 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DMTNet: Dynamic Multi-scale Network for Dual-pixel Images Defocus Deblurring with Transformer
Sep 13, 2022

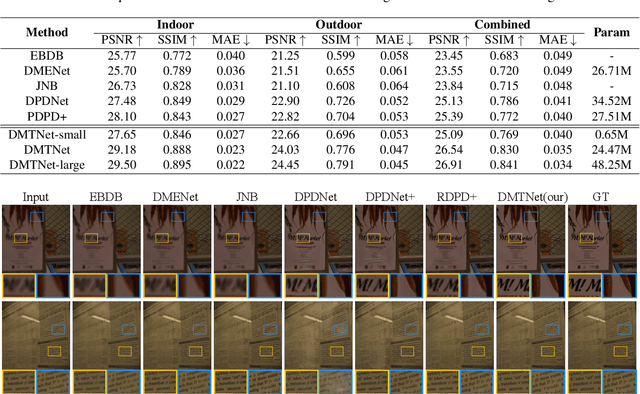
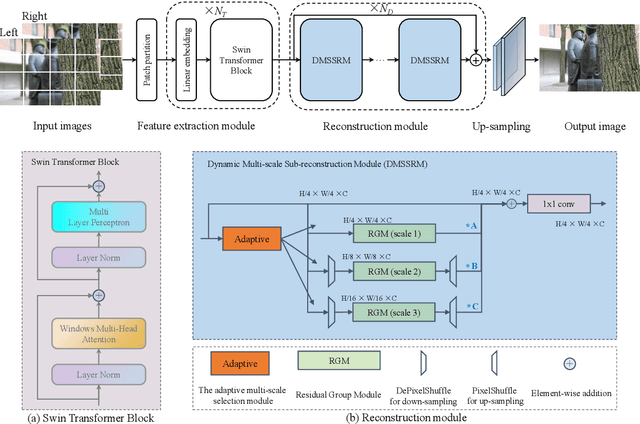
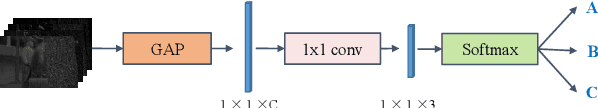
Recent works achieve excellent results in defocus deblurring task based on dual-pixel data using convolutional neural network (CNN), while the scarcity of data limits the exploration and attempt of vision transformer in this task. In addition, the existing works use fixed parameters and network architecture to deblur images with different distribution and content information, which also affects the generalization ability of the model. In this paper, we propose a dynamic multi-scale network, named DMTNet, for dual-pixel images defocus deblurring. DMTNet mainly contains two modules: feature extraction module and reconstruction module. The feature extraction module is composed of several vision transformer blocks, which uses its powerful feature extraction capability to obtain richer features and improve the robustness of the model. The reconstruction module is composed of several Dynamic Multi-scale Sub-reconstruction Module (DMSSRM). DMSSRM can restore images by adaptively assigning weights to features from different scales according to the blur distribution and content information of the input images. DMTNet combines the advantages of transformer and CNN, in which the vision transformer improves the performance ceiling of CNN, and the inductive bias of CNN enables transformer to extract more robust features without relying on a large amount of data. DMTNet might be the first attempt to use vision transformer to restore the blurring images to clarity. By combining with CNN, the vision transformer may achieve better performance on small datasets. Experimental results on the popular benchmarks demonstrate that our DMTNet significantly outperforms state-of-the-art methods.
SnowFormer: Scale-aware Transformer via Context Interaction for Single Image Desnowing
Aug 23, 2022
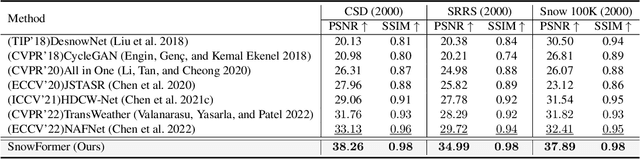
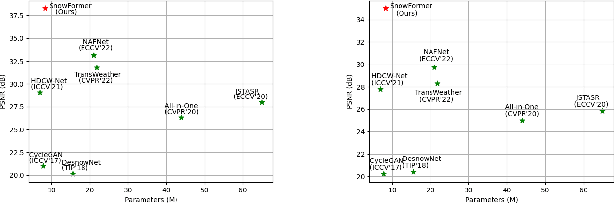
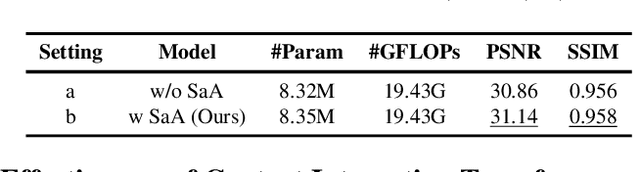
Single image desnowing is a common yet challenging task. The complex snow degradations and diverse degradation scales demand strong representation ability. In order for the desnowing network to see various snow degradations and model the context interaction of local details and global information, we propose a powerful architecture dubbed as SnowFormer. First, it performs Scale-aware Feature Aggregation in the encoder to capture rich snow information of various degradations. Second, in order to tackle with large-scale degradation, it uses a novel Context Interaction Transformer Block in the decoder, which conducts context interaction of local details and global information from previous scale-aware feature aggregation in global context interaction. And the introduction of local context interaction improves recovery of scene details. Third, we devise a Heterogeneous Feature Projection Head which progressively fuse features from both the encoder and decoder and project the refined feature into the clean image. Extensive experiments demonstrate that the proposed SnowFormer achieves significant improvements over other SOTA methods. Compared with SOTA single image desnowing method HDCW-Net, it boosts the PSNR metric by 9.2dB on the CSD testset. Moreover, it also achieves a 5.13dB increase in PSNR compared with general image restoration architecture NAFNet, which verifies the strong representation ability of our SnowFormer for snow removal task. The code is released in \url{https://github.com/Ephemeral182/SnowFormer}.
EiHi Net: Out-of-Distribution Generalization Paradigm
Sep 29, 2022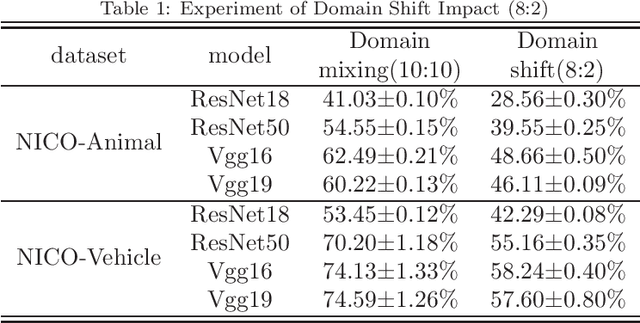



This paper develops a new EiHi net to solve the out-of-distribution (OoD) generalization problem in deep learning. EiHi net is a model learning paradigm that can be blessed on any visual backbone. This paradigm can change the previous learning method of the deep model, namely find out correlations between inductive sample features and corresponding categories, which suffers from pseudo correlations between indecisive features and labels. We fuse SimCLR and VIC-Reg via explicitly and dynamically establishing the original - positive - negative sample pair as a minimal learning element, the deep model iteratively establishes a relationship close to the causal one between features and labels, while suppressing pseudo correlations. To further validate the proposed model, and strengthen the established causal relationships, we develop a human-in-the-loop strategy, with few guidance samples, to prune the representation space directly. Finally, it is shown that the developed EiHi net makes significant improvements in the most difficult and typical OoD dataset Nico, compared with the current SOTA results, without any domain ($e.g.$ background, irrelevant features) information.
Just Noticeable Difference Modeling for Face Recognition System
Sep 13, 2022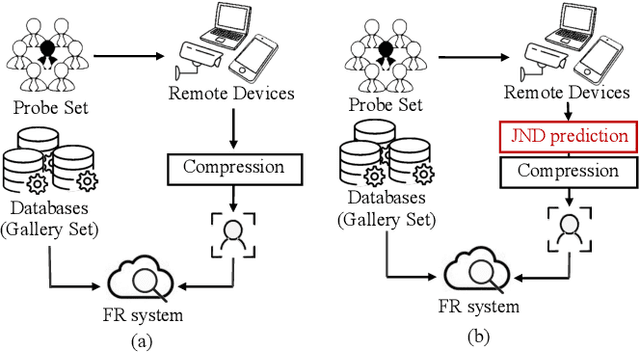
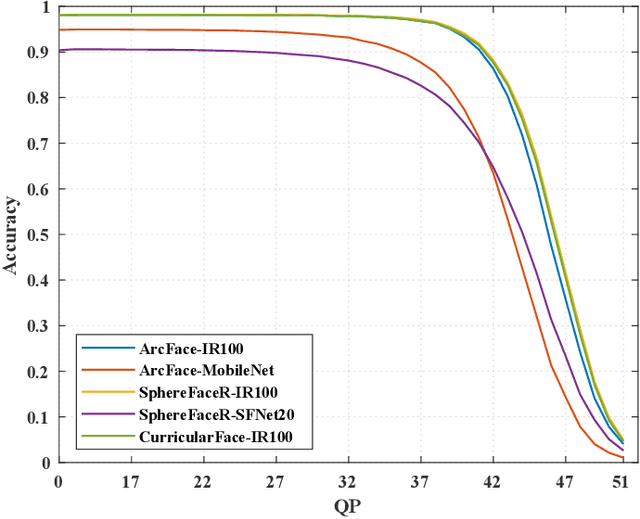
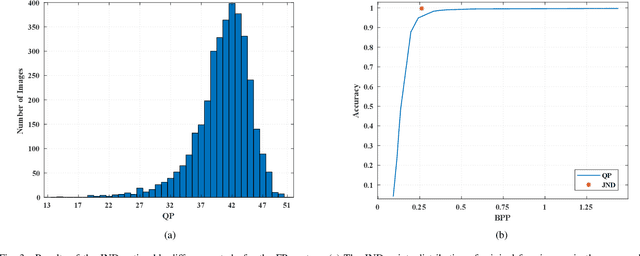
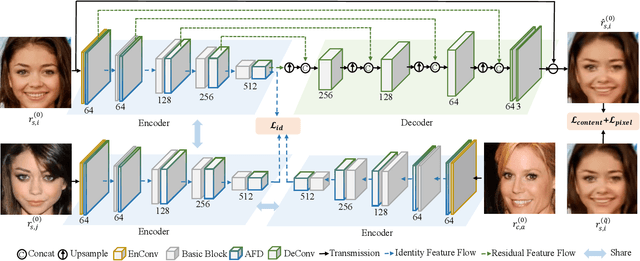
High-quality face images are required to guarantee the stability and reliability of automatic face recognition (FR) systems in surveillance and security scenarios. However, a massive amount of face data is usually compressed before being analyzed due to limitations on transmission or storage. The compressed images may lose the powerful identity information, resulting in the performance degradation of the FR system. Herein, we make the first attempt to study just noticeable difference (JND) for the FR system, which can be defined as the maximum distortion that the FR system cannot notice. More specifically, we establish a JND dataset including 3530 original images and 137,670 compressed images generated by advanced reference encoding/decoding software based on the Versatile Video Coding (VVC) standard (VTM-15.0). Subsequently, we develop a novel JND prediction model to directly infer JND images for the FR system. In particular, in order to maximum redundancy removal without impairment of robust identity information, we apply the encoder with multiple feature extraction and attention-based feature decomposition modules to progressively decompose face features into two uncorrelated components, i.e., identity and residual features, via self-supervised learning. Then, the residual feature is fed into the decoder to generate the residual map. Finally, the predicted JND map is obtained by subtracting the residual map from the original image. Experimental results have demonstrated that the proposed model achieves higher accuracy of JND map prediction compared with the state-of-the-art JND models, and is capable of saving more bits while maintaining the performance of the FR system compared with VTM-15.0.
Mask-Guided Image Person Removal with Data Synthesis
Sep 29, 2022
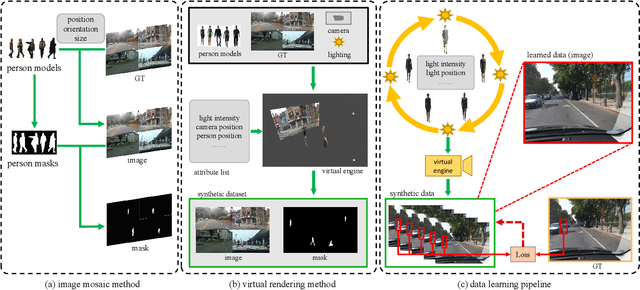
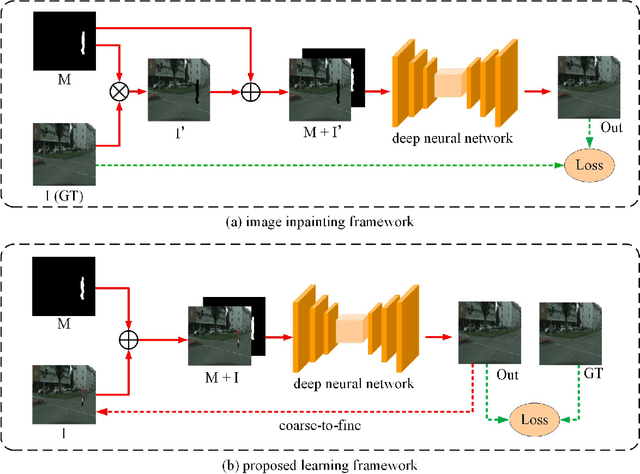

As a special case of common object removal, image person removal is playing an increasingly important role in social media and criminal investigation domains. Due to the integrity of person area and the complexity of human posture, person removal has its own dilemmas. In this paper, we propose a novel idea to tackle these problems from the perspective of data synthesis. Concerning the lack of dedicated dataset for image person removal, two dataset production methods are proposed to automatically generate images, masks and ground truths respectively. Then, a learning framework similar to local image degradation is proposed so that the masks can be used to guide the feature extraction process and more texture information can be gathered for final prediction. A coarse-to-fine training strategy is further applied to refine the details. The data synthesis and learning framework combine well with each other. Experimental results verify the effectiveness of our method quantitatively and qualitatively, and the trained network proves to have good generalization ability either on real or synthetic images.
Baking in the Feature: Accelerating Volumetric Segmentation by Rendering Feature Maps
Sep 26, 2022


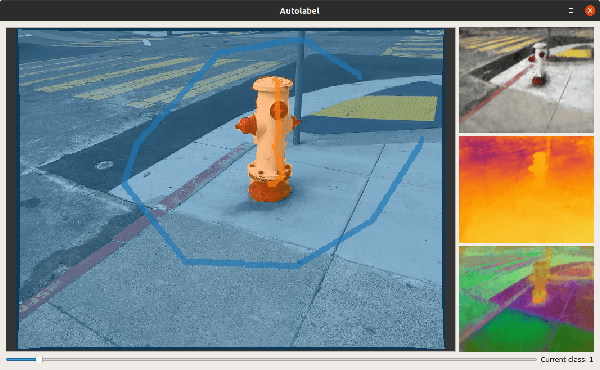
Methods have recently been proposed that densely segment 3D volumes into classes using only color images and expert supervision in the form of sparse semantically annotated pixels. While impressive, these methods still require a relatively large amount of supervision and segmenting an object can take several minutes in practice. Such systems typically only optimize their representation on the particular scene they are fitting, without leveraging any prior information from previously seen images. In this paper, we propose to use features extracted with models trained on large existing datasets to improve segmentation performance. We bake this feature representation into a Neural Radiance Field (NeRF) by volumetrically rendering feature maps and supervising on features extracted from each input image. We show that by baking this representation into the NeRF, we make the subsequent classification task much easier. Our experiments show that our method achieves higher segmentation accuracy with fewer semantic annotations than existing methods over a wide range of scenes.
Reference Resolution and Context Change in Multimodal Situated Dialogue for Exploring Data Visualizations
Sep 06, 2022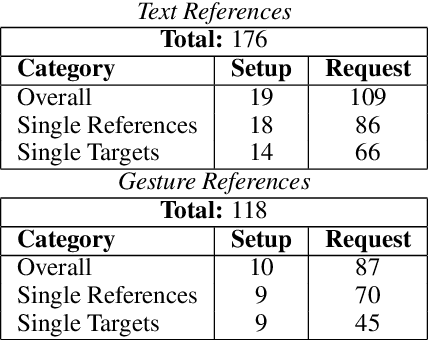
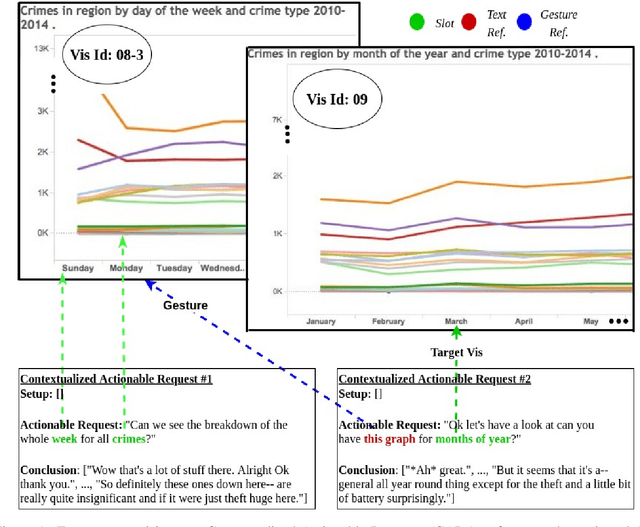
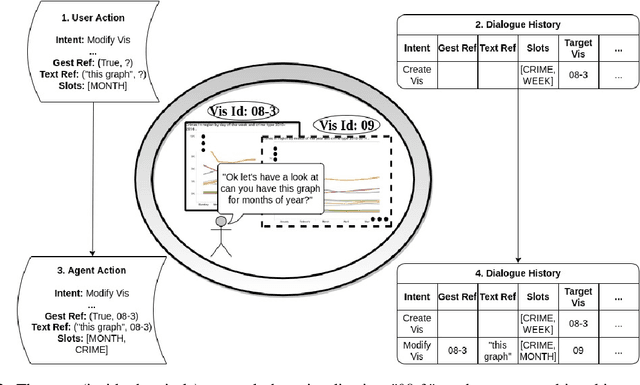
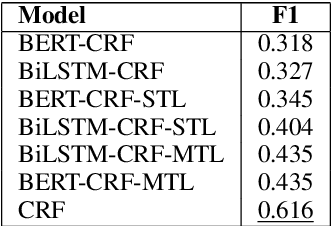
Reference resolution, which aims to identify entities being referred to by a speaker, is more complex in real world settings: new referents may be created by processes the agents engage in and/or be salient only because they belong to the shared physical setting. Our focus is on resolving references to visualizations on a large screen display in multimodal dialogue; crucially, reference resolution is directly involved in the process of creating new visualizations. We describe our annotations for user references to visualizations appearing on a large screen via language and hand gesture and also new entity establishment, which results from executing the user request to create a new visualization. We also describe our reference resolution pipeline which relies on an information-state architecture to maintain dialogue context. We report results on detecting and resolving references, effectiveness of contextual information on the model, and under-specified requests for creating visualizations. We also experiment with conventional CRF and deep learning / transformer models (BiLSTM-CRF and BERT-CRF) for tagging references in user utterance text. Our results show that transfer learning significantly boost performance of the deep learning methods, although CRF still out-performs them, suggesting that conventional methods may generalize better for low resource data.
Adversarial Scrubbing of Demographic Information for Text Classification
Sep 17, 2021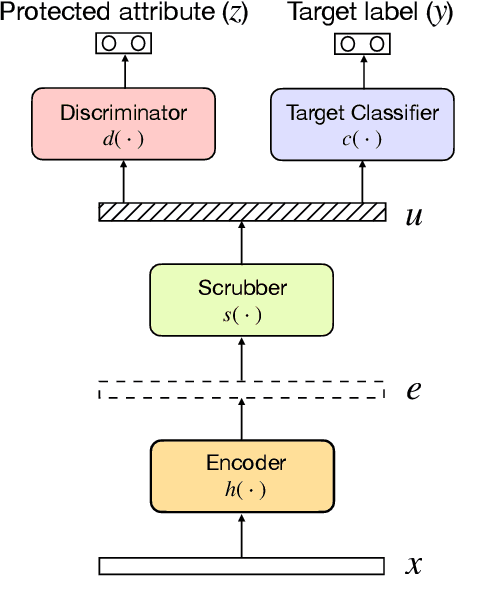
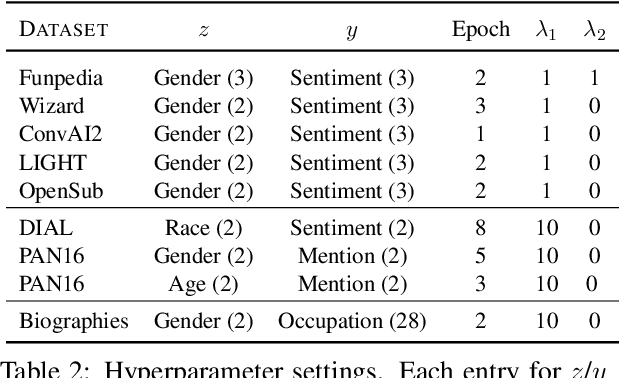
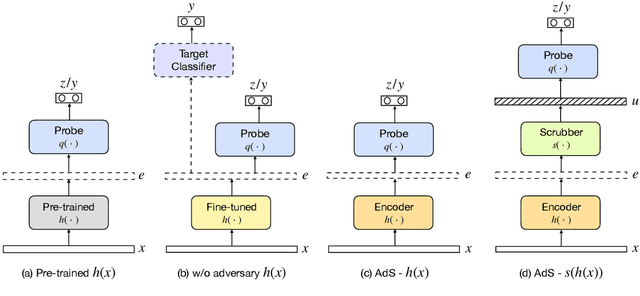
Contextual representations learned by language models can often encode undesirable attributes, like demographic associations of the users, while being trained for an unrelated target task. We aim to scrub such undesirable attributes and learn fair representations while maintaining performance on the target task. In this paper, we present an adversarial learning framework "Adversarial Scrubber" (ADS), to debias contextual representations. We perform theoretical analysis to show that our framework converges without leaking demographic information under certain conditions. We extend previous evaluation techniques by evaluating debiasing performance using Minimum Description Length (MDL) probing. Experimental evaluations on 8 datasets show that ADS generates representations with minimal information about demographic attributes while being maximally informative about the target task.
A Study on the Efficient Product Search Service for the Damaged Image Information
Nov 14, 2021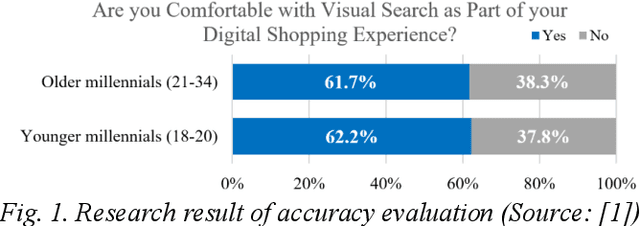
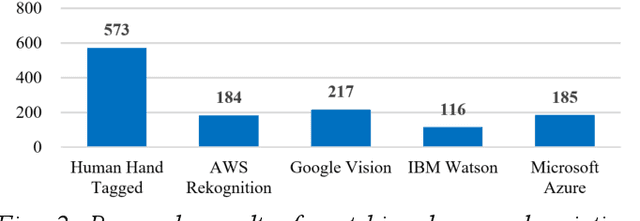

With the development of Information and Communication Technologies and the dissemination of smartphones, especially now that image search is possible through the internet, e-commerce markets are more activating purchasing services for a wide variety of products. However, it often happens that the image of the desired product is impaired and that the search engine does not recognize it properly. The idea of this study is to help search for products through image restoration using an image pre-processing and image inpainting algorithm for damaged images. It helps users easily purchase the items they want by providing a more accurate image search system. Besides, the system has the advantage of efficiently showing information by category, so that enables efficient sales of registered information.
Self-supervised Pre-training for Semantic Segmentation in an Indoor Scene
Oct 04, 2022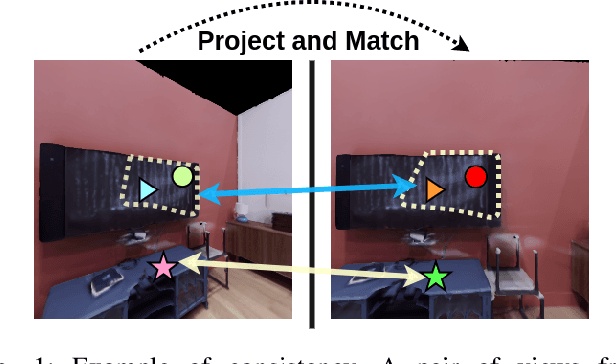
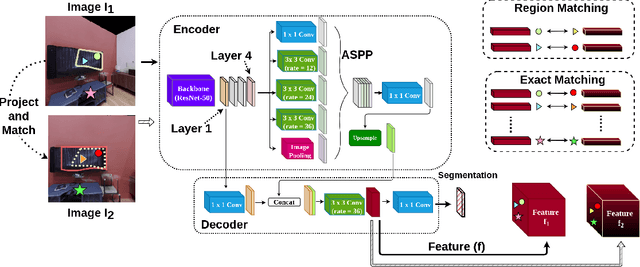

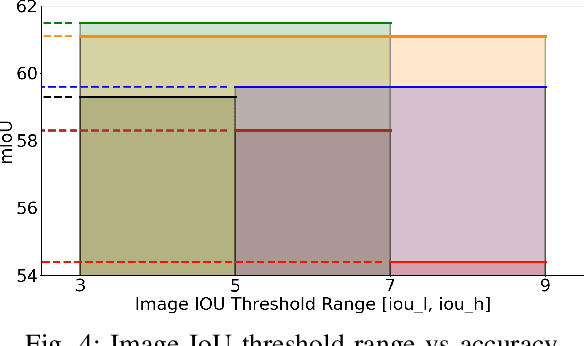
The ability to endow maps of indoor scenes with semantic information is an integral part of robotic agents which perform different tasks such as target driven navigation, object search or object rearrangement. The state-of-the-art methods use Deep Convolutional Neural Networks (DCNNs) for predicting semantic segmentation of an image as useful representation for these tasks. The accuracy of semantic segmentation depends on the availability and the amount of labeled data from the target environment or the ability to bridge the domain gap between test and training environment. We propose RegConsist, a method for self-supervised pre-training of a semantic segmentation model, exploiting the ability of the agent to move and register multiple views in the novel environment. Given the spatial and temporal consistency cues used for pixel level data association, we use a variant of contrastive learning to train a DCNN model for predicting semantic segmentation from RGB views in the target environment. The proposed method outperforms models pre-trained on ImageNet and achieves competitive performance when using models that are trained for exactly the same task but on a different dataset. We also perform various ablation studies to analyze and demonstrate the efficacy of our proposed method.