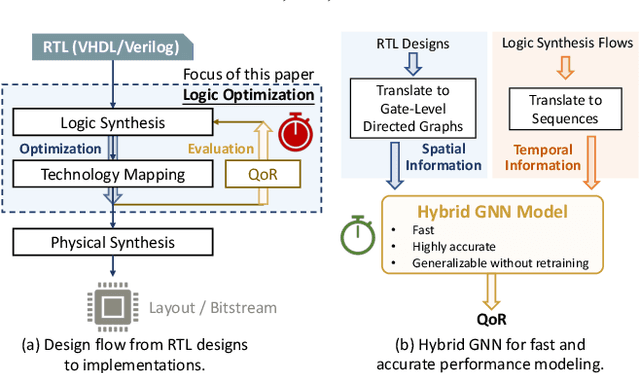



Despite the stride made by machine learning (ML) based performance modeling, two major concerns that may impede production-ready ML applications in EDA are stringent accuracy requirements and generalization capability. To this end, we propose hybrid graph neural network (GNN) based approaches towards highly accurate quality-of-result (QoR) estimations with great generalization capability, specifically targeting logic synthesis optimization. The key idea is to simultaneously leverage spatio-temporal information from hardware designs and logic synthesis flows to forecast performance (i.e., delay/area) of various synthesis flows on different designs. The structural characteristics inside hardware designs are distilled and represented by GNNs; the temporal knowledge (i.e., relative ordering of logic transformations) in synthesis flows can be imposed on hardware designs by combining a virtually added supernode or a sequence processing model with conventional GNN models. Evaluation on 3.3 million data points shows that the testing mean absolute percentage error (MAPE) on designs seen and unseen during training are no more than 1.2% and 3.1%, respectively, which are 7-15X lower than existing studies.