 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Self-Supervised Pyramid Representation Learning for Multi-Label Visual Analysis and Beyond
Aug 30, 2022
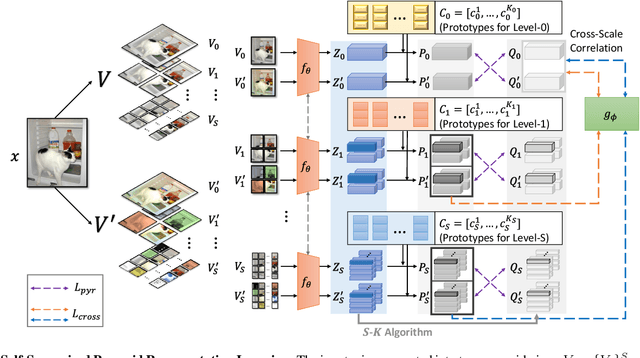
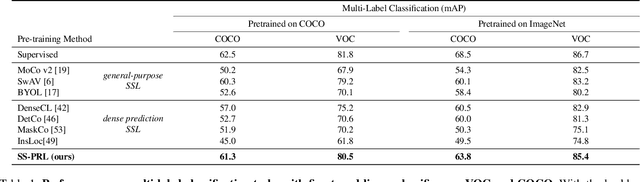
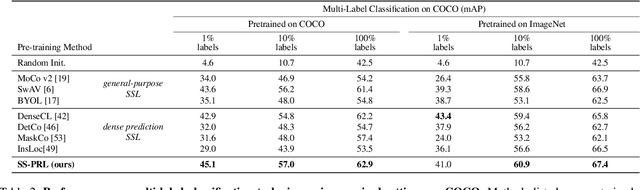
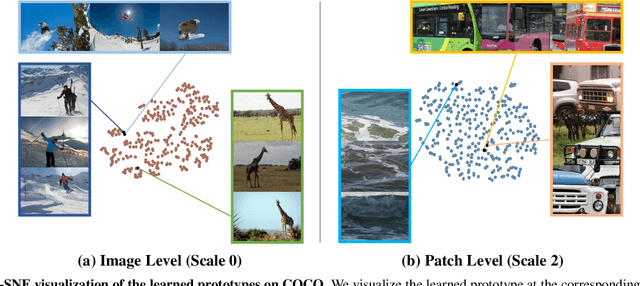
While self-supervised learning has been shown to benefit a number of vision tasks, existing techniques mainly focus on image-level manipulation, which may not generalize well to downstream tasks at patch or pixel levels. Moreover, existing SSL methods might not sufficiently describe and associate the above representations within and across image scales. In this paper, we propose a Self-Supervised Pyramid Representation Learning (SS-PRL) framework. The proposed SS-PRL is designed to derive pyramid representations at patch levels via learning proper prototypes, with additional learners to observe and relate inherent semantic information within an image. In particular, we present a cross-scale patch-level correlation learning in SS-PRL, which allows the model to aggregate and associate information learned across patch scales. We show that, with our proposed SS-PRL for model pre-training, one can easily adapt and fine-tune the models for a variety of applications including multi-label classification, object detection, and instance segmentation.
Scaling and compressing melodies using geometric similarity measures
Sep 19, 2022

Melodic similarity measurement is of key importance in music information retrieval. In this paper, we use geometric matching techniques to measure the similarity between two melodies. We represent music as sets of points or sets of horizontal line segments in the Euclidean plane and propose efficient algorithms for optimization problems inspired in two operations on melodies; linear scaling and audio compression. In the scaling problem, an incoming query melody is scaled forward until the similarity measure between the query and a reference melody is minimized. The compression problem asks for a subset of notes of a given melody such that the matching cost between the selected notes and the reference melody is minimized.
Landmark Enhanced Multimodal Graph Learning for Deepfake Video Detection
Sep 12, 2022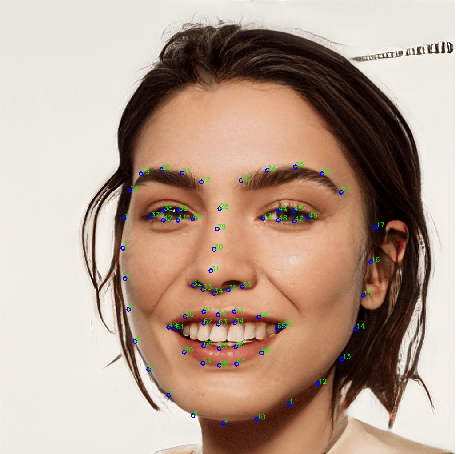
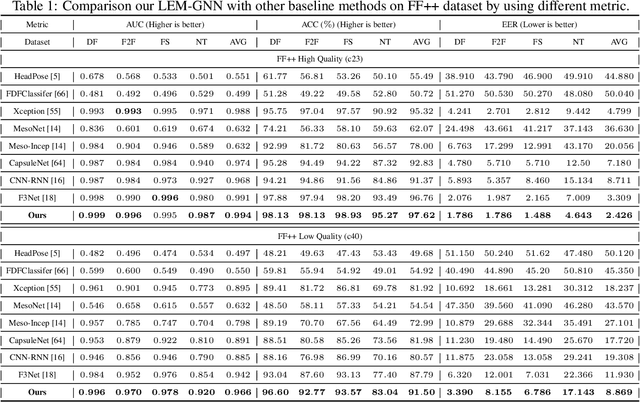
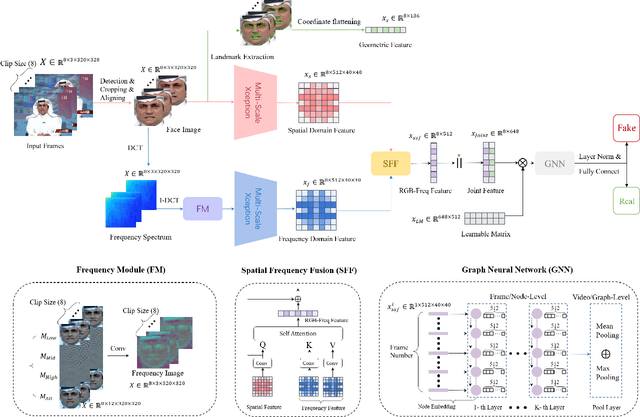
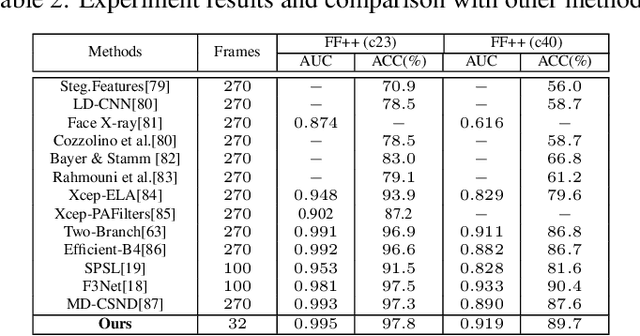
With the rapid development of face forgery technology, deepfake videos have attracted widespread attention in digital media. Perpetrators heavily utilize these videos to spread disinformation and make misleading statements. Most existing methods for deepfake detection mainly focus on texture features, which are likely to be impacted by external fluctuations, such as illumination and noise. Besides, detection methods based on facial landmarks are more robust against external variables but lack sufficient detail. Thus, how to effectively mine distinctive features in the spatial, temporal, and frequency domains and fuse them with facial landmarks for forgery video detection is still an open question. To this end, we propose a Landmark Enhanced Multimodal Graph Neural Network (LEM-GNN) based on multiple modalities' information and geometric features of facial landmarks. Specifically, at the frame level, we have designed a fusion mechanism to mine a joint representation of the spatial and frequency domain elements while introducing geometric facial features to enhance the robustness of the model. At the video level, we first regard each frame in a video as a node in a graph and encode temporal information into the edges of the graph. Then, by applying the message passing mechanism of the graph neural network (GNN), the multimodal feature will be effectively combined to obtain a comprehensive representation of the video forgery. Extensive experiments show that our method consistently outperforms the state-of-the-art (SOTA) on widely-used benchmarks.
Dual Representation Learning for One-Step Clustering of Multi-View Data
Aug 30, 2022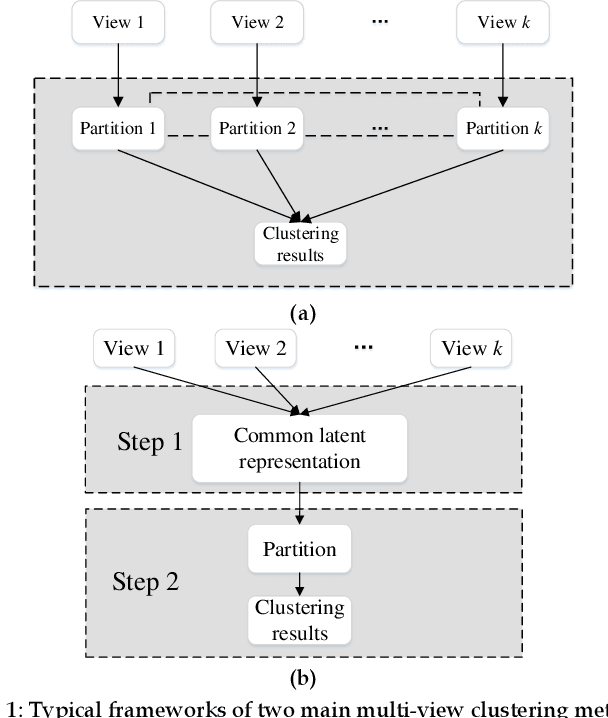
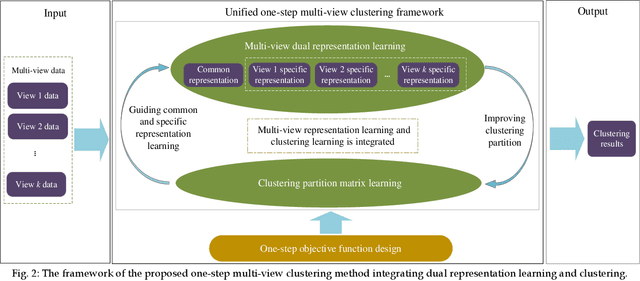
Multi-view data are commonly encountered in data mining applications. Effective extraction of information from multi-view data requires specific design of clustering methods to cater for data with multiple views, which is non-trivial and challenging. In this paper, we propose a novel one-step multi-view clustering method by exploiting the dual representation of both the common and specific information of different views. The motivation originates from the rationale that multi-view data contain not only the consistent knowledge between views but also the unique knowledge of each view. Meanwhile, to make the representation learning more specific to the clustering task, a one-step learning framework is proposed to integrate representation learning and clustering partition as a whole. With this framework, the representation learning and clustering partition mutually benefit each other, which effectively improve the clustering performance. Results from extensive experiments conducted on benchmark multi-view datasets clearly demonstrate the superiority of the proposed method.
Unsupervised domain adaptation for speech recognition with unsupervised error correction
Sep 24, 2022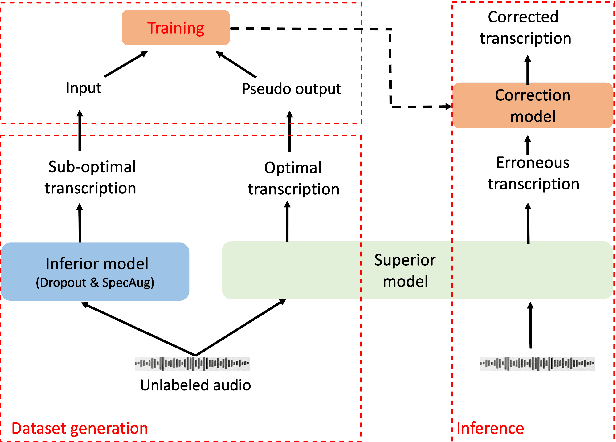
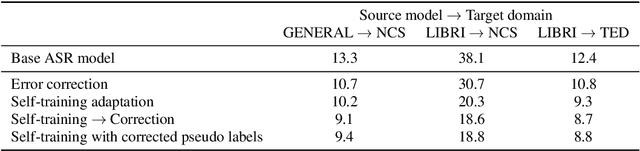
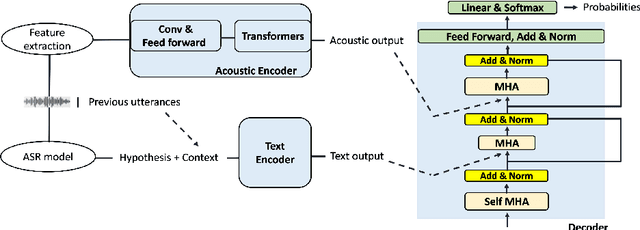

The transcription quality of automatic speech recognition (ASR) systems degrades significantly when transcribing audios coming from unseen domains. We propose an unsupervised error correction method for unsupervised ASR domain adaption, aiming to recover transcription errors caused by domain mismatch. Unlike existing correction methods that rely on transcribed audios for training, our approach requires only unlabeled data of the target domains in which a pseudo-labeling technique is applied to generate correction training samples. To reduce over-fitting to the pseudo data, we also propose an encoder-decoder correction model that can take into account additional information such as dialogue context and acoustic features. Experiment results show that our method obtains a significant word error rate (WER) reduction over non-adapted ASR systems. The correction model can also be applied on top of other adaptation approaches to bring an additional improvement of 10% relatively.
Optimal Power Allocation for Integrated Visible Light Positioning and Communication System with a Single LED-Lamp
Aug 30, 2022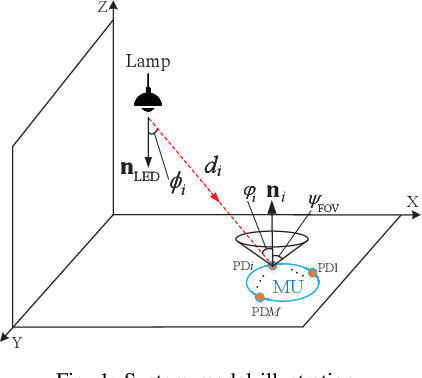
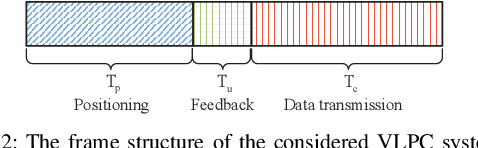
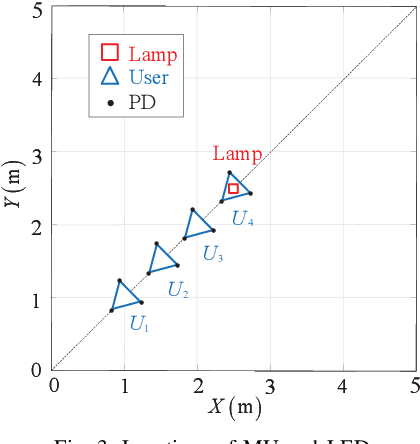
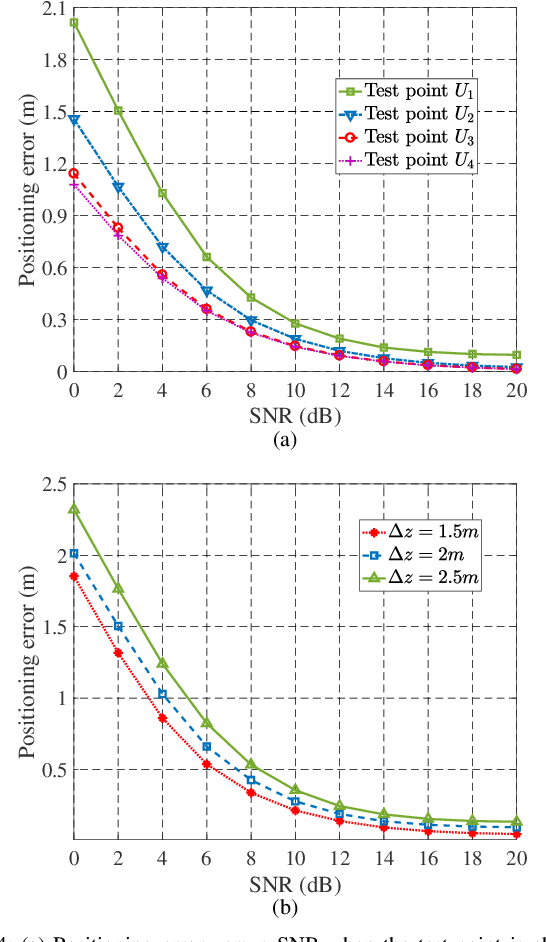
In this paper, we investigate an integrated visible light positioning and communication (VLPC) system with a single LED-lamp. First, by leveraging the fact that the VLC channel model is a function of the receiver's location, we propose a system model that estimates the channel state information (CSI) based on the positioning information without transmitting pilot sequences. Second, we derive the Cramer-Rao lower bound (CRLB) on the positioning error variance and a lower bound on the achievable rate with on-off keying modulation. Third, based on the derived performance metrics, we optimize the power allocation to minimize the CRLB, while satisfying the rate outage probability constraint. To tackle this non-convex optimization problem, we apply the worst-case distribution of the Conditional Value-at-Risk (CVaR) and the block coordinate descent (BCD) methods to obtain the feasible solutions. Finally, the effects of critical system parameters, such as outage probability, rate threshold, total power threshold, are revealed by numerical results.
Data Augmentation-free Unsupervised Learning for 3D Point Cloud Understanding
Oct 06, 2022

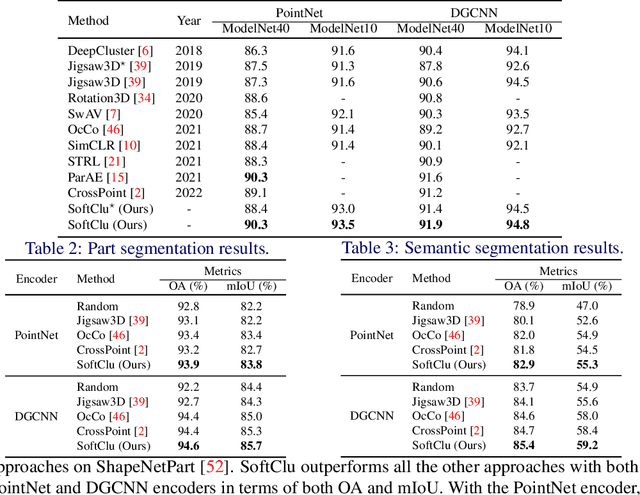
Unsupervised learning on 3D point clouds has undergone a rapid evolution, especially thanks to data augmentation-based contrastive methods. However, data augmentation is not ideal as it requires a careful selection of the type of augmentations to perform, which in turn can affect the geometric and semantic information learned by the network during self-training. To overcome this issue, we propose an augmentation-free unsupervised approach for point clouds to learn transferable point-level features via soft clustering, named SoftClu. SoftClu assumes that the points belonging to a cluster should be close to each other in both geometric and feature spaces. This differs from typical contrastive learning, which builds similar representations for a whole point cloud and its augmented versions. We exploit the affiliation of points to their clusters as a proxy to enable self-training through a pseudo-label prediction task. Under the constraint that these pseudo-labels induce the equipartition of the point cloud, we cast SoftClu as an optimal transport problem. We formulate an unsupervised loss to minimize the standard cross-entropy between pseudo-labels and predicted labels. Experiments on downstream applications, such as 3D object classification, part segmentation, and semantic segmentation, show the effectiveness of our framework in outperforming state-of-the-art techniques.
Video Referring Expression Comprehension via Transformer with Content-aware Query
Oct 06, 2022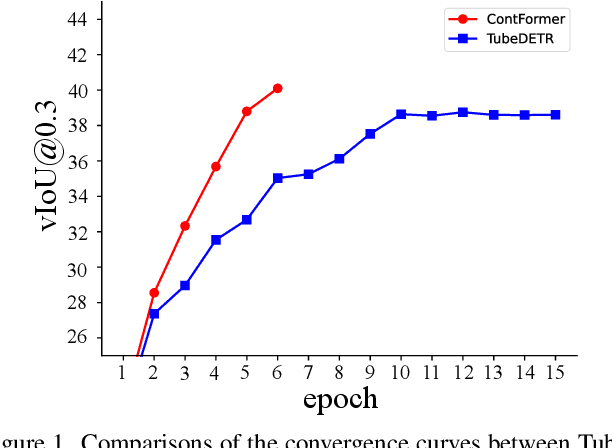
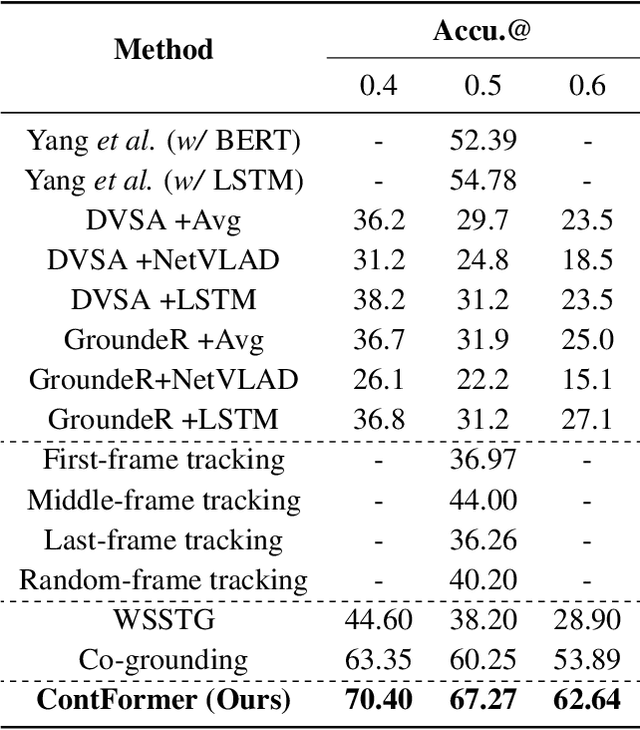

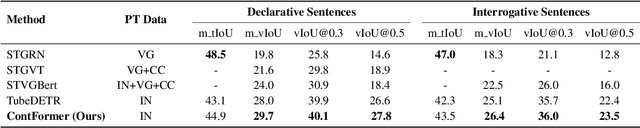
Video Referring Expression Comprehension (REC) aims to localize a target object in video frames referred by the natural language expression. Recently, the Transformerbased methods have greatly boosted the performance limit. However, we argue that the current query design is suboptima and suffers from two drawbacks: 1) the slow training convergence process; 2) the lack of fine-grained alignment. To alleviate this, we aim to couple the pure learnable queries with the content information. Specifically, we set up a fixed number of learnable bounding boxes across the frame and the aligned region features are employed to provide fruitful clues. Besides, we explicitly link certain phrases in the sentence to the semantically relevant visual areas. To this end, we introduce two new datasets (i.e., VID-Entity and VidSTG-Entity) by augmenting the VIDSentence and VidSTG datasets with the explicitly referred words in the whole sentence, respectively. Benefiting from this, we conduct the fine-grained cross-modal alignment at the region-phrase level, which ensures more detailed feature representations. Incorporating these two designs, our proposed model (dubbed as ContFormer) achieves the state-of-the-art performance on widely benchmarked datasets. For example on VID-Entity dataset, compared to the previous SOTA, ContFormer achieves 8.75% absolute improvement on Accu.@0.6.
Cyber-Resilient Privacy Preservation and Secure Billing Approach for Smart Energy Metering Devices
Oct 06, 2022
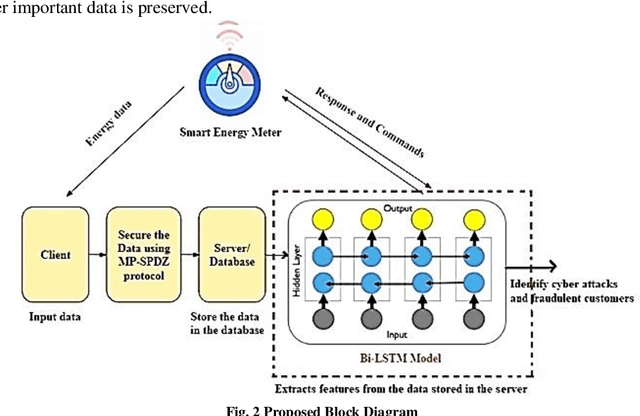
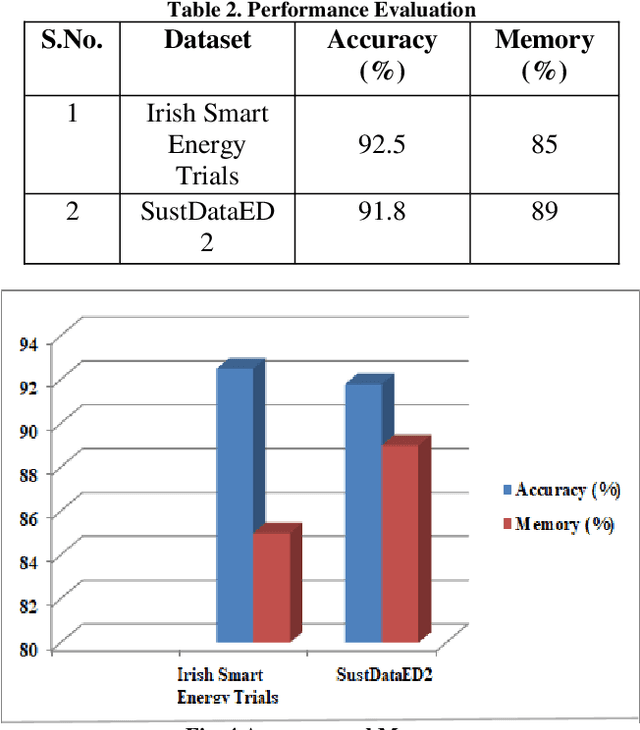
Most of the smart applications, such as smart energy metering devices, demand strong privacy preservation to strengthen data privacy. However, it is difficult to protect the privacy of the smart device data, especially on the client side. It is mainly because payment for billing is computed by the server deployed at the client's side, and it is highly challenging to prevent the leakage of client's information to unauthorised users. Various researchers have discussed this problem and have proposed different privacy preservation techniques. Conventional techniques suffer from the problem of high computational and communication overload on the client side. In addition, the performance of these techniques deteriorates due to computational complexity and their inability to handle the security of large-scale data. Due to these limitations, it becomes easy for the attackers to introduce malicious attacks on the server, posing a significant threat to data security. In this context, this proposal intends to design novel privacy preservation and secure billing framework using deep learning techniques to ensure data security in smart energy metering devices. This research aims to overcome the limitations of the existing techniques to achieve robust privacy preservation in smart devices and increase the cyber resilience of these devices.
* Journal article
FloatingFusion: Depth from ToF and Image-stabilized Stereo Cameras
Oct 06, 2022High-accuracy per-pixel depth is vital for computational photography, so smartphones now have multimodal camera systems with time-of-flight (ToF) depth sensors and multiple color cameras. However, producing accurate high-resolution depth is still challenging due to the low resolution and limited active illumination power of ToF sensors. Fusing RGB stereo and ToF information is a promising direction to overcome these issues, but a key problem remains: to provide high-quality 2D RGB images, the main color sensor's lens is optically stabilized, resulting in an unknown pose for the floating lens that breaks the geometric relationships between the multimodal image sensors. Leveraging ToF depth estimates and a wide-angle RGB camera, we design an automatic calibration technique based on dense 2D/3D matching that can estimate camera extrinsic, intrinsic, and distortion parameters of a stabilized main RGB sensor from a single snapshot. This lets us fuse stereo and ToF cues via a correlation volume. For fusion, we apply deep learning via a real-world training dataset with depth supervision estimated by a neural reconstruction method. For evaluation, we acquire a test dataset using a commercial high-power depth camera and show that our approach achieves higher accuracy than existing baselines.