 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Model-Based Approach for Improving Reinforcement Learning Efficiency Leveraging Expert Observations
Feb 29, 2024
This paper investigates how to incorporate expert observations (without explicit information on expert actions) into a deep reinforcement learning setting to improve sample efficiency. First, we formulate an augmented policy loss combining a maximum entropy reinforcement learning objective with a behavioral cloning loss that leverages a forward dynamics model. Then, we propose an algorithm that automatically adjusts the weights of each component in the augmented loss function. Experiments on a variety of continuous control tasks demonstrate that the proposed algorithm outperforms various benchmarks by effectively utilizing available expert observations.
Investigating Gender Fairness in Machine Learning-driven Personalized Care for Chronic Pain
Feb 29, 2024This study investigates gender fairness in personalized pain care recommendations using machine learning algorithms. Leveraging a contextual bandits framework, personalized recommendations are formulated and evaluated using LinUCB algorithm on a dataset comprising interactions with $164$ patients across $10$ sessions each. Results indicate that while adjustments to algorithm parameters influence the quality of pain care recommendations, this impact remains consistent across genders. However, when certain patient information, such as self-reported pain measurements, is absent, the quality of pain care recommendations for women is notably inferior to that for men.
RORA: Robust Free-Text Rationale Evaluation
Feb 28, 2024Free-text rationales play a pivotal role in explainable NLP, bridging the knowledge and reasoning gaps behind a model's decision-making. However, due to the diversity of potential reasoning paths and a corresponding lack of definitive ground truth, their evaluation remains a challenge. Existing evaluation metrics rely on the degree to which a rationale supports a target label, but we find these fall short in evaluating rationales that inadvertently leak the labels. To address this problem, we propose RORA, a Robust free-text Rationale evaluation against label leakage. RORA quantifies the new information supplied by a rationale to justify the label. This is achieved by assessing the conditional V-information \citep{hewitt-etal-2021-conditional} with a predictive family robust against leaky features that can be exploited by a small model. RORA consistently outperforms existing approaches in evaluating human-written, synthetic, or model-generated rationales, particularly demonstrating robustness against label leakage. We also show that RORA aligns well with human judgment, providing a more reliable and accurate measurement across diverse free-text rationales.
A Self-matching Training Method with Annotation Embedding Models for Ontology Subsumption Prediction
Feb 28, 2024Recently, ontology embeddings representing entities in a low-dimensional space have been proposed for ontology completion. However, the ontology embeddings for concept subsumption prediction do not address the difficulties of similar and isolated entities and fail to extract the global information of annotation axioms from an ontology. In this paper, we propose a self-matching training method for the two ontology embedding models: Inverted-index Matrix Embedding (InME) and Co-occurrence Matrix Embedding (CoME). The two embeddings capture the global and local information in annotation axioms by means of the occurring locations of each word in a set of axioms and the co-occurrences of words in each axiom. The self-matching training method increases the robustness of the concept subsumption prediction when predicted superclasses are similar to subclasses and are isolated to other entities in an ontology. Our evaluation experiments show that the self-matching training method with InME outperforms the existing ontology embeddings for the GO and FoodOn ontologies and that the method with the concatenation of CoME and OWL2Vec* outperforms them for the HeLiS ontology.
Lemur: Log Parsing with Entropy Sampling and Chain-of-Thought Merging
Feb 28, 2024Logs produced by extensive software systems are integral to monitoring system behaviors. Advanced log analysis facilitates the detection, alerting, and diagnosis of system faults. Log parsing, which entails transforming raw log messages into structured templates, constitutes a critical phase in the automation of log analytics. Existing log parsers fail to identify the correct templates due to reliance on human-made rules. Besides, These methods focus on statistical features while ignoring semantic information in log messages. To address these challenges, we introduce a cutting-edge \textbf{L}og parsing framework with \textbf{E}ntropy sampling and Chain-of-Thought \textbf{M}erging (Lemur). Specifically, to discard the tedious manual rules. We propose a novel sampling method inspired by information entropy, which efficiently clusters typical logs. Furthermore, to enhance the merging of log templates, we design a chain-of-thought method for large language models (LLMs). LLMs exhibit exceptional semantic comprehension, deftly distinguishing between parameters and invariant tokens. We have conducted experiments on large-scale public datasets. Extensive evaluation demonstrates that Lemur achieves the state-of-the-art performance and impressive efficiency.
Multi-Source Interactive Resilient Fusion Algorithm Based on RIEKF
Mar 02, 2024
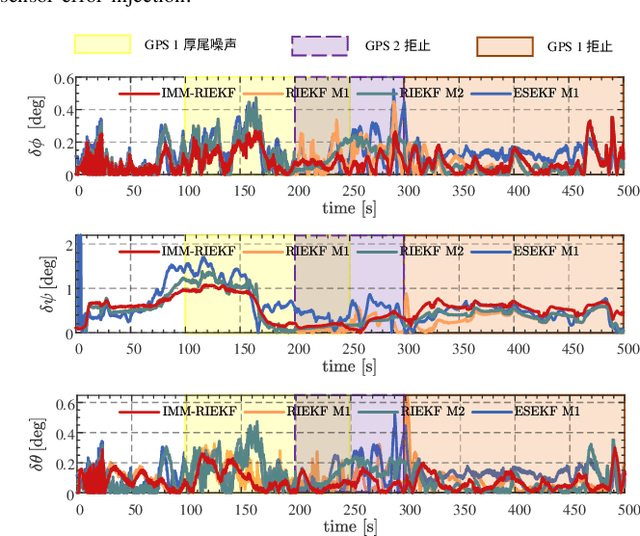
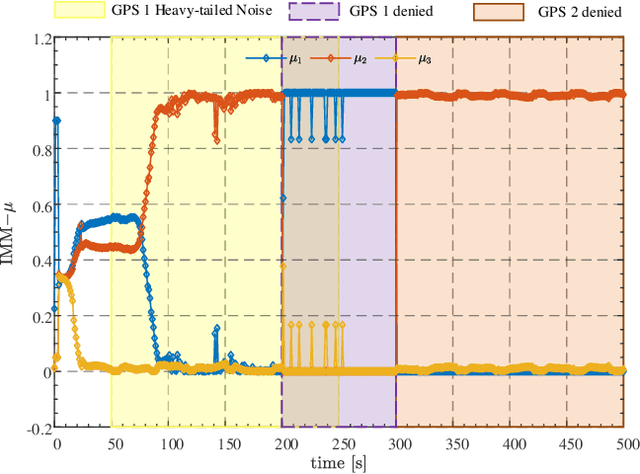
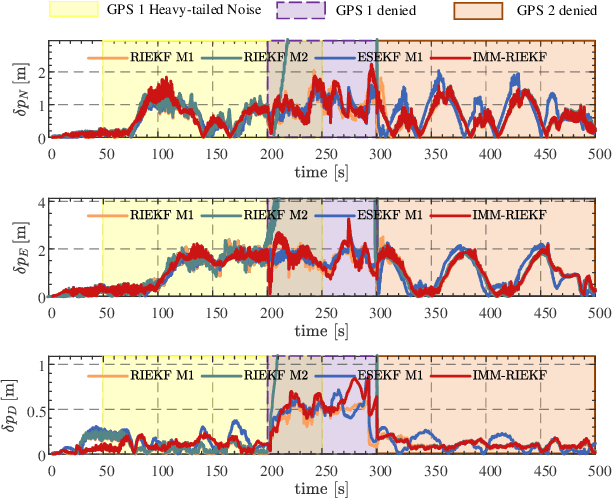
As the number of heterogeneous redundant sensors on unmanned aerial vehicle (UAV) increases, onboard sensors require a more rational and efficient credibility evaluation system and a resilient fusion framework to achieve the essence of seamless sensor group switching. A simple and efficient sensor credibility evaluation system is proposed to guide the selection of the optimal multi-source sensor submodel combination, thereby providing key model prior knowledge for multi-source resilient fusion. Furthermore, a multi-model interactive resilient fusion framework based on RIEKF is proposed, utilizing the defined sensor credibility indexes to guide the design of the model transition probability matrix, thereby reducing the sensitivity of submodel weights to fusion stability and solving the problem of the model transition matrix lacking a basis for adjustment. Model weights are updated in real time through credibility prior information and submodel posterior probabilities, thus leveraging the adaptive resilience advantage between models to achieve seamless switching between submodels in complex environments. Experimental results show that the algorithm presented in this paper, without using any sensor fault diagnosis and isolation logic, without setting any complex detection timing and thresholds, demonstrates a resilience advantage, thereby enhancing the adaptability of the state estimation system in complex environments.
An Analysis of Capacity-Distortion Trade-Offs in Memoryless ISAC Systems
Feb 26, 2024This manuscript investigates the information-theoretic limits of integrated sensing and communications (ISAC), aiming for simultaneous reliable communication and precise channel state estimation. We model such a system with a state-dependent discrete memoryless channel (SD-DMC) with present or absent channel feedback and generalized side information at the transmitter and the receiver, where the joint task of message decoding and state estimation is performed at the receiver. The relationship between the achievable communication rate and estimation error, the capacity-distortion (C-D) trade-off, is characterized across different causality levels of the side information. This framework is shown to be capable of modeling various practical scenarios by assigning the side information with different meanings, including monostatic and bistatic radar systems. The analysis is then extended to the two-user degraded broadcast channel, and we derive an achievable C-D region that is tight under certain conditions. To solve the optimization problem arising in the computation of C-D functions/regions, we propose a proximal block coordinate descent (BCD) method, prove its convergence to a stationary point, and derive a stopping criterion. Finally, several representative examples are studied to demonstrate the versatility of our framework and the effectiveness of the proposed algorithm.
Limits to classification performance by relating Kullback-Leibler divergence to Cohen's Kappa
Mar 03, 2024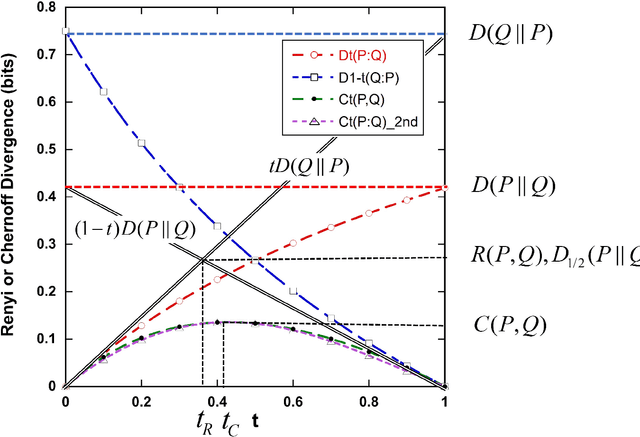
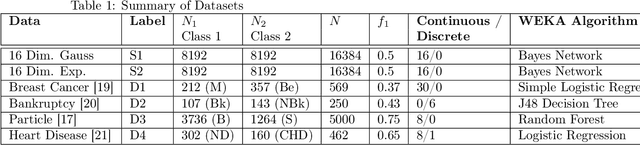
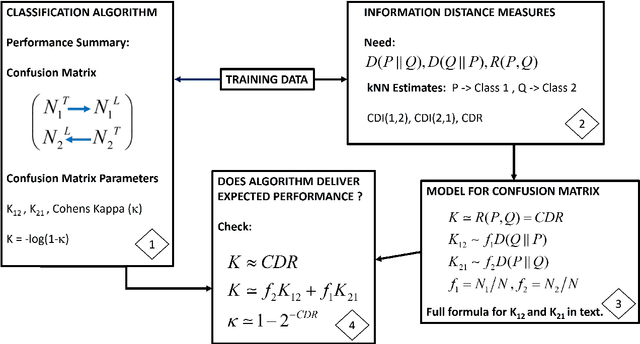

The performance of machine learning classification algorithms are evaluated by estimating metrics, often from the confusion matrix, using training data and cross-validation. However, these do not prove that the best possible performance has been achieved. Fundamental limits to error rates can be estimated using information distance measures. To this end, the confusion matrix has been formulated to comply with the Chernoff-Stein Lemma. This links the error rates to the Kullback-Leibler divergences between the probability density functions describing the two classes. This leads to a key result that relates Cohen's Kappa to the Resistor Average Distance which is the parallel resistor combination of the two Kullback-Leibler divergences. The Resistor Average Distance has units of bits and is estimated from the same training data used by the classification algorithm, using kNN estimates of the KullBack-Leibler divergences. The classification algorithm gives the confusion matrix and Kappa. Theory and methods are discussed in detail and then applied to Monte Carlo data and real datasets. Four very different real datasets - Breast Cancer, Coronary Heart Disease, Bankruptcy, and Particle Identification - are analysed, with both continuous and discrete values, and their classification performance compared to the expected theoretical limit. In all cases this analysis shows that the algorithms could not have performed any better due to the underlying probability density functions for the two classes. Important lessons are learnt on how to predict the performance of algorithms for imbalanced data using training datasets that are approximately balanced. Machine learning is very powerful but classification performance ultimately depends on the quality of the data and the relevance of the variables to the problem.
Enhancing Data Provenance and Model Transparency in Federated Learning Systems -- A Database Approach
Mar 03, 2024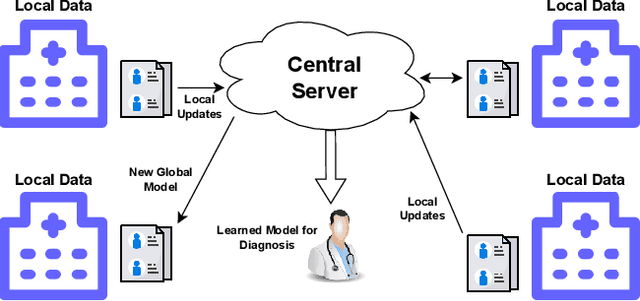
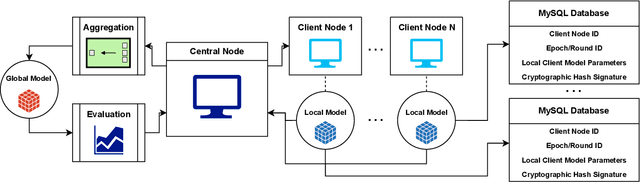
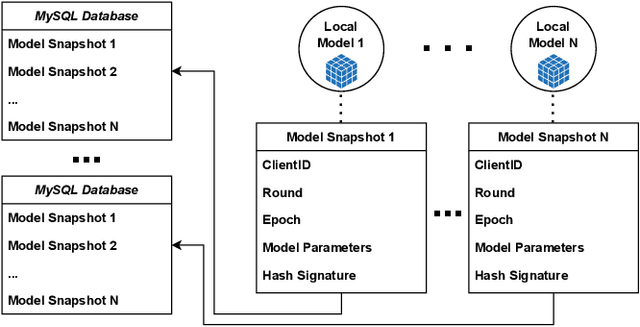
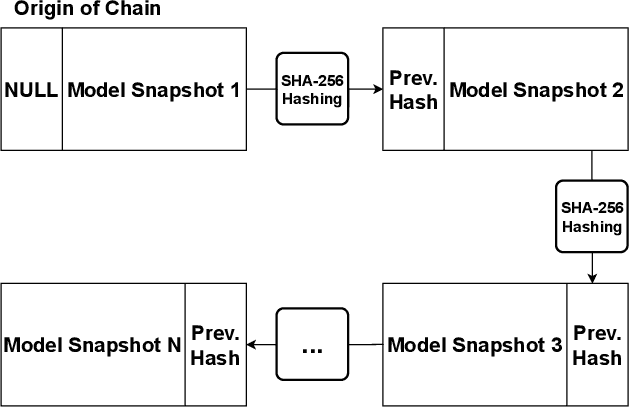
Federated Learning (FL) presents a promising paradigm for training machine learning models across decentralized edge devices while preserving data privacy. Ensuring the integrity and traceability of data across these distributed environments, however, remains a critical challenge. The ability to create transparent artificial intelligence, such as detailing the training process of a machine learning model, has become an increasingly prominent concern due to the large number of sensitive (hyper)parameters it utilizes; thus, it is imperative to strike a reasonable balance between openness and the need to protect sensitive information. In this paper, we propose one of the first approaches to enhance data provenance and model transparency in federated learning systems. Our methodology leverages a combination of cryptographic techniques and efficient model management to track the transformation of data throughout the FL process, and seeks to increase the reproducibility and trustworthiness of a trained FL model. We demonstrate the effectiveness of our approach through experimental evaluations on diverse FL scenarios, showcasing its ability to tackle accountability and explainability across the board. Our findings show that our system can greatly enhance data transparency in various FL environments by storing chained cryptographic hashes and client model snapshots in our proposed design for data decoupled FL. This is made possible by also employing multiple optimization techniques which enables comprehensive data provenance without imposing substantial computational loads. Extensive experimental results suggest that integrating a database subsystem into federated learning systems can improve data provenance in an efficient manner, encouraging secure FL adoption in privacy-sensitive applications and paving the way for future advancements in FL transparency and security features.
Can Transformers Capture Spatial Relations between Objects?
Mar 01, 2024
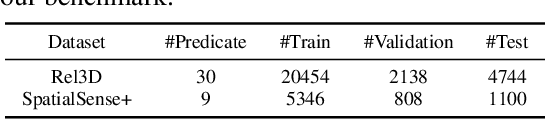


Spatial relationships between objects represent key scene information for humans to understand and interact with the world. To study the capability of current computer vision systems to recognize physically grounded spatial relations, we start by proposing precise relation definitions that permit consistently annotating a benchmark dataset. Despite the apparent simplicity of this task relative to others in the recognition literature, we observe that existing approaches perform poorly on this benchmark. We propose new approaches exploiting the long-range attention capabilities of transformers for this task, and evaluating key design principles. We identify a simple "RelatiViT" architecture and demonstrate that it outperforms all current approaches. To our knowledge, this is the first method to convincingly outperform naive baselines on spatial relation prediction in in-the-wild settings. The code and datasets are available in \url{https://sites.google.com/view/spatial-relation}.