 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
An NLoS-based Enhanced Sensing Method for MmWave Communication System
Oct 10, 2022
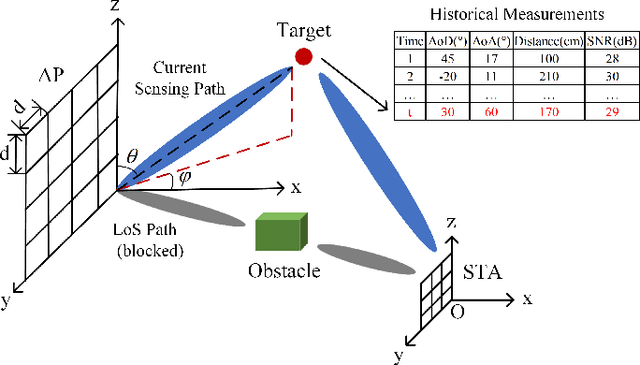
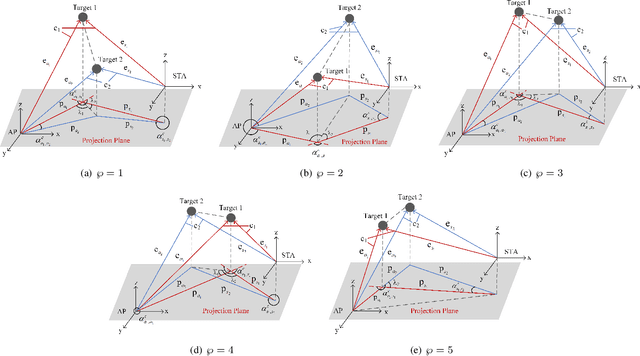
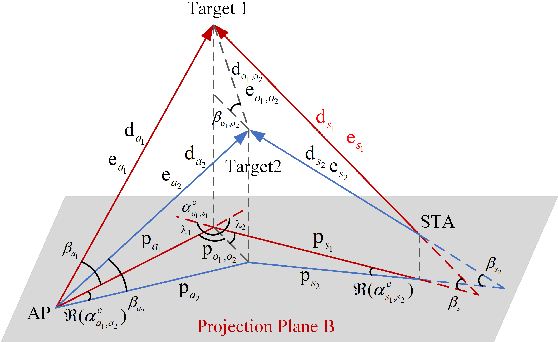
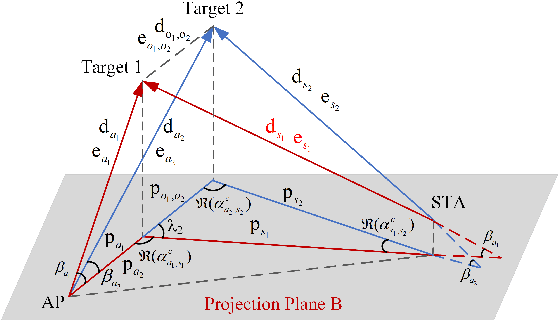
The millimeter-wave (mmWave)-based Wi-Fi sensing technology has recently attracted extensive attention since it provides a possibility to realize higher sensing accuracy. However, current works mainly concentrate on sensing scenarios where the line-of-sight (LoS) path exists, which significantly limits their applications. To address the problem, we propose an enhanced mmWave sensing algorithm in the 3D non-line-of-sight environment (mm3NLoS), aiming to sense the direction and distance of the target when the LoS path is weak or blocked. Specifically, we first adopt the directional beam to estimate the azimuth/elevation angle of arrival (AoA) and angle of departure (AoD) of the reflection path. Then, the distance of the related path is measured by the fine timing measurement protocol. Finally, we transform the AoA and AoD of the multiple non-line-of-sight (NLoS) paths into the direction vector and then obtain the information of targets based on the geometric relationship. The simulation results demonstrate that mm3NLoS can achieve a centimeter-level error with a 2m spacing. Compared to the prior work, it can significantly reduce the performance degradation under the NLoS condition.
Distill the Image to Nowhere: Inversion Knowledge Distillation for Multimodal Machine Translation
Oct 10, 2022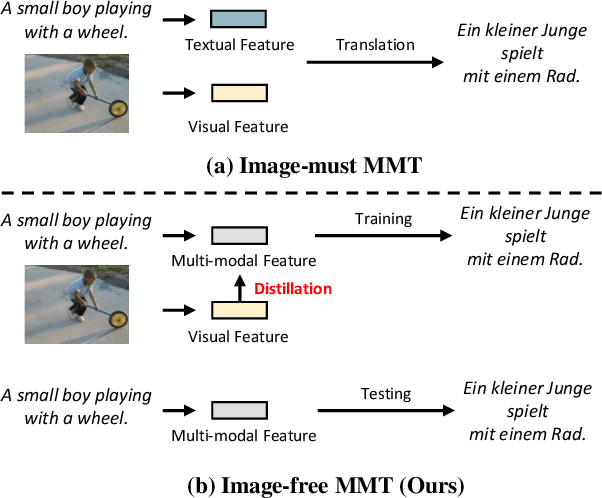
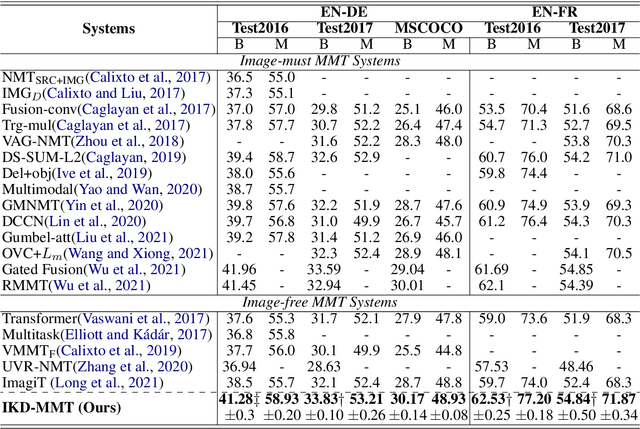
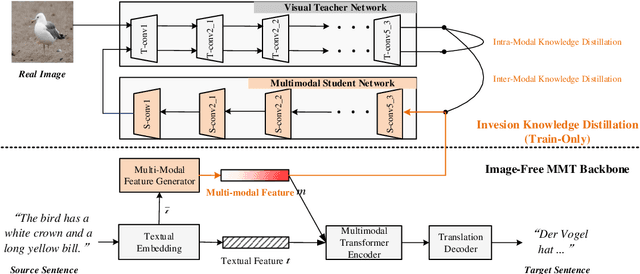
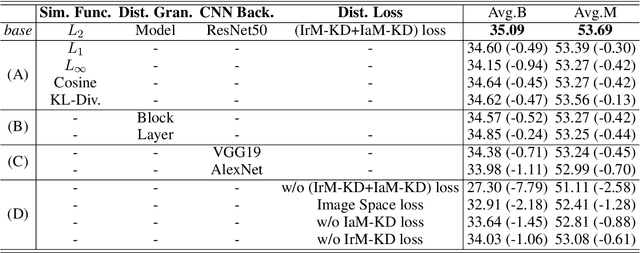
Past works on multimodal machine translation (MMT) elevate bilingual setup by incorporating additional aligned vision information. However, an image-must requirement of the multimodal dataset largely hinders MMT's development -- namely that it demands an aligned form of [image, source text, target text]. This limitation is generally troublesome during the inference phase especially when the aligned image is not provided as in the normal NMT setup. Thus, in this work, we introduce IKD-MMT, a novel MMT framework to support the image-free inference phase via an inversion knowledge distillation scheme. In particular, a multimodal feature generator is executed with a knowledge distillation module, which directly generates the multimodal feature from (only) source texts as the input. While there have been a few prior works entertaining the possibility to support image-free inference for machine translation, their performances have yet to rival the image-must translation. In our experiments, we identify our method as the first image-free approach to comprehensively rival or even surpass (almost) all image-must frameworks, and achieved the state-of-the-art result on the often-used Multi30k benchmark. Our code and data are available at: https://github.com/pengr/IKD-mmt/tree/master..
SUN: Exploring Intrinsic Uncertainties in Text-to-SQL Parsers
Sep 14, 2022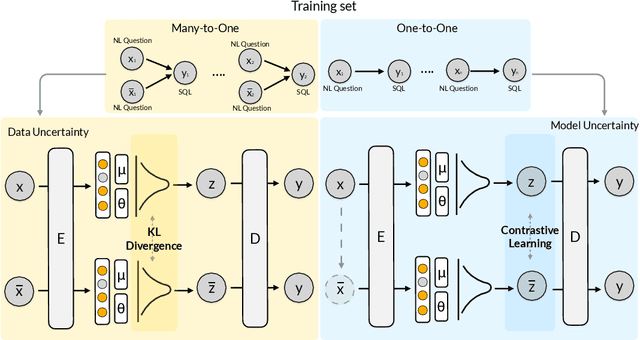
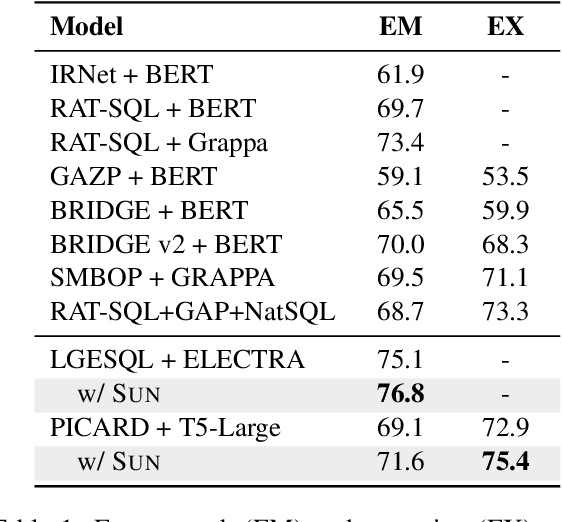
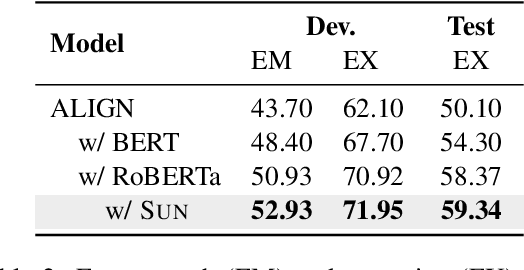
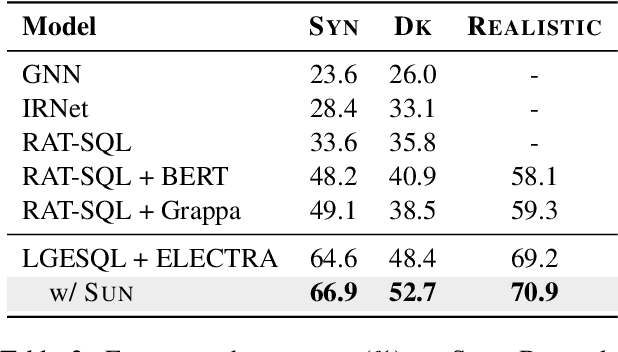
This paper aims to improve the performance of text-to-SQL parsing by exploring the intrinsic uncertainties in the neural network based approaches (called SUN). From the data uncertainty perspective, it is indisputable that a single SQL can be learned from multiple semantically-equivalent questions.Different from previous methods that are limited to one-to-one mapping, we propose a data uncertainty constraint to explore the underlying complementary semantic information among multiple semantically-equivalent questions (many-to-one) and learn the robust feature representations with reduced spurious associations. In this way, we can reduce the sensitivity of the learned representations and improve the robustness of the parser. From the model uncertainty perspective, there is often structural information (dependence) among the weights of neural networks. To improve the generalizability and stability of neural text-to-SQL parsers, we propose a model uncertainty constraint to refine the query representations by enforcing the output representations of different perturbed encoding networks to be consistent with each other. Extensive experiments on five benchmark datasets demonstrate that our method significantly outperforms strong competitors and achieves new state-of-the-art results. For reproducibility, we release our code and data at https://github.com/AlibabaResearch/DAMO-ConvAI/tree/main/sunsql.
Automated MeSH Term Suggestion for Effective Query Formulation in Systematic Reviews Literature Search
Sep 19, 2022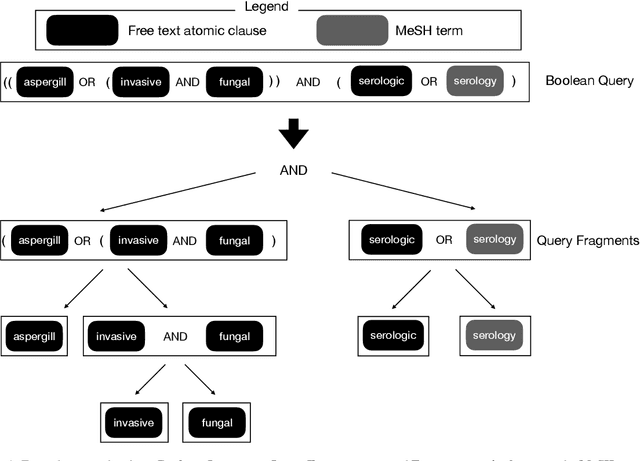

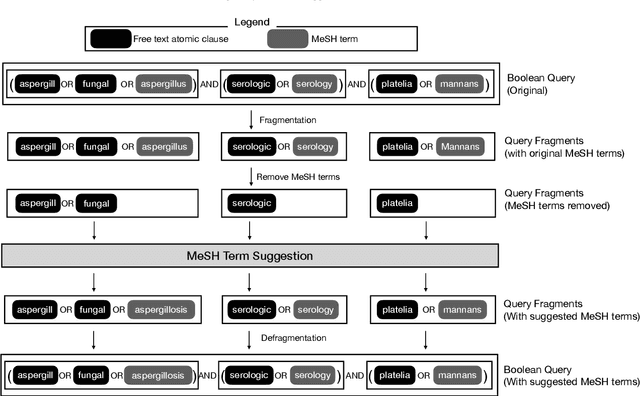
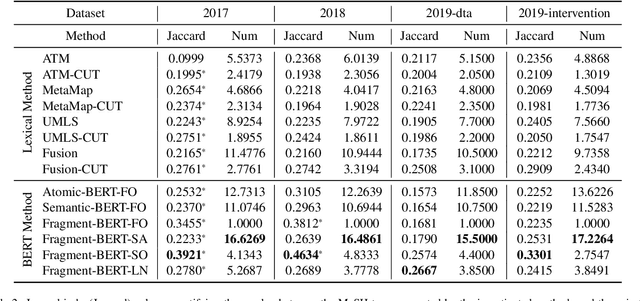
High-quality medical systematic reviews require comprehensive literature searches to ensure the recommendations and outcomes are sufficiently reliable. Indeed, searching for relevant medical literature is a key phase in constructing systematic reviews and often involves domain (medical researchers) and search (information specialists) experts in developing the search queries. Queries in this context are highly complex, based on Boolean logic, include free-text terms and index terms from standardised terminologies (e.g., the Medical Subject Headings (MeSH) thesaurus), and are difficult and time-consuming to build. The use of MeSH terms, in particular, has been shown to improve the quality of the search results. However, identifying the correct MeSH terms to include in a query is difficult: information experts are often unfamiliar with the MeSH database and unsure about the appropriateness of MeSH terms for a query. Naturally, the full value of the MeSH terminology is often not fully exploited. This article investigates methods to suggest MeSH terms based on an initial Boolean query that includes only free-text terms. In this context, we devise lexical and pre-trained language models based methods. These methods promise to automatically identify highly effective MeSH terms for inclusion in a systematic review query. Our study contributes an empirical evaluation of several MeSH term suggestion methods. We further contribute an extensive analysis of MeSH term suggestions for each method and how these suggestions impact the effectiveness of Boolean queries.
On the Average Mutual Information of MIMO Keyhole Channels with Finite Inputs
Dec 08, 2021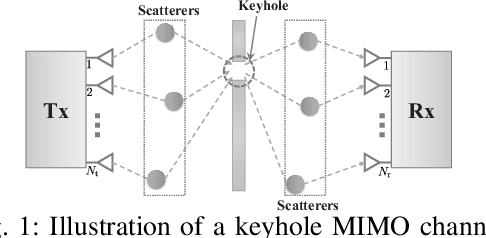
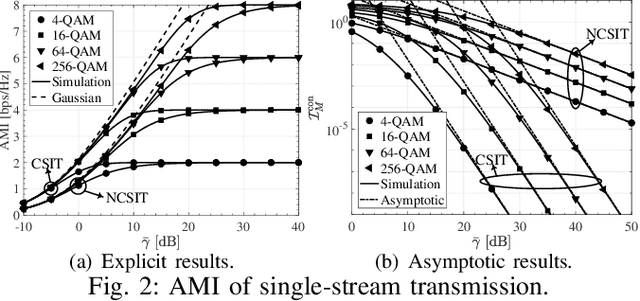
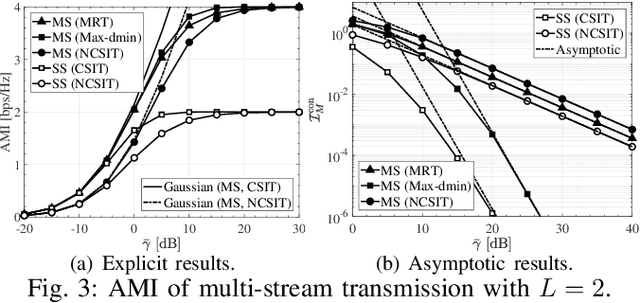
This letter studies the average mutual information (AMI) of keyhole multiple-input multiple-output (MIMO) systems having finite input signals. At first, the AMI of single-stream transmission is investigated under two cases where the state information at the transmitter (CSIT) is available or not. Then, the derived results are further extended to the case of multi-stream transmission. For the sake of providing more system insights, asymptotic analyses are performed in the regime of high signal-to-noise ratio (SNR), which suggests that the high-SNR AMI converges to some constant with its rate of convergence determined by the diversity order. All the results are validated by numerical simulations and are in excellent agreement.
Handling big tabular data of ICT supply chains: a multi-task, machine-interpretable approach
Aug 11, 2022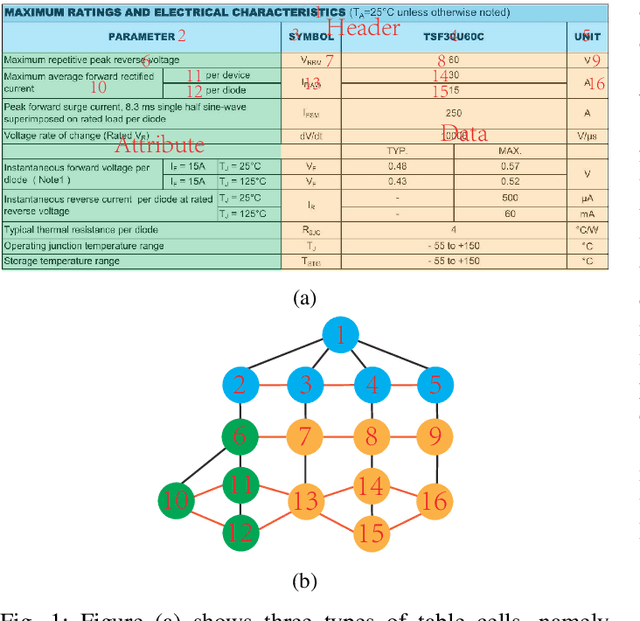
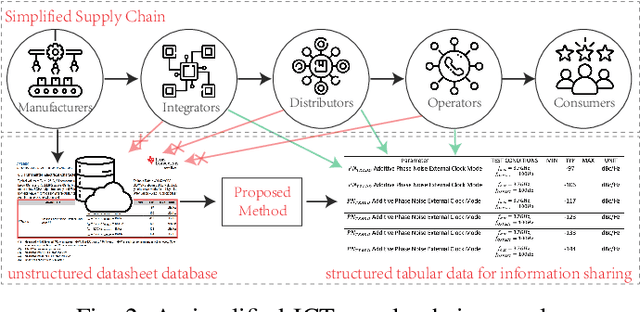
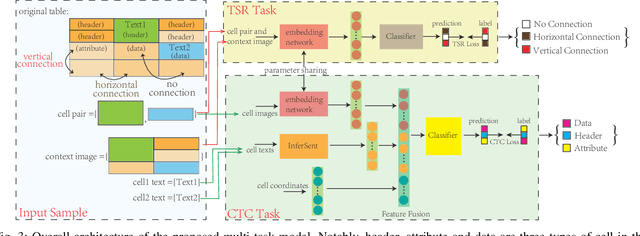
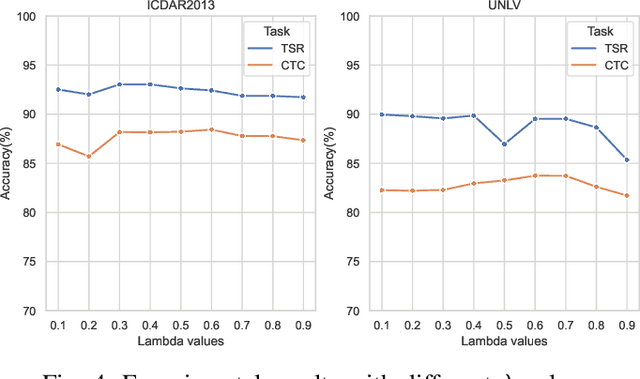
Due to the characteristics of Information and Communications Technology (ICT) products, the critical information of ICT devices is often summarized in big tabular data shared across supply chains. Therefore, it is critical to automatically interpret tabular structures with the surging amount of electronic assets. To transform the tabular data in electronic documents into a machine-interpretable format and provide layout and semantic information for information extraction and interpretation, we define a Table Structure Recognition (TSR) task and a Table Cell Type Classification (CTC) task. We use a graph to represent complex table structures for the TSR task. Meanwhile, table cells are categorized into three groups based on their functional roles for the CTC task, namely Header, Attribute, and Data. Subsequently, we propose a multi-task model to solve the defined two tasks simultaneously by using the text modal and image modal features. Our experimental results show that our proposed method can outperform state-of-the-art methods on ICDAR2013 and UNLV datasets.
Iterative Optimization of Pseudo Ground-Truth Face Image Quality Labels
Aug 31, 2022While recent face recognition (FR) systems achieve excellent results in many deployment scenarios, their performance in challenging real-world settings is still under question. For this reason, face image quality assessment (FIQA) techniques aim to support FR systems, by providing them with sample quality information that can be used to reject poor quality data unsuitable for recognition purposes. Several groups of FIQA methods relying on different concepts have been proposed in the literature, all of which can be used for generating quality scores of facial images that can serve as pseudo ground-truth (quality) labels and can be exploited for training (regression-based) quality estimation models. Several FIQA appro\-aches show that a significant amount of sample-quality information can be extracted from mated similarity-score distributions generated with some face matcher. Based on this insight, we propose in this paper a quality label optimization approach, which incorporates sample-quality information from mated-pair similarities into quality predictions of existing off-the-shelf FIQA techniques. We evaluate the proposed approach using three state-of-the-art FIQA methods over three diverse datasets. The results of our experiments show that the proposed optimization procedure heavily depends on the number of executed optimization iterations. At ten iterations, the approach seems to perform the best, consistently outperforming the base quality scores of the three FIQA methods, chosen for the experiments.
Multimodal Analogical Reasoning over Knowledge Graphs
Oct 01, 2022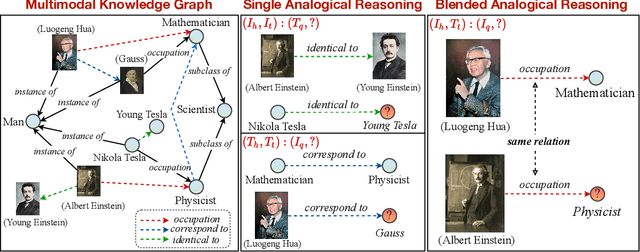

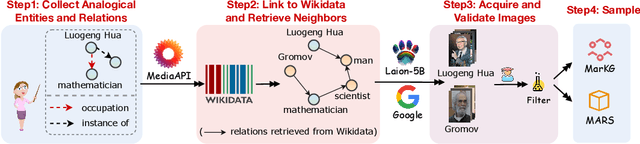
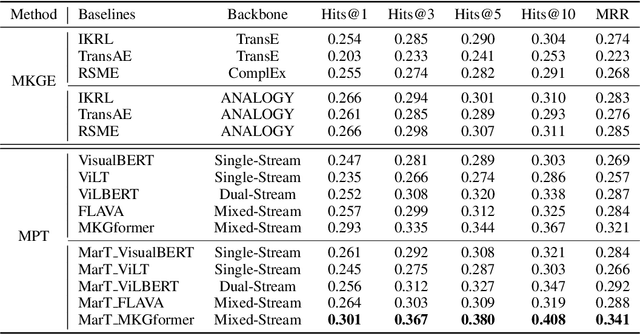
Analogical reasoning is fundamental to human cognition and holds an important place in various fields. However, previous studies mainly focus on single-modal analogical reasoning and ignore taking advantage of structure knowledge. Notably, the research in cognitive psychology has demonstrated that information from multimodal sources always brings more powerful cognitive transfer than single modality sources. To this end, we introduce the new task of multimodal analogical reasoning over knowledge graphs, which requires multimodal reasoning ability with the help of background knowledge. Specifically, we construct a Multimodal Analogical Reasoning dataSet (MARS) and a multimodal knowledge graph MarKG. We evaluate with multimodal knowledge graph embedding and pre-trained Transformer baselines, illustrating the potential challenges of the proposed task. We further propose a novel model-agnostic Multimodal analogical reasoning framework with Transformer (MarT) motivated by the structure mapping theory, which can obtain better performance.
An F-shape Click Model for Information Retrieval on Multi-block Mobile Pages
Jun 17, 2022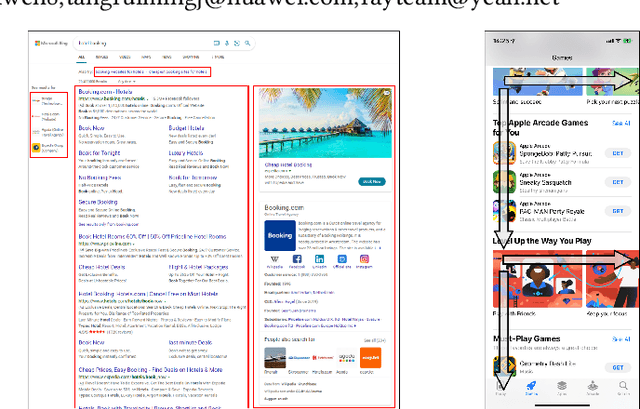


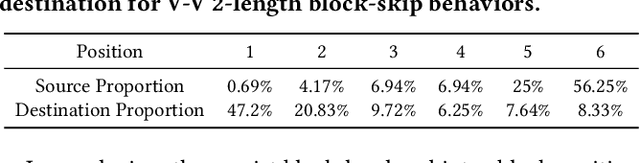
To provide click simulation or relevance estimation based on users' implicit interaction feedback, click models have been much studied during recent years. Most click models focus on user behaviors towards a single list. However, with the development of user interface (UI) design, the layout of displayed items on a result page tends to be multi-block (i.e., multi-list) style instead of a single list, which requires different assumptions to model user behaviors more accurately. There exist click models for multi-block pages in desktop contexts, but they cannot be directly applied to mobile scenarios due to different interaction manners, result types and especially multi-block presentation styles. In particular, multi-block mobile pages can normally be decomposed into interleavings of basic vertical blocks and horizontal blocks, thus resulting in typically F-shape forms. To mitigate gaps between desktop and mobile contexts for multi-block pages, we conduct a user eye-tracking study, and identify users' sequential browsing, block skip and comparison patterns on F-shape pages. These findings lead to the design of a novel F-shape Click Model (FSCM), which serves as a general solution to multi-block mobile pages. Firstly, we construct a directed acyclic graph (DAG) for each page, where each item is regarded as a vertex and each edge indicates the user's possible examination flow. Secondly, we propose DAG-structured GRUs and a comparison module to model users' sequential (sequential browsing, block skip) and non-sequential (comparison) behaviors respectively. Finally, we combine GRU states and comparison patterns to perform user click predictions. Experiments on a large-scale real-world dataset validate the effectiveness of FSCM on user behavior predictions compared with baseline models.
Hyperspectral Image Reconstruction from Multispectral Images Using Non-Local Filtering
Sep 16, 2022


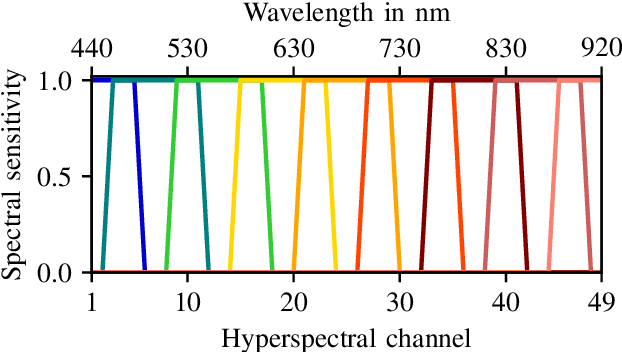
Using light spectra is an essential element in many applications, for example, in material classification. Often this information is acquired by using a hyperspectral camera. Unfortunately, these cameras have some major disadvantages like not being able to record videos. Therefore, multispectral cameras with wide-band filters are used, which are much cheaper and are often able to capture videos. However, using multispectral cameras requires an additional reconstruction step to yield spectral information. Usually, this reconstruction step has to be done in the presence of imaging noise, which degrades the reconstructed spectra severely. Typically, same or similar pixels are found across the image with the advantage of having independent noise. In contrast to state-of-the-art spectral reconstruction methods which only exploit neighboring pixels by block-based processing, this paper introduces non-local filtering in spectral reconstruction. First, a block-matching procedure finds similar non-local multispectral blocks. Thereafter, the hyperspectral pixels are reconstructed by filtering the matched multispectral pixels collaboratively using a reconstruction Wiener filter. The proposed novel procedure even works under very strong noise. The method is able to lower the spectral angle up to 18% and increase the peak signal-to-noise-ratio up to 1.1dB in noisy scenarios compared to state-of-the-art methods. Moreover, the visual results are much more appealing.