 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Model Selection in High-Dimensional Block-Sparse Linear Regression
Sep 03, 2022
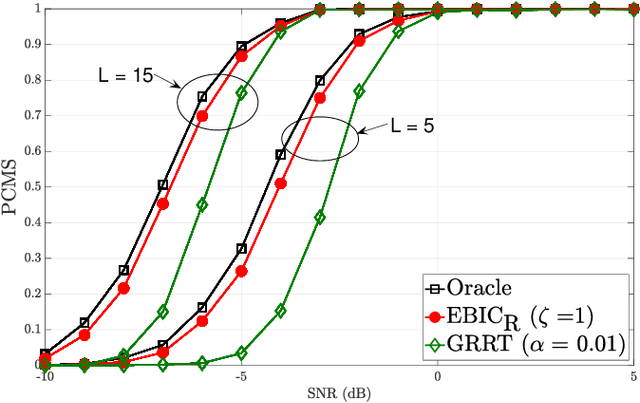
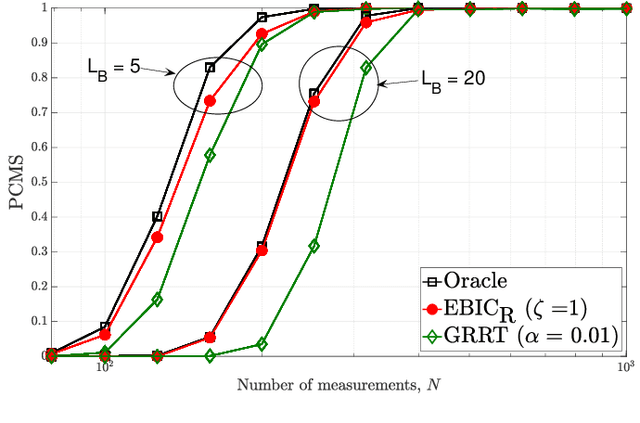
Model selection is an indispensable part of data analysis dealing very frequently with fitting and prediction purposes. In this paper, we tackle the problem of model selection in a general linear regression where the parameter matrix possesses a block-sparse structure, i.e., the non-zero entries occur in clusters or blocks and the number of such non-zero blocks is very small compared to the parameter dimension. Furthermore, a high-dimensional setting is considered where the parameter dimension is quite large compared to the number of available measurements. To perform model selection in this setting, we present an information criterion that is a generalization of the Extended Bayesian Information Criterion-Robust (EBIC-R) and it takes into account both the block structure and the high-dimensionality scenario. The analytical steps for deriving the EBIC-R for this setting are provided. Simulation results show that the proposed method performs considerably better than the existing state-of-the-art methods and achieves empirical consistency at large sample sizes and/or at high-SNR.
DFA: Dynamic Feature Aggregation for Efficient Video Object Detection
Oct 02, 2022
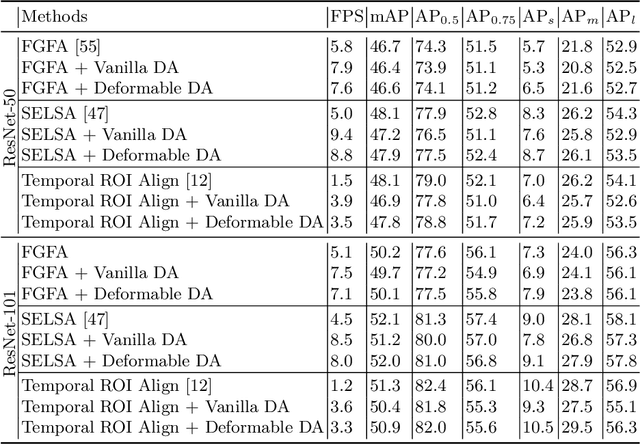
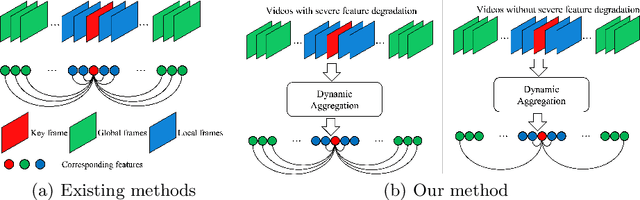

Video object detection is a fundamental yet challenging task in computer vision. One practical solution is to take advantage of temporal information from the video and apply feature aggregation to enhance the object features in each frame. Though effective, those existing methods always suffer from low inference speeds because they use a fixed number of frames for feature aggregation regardless of the input frame. Therefore, this paper aims to improve the inference speed of the current feature aggregation-based video object detectors while maintaining their performance. To achieve this goal, we propose a vanilla dynamic aggregation module that adaptively selects the frames for feature enhancement. Then, we extend the vanilla dynamic aggregation module to a more effective and reconfigurable deformable version. Finally, we introduce inplace distillation loss to improve the representations of objects aggregated with fewer frames. Extensive experimental results validate the effectiveness and efficiency of our proposed methods: On the ImageNet VID benchmark, integrated with our proposed methods, FGFA and SELSA can improve the inference speed by 31% and 76% respectively while getting comparable performance on accuracy.
Loc-VAE: Learning Structurally Localized Representation from 3D Brain MR Images for Content-Based Image Retrieval
Oct 02, 2022
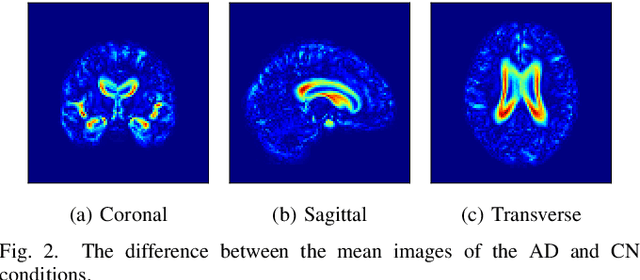
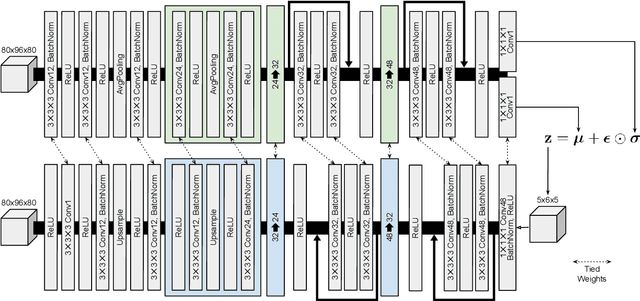
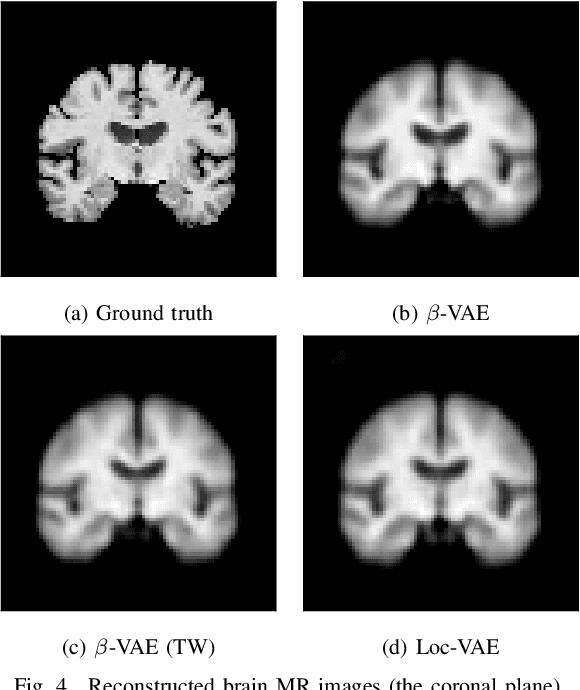
Content-based image retrieval (CBIR) systems are an emerging technology that supports reading and interpreting medical images. Since 3D brain MR images are high dimensional, dimensionality reduction is necessary for CBIR using machine learning techniques. In addition, for a reliable CBIR system, each dimension in the resulting low-dimensional representation must be associated with a neurologically interpretable region. We propose a localized variational autoencoder (Loc-VAE) that provides neuroanatomically interpretable low-dimensional representation from 3D brain MR images for clinical CBIR. Loc-VAE is based on $\beta$-VAE with the additional constraint that each dimension of the low-dimensional representation corresponds to a local region of the brain. The proposed Loc-VAE is capable of acquiring representation that preserves disease features and is highly localized, even under high-dimensional compression ratios (4096:1). The low-dimensional representation obtained by Loc-VAE improved the locality measure of each dimension by 4.61 points compared to naive $\beta$-VAE, while maintaining comparable brain reconstruction capability and information about the diagnosis of Alzheimer's disease.
Passive Non-line-of-sight Imaging for Moving Targets with an Event Camera
Sep 27, 2022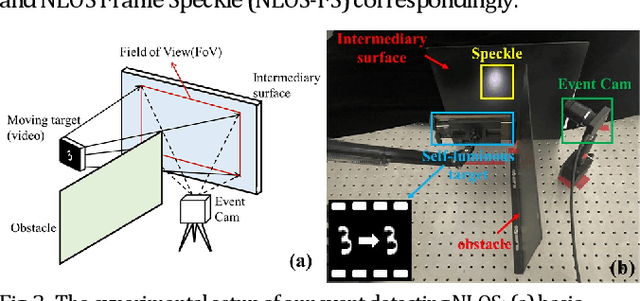



Non-line-of-sight (NLOS) imaging is an emerging technique for detecting objects behind obstacles or around corners. Recent studies on passive NLOS mainly focus on steady-state measurement and reconstruction methods, which show limitations in recognition of moving targets. To the best of our knowledge, we propose a novel event-based passive NLOS imaging method. We acquire asynchronous event-based data which contains detailed dynamic information of the NLOS target, and efficiently ease the degradation of speckle caused by movement. Besides, we create the first event-based NLOS imaging dataset, NLOS-ES, and the event-based feature is extracted by time-surface representation. We compare the reconstructions through event-based data with frame-based data. The event-based method performs well on PSNR and LPIPS, which is 20% and 10% better than frame-based method, while the data volume takes only 2% of traditional method.
Guided-deconvolution for Correlative Light and Electron Microscopy
Aug 19, 2022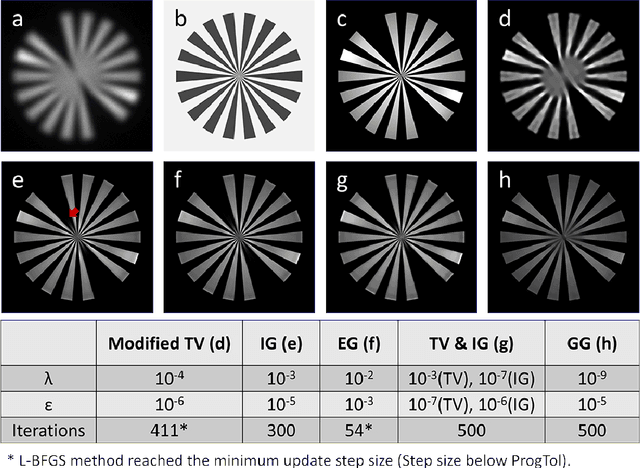
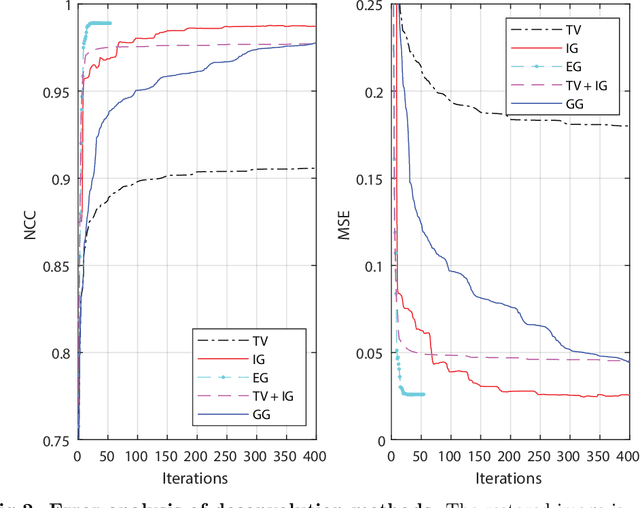

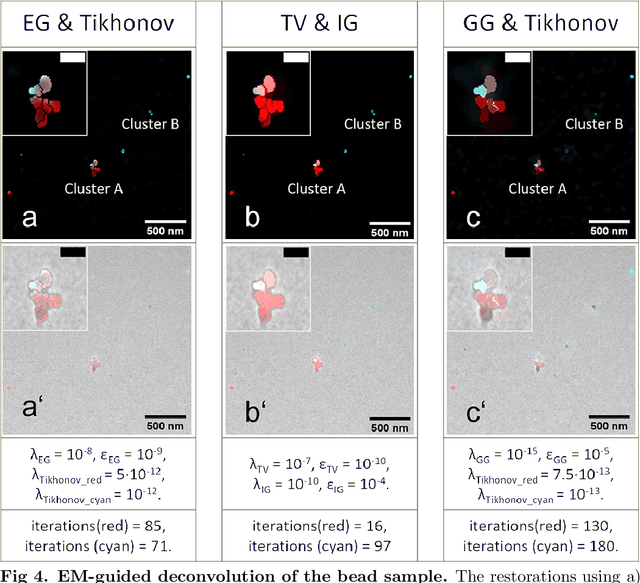
Correlative light and electron microscopy is a powerful tool to study the internal structure of cells. It combines the mutual benefit of correlating light (LM) and electron (EM) microscopy information. However, the classical approach of overlaying LM onto EM images to assign functional to structural information is hampered by the large discrepancy in structural detail visible in the LM images. This paper aims at investigating an optimized approach which we call EM-guided deconvolution. It attempts to automatically assign fluorescence-labelled structures to details visible in the EM image to bridge the gaps in both resolution and specificity between the two imaging modes.
Information retrieval for label noise document ranking by bag sampling and group-wise loss
Mar 12, 2022
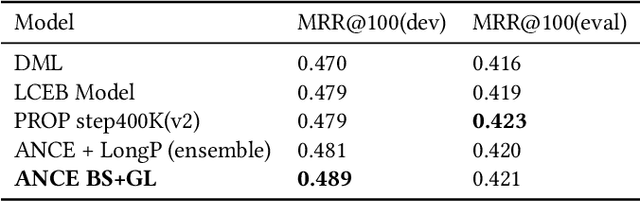
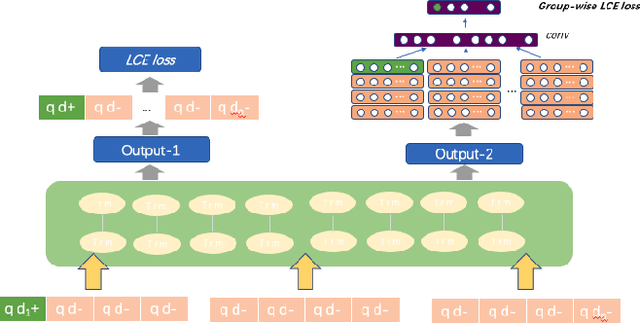
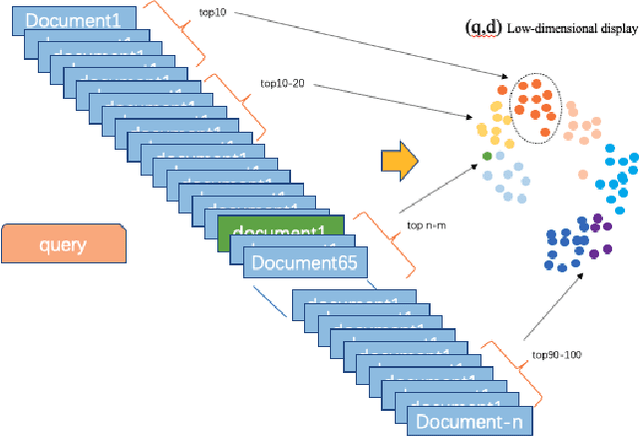
Long Document retrieval (DR) has always been a tremendous challenge for reading comprehension and information retrieval. The pre-training model has achieved good results in the retrieval stage and Ranking for long documents in recent years. However, there is still some crucial problem in long document ranking, such as data label noises, long document representations, negative data Unbalanced sampling, etc. To eliminate the noise of labeled data and to be able to sample the long documents in the search reasonably negatively, we propose the bag sampling method and the group-wise Localized Contrastive Estimation(LCE) method. We use the head middle tail passage for the long document to encode the long document, and in the retrieval, stage Use dense retrieval to generate the candidate's data. The retrieval data is divided into multiple bags at the ranking stage, and negative samples are selected in each bag. After sampling, two losses are combined. The first loss is LCE. To fit bag sampling well, after query and document are encoded, the global features of each group are extracted by convolutional layer and max-pooling to improve the model's resistance to the impact of labeling noise, finally, calculate the LCE group-wise loss. Notably, our model shows excellent performance on the MS MARCO Long document ranking leaderboard.
Fuse: In-Situ Sensemaking Support in the Browser
Aug 31, 2022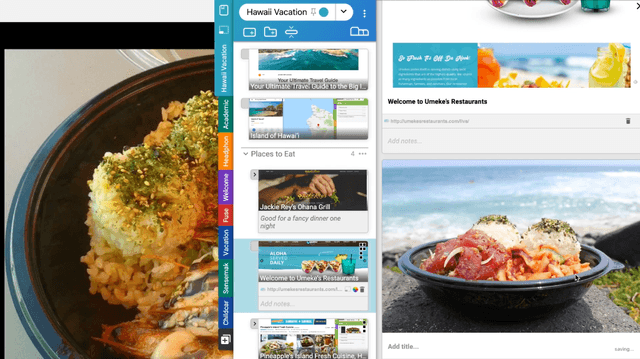

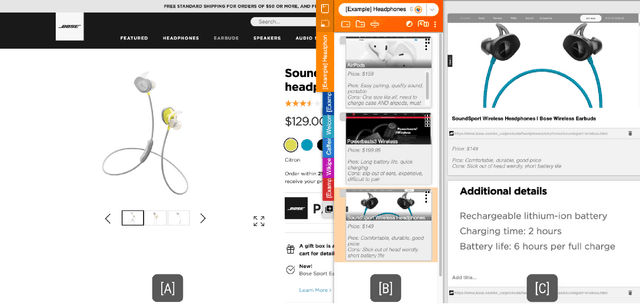
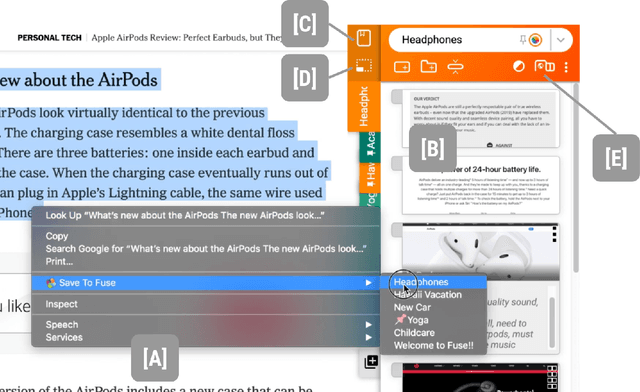
People spend a significant amount of time trying to make sense of the internet, collecting content from a variety of sources and organizing it to make decisions and achieve their goals. While humans are able to fluidly iterate on collecting and organizing information in their minds, existing tools and approaches introduce significant friction into the process. We introduce Fuse, a browser extension that externalizes users' working memory by combining low-cost collection with lightweight organization of content in a compact card-based sidebar that is always available. Fuse helps users simultaneously extract key web content and structure it in a lightweight and visual way. We discuss how these affordances help users externalize more of their mental model into the system (e.g., saving, annotating, and structuring items) and support fast reviewing and resumption of task contexts. Our 22-month public deployment and follow-up interviews provide longitudinal insights into the structuring behaviors of real-world users conducting information foraging tasks.
Estimation of Soiling Losses in Unlabeled PV Data
Sep 20, 2022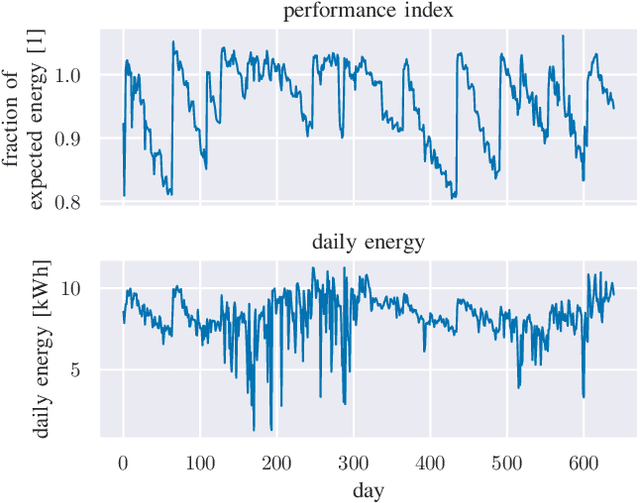
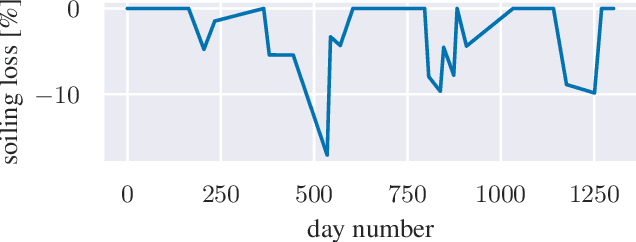
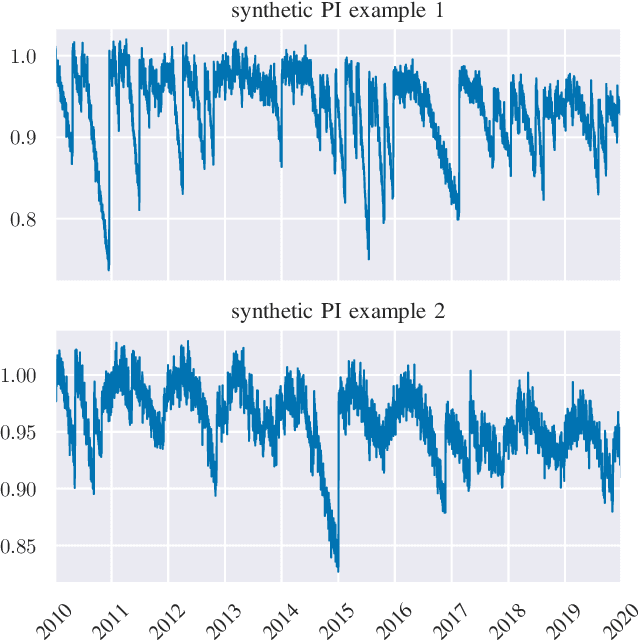
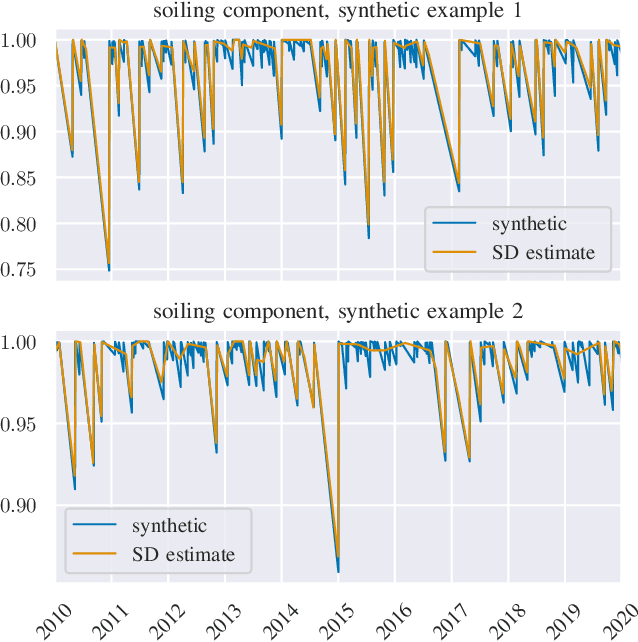
We provide a methodology for estimating the losses due to soiling for photovoltaic (PV) systems. We focus this work on estimating the losses from historical power production data that are unlabeled, i.e. power measurements with time stamps, but no other information such as site configuration or meteorological data. We present a validation of this approach on a small fleet of typical rooftop PV systems. The proposed method differs from prior work in that the construction of a performance index is not required to analyze soiling loss. This approach is appropriate for analyzing the soiling losses in field production data from fleets of distributed rooftop systems and is highly automatic, allowing for scaling to large fleets of heterogeneous PV systems.
Estimation of Shade Losses in Unlabeled PV Data
Sep 20, 2022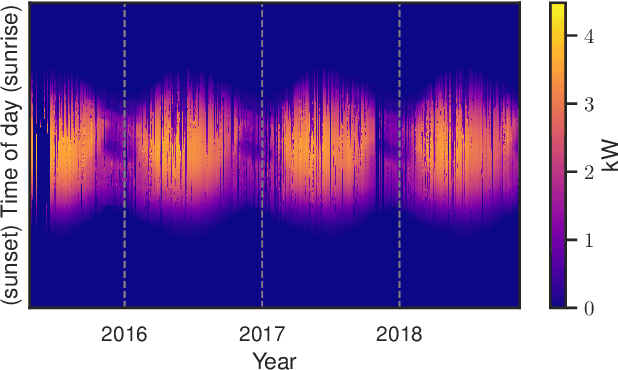
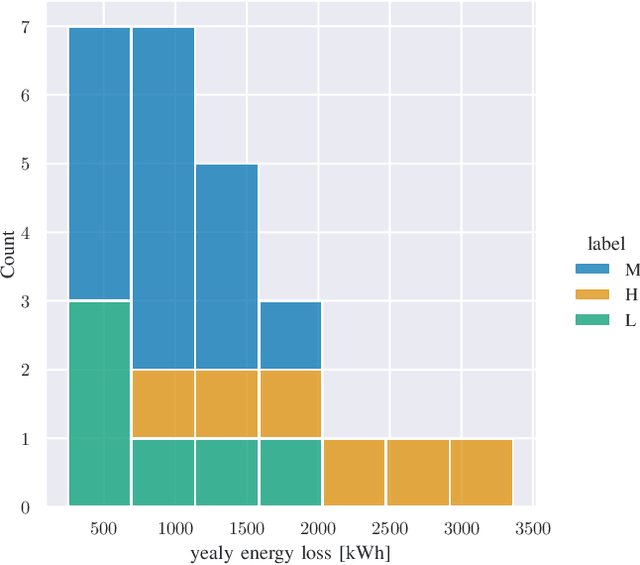
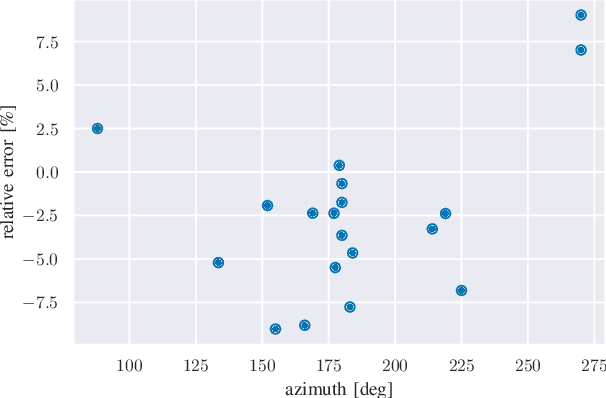
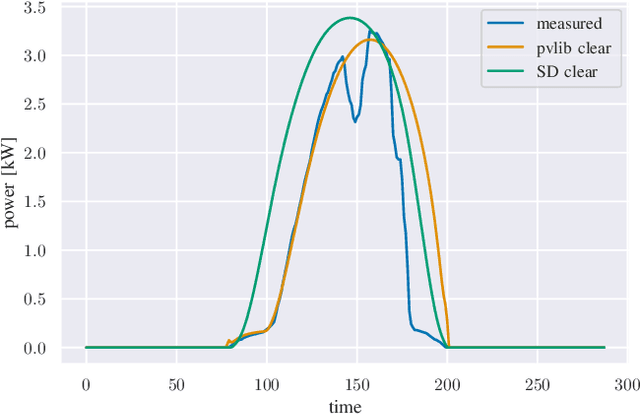
We provide a methodology for estimating the losses due to shade in power generation data sets produced by real-world photovoltaic (PV) systems. We focus this work on estimating shade loss from data that are unlabeled, i.e. power measurements with time stamps but no other information such as site configuration or meteorological data. This approach enables, for the first time, the analysis of data generated by small scale, distributed PV systems, which do not have the data quality or richness of large, utility-scale PV systems or research-grade installations. This work is an application of the newly published signal decomposition (SD) framework, which provides an extensible approach for estimating hidden components in time-series data.
GNM: A General Navigation Model to Drive Any Robot
Oct 07, 2022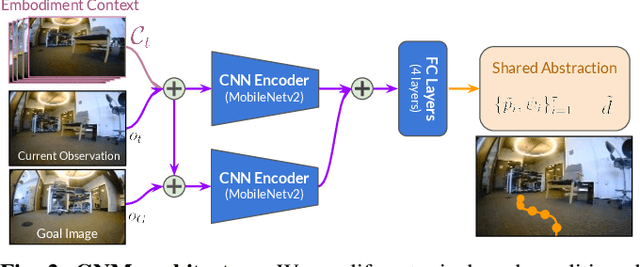

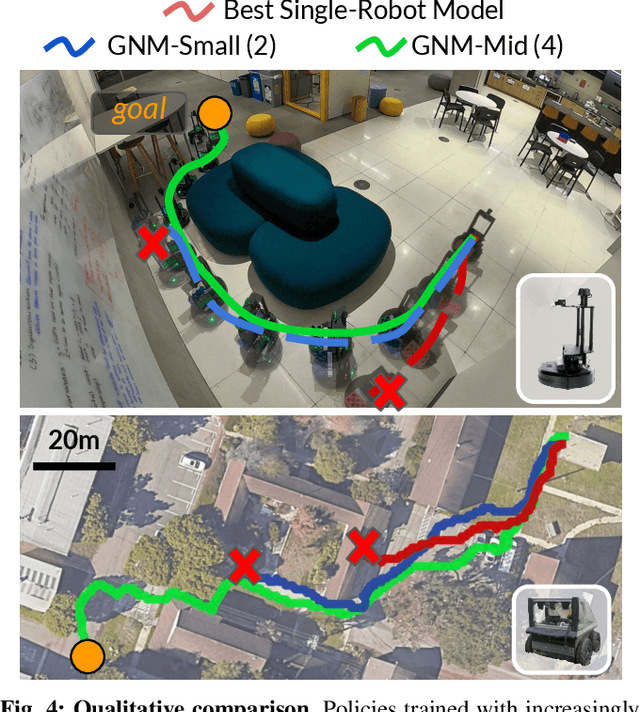
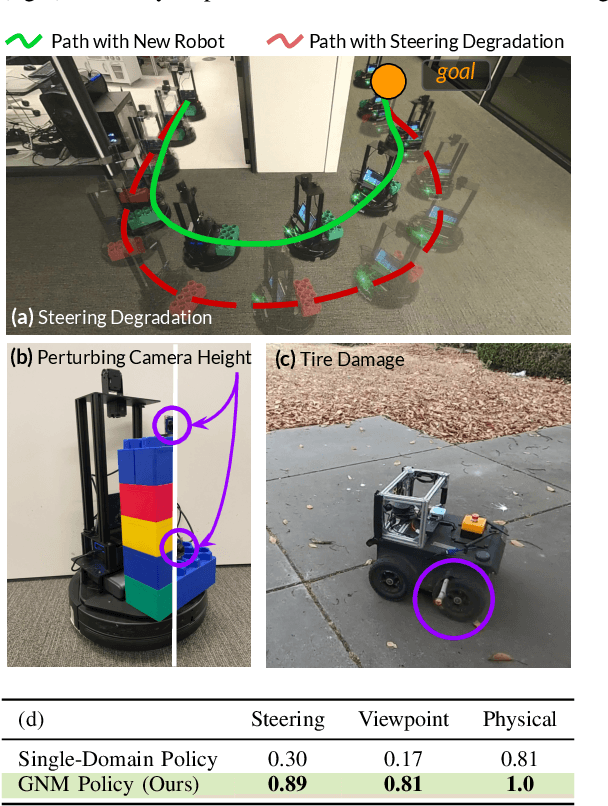
Learning provides a powerful tool for vision-based navigation, but the capabilities of learning-based policies are constrained by limited training data. If we could combine data from all available sources, including multiple kinds of robots, we could train more powerful navigation models. In this paper, we study how a general goal-conditioned model for vision-based navigation can be trained on data obtained from many distinct but structurally similar robots, and enable broad generalization across environments and embodiments. We analyze the necessary design decisions for effective data sharing across robots, including the use of temporal context and standardized action spaces, and demonstrate that an omnipolicy trained from heterogeneous datasets outperforms policies trained on any single dataset. We curate 60 hours of navigation trajectories from 6 distinct robots, and deploy the trained GNM on a range of new robots, including an underactuated quadrotor. We find that training on diverse data leads to robustness against degradation in sensing and actuation. Using a pre-trained navigation model with broad generalization capabilities can bootstrap applications on novel robots going forward, and we hope that the GNM represents a step in that direction. For more information on the datasets, code, and videos, please check out http://sites.google.com/view/drive-any-robot.