 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Cautious Planning with Incremental Symbolic Perception: Designing Verified Reactive Driving Maneuvers
Sep 20, 2022
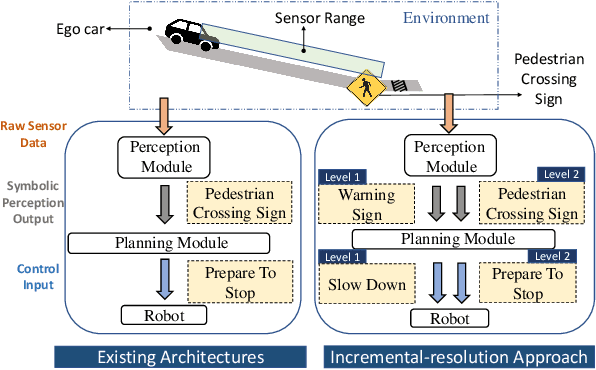
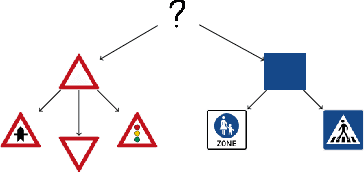
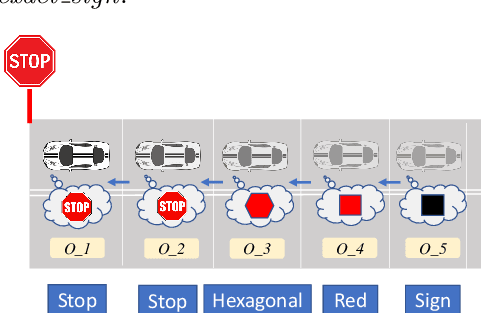
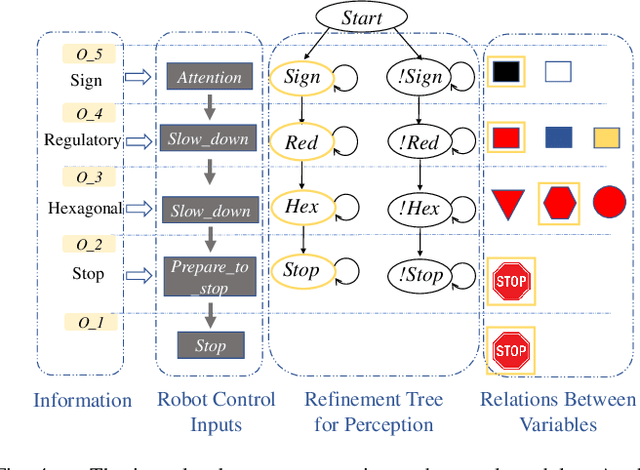
This work presents a step towards utilizing incrementally-improving symbolic perception knowledge of the robot's surroundings for provably correct reactive control synthesis applied to an autonomous driving problem. Combining abstract models of motion control and information gathering, we show that assume-guarantee specifications (a subclass of Linear Temporal Logic) can be used to define and resolve traffic rules for cautious planning. We propose a novel representation called symbolic refinement tree for perception that captures the incremental knowledge about the environment and embodies the relationships between various symbolic perception inputs. The incremental knowledge is leveraged for synthesizing verified reactive plans for the robot. The case studies demonstrate the efficacy of the proposed approach in synthesizing control inputs even in case of partially occluded environments.
Graph2Vid: Flow graph to Video Grounding forWeakly-supervised Multi-Step Localization
Oct 10, 2022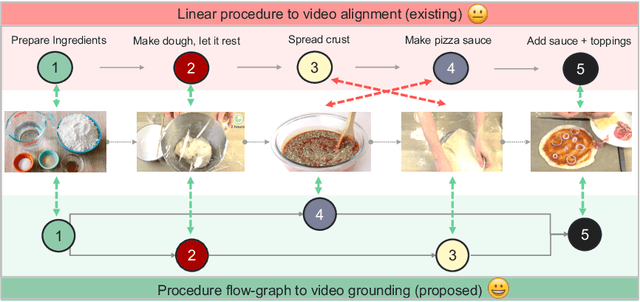
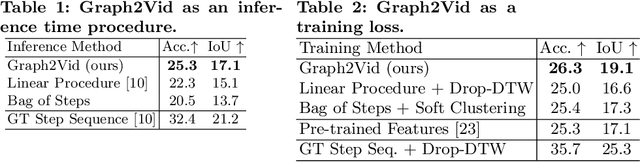

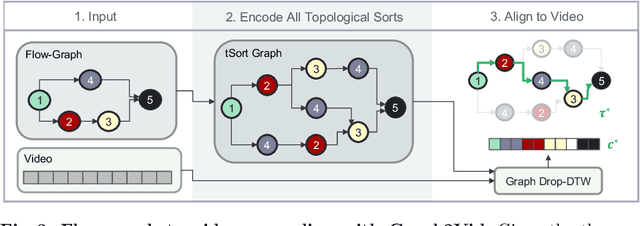
In this work, we consider the problem of weakly-supervised multi-step localization in instructional videos. An established approach to this problem is to rely on a given list of steps. However, in reality, there is often more than one way to execute a procedure successfully, by following the set of steps in slightly varying orders. Thus, for successful localization in a given video, recent works require the actual order of procedure steps in the video, to be provided by human annotators at both training and test times. Instead, here, we only rely on generic procedural text that is not tied to a specific video. We represent the various ways to complete the procedure by transforming the list of instructions into a procedure flow graph which captures the partial order of steps. Using the flow graphs reduces both training and test time annotation requirements. To this end, we introduce the new problem of flow graph to video grounding. In this setup, we seek the optimal step ordering consistent with the procedure flow graph and a given video. To solve this problem, we propose a new algorithm - Graph2Vid - that infers the actual ordering of steps in the video and simultaneously localizes them. To show the advantage of our proposed formulation, we extend the CrossTask dataset with procedure flow graph information. Our experiments show that Graph2Vid is both more efficient than the baselines and yields strong step localization results, without the need for step order annotation.
* ECCV'22, oral
DDoS: A Graph Neural Network based Drug Synergy Prediction Algorithm
Oct 10, 2022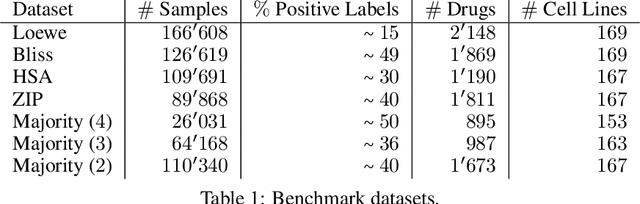
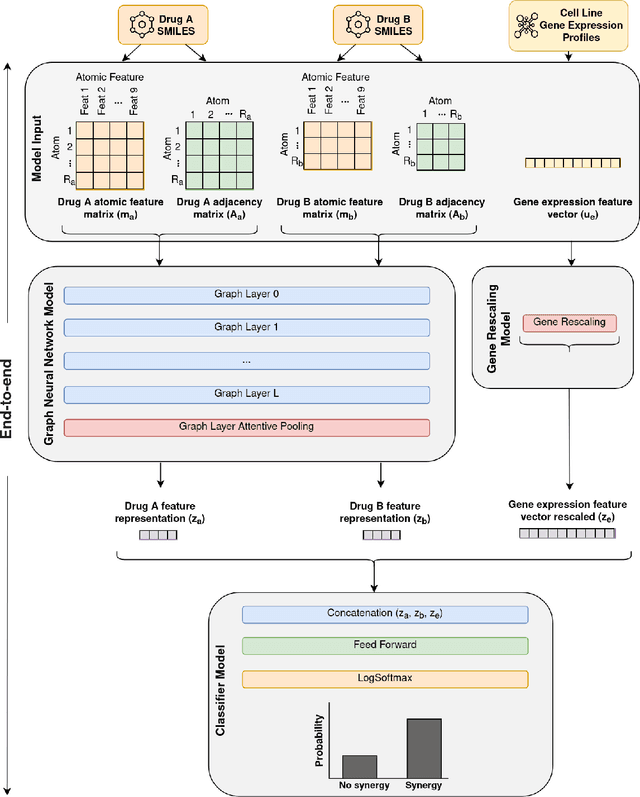
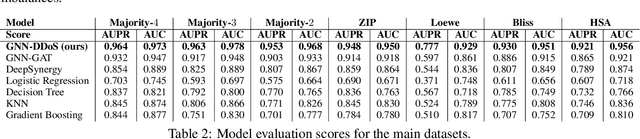
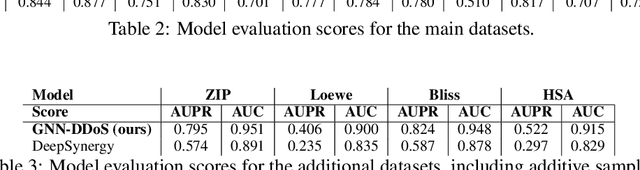
Background: Drug synergy occurs when the combined effect of two drugs is greater than the sum of the individual drugs' effect. While cell line data measuring the effect of single drugs are readily available, there is relatively less comparable data on drug synergy given the vast amount of possible drug combinations. Thus, there is interest to use computational approaches to predict drug synergy for untested pairs of drugs. Methods: We introduce a Graph Neural Network (GNN) based model for drug synergy prediction, which utilizes drug chemical structures and cell line gene expression data. We use information from the largest drug combination database available (DrugComb), combining drug synergy scores in order to construct high confidence benchmark datasets. Results: Our proposed solution for drug synergy predictions offers a number of benefits: 1) It utilizes a combination of 34 distinct drug synergy datasets to learn on a wide variety of drugs and cell lines representations. 2) It is trained on constructed high confidence benchmark datasets. 3) It learns task-specific drug representations, instead of relying on generalized and pre-computed chemical drug features. 4) It achieves similar or better prediction performance (AUPR scores ranging from 0.777 to 0.964) compared to state-of-the-art baseline models when tested on various benchmark datasets. Conclusions: We demonstrate that a GNN based model can provide state-of-the-art drug synergy predictions by learning task-specific representations of drugs.
WatchPed: Pedestrian Crossing Intention Prediction Using Embedded Sensors of Smartwatch
Aug 15, 2022
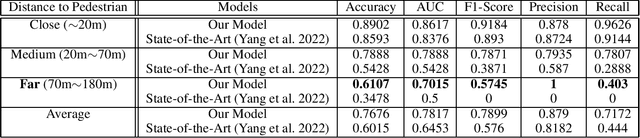
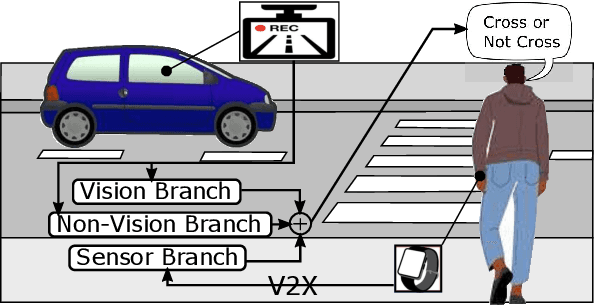
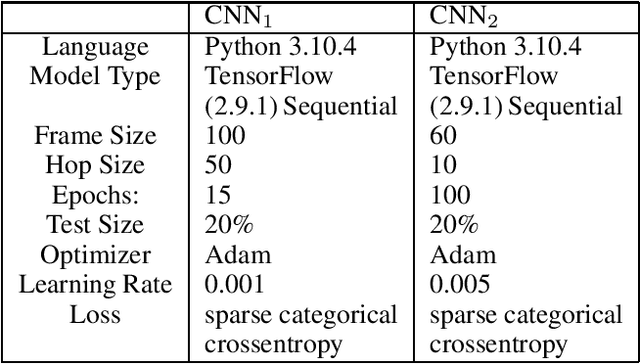
The pedestrian intention prediction problem is to estimate whether or not the target pedestrian will cross the street. State-of-the-art approaches heavily rely on visual information collected with the front camera of the ego-vehicle to make a prediction of the pedestrian's intention. As such, the performance of existing methods significantly degrades when the visual information is not accurate, e.g., when the distance between the pedestrian and ego-vehicle is far, or the lighting conditions are not good enough. In this paper, we design, implement, and evaluate the first pedestrian intention prediction model based on integration of motion sensor data gathered with the smartwatch (or smartphone) of the pedestrian. A novel machine learning architecture is proposed to effectively incorporate the motion sensor data to reinforce the visual information to significantly improve the performance in adverse situations where the visual information may be unreliable. We also conduct a large-scale data collection and present the first pedestrian intention prediction dataset integrated with time-synchronized motion sensor data. The dataset consists of a total of 128 video clips with different distances and varying levels of lighting conditions. We trained our model using the widely-used JAAD and our own datasets and compare the performance with a state-of-the-art model. The results demonstrate that our model outperforms the state-of-the-art method particularly when the distance to the pedestrian is far (over 70m), and the lighting conditions are not sufficient.
Multi-Content Time-Series Popularity Prediction with Multiple-Model Transformers in MEC Networks
Oct 12, 2022
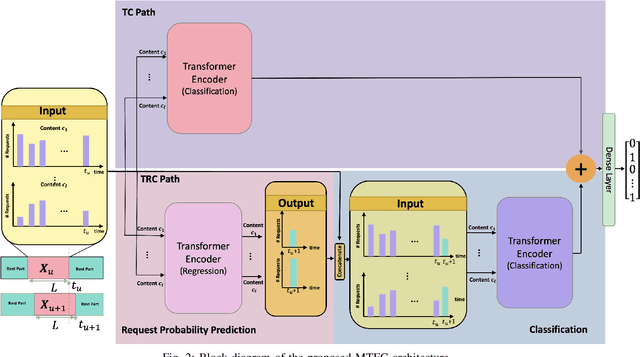
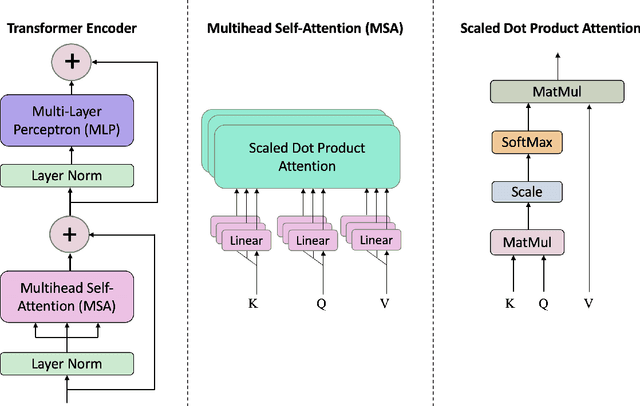
Coded/uncoded content placement in Mobile Edge Caching (MEC) has evolved as an efficient solution to meet the significant growth of global mobile data traffic by boosting the content diversity in the storage of caching nodes. To meet the dynamic nature of the historical request pattern of multimedia contents, the main focus of recent researches has been shifted to develop data-driven and real-time caching schemes. In this regard and with the assumption that users' preferences remain unchanged over a short horizon, the Top-K popular contents are identified as the output of the learning model. Most existing datadriven popularity prediction models, however, are not suitable for the coded/uncoded content placement frameworks. On the one hand, in coded/uncoded content placement, in addition to classifying contents into two groups, i.e., popular and nonpopular, the probability of content request is required to identify which content should be stored partially/completely, where this information is not provided by existing data-driven popularity prediction models. On the other hand, the assumption that users' preferences remain unchanged over a short horizon only works for content with a smooth request pattern. To tackle these challenges, we develop a Multiple-model (hybrid) Transformer-based Edge Caching (MTEC) framework with higher generalization ability, suitable for various types of content with different time-varying behavior, that can be adapted with coded/uncoded content placement frameworks. Simulation results corroborate the effectiveness of the proposed MTEC caching framework in comparison to its counterparts in terms of the cache-hit ratio, classification accuracy, and the transferred byte volume.
Attention Distillation: self-supervised vision transformer students need more guidance
Oct 03, 2022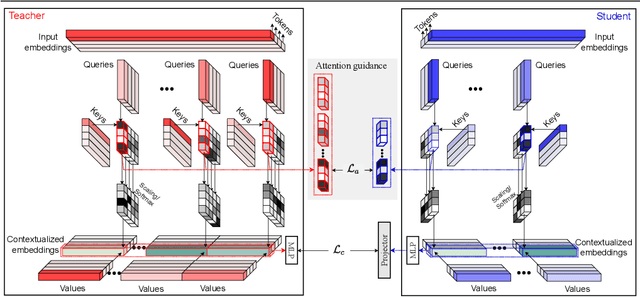
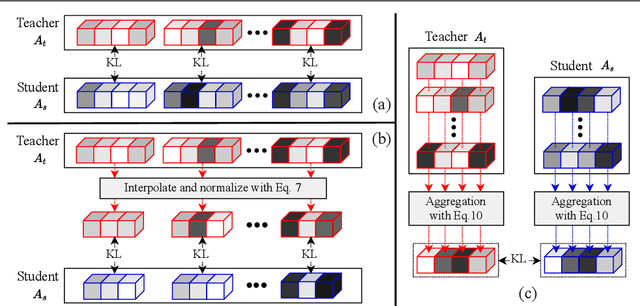
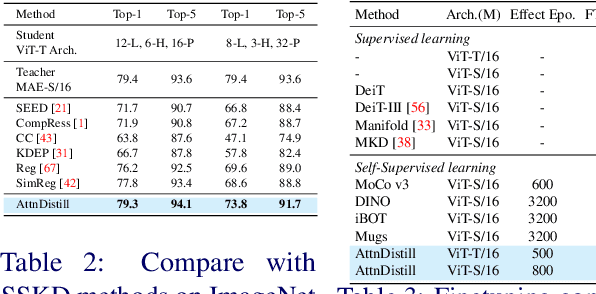
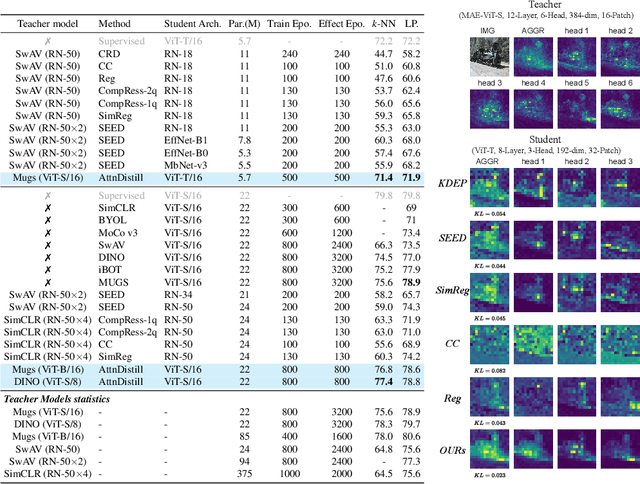
Self-supervised learning has been widely applied to train high-quality vision transformers. Unleashing their excellent performance on memory and compute constraint devices is therefore an important research topic. However, how to distill knowledge from one self-supervised ViT to another has not yet been explored. Moreover, the existing self-supervised knowledge distillation (SSKD) methods focus on ConvNet based architectures are suboptimal for ViT knowledge distillation. In this paper, we study knowledge distillation of self-supervised vision transformers (ViT-SSKD). We show that directly distilling information from the crucial attention mechanism from teacher to student can significantly narrow the performance gap between both. In experiments on ImageNet-Subset and ImageNet-1K, we show that our method AttnDistill outperforms existing self-supervised knowledge distillation (SSKD) methods and achieves state-of-the-art k-NN accuracy compared with self-supervised learning (SSL) methods learning from scratch (with the ViT-S model). We are also the first to apply the tiny ViT-T model on self-supervised learning. Moreover, AttnDistill is independent of self-supervised learning algorithms, it can be adapted to ViT based SSL methods to improve the performance in future research. The code is here: https://github.com/wangkai930418/attndistill
Efficient Bayes Inference in Neural Networks through Adaptive Importance Sampling
Oct 03, 2022

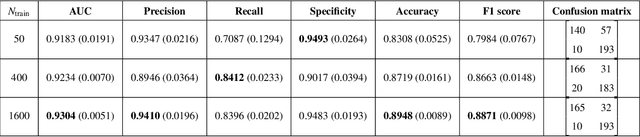
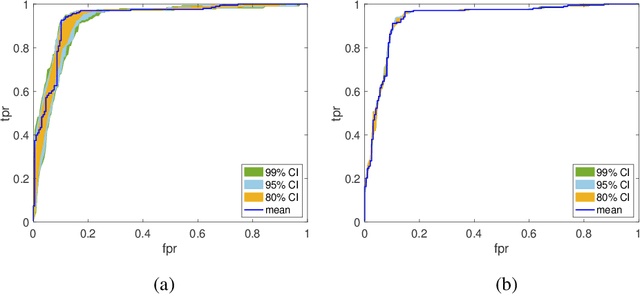
Bayesian neural networks (BNNs) have received an increased interest in the last years. In BNNs, a complete posterior distribution of the unknown weight and bias parameters of the network is produced during the training stage. This probabilistic estimation offers several advantages with respect to point-wise estimates, in particular, the ability to provide uncertainty quantification when predicting new data. This feature inherent to the Bayesian paradigm, is useful in countless machine learning applications. It is particularly appealing in areas where decision-making has a crucial impact, such as medical healthcare or autonomous driving. The main challenge of BNNs is the computational cost of the training procedure since Bayesian techniques often face a severe curse of dimensionality. Adaptive importance sampling (AIS) is one of the most prominent Monte Carlo methodologies benefiting from sounded convergence guarantees and ease for adaptation. This work aims to show that AIS constitutes a successful approach for designing BNNs. More precisely, we propose a novel algorithm PMCnet that includes an efficient adaptation mechanism, exploiting geometric information on the complex (often multimodal) posterior distribution. Numerical results illustrate the excellent performance and the improved exploration capabilities of the proposed method for both shallow and deep neural networks.
Automated Drug-Related Information Extraction from French Clinical Documents: ReLyfe Approach
Nov 29, 2021
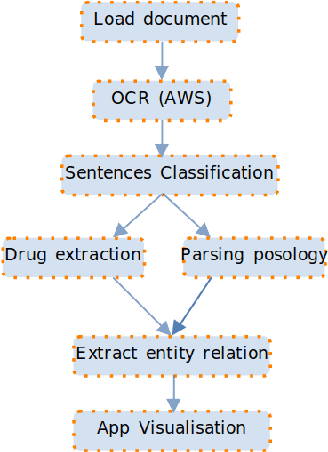


Structuring medical data in France remains a challenge mainly because of the lack of medical data due to privacy concerns and the lack of methods and approaches on processing the French language. One of these challenges is structuring drug-related information in French clinical documents. To our knowledge, over the last decade, there are less than five relevant papers that study French prescriptions. This paper proposes a new approach for extracting drug-related information from French clinical scanned documents while preserving patients' privacy. In addition, we deployed our method in a health data management platform where it is used to structure drug medical data and help patients organize their drug schedules. It can be implemented on any web or mobile platform. This work closes the gap between theoretical and practical work by creating an application adapted to real production problems. It is a combination of a rule-based phase and a Deep Learning approach. Finally, numerical results show the outperformance and relevance of the proposed methodology.
* It is published in "GLOBAL HEALTH 2021: The Tenth International Conference on Global Health Challenges" , Pages: 24 to 29, Location: Barcelona, Spain , Publication date: October 3, 2021 , URL paper: https://thinkmind.org/index.php?view=article&articleid=global_health_2021_2_30_70030
Evaluation Framework for Computer Vision-Based Guidance of the Visually Impaired
Sep 20, 2022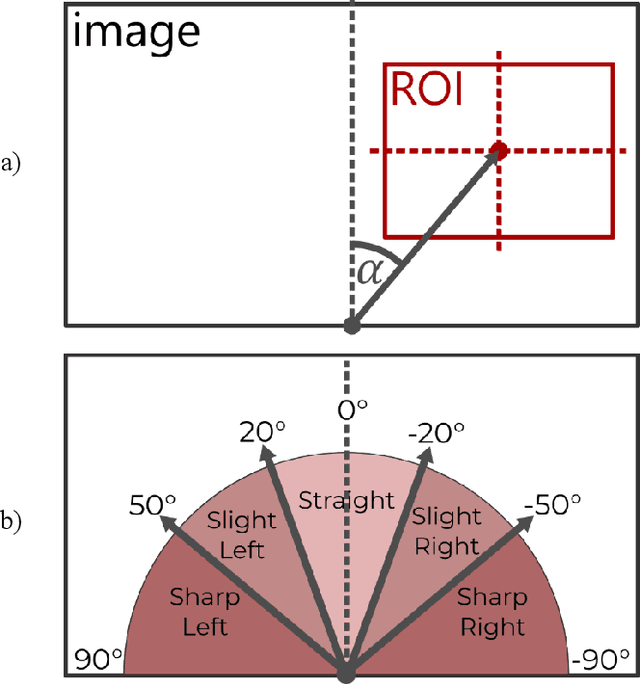
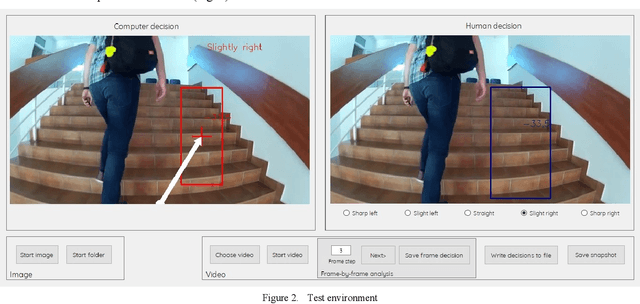
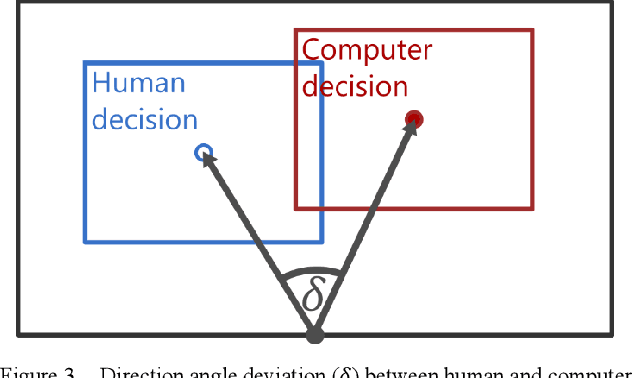
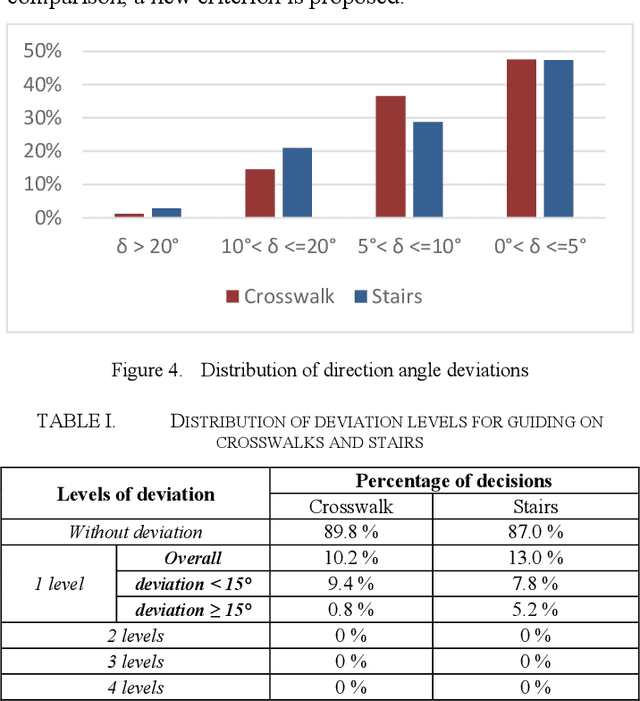
Visually impaired persons have significant problems in their everyday movement. Therefore, some of our previous work involves computer vision in developing assistance systems for guiding the visually impaired in critical situations. Some of those situations includes crosswalks on road crossings and stairs in indoor and outdoor environment. This paper presents an evaluation framework for computer vision-based guiding of the visually impaired persons in such critical situations. Presented framework includes the interface for labeling and storing referent human decisions for guiding directions and compares them to computer vision-based decisions. Since strict evaluation methodology in this research field is not clearly defined and due to the specifics of the transfer of information to visually impaired persons, evaluation criterion for specific simplified guiding instructions is proposed.
Stock Volatility Prediction using Time Series and Deep Learning Approach
Oct 05, 2022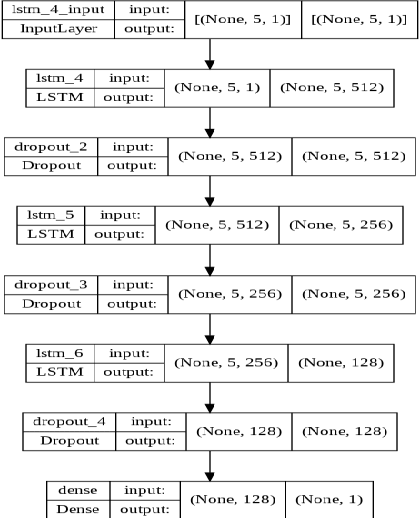
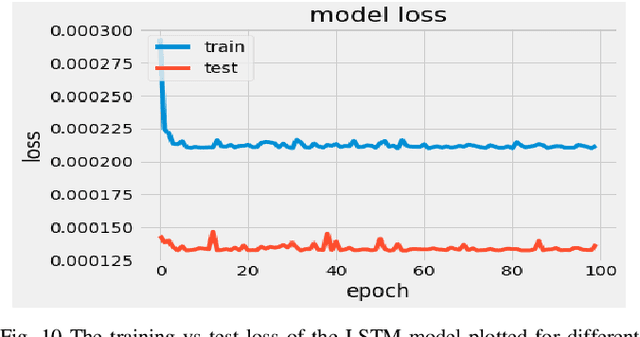
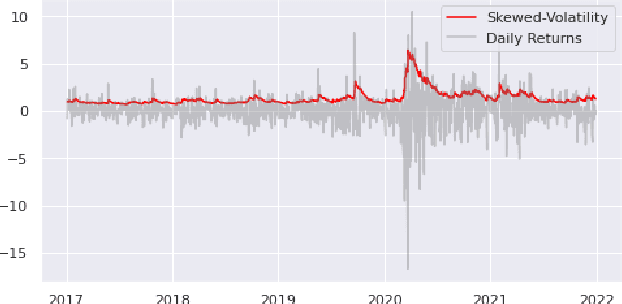
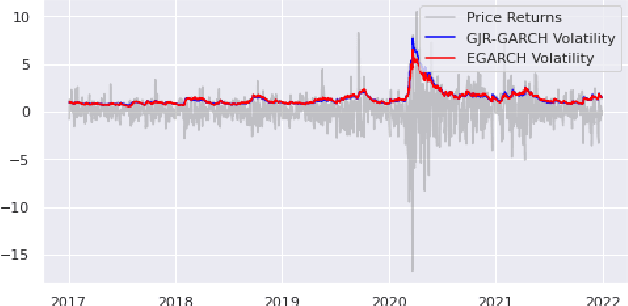
Volatility clustering is a crucial property that has a substantial impact on stock market patterns. Nonetheless, developing robust models for accurately predicting future stock price volatility is a difficult research topic. For predicting the volatility of three equities listed on India's national stock market (NSE), we propose multiple volatility models depending on the generalized autoregressive conditional heteroscedasticity (GARCH), Glosten-Jagannathan-GARCH (GJR-GARCH), Exponential general autoregressive conditional heteroskedastic (EGARCH), and LSTM framework. Sector-wise stocks have been chosen in our study. The sectors which have been considered are banking, information technology (IT), and pharma. yahoo finance has been used to obtain stock price data from Jan 2017 to Dec 2021. Among the pulled-out records, the data from Jan 2017 to Dec 2020 have been taken for training, and data from 2021 have been chosen for testing our models. The performance of predicting the volatility of stocks of three sectors has been evaluated by implementing three different types of GARCH models as well as by the LSTM model are compared. It has been observed the LSTM performed better in predicting volatility in pharma over banking and IT sectors. In tandem, it was also observed that E-GARCH performed better in the case of the banking sector and for IT and pharma, GJR-GARCH performed better.