 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Stock Volatility Prediction using Time Series and Deep Learning Approach
Oct 05, 2022
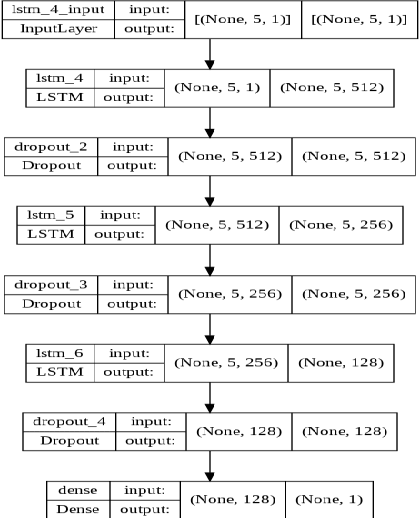
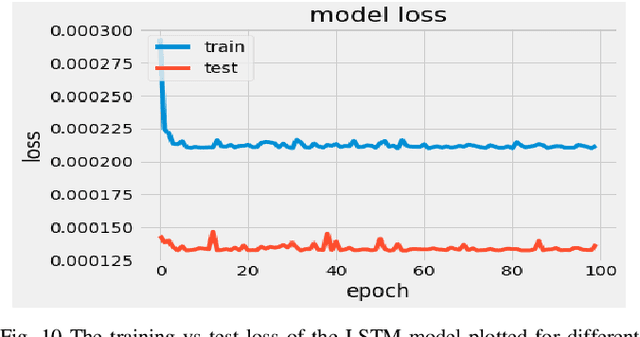
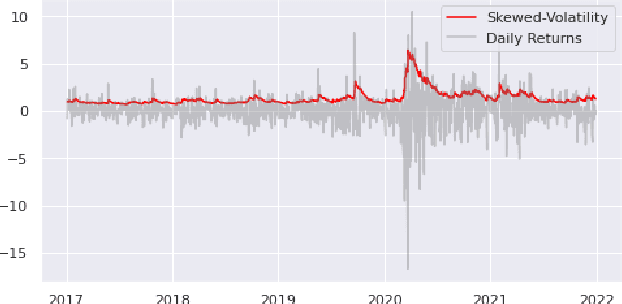
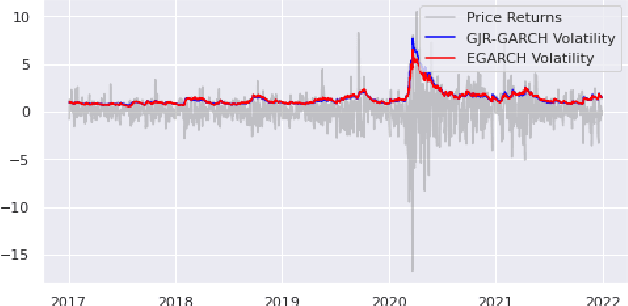
Volatility clustering is a crucial property that has a substantial impact on stock market patterns. Nonetheless, developing robust models for accurately predicting future stock price volatility is a difficult research topic. For predicting the volatility of three equities listed on India's national stock market (NSE), we propose multiple volatility models depending on the generalized autoregressive conditional heteroscedasticity (GARCH), Glosten-Jagannathan-GARCH (GJR-GARCH), Exponential general autoregressive conditional heteroskedastic (EGARCH), and LSTM framework. Sector-wise stocks have been chosen in our study. The sectors which have been considered are banking, information technology (IT), and pharma. yahoo finance has been used to obtain stock price data from Jan 2017 to Dec 2021. Among the pulled-out records, the data from Jan 2017 to Dec 2020 have been taken for training, and data from 2021 have been chosen for testing our models. The performance of predicting the volatility of stocks of three sectors has been evaluated by implementing three different types of GARCH models as well as by the LSTM model are compared. It has been observed the LSTM performed better in predicting volatility in pharma over banking and IT sectors. In tandem, it was also observed that E-GARCH performed better in the case of the banking sector and for IT and pharma, GJR-GARCH performed better.
A Transferable Intersection Reconstruction Network for Traffic Speed Prediction
Jul 22, 2022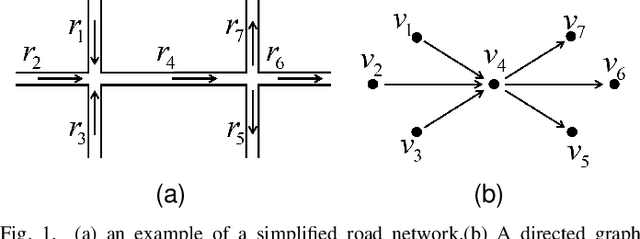
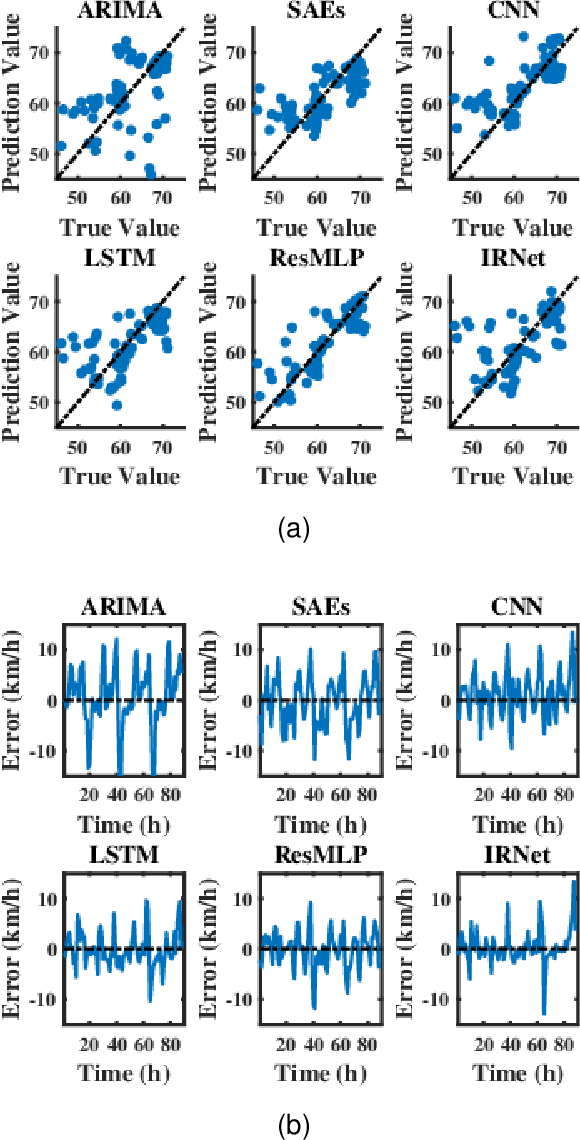
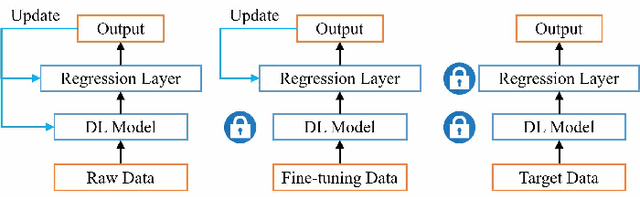
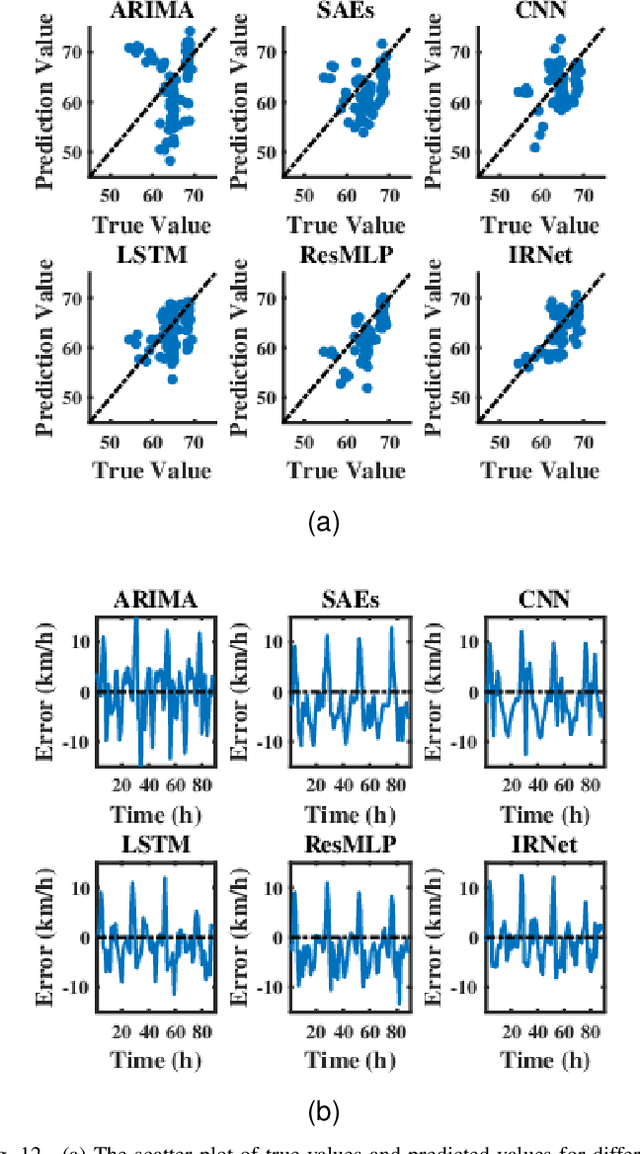
Traffic speed prediction is the key to many valuable applications, and it is also a challenging task because of its various influencing factors. Recent work attempts to obtain more information through various hybrid models, thereby improving the prediction accuracy. However, the spatial information acquisition schemes of these methods have two-level differentiation problems. Either the modeling is simple but contains little spatial information, or the modeling is complete but lacks flexibility. In order to introduce more spatial information on the basis of ensuring flexibility, this paper proposes IRNet (Transferable Intersection Reconstruction Network). First, this paper reconstructs the intersection into a virtual intersection with the same structure, which simplifies the topology of the road network. Then, the spatial information is subdivided into intersection information and sequence information of traffic flow direction, and spatiotemporal features are obtained through various models. Third, a self-attention mechanism is used to fuse spatiotemporal features for prediction. In the comparison experiment with the baseline, not only the prediction effect, but also the transfer performance has obvious advantages.
Placing by Touching: An empirical study on the importance of tactile sensing for precise object placing
Oct 05, 2022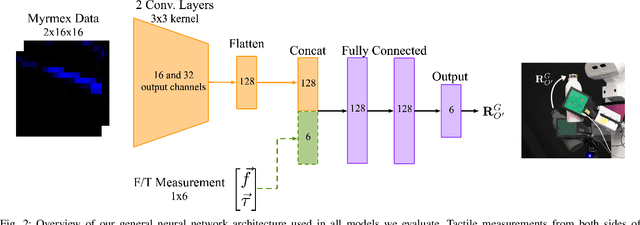
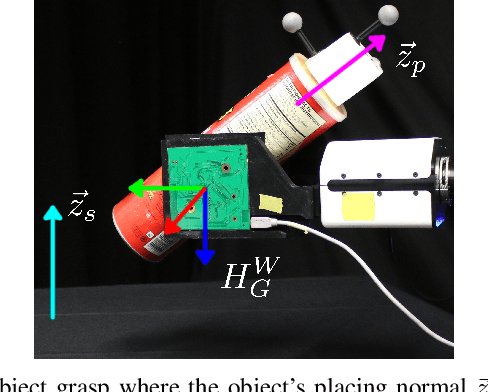
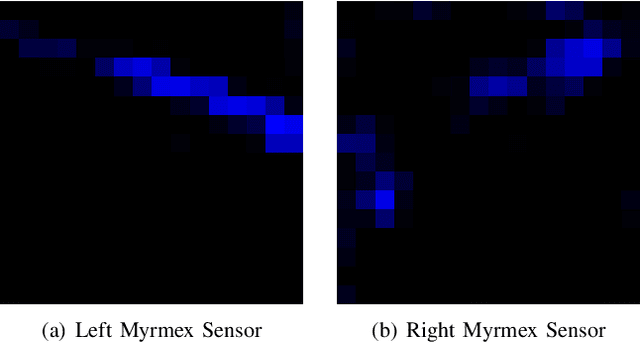

Tactile sensors are promising tools for endowing robots with embodied intelligence and increased dexterity. These sensors can provide robotic systems with direct information about physical interactions with the world, which is difficult to obtain from extrinsic perception systems. This work deals with a practical everyday living problem: stable object placement on flat surfaces starting from unknown initial poses. Common approaches for object placing either require complete scene specifications or indirect sensor measurements, such as cameras which are prone to suffer from occlusions. Instead, this work proposes a novel approach for stable object placing that combines tactile feedback and proprioceptive sensing. We devise a neural architecture that estimates a rotation matrix which results in a corrective gripper movement that aligns the object with the table and paves the way for the subsequent stable object placement. We compare models with different sensing modalities, such as force-torque and an external motion capture system, in real-world object placement tasks with different objects. Our experimental evaluation of the placing policies with a set of unknown everyday objects reveals an impressive generalization of the tactile-based pipeline and suggests that tactile sensing plays a vital role in the intrinsic understanding of dexterous object manipulation. Videos of our approach are available at https://sites.google.com/view/placing-by-touching.
Towards Top-Down Deep Code Generation in Limited Scopes
Sep 04, 2022

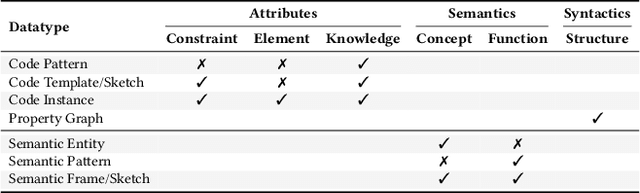
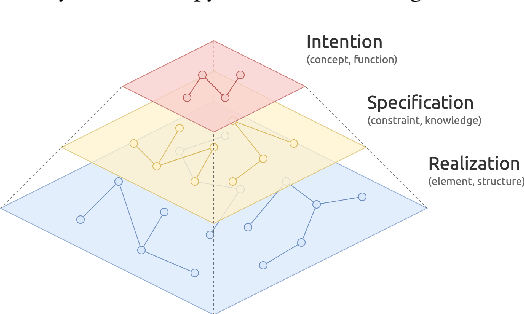
Deep code generation is a topic of deep learning for software engineering (DL4SE), which adopts neural models to generate code for the intended functions. Since end-to-end neural methods lack the awareness of domain knowledge and software hierarchy, the results often require manual correction. To systematically explore the potential improvements of code generation, we let it participate in the whole top-down development from intentions to realizations, which is possible in limited scopes. In the process, it benefits from massive samples, features, and knowledge. As the foundation, we suggest building a taxonomy on code data, namely code taxonomy, leveraging the categorization of code information. Moreover, we introduce a three-layer semantic pyramid (SP) to associate text data and code data. It identifies the information of different abstraction levels, and thus introduces the domain knowledge on development and reveals the hierarchy of software. Furthermore, we propose a semantic pyramid framework (SPF) as the approach, focusing on softwares of high modularity and low complexity. SPF divides the code generation process into stages and reserves spots for potential interactions. Eventually, we conceived application scopes for SPF.
KeypartX: Graph-based Perception (Text) Representation
Sep 23, 2022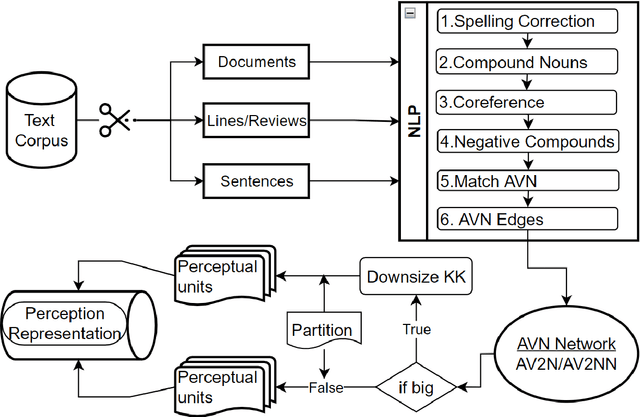

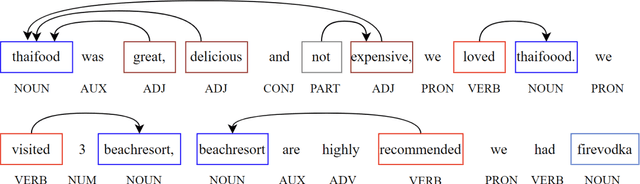
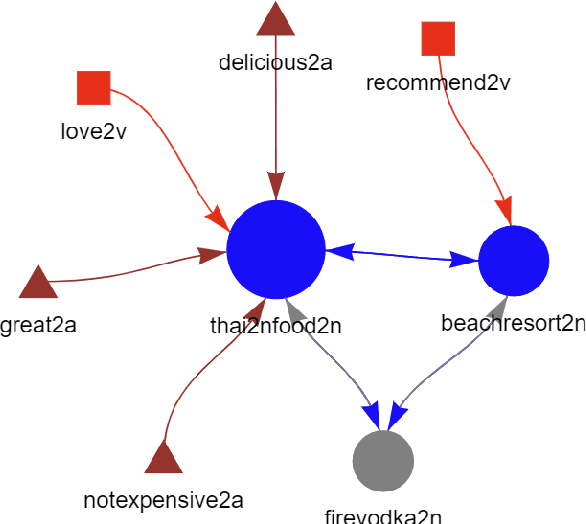
The availability of big data has opened up big opportunities for individuals, businesses and academics to view big into what is happening in their world. Previous works of text representation mostly focused on informativeness from massive words' frequency or cooccurrence. However, big data is a double-edged sword which is big in volume but unstructured in format. The unstructured edge requires specific techniques to transform 'big' into meaningful instead of informative alone. This study presents KeypartX, a graph-based approach to represent perception (text in general) by key parts of speech. Different from bag-of-words/vector-based machine learning, this technique is human-like learning that could extracts meanings from linguistic (semantic, syntactic and pragmatic) information. Moreover, KeypartX is big-data capable but not hungry, which is even applicable to the minimum unit of text:sentence.
Learning Video-independent Eye Contact Segmentation from In-the-Wild Videos
Oct 05, 2022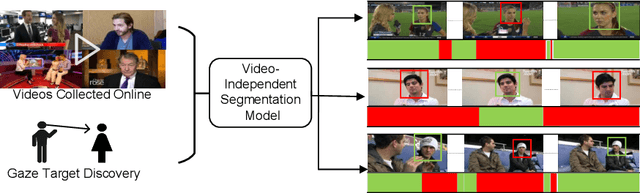

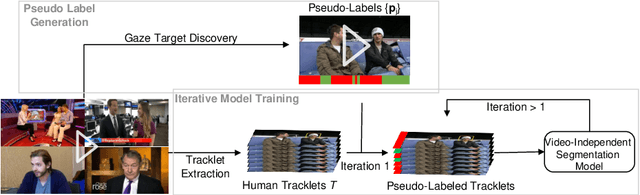
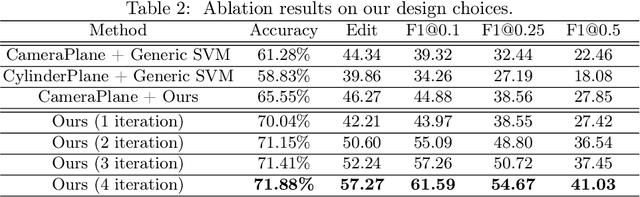
Human eye contact is a form of non-verbal communication and can have a great influence on social behavior. Since the location and size of the eye contact targets vary across different videos, learning a generic video-independent eye contact detector is still a challenging task. In this work, we address the task of one-way eye contact detection for videos in the wild. Our goal is to build a unified model that can identify when a person is looking at his gaze targets in an arbitrary input video. Considering that this requires time-series relative eye movement information, we propose to formulate the task as a temporal segmentation. Due to the scarcity of labeled training data, we further propose a gaze target discovery method to generate pseudo-labels for unlabeled videos, which allows us to train a generic eye contact segmentation model in an unsupervised way using in-the-wild videos. To evaluate our proposed approach, we manually annotated a test dataset consisting of 52 videos of human conversations. Experimental results show that our eye contact segmentation model outperforms the previous video-dependent eye contact detector and can achieve 71.88% framewise accuracy on our annotated test set. Our code and evaluation dataset are available at https://github.com/ut-vision/Video-Independent-ECS.
Medical Image Understanding with Pretrained Vision Language Models: A Comprehensive Study
Sep 30, 2022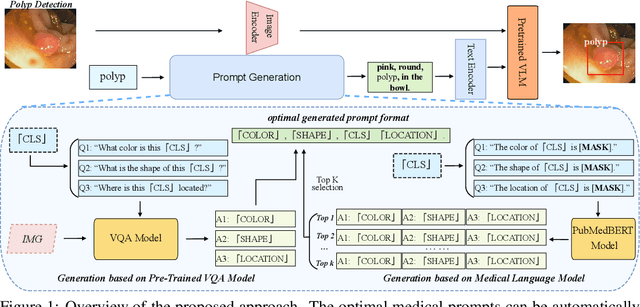
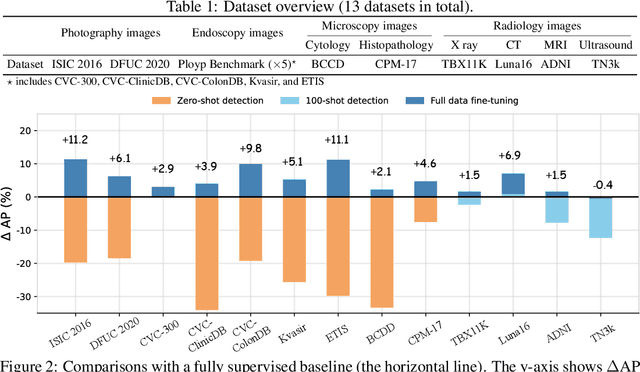
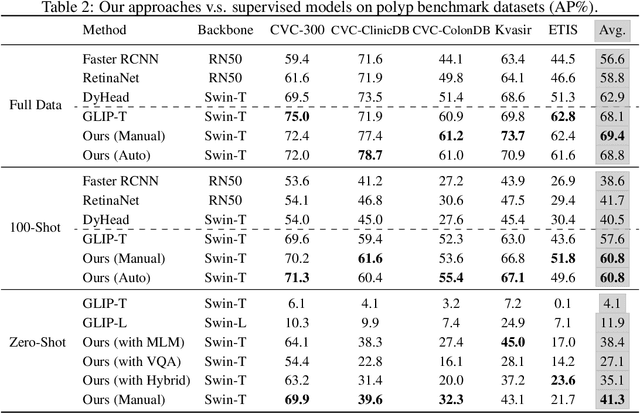
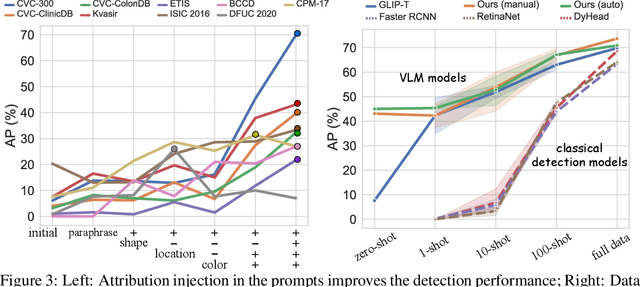
The large-scale pre-trained vision language models (VLM) have shown remarkable domain transfer capability on natural images. However, it remains unknown whether this capability can also apply to the medical image domain. This paper thoroughly studies the knowledge transferability of pre-trained VLMs to the medical domain, where we show that well-designed medical prompts are the key to elicit knowledge from pre-trained VLMs. We demonstrate that by prompting with expressive attributes that are shared between domains, the VLM can carry the knowledge across domains and improve its generalization. This mechanism empowers VLMs to recognize novel objects with fewer or without image samples. Furthermore, to avoid the laborious manual designing process, we develop three approaches for automatic generation of medical prompts, which can inject expert-level medical knowledge and image-specific information into the prompts for fine-grained grounding. We conduct extensive experiments on thirteen different medical datasets across various modalities, showing that our well-designed prompts greatly improve the zero-shot performance compared to the default prompts, and our fine-tuned models surpass the supervised models by a significant margin.
IMB-NAS: Neural Architecture Search for Imbalanced Datasets
Sep 30, 2022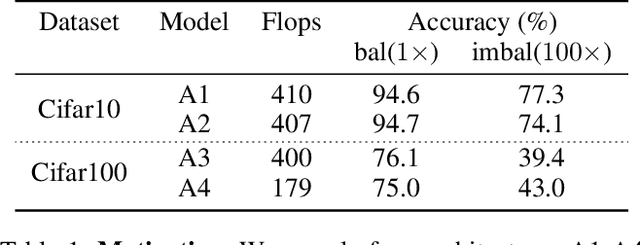
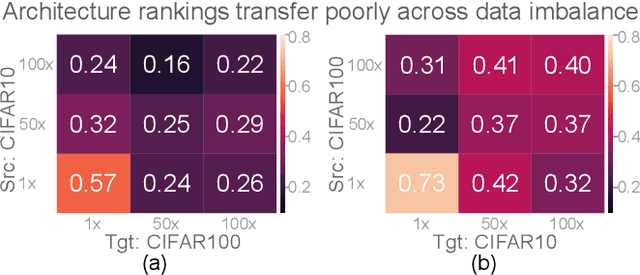

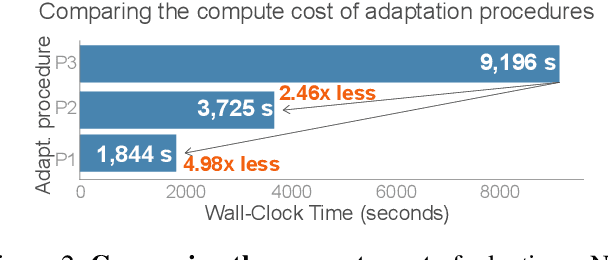
Class imbalance is a ubiquitous phenomenon occurring in real world data distributions. To overcome its detrimental effect on training accurate classifiers, existing work follows three major directions: class re-balancing, information transfer, and representation learning. In this paper, we propose a new and complementary direction for improving performance on long tailed datasets - optimizing the backbone architecture through neural architecture search (NAS). We find that an architecture's accuracy obtained on a balanced dataset is not indicative of good performance on imbalanced ones. This poses the need for a full NAS run on long tailed datasets which can quickly become prohibitively compute intensive. To alleviate this compute burden, we aim to efficiently adapt a NAS super-network from a balanced source dataset to an imbalanced target one. Among several adaptation strategies, we find that the most effective one is to retrain the linear classification head with reweighted loss, while freezing the backbone NAS super-network trained on a balanced source dataset. We perform extensive experiments on multiple datasets and provide concrete insights to optimize architectures for long tailed datasets.
Direct Embedding of Temporal Network Edges via Time-Decayed Line Graphs
Sep 30, 2022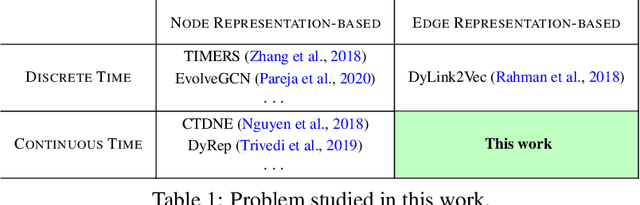
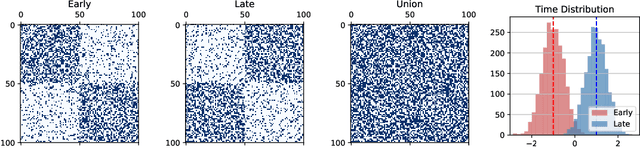
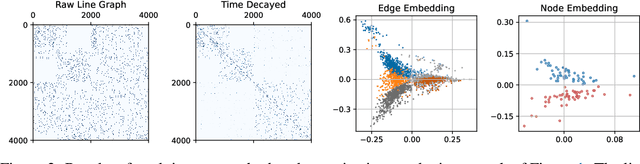
Temporal networks model a variety of important phenomena involving timed interactions between entities. Existing methods for machine learning on temporal networks generally exhibit at least one of two limitations. First, time is assumed to be discretized, so if the time data is continuous, the user must determine the discretization and discard precise time information. Second, edge representations can only be calculated indirectly from the nodes, which may be suboptimal for tasks like edge classification. We present a simple method that avoids both shortcomings: construct the line graph of the network, which includes a node for each interaction, and weigh the edges of this graph based on the difference in time between interactions. From this derived graph, edge representations for the original network can be computed with efficient classical methods. The simplicity of this approach facilitates explicit theoretical analysis: we can constructively show the effectiveness of our method's representations for a natural synthetic model of temporal networks. Empirical results on real-world networks demonstrate our method's efficacy and efficiency on both edge classification and temporal link prediction.
What Makes Pre-trained Language Models Better Zero/Few-shot Learners?
Sep 30, 2022

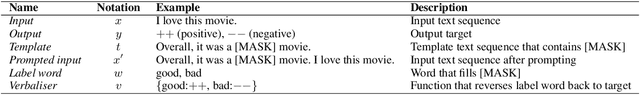
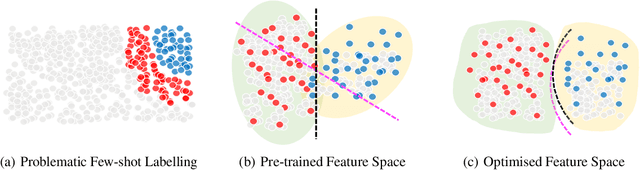
In this paper, we propose a theoretical framework to explain the efficacy of prompt learning in zero/few-shot scenarios. First, we prove that conventional pre-training and fine-tuning paradigm fails in few-shot scenarios due to overfitting the unrepresentative labelled data. We then detail the assumption that prompt learning is more effective because it empowers pre-trained language model that is built upon massive text corpora, as well as domain-related human knowledge to participate more in prediction and thereby reduces the impact of limited label information provided by the small training set. We further hypothesize that language discrepancy can measure the quality of prompting. Comprehensive experiments are performed to verify our assumptions. More remarkably, inspired by the theoretical framework, we propose an annotation-agnostic template selection method based on perplexity, which enables us to ``forecast'' the prompting performance in advance. This approach is especially encouraging because existing work still relies on development set to post-hoc evaluate templates. Experiments show that this method leads to significant prediction benefits compared to state-of-the-art zero-shot methods.