 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
ConvTransSeg: A Multi-resolution Convolution-Transformer Network for Medical Image Segmentation
Oct 13, 2022
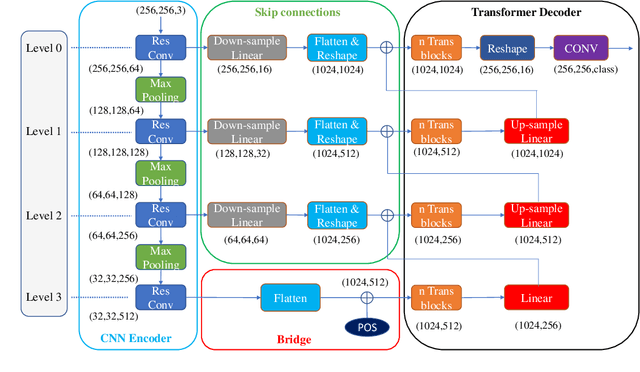
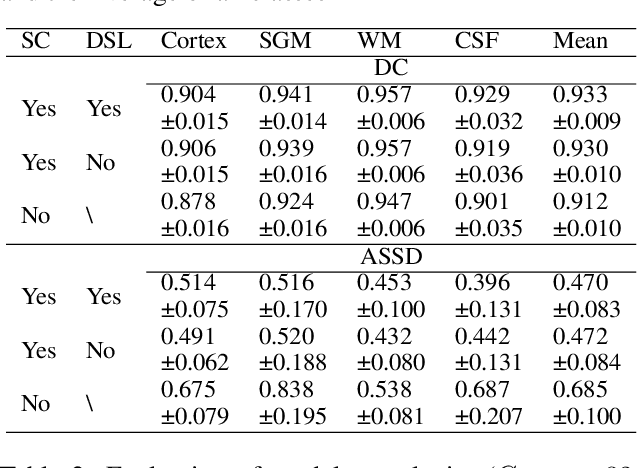
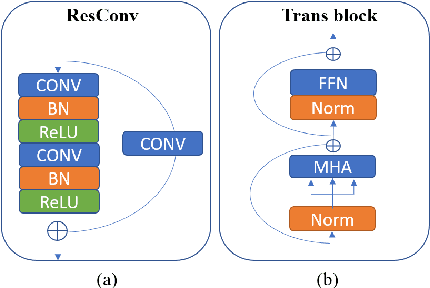
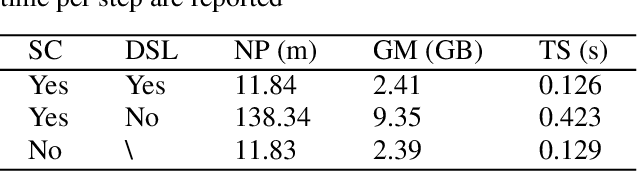
Convolutional neural networks (CNNs) achieved the state-of-the-art performance in medical image segmentation due to their ability to extract highly complex feature representations. However, it is argued in recent studies that traditional CNNs lack the intelligence to capture long-term dependencies of different image regions. Following the success of applying Transformer models on natural language processing tasks, the medical image segmentation field has also witnessed growing interest in utilizing Transformers, due to their ability to capture long-range contextual information. However, unlike CNNs, Transformers lack the ability to learn local feature representations. Thus, to fully utilize the advantages of both CNNs and Transformers, we propose a hybrid encoder-decoder segmentation model (ConvTransSeg). It consists of a multi-layer CNN as the encoder for feature learning and the corresponding multi-level Transformer as the decoder for segmentation prediction. The encoder and decoder are interconnected in a multi-resolution manner. We compared our method with many other state-of-the-art hybrid CNN and Transformer segmentation models on binary and multiple class image segmentation tasks using several public medical image datasets, including skin lesion, polyp, cell and brain tissue. The experimental results show that our method achieves overall the best performance in terms of Dice coefficient and average symmetric surface distance measures with low model complexity and memory consumption. In contrast to most Transformer-based methods that we compared, our method does not require the use of pre-trained models to achieve similar or better performance. The code is freely available for research purposes on Github: (the link will be added upon acceptance).
C-Mixup: Improving Generalization in Regression
Oct 11, 2022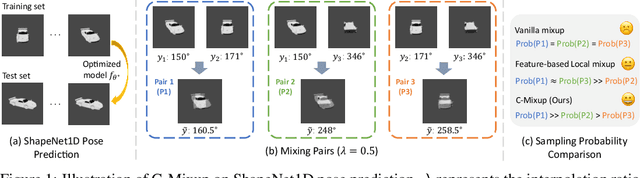

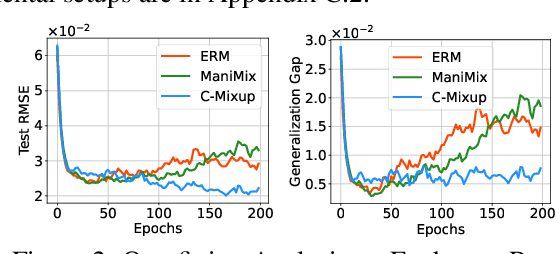
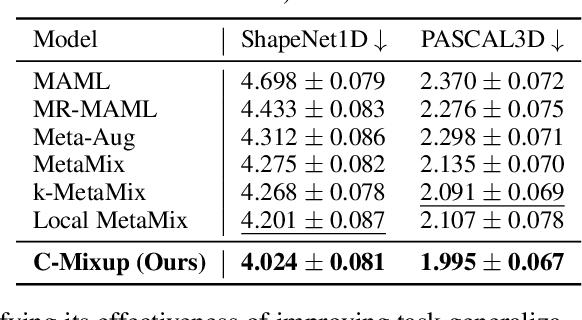
Improving the generalization of deep networks is an important open challenge, particularly in domains without plentiful data. The mixup algorithm improves generalization by linearly interpolating a pair of examples and their corresponding labels. These interpolated examples augment the original training set. Mixup has shown promising results in various classification tasks, but systematic analysis of mixup in regression remains underexplored. Using mixup directly on regression labels can result in arbitrarily incorrect labels. In this paper, we propose a simple yet powerful algorithm, C-Mixup, to improve generalization on regression tasks. In contrast with vanilla mixup, which picks training examples for mixing with uniform probability, C-Mixup adjusts the sampling probability based on the similarity of the labels. Our theoretical analysis confirms that C-Mixup with label similarity obtains a smaller mean square error in supervised regression and meta-regression than vanilla mixup and using feature similarity. Another benefit of C-Mixup is that it can improve out-of-distribution robustness, where the test distribution is different from the training distribution. By selectively interpolating examples with similar labels, it mitigates the effects of domain-associated information and yields domain-invariant representations. We evaluate C-Mixup on eleven datasets, ranging from tabular to video data. Compared to the best prior approach, C-Mixup achieves 6.56%, 4.76%, 5.82% improvements in in-distribution generalization, task generalization, and out-of-distribution robustness, respectively. Code is released at https://github.com/huaxiuyao/C-Mixup.
Neighbourhood Representative Sampling for Efficient End-to-end Video Quality Assessment
Oct 11, 2022
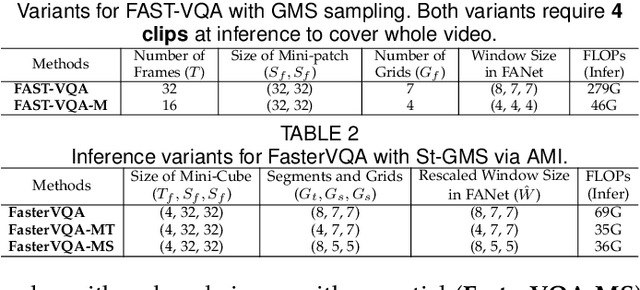
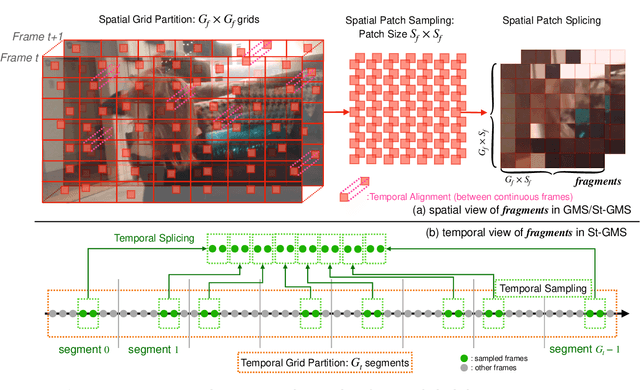
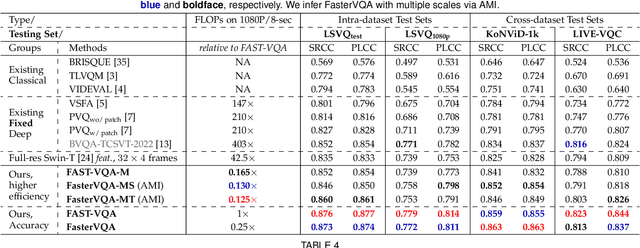
The increased resolution of real-world videos presents a dilemma between efficiency and accuracy for deep Video Quality Assessment (VQA). On the one hand, keeping the original resolution will lead to unacceptable computational costs. On the other hand, existing practices, such as resizing and cropping, will change the quality of original videos due to the loss of details and contents, and are therefore harmful to quality assessment. With the obtained insight from the study of spatial-temporal redundancy in the human visual system and visual coding theory, we observe that quality information around a neighbourhood is typically similar, motivating us to investigate an effective quality-sensitive neighbourhood representatives scheme for VQA. In this work, we propose a unified scheme, spatial-temporal grid mini-cube sampling (St-GMS) to get a novel type of sample, named fragments. Full-resolution videos are first divided into mini-cubes with preset spatial-temporal grids, then the temporal-aligned quality representatives are sampled to compose the fragments that serve as inputs for VQA. In addition, we design the Fragment Attention Network (FANet), a network architecture tailored specifically for fragments. With fragments and FANet, the proposed efficient end-to-end FAST-VQA and FasterVQA achieve significantly better performance than existing approaches on all VQA benchmarks while requiring only 1/1612 FLOPs compared to the current state-of-the-art. Codes, models and demos are available at https://github.com/timothyhtimothy/FAST-VQA-and-FasterVQA.
Graph Anomaly Detection with Graph Neural Networks: Current Status and Challenges
Oct 04, 2022
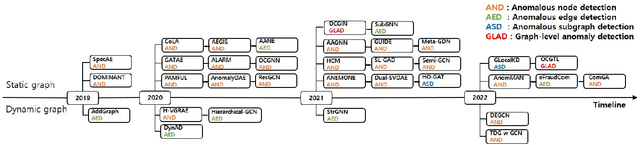
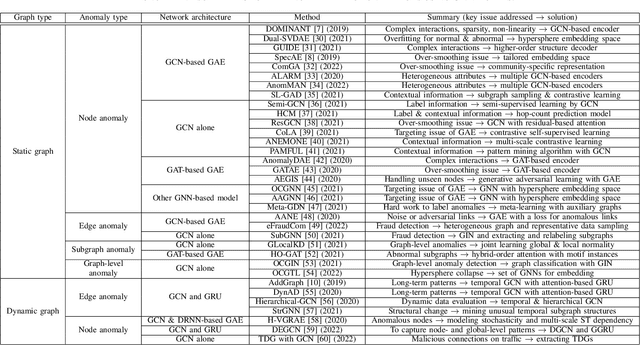
Graphs are used widely to model complex systems, and detecting anomalies in a graph is an important task in the analysis of complex systems. Graph anomalies are patterns in a graph that do not conform to normal patterns expected of the attributes and/or structures of the graph. In recent years, graph neural networks (GNNs) have been studied extensively and have successfully performed difficult machine learning tasks in node classification, link prediction, and graph classification thanks to the highly expressive capability via message passing in effectively learning graph representations. To solve the graph anomaly detection problem, GNN-based methods leverage information about the graph attributes (or features) and/or structures to learn to score anomalies appropriately. In this survey, we review the recent advances made in detecting graph anomalies using GNN models. Specifically, we summarize GNN-based methods according to the graph type (i.e., static and dynamic), the anomaly type (i.e., node, edge, subgraph, and whole graph), and the network architecture (e.g., graph autoencoder, graph convolutional network). To the best of our knowledge, this survey is the first comprehensive review of graph anomaly detection methods based on GNNs.
Improving Sample Quality of Diffusion Models Using Self-Attention Guidance
Oct 04, 2022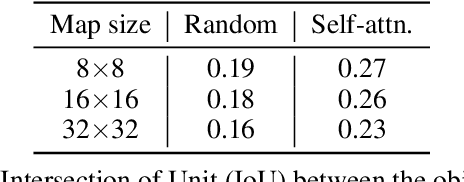
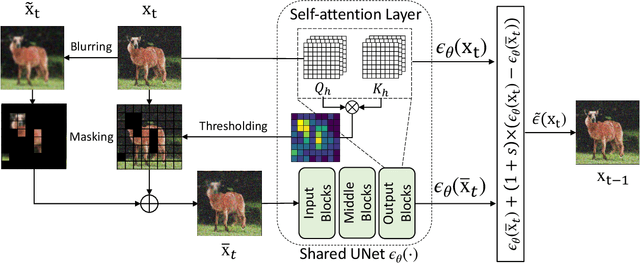
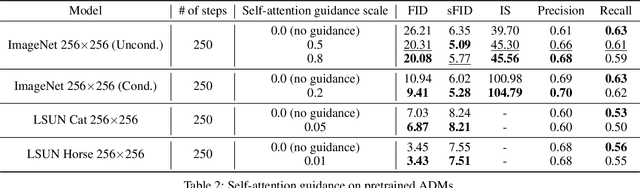

Following generative adversarial networks (GANs), a de facto standard model for image generation, denoising diffusion models (DDMs) have been actively researched and attracted strong attention due to their capability to generate images with high quality and diversity. However, the way the internal self-attention mechanism works inside the UNet of DDMs is under-explored. To unveil them, in this paper, we first investigate the self-attention operations within the black-boxed diffusion models and build hypotheses. Next, we verify the hypotheses about the self-attention map by conducting frequency analysis and testing the relationships with the generated objects. In consequence, we find out that the attention map is closely related to the quality of generated images. On the other hand, diffusion guidance methods based on additional information such as labels are proposed to improve the quality of generated images. Inspired by these methods, we present label-free guidance based on the intermediate self-attention map that can guide existing pretrained diffusion models to generate images with higher fidelity. In addition to the enhanced sample quality when used alone, we show that the results are further improved by combining our method with classifier guidance on ImageNet 128x128.
Transformer-based Subject Entity Detection in Wikipedia Listings
Oct 04, 2022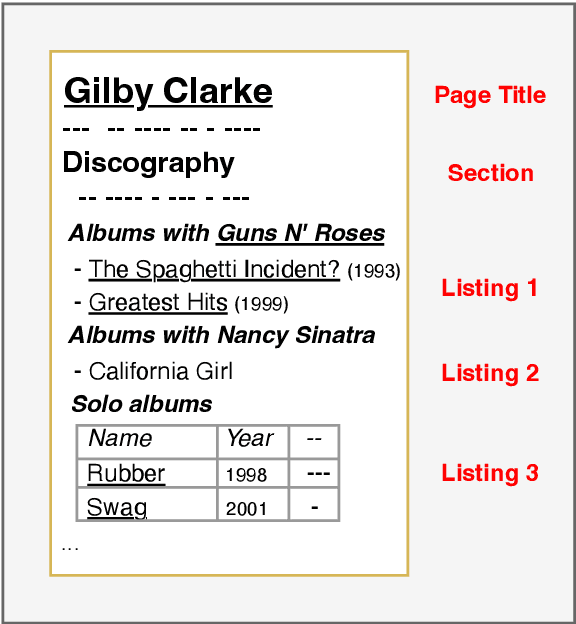
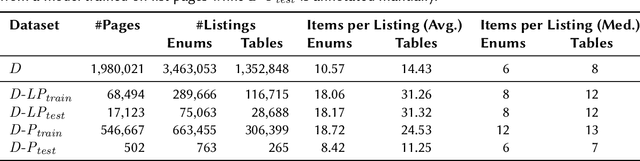
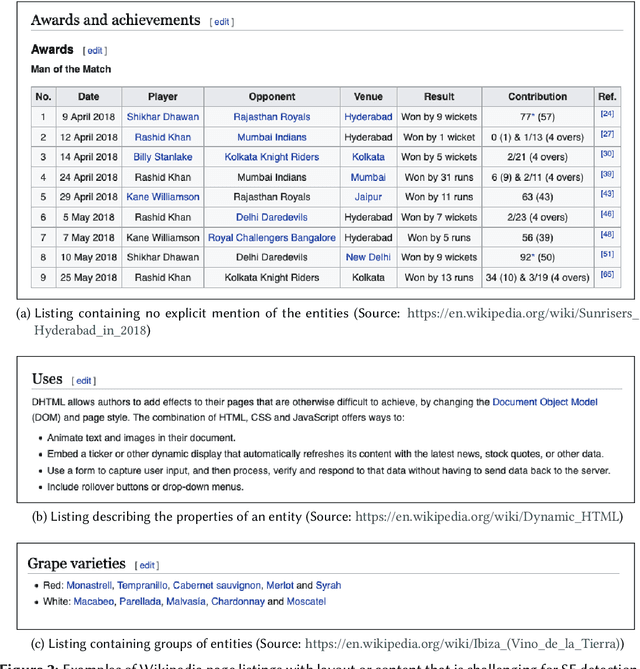
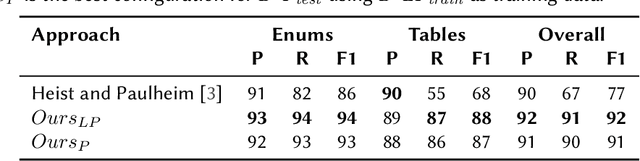
In tasks like question answering or text summarisation, it is essential to have background knowledge about the relevant entities. The information about entities - in particular, about long-tail or emerging entities - in publicly available knowledge graphs like DBpedia or CaLiGraph is far from complete. In this paper, we present an approach that exploits the semi-structured nature of listings (like enumerations and tables) to identify the main entities of the listing items (i.e., of entries and rows). These entities, which we call subject entities, can be used to increase the coverage of knowledge graphs. Our approach uses a transformer network to identify subject entities at the token-level and surpasses an existing approach in terms of performance while being bound by fewer limitations. Due to a flexible input format, it is applicable to any kind of listing and is, unlike prior work, not dependent on entity boundaries as input. We demonstrate our approach by applying it to the complete Wikipedia corpus and extracting 40 million mentions of subject entities with an estimated precision of 71% and recall of 77%. The results are incorporated in the most recent version of CaLiGraph.
Nuisances via Negativa: Adjusting for Spurious Correlations via Data Augmentation
Oct 04, 2022



There exist features that are related to the label in the same way across different settings for that task; these are semantic features or semantics. Features with varying relationships to the label are nuisances. For example, in detecting cows from natural images, the shape of the head is a semantic and because images of cows often have grass backgrounds but only in certain settings, the background is a nuisance. Relationships between a nuisance and the label are unstable across settings and, consequently, models that exploit nuisance-label relationships face performance degradation when these relationships change. Direct knowledge of a nuisance helps build models that are robust to such changes, but knowledge of a nuisance requires extra annotations beyond the label and the covariates. In this paper, we develop an alternative way to produce robust models by data augmentation. These data augmentations corrupt semantic information to produce models that identify and adjust for where nuisances drive predictions. We study semantic corruptions in powering different robust-modeling methods for multiple out-of distribution (OOD) tasks like classifying waterbirds, natural language inference, and detecting Cardiomegaly in chest X-rays.
On semi shift invariant graph filters
Sep 28, 2022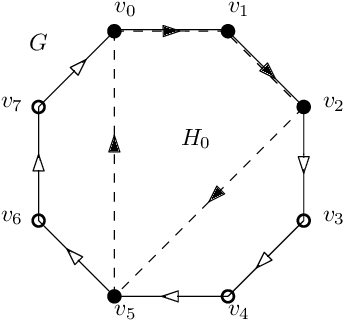
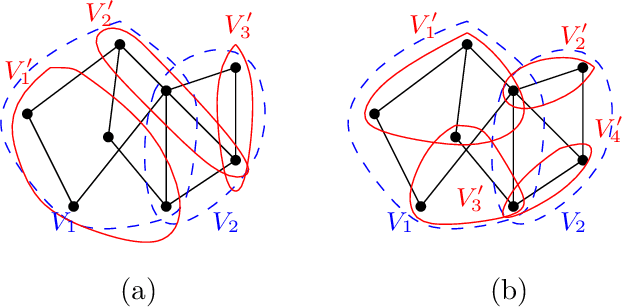
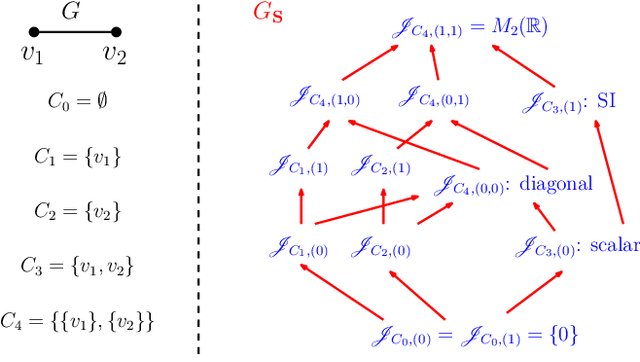
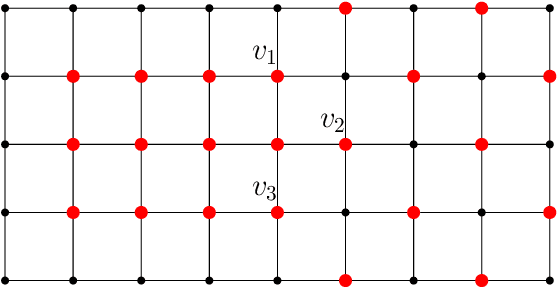
In graph signal processing, one of the most important subjects is the study of filters, i.e., linear transformations that capture relations between graph signals. One of the most important families of filters is the space of shift invariant filters, defined as transformations commute with a preferred graph shift operator. Shift invariant filters have a wide range of applications in graph signal processing and graph neural networks. A shift invariant filter can be interpreted geometrically as an information aggregation procedure (from local neighborhood), and can be computed easily using matrix multiplication. However, there are still drawbacks to using solely shift invariant filters in applications, such as being restrictively homogeneous. In this paper, we generalize shift invariant filters by introducing and studying semi shift invariant filters. We give an application of semi shift invariant filters with a new signal processing framework, the subgraph signal processing. Moreover, we also demonstrate how semi shift invariant filters can be used in graph neural networks.
Research on restaurant recommendation using machine learning
Aug 10, 2022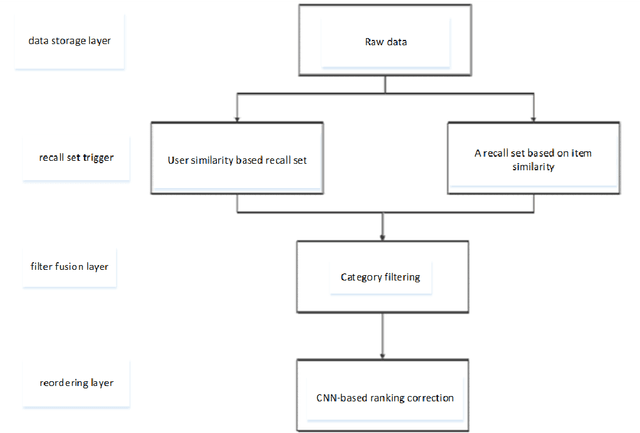



A recommender system is a system that helps users filter irrelevant information and create user interest models based on their historical records. With the continuous development of Internet information, recommendation systems have received widespread attention in the industry. In this era of ubiquitous data and information, how to obtain and analyze these data has become the research topic of many people. In view of this situation, this paper makes some brief overviews of machine learning-related recommendation systems. By analyzing some technologies and ideas used by machine learning in recommender systems, let more people understand what is Big data and what is machine learning. The most important point is to let everyone understand the profound impact of machine learning on our daily life.
Counter-Adversarial Learning with Inverse Unscented Kalman Filter
Oct 01, 2022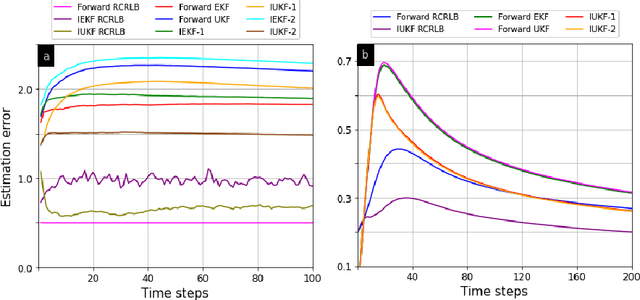
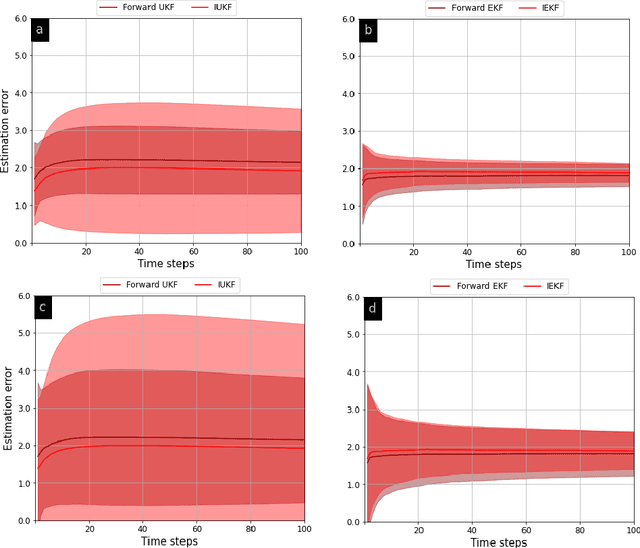
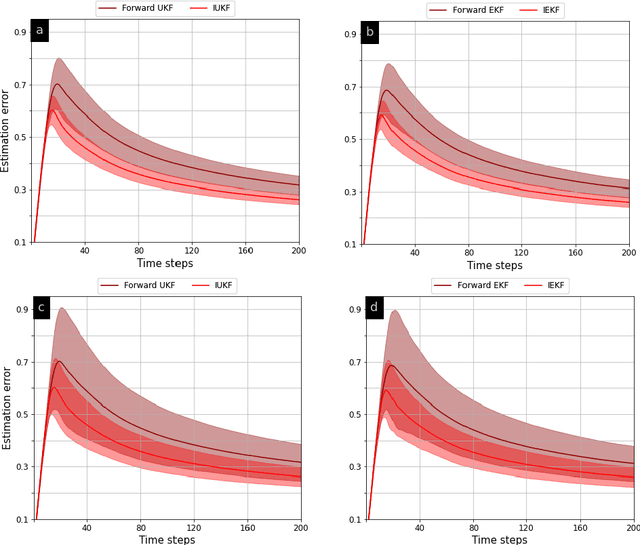
In order to infer the strategy of an intelligent attacker, it is desired for the defender to cognitively sense the attacker's state. In this context, we aim to learn the information that an adversary has gathered about us from a Bayesian perspective. Prior works employ linear Gaussian state-space models and solve this inverse cognition problem through the design of inverse stochastic filters. In practice, these counter-adversarial settings are highly nonlinear systems. We address this by formulating the inverse cognition as a nonlinear Gaussian state-space model, wherein the adversary employs an unscented Kalman filter (UKF) to estimate our state with reduced linearization errors. To estimate the adversary's estimate of us, we propose and develop an inverse UKF (IUKF), wherein the system model is known to both the adversary and the defender. We also derive the conditions for the stochastic stability of IUKF in the mean-squared boundedness sense. Numerical experiments for multiple practical system models show that the estimation error of IUKF converges and closely follows the recursive Cram\'{e}r-Rao lower bound.